近几年做跨境电商或内容运营的同学,应该都能感受到视频内容正逐渐从“锦上添花”变成了“必选项”。
尤其是 TikTok、Instagram Reels、Facebook 短视频、甚至一些独立站内嵌视频讲解页,对带讲解、有人脸、自然语音的视频内容都有显著的转化提升作用。
但实际做过的人都知道——内容制作往往是最难推进的一环:
视频要讲解,就要出镜
出镜就涉及拍摄、化妆、场地、设备
还需要录音、剪辑、调色、字幕配合
如果要做多语言,还得翻译+重新录制
对于个体从业者、小团队、或没有视频制作经验的人来说,这是一道很难跨过去的门槛。
内容自动化的突破口:语音+口型生成技术
随着文本转语音(TTS)和视频合成技术的发展,AI 在内容生产中的角色越来越明显。
现在,借助一些轻量化工具,不录音、不出镜、不剪辑也能完成一条讲解类视频的核心内容。
例如我最近测试的一款工具:LipSync, 它的实现方式是:给定一段语音(或 TTS 合成语音),自动生成与之口型同步的人脸视频。
实际效果比传统的 Avatar 类工具更自然,尤其在口型、语速和语音同步方面准确率非常高,配合剪映等工具即可快速生成完整内容。
实践场景举例:AI 驱动的“讲解视频自动化”流程
这是我现在常用的一套工作流,适合用于 TikTok 产品讲解、广告片段、多语言教程等内容场景:
文案撰写(中文或英文)
使用 AI 配音工具生成语音
将语音导入生成对口型讲解视频
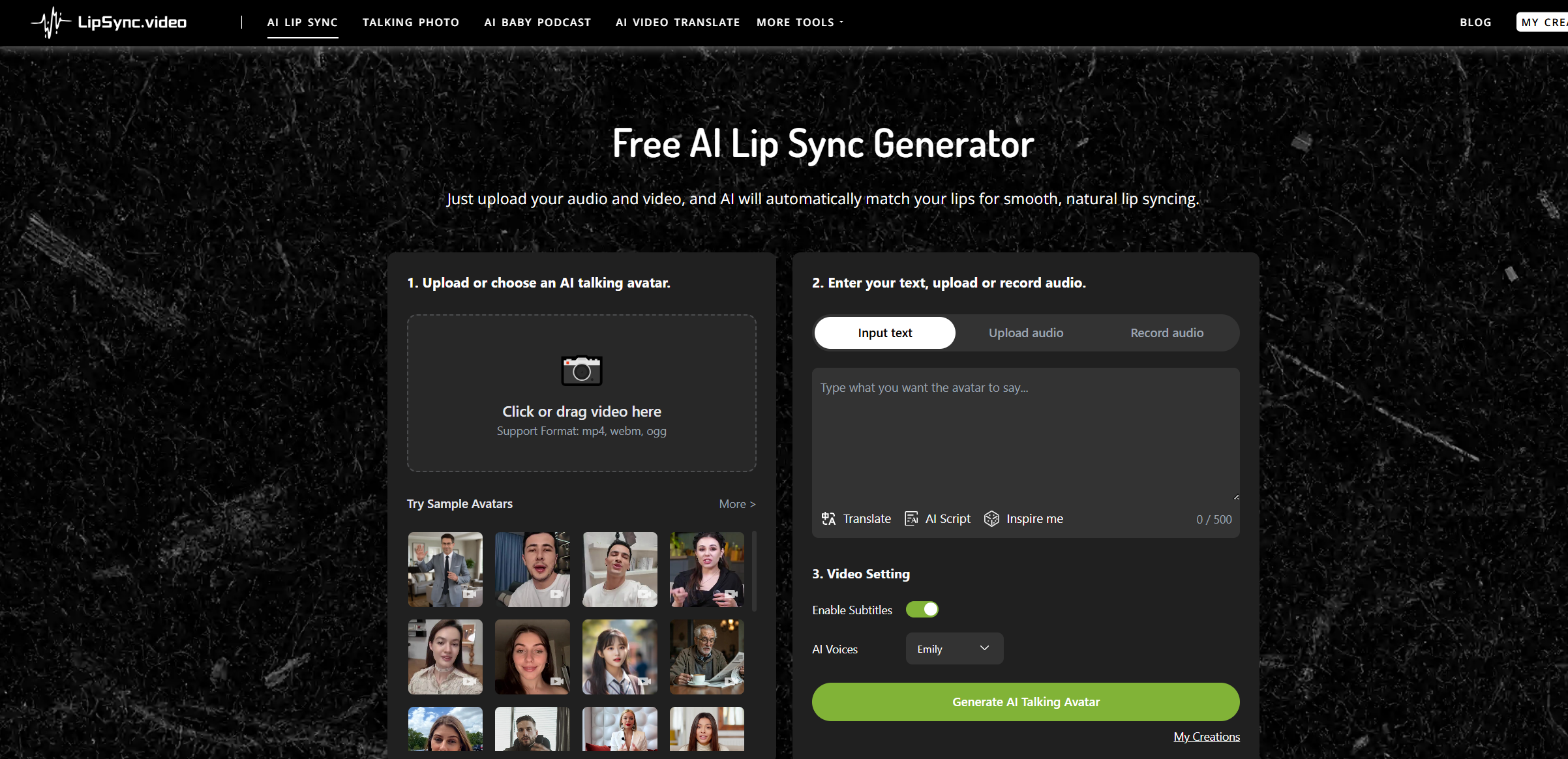
使用剪映 / capcut 添加产品画面、字幕、BGM
输出并发布
这种流程的优势是:
成本极低:不需要请配音、不请模特、不用剪辑师
速度极快:平均一条视频制作耗时可控制在 30 分钟内
支持多语言版本:只需替换配音内容,其余流程保持一致
技术角度简析核心原理
该工具背后的合成逻辑主要涉及三类关键技术:
语音驱动的人脸动作建模:通过声音频谱分析与机器学习模型,提取关键嘴型动作参数;
动态面部渲染:将静态头像素材进行动态映射(类似 Talking Head 技术);
音视频对齐与合成引擎:保证输出视频与音频节奏同步,自然过渡不跳帧。
这种方式较传统的剪辑式口型合成,具备更强的时间一致性和面部动态还原能力。
哪些人适合这种内容制作方式?
跨境电商团队:多语言视频内容本地化需求大,传统方式成本高;
一人公司 / 自由职业者:没有拍摄条件但需要大量产出;
教育 / SaaS 产品运营:需要批量输出讲解内容,提高客户留存;
AI 工具测评 / 视频播客制作者:需要大量 AI 人像视频素材支持。
小结:技术正在降低内容门槛
内容创作曾经是一个“门槛高、流程重”的领域,但 AI 正在逐渐解构这些壁垒。
从文字 → 语音 → 视频,整条链路如今都可以借助 AI 自动完成。
像这样的工具,提供了一个很实用的切入点,让“不会出镜”的创作者也有机会参与到视频内容生态中。
如果你正面临视频内容制作上的难题,不妨尝试这类工具辅助制作,可能会带来意想不到的效率提升。