目录
一,Redis持久化
redis持久化的两种方式:RDB和AOF
1,RDB
RDB 持久化是把当前进程数据⽣成快照保存到硬盘的过程,触发 RDB 持久化过程分为手动触发和⾃动触发。
手动触发分别对应 save 和 bgsave 命令:
• save 命令:阻塞当前 Redis 服务器,直到 RDB 过程完成为⽌,基本不采用。
• bgsave 命令:Redis 进程执行fork 操作创建⼦进程,RDB 持久化过程由子进程负责,完成后自动结束。阻塞只发生在 fork 阶段,⼀般时间很短。
Redis 内部的所有涉及 RDB 的操作都采⽤类似 bgsave 的方式。
除了手动触发之外,Redis 运行自动触发 RDB 持久化机制,这个触发机制才是在实战中有价值的。
使用save 配置。如 "save m n" 表示m 秒内数据集发生了 n 次修改,自动 RDB 持久化。
从节点进行全量复制操作时,主节点自动进行RDB 持久化,随后将 RDB ⽂件内容发送给从节点。(这个在主从复制部分会进行说明)。
执行shutdown 命令关闭 Redis 时,执行RDB 持久化。
2,RDB生成文件流程
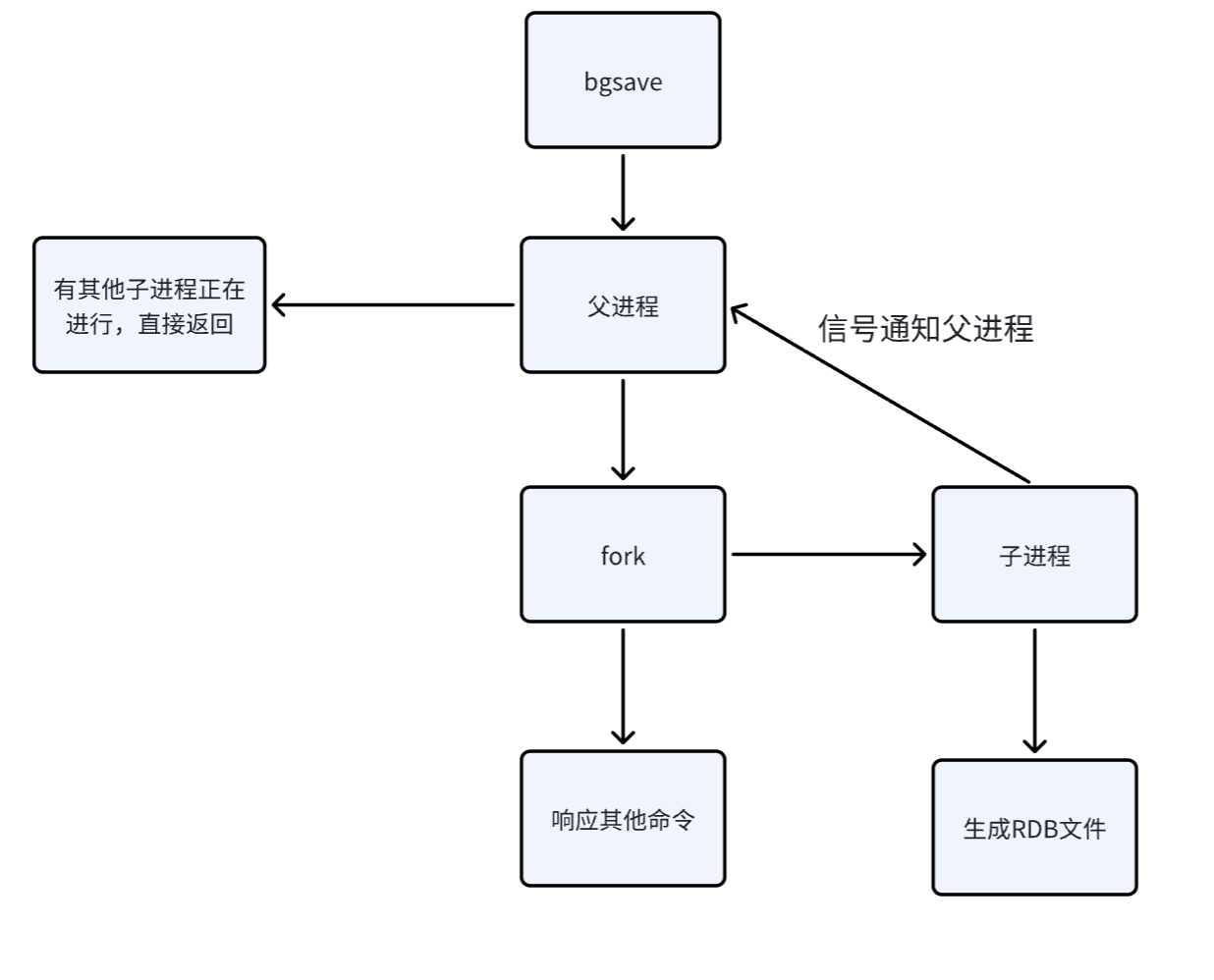
执行bgsave 命令,Redis ⽗进程判断当前进是否存在其他正在执行的子进程。比如现在已经有一个子进程正在执行bgsave了,此时就把当前的bgsave给返回。也就是说,此时redis服务器可能会收到多个客户端发送来的bgsave命令,但只处理一个,其他的都返回。
父进程执行fork 创建⼦进程。
