一、项目背景与需求
【打怪升级 - 08】基于 YOLO11 的抽烟检测系统(包含环境搭建 + 数据集处理 + 模型训练 + 效果对比 + 调参技巧)
今天我们使用YOLO11来训练一个抽烟检测系统,基于YOLO11的抽烟检测系统。我们使用了大概两万张图片的数据集训练了这次的基于YOLO11的抽烟检测模型,然后在推理的基础上使用PyQt设计了可视化的操作界面。
二、数据集
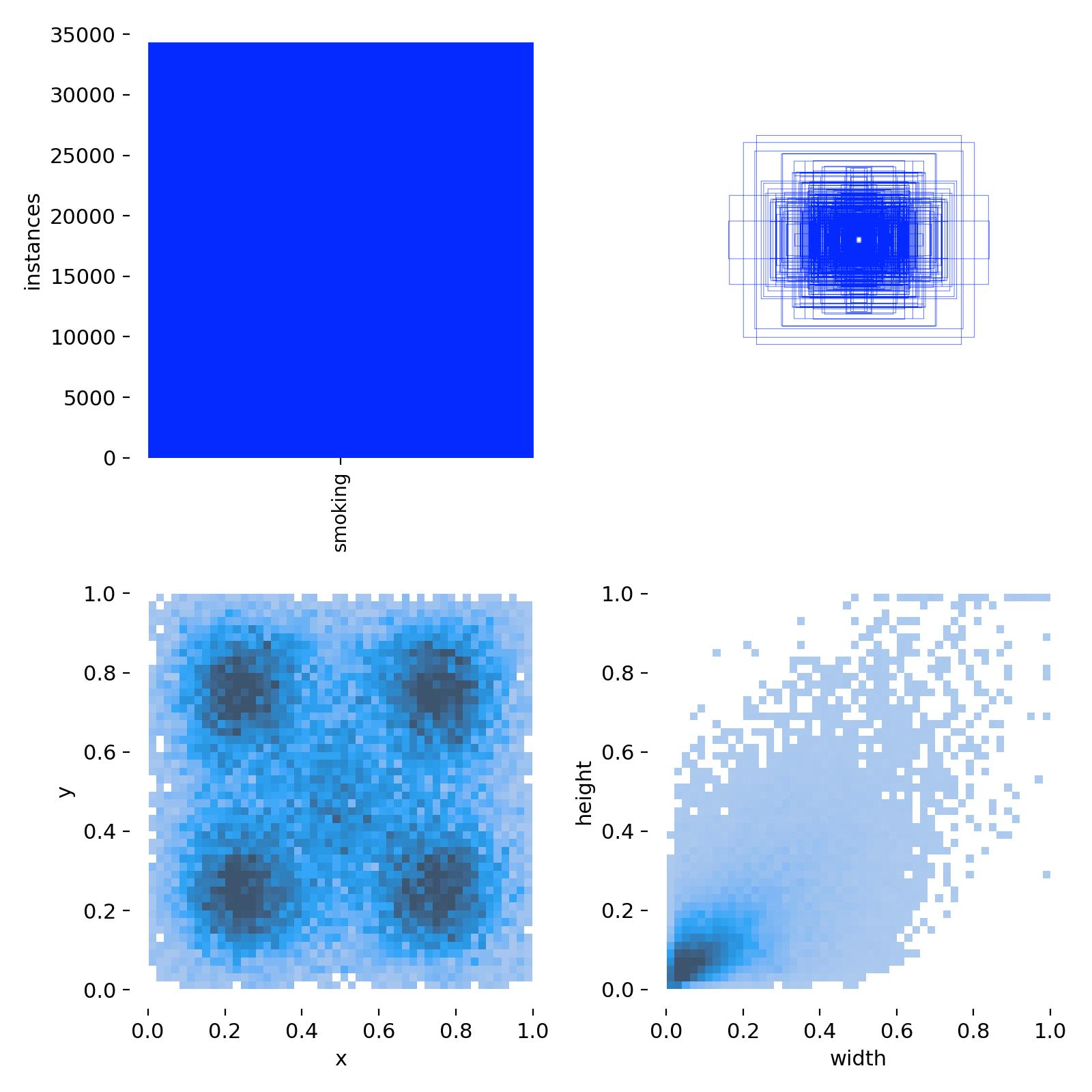
此次训练用的抽烟检测数据集,只有一类,即smoking。然后下面是数据集的统计分析图。一共有近35000个抽烟检测框,标签的中心坐标分布比较均匀,在图像中的各个位置都有,但都不靠近边缘;目标,即抽烟目标的长宽同样比较集中,属于小目标的范围(小于图像长宽的0.2倍)。
部分数据集截图:

三、简单介绍:YOLO11有哪些特点?
