数据标准化:让特征“公平竞争”的两种核心方法(完整篇)
上一篇我们讲了数据标准化的重要性和归一化方法,有同学反馈意犹未尽,今天补全剩下的标准化(Z-Score)内容,加上两种方法的对比和完整代码,确保你看完就能熟练应用~
三、方法二:标准化(Z-Score Normalization)—— 让数据符合标准正态分布
1. 原理
标准化(又称Z-Score变换)将数据转换为均值为0、标准差为1的标准正态分布,公式:
z=x−μσz = \frac{x - \mu}{\sigma}z=σx−μ
其中:
- μ\muμ 是特征的均值(μ=1n∑i=1nxi\mu = \frac{1}{n}\sum_{i=1}^n x_iμ=n1∑i=1nxi);
- σ\sigmaσ 是特征的标准差(σ=1n−1∑i=1n(xi−μ)2\sigma = \sqrt{\frac{1}{n-1}\sum_{i=1}^n (x_i - \mu)^2}σ=n−11∑i=1n(xi−μ)2)。
2. 公式推导
标准化的目标是让数据服从标准正态分布 N(0,1)N(0,1)N(0,1)(均值0,方差1),分两步实现:
去均值:将数据中心平移到0
x1=x−μx_1 = x - \mux1=x−μ
(此时数据均值为0,但方差仍为σ2\sigma^2σ2)缩放:将方差缩放到1
因为方差的缩放公式为 Var(k⋅x)=k2⋅Var(x)\text{Var}(k \cdot x) = k^2 \cdot \text{Var}(x)Var(k⋅x)=k2⋅Var(x),要让新方差为1:
k2⋅σ2=1 ⟹ k=1σk^2 \cdot \sigma^2 = 1 \implies k = \frac{1}{\sigma}k2⋅σ2=1⟹k=σ1
因此最终变换为:
z=x1σ=x−μσz = \frac{x_1}{\sigma} = \frac{x - \mu}{\sigma}z=σx1=σx−μ
3. 举例
特征“月消费”的均值μ=2000\mu=2000μ=2000,标准差σ=500\sigma=500σ=500:
- 当x=2000x=2000x=2000时,z=(2000−2000)/500=0z=(2000-2000)/500=0z=(2000−2000)/500=0(均值点);
- 当x=3000x=3000x=3000时,z=(3000−2000)/500=2z=(3000-2000)/500=2z=(3000−2000)/500=2(高于均值2个标准差);
- 当x=1000x=1000x=1000时,z=(1000−2000)/500=−2z=(1000-2000)/500=-2z=(1000−2000)/500=−2(低于均值2个标准差)。
4. 适用场景
- 数据近似正态分布(如身高、成绩);
- 存在异常值(标准化对异常值更稳健);
- 后续模型依赖正态分布假设(如线性回归、SVM)。
四、归一化 vs 标准化:怎么选?
| 维度 | 归一化(Min-Max) | 标准化(Z-Score) |
|---|---|---|
| 范围 | 固定在[0,1](或自定义范围) | 无固定范围,通常在[-3,3](正态分布) |
| 异常值影响 | 敏感(极端值会压缩其他数据的范围) | 稳健(异常值影响小,因基于均值和标准差) |
| 数据分布 | 不改变原始分布形状 | 转换为标准正态分布 |
| 适用模型 | 神经网络、推荐系统(需固定输入范围) | 线性回归、聚类、PCA(依赖距离计算) |
一句话总结:
- 若特征有明确边界(如图像像素0-255),用归一化;
- 若数据近似正态分布或有异常值,用标准化。
五、完整代码:两种方法实战对比
我们用三个不同量纲的特征(范围差异100倍),分别用两种方法标准化,可视化对比效果:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# ----------------------
# 1. 生成模拟数据(三个特征,量纲差异大)
# ----------------------
np.random.seed(42) # 固定随机种子
data = {
'Feature1': np.random.randint(0, 1000, 100), # 范围0-1000