子进程负责写文件,生成快照的过程。父进程继续接受其他客户端的请求,继续正常提供服务。这个写文件的过程中,如果rdb文件不存在,则直接创建文件再写入数据。而如果存在rdb文件,就会把数据先保存到一个临时rdb文件中,当快照生成完毕之后,再删除之前旧的rdb,把临时rdb文件的名称改为原来rdb文件的名称。这里涉及到一个文件替换的过程。
子进程完成持久后工作后,就会通过信号通知父进程,之后子进程就可以退出销毁了。
3,RDB特点
1,RDB:RDB是一个紧凑的二进制文件,代表redis在某一时刻的数据快照。
2,Redis加载RDB比AOF的方式更快:RDB这里使用的是二进制的方式来组织数据的,直接把数据加载到内存中,按照字节的格式去出来,放到结构体/对象中即可。而AOF是使用文本的方式来组织数据的,这会涉及到一些字符串分割操作。
3,RDB文件使用特点的二进制格式保存,Redis版本演进过程中,有多个RDB版本没兼容性可能有风险。
4,RDB最大的问题:
不能实时的持久化保存数据。在两次生成快照之间,实时的数据可能会随着重启而丢失。
5,AOF
类似于MySQL的的binlog,就会把用户的每个操作都记录在文件中。当redis重新启动的时候,就会读取这个AOF文件的内容,用来恢复数据。
aof功能是默认关闭的,可以通过修改配置文件或者命令来启动。
当aof功能开启后,rdb就不再生效了,服务器启动的时候就不会读取rdb文件了。
6,AOF写文件的机制
redis是一个单线程的服务器,AOF机制并非是让工作线程把数据写入硬盘,而是先写入内存中的一块缓冲区中,积累一波后,再写入硬盘中。
而写入缓冲区,可以大大降低写硬盘的次数。
硬盘上读写数据,顺序读写的速度是很快的(但还是比内存慢很多),而随机读写的速度是比较慢的。
而AOF每次把新的操作写入到原有文件的末尾,属于顺序写入。
