背景介绍
这是一个 简单的人脸识别项目,用 FastApi 在本地实现,使用预训练模型,直接可用。
新方案比之前的FaceNet强太多了,甚至不用数据增强等操作,就可以识别戴眼镜、不戴眼镜、歪着的人脸等。
充分证明了选型的重要性,选对了模型方案,效果直线上升。
细节说明
1、model.py 的 align_face 方法使用的是 仿射变换,不可以换成 透视变换哦,尤其是 ArcFace 这种场景,仿射变换更合适,原因如下:
①ArcFace 训练是基于仿射对齐后的人脸图像(五点坐标 + 仿射对齐 +输出112x112),改变对齐方式容易导致提取的 embedding 无法匹配;
②人脸在拍摄中的角度变化通常较小,仿射变换可以很好地处理这类刚性变换(左右偏转,微小仰头低头,轻微比例失衡等);
③透视变换自由度太高,容易引入图像畸变,对 ArcFace 这种要求人脸标准姿态输入的模型来说可能导致 向量化的不稳定;
可改善
1、可增加活体检测功能;
项目结构
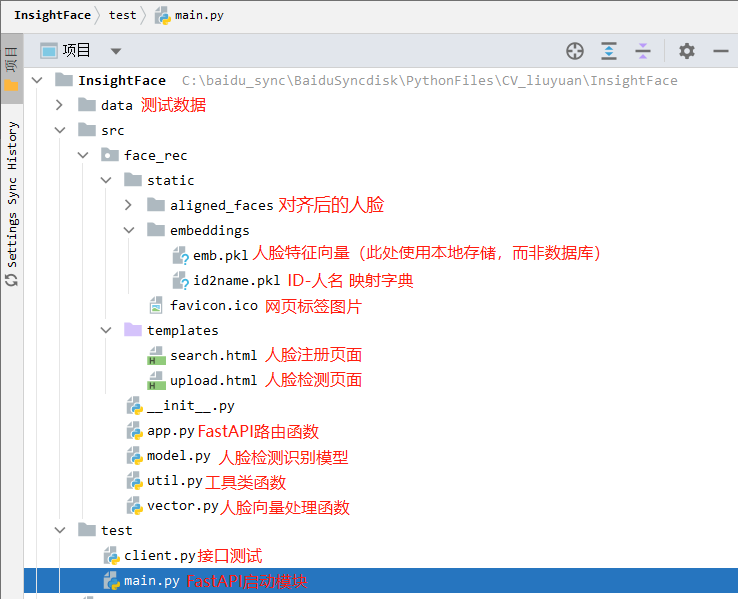
核心代码都放下面了
src/face_rec/model.py
# src/face_rec/model.py
# RetinaFace + ArcFace + 五点对齐;使用cpu
import cv2, os
import numpy as np
from PIL import Image
from datetime import datetime
# insightface 库:arcface 和 retinaface
from insightface.app import FaceAnalysis
class FaceRecModel:
def __init__(self, root_dir):
"""初始化 RetinaFace 检测器 + ArcFace 特征提取器"""
self.root_dir = root_dir
# FaceAnalysis集成了 人脸检测器(RetinaFace)、人脸识别器(ArcFace)、关键点提取器(5点、106点)
# providers:这是 onnxruntime 的后端执行器选择,代表你想使用什么设备运行模型
self.app = FaceAnalysis(
providers=['CPUExecutionProvider']) # 也可以用 GPUExecutionProvider、TensorrtExecutionProvider
# prepare是对 FaceAnalysis 进行初始化配置,必须调用,否则模型无法运行。
# det_size=(320, 320):会影响 检测速度和检测精度,太小-快但容易漏检小人脸;太大-准但慢,资源消耗大;
# 实测 det_size=(320, 320) 比较好用
self.app.prepare(ctx_id=-1, det_size=(320, 320)) # ctx_id=-1是CPU,0是GPU,det_size是检测尺寸(宽,高)
