这篇文章将通过一个接口文档知识库示例,带你了解如何在 Cursor 中通过 Mcp Server 调用 Dify 平台配置的工作流。
1. 准备工作
需要准备文本生成模型、向量模型、Rerank 模型(可选),这些都可以在 阿里云百炼平台 申请免费使用额度。
准备知识库文档,我这里使用 Dify 维护知识库API 文档进行展示。
已熟悉使用 Cursor 。
我使用的文本生成模型为:qwen-plus-2025-04-28,向量模型:text-embedding-v4,rerank 模型:gte-rerank-v2。
1.1 如何将在线的 API 文档一键转换成 markdown 格式?
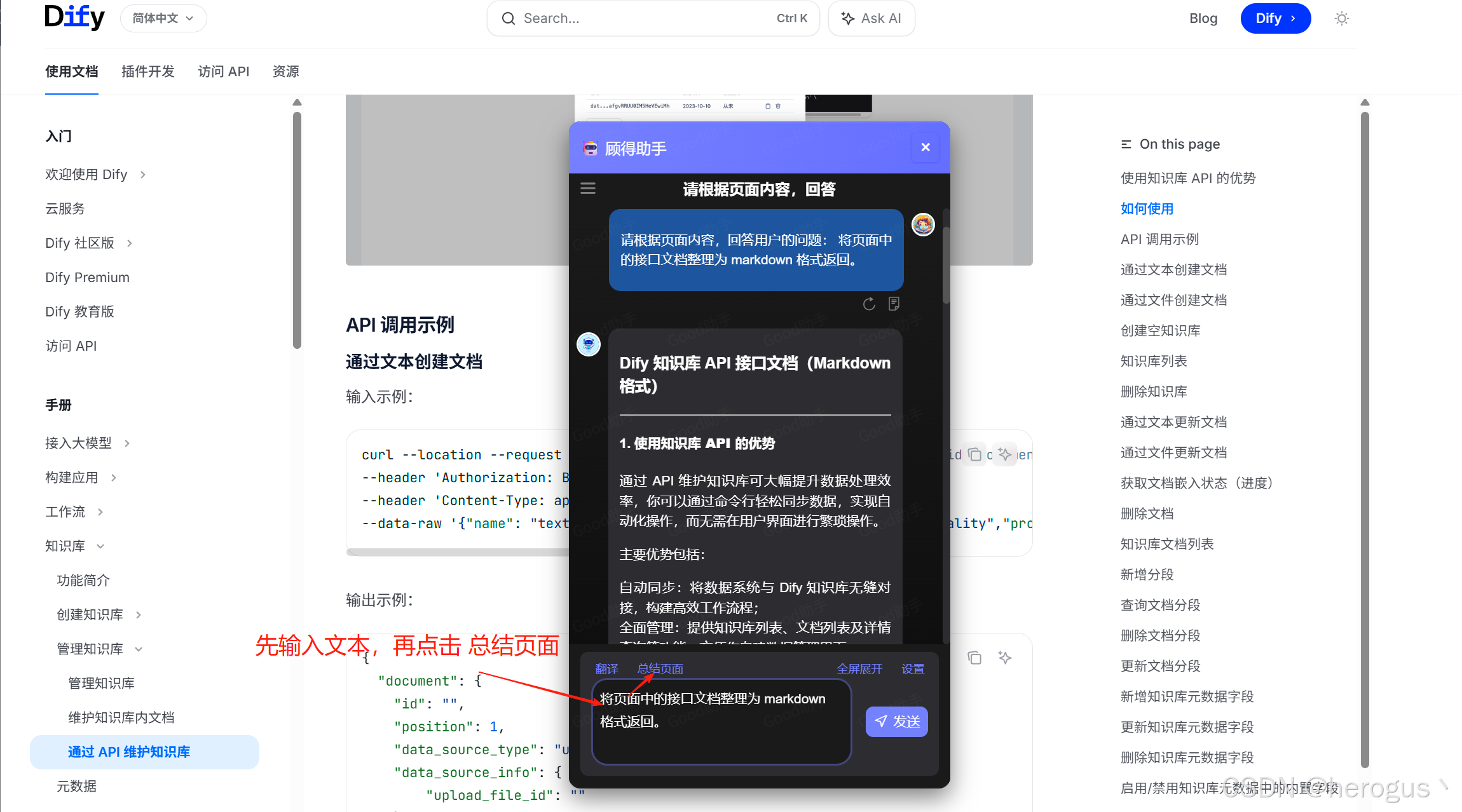
你可以通过我开发的 ' 顾得助手 ' (chrome 扩展程序)一键将网页内容转换为任意格式文档。该扩展程序已上架 chrome 应用商店,搜索 顾得助手 即可获得,也可以通过 github 下载体验最新功能,地址:https://github.com/herogus/good_ai_chrome_extension。我的这篇博客有详细介绍,感兴趣的可以点击阅读。
下图是简单的请求示例:
2. 知识库工作流搭建
2. 安装 Dify
windows 下需要安装 Docker destop,安装教程可参考我的博客:
# 下载代码
git clone https://github.com/langgenius/dify.git
# 进入docker目录
cd docker
# 使用 docker compose 部署
cp .env.example .env
docker compose up -d也可以体验官方提供的在线免费版(需科学上网):https://cloud.dify.ai/apps
2.2 知识库搭建
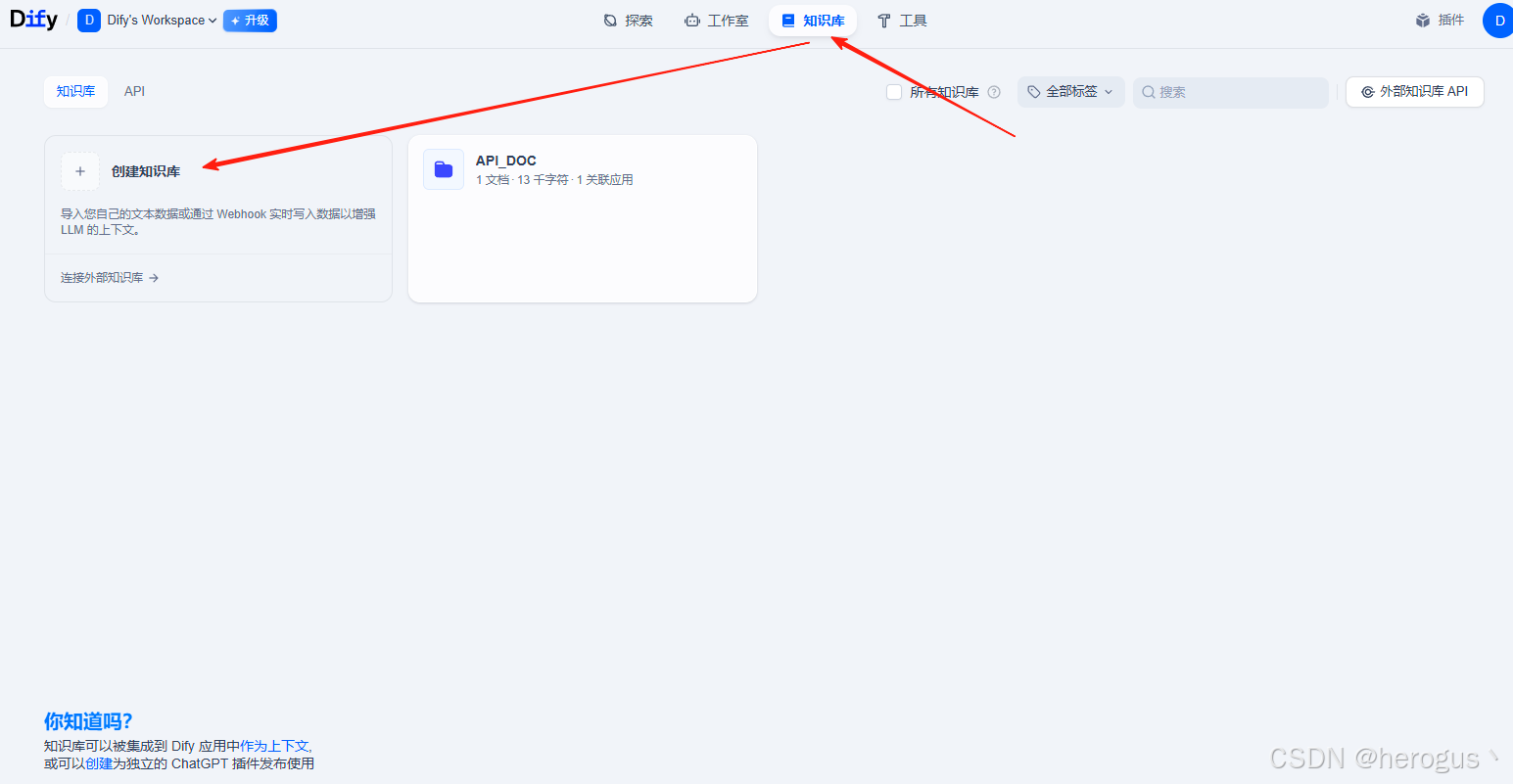
2.2.1 创建知识库
进入 Dify 首页 》 知识库 》 创建知识库 》 创建一个新的知识库
2.2.2 文本分段设置
上传文件后会进入到文本分割设置界面,点击‘预览块’支持查看分割详情。
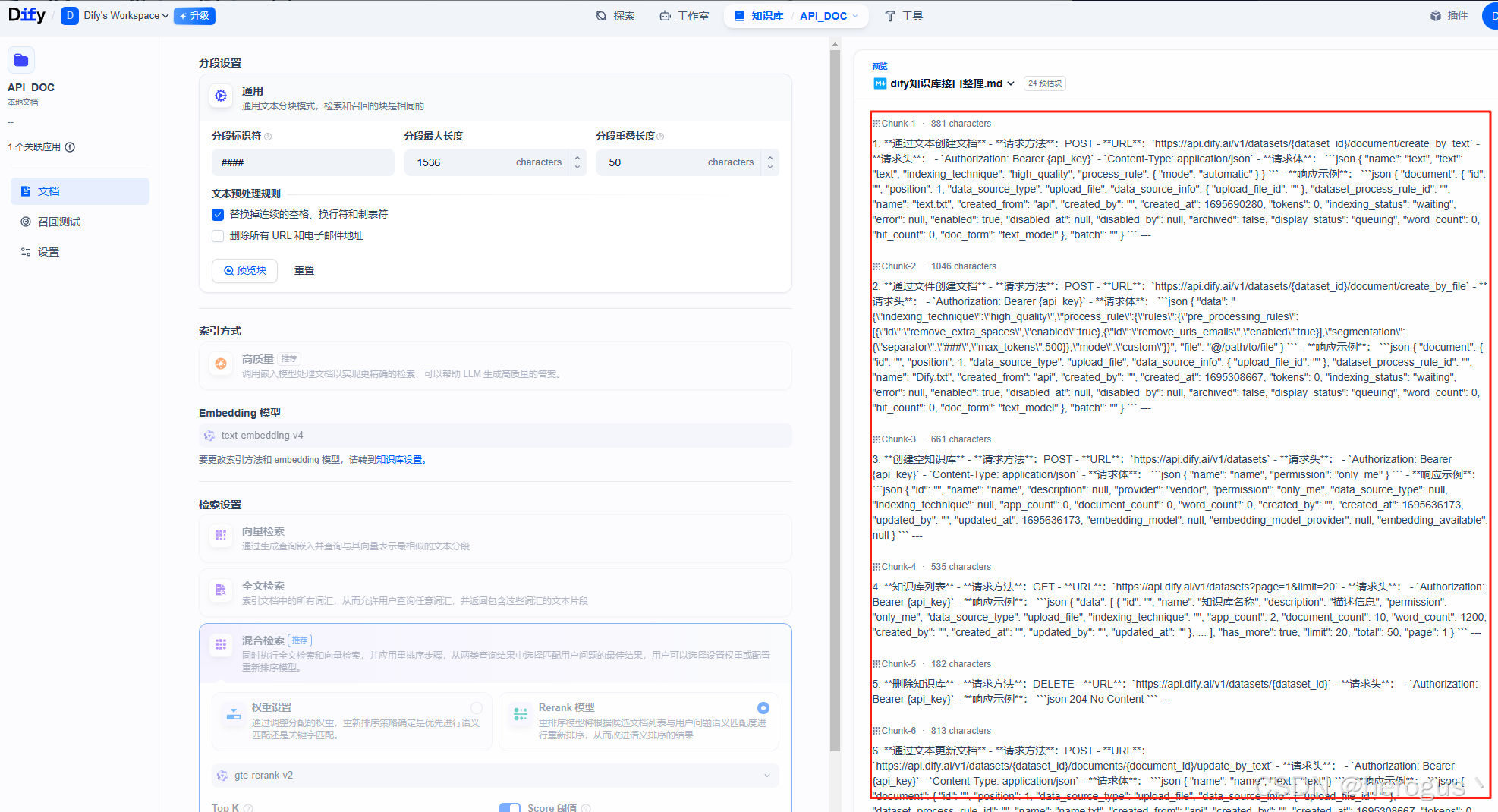
分段设置:用于设置 ' 文本分块 ' 规则,文本文档可以按照 \n\n,\n (段落、行) , markdown 文档按照标题分块 ##,###,####。
