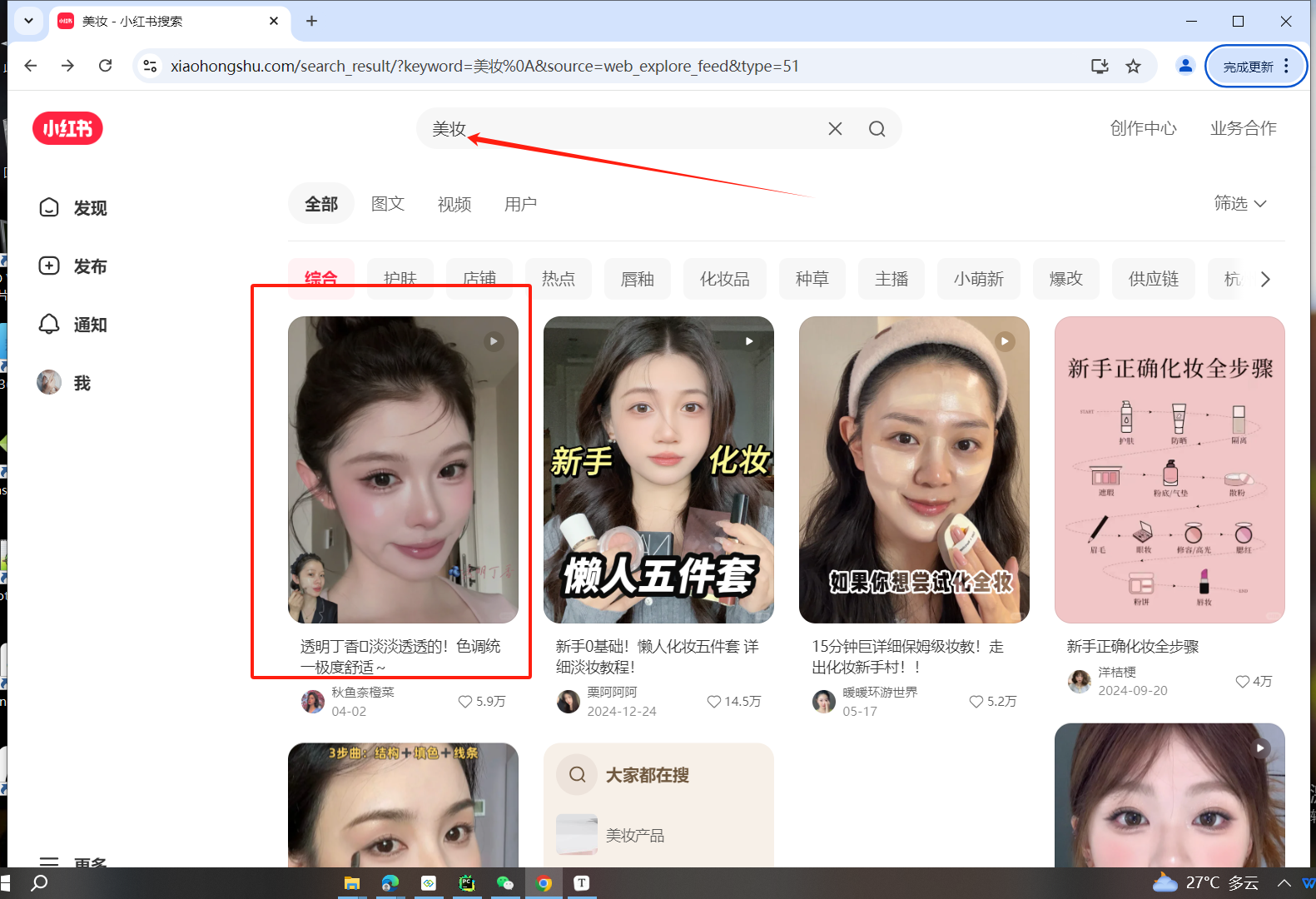
案例一:搜索【美妆】获取每一个卡片的信
代码如下:
# 导入时间等待库
import time
# 导入ChromiumPage
from DrissionPage import ChromiumPage
# 数据写入到excel文件
from DataRecorder import Recorder
# 写入到excel表格中
recorder = Recorder("./data.xlsx")
recorder.set.show_msg(False) # 不显示日志信息--会显示很多无用的日志,所以这里屏蔽掉无用的日志打印
def handler(page, keyword):
# 访问小红书的搜索【美妆】后的界面链接
# https://www.xiaohongshu.com/search_result?keyword=美妆&source=web_explore_feed
page.get(f"https://www.xiaohongshu.com/search_result?keyword={keyword}&source=web_explore_feed&type=51")
time.sleep(5) # 为了防止网络的影响加载慢,可以等待5秒,让数据加载一下
# 7--【循环进行向下滑动滚轮,不断加载跟多内容】
for i in range(1, 3): # 滚轮向下滑动3次 滚动的操作会做3次
# 为了捕获失败,防止程序报错,加上try...except
try:
# 通过class="note-item" 定位界面上的每一个卡片数据
# cards = page.eles('@class=note-item') # 该行代码等价于下一行,都是class定位
cards = page.eles('.note-item')
# 3--【(1) 启动监听机制 监听卡片详情接口 对指定的数据包进行监听】
page.listen.start("/sns/web/v1/feed")
# 遍历的每一个卡片
for card in cards:
# print(card)
# 通过局部定位定位大图,根据标签名定位img标签,并进行点击操作
card.ele('@tag()=img').click(by_js=True) # by_js=True 参数可以不写,进行默认
# 4--【(2) 等待卡片详情接口数据返回 点击显示的数据是动态请求的】
res = page.listen.wait(count=1, timeout=1, fit_count=True)
# (3) 获取数据
data = res.response.body