主要功能
- 增强的特征提取: YOLO11 采用改进的 backbone和 neck 架构,从而增强了特征提取能力,以实现更精确的目标检测和复杂的任务性能。
- 优化效率和速度: YOLO11 引入了改进的架构设计和优化的训练流程,从而提供更快的处理速度,并在精度和性能之间保持最佳平衡。
- 以更少的参数实现更高的精度: 凭借模型设计的进步,YOLO11m 在 COCO 数据集上实现了更高的 平均精度均值 (mAP),同时比 YOLOv8m 使用的参数减少了 22%,从而在不影响精度的情况下提高了计算效率。
- 跨环境的适应性: YOLO11 可以无缝部署在各种环境中,包括边缘设备、云平台和支持 NVIDIA GPU 的系统,从而确保最大的灵活性。
- 广泛的支持任务范围: 无论是目标检测、实例分割、图像分类、姿态估计还是定向目标检测 (OBB),YOLO11 都旨在满足各种计算机视觉挑战。
与之前的版本相比,Ultralytics YOLO11 的主要改进是什么?
Ultralytics YOLO11 在其前代产品的基础上进行了多项重大改进。主要改进包括:
- 增强的特征提取: YOLO11 采用了改进的骨干网络和颈部架构,增强了特征提取能力,从而实现更精确的目标检测。
