1. 简介
对于企业级应用来说,尤其是后台服务,考虑的因素会非常多。比如大模型问答的响应速度,系统服务的稳定性,业务请求的错误率,资源的利用率等等多个方面。不同应用场景,考虑的因素也会有所不同。
企业需要处理大量用户或设备的请求,尤其是在高峰时段。如果服务吞吐量低,可能导致延迟增加,用户体验下降,甚至服务崩溃。如果并发量不足,用户可能会遇到等待或超时;吞吐量低的话,处理速度慢,整体效率低下。
因此我们需要了解硬件资源的压力,便于采购
我们基于Ollama模型服务启动的 REST API接口,每秒生成的 Token数量可以被视为系统的吞吐量,因此我们需要一些方法,来根据实际的业务需求来评估当前的硬件资源是否满足需求,或者应该如何去采购硬件资源。
2. Ollama两种启动方式
在进行压力测试前,我们先了解ollama的两种启动方式
2.1 ollama serve(手动启动)
定义:直接执行 Ollama 服务的命令,在前台运行。
特点:
前台运行:阻塞当前终端,输出日志直接显示在控制台。
临时性:进程与终端会话绑定,关闭终端或按
Ctrl+C会终止服务。无自动恢复:崩溃后需手动重启。
依赖用户会话:以当前用户权限运行(可能权限不足)。
适合场景:调试、开发或临时测试。
手动启动可以在执行命令前加入参数
OLLAMA_HOST=0.0.0.0:11434 CUDA_VISIBLE_DEVICES=0,1 OLLAMA_SCHED_SPREAD=1 OLLAMA_NUM_PARALLEL=10 ollama serve如果你的模型位置不是默认安装位置,下面命令还需要指定模型位置变量 ,否则会找不到模型
OLLAMA_HOST=0.0.0.0:11434 CUDA_VISIBLE_DEVICES=0,1 OLLAMA_SCHED_SPREAD=1 OLLAMA_NUM_PARALLEL=10 OLLAMA_MODELS=/home/ollama/models ollama serve 2.2 systemctl ollama.service(系统服务管理)
定义:通过 Systemd(Linux 系统服务管理器)将 Ollama 注册为守护进程。
核心优势:
后台守护进程:服务在后台运行,不占用终端。
开机自启:通过
systemctl enable ollama实现系统启动时自动运行。自动恢复:配置
Restart=on-failure可在崩溃后自动重启。集中管理:
启动:
sudo systemctl start ollama停止:
sudo systemctl stop ollama查看状态:
systemctl status ollama日志:
journalctl -u ollama.service
安全隔离:以专用系统用户(如
ollama用户)运行,提升安全性。资源控制:可配置 CPU/内存限制(通过
systemd.resource-control)。
创建服务文件
sudo nano /etc/systemd/system/ollama.service配置示例
[Unit] Description=Ollama Service After=network.target [Service] ExecStart=/usr/bin/ollama serve # 根据实际路径调整 User=ollama # 专用用户(需提前创建) Group=ollama Restart=on-failure RestartSec=5 Environment="HOME=/var/lib/ollama" # 模型存储目录 [Install] WantedBy=multi-user.target启用服务
sudo systemctl daemon-reload sudo systemctl enable ollama # 开机自启 sudo systemctl start ollama # 立即启动
2.3 区别差异
直接运行ollama serve无需额外配置文件,而通过systemctl管理时需创建服务文件(如/etc/systemd/system/ollama.service),并设置重启策略、用户权限等参数。
Ollama 服务启动方式对比:
| 特性 | ollama serve 启动 | systemd 启动 |
|---|---|---|
| 运行方式 | 前台运行,依赖终端 | 后台运行,独立于终端 |
| 服务管理 | 手动管理 | 支持启动、停止、重启、状态查看 |
| 自动恢复 | 不支持 | 支持崩溃后自动重启 |
| 开机自启动 | 不支持 | 支持 |
| 日志管理 | 输出到终端,无持久化 | 由 journald 管理,支持持久化 |
| 资源控制 | 无 | 支持 CPU、内存等资源限制 |
| 适用场景 | 开发、测试、临时运行 | 生产环境、长期运行 |
2.4 何时选择哪种方式?
