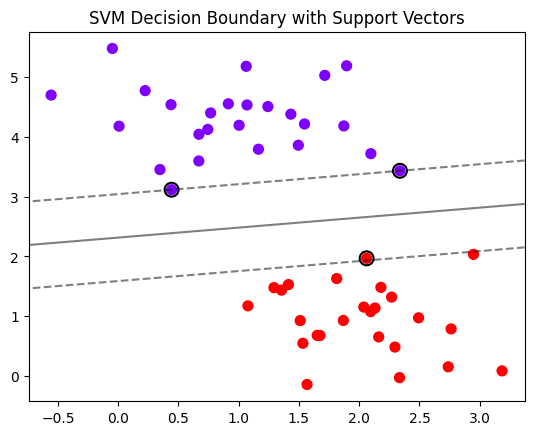
概述:现在就只知道这个svm可以画出决策边界,对数据的划分。简单举例就是:好的和坏的数据分开,中间的再验证
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
# 1. 生成数据
X, y = make_blobs(
n_samples=50, # 50个样本
centers=2, # 2个类别(二分类)
random_state=0, # 固定随机种子
cluster_std=0.6 # 控制数据点的分散程度
) # X是样本,y是标签
# 2. 训练线性SVM
model = SVC(kernel='linear').fit(X, y)
# 3. 绘制数据点
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="rainbow") # 按类别着色
# 4. 绘制决策边界和支持向量间隔
ax = plt.gca() # 获取当前坐标轴
xlim = ax.get_xlim() # 获取x轴范围
ylim = ax.get_ylim() # 获取y轴范围
# 生成网格点(用于绘制决策边界)
xx, yy = np.meshgrid(
np.linspace(xlim[0], xlim[1], 50), # x轴50个点
np.linspace(ylim[0], ylim[1], 50) # y轴50个点
) # 分成50分画网格
# 计算决策函数值(SVM的间隔)
Z = model.decision_function(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape) # 计算决策值并重塑为网格矩阵
# 绘制决策边界(黑色实线)和间隔边界(黑色虚线)
ax.contour(
xx, yy, Z,
colors='k',
levels=[-1, 0, 1], # 0是决策边界,±1是支持向量间隔
alpha=0.5, # 透明度
linestyles=['--', '-', '--'] # 虚线-实线-虚线
)
# 5. 标记支持向量(SVM的关键数据点)
ax.scatter(
model.support_vectors_[:, 0], # 支持向量的x坐标
model.support_vectors_[:, 1], # 支持向量的y坐标
s=100, # 点的大小
facecolors='none', # 空心点
edgecolors='k', # 黑色边框
linewidths=1.5 # 边框宽度
)
plt.title("SVM Decision Boundary with Support Vectors")
plt.show()
print(Z)