
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#,Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用,熟悉DICOM医学影像及DICOM协议,业余时间自学JavaScript,Vue,qt,python等,具备多种混合语言开发能力。撰写博客分享知识,致力于帮助编程爱好者共同进步。欢迎关注、交流及合作,提供技术支持与解决方案。\n技术合作请加本人wx(注明来自csdn):xt20160813
使用 PyTorch 实现简单 CNN 分类医学影像(胸部 X 光)
本文基于 Kaggle 胸部 X 光图像数据集,实现一个简单 CNN 模型,用于区分正常和肺炎 X 光图像。我们将涵盖数据预处理、模型构建、训练、评估和结果可视化,主要内容包括: 数据集:包含5,216张训练图像(1,341正常,3,875肺炎),存在类别不平衡问题。 预处理: 图像灰度化并调整为224×224 应用随机翻转、旋转等数据增强 使用标准化处理 模型架构: 3个卷积层(带ReLU和最大池化) 2个全连接层 适合二分类任务 实现特点: 详细注释的代码 包含数据可视化(Chart.js图表) 考虑计算资源优化 适用性:适合初学者和进阶开发者。
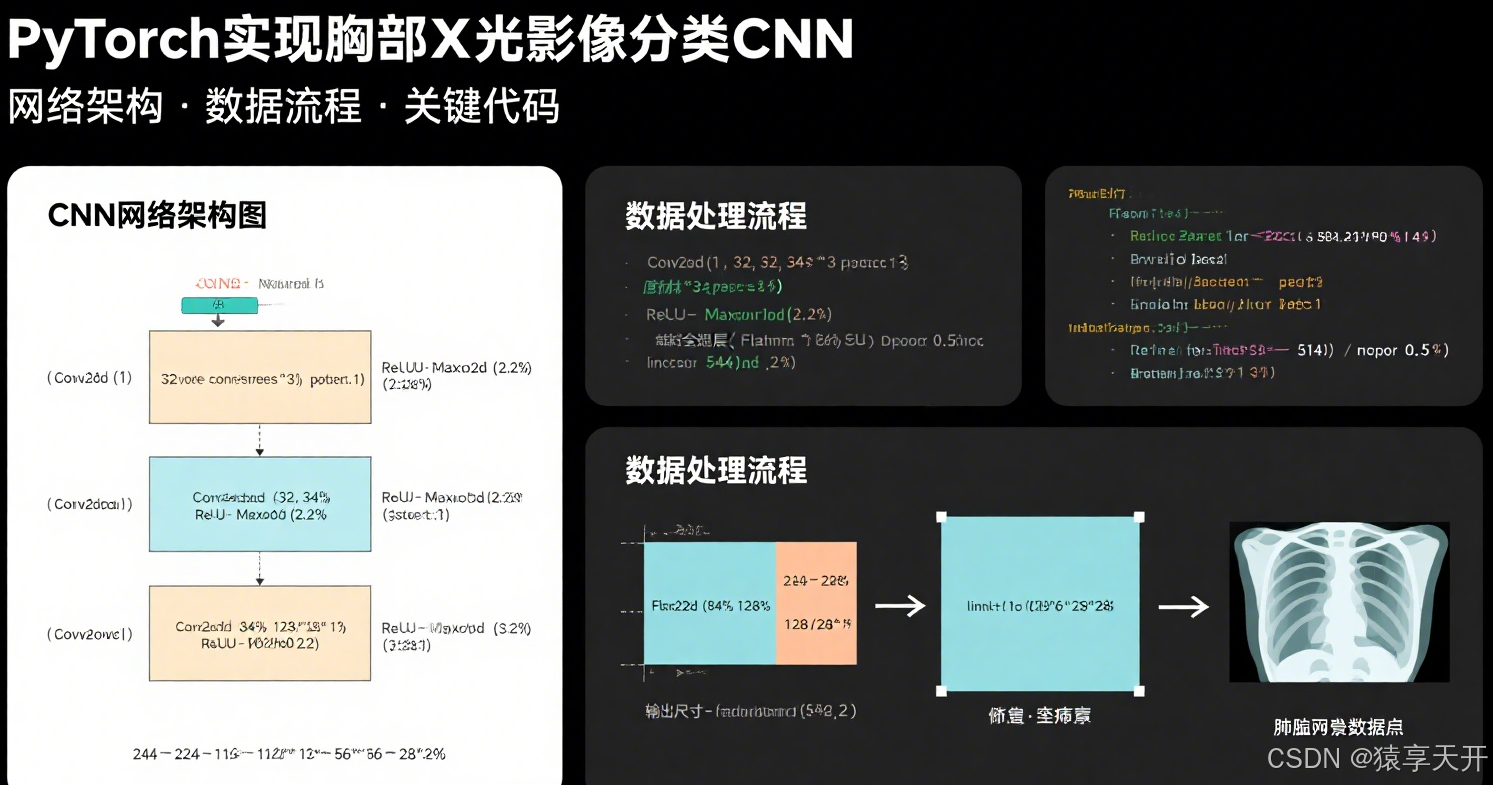
一、任务概述
- 数据集:Kaggle 胸部 X 光图像数据集,包含约 5,216 张训练图像(1,341 正常,3,875 肺炎)。
- 任务:二分类,预测 X 光图像是否为肺炎(0: 正常,1: 肺炎)。
- 模型:简单 CNN,包含 3 个卷积层(带 ReLU 和最大池化)+ 2 个全连接层。
- 环境:PyTorch, 推荐 GPU 加速。
- 挑战:
- 类不平衡:肺炎样本占主导。
- 图像噪声:X 光图像质量差异。
- 计算资源:需优化模型以适应有限硬件。
二、实现步骤
2.1 环境设置
安装必要的 Python 库:
pip install torch torchvision opencv-python pandas numpy matplotlib seaborn
2.2 数据预处理
CNN 直接处理原始图像,无需手动特征提取。我们使用 torchvision 的数据增强和标准化来提高模型鲁棒性。
import os
import cv2
import numpy as np
from glob import glob
from sklearn.model_selection import train_test_split
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
class ChestXRayDataset(Dataset):
"""
胸部 X 光图像数据集
"""
def __init__(self, image_paths, labels, transform=None):
"""
初始化数据集
:param image_paths: 图像路径列表
:param labels: 标签列表 (0: 正常, 1: 肺炎)
:param transform: 数据增强变换
"""
self.image_paths = image_paths
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
# 读取灰度图像
img = cv2.imread(self.image_paths[idx], cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, (224, 224)) # 调整为 224x224
img = img[:, :, np.newaxis] # 增加通道维度 [224, 224, 1]
if self.transform:
img = self.transform(img)
label = self.labels[idx]
return img, label
# 数据增强和标准化
transform = transforms.Compose([
transforms.ToTensor(), # 转换为张量
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转
transforms.RandomRotation(10), # 随机旋转 ±10 度
transforms.Normalize(mean=[0.5], std=[0.5]) # 灰度图像标准化
])
# 加载数据
data_dir = 'chest_xray/train' # 替换为实际 Kaggle 数据集路径
normal_paths = glob(os.path.join(data_dir, 'NORMAL', '*.jpeg'))
pneumonia_paths = glob(os.path.join(data_dir, 'PNEUMONIA', '*.jpeg'))
