目录
昨日总结
- redis高级篇(分布式缓存完结),JVM底层原理
- cv(停滞中)
- 背诵小林coding--Java并发面试篇(1/5)
- 代码随想录——前k个高频元素,滑动窗口最大值(单调队列解法另一种实现法)
今日计划
- redis高级篇(多级缓存),JVM底层原理
- cv(停滞中)
- 背诵小林coding--Java并发面试篇(2/5)
- 代码随想录——二叉树的递归遍历,非递归遍历,广度优先搜索
算法——前k个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2 输出: [1,2]
示例 2:
输入: nums = [1], k = 1 输出: [1]
//在此基础上的优化,可以用小顶堆来实现对hashmap的排序。小顶堆中剩余的元素,即是前k个频率最高的元素
class Solution {
public int[] topKFrequent(int[] nums, int k) {
//用hashmap存储元素和元素出现的次数
HashMap<Integer, Integer> map = new HashMap<>();
for(int num : nums) {
//可以用一段代码实现,如下
// map.put(num, map.getOrDefault(num, 0) + 1);
if(map.containsKey(num)) {
map.put(num,map.get(num) + 1);
}else{
map.put(num,1);
}
}
// 将 HashMap 的键值对转换为 List
List<Map.Entry<Integer, Integer>> list = new ArrayList<>(map.entrySet());
//可以用stream流实现排序
// 使用 Stream 流实现排序
// List<Map.Entry<Integer, Integer>> sortedList = list.stream()
// // 按照 Map.Entry 的值进行降序排序
// .sorted(Map.Entry.<Integer, Integer>comparingByValue().reversed())
// // 将排序后的元素收集到一个新的列表中
// .collect(Collectors.toList());
// 使用 Collections.sort() 方法对值进行排序
// Collections.sort(list, new Comparator<Map.Entry<Integer, Integer>>() {
// @Override
// public int compare(Map.Entry<Integer, Integer> o1, Map.Entry<Integer, Integer> o2) {
// return o2.getValue().compareTo(o1.getValue());
// }
// });
//最简洁的是使用Lambda表达式实现
Collections.sort(list, (o1, o2) -> o2.getValue().compareTo(o1.getValue()));
List<Integer> resp = new ArrayList<>();
int num = 0;
for (Map.Entry<Integer, Integer> entry : list) {
if(num == k)
break;
resp.add(entry.getKey());
num++;
}
return resp.stream().mapToInt(Integer::intValue).toArray();
}
}算法——滑动窗口最大值(单调队列解法另一种实现法)
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回 滑动窗口中的最大值 。
示例 :
输入:nums = [1,3,-1,-3,5,3,6,7], k = 3 输出:[3,3,5,5,6,7]
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
int len = nums.length;
int[] res = new int[len - k + 1];
Deque<Integer> queue = new ArrayDeque<Integer>();
//先将队列填满,将数组里面的前k个元素入队,同是保证他是一个单调队列
for (int i = 0; i < k; i++) {
//移除最大元素之前的元素,保证队头是最大元素
while (!queue.isEmpty() && nums[i] > queue.peekLast()) {
queue.pollLast();
}
queue.offerLast(nums[i]);
}
//记录目前最大元素
res[0] = queue.peekFirst();
for (int i = k, j = 1; i < len; i++, j++) {
//移除队列最大的元素
if (!queue.isEmpty() && nums[i - k] == queue.peekFirst()) {
queue.pollFirst();
}
//移除最大元素之前的元素,保证队头是最大元素
while (!queue.isEmpty() && nums[i] > queue.peekLast()) {
queue.pollLast();
}
queue.offerLast(nums[i]);
//记录数组中最大元素
res[j] = queue.peekFirst();
}
return res;
}
}JVM
- 栈的存取速度大于堆
- 栈中存取是的对象的引用。例如MyObject obj = new MyObejct(),这里的obj实际上是一个存储在栈上的引用,指向堆中世纪的对象的实例
Redis分片集群的散列插槽结构
Redis会把每一个master节点映射到0~16383共16384个插槽(hashslot)上,查看集群信息时就能看到。
为什么要引入插槽,用它来绑定数据的key?
当节点的master宕机时,引入插槽的集群信息就可以直接转移到别的master上,不会因此丢失信息。
redis如何判断某个key在哪个master节点中?