print("data:::", data)
time.sleep(2)
# 数据提取
nickname = find_first_key_value(data, "nickname")
title = find_first_key_value(data, "title")
desc = find_first_key_value(data, "desc")
comment_count = find_first_key_value(data, "comment_count")
liked_count = find_first_key_value(data, "liked_count")
# 基于recorder将采集的数据写入excel,recorder需要是字典格式
# 把每个字典作为是一行数据,一行一行写入,所以这里需要组装成字典格式
map = {
"博主昵称": nickname,
"标题": title,
"详情": desc,
"评论数": comment_count,
"点赞数": liked_count,
}
recorder.add_data(map)
recorder.record()
# 5--【关闭卡片并等待 弹窗关闭】
close_btn = page.ele('@class=close close-mask-dark')
close_btn.click()
time.sleep(2)
except Exception as e:
print("错误失败了--error::::", e)
finally:
# 7.1--【滚动滚轮】 try抛不抛异常,这个finally都会在try执行完一次以后被执行一次
page.scroll.up(100) # 点击滑块
time.sleep(1)
page.scroll.to_bottom()
time.sleep(1)
# 6--【数据解析函数】
def find_first_key_value(data, target_key):
# (1) 处理数据为字典的递归遍历
if isinstance(data, dict): # 判断是否是字典类型
# 便利字典的key和value
for key, val in data.items():
# 如果key等于传递进来的target_key,就把对应的value返回出去
if key == target_key:
return val
# 递归遍历子元素
ret = find_first_key_value(val, target_key)
if ret is not None:
return ret
# (2) 处理数据为列表的递归遍历
if isinstance(data, list):
for item in data: # 遍历列表获取列表中的字典形式的列表元素