生产环境:必须用
systemctl,确保稳定性、自动恢复和资源隔离。开发/调试:临时使用
ollama serve快速查看日志,但正式运行需转为 Systemd 服务。
3. Ollama压力测试
3.1 压力测试关注指标
我们测试 Ollama 模型服务的吞吐量和并发量,需要核心关注的是以下几点:
- 使用
REST API接口进行测试,可以尝试使用/api/generate或者/api/chat,真实模拟用户在实际使用中的请求模式,帮助评估系统在真实场景下的表现。 Ollama原生的REST API接口支持多个控制Ollama行为的参数,可以更灵活的控制测试流程,其中:num_predict参数来控制生成的token数量keep_alive设置为0,使用完模型后立即卸载temperature参数来控制生成文本的多样性,很多情况下,希望生成的文本尽可能保持一致,会将其设置为0,
- 根据
Ollama的REST API接口返回响应体中的eval_count和eval_duration来计算每秒生成的Token数量,即吞吐量,而不是用resquest发起和接收到响应的时间差值来计算,将模型服务和网络延迟解耦,更准确的评估模型服务的吞吐量。
3.2 测试前环境设置
3.2.1 关闭systemd 启动的Ollama 服务
因此,在测试前需要先关闭通过systemd 启动的Ollama 服务,操作方法如下:
- 先通过
systemctl stop ollama停止Ollama服务,否则systemd会监听ollama.service文件并不断自动拉起服务; - 接着通过
lsof -i:11434命令查看ollama serve进程的PID; - 然后通过
kill -9 <PID>命令杀掉进程; - 再次查看就会发现进程已经被杀掉;
3.2.2 使用ollama serve 命令启动Ollama
如果你的模型位置不是默认安装位置,下面命令还需要指定模型位置变量 ,否则会找不到模型
OLLAMA_HOST=192.168.11.103:11434 CUDA_VISIBLE_DEVICES=0,1 OLLAMA_SCHED_SPREAD=1 OLLAMA_NUM_PARALLEL=10 OLLAMA_MODELS=/home/ollama/models ollama serve3.3 执行测试代码
3.3.1 压力测试前提环境约定
- 约定测试模型:deepseek-r1:1.5b
- 客户能够接受的最长响应时间:5s,10s,20s
- 每次对话,都能够正确返回结果,成功率95%以上
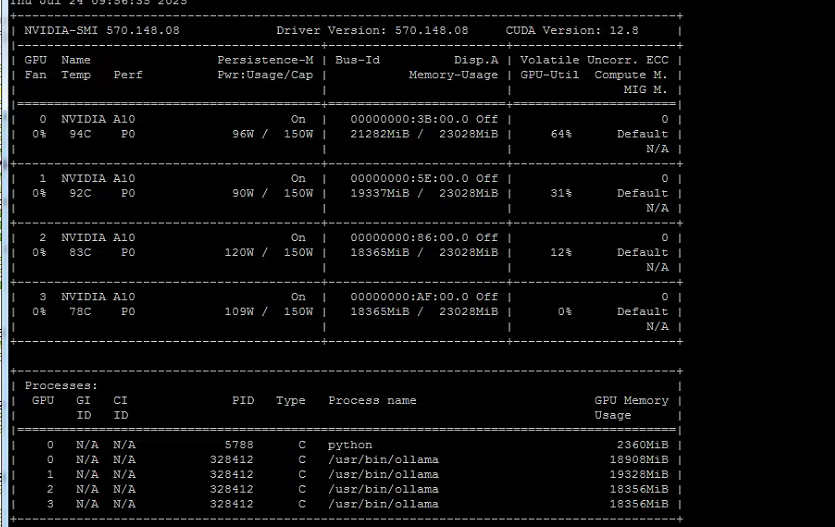
- 目前4张 NVIDIA A10 24G的显卡
- 显卡负载不超过 80%
- 每个测试问题,限制300token的回答结果
代码核心参数设定如下:
benchmark = OllamaBenchmark(
url="http://192.168.11.103:11434", # 这里替换成实际的ollama endpoint
model="deepseek-r1:32b" # 这里替换成实际要进行测试的模型名称
)
concurrency_results = await benchmark.find_max_concurrency(
start_concurrent=2, # 从2开始
max_concurrent=10, # 最多只测到10个并发
requests_per_test=10, # 每轮只测10个请求
success_rate_threshold=0.95, # 成功率要求提高到95%
latency_threshold=20.0 # 延迟阈值降低到20秒
)3.3.2 代码参数解释
- start_concurrent=2, # 从2开始
- max_concurrent=10, # 最多只测到10个并发
每一次代码执行测试的时候,从2个并发量递增到10个并发量(线程数量)
- requests_per_test=10, # 每轮只测10个请求
- success_rate_threshold=0.95, # 成功率要求提高到95%
单测某个并发量等级(如3个并发)的时候,执行10次请求,如果测一个并发量只测一次请求,没有代表意义,执行10次请求,便于我们统计当前并发量等级平均的测量指标效果(平均吞吐量,平均耗时等),同时10次请求,便于统计成功率,并不一定每次请求大模型都会成功返回,可能异常报错,因此要设定成功率!