但是AOF写文件的本质仍然是向内存中写,如果redis服务器挂了,那么内存中的数据仍然是会丢失的。
所以redis给出了一些选项,来决定缓冲区的刷新策略。
当缓冲区的刷新频率越高,也就是写文件操作的频率越高,对性能的影响就越大,同时数据的可靠性就越高。
当缓冲区的刷新频率越高低,也就是写文件操作的频率越低,对性能的影响就越小,同时数据的可靠性就越低。
一共有3个选项,always,everysec,no;always表示当向缓冲区写入数据后,立即刷新,立即执行写文件的操作;
everysec表示每秒执行刷新的操作;no,频率最低,将什么时候刷新交给操作系统,比如当服务退出了,执行刷新操作,当缓冲区满了,执行刷新操作。
默认情况下采取的是everysec刷新策略。
7,AOF文件的重写机制
Redis存在一种机制,能够对aof文件进行整理操作,这个整理操作就是剔除其中的冗余操作,并且合并一些操作,达到给aof文件瘦身的效果。
比如现在有以下几个操作:
1,set key 111,set key 222,set key 333,最后整合成一个命令set key 333,也就是前面的两个操作不用保存,只保留最后一个即可。
2,同理还有对列表的操作:lpush key 111,lpush key 222,lpush key 333,这几个操作最后也可以整合成一个命令:lpush key 111 222 333
通过这样的方式,可以减少aof文件的大小。
重写机制的触发时机:
手动触发:
bgrewriteaof命令。自动触发:修改配置文件(在ubutun下,配置文件的目录是在/etc/redis下)。
8,AOF文件的重写流程
当触发AOF文件重写机制时:
父进程会fork出子进程,子进程负责将当前内存中的数据写入到新的aof文件中。
在子进程重写文件的同时,父进程仍然在不停的接受其他客户端的请求,父进程还是会把这些请求写入到缓冲区aof_buf中,同时父进程这里又准备了一个aof_rewrite_buf缓冲区,也会将新收到的请求写入到这个缓冲区中,也就是说aof_rewrite_buf缓冲区专门放fork之后收到的数据。
子进程这边,把aof数据写完之后,会通过信号通知一下父进程。父进程再把aof_rewrite_buf缓冲区的数据也写入到新的aof文件中。
最后使用新的aof文件代替旧的aof文件。
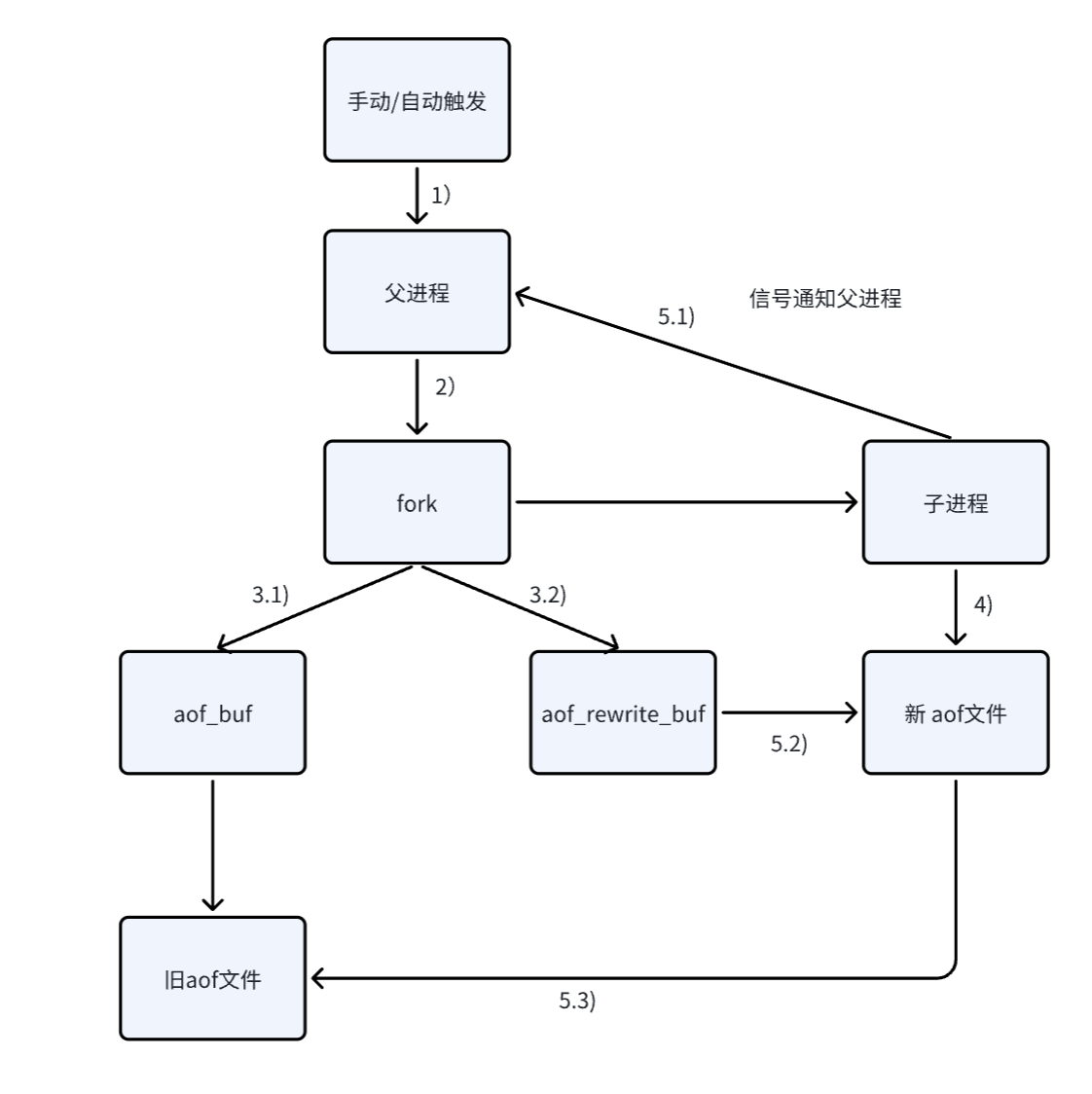
在上述重写流程中,父进程fork之后,子进程就开始写新的aof文件了,并随着时间的推移,子进程很快就写完了新的文件,要让新的aof文件代替旧的aof文件。在这个过程中,父进程仍然在继续写这个即将消亡的旧的aof文件,是否还有意义?
注意,这里不能不写,考虑到极端情况,如果子进程在重写的过程中,服务器挂了,子进程内存中的数据就会丢失,此时 新的aof文件中的内容还不完整。所以,如果父进程不坚持写旧的aof文件,重启之后就无法保证数据的完整性了。
如果,在执行bgrewriteaof的时候,当前redis已经正在进行aof重写了,此时不会再执行重写了,会直接返回。
如果,在执行bgrewriteaof的时候,发现redis正在生成rdb文件的快照,此时,aof重写操作就会等待,等待rdb快照生成完成之后,再执行aof重写。
注意:AOF本来是按照文本的方式来写入文件的,但是以文本的方式写文件,后续加载的成本是比较高的。
所以redis就引入了"混合持久化"的方式,结合了rdb和aof的特点。