# 如果你输入的图像尺寸不是 (320, 320),会怎么样?
# insightface 会自动 resize 成指定的 det_size(保持长宽比)来检测。原图尺寸不会影响使用,只是检测过程会先缩放成这个尺寸,然后再还原人脸框到原图坐标。
def get_image_face_vector(self, pil_img, name=None):
"""
检测人脸,返回对齐后的最大人脸图像及其特征向量。
:param pil_img: PIL.Image RGB 图像
:param name: 用户名(保存图片时使用)
:return: 对齐后的 PIL.Image(或None),对齐人脸保存路径(或None),特征向量(或None)
"""
# 将 PIL 图像转成 numpy RGB 数组
np_img = np.array(pil_img)
# faces 是一个人脸列表,每个元素是一个 insightface.Face 对象(可以理解为一个人脸的“数据包”),包含了检测框、关键点、embedding 特征等信息。
# app.get() 方法会执行人脸检测、特征提取。
faces = self.app.get(np_img)
if len(faces) == 0:
print("[INFO] 未在图像中检测到人脸,无法进行对齐和特征提取。")
return None, None, None
# 选择最大面积人脸
face = max(faces, key=lambda x: x.bbox[2] * x.bbox[3]) # W*H=人脸框面积
# 五点关键点坐标 (5,2) numpy数组
kps = face.kps.astype(np.float32) # 左眼,右眼,鼻子,左嘴角,右嘴角
# 仿射对齐人脸,输出 112x112 RGB 图像
aligned_face_np = self.align_face(np_img, kps) # align_face 是自定义函数,返回 numpy 数组
# 将对齐后的 numpy 图像转回 PIL 图像
aligned_pil = Image.fromarray(aligned_face_np)
# 保存对齐后图像
save_dir = os.path.join(self.root_dir, 'aligned_faces')
os.makedirs(save_dir, exist_ok=True)
# 命名方式:name_时间戳.jpg 或 timestamp.jpg
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"{name}_{timestamp}_insert.jpg" if name else f"face_{timestamp}_search.jpg"
save_path = os.path.join(save_dir, filename)
aligned_pil.save(save_path)
print(f"[INFO] 已保存对齐人脸: {save_path}")
# --- 在这里整合特征提取逻辑 ---
# 优先使用 app.get() 已经提取的 embedding,因为它是在检测阶段就完成了。并且通常是针对原始图像的更鲁棒的特征。
# 如果 face.embedding 存在且不为 None,就直接使用它。
if hasattr(face, 'embedding') and face.embedding is not None:
embedding = face.embedding.astype(np.float32)
print("[INFO] 已成功提取人脸特征。", embedding.mean())
else:
# 如果 face 对象中没有 embedding,说明 app.get() 未能成功提取特征。
# 这可能是由于识别模型加载失败、图像质量问题或其他内部原因。
print("[ERROR] FaceAnalysis.get() 未能为检测到的人脸提取特征。")
print("请检查 FaceAnalysis 的初始化配置和输入图像质量。")
embedding = None # 无法获取特征,返回 None
return aligned_pil, save_path, embedding
def align_face(self, np_img, landmark5):
"""
使用五点关键点仿射变换对齐人脸,输出 112x112 RGB 图像(ArcFace标准输入)
:param np_img: numpy RGB 图像
:param landmark5: numpy array (5,2) 左眼,右眼,鼻子,左嘴角,右嘴角
:return: 对齐后 112x112 RGB numpy 图像
"""
# ArcFace标准5点模板坐标,单位像素
src = np.array([
[38.2946, 51.6963],
[73.5318, 51.5014],
[56.0252, 71.7366],
[41.5493, 92.3655],
[70.7299, 92.2041]
], dtype=np.float32)
dst = landmark5.astype(np.float32)
# 计算仿射变换矩阵: 计算 从 dst(检测的人脸五点) 到 src(ArcFace标准模板五点) 的 仿射变换矩阵(2x3)
# 使用 LMEDS(最小中值平方)方法计算仿射矩阵,比普通最小二乘法更稳健(可以抵抗部分错误点)。
tform = cv2.estimateAffinePartial2D(dst, src, method=cv2.LMEDS)[0]
# 使用仿射矩阵 tform 对整张人脸图像做变换(对齐),输出大小为 (112, 112) 的人脸图像
# borderValue=0:如果变换后图像边界有空白部分,用黑色像素(值为0)填充。
aligned = cv2.warpAffine(np_img, tform, (112, 112), borderValue=0)
return aligned
src/face_rec/vector.py
# src/face_rec/vector.py
# 使用 FAISS + cosine 相似度做人脸特征向量的存储与检索
import os
import pickle
import numpy as np
import faiss # Facebook AI 相似度搜索库,适合处理大规模向量比对
class VectorService:
def __init__(self, root_dir):
# 保存向量的目录
self.root_dir = os.path.join(root_dir, "embeddings")
if not os.path.exists(self.root_dir):
os.makedirs(self.root_dir)
self.dims = 512 # ArcFace 输出是 512 维向量