Embedding 模型设置:这里配置向量模型,用于资源向量化。
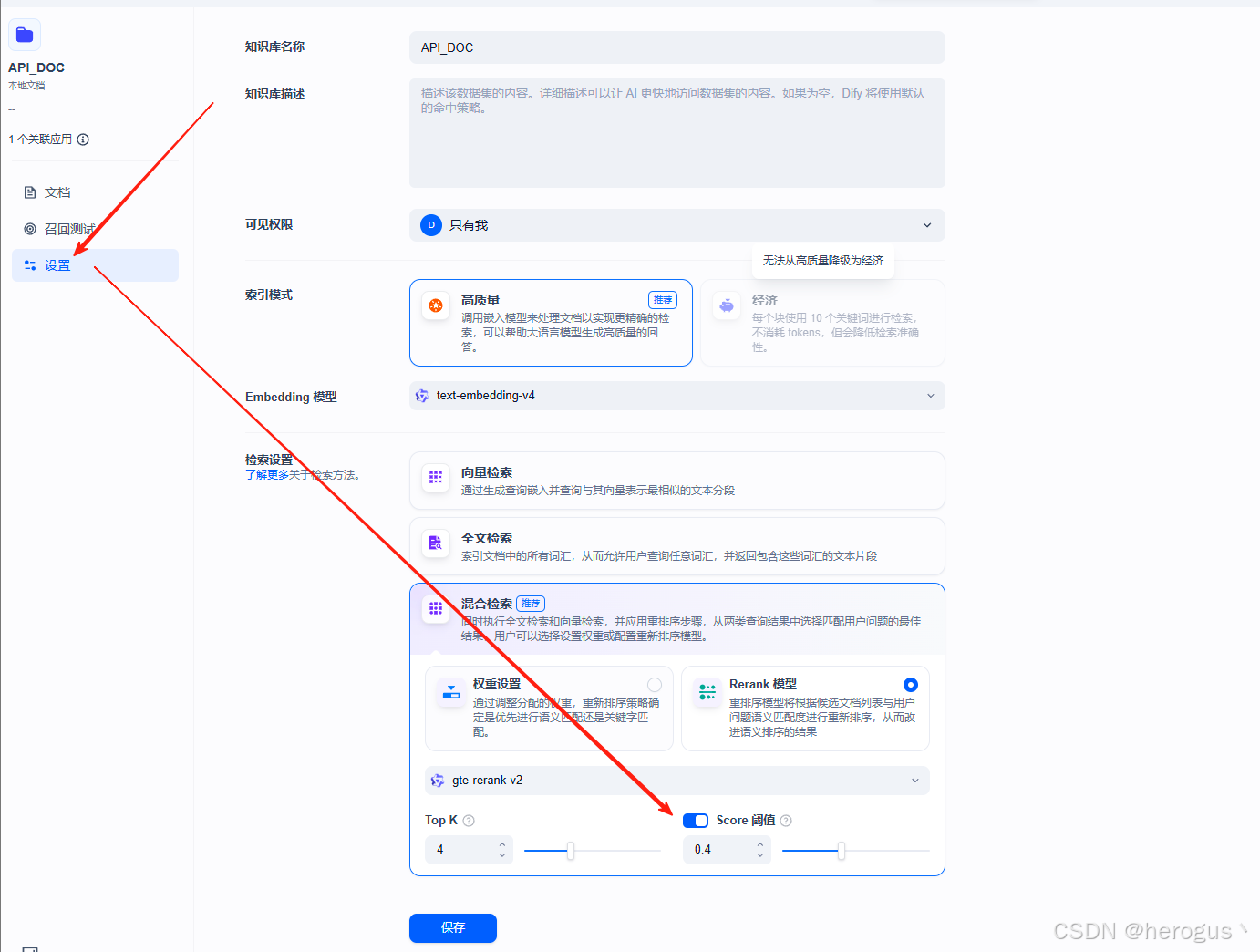
检索设置,支持以下几种检索方式:
向量检索:基于向量相似度检索方式。
全文索引:基于关键词倒排索引,类似 ES。
混合索引:同时执行全文检索和向量检索,最后通过 Rerank 模型对结果进行重排序。Top K 表示返回的结果数量(相似度得分最高的 K 个值)。
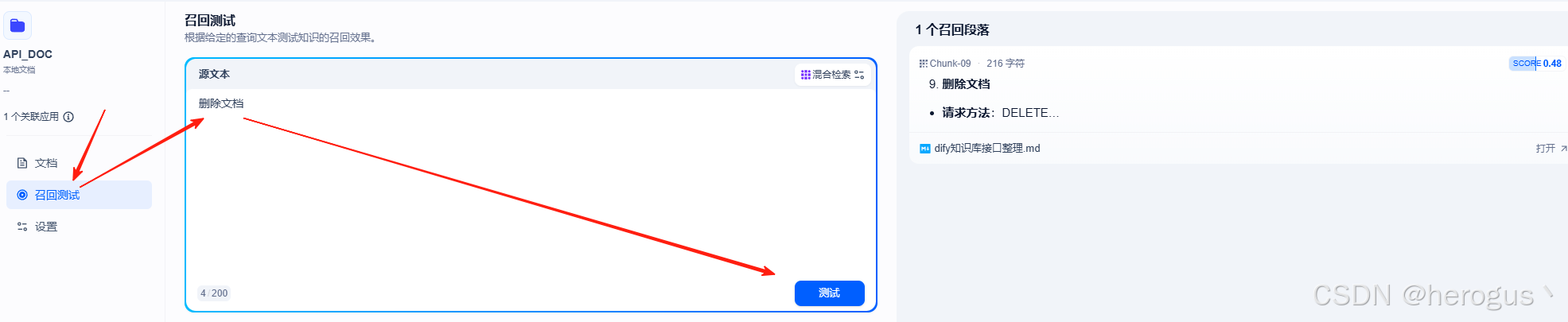
注:配置完之后,可以在 召回测试 中测试效果,如果效果不好,可以尝试调整 相似度阈值 (值越大,精确度越高)。
2.2.3 搭建知识库工作流
你可以在 ‘ 探索 ’ 模块使用已有的模板创建工作流或者在 ' 工作室 ' 模块创建一个新的工作流。
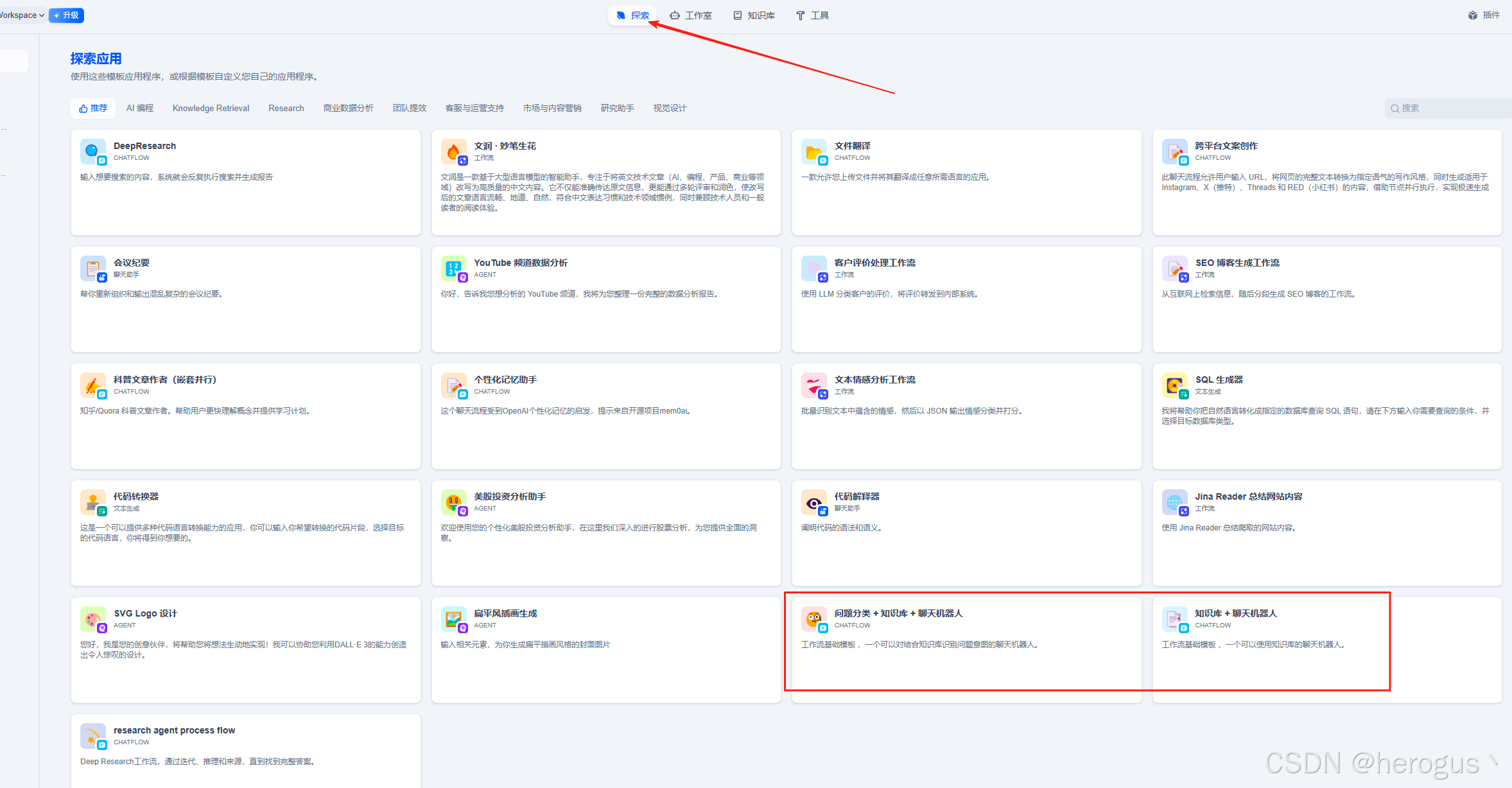
我这边使用最简单的配置,根据请求内容直接进行知识库检索,然后通过大模型总结后返回,你可以在 '知识检索' 之前,增加一个 '问题分类' 流程,让模型根据不同的输入内容,索引到不同的知识库。
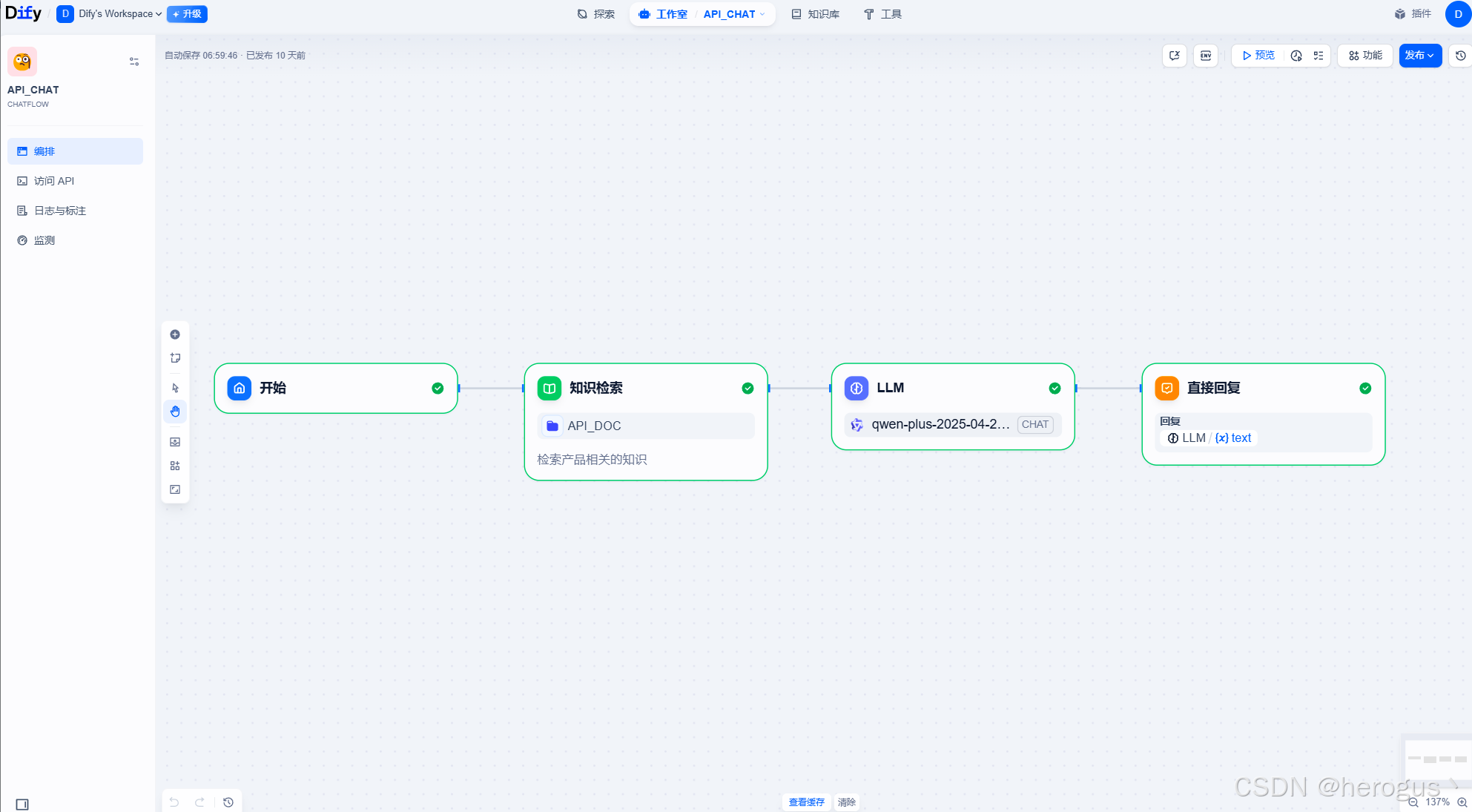