- latency_threshold=20.0 # 延迟阈值降低到20秒
并发过程中,每次向大模型发起的请求响应时长(通常客户能够忍受等待时长)
3.4 分析测试结果
3.4.1 四卡负载测试结果
(base) root@jinhu:/home/ollama# OLLAMA_HOST=192.168.11.103:11434 CUDA_VISIBLE_DEVICES=0,1,2,3 OLLAMA_SCHED_SPREAD=1 OLLAMA_NUM_PARALLEL=10 OLLAMA_MODELS=/home/ollama/models ollama serve
time=2025-07-24T08:08:02.817Z level=INFO source=routes.go:1235 msg="server config" env="map[CUDA_VISIBLE_DEVICES:0,1,2,3 GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_CONTEXT_LENGTH:4096 OLLAMA_DEBUG:INFO OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://192.168.11.103:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/home/ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NEW_ENGINE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:10 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://* vscode-file://*] OLLAMA_SCHED_SPREAD:true ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]"
time=2025-07-24T08:08:02.818Z level=INFO source=images.go:476 msg="total blobs: 11"
time=2025-07-24T08:08:02.818Z level=INFO source=images.go:483 msg="total unused blobs removed: 0"
time=2025-07-24T08:08:02.818Z level=INFO source=routes.go:1288 msg="Listening on 192.168.11.103:11434 (version 0.9.6)"
time=2025-07-24T08:08:02.818Z level=INFO source=gpu.go:217 msg="looking for compatible GPUs"
time=2025-07-24T08:08:03.623Z level=INFO source=types.go:130 msg="inference compute" id=GPU-c0bcb996-6767-7086-1912-fe7fdf793bf0 library=cuda variant=v12 compute=8.6 driver=12.8 name="NVIDIA A10" total="22.1 GiB" available="19.5 GiB"