- 优化的效率和速度: 改进的架构设计和优化的训练流程提供了更快的处理速度,同时保持了准确性和性能之间的平衡。
- 以更少的参数实现更高的精度: YOLO11m 在 COCO 数据集上实现了更高的平均精度均值 [mAP],与 YOLOv8m 相比,参数减少了 22%,从而在不影响准确性的前提下提高了计算效率。
- 跨环境的适应性: YOLO11 可以部署在各种环境中,包括边缘设备、云平台和支持 NVIDIA GPU 的系统。
- 广泛的支持任务范围: YOLO11 支持各种计算机视觉任务,例如目标检测、实例分割、图像分类、姿态估计和定向目标检测 (OBB)。
环境搭建:
【打怪升级 - 01】保姆级机器视觉入门指南:硬件选型 + CUDA/cuDNN/Miniconda/PyTorch/Pycharm 安装全流程(附版本匹配秘籍+文末有视频讲解)
数据集处理
labelme数据标注保姆级教程:从安装到格式转换全流程,附常见问题避坑指南(含视频讲解)
四、模型训练
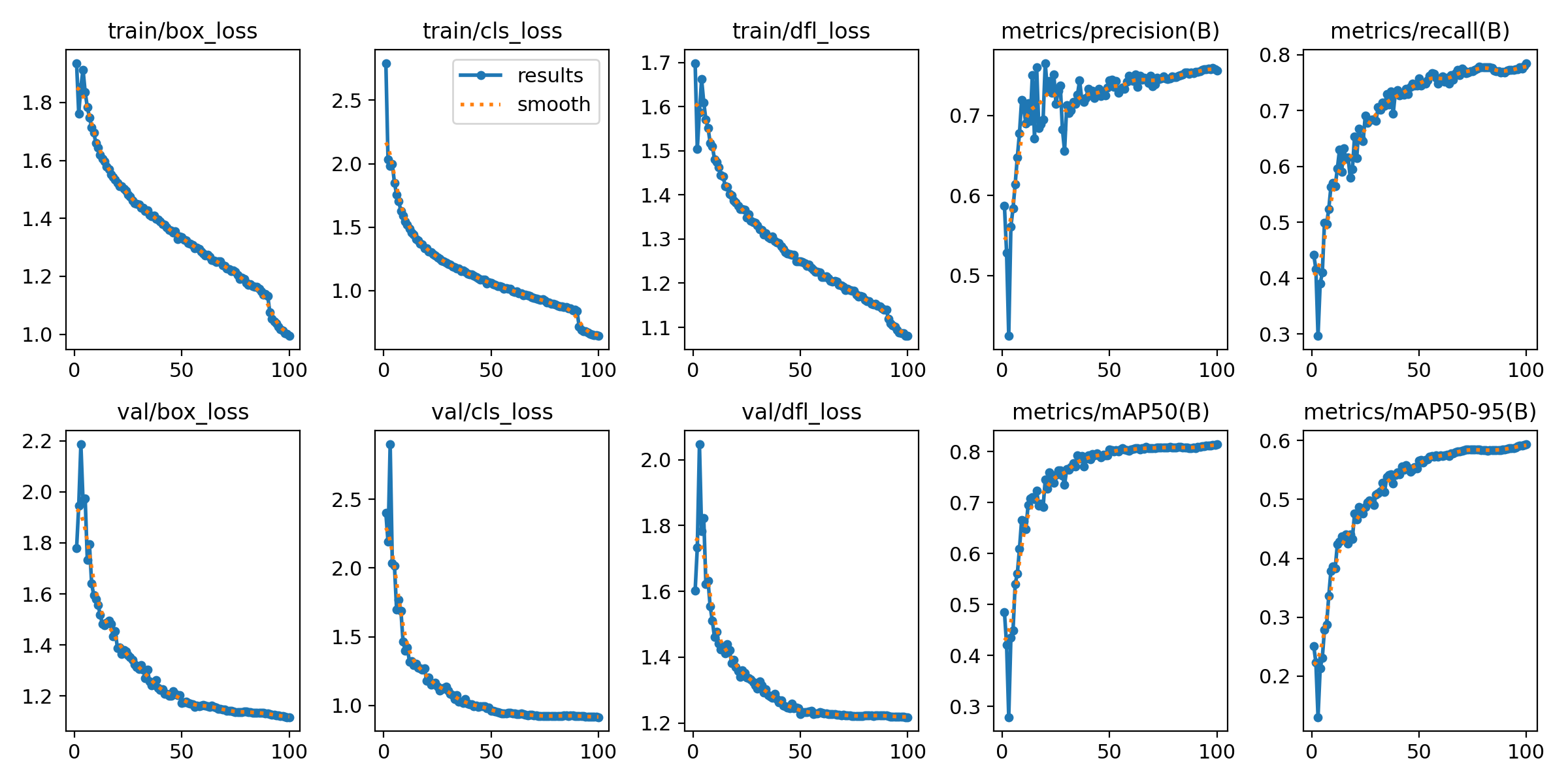
本次训练使用的预训练模型是YOLO11n.pt(COCO数据集训练所得),epochs设置为100,batch设置为64,imgsz设置为640,其他均采用默认参数。
