1. 实现功能
M4-2: 若无字幕则自动下载音频并用 whisper 转写,再用 LLM 总结。
2.运行效果
(base) root@DESKTOP-8IU6393:/mnt/e/AI-lab/AI 技术分享/1.yt-dlp 从入门到精通【101课程】:5个实战案例,从命令行到AI分析网站/ytdlp101# conda activate whisper
(whisper) root@DESKTOP-8IU6393:/mnt/e/AI-lab/AI 技术分享/1.yt-dlp 从入门到精通【101课程】:5个实战案例,从命令行到AI分析网站/ytdlp101# ls
M2-快速上手 M3-下载选项 M4-接入大模型 M5-Web化下载 cookies.txt downloads summaries temp video_metadata.json
(whisper) root@DESKTOP-8IU6393:/mnt/e/AI-lab/AI 技术分享/1.yt-dlp 从入门到精通【101课程】:5个实战案例,从命令行到AI分析网站/ytdlp101# cd M4-接入 大模型/
(whisper) root@DESKTOP-8IU6393:/mnt/e/AI-lab/AI 技术分享/1.yt-dlp 从入门到精通【101课程】:5个实战案例,从命令行到AI分析网站/ytdlp101/M4-接入大模
型# ls
'M4-1-接入 LLM.py' 'M4-2-接入 whisper.py' 'M4-3-接入 Crawl4ai.py' M4-4-优化观点提取.py downloads summaries
(whisper) root@DESKTOP-8IU6393:/mnt/e/AI-lab/AI 技术分享/1.yt-dlp 从入门到精通【101课程】:5个实战案例,从命令行到AI分析网站/ytdlp101/M4-接入大模
型# python 'M4-2-接入 whisper.py'
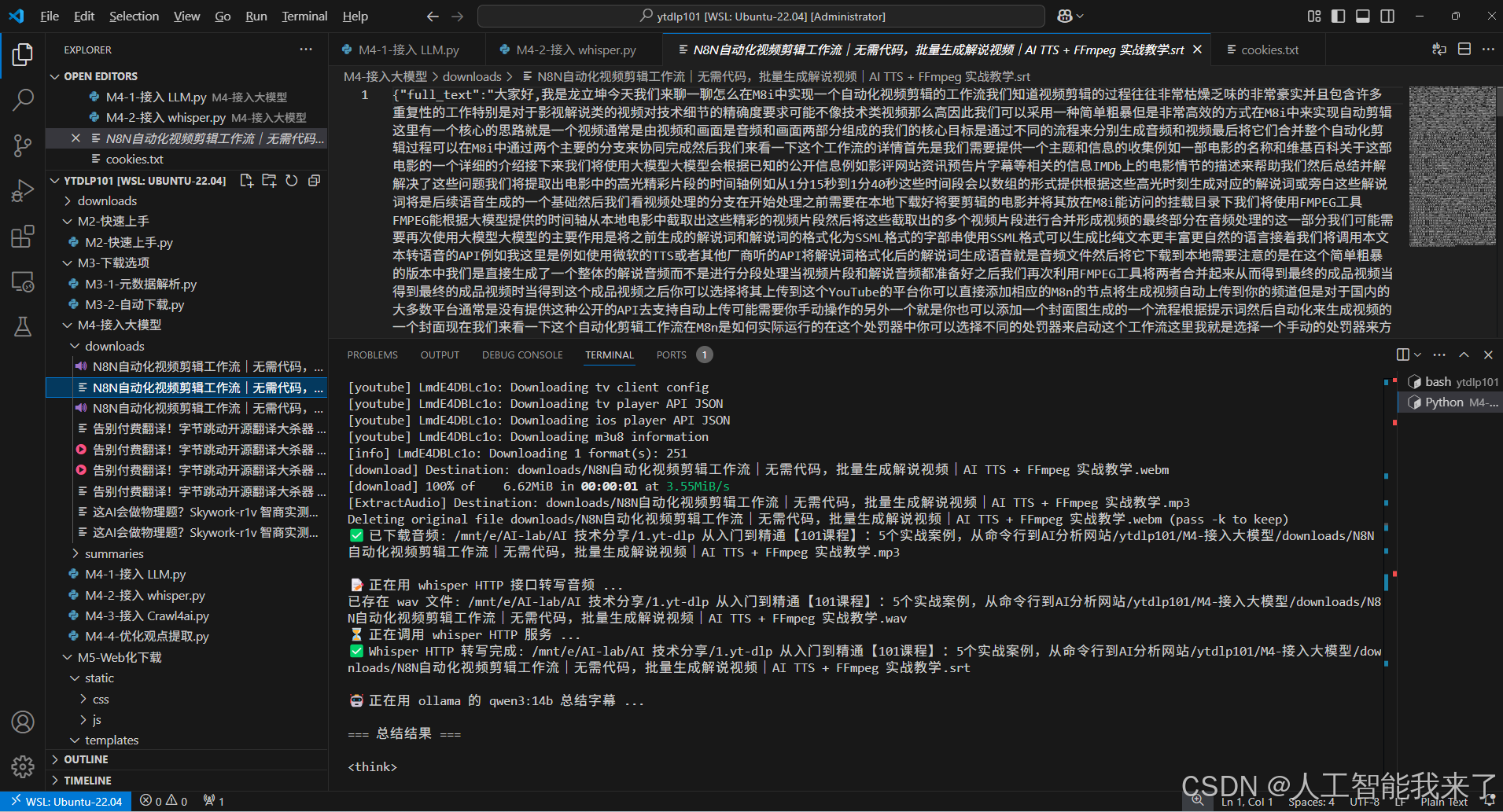
🔍 正在提取视频元数据...
