使用Python,OpenCV,K-Means聚类查找图像中最主要的颜色
分别把跑图聚类选取1, 2, 3,4, 5, 6, 7,8, 9种主要颜色并绘制colormap颜色图;
效果图
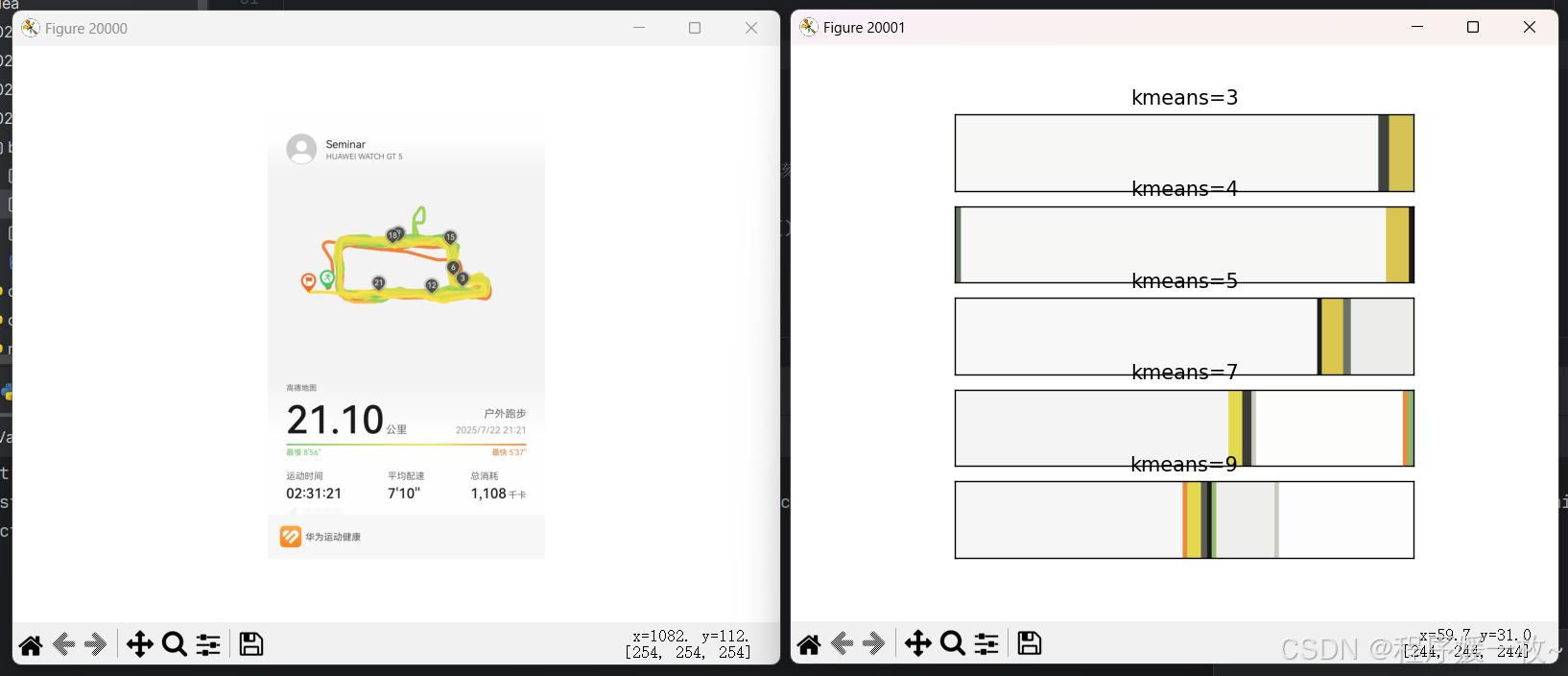
分别把跑图聚类选取3,4, 5,7,9种主要颜色并绘制colormap颜色图,跑图和颜色图汇总如下:
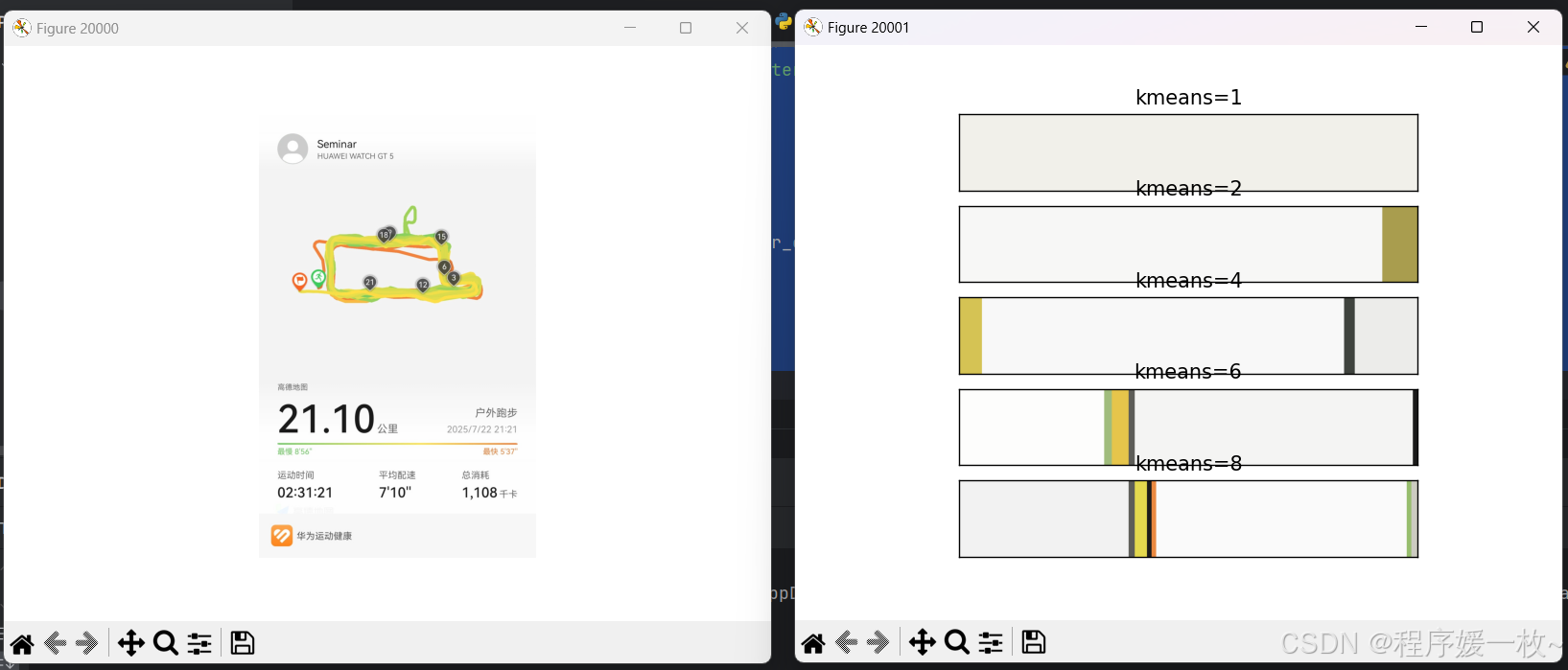
分别把跑图聚类选取1,2, 4,6,8种主要颜色并绘制colormap颜色图,跑图和颜色图汇总如下:
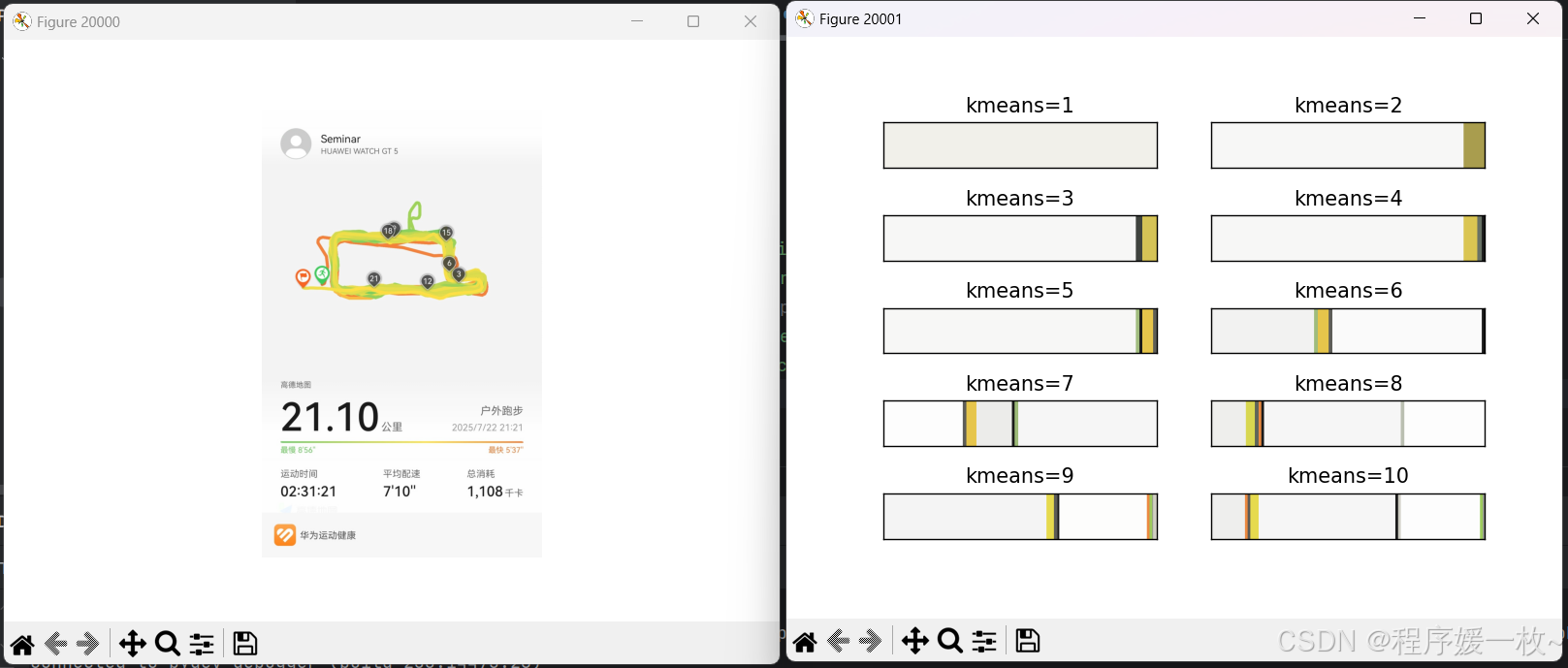
分别聚类1-10种颜色得到的主要颜色排布如下:
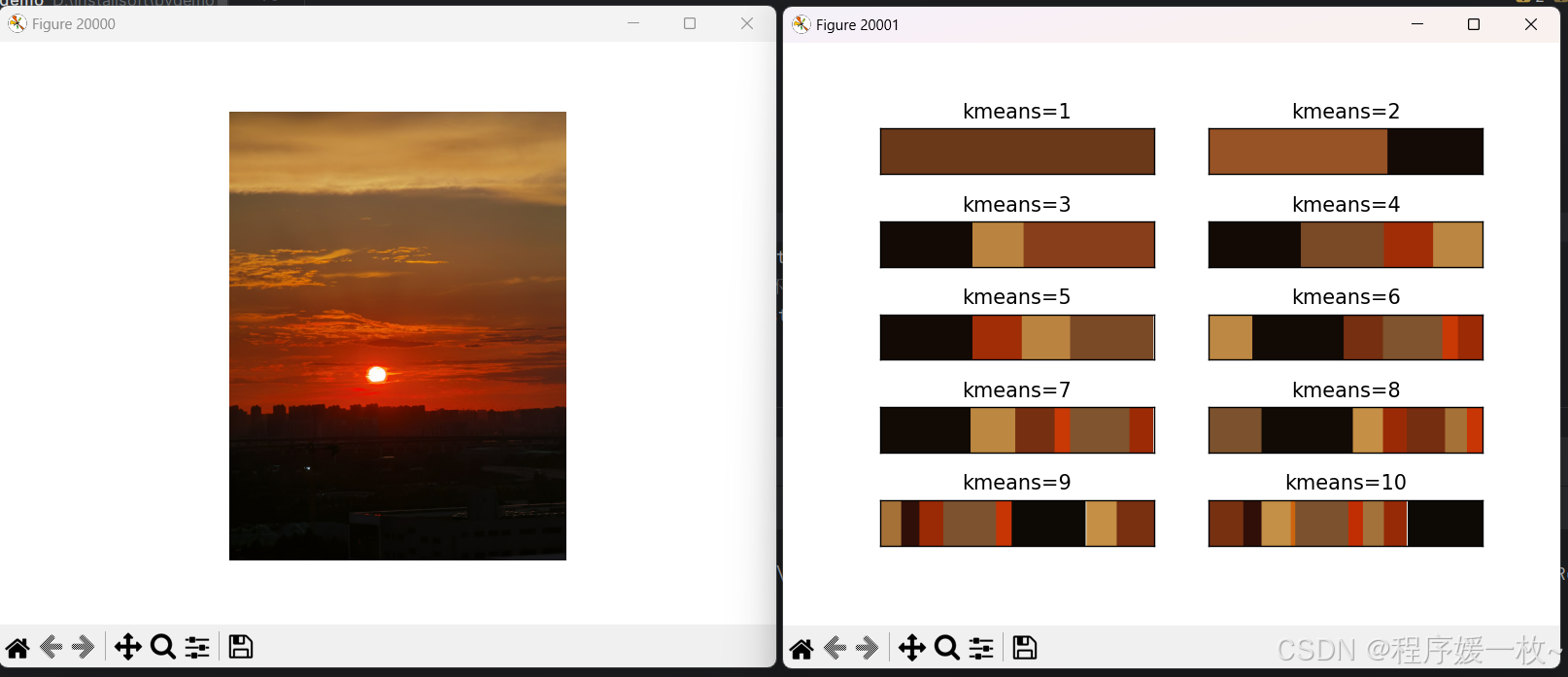
换一张绚烂的落日图,分别聚类1-10种颜色得到的主要颜色排布如下:
源码见如下链接:
https://blog.csdn.net/qq_40985985/article/details/109738677?spm=1011.2415.3001.5331
# python color_kmeans.py --image images/cactus.jpg --clusters 3
# 导入必要的包
import argparse
import cv2
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
def centroid_histogram(clt):