按照aof的格式 ,每次的请求/操作,都记录写入文件(文本的形式)。
在触发aof重写之后,就会把当前内存的状态按照rdb的二进制形式写入 aof文件中。
后续再进行操作,仍然是按照aof文本的方式追加到文件后面。

配置文件中的这个选项,就表示开启"混合持久化"的方式。
二,Redis事务(Transactions)
1,认识redis事务
redis的事务,类似于MySQL中的事务,但是相比于MySQL,redis的事务简单了不少。
关于MySQL中的事务,简单回顾下:
原子性:把多个操作打包成一个整体。
一致性:事务执行前后,数据都必须是正确的。
持久性:事务中做出的修改都会存硬盘,保证服务器在重启之后 ,数据仍然存在。
隔离性:事务的并发执行,会涉及到的一系列问题(比如脏读,幻读,不可重复读等)。
redis事务:
弱化原子性:MySQL的原子性,保证事务在执行过程中,要么全部执行成功,要么不执行,也就是有"回滚"操作。而redis事务的原子性,没有"回滚"进制,也就是redis也将一系列操作打包成一个事务,但是事务的执行结果是否正确,是不知道的。
没有一致性:redis没有约束,也没有"回滚"机制,事务在执行过程中,如果某个修改操作出现失败,就可能引起数据不一致的情况。
不具备持久性:redis本身是内存数据库,数据是存储在内存中的。redis本身也是具有持久化机制的,比如上面的RDB和AOF,但是这里的持久化,和事务没有关系。redis收到一条命令(或事务)是进行操作内存的,而MySQL是操作硬盘的。
不涉及隔离性:并发执行事务才会涉及到隔离性,而redis是单线程模型的服务器程序,所有的请求/事务,都是"串行"执行的。
2,redis事务的了解
