目录
一、HTTP
1.1 HTTP是什么
HTTP(全称“超文本传输协议”)是一种应用非常广泛的 应用层协议。
我们平时打开一个网站,就是通过HTTP协议来传输数据的。
1.2 HTTP协议的工作过程
当我们在浏览器中输入一个“网址”,此时浏览器就会给对应的服务器发送一个HTTP请求,对应的服务器收到这个请求经过计算处理,就会返回一个HTTP响应。
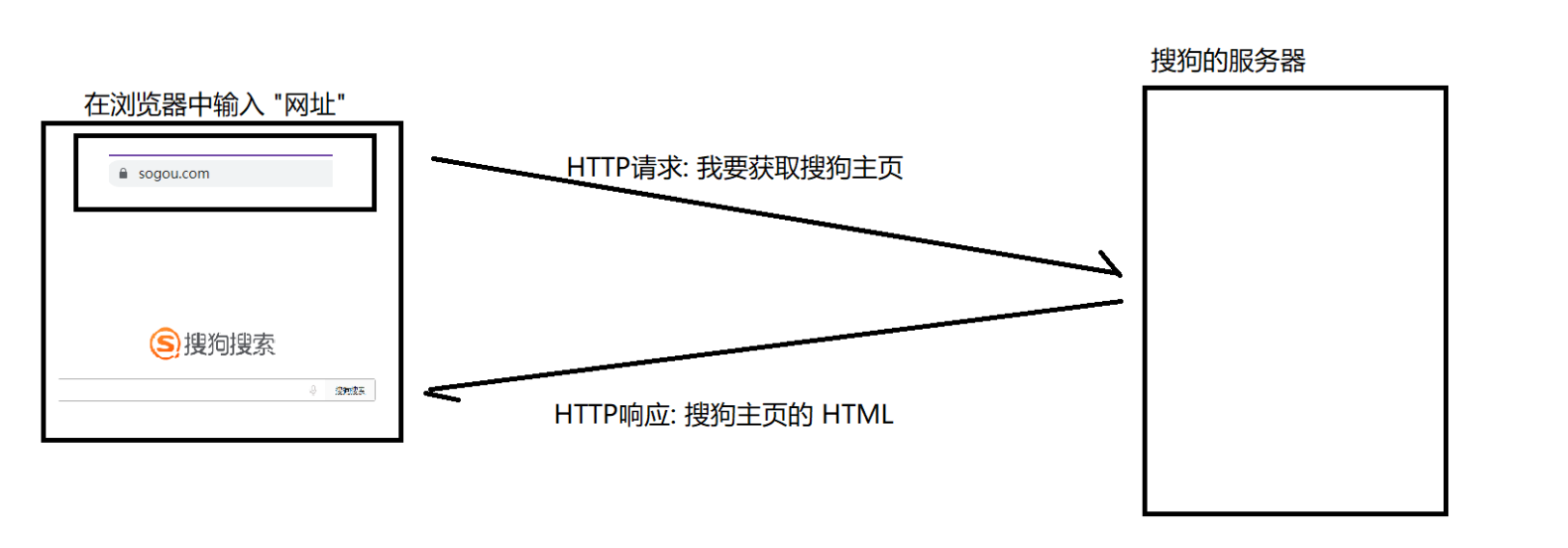
事实上,当我们访问一个网站的时候,可能涉及布置一次的HTTP请求/响应的过程。
可以通过浏览器的开发者工具来观察这个详细的过程。
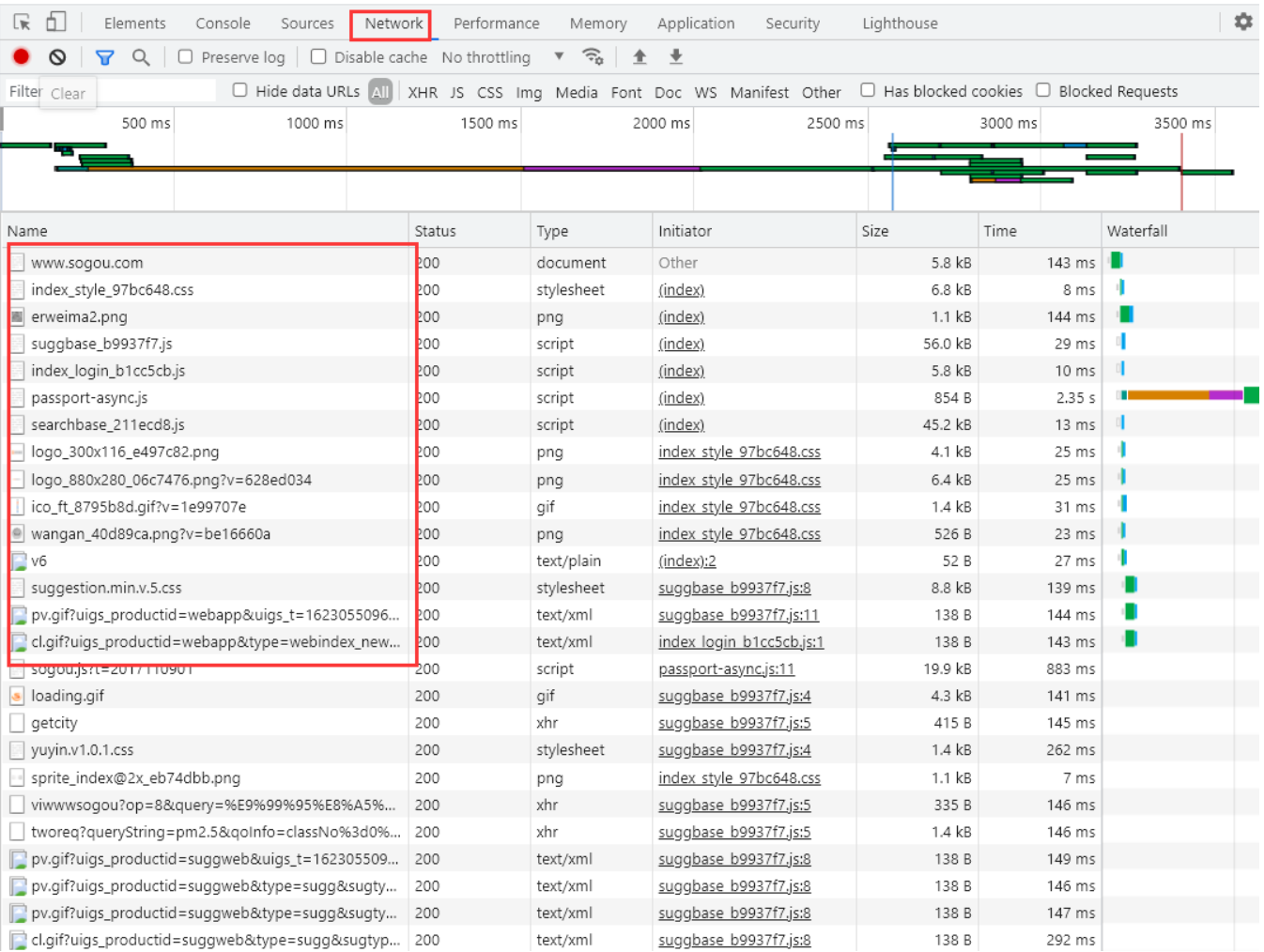