WARNING: [youtube] LmdE4DBLc1o: Some web client https formats have been skipped as they are missing a url. YouTube is forcing SABR streaming for this client. See https://github.com/yt-dlp/yt-dlp/issues/12482 for more details
🔊 没有字幕,正在下载音频...
[youtube] Extracting URL: https://www.youtube.com/watch?v=LmdE4DBLc1o
[youtube] LmdE4DBLc1o: Downloading webpage
[youtube] LmdE4DBLc1o: Downloading tv client config
[youtube] LmdE4DBLc1o: Downloading tv player API JSON
[youtube] LmdE4DBLc1o: Downloading ios player API JSON
[youtube] LmdE4DBLc1o: Downloading m3u8 information
[info] LmdE4DBLc1o: Downloading 1 format(s): 251
[download] Destination: downloads/N8N自动化视频剪辑工作流|无需代码,批量生成解说视频|AI TTS + FFmpeg 实战教学.webm
[download] 100% of 6.62MiB in 00:00:01 at 3.55MiB/s
[ExtractAudio] Destination: downloads/N8N自动化视频剪辑工作流|无需代码,批量生成解说视频|AI TTS + FFmpeg 实战教学.mp3
Deleting original file downloads/N8N自动化视频剪辑工作流|无需代码,批量生成解说视频|AI TTS + FFmpeg 实战教学.webm (pass -k to keep)
✅ 已下载音频: /mnt/e/AI-lab/AI 技术分享/1.yt-dlp 从入门到精通【101课程】:5个实战案例,从命令行到AI分析网站/ytdlp101/M4-接入大模型/downloads/N8N自动化视频剪辑工作流|无需代码,批量生成解说视频|AI TTS + FFmpeg 实战教学.mp3
📝 正在用 whisper HTTP 接口转写音频 ...
已存在 wav 文件: /mnt/e/AI-lab/AI 技术分享/1.yt-dlp 从入门到精通【101课程】:5个实战案例,从命令行到AI分析网站/ytdlp101/M4-接入大模型/downloads/N8N自动化视频剪辑工作流|无需代码,批量生成解说视频|AI TTS + FFmpeg 实战教学.wav
⏳ 正在调用 whisper HTTP 服务 ...
✅ Whisper HTTP 转写完成: /mnt/e/AI-lab/AI 技术分享/1.yt-dlp 从入门到精通【101课程】:5个实战案例,从命令行到AI分析网站/ytdlp101/M4-接入大模型/downloads/N8N自动化视频剪辑工作流|无需代码,批量生成解说视频|AI TTS + FFmpeg 实战教学.srt
🤖 正在用 ollama 的 qwen3:14b 总结字幕 ...