time=2025-07-24T08:08:03.623Z level=INFO source=types.go:130 msg="inference compute" id=GPU-5b199ee0-0ff8-f21b-db58-4d922ea7fc34 library=cuda variant=v12 compute=8.6 driver=12.8 name="NVIDIA A10" total="22.1 GiB" available="21.8 GiB"
time=2025-07-24T08:08:03.623Z level=INFO source=types.go:130 msg="inference compute" id=GPU-05156999-de2d-5ae1-d14f-36834b4b7648 library=cuda variant=v12 compute=8.6 driver=12.8 name="NVIDIA A10" total="22.1 GiB" available="21.8 GiB"
time=2025-07-24T08:08:03.623Z level=INFO source=types.go:130 msg="inference compute" id=GPU-ff036e62-e4b7-0005-cbf4-fa9e16ffd04b library=cuda variant=v12 compute=8.6 driver=12.8 name="NVIDIA A10" total="22.1 GiB" available="21.8 GiB"
参数设定如下
# 使用保守的并发测试参数
concurrency_results = await benchmark.find_max_concurrency(
start_concurrent=2, # 从2开始
max_concurrent=10, # 最多只测到5个并发
requests_per_test=10, # 每轮只测10个请求
success_rate_threshold=0.95, # 成功率要求提高到95%
latency_threshold=20.0 # 延迟阈值降低到5秒
)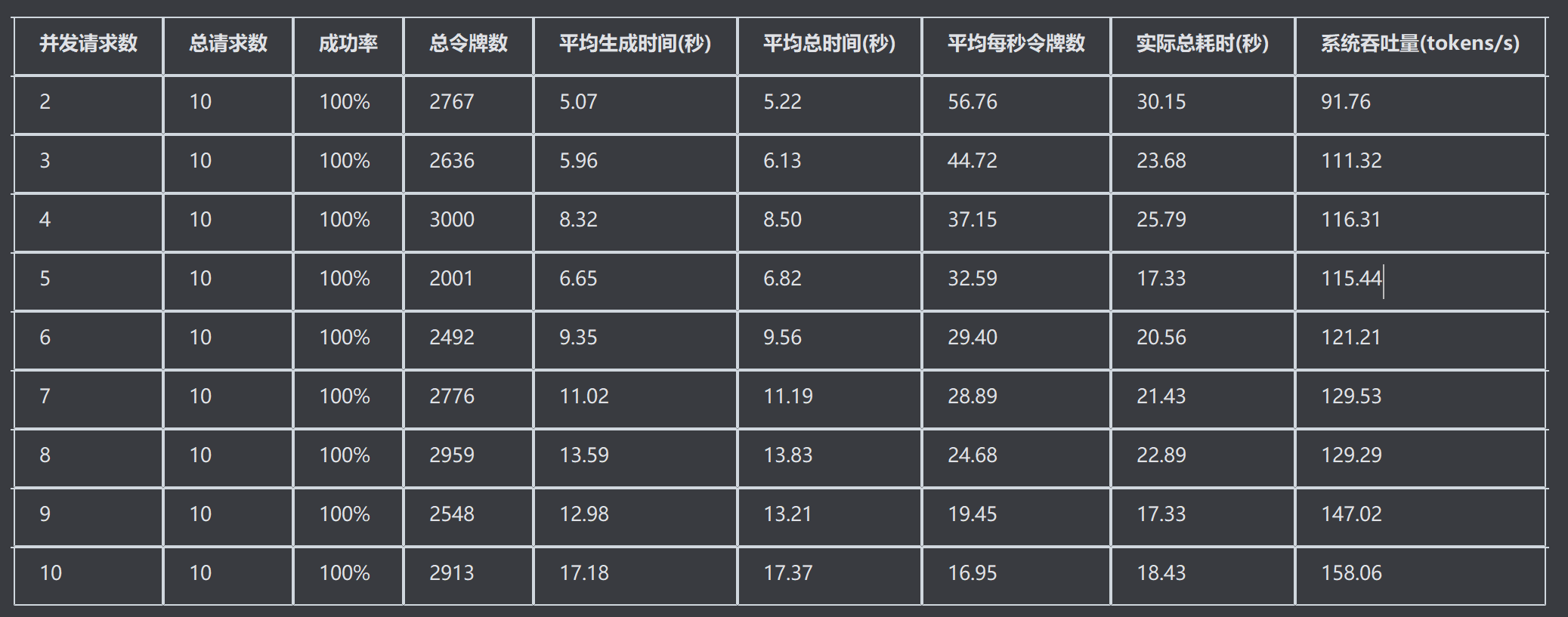
按照平均生成时间,结合系统吞吐量,可以看出来 并发10次,平均需要17秒响应时间,吞吐量158.06 tokens/s
3.4.2 双卡负载测试结果
参数如上,结果如下
(base) root@jinhu:/home/ollama# OLLAMA_HOST=192.168.11.103:11434 CUDA_VISIBLE_DEVICES=0,1 OLLAMA_SCHED_SPREAD=1 OLLAMA_NUM_PARALLEL=10 OLLAMA_MODELS=/home/ollama/models ollama serve