当前搜狗主页是利用了HTTPS协议进行通信的,HTTPS是在HTTP的基础上做了一个加密解密的工作后面再详细介绍。
1.3 HTTP协议格式
HTTP是一个文本格式的协议,可以通过浏览器的开发者工具或者抓包工具抓包来查看HTTP请求/响应的细节。
1.3.1 抓包工具的使用
这里以Fiddler为例。
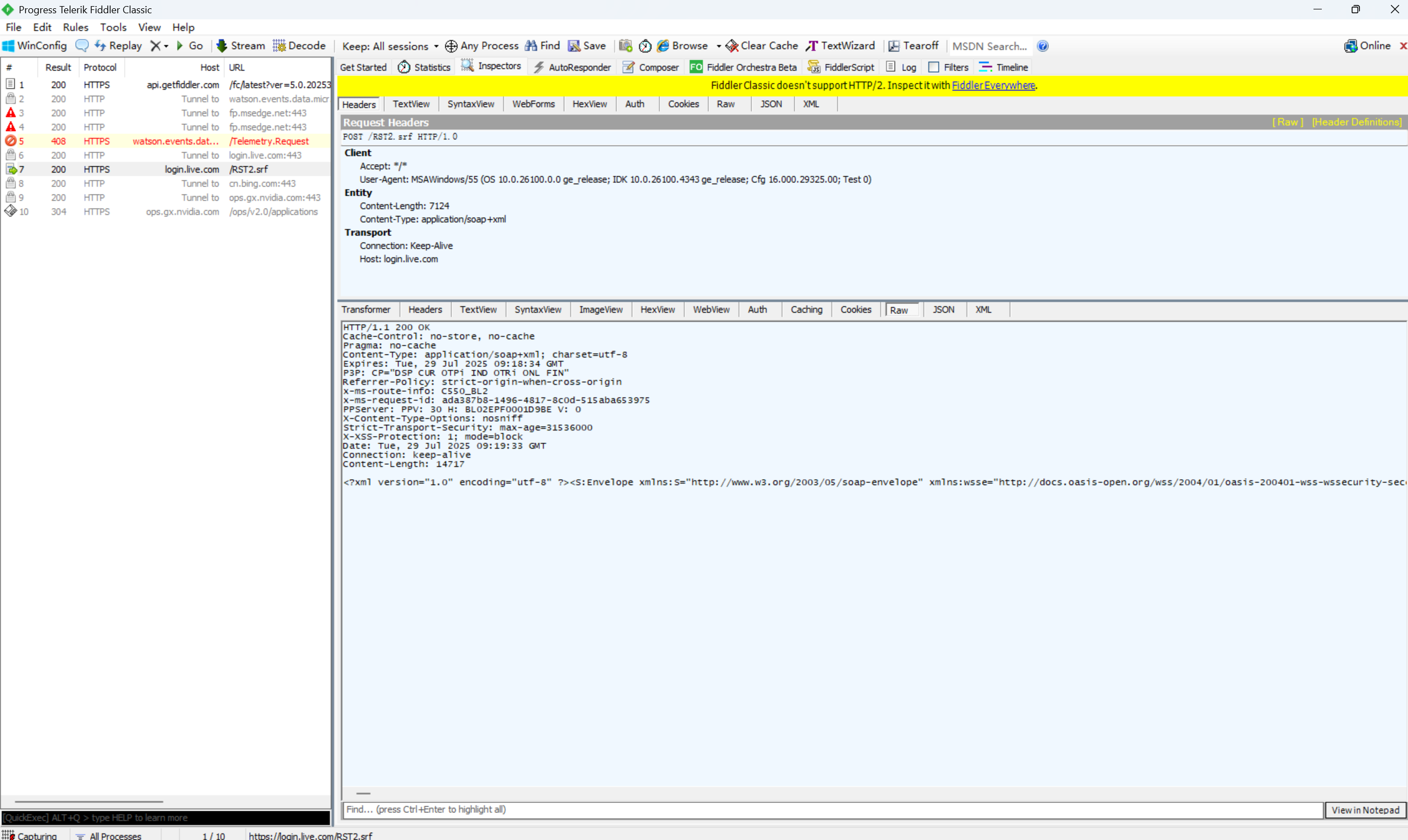
左侧窗口显示了所有的HTTP请求/响应,可以选中某个请求查看详情。
右侧上方显示了HTTP请求的报文内容(切换到RAW标签页可以看到详细的数据格式)
右侧下方显示了HTTP响应的报文内容(切换到RAW标签页可以看到详细的数据格式)