配置好后,点击 发布 按钮,发布自己的应用。
3. 配置MCP_SERVER
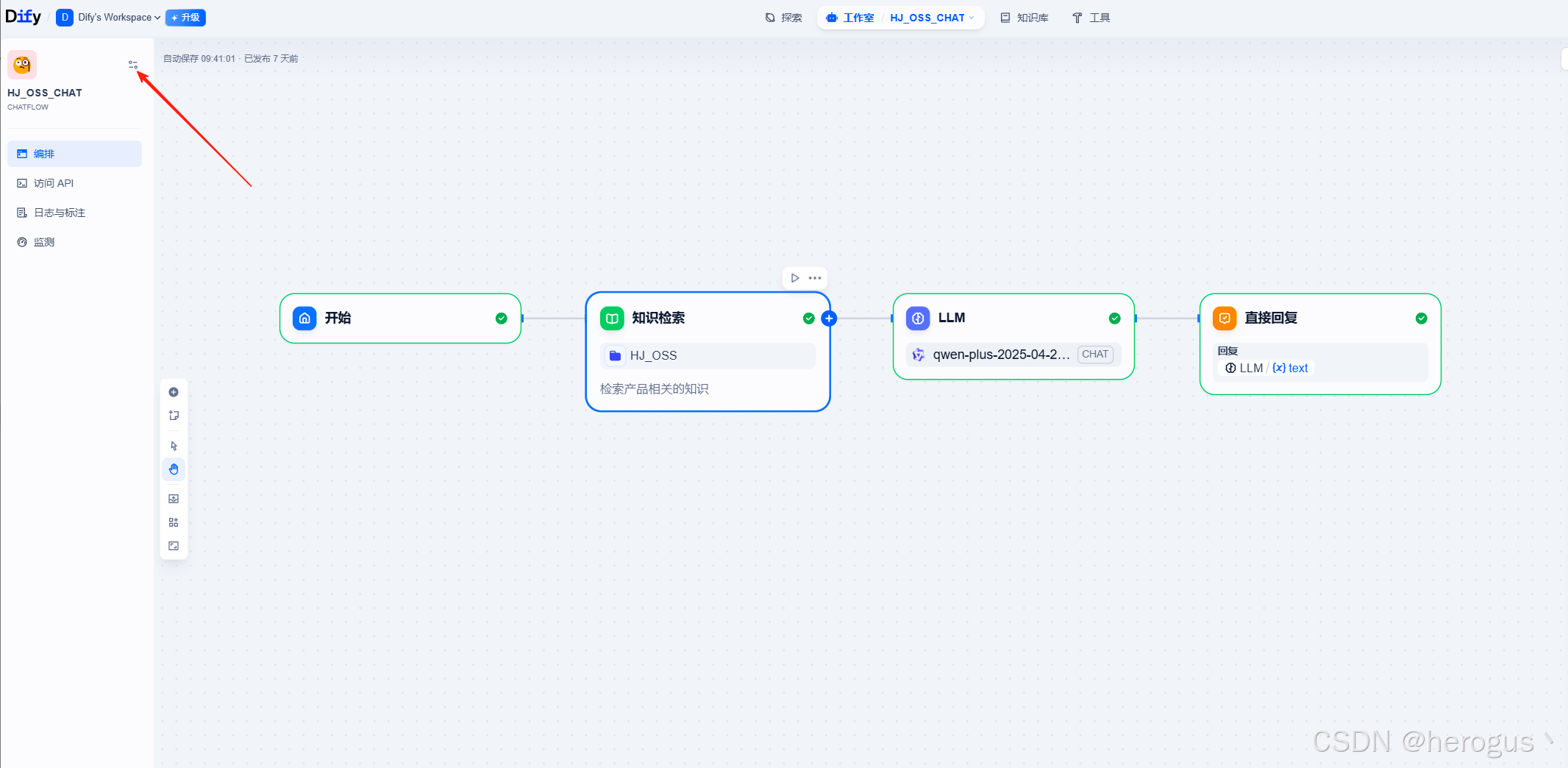
3.1 官方提供的 MCP 服务
3.1.1 入口
可以在 ' 编辑描述 ' 中说明工作流的功能以及调用说明。
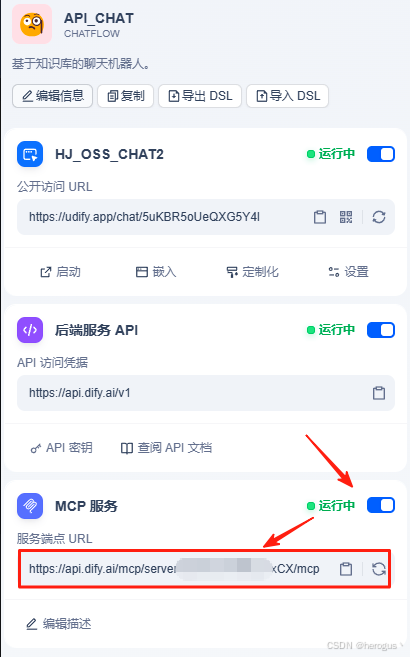
3.1.2 cursor 配置
进入 cursor ,编辑 mcp.json,其中 url 为上图 ‘ 服务端点 URL ’。
{
"mcpServers": {
"OnlineDifyServer": {
"url": "https://api.dify.ai/mcp/server/QfH9DT07Mf33kxCX/mcp"
}
}3.2 自己开发一个 MCP Server
3.2.1 python 源码
当然我喜欢自己自足,下面是我用 python 开发的一个调用 Dify 工作流(应用)的 Mcp Server 。
里面的 BASE_URL 是固定的,不同的工作流(应用)对应不同的 API_KEY。
import os
import uuid
from typing import Dict, Any, Optional