redis的事务,主要的意义,就是"打包",避免其他客户端的命令,插队插到中间。
redis中实现事务,是引入了队列(每个客户端都有一个)。
开启事务的时候,此时客户端输入的命令,就会发给服务器并且进入这个队列中(而不是立即执行)。
当遇到了"执行事务"的命令,此时就会把队列中的这些命令按照顺序依次推送给服务器去执行。
3,相关命令
事务的开启与执行
开启事务:MULTI
执行事务:EXEC
放弃当前事务:DISCARD
WATCH和UNWATCH
在redis事务中,还提供了WATCH和UNWATCH两个命令。
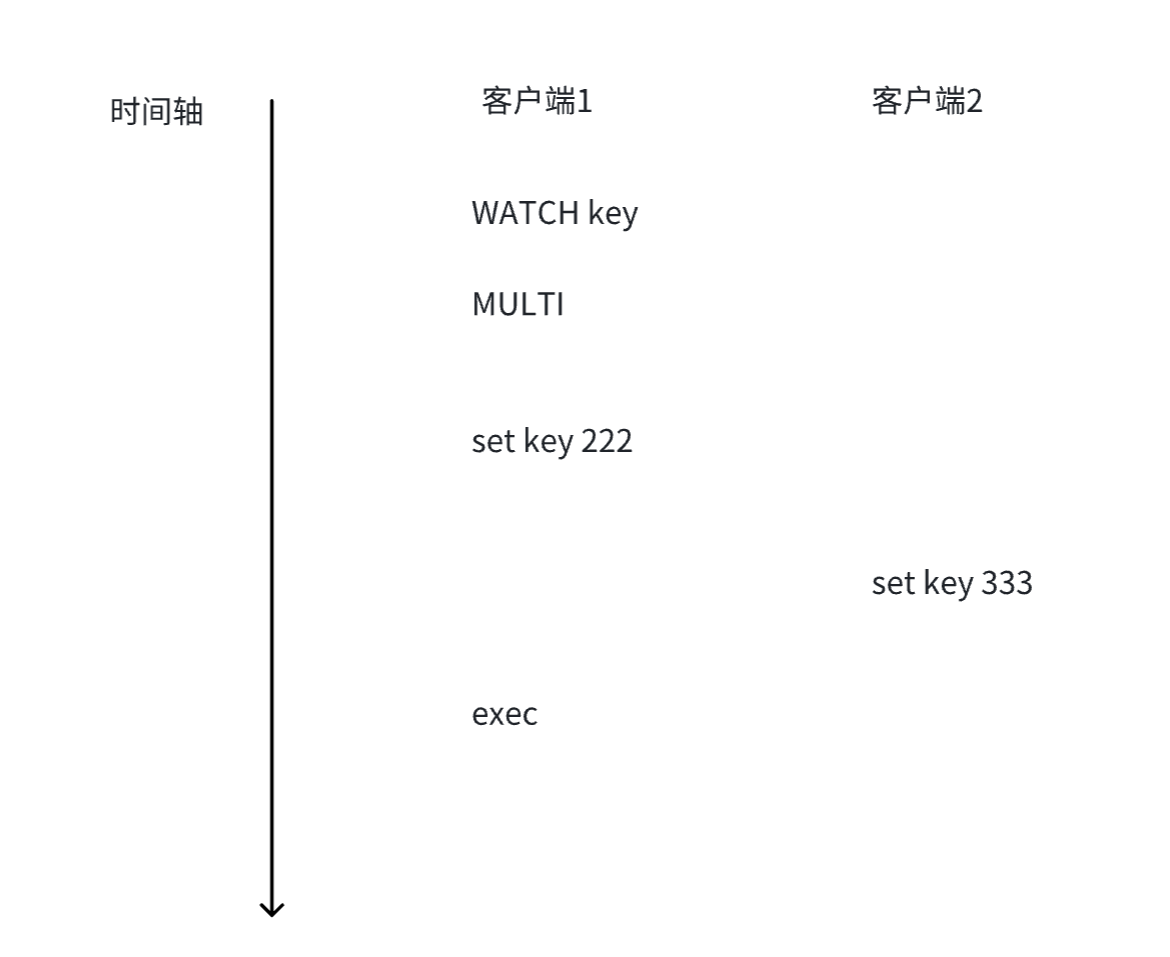
首先引入下面的场景:
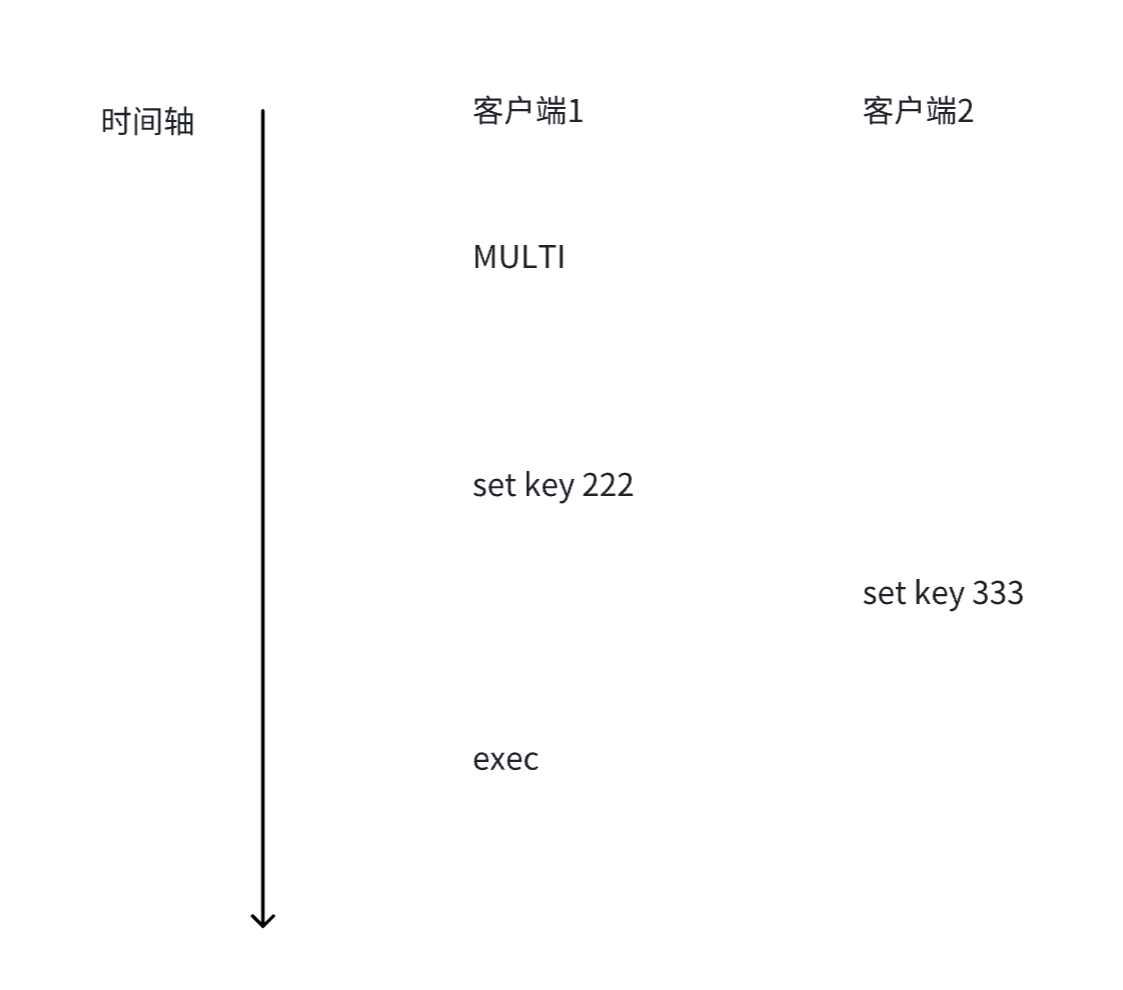
从时间上看,客户端1是先发送了
set key 222,客户端2后发送了set key 333,按理来说应该是后发送的生效,也就是key的最终值是 333。但实际上并非如此,由于客户端1中,必须是exec执行了,才会真正执行
set key 222。因此这个操作变成了更晚的操作,所以key的最终值是222,而这也符合事务的特性。此时就产生了歧义,这时就可以使用
WATCH来监视这个key,看看这个key在事务的MULTI和EXEC之间,set key 之后,是否有外部 其他的客户端修改这个key。如果有,会给出提示。相对的,还有一个
UNWATCH命令,这个就是解除对某个key的监视。
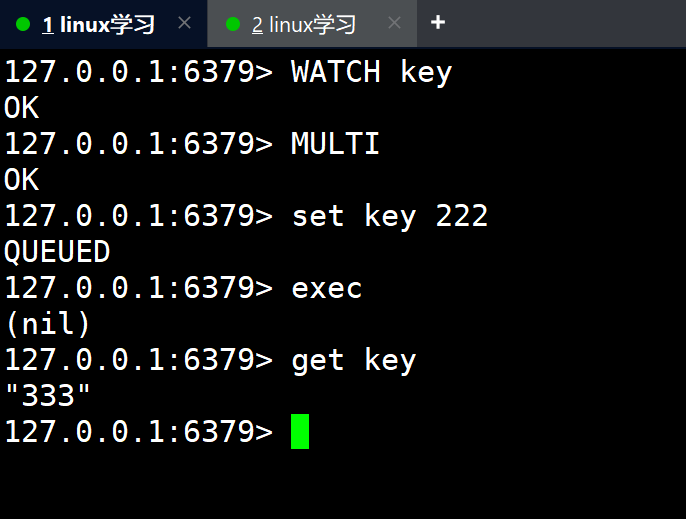
效果演示:
在执行exec后,在执行上述事务中的命令时,发现key在外部有修改,那么在执行set key 222时,就没有真正执行,返回接轨是nil,不是ok。