请求和响应的详细数据,可以通过右下角的View in Notepad 通过记事本打开
1.3.2 抓包结果
以下是一个HTTP请求/响应的抓包结果
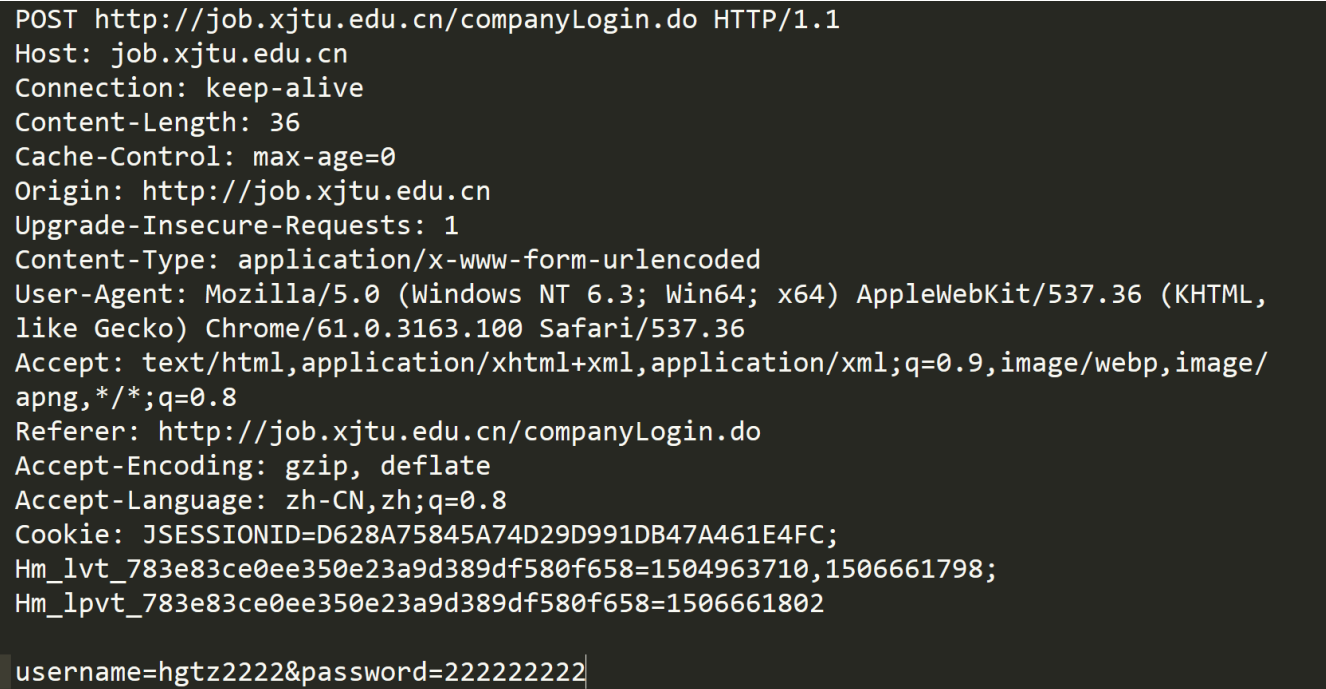
首行:[方法] + [url] + [版本]
Header:请求的属性,冒号分隔的键值对;每组数据之间使用 \n 分割;遇到空行表示Header部分结束。
Body:空行后面的内容都是Body。Body允许空字符串,如果Body存在,则在Header部分中有一个Content-Length属性来标识Body的长度
HTTP响应
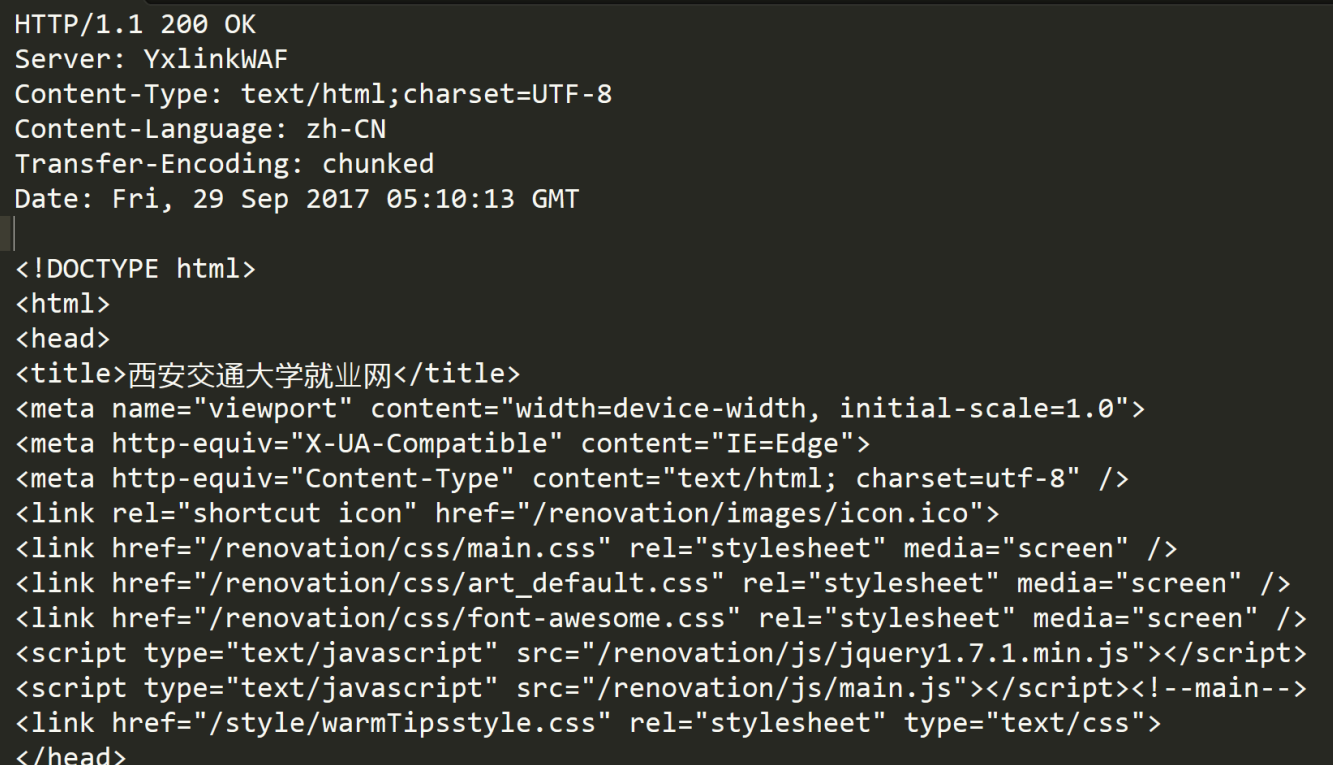
首行:[版本号] + [状态码] + [状态码解释]
Header:请求的属性,冒号分隔的键值对;每组数据之间使用 \n 分割;遇到空行表示Header部分结束。
Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有⼀个Content-Length属性来标识Body的长度; 如果服务器返回了⼀个html页面, 那么html页面内容就是
在body中.
HTTP 协议并没有规定报头部分的键值对有多少个. 空行就相当于是 "报头的结束标记", 或者是
报头和正文之间的分隔符".
HTTP 在传输层依赖 TCP 协议, TCP 是面向字节流的. 如果没有这个空行, 就会出现 "粘包问题".