# 特征向量文件(以 pickle 存储)
self.embedding_file = os.path.join(self.root_dir, "emb.pkl")
if os.path.exists(self.embedding_file):
# 如果文件存在就加载已有向量
self.embeddings = np.asarray(self.load_pickle_data(self.embedding_file)).astype('float32')
else:
# 否则初始化为一个全0向量(避免空索引时报错)
self.embeddings = np.zeros((1, self.dims), dtype='float32')
# 初始化 FAISS 索引:使用 HNSW(图结构)+ cosine 相似度(归一化后使用内积)
# HNSW:Hierarchical Navigable Small World 一种高效的图结构索引算法,适合大规模、近似最近邻查找(Approximate Nearest Neighbor, ANN)
# faiss.METRIC_INNER_PRODUCT:表示使用 内积(dot product) 作为距离度量方式。但这并不是欧氏距离,而是为了计算 cosine 相似度
self.face_index = faiss.index_factory(self.dims, 'HNSW16', faiss.METRIC_INNER_PRODUCT)
# 如果已有向量,归一化后加入索引中
if self.embeddings.shape[0] > 0:
faiss.normalize_L2(self.embeddings) # L2归一化后,求内积就是cosine 余弦相似度
self.face_index.add(self.embeddings)
# ID 到用户姓名的映射表
self.idx_2_name_file = os.path.join(self.root_dir, 'id2name.pkl')
if os.path.exists(self.idx_2_name_file):
self.idx_2_name = self.load_pickle_data(self.idx_2_name_file)
else:
self.idx_2_name = {}
# 当前用户索引起始值(从已有数量+1开始)
self.user_idx = len(self.idx_2_name) + 1
def add_embedding(self, vector, name):
"""添加一个人脸向量及其对应用户名"""
vector = np.asarray(vector, dtype='float32').reshape((1, self.dims))
faiss.normalize_L2(vector) # cosine相似度必须先归一化
# 更新内存中的向量数组
self.embeddings = np.concatenate([self.embeddings, vector], axis=0)
self.face_index.add(vector) # 加入FAISS索引
# 保存向量到文件
self.save_pickle_data(self.embedding_file, self.embeddings)
# 记录用户索引与名字的对应关系
self.idx_2_name[self.user_idx] = name
self.user_idx += 1
self.save_pickle_data(self.idx_2_name_file, self.idx_2_name)
def search(self, vector, thred=0.4):
"""
给定一个向量,返回最相似的用户名(如果相似度超过阈值)
:param vector: 512维特征向量
:param thred: 相似度阈值,越高越严格(默认0.4)
:return: 最相似用户名 或 None
"""
vector = np.asarray(vector, dtype='float32').reshape((1, self.dims))
faiss.normalize_L2(vector)
# 搜索与该向量最接近的索引。np.ndarray prob.shape=(1, 1), np.ndarray idx.shape=(1, 1)
prob, idx = self.face_index.search(vector, 1) # 返回前1个最相似结果
prob = prob[0, 0] # 相似度(cosine)
idx = idx[0, 0] # 对应索引值
print(f"最大相似度:{prob}(判定阈值:{thred})")
if prob < thred:
return None
return self.idx_2_name.get(idx, None)
@staticmethod
def load_pickle_data(path):
"""从指定路径加载pickle对象"""
# 因为 pickle 模块在保存/读取 Python 对象时,是按二进制格式编码的,不是普通文本。
with open(path, 'rb') as r: # 以“二进制”的方式打开一个文件,只读
return pickle.load(r)
@staticmethod
def save_pickle_data(path, data):
"""将对象保存到pickle文件"""
# 因为 pickle 模块在保存/读取 Python 对象时,是按二进制格式编码的,不是普通文本。
with open(path, 'wb') as w: # 以“二进制”的方式打开一个文件,可写
pickle.dump(data, w)
src/face_rec/util.py
# src/face_rec/util.py
# 对齐仍使用五点关键点,图像增强接口保留,增强亮度、对比度、锐度,确保模型识别效果更稳定
import numpy as np
from PIL import ImageEnhance
def preprocess_image(pil_image):
'''图像预处理函数(可选):增强亮度、对比度、锐度
image (PIL.Image.Image): 输入的 PIL 图像对象:
np.ndarray: 增强后的图像,格式为 NumPy 数组,可用于 OpenCV 或模型输入
'''
# 亮度增强:增强到原始亮度的 1.3 倍
enhancer = ImageEnhance.Brightness(pil_image)
image_bright = enhancer.enhance(1.3)
# 对比度增强:增强到原始对比度的 1.2 倍
enhancer_contrast = ImageEnhance.Contrast(image_bright)
image_contrast = enhancer_contrast.enhance(1.2)
# 锐度增强:增强到原始锐度的 2.0 倍
enhancer_sharp = ImageEnhance.Sharpness(image_contrast)