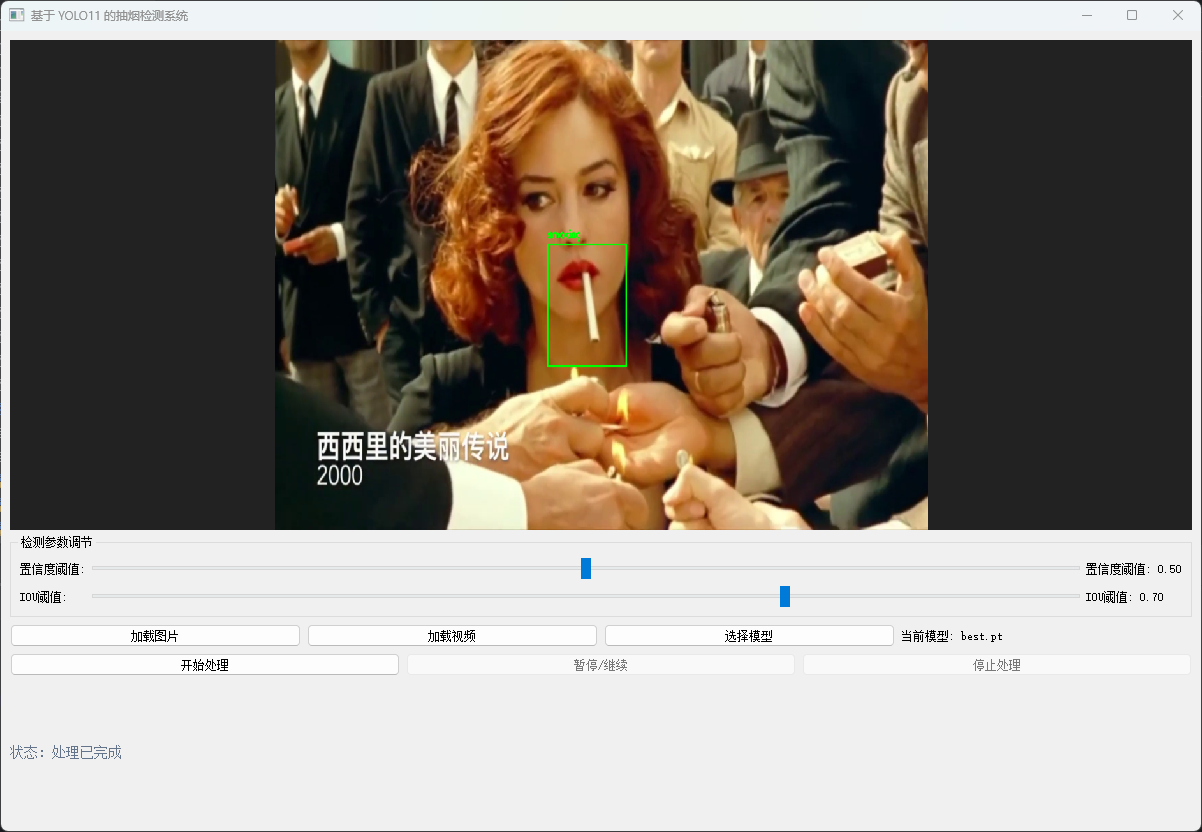
五、可视化模型推理
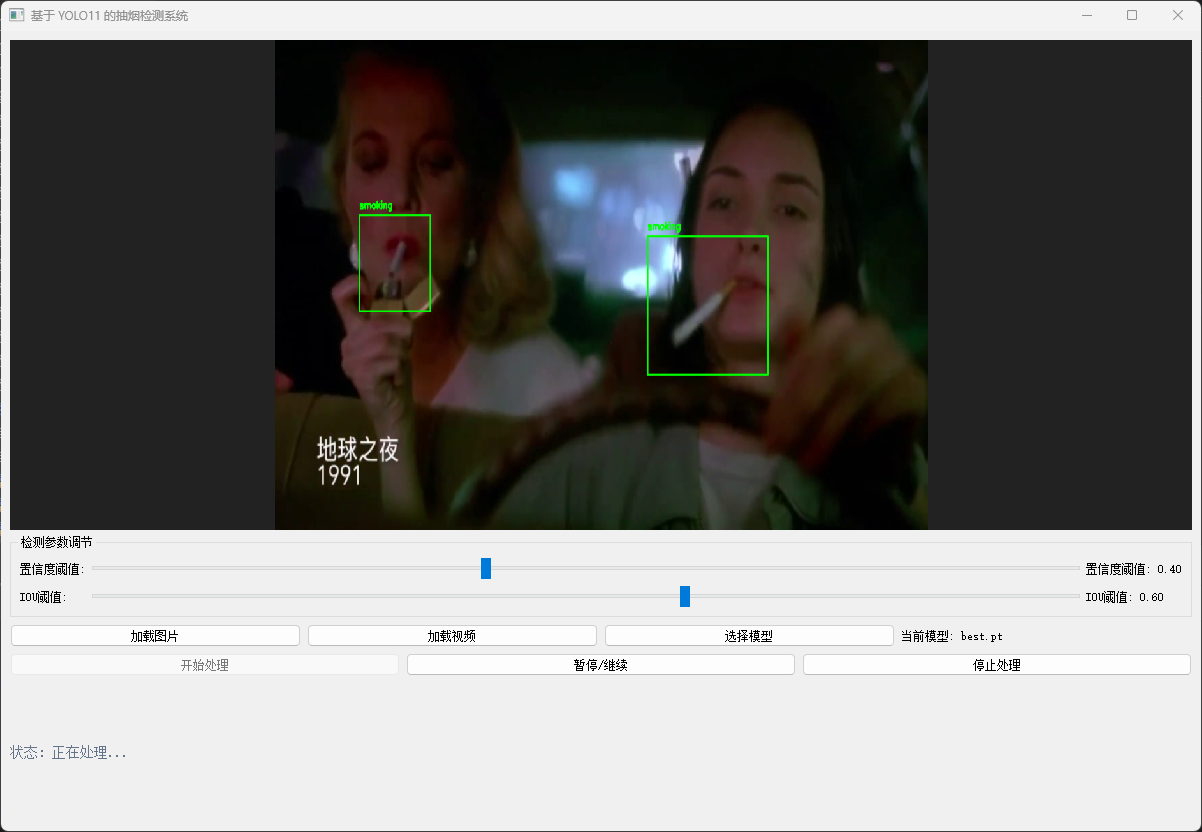
补充:
平均精度(mAP)是计算机视觉领域广泛使用的一个重要评估指标,尤其适用于物体检测任务。它提供了一个单一的综合分数,通过衡量模型对所有物体类别的预测准确度来总结模型的性能。mAP 分数既考虑了分类的正确性(物体是否如模型所说?),也考虑了定位的质量(预测的边界框与实际物体位置的匹配程度如何?)由于 mAP 能提供均衡的评估,因此已成为比较Ultralytics YOLO 等不同物体检测模型性能的标准指标。
mAP 如何工作
要了解 mAP,首先要掌握其核心组成部分:精确度(Precision)、召回率(Recall)和联合交集(IoU)。
- 精确度衡量模型预测的准确程度。它回答的问题是:“在模型检测到的所有物体中,正确率是多少?”
- 召回率:衡量模型找到所有实际物体的程度。它能回答以下问题"在图像中存在的所有真实物体中,模型成功检测到的物体占多大比例?