1.4 HTTP请求
1.4.1 URL
平时我们俗称的“网址”其实就是一个URL。
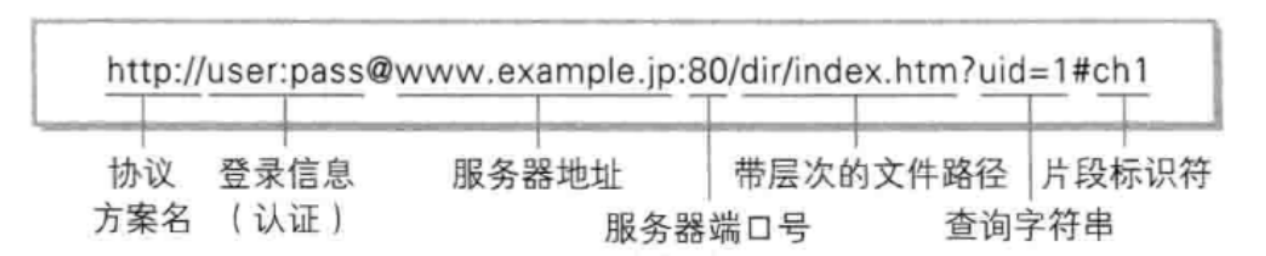
关于query string :query string 中的内容是键值对结构,其中的 key 和 value 的取值和个数,完全由程序员自己约定的,我们可以通过这样的方式来定制传输我们需要的信息给服务器。
1.4.2 认识“方法” (method)
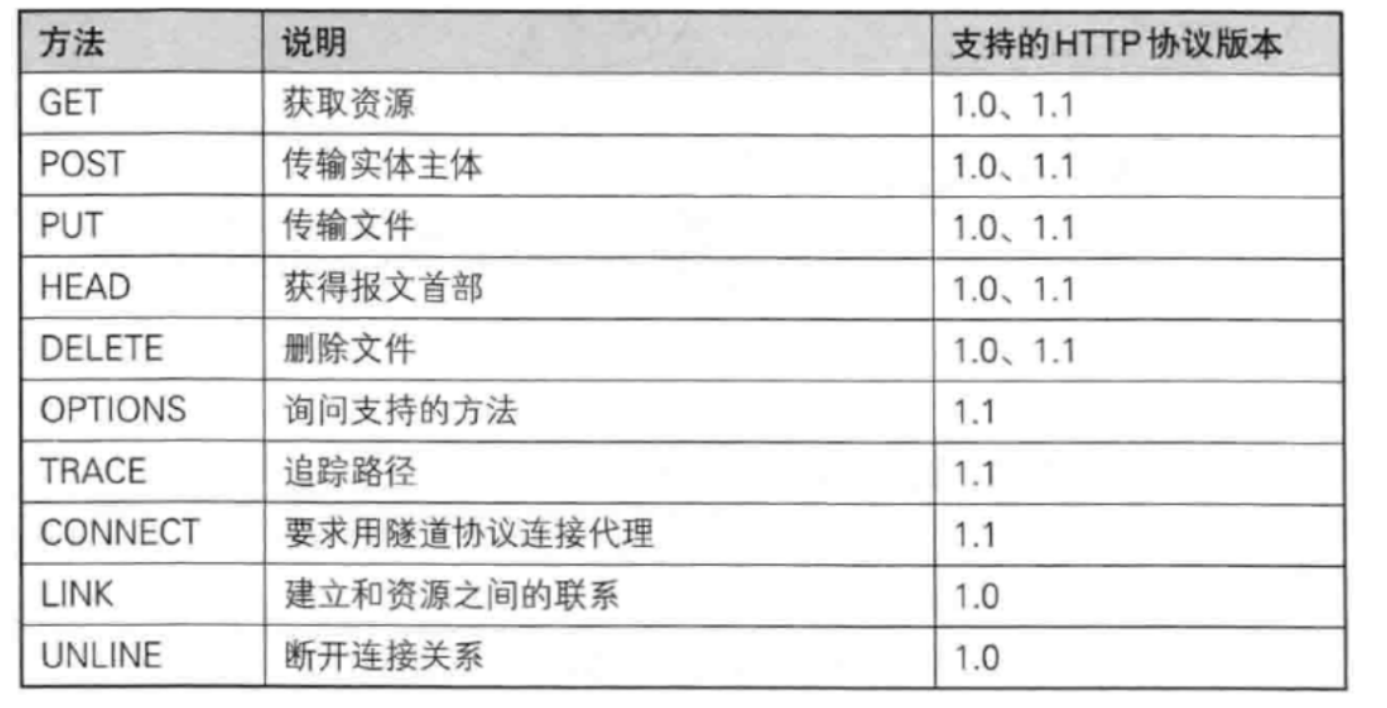
GET方法
GET方法是最常用的HTTP方法,常用于获取服务器的某个资源。在浏览器中直接输入URL,此时浏览器就会发出一个GET请求
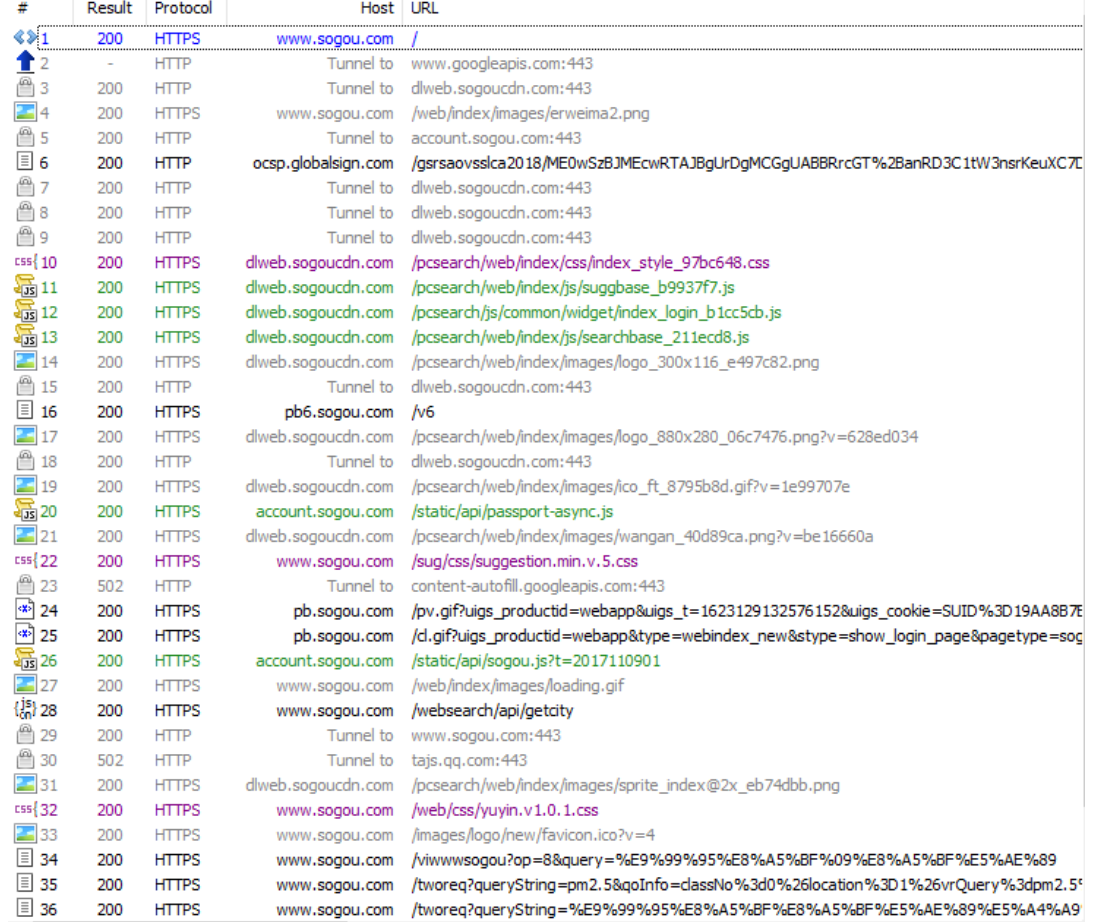
在上面的抓包结果中可以看到最上面的

是通过浏览器地址栏发送的get请求。
选中这条观察请求的详细结果:
GET https://www.sogou.com/ HTTP/1.1
Host: www.sogou.com
Connection: keep-alive
Cache-Control: max-age=0
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/w
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: SUID=19AA8B7B6E1CA00A000000005F9A2F76; SUV=1603940214073598; pgv_pvi=266GET请求的特点:
首行第一部分为GET
URL的query string 可以为空也可以不为空
header由若干个键值对结构
body部分为空
1.4.3 认识请求“报头”(header)
header 的整体格式也是“键值对” 的结构
Host 表示服务器主机的地址和端口
Content-Length 表示body中数据的长度
Content-Type 表示请求body中的数据格式。常见选项:
application/x-www-form-urlencoded: form 表单提交的数据格式. 此时 body 的格式形如:
title=test&content=hellomultipart/form-data: form 表单提交的数据格式(在 form 标签中加上enctyped="multipart/form-data" . 通常用于提交图片/文件. body 格式形如:
Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryrGKCBY7qhFd3Trw