'Feature2': np.random.randint(0, 50, 100), # 范围0-50(比Feature1小20倍)
'Feature3': np.random.randint(-100, 100, 100) # 范围-100到100(含负数)
}
df = pd.DataFrame(data)
# ----------------------
# 2. 分别用两种方法标准化
# ----------------------
# 归一化(缩放到[0,1])
minmax_scaler = MinMaxScaler()
df_minmax = pd.DataFrame(
minmax_scaler.fit_transform(df),
columns=df.columns
)
# 标准化(Z-Score)
zscore_scaler = StandardScaler()
df_zscore = pd.DataFrame(
zscore_scaler.fit_transform(df),
columns=df.columns
)
# ----------------------
# 3. 可视化对比(原始数据+两种标准化结果)
# ----------------------
plt.figure(figsize=(18, 12))
# 原始数据分布
for i, col in enumerate(df.columns):
plt.subplot(3, 3, i+1)
plt.hist(df[col], bins=20, color='blue', alpha=0.7)
plt.title(f'原始数据:{col}')
plt.xlabel('值')
plt.ylabel('频数')
# 归一化后分布
for i, col in enumerate(df_minmax.columns):
plt.subplot(3, 3, i+4)
plt.hist(df_minmax[col], bins=20, color='green', alpha=0.7)
plt.title(f'归一化后:{col}')
plt.xlabel('值(0-1)')
plt.ylabel('频数')
# 标准化后分布
for i, col in enumerate(df_zscore.columns):
plt.subplot(3, 3, i+7)
plt.hist(df_zscore[col], bins=20, color='red', alpha=0.7)
plt.title(f'标准化后:{col}')
plt.xlabel('Z-Score(均值0,标准差1)')
plt.ylabel('频数')
plt.tight_layout()
plt.show()
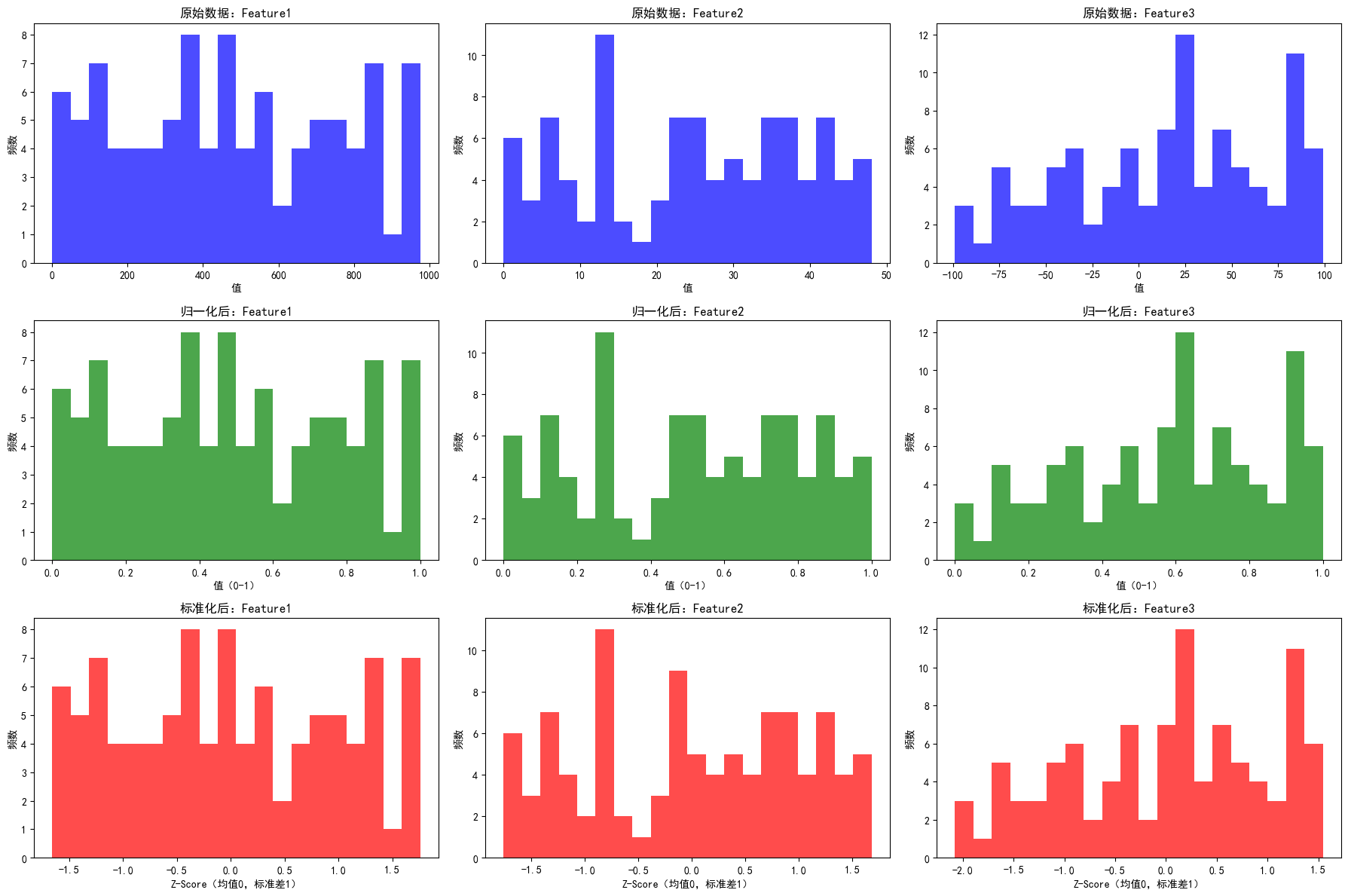
六、代码结果解读
运行代码后,你会看到三个明显变化:
- 原始数据:三个特征的x轴范围差异巨大(Feature1是0-1000,Feature2是0-50),分布形状相似但尺度不同;
- 归一化后:所有特征的x轴都压缩到[0,1],分布形状不变,方便直接比较;
- 标准化后:所有特征的x轴集中在[-2,2],均值附近数据最多,符合标准正态分布特征。
这就是标准化的魔力——无论原始数据差异多大,都能被“拉平”到同一尺度,让模型不再“偏心”。
七、避坑指南
训练集和测试集的一致性:
必须用训练集的参数(均值、标准差、最大最小值)去标准化测试集,否则会导致数据泄露(测试集的信息影响模型)。
正确做法:# 用训练集拟合scaler scaler.fit(X_train) # 用同一scaler转换训练集和测试集 X_train_scaled = scaler.transform(X_train) X_test_scaled = scaler.transform(X_test)异常值处理优先:
归一化对异常值敏感(比如Feature1中突然出现10000的异常值,会把其他数据压缩到0附近),建议先处理异常值再标准化。
总结
数据标准化是机器学习的“预处理刚需”,核心记住两点:
- 归一化适合有边界、无异常值的数据,输出范围固定;
- 标准化适合近似正态分布、有异常值的数据,输出服从标准正态分布。
掌握这两种方法,能让你的模型预测精度提升一个档次~ 你平时更常用哪种方法?评论区聊聊!