import httpx
from dotenv import load_dotenv
from mcp.server.fastmcp import FastMCP
# 定义一个 FastMCp 实例
mcp = FastMCP("DIFY_MCP_SERVER")
# DIFY API配置信息
load_dotenv()
BASE_URL = "https://api.dify.ai/v1/chat-messages"
API_KEY = os.getenv("API_KEY")
async def query_knowledge(query: str) -> Optional[Dict[str, Any]]:
"""查询知识库信息"""
if not API_KEY:
return {"error": "API_KEY 未配置或为空"}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
data = {
"query": query,
"user": str(uuid.uuid4()),
"inputs": {},
"response_mode": "blocking",
"conversation_id": "",
}
try:
async with httpx.AsyncClient(timeout=120.0) as client:
response = await client.post(BASE_URL, headers=headers, json=data)
response.raise_for_status()
print(f"Response status: {response.status_code}")
print(f"Response text: {response.text}")
return response.json()
except httpx.HTTPError as e:
return {"error": f"查询知识库请求失败:{e}"}
except Exception as e:
return {"error": f"未知错误:{e}"}
def format_response_data(response_data: Dict[str, Any]) -> str:
"""格式化 Dify 返回数据"""
event = response_data.get("event", "")
if "error" == event:
return str(response_data["message"])
return response_data.get("answer", "")
@mcp.tool()
async def query_dify_interface_info(query: str) -> str:
"""
用于查询 Dify 维护知识库接口文档
参数:
- query: 查询内容,str格式
- 请求示例:
1、通过文本创建文档
2、通过文件创建文档
3、创建空知识库
4、知识库列表
...
"""
response_data = await query_knowledge(query)
return format_response_data(response_data)
if __name__ == "__main__":
# 运行 MCP 服务器,默认传输协议 stdio
mcp.run(transport="stdio")
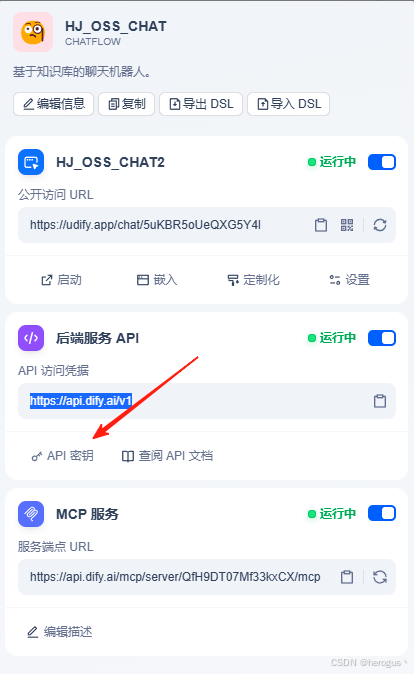
请求密钥在这里获取:
3.2.2 cursor 配置
{
"mcpServers": {
"LocalDifyServer": {