image_sharpened = enhancer_sharp.enhance(2.0)
# 将 PIL 图像转换为 NumPy 格式(OpenCV 可用)
image_sharpened = np.array(image_sharpened)
return image_sharpened
src/face_rec/app.py
# src/face_rec/app.py
import os
import io
import base64
from fastapi import FastAPI, File, Form, UploadFile, Request
from fastapi.responses import HTMLResponse, JSONResponse, FileResponse
from fastapi.templating import Jinja2Templates
from PIL import Image, ImageOps
from .model import FaceRecModel # 引入人脸识别模型封装
from .vector import VectorService # 引入向量搜索服务
from .util import preprocess_image # 可选:图像预处理(增强)
# 获取静态资源目录(如 模型文件、向量文件等) C:\baidu_sync\BaiduSyncdisk\PythonFiles\CV_liuyuan\InsightFace\src\face_rec\static
__static_dir_path__ = os.path.join(os.path.dirname(os.path.abspath(__file__)), "static")
# 创建 FastAPI 应用
app = FastAPI()
# 指定 FastAPI 中 Jinja2 模板文件目录(用于返回 HTML 页面) C:\baidu_sync\BaiduSyncdisk\PythonFiles\CV_liuyuan\InsightFace\src\face_rec\templates
# FastAPI 使用 Jinja2 来支持 HTML 模板渲染(跟 Flask 类似)
templates = Jinja2Templates(directory=os.path.join(os.path.dirname(__file__), "templates"))
# 实例化加载人脸识别模型与向量库
model = FaceRecModel(root_dir=__static_dir_path__)
vector = VectorService(root_dir=__static_dir_path__)
# 网页标签图片
@app.get("/favicon.ico")
async def favicon():
return FileResponse(os.path.join(__static_dir_path__, "favicon.ico"))
# 首页:GET / 或 /index,返回欢迎信息
@app.get("/", response_class=HTMLResponse)
@app.get("/index", response_class=HTMLResponse)
# 异步的处理函数(协程)
async def index(request: Request):
return HTMLResponse("欢迎使用简易人脸检索系统!")
# GET 上传页面:返回上传图片的 HTML 页面
@app.get("/face/image/upload", response_class=HTMLResponse)
async def upload_get(request: Request):
return templates.TemplateResponse("upload.html", {"request": request})
# POST 上传接口:上传用户图像并提取特征,存入向量库
@app.post("/face/image/upload")
async def upload_post(
name: str = Form(...), # 表单中提供的人名(作为身份标签)
file: UploadFile = File(...) # 上传的图片文件 (此时 file 是一个 UploadFile 对象,它是一个 异步文件类,用于处理客户端上传的文件)
): # HTML 表单的 name 名称和后端参数名一致;后端用 Form(...) 处理文本、用 File(...) 处理文件
# 读取上传文件内容并转为 PIL 图像
# await 表示“等待它完成”并获取返回值,必须在 async def 里使用
contents = await file.read() # file.read() 是一个异步操作(coroutine),会从上传的文件中读取所有字节内容(返回 bytes)
img = Image.open(io.BytesIO(contents)).convert("RGB")
# 处理图片方向信息(EXIF)
img = ImageOps.exif_transpose(img)
# 可选预处理(增强亮度/对比度/锐度)
# img = preprocess_image(img)
# 检测并裁剪人脸图像,保存文件,提取人脸特征向量
img, save_path, embedding = model.get_image_face_vector(img, name)
if img is None:
return templates.TemplateResponse("upload.html", {"request": {}, "msg": "未检测到人脸区域!"})
if embedding is None:
return templates.TemplateResponse("upload.html", {"request": {}, "msg": "人脸特征提取失败!"})
# 将特征向量存入数据库
vector.add_embedding(embedding, name)
return JSONResponse({"code": 0, "msg": "人脸添加成功!"})
# GET 检索页面:返回搜索页面的 HTML 页面
@app.get("/face/image/search", response_class=HTMLResponse)
async def search_get(request: Request):
return templates.TemplateResponse("search.html", {"request": request})
# POST 检索接口:上传图像 -> 提取特征 -> 搜索库中最相似用户
@app.post("/face/image/search")
async def search_post(file: UploadFile = File(...)):