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="text"
title
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="file"; filename="chrome.png"
Content-Type: image/png
PNG ... content of chrome.png ...
------WebKitFormBoundaryrGKCBY7qhFd3TrwA--application/json: 数据为 json 格式. body 格式形如:
{"username":"123456789","password":"xxxx","code":"jw7l","uuid":"d110a05ccde64b16"}User-Agent 表示浏览器/操作系统的属性
Referer 表示这个页面是从哪个页面跳转过来的。如果直接在浏览器输入URL或者直接通过收藏夹访问是没有 Referer 的。
Cookie 中存储了一个字符串,这个数据可能是客户端(网页)自行通过JS写入的,也可能来自于服务器(服务器在HTTP响应的header中通过set-cookie字段给浏览器返回数据)。往往可以通过这个字段实现“身份标识”的功能。可以通过抓包观察登陆的过程。
1.4.4 认识请求“正文”(body)
正文中的内容格式和header 中的 content-type 密切相关。上面也罗列了三种常见情况。
1.5 HTTP 响应详解
1.5.1 HTTP 状态码
状态码表示访问一个页面的结果(是访问成功还是失败还是其他的一些情况...)
以下为一些常见的状态码
200 OK 这是最常见的一个状态码,表示访问成功
404 Not Found 没有找到资源
403 Forbidden 表示访问被拒绝,有的页面需要一些权限才能够访问(登录后才能访问),如果用户没有登陆直接访问,就容易见到 403
405 Method Not Allowed 前面我们已经学习了 HTTP 中所支持的方法,但是对方的服务器不一定支持所有的方法
500 Internal Server Error 服务器出现内部错误,一般是服务器的代码执行过程中遇到了一些特殊情况。
504 Gateway Timeout 当服务器负载比较大的时候,服务器处理单条请求的时候耗时就会比较长,就很可能会出现超时的情况。
302 Move temporarily 临时重定向。
301 Moved Permanently 永久重定向。
1.5.2 响应“报头”(header)
响应报头的基本格式和请求报头的格式基本⼀致.