# 根据target_key提取对应的value值
ret = find_first_key_value(item, target_key)
if ret is not None:
return ret
return None
def main():
with open("关键词.txt", mode="r", encoding="utf-8") as f:
# 1--【readlines 逐行进行读取txt文件中的搜索关键词,并以列表的形式进行返回】
keyword_list = f.readlines()
# 创建浏览器驱动对象
page = ChromiumPage()
# 访问小红书首页
page.get("https://www.xiaohongshu.com/explore")
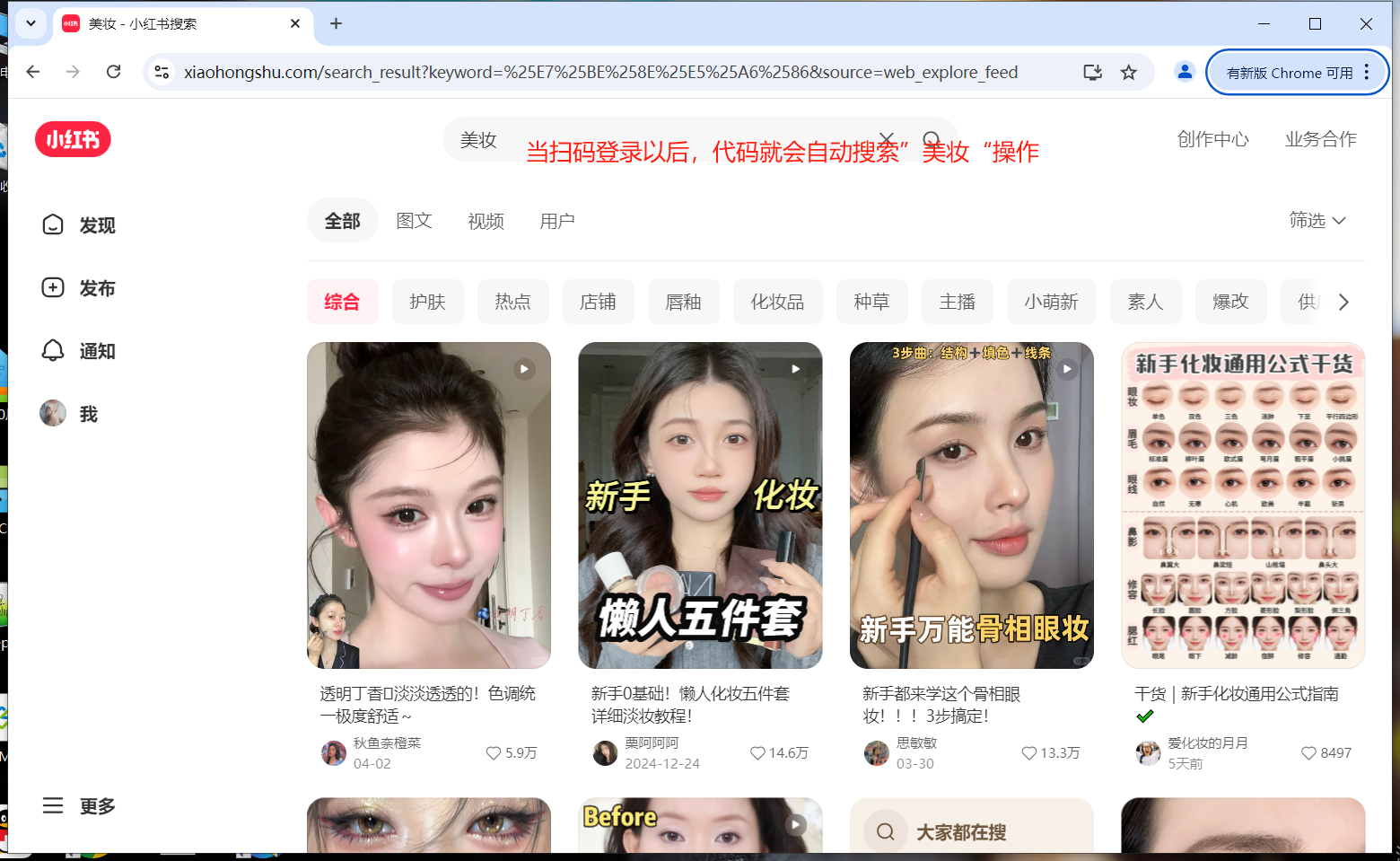
# 2--【小红书的登录很难,如果用逆向的话比较麻烦,所以这里我们进行手动登录】
input("等待登录")
for keyword in keyword_list:
# 把显示的页面page和关键词keyword传递过去
handler(page, keyword)
# 程序的入口
main()
"""
对代码中【】括起来的注释进行分析和解释
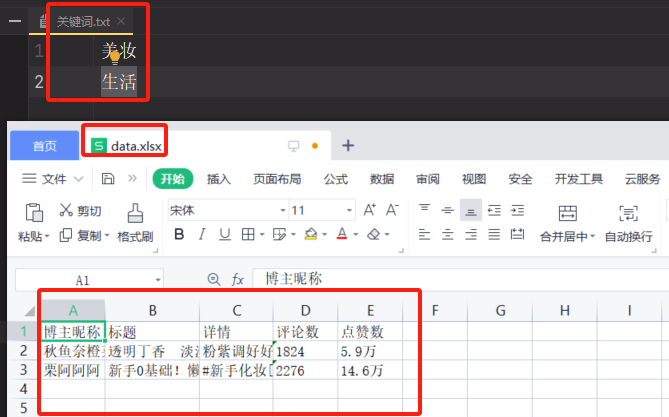
1、在编写代码前需要创建一个【关键词.txt】文件,里面存放将要搜索的关键词,例如:美妆、生活
2、因为小红书的登录如果使用逆向操作比较麻烦,所以我们可以使用ChromiumPage控制浏览器,进行手动扫码登录
3、因为卡片点击后,每次放大显示的数据都是通过接口直接请求的数据,所以我们需要监听,每次请求后接口返回的数据
因为如果通过逆向发送请求,并且获取接口的返回数据比较麻烦(接口中的参数和返回的数据都进行了加密处理还需要破解)
所以我们可以通过page提供的监听机制,可以动态的获取被监听的接口的请求和返回的数据
3.1、监听不能放到for循环里面,不然每点击一次卡片数据都会开启一次监听,所以需要放到外面,开启一次监听即可
4、获取监听到指定请求响应回来的数据内容 count=1, timeout=1, fit_count=True 参数可写可不写
5、点击放到后,需要先关闭放大后的弹窗,才能继续进行下一个点击,不然就只能获取到一个卡片数据
6、数据解析方法有案例
7、因为每一页只能显示几条数据,所以我们需要滑动滑块加载更多
因为当try...except加载完以后,不管会不会抛异常,都会执行finally中的代码,所以我们把
点击滑块,滑动滑块的动作放到这里
问题1:不能滚轮滚到底在进行加载数据吗?