contents = await file.read()
img = Image.open(io.BytesIO(contents)).convert("RGB")
# 处理图片方向信息(EXIF)
img = ImageOps.exif_transpose(img)
# 可选预处理(增强亮度/对比度/锐度)
# img = preprocess_image(img)
# 检测并裁剪人脸图像,保存文件,提取人脸特征向量
img, save_path, embedding = model.get_image_face_vector(img)
if img is None:
return templates.TemplateResponse("search.html", {"request": {}, "msg": "未检测到人脸区域!"})
if embedding is None:
return templates.TemplateResponse("search.html", {"request": {}, "msg": "人脸特征提取失败!"})
# 在向量库中进行相似度匹配
name = vector.search(embedding)
if name is None:
return templates.TemplateResponse("search.html", {"request": {}, "msg": "人脸未匹配到用户!"})
return JSONResponse({"code": 0, "msg": "search success!", "name": name})
# POST 检测接口(用于 API 接口)接收 base64 图像,输出识别结果
@app.post('/face/image/detect')
async def detect_post(request: Request):
data = await request.json()
img_b64 = data.get('img')
if img_b64 is None:
return JSONResponse({'code': 202, 'msg': '必须提供 img 参数!'})
# 解码 base64 图像并转换为 PIL 图像
img_data = base64.b64decode(img_b64)
img = Image.open(io.BytesIO(img_data)).convert("RGB")
# 处理图片方向信息(EXIF)
img = ImageOps.exif_transpose(img)
# 可选预处理(增强亮度/对比度/锐度)
# img = preprocess_image(img)
# 检测并裁剪人脸图像,保存文件,提取人脸特征向量
img, save_path, embedding = model.get_image_face_vector(img)
if img is None:
return JSONResponse({'code': 203, 'msg': '未检测到人脸区域!'})
if embedding is None:
return JSONResponse({'code': 204, 'msg': '人脸特征提取失败!'})
name = vector.search(embedding)
if name is None:
return JSONResponse({'code': 205, 'msg': '人脸未匹配到用户!'})
return JSONResponse({'code': 200, 'msg': 'search success!', 'name': name})
test/main.py
# test/main.py
# 项目入口文件,用于启动 FastAPI 服务(人脸识别 Web 接口)
import warnings
warnings.filterwarnings('ignore') # 忽略所有警告信息,保持输出干净
import os
import sys
import uvicorn # 用于运行 FastAPI 的 ASGI 服务器
# ASGI(Asynchronous Server Gateway Interface)是 Python 的一种 Web 应用服务器接口规范,是 WSGI 的升级版,用于支持异步编程。
# ASGI 是连接 Web 框架(如 FastAPI)和底层服务器(如 Uvicorn)的桥梁接口标准,支持异步请求处理。
# 避免 OpenMP 多线程库冲突(常用于 PyTorch 或 NumPy 内部),防止报错
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# 将 src 目录添加到模块导入路径,确保可以导入 src 下的自定义模块
# 例如:C:\baidu_sync\BaiduSyncdisk\PythonFiles\CV_liuyuan\InsightFace\src
sys.path.append(os.path.join(os.path.dirname(__file__), "..", "src"))
# 导入 FastAPI 应用实例(app)供 uvicorn 启动
from src.face_rec.app import app
# 运行服务
if __name__ == "__main__":
# 启动 FastAPI 应用,监听所有 IP,端口为 9999,日志级别为 info
uvicorn.run(app, host="0.0.0.0", port=9999, log_level="info") # 正常启动
# uvicorn.run(app, host="0.0.0.0", port=9999, log_level="info", reload=False) # 调试启动(debug)
test/client.py
# test/client.py
"""客户端测试代码:向 FastAPI 服务端发送 base64 编码的人脸图像,接收识别结果"""
import base64
from typing import Optional
import requests
import cv2
import numpy as np
from io import BytesIO
from pathlib import Path
from PIL import Image
from datetime import datetime
def fetch_person_name(img: np.ndarray) -> Optional[str]:
"""
给定一张图像(OpenCV格式 BGR),向服务端发送请求,返回识别结果
:param img: OpenCV 格式图像(BGR)
:return: 返回识别出的姓名字符串,或 None
"""
# 转换 OpenCV (BGR) -> PIL (RGB)
pil_img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 将图像保存为 PNG 到内存