类似于 Content-Type , Content-Length 等属性的含义也和请求中的含义⼀致.
响应中的 Content-Type 常见取值有以下几种:
text/html : body 数据格式是 HTML
text/css : body 数据格式是 CSS
application/javascript : body 数据格式是 JavaScript
application/json : body 数据格式是 JSON
1.5.3 响应“正文”(body)
text/html:
Server: nginx/1.17.3
Date: Thu, 10 Jun 2021 07:25:09 GMT
Content-Type: text/html; charset=utf-8
Last-Modified: Thu, 13 May 2021 09:01:26 GMT
Connection: keep-alive
ETag: W/"609ceae6-3206"
Content-Length: 12806
<!DOCTYPE html><html><head><meta charset=utf-8><meta http-equiv=X-UA-Compatible
body,
#app {
height: 100%;
margin: 0px;
padding: 0px;
}
.chromeframe {
margin: 0.2em 0;
background: #ccc;
color: #000;
padding: 0.2em 0;
}
#loader-wrapper {
position: fixed;
top: 0;
left: 0;
width: 100%;
height: 100%;
z-index: 999999;
}
......
text/css:
HTTP/1.1 200 OK
Server: nginx/1.17.3
Date: Thu, 10 Jun 2021 07:25:09 GMT
Content-Type: text/css
Last-Modified: Thu, 13 May 2021 09:01:26 GMT
Connection: keep-alive
ETag: W/"609ceae6-3cfbe"
Content-Length: 249790
@font-face{font-family:element-icons;src:url(../../static/fonts/element-icons.53
......application/JavaScript
HTTP/1.1 200 OK
Server: nginx/1.17.3
Date: Thu, 10 Jun 2021 07:25:09 GMT
Content-Type: application/javascript; charset=utf-8
Last-Modified: Thu, 13 May 2021 09:01:26 GMT
Connection: keep-alive
ETag: W/"609ceae6-427d4"
Content-Length: 272340
(window["webpackJsonp"]=window["webpackJsonp"]||[]).push([["app"],{0:function(t,
......application/json:
HTTP/1.1 200
Server: nginx/1.17.3
Date: Thu, 10 Jun 2021 07:25:10 GMT
1 2 3Content-Type: application/json;charset=UTF-8
Connection: keep-alive
X-Content-Type-Options: nosniff
X-XSS-Protection: 1; mode=block
Cache-Control: no-cache, no-store, max-age=0, must-revalidate
Pragma: no-cache
Expires: 0
vary: accept-encoding
Content-Length: 12268
{"msg":"操作成功","code":200,"permissions":[] }二、HTTPS
HTTPS 也是应用层协议,是在HTTP协议的基础上引入了一个加密层。
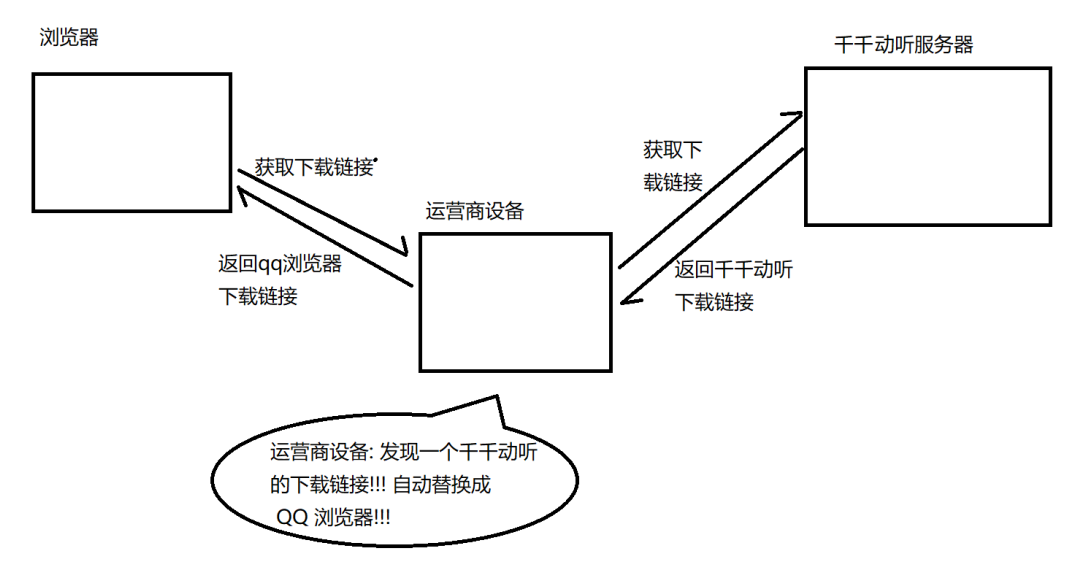
HTTP协议内容都是按照文本的方式明文传输的,这就导致在传输过程中会出现被篡改的情况。臭名昭著的“运营商劫持”。就比如你下载一个天天动听,未被劫持的情况下你点击下载按钮就会弹出天天动听的下载链接,如果已被劫持就会弹出QQ浏览器的下载链接。
由于我们通过网络传输的任何数据包都会经过运营商的网络设备,那么运营商的网络设备就可以解析出你传输的数据内容,并进行篡改。点击 "下载按钮", 其实就是在给服务器发送了⼀个 HTTP 请求, 获取到的 HTTP 响应其实就包含了该 APP 的下载链接. 运营商劫持之后, 就发现这个请求是要下载天天动听, 那么就自动的把交给用户的响应给篡改成 "QQ浏览器" 的下载地址了.