不能,因为每次滚轮滚到底,加载完以后,滚轮自动就会回到中间
问题2:滚轮可以一下滚到底,在一个一个点吗?
因为滚轮滚到底以后,会在动态在加载数据,滚轮还会回到中间,在往下滚,在回到中间,类似一页一页的
7.1、100就是点击的时候上下晃动100个像素,不要这个也行直接滑倒底部
写50 100 200都可以 为了模拟人的行为 up是向上100个像素再往下滑倒底部,更真实的模拟人的行为
"""
准备文件1:创建一个txt文件,用于存放需要搜索的字段,比如需要获取"美妆"和"生活"的数据,就写"美妆"和"生活"
分析一:当代码打印【等待登录】的时候就需要我们手动扫描登录,减少了逆向破解的繁琐操作

分析二:
分析三:
1、通过class="note-item" 定位界面上的每一个卡片数据,
2、通过局部定位定位大图,根据标签名定位img标签,并进行点击操作
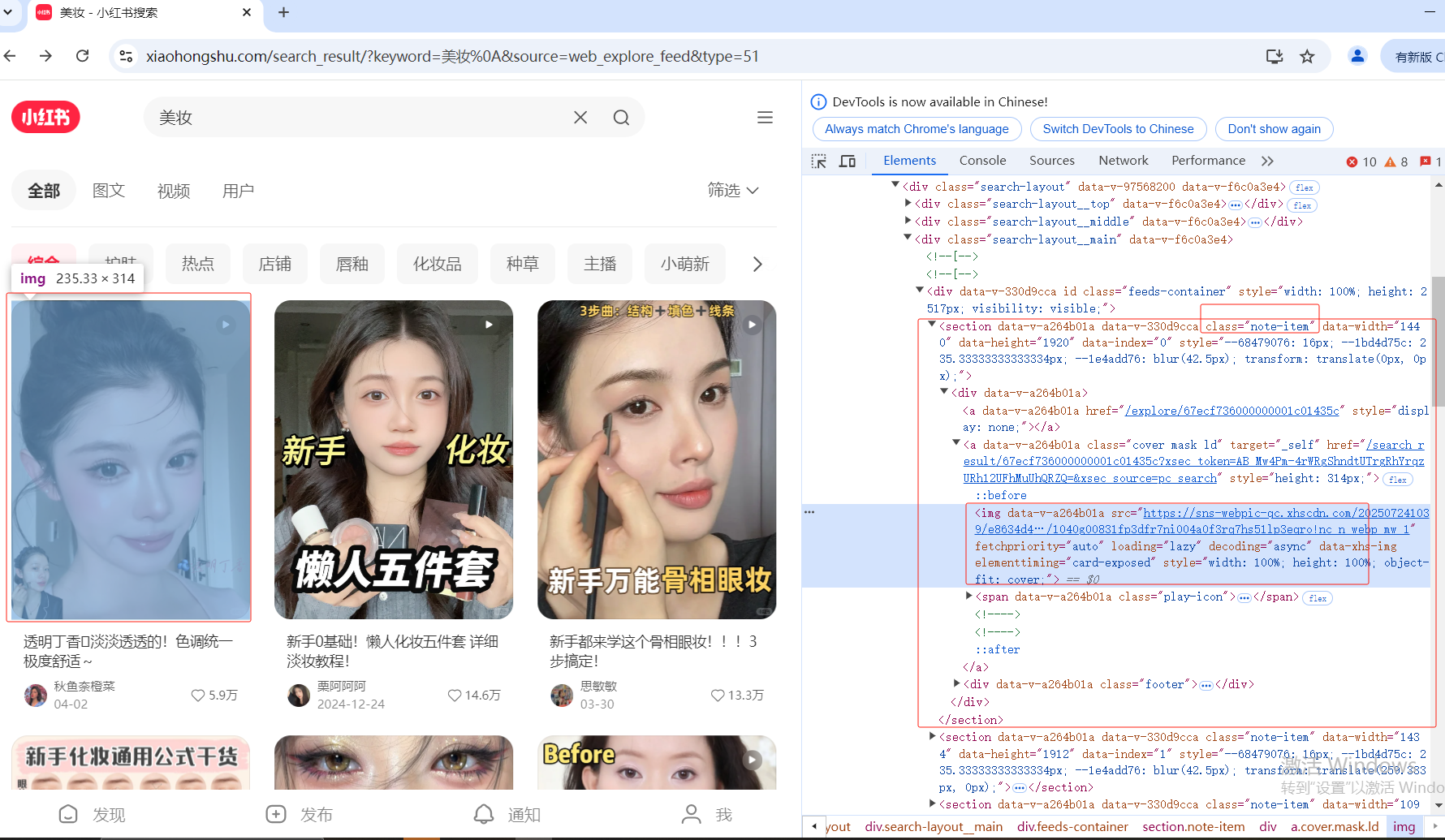
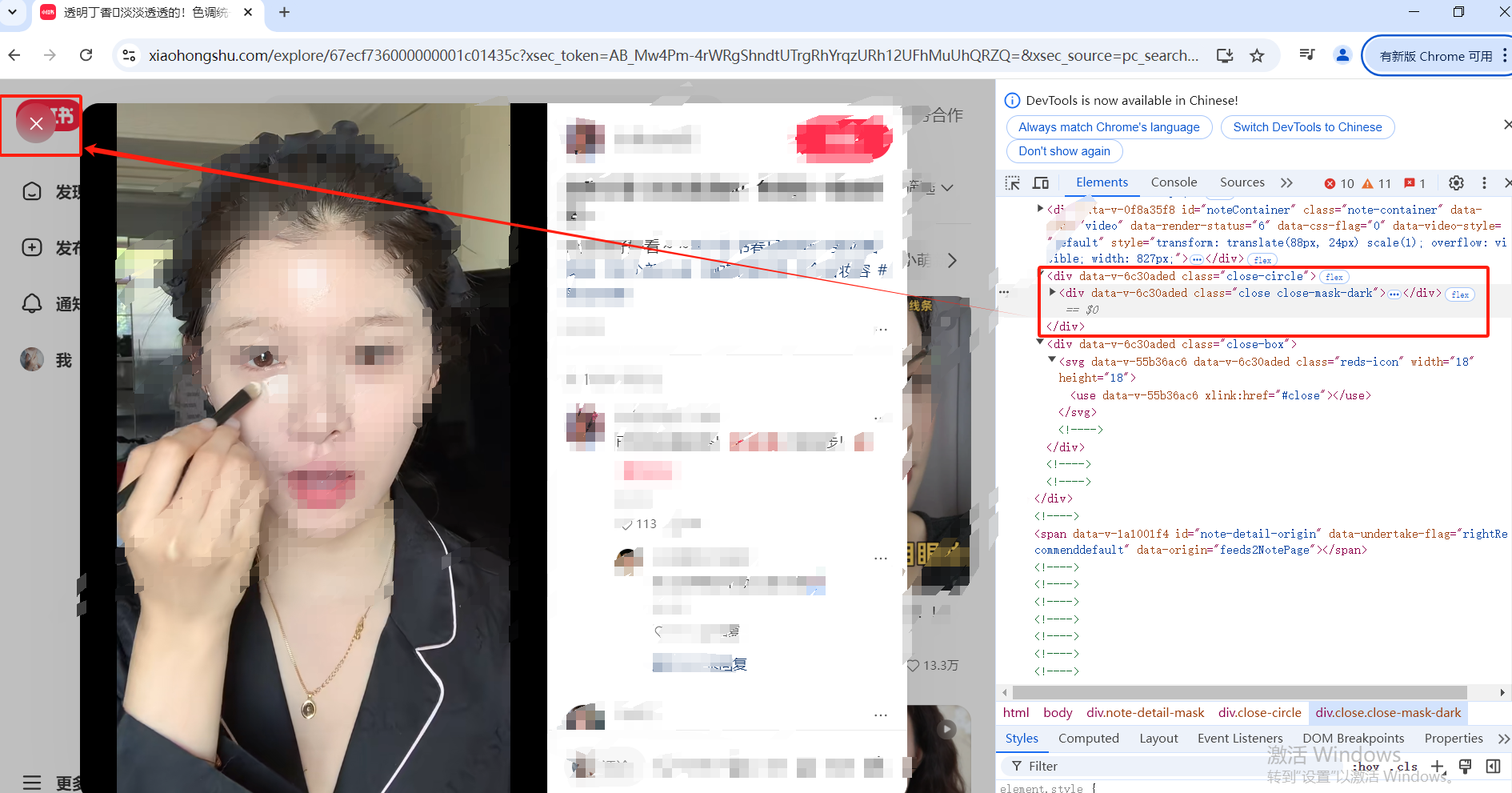
分析四:
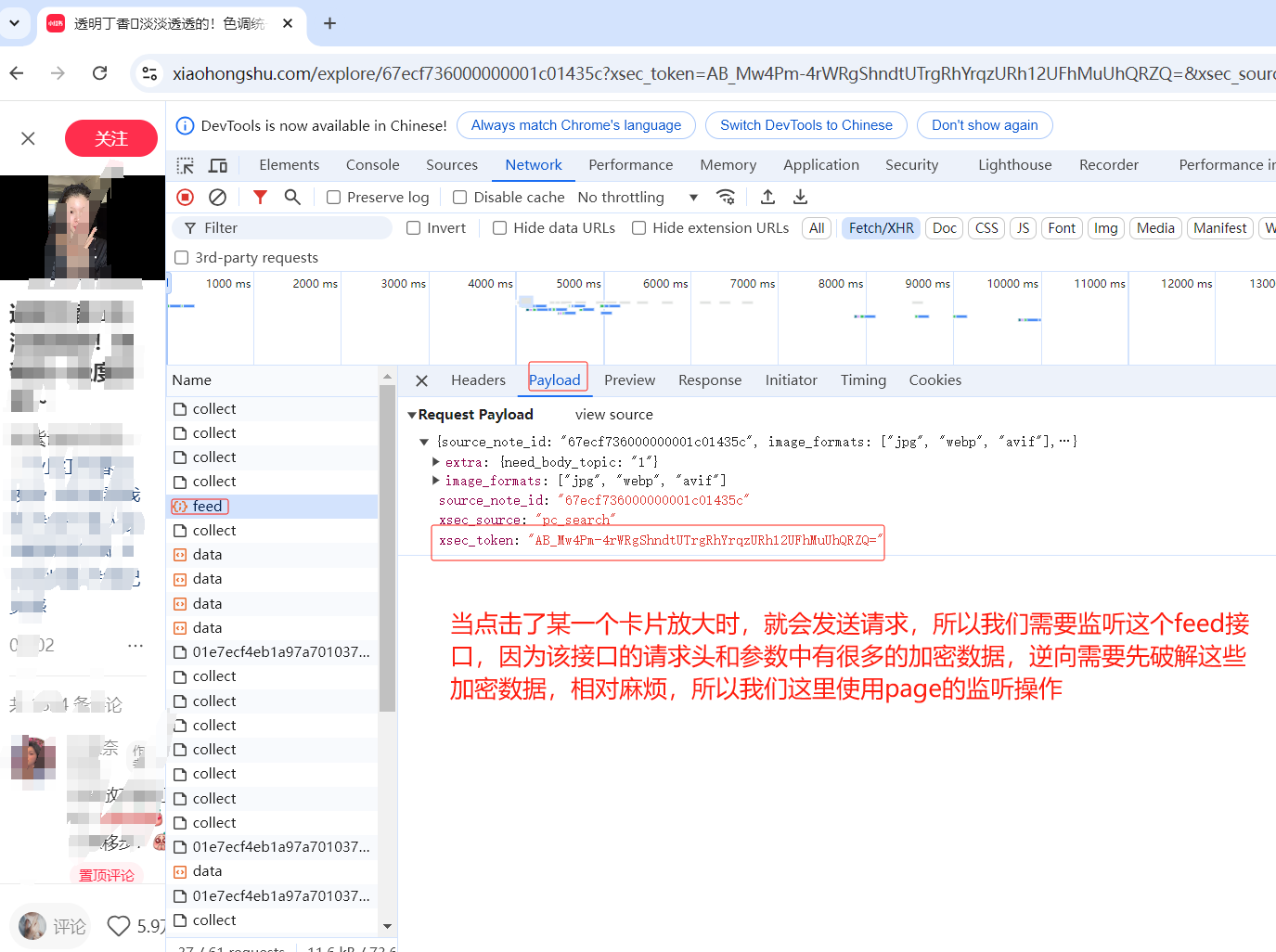
分析五:
for i in range(1, 3):
try:
print("开始执行-----try")
except Exception as e:
print("开始执行-----try", e)
finally:
print("滚轮滑动了一次")
"""
开始执行-----try
滚轮滑动了一次
开始执行-----try
滚轮滑动了一次
"""
分析六:
dic = {
'a': {
'b': 'i am b',
'c': 'i am c',
'd1': {
'd1': 'i am d1'
}
},
'ab': {
'abb': 'i am abb'
},
'cc': [
{'c1': 'i am c1', 'c2': 'i am c2'}
]
}
# 数据解析函数
def find_first_key_value(data, target_key):
# (1) 处理数据为字典的递归遍历
if isinstance(data, dict): # 判断是否是字典类型
# 便利字典的key和value
for key, val in data.items():
# 如果key等于传递进来的target_key,就把对应的value返回出去
if key == target_key:
return val