"command": "uv",
"args": [
"--directory",
"D:\\workspace\\project\\python\\2025\\good-agent-fastapi\\mcps",
"run",
"dify_mcp_server.py"
],
"env": {
"API_KEY": "填写服务密钥"
}
}
}
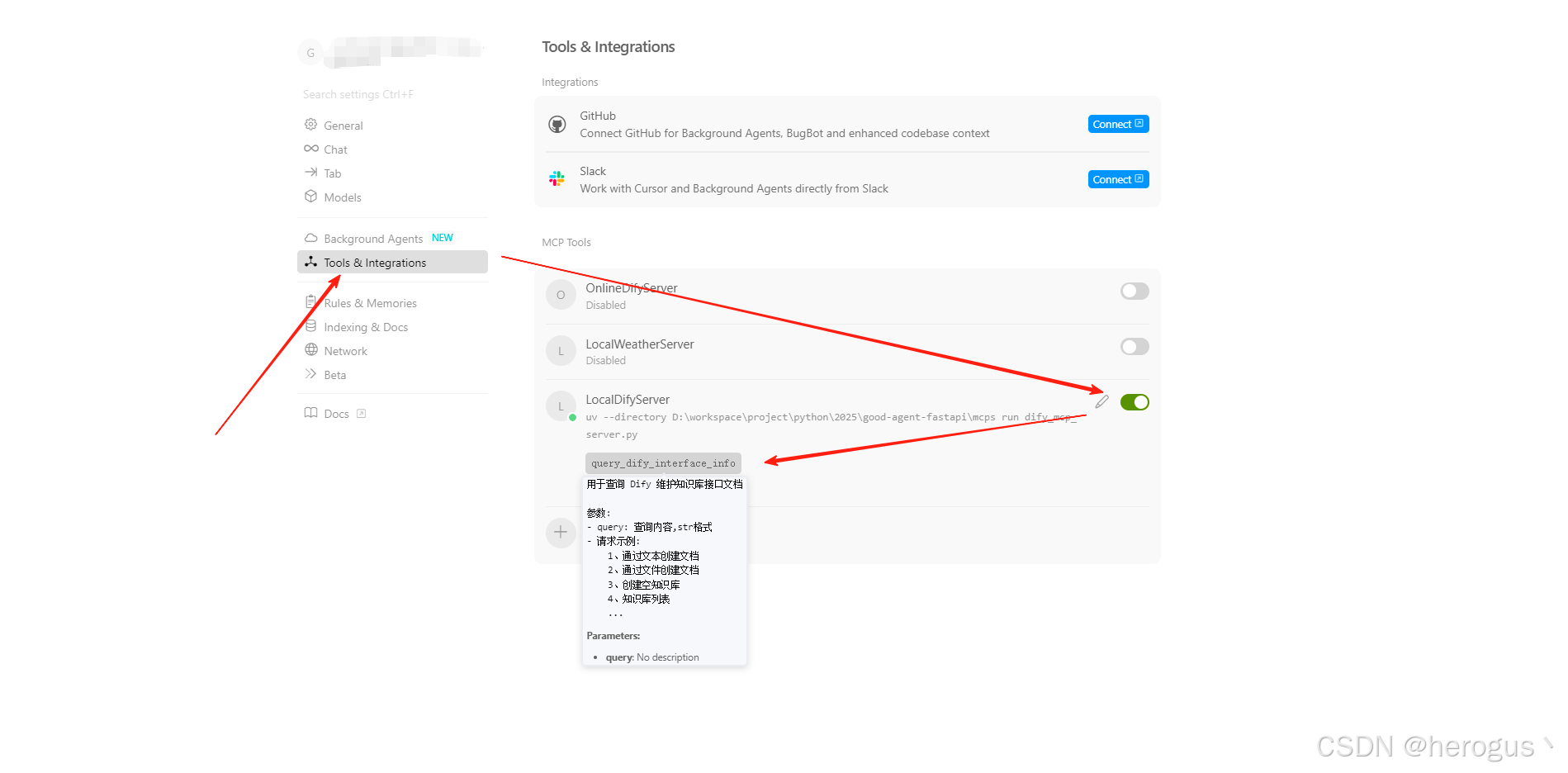
}4. 验证Mcp Server是否加载
Cursor 设置界面,出现如下信息说明工具加载正常。
5. 执行效果
问:查询DIFY 创建空知识库接口文档
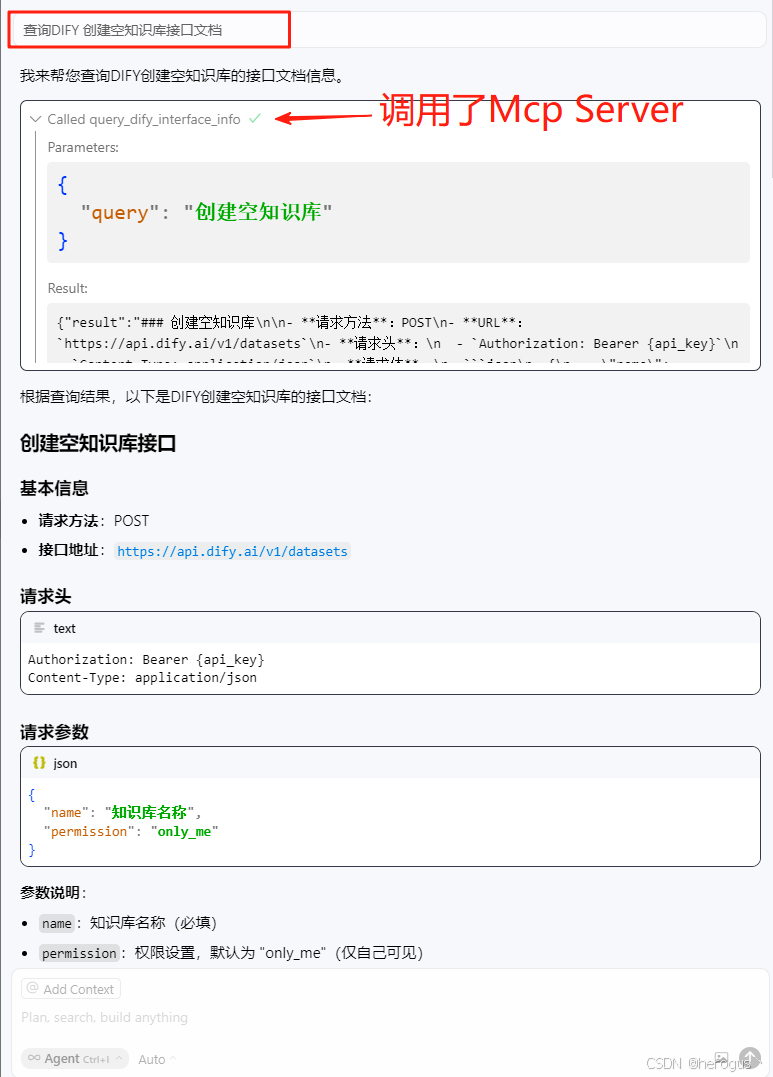
6. 拓展
6.1 如何提高查询匹配度?
在使用过程中,可能口语提问往往不能查询到自己想要的结果,可以尝试在每个文本分段中,增加常见问题段落以提高自然提问命中率,比如(以 ' 通过文本创建文档 ' 接口为例):
#### 💬 常见用户提问
- 如何通过一段文本添加一个知识文档?
- 可以用 API 上传文字内容吗?
- 不上传文件,怎么创建文档?
- `create_by_text` 是什么用的?