2.1 HTTPS的工作过程
既然要保证数据安全,就需要进行“加密”。
网络传输中不再直接传输明文了,而是加密后生成的“密文”。
加密的方法有很多,但是大致可以分为对称加密和非对称加密。
HTTPS加密完整流程:
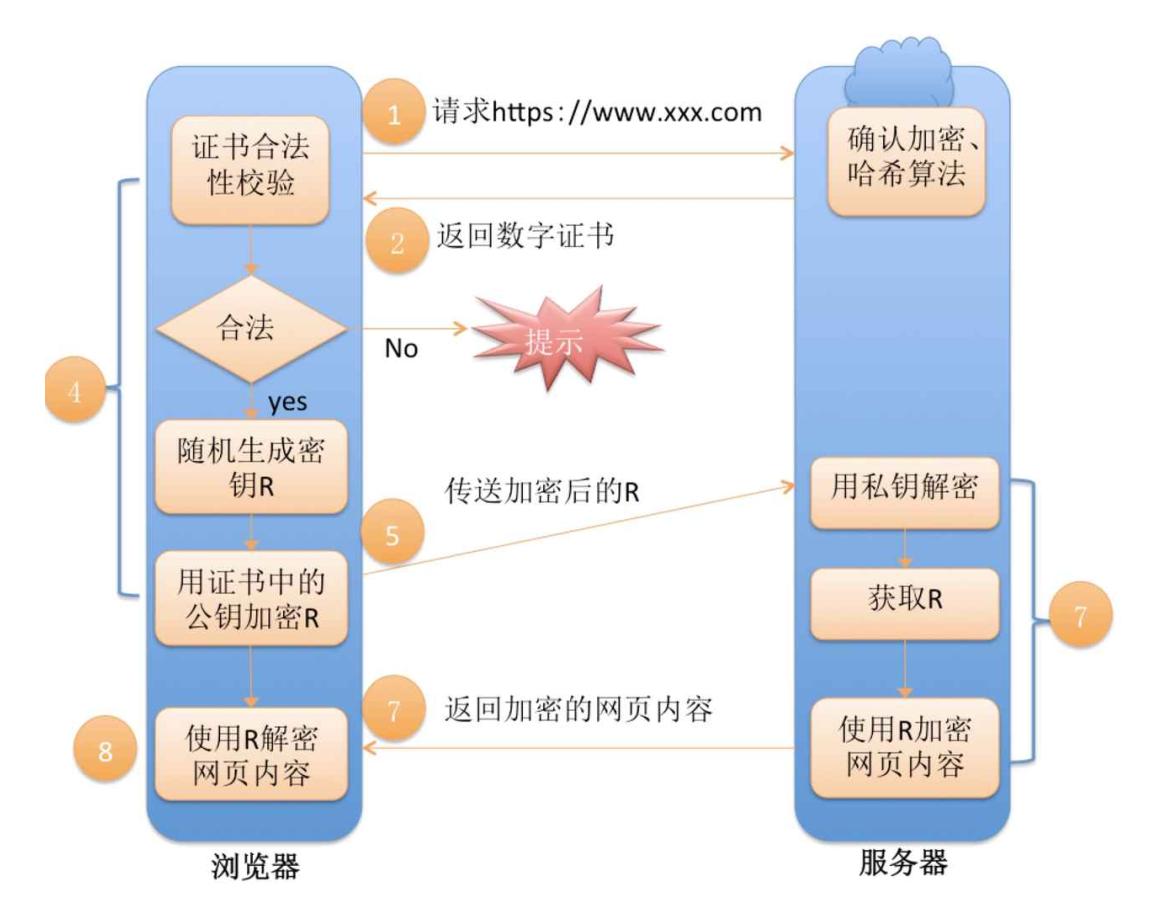
HTTPS ⼯作过程中涉及到的密钥有三组.
第⼀组(非对称加密): 用于校验证书是否被篡改. 服务器持有私钥(私钥在注册证书时获得), 客户端持有公钥(操作系统包含了可信任的 CA 认证机构有哪些, 同时持有对应的公钥). 服务器使用这个私钥对证书的签名进行加密. 客户端通过这个公钥解密获取到证书的签名, 从而校验证书内容是否是篡改过.
第⼆组(非对称加密): 用于协商生成对称加密的密钥. 服务器生成这组 私钥-公钥 对, 然后通过证书把公钥传递给客户端. 然后客户端用这个公钥给生成的对称加密的密钥加密, 传输给服务器, 服务器通过私钥解密获取到对称加密密钥.
第三组(对称加密): 客户端和服务器后续传输的数据都通过这个对称密钥加密解密.