# 递归遍历子元素
ret = find_first_key_value(val, target_key)
if ret is not None:
return ret
# (2) 处理数据为列表的递归遍历
if isinstance(data, list):
for item in data: # 遍历列表获取列表中的字典形式的列表元素
# 根据target_key提取对应的value值
ret = find_first_key_value(item, target_key)
if ret is not None:
return ret
return None
# 把json类型的数据转递作为第一个参数传递进去,把需要获取数据的key作为第二个参数,
# 就可返回得到key对应的value
ret_a = find_first_key_value(dic, "a")
print(ret_a)
# {'b': 'i am b', 'c': 'i am c', 'd1': {'d1': 'i am d1'}}
ret_d1 = find_first_key_value(dic, "d1")
print(ret_d1)
# {'d1': 'i am d1'}
ret_abb = find_first_key_value(dic, "abb")
print(ret_abb)
# i am abb
ret_c = find_first_key_value(dic, "c")
print(ret_c)
# i am c
ret_c2 = find_first_key_value(dic, "c2")
print(ret_c2)
# i am c2
分析七:爬取的结果如下
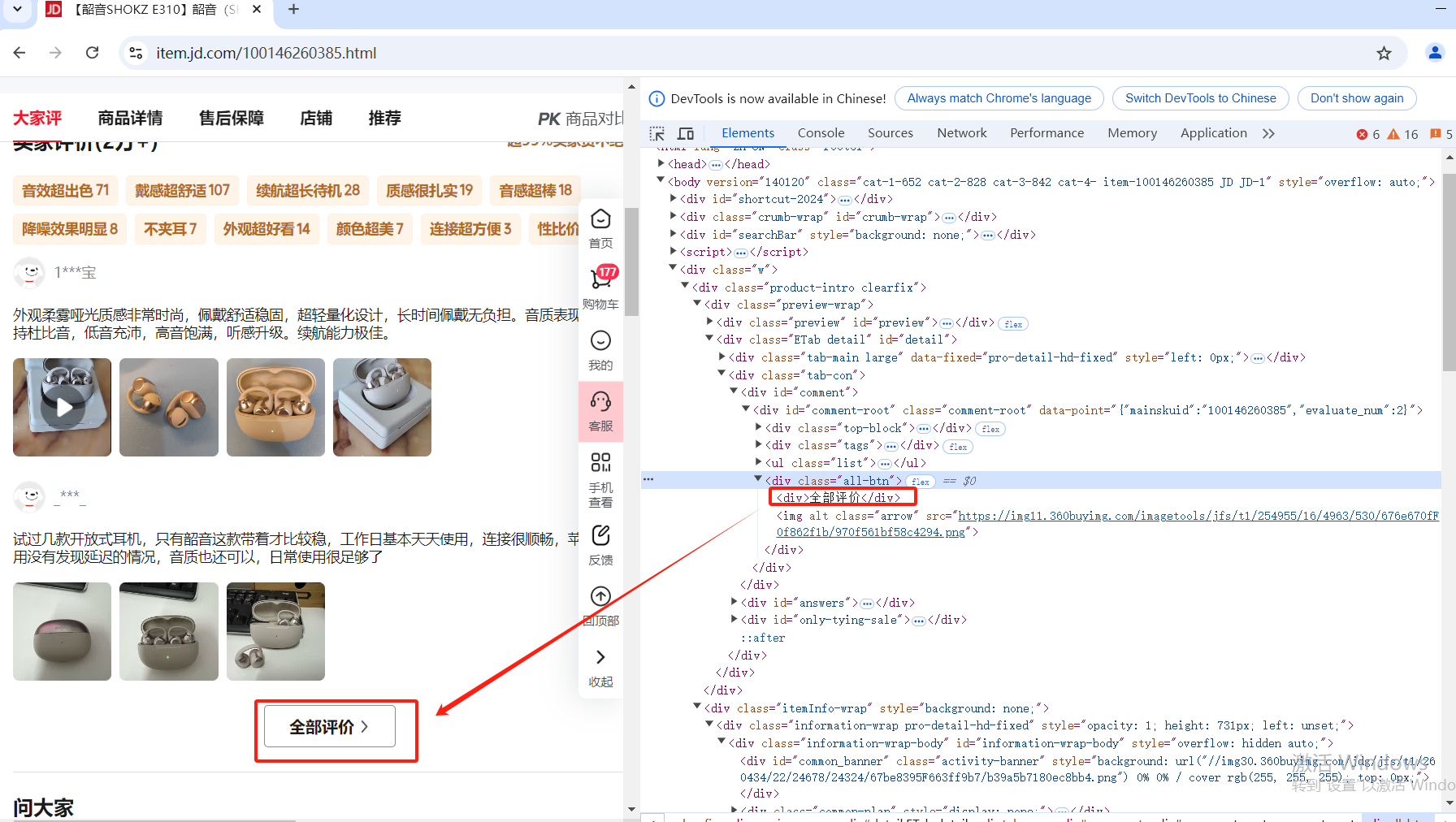
案例二:爬取某东某个商品的【全部评价】数据信息
import json
# 导入时间等待库
import time
# 导入ChromiumPage
from DrissionPage import ChromiumPage
# 数据写入到excel文件
from DataRecorder import Recorder
recorder = Recorder("JD.xlsx")
recorder.set.show_msg(False)
def find_key_val(data, target_key, max_count=1):
results = []