WATCH的实现
WATCH是如何知道其他客户端修改了这个key呢?也就是WATCH是如何实现的。
WATCH的实现,类似于一个"乐观锁"。
所谓乐观锁和悲观锁,不是指某个具体的锁,而是指某一类锁的特性。
乐观锁:加锁之前,就有一个心理预期,预期接下来的锁冲突(锁竞争)概率比较低。
悲观锁:加锁之前 ,也有一个心理预期,预期接下来的锁冲突(锁竞争)概率比较高。
而锁冲突概率高,和所冲突概率低,接下来要做的工作是不一样的。
redis的WATCH就使用相当于"版本号"这样的机制,来实现了"乐观锁"。依旧是上面的例子,不过此时加上了WATCH来监控key 。
当执行WATCH的时候,就会给这个key安排一个"版本号",可以理解为一个整数。每次在修改这个key的时候,这个key的版本号就会变大。
所以当客户端2在执行set key 333时,就会修改这个key的版本号。
当客户端1执行到exec时,在执行事务中命令的时候,此时就会做出判定。判定当前key的版本号和最初WATCH时候记录的版本号是否一致。如果一致,说明当前key在事务开启到执行的整个过程中,没有其他客户端修改,于是才能进行真正的设置;如果发现不一致,说明key在其他客户端中改过了,因此此时就会丢弃该操作,exec返回一个nil。
所以,WATCH本质是给exec加了一个判定条件,这个过程也可以视作是一种加锁的过程。C++中的std::mutex,这是一个悲观锁,不满足条件会进行阻塞等待。而这里的锁,不满足条件就直接丢弃该操作,就相当于执行失败了。这个锁更加简单,也更加轻量,而出现上述情况的概率比较低,所以就没有使用像std::mutex这样复杂的机制,所以说WATCH的实现,类似于一个"乐观锁"。