image_paths = normal_paths + pneumonia_paths
labels = [0] * len(normal_paths) + [1] * len(pneumonia_paths)
# 划分训练集和测试集
train_paths, test_paths, train_labels, test_labels = train_test_split(
image_paths, labels, test_size=0.2, random_state=42, stratify=labels
)
# 创建数据集和数据加载器
train_dataset = ChestXRayDataset(train_paths, train_labels, transform=transform)
test_dataset = ChestXRayDataset(test_paths, test_labels, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32)
# 数据集统计
print(f'训练集样本数: {
len(train_dataset)}, 测试集样本数: {
len(test_dataset)}')
print(f'正常样本: {
sum(labels == 0)}, 肺炎样本: {
sum(labels == 1)}')
数据预处理流程的文本描述:
- 输入:X 光图像(JPEG 格式,灰度)。
- 处理:
- 读取图像,转换为灰度。
- 调整尺寸至 224x224。
- 增加通道维度,形状为 [224, 224, 1]。
- 数据增强:随机翻转、旋转,标准化(均值 0.5,标准差 0.5)。
- 输出:张量形式的图像和标签,送入 DataLoader 分批处理。
- 箭头:从图像文件到张量,标注变换步骤(Resize → Transform → Tensor)。
数据集分布可视化:
以下 图表展示训练集和测试集的类别分布。
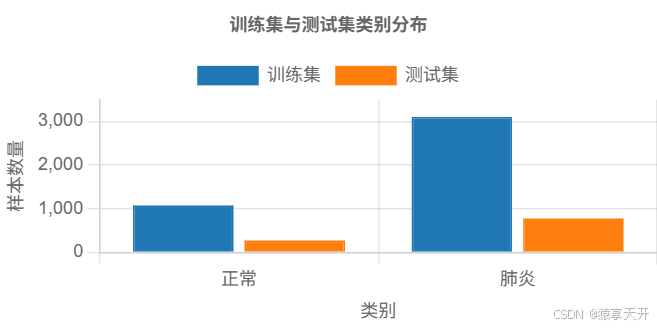
{
"type": "bar",
"data": {
"labels": ["正常", "肺炎"],
"datasets": [
{
"label": "训练集",
"data": [1072, 3100], // 假设 80% 训练集比例
"backgroundColor": "#1f77b4",
"borderColor": "#1f77b4",
"borderWidth": 1
},
{
"label": "测试集",
"data": [269, 775], // 假设 20% 测试集比例
"backgroundColor": "#ff7f0e",
"borderColor": "#ff7f0e",
"borderWidth": 1
}
]
},
"options": {
"scales": {
"y": {
"beginAtZero": true,
"title": {
"display": true,
"text": "样本数量"
}
},
"x": {
"title": {
"display": true,
"text": "类别"
}
}
},
"plugins": {
"title": {
"display": true,
"text": "训练集与测试集类别分布"
}
}
}
}
2.3 定义简单 CNN 模型
设计一个简单 CNN,包含 3 个卷积层(带 ReLU 和最大池化)+ 2 个全连接层,适合二分类任务。
import torch.nn as nn
class SimpleCNN(nn.Module):
"""
简单 CNN 模型,用于 X 光图像二分类
"""
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv_layers = nn.Sequential(
# 卷积层 1: 输入 [1, 224, 224] -> 输出 [16, 112, 112]
nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
# 卷积层 2: 输入 [16, 112, 112] -> 输出 [32, 56, 56]
nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
# 卷积层 3: 输入 [32, 56, 56] -> 输出 [64, 28, 28]
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc_layers = nn.Sequential(
nn.Flatten(), # 展平 [64, 28, 28] -> [64*28*28]
nn.Linear(64 * 28 * 28, 512),
nn.ReLU(),
nn.Dropout(0.5), # 防止过拟合
nn.Linear(512, 1),
nn.Sigmoid() # 二分类输出
)