首先将16384个插槽分配给不同的maser节点,根据key的有效部分计算哈希值,对16384取余,余数作为插槽值。
Redis分片集群的伸缩
新建节点操作,同时分配插槽(用的时候直接查命令,知道有这个方法就行)
Redis分片集群的故障转移
Reids集群不需要哨兵,他可以自动实现主从集群的切换
也可以手动实现数据迁移,实现主从集群的切换(用的时候直接查命令,知道有这个方法就行)
RedisTemplate分片集群的访问
redistemplate底层基于lettuce实现了分片集群的支持,使用步骤与哨兵模式基本一致:
- 引入redis的starter依赖
- 配置分片集群地址(与哨兵模式略有差异)
- 配置读写分离
昨日八股答案
JVM的内存模型架构
一张图可以清晰的展示出整体架构,大概的流程就是:
- 当java程序启动时,字节码文件被加载到类加载器中
- 经过类加载器的链接和初始化操作,将加载的信息传到运行时数据区
- 加载的类信息被传送到方法区,JVM会创建线程分配其空间来执行main方法,过程中需要用到java栈,程序计数器等帮助,同时,类创建的对象分配在堆中
- 程序结束后,JVM会销毁线程,同时释放资源。
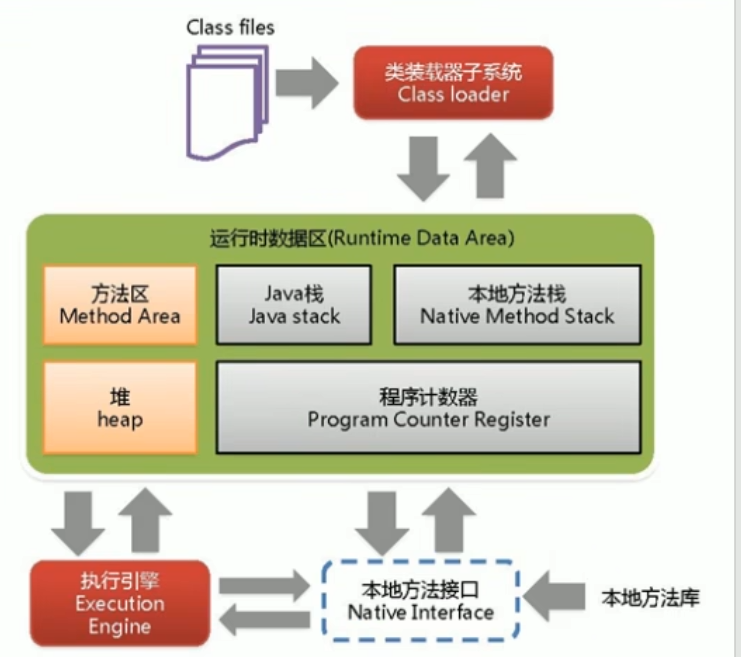
JVM中堆栈的区别
- 栈用于存储局部变量,方法调用的参数,方法返回地址等一些临时的数据,每一个方法被调用,一个栈帧就会在栈中创建;堆用于存储对象的实例。
- 生命周期不同。当一个方法调用结束时,其对应的栈帧就会销毁;堆中的对象生命周期不确定,需要在检测对象不再被引用时才能被回收。
- 栈基于先进后出原则,操作简单,运行速度快;堆需要对象的分配和回收,这些机制导致其速度较慢
- 栈的空间大小较小;堆的大
- 栈中的数据对线程是私有的;堆中的数据对线程是共享的。
JVM方法区中方法的执行过程
- JVM会根据方法的符号引用(逻辑)找到方法的物理地址
- 在执行方法前,需要分配一个新的栈帧,用于存储局部变、操作数栈、方法出口等信息
- 之后开始执行方法
- 执行完毕后,返回结果给调用者,清理栈帧。
程序计数器的作用,为什么是私有的
记录程序运行到的位置,方便回调后找到执行的位置。
每个线程都有自己的程序计数器。每个线程执行的程序指令不一样,所以记录的位置也不同,需要自己维护一个程序计数器。
今日八股
引用类型有哪些?有什么区别?
内存泄漏和内存溢出的理解
JVM内存结构溢出的情况
总结
写代码题耗了好长的时间,还是要多练习,不过收获很大。