# (1) json字符串反序列化 先判断传递来的是字符串吗?是的话就反序列化转化为对象
if isinstance(data, str):
try:
data = json.loads(data)
except json.JSONDecodeError:
return results
def _search(data):
# 最大数量限制
if len(results) == max_count:
return
# 处理数据为字典的递归遍历
if isinstance(data, dict):
for key, val in data.items():
if key == target_key:
results.append(val)
if len(results) == max_count:
return
# 递归遍历子元素
_search(val)
# (2) 处理数据为列表的递归遍历
if isinstance(data, list):
for item in data:
ret = _search(item)
if ret is not None:
return ret
return None
_search(data)
return results
def handler(page):
try:
# 监听某个固定的接口
page.listen.start("client.action")
# 定位到”全部评价“这个按钮,并点击
page.ele('@text()=全部评价').click()
# 因为在滚动滚轮的时候被监听的接口会不断的更新返回的数据,
# 所以我们要写死循环不断的接听返回的数据,不然监听的数据只会返回一条评价
while 1:
# 获取返回的数据 循环一次,获取一次评价数据
res = page.listen.wait()
data = res.response.body
print("data:::", data)
# 解析数据
commentInfoList = find_key_val(data, "commentInfo", 11)
for commentInfo in commentInfoList:
map = {
"用户名": commentInfo.get("userNickName"),
"评论时间": commentInfo.get("commentDate"),
"评论内容": commentInfo.get("commentData"),