buffer = BytesIO()
pil_img.save(buffer, format='PNG')
img_bytes = buffer.getvalue()
# 编码成 base64 字符串
img_b64 = base64.b64encode(img_bytes).decode('utf-8')
# 构造 JSON 请求体
payload = {'img': img_b64}
headers = {'Content-Type': 'application/json'}
try:
# 向本地服务发送 POST 请求(FastAPI)
response = requests.post('http://127.0.0.1:9999/face/image/detect', json=payload, headers=headers)
if response.status_code == 200:
result = response.json()
if result.get('code') == 200:
return result.get('name')
else:
print(f"[服务返回] 识别失败: {result}")
else:
print(f"[HTTP错误] 状态码: {response.status_code}")
except Exception as e:
print(f"[异常] 请求失败: {e}")
return None
if __name__ == '__main__':
# 加载测试图像
img_path = Path('..') / 'data' / 'img0.jpeg'
img = cv2.imread(str(img_path))
if img is None:
print(f"图像读取失败: {img_path}")
exit(1) # 程序异常退出,错误码为 1
# 获取识别结果
name = fetch_person_name(img)
print(f"识别结果: {name}")
# 画图、显示(如有识别结果,在图像上绘制姓名)
if name:
cv2.putText(img, name, (10, 50), cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 0, 255), 2) # BGR,红色255
else:
cv2.putText(img, "No Match", (10, 50), cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 255, 255), 2)
cv2.imshow('Face Recognition Result', img)
cv2.waitKey(0) # 等待任意键
cv2.destroyAllWindows()
# The function is not implemented
# OpenCV 安装缺少图形界面后端支持,默认安装的是一个轻量级的版本,
# 不包含 GUI (图形用户界面) 功能,例如 cv2.imshow()、cv2.waitKey() 等。这在服务器环境或不需要显示图像的场景下是常见的。
src/face_rec/templates/upload.html
<!-- upload.html 人脸图像录入表单页的模板 -->
<!DOCTYPE html>
<html lang="zh-CN"> <!-- 设置页面语言为中文(简体) -->
<head>
<meta charset="UTF-8"> <!-- 设置网页的字符编码为 UTF-8,支持中文 -->
<title>人脸录入</title> <!-- 网页标题:浏览器标签页上显示 -->
</head>
<body>
<h1>员工人脸打卡系统(人脸录入)</h1>
<!-- 若后端传递了 msg(通常是错误或提示信息),则显示为红色加粗字体 -->
{% if msg %}
<strong style="color:red">{{msg}}</strong>
{% endif %}
<!-- 上传表单 -->
<!-- method="POST" 表示表单提交方式为 POST -->
<!-- action="/face/image/upload" 表示提交到后端对应的 Flask 路由 -->
<!-- enctype="multipart/form-data" 表示表单中包含文件上传字段(如图像) -->
<form method="POST" action="/face/image/upload" enctype="multipart/form-data">
<!-- 文本输入框:输入姓名 -->
姓名:<input type="text" name="name"/> <br/><br/>
<!-- 文件选择框:上传图像文件 -->
图像:<input type="file" name="file"/> <br/><br/>
<!-- 提交按钮 -->
<input type="submit" name="submit" value="录入"/>
</form>
</body>
</html>
src/face_rec/templates/search.html
<!--人脸图像检索表单页的模板-->
<!DOCTYPE html>
<html lang="zh-CN"> <!-- 设置页面语言为中文(简体) -->
<head>
<meta charset="UTF-8"> <!-- 设置网页的字符编码为 UTF-8,支持中文 -->
<title>人脸检索</title> <!-- 网页标题:浏览器标签页上显示 -->
</head>
<body>
<h1>员工人脸打卡系统(人脸检索)</h1>
<!-- 若后端传递了 msg(通常是错误或提示信息),则显示为红色加粗字体 -->
{% if msg %}
<strong style="color:red">{{msg}}</strong>
{% endif %}
<!-- 上传表单 -->
<!-- method="POST" 表示表单提交方式为 POST -->
<!-- action="/face/image/search" 表示提交到后端对应的 Flask 路由 -->
<!-- enctype="multipart/form-data" 表示表单中包含文件上传字段(如图像) -->
<form method="POST" action="/face/image/search" enctype="multipart/form-data">
<!-- 文件选择框:上传图像文件 -->
图像:<input type="file" name="file"/> <br/><br/>
<!-- 提交按钮 -->
<input type="submit" name="submit" value="检索"/>
</form>
</body>
</html>