# 获取不同聚簇的个数,根据每个聚簇的像素数生成直方图
# k均值算法将图像中的每个像素分配给最近的聚类。
numLabels = np.arange(0, len(np.unique(clt.labels_)) + 1)
(hist, _) = np.histogram(clt.labels_, bins=numLabels)
# 对直方图进行归一化,使得总和为1
hist = hist.astype("float")
hist /= hist.sum()
# 返回直方图
return hist
# plot_colors函数需要两个参数:
# hist,它是从centroid_histogram函数生成的直方图;
# centroids,是由k-means算法生成的质心(集群中心)的列表。
def plot_colors(hist, centroids):
# 初始化代表相对频率的每种颜色的条形图
# 定义了一个300×50像素的矩形,以容纳图像中最主要的颜色
bar = np.zeros((50, 300, 3), dtype="uint8")
startX = 0
# 遍历每一个聚簇的百分比及颜色
for (percent, color) in zip(hist, centroids):
# 绘制每一聚簇的相对百分比
endX = startX + (percent * 300)
cv2.rectangle(bar, (int(startX), 0), (int(endX), 50),
color.astype("uint8").tolist(), -1)
startX = endX
# 返回条形图
return bar
# 构建命令行参数和解析
# --image 原始图像路径
# --clusters 期望生成的簇数
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=False,
# default='bm_sports/sports/sporthealth-3-20250722-235354.jpg',
default='bm_sports/sports/IMG_20250703_194927.jpg',
help="Path to the image")
ap.add_argument("-c", "--clusters", required=False, default=5, type=int,
help="# of clusters")
args = vars(ap.parse_args())
# 加载图像,转换BGR-->RGB 以在matplotlib展示
image = cv2.imread(args["image"])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 展示图像
plt.figure(200 * 100)
plt.axis("off")
plt.imshow(image)
# 将NumPy数组重塑为RGB像素列表
image = image.reshape((image.shape[0] * image.shape[1], 3))
def plot_subplots(kmeans_list, bar_list):
plt.figure()
width_col = 1
if len(bar_list) > 5:
width_col = 2
for i in range(len(bar_list)):
plt.subplot(len(bar_list)//width_col, width_col, i + 1)
plt.imshow(bar_list[i]) # 通过for循环逐个显示图像
plt.title('kmeans=' + str(kmeans_list[i]))
plt.xticks([]) # 去掉x轴的刻度
plt.yticks([]) # 去掉y轴的刻度
plt.show()
bar_list = []
kmeans_list = [3, 4, 5, 7, 9]
kmeans_list = [1, 2, 4, 6, 8]
kmeans_list = list(range(1, 11))
for cluster in kmeans_list:
args['clusters'] = cluster
# 使用scikit-learn中的K-means实现来避免重新实现该算法
# 使用K-means查找图像中最主要的颜色
# 使用期望获取的聚簇数,初始化局KMeans类,调用fit()方法将像素列表聚集在一起
clt = KMeans(n_clusters=args["clusters"])
clt.fit(image)
# 构建聚簇直方图
# 建立图表以代表每一种颜色所对应的像素数
hist = centroid_histogram(clt)
bar = plot_colors(hist, clt.cluster_centers_)
bar_list.append(bar)
plot_subplots(kmeans_list, bar_list)