"评分": commentInfo.get("commentScore"),
}
recorder.add_data(map)
recorder.record()
# 滚动滚轮并等待
page.ele('@class=_rateListContainer_1ygkr_45').scroll.to_bottom()
time.sleep(3) # 防止被封号
except Exception as e:
print("错误失败了---error:::", e)
def main():
# 创建浏览器驱动对象
page = ChromiumPage()
# 访问需要爬取的商品的链接
page.get("https://item.jd.com/100146260385.html")
input("等待登录")
handler(page)
# 程序的入口
main()
"""
在Python中,字符串序列化是将数据结构(如字典、列表等)转换为字符串格式的过程,
而反序列化则是将字符串重新转换回原始数据结构。以下是主要实现方式:
json模块(最常用):
json.dumps()实现序列化,可将Python对象转为JSON格式字符串
json.loads()实现反序列化,将JSON字符串转回Python对象
处理中文时建议添加ensure_ascii=False参数避免Unicode编码
import json
data = {"name": "张三", "age": 25}
# 序列化
json_str = json.dumps(data, ensure_ascii=False)
# 反序列化
restored_data = json.loads(json_str)
"""
分析一:如果给出的返回数据是字符串格式的,就需要先进行反序列化操作
import json
dic = {
'a': {
'b': 'i am b',
'c': 'i am c',
'd1': {
'd1': 'i am d1'
}
},
'ab': {
'abb': 'i am abb'
},
'data': [
{'commentInfo': {'name': 'i am name_1', 'userImgURL': 'i am userImgURL_1', 'iconType': 'i am iconType_1'}},
{'commentInfo': {'name': 'i am name_2', 'userImgURL': 'i am userImgURL_2', 'iconType': 'i am iconType_2'}},