- 交集大于联合 (IoU):量化预测边界框与地面真实(人工标注)边界框重叠程度的指标。如果 IoU 高于某个阈值(如 0.5),则通常认为检测为真阳性。
mAP 计算综合了这些概念。对于每个对象类别,通过绘制不同置信度阈值下的精确度与召回率曲线,生成精确度-召回率曲线。该类别的平均精度(Average Precision,AP)就是该曲线下的面积,它提供了一个代表模型在该特定类别上性能的单一数字。最后,取所有对象类别的 AP 分数的平均值来计算 mAP。有些评估方案,如流行的COCO 数据集的评估方案,则更进一步,通过对多个 IoU 阈值的 mAP 取平均值来提供更稳健的评估。
将 mAP 与其他指标区分开来
虽然 mAP 与其他评价指标相关,但其目的截然不同。
准确性准确度衡量的是正确预测与预测总数的比率。它一般用于分类任务,不适合对象检测,因为在对象检测中,预测必须同时正确分类和定位。
- F1 分数F1 分数是精确度和召回率的调和平均值。虽然有用,但它通常是在单一置信度阈值下计算的。相比之下,mAP 通过平均所有阈值的性能来提供更全面的评估。
- 置信度:这不是模型整体的评估指标,而是分配给每个预测的分数,表示模型对该检测的确定程度。mAP 计算使用这些置信度分数来创建精度-召回曲线。