time=2025-07-24T09:21:36.413Z level=INFO source=routes.go:1235 msg="server config" env="map[CUDA_VISIBLE_DEVICES:0,1 GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_CONTEXT_LENGTH:4096 OLLAMA_DEBUG:INFO OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://192.168.11.103:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/home/ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NEW_ENGINE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:10 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://* vscode-file://*] OLLAMA_SCHED_SPREAD:true ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]"
time=2025-07-24T09:21:36.414Z level=INFO source=images.go:476 msg="total blobs: 11"
time=2025-07-24T09:21:36.414Z level=INFO source=images.go:483 msg="total unused blobs removed: 0"
time=2025-07-24T09:21:36.414Z level=INFO source=routes.go:1288 msg="Listening on 192.168.11.103:11434 (version 0.9.6)"
time=2025-07-24T09:21:36.414Z level=INFO source=gpu.go:217 msg="looking for compatible GPUs"
time=2025-07-24T09:21:36.877Z level=INFO source=types.go:130 msg="inference compute" id=GPU-c0bcb996-6767-7086-1912-fe7fdf793bf0 library=cuda variant=v12 compute=8.6 driver=12.8 name="NVIDIA A10" total="22.1 GiB" available="19.5 GiB"
time=2025-07-24T09:21:36.877Z level=INFO source=types.go:130 msg="inference compute" id=GPU-5b199ee0-0ff8-f21b-db58-4d922ea7fc34 library=cuda variant=v12 compute=8.6 driver=12.8 name="NVIDIA A10" total="22.1 GiB" available="21.8 GiB"

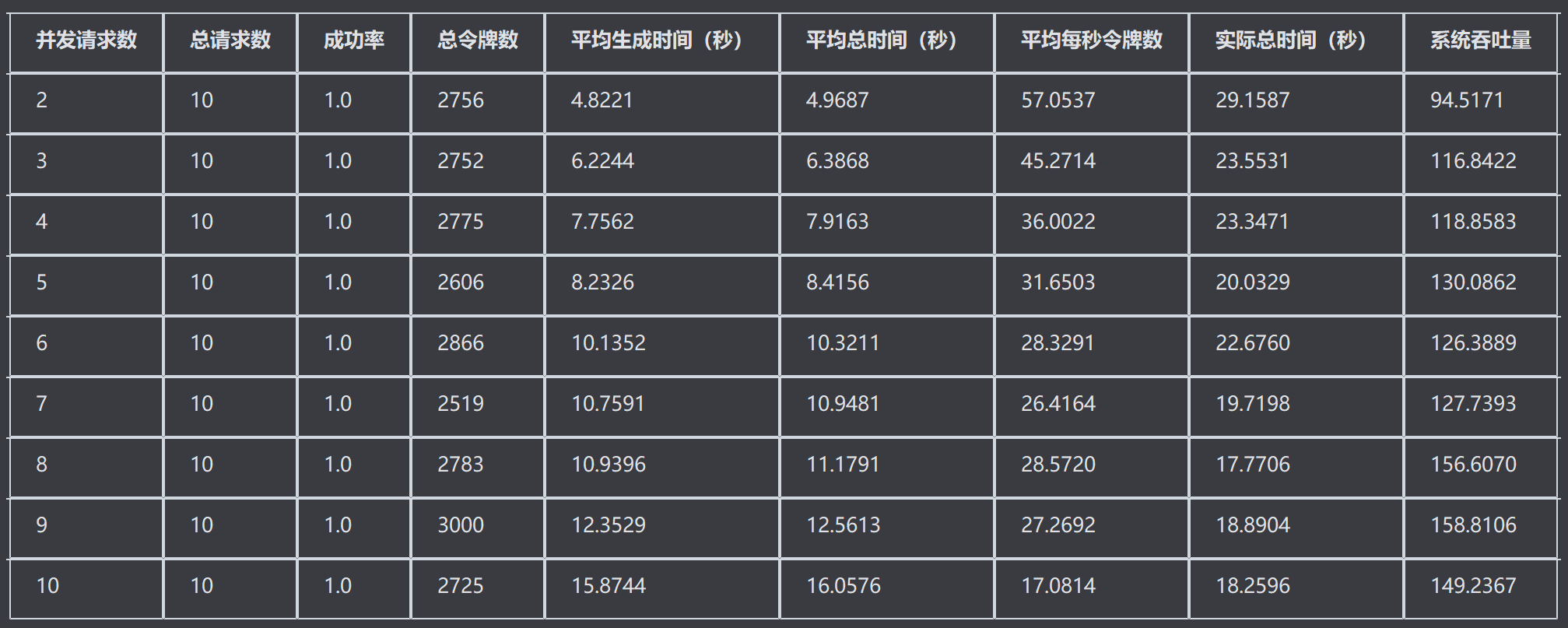
3.4.3 总结
双卡和四卡,测试结果来看,并非显卡越多,效果越好。
3.4.3.1 加餐:
当我测试deepseek-r1:70B的模型时,显卡的负载几度超过90%,无论双卡,还是四卡
双卡单个请求测试结果:

每秒token都是个位数的输出,等待时长,更是3分钟左右,并发就更不需要测试了!!!!
四卡单个请求测试结果:

四卡紧在时间上相比双卡,快了3倍,吞吐量仍然难以接受
测试中发现显卡负载,每张卡上都是不均匀的