{'commentInfo': {'name': 'i am name_3', 'userImgURL': 'i am userImgURL_3', 'iconType': 'i am iconType_3'}}
]
}
json_str = json.dumps(dic, ensure_ascii=False, indent=4)
# print(type(json_str))
# print("json_str:", json_str)
def find_key_val(data, target_key, max_count=1):
results = []
# (1) json字符串反序列化 先判断传递来的是字符串吗?是的话就反序列化转化为对象
if isinstance(data, str):
try:
data = json.loads(data)
print("进行了反序列化")
except json.JSONDecodeError:
return results
def _search(data):
# 最大数量限制
if len(results) == max_count:
return
# 处理数据为字典的递归遍历
if isinstance(data, dict):
for key, val in data.items():
if key == target_key:
results.append(val)
if len(results) == max_count:
return
# 递归遍历子元素
_search(val)
# (2) 处理数据为列表的递归遍历
if isinstance(data, list):
for item in data:
ret = _search(item)
if ret is not None:
return ret
return None
_search(data)
return results
ret_c2 = find_key_val(json_str, "commentInfo")
print(ret_c2)
"""
进行了反序列化
[{'name': 'i am name_1', 'userImgURL': 'i am userImgURL_1', 'iconType': 'i am iconType_1'}]
"""
分析二:定位到”全部评价“这个按钮