🔍 Valgrind Cachegrind 全解析:用缓存效率,换系统流畅!
缓存是现代 CPU 性能的护城河,而你写的代码,可能正在悄悄地把桥炸了。
本文将通过两个对比鲜明的示例,深入理解 Cachegrind 的工作原理、常见缓存问题,以及对 UI 或系统层面的真实影响。
🧠 为什么要关注缓存?
在现代 CPU 中,访问内存的代价是巨大的:
| 类型 | 延迟大约 | 对比 CPU 周期 |
|---|---|---|
| L1 Cache | 1~4 cycles | 非常快 |
| L2 Cache | 10~20 cycles | 可接受 |
| L3 Cache | 30~70 cycles | 显著慢 |
| 主存 DRAM | 100~300 cycles | 很慢 |
程序中一旦 Cache Miss(缓存未命中),CPU 就必须去访问慢速内存,直接拖垮性能。
🧰 工具介绍:Valgrind 的 Cachegrind
Cachegrind 是 Valgrind 中的一个子工具,用于模拟:
- 一级指令缓存(I1)
- 一级数据缓存(D1)
- 二级统一缓存(L2/LL)
- 以及 分支预测器(branch prediction)
它能详细报告:
👉 指令/数据访问量、缓存命中率、缓存未命中导致的性能浪费等指标。
🚀 基本命令格式
valgrind --tool=cachegrind ./your_program
输出将保存为 cachegrind.out.<pid> 文件。使用 cg_annotate 查看人类可读的报告:
cg_annotate cachegrind.out.<pid>
📦 示例程序对比:bad vs good cache
我们用一个简单的二维数组访问方式差异,模拟两种缓存使用情况。
🔴 bad_cache.c:列优先访问(缓存不友好)
#include <stdio.h>
#define N 1000
int a[N][N];
int main() {
int sum = 0;
for (int j = 0; j < N; j++) // 列
for (int i = 0; i < N; i++) // 行
sum += a[i][j];
printf("sum = %d\n", sum);
return 0;
}
✅ good_cache.c:行优先访问(缓存友好)
#include <stdio.h>
#define N 1000
int a[N][N];
int main() {
int sum = 0;
for (int i = 0; i < N; i++) // 行
for (int j = 0; j < N; j++) // 列
sum += a[i][j];
printf("sum = %d\n", sum);
return 0;
}
编译命令(禁用优化并保留调试符号):
gcc -O0 -g -o good_cache good_cache.c
gcc -O0 -g -o bad_cache bad_cache.c
📊 运行 Cachegrind 观察差异
valgrind --tool=cachegrind ./good_cache
valgrind --tool=cachegrind ./bad_cache
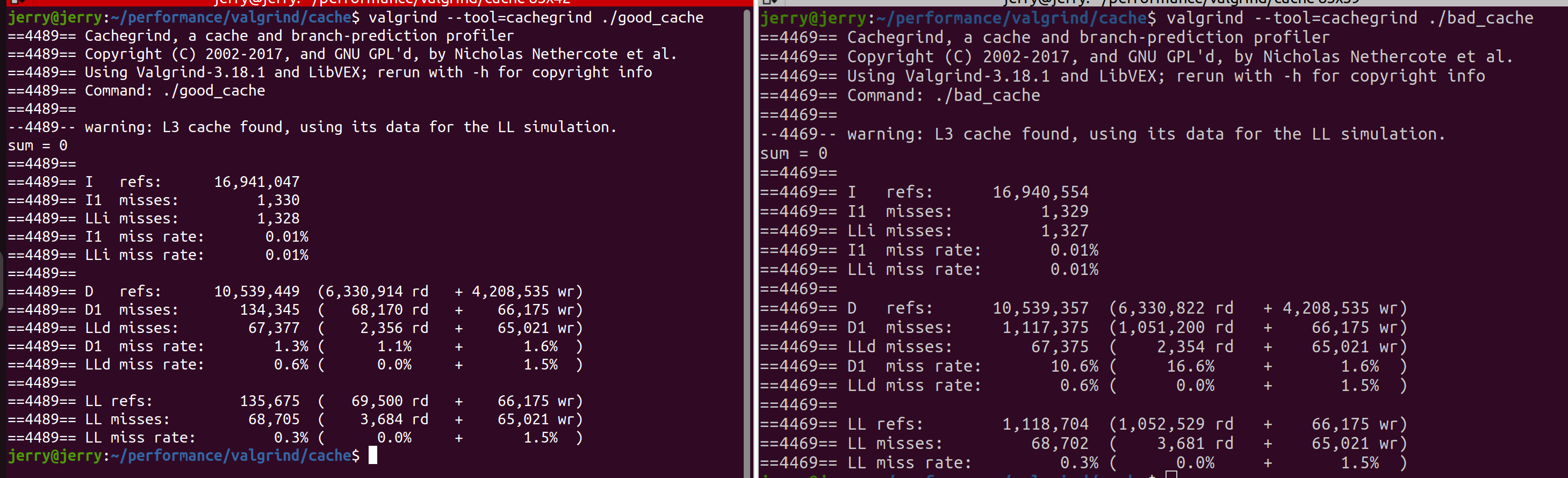
✅ good_cache 结果片段:
D1 misses: 134,345
LLd misses: 67,377
❌ bad_cache 结果片段:
D1 misses: 1,117,379
LLd misses: 67,375
📌 相比
good_cache,bad_cache的 一级数据缓存未命中暴涨了 8 倍!
🎯 关键术语解释
| 缩写 | 含义 |
|---|---|
| D1 misses | 一级数据缓存未命中数 |
| LLd misses | 最后一级缓存未命中(通常为 L3) |
| I1 misses | 一级指令缓存未命中 |
| refs | 读写总次数 |
| miss rate | 未命中比例,越低越好 |
🧩 Cache 问题在实际项目中的表现
| 表现场景 | 原因 | Cachegrind 如何体现 |
|---|---|---|
| UI 页面卡顿/掉帧 | 数据布局或访问顺序不当 | D1 Misses 高 |
| 高性能计算性能不达标 | 内存局部性差,算法缓存效率低 | LL Misses 高 |
| 嵌入式系统异常耗电 | DRAM 访问频繁,唤醒率高 | D1/LLd Misses 高 |
| 某函数极慢但代码正常 | 数据结构访问不连续 | cg_annotate 显示热点 |
📌 小技巧:如何改善缓存命中率?
✅ 按行顺序访问数据(行主序)
✅ 尽量避免链表、散乱内存访问结构
✅ 使用 restrict 提示优化器(高阶技巧)
✅ 考虑手动预取(如 __builtin_prefetch)
🧠 小结
Cachegrind 是低成本掌握“代码和 CPU 之间对话”的利器。
它不但能定位问题,还能量化你优化前后的差异。学会它,就等于学会性能调优的放大镜。
📥 推荐命令备查表
# 基础用法
valgrind --tool=cachegrind ./myapp
# 查看详细注释
cg_annotate cachegrind.out.<pid>
# 自定义模拟参数
valgrind --tool=cachegrind --I1=64,1,64 --D1=64,1,64 --LL=512,4,64 ./myapp