=== 总结结果 ===
<think>
</think>
你提供的内容看起来是一段**视频的字幕文本**,其中详细描述了一个**基于 M8n 平台的自动化视频剪辑工作流**。该工作流结合了以下技术:
---
### 🎥 **视频内容概述**
这段视频主要讲解了如何使用 M8n(可能是一个自动化工作流平台)实现**影视解说类视频的自动化剪辑**。主要步骤包括:
1. **使用大模型(如 AI)生成解说词**;
2. **使用 FFMPEG 实现音视频剪辑与合成**;
3. **集成 TTS(文本转语音)生成配音**;
4. **通过 APA(可能是 API 调用)获取数据或控制流程**;
5. **批量处理多个视频**;
6. **优化剪辑精度**(分段处理 vs 粗暴处理);
7. **同步问题的处理**(音视频可能不完全同步);
8. **自动化表格管理**(批量处理多个视频);
9. **最后总结自动化剪辑的价值**。
---
### 🔍 **关键点提取**
- **平台使用**:M8n(可能是低代码/自动化工作流平台)
- **技术集成**:
- **FFMPEG**(音视频处理)
- **TTS**(文本转语音)
- **APA**(可能是 API 调用)
- **数据来源**:
- 电影名称
- 电影字幕(可选)
- 电影地址
- **输出**:
- 自动生成的影视解说视频
- 可批量处理
- **挑战与优化**:
- 音视频同步问题
- 大模型基于有限信息可能导致时间误差
- 可通过提供更详细的输入信息(如完整字幕)提高精度
- **应用场景**:
- 影视解说类视频
- 自动化内容生成
- 重复性剪辑任务优化
---
### 📌 **可能的用途(如果你是开发者或内容创作者)**
- **自动化生成影视解说视频**(如“电影解说”、“电视剧剪辑”等)
- **内容生产工具开发**(如 YouTube、Bilibili 视频批量生成)
- **AI + 自动化工作流平台集成案例**
- **学习 FFMPEG、TTS、API 调用等技术的实际应用**
---
### ✅ **建议下一步**
如果你是开发者,可以尝试:
1. **复现该工作流**,使用类似 M8n 的平台(如 n8n、Make、Zapier 等);
2. **尝试集成 FFMPEG 和 TTS 服务**(如 Azure TTS、Google TTS、阿里云 TTS);
3. **使用大模型生成解说词**(如通义千问、讯飞星火、ChatGLM 等);
4. **优化音视频同步逻辑**(如使用 FFMPEG 的 `setpts` 和 `itsoffset` 选项);
5. **构建批量处理系统**(如通过 Excel/CSV 表格管理多个视频任务)。
---
### 📄 **如果这是你自己的视频内容**
你可以考虑:
- **将该工作流封装成一个教程**,发布到 YouTube、Bilibili、知乎等平台;
- **提供该 JSON 工作流文件**(如你提到的“不提供免费分享,但可付费获取”);
- **加入更多实际案例**(如展示多个电影剪辑过程);
- **添加优化建议**(如如何提高同步精度、如何批量处理等)。
---
如果你有特定问题(如:如何实现音视频同步?如何使用 FFMPEG?如何集成 TTS?),欢迎继续提问,我可以为你详细解答。
(whisper) root@DESKTOP-8IU6393:/mnt/e/AI-lab/AI 技术分享/1.yt-dlp 从入门到精通【101课程】:5个实战案例,从命令行到AI分析网站/ytdlp101/M4-接入大模
型#
3.实现过程
3.1 搭建环境
需要whisper api服务开启。具体见https://blog.csdn.net/weixin_44626085/article/details/150107899?spm=1011.2415.3001.5331
(base) root@DESKTOP-8IU6393:/mnt/e/AI-lab/AI 技术分享/1.yt-dlp 从入门到精通【101课程】:5个实战案例,从命令行到AI分析网站/ytdlp101# conda activate whisper
(whisper) root@DESKTOP-8IU6393:/mnt/e/AI-lab/AI 技术分享/1.yt-dlp 从入门到精通【101课程】:5个实战案例,从命令行到AI分析网站/ytdlp101# ls
M2-快速上手 M3-下载选项 M4-接入大模型 M5-Web化下载 cookies.txt downloads summaries temp video_metadata.json
(whisper) root@DESKTOP-8IU6393:/mnt/e/AI-lab/AI 技术分享/1.yt-dlp 从入门到精通【101课程】:5个实战案例,从命令行到AI分析网站/ytdlp101# cd M4-接入 大模型/
(whisper) root@DESKTOP-8IU6393:/mnt/e/AI-lab/AI 技术分享/1.yt-dlp 从入门到精通【101课程】:5个实战案例,从命令行到AI分析网站/ytdlp101/M4-接入大模
型# ls
'M4-1-接入 LLM.py' 'M4-2-接入 whisper.py' 'M4-3-接入 Crawl4ai.py' M4-4-优化观点提取.py downloads summaries
(whisper) root@DESKTOP-8IU6393:/mnt/e/AI-lab/AI 技术分享/1.yt-dlp 从入门到精通【101课程】:5个实战案例,从命令行到AI分析网站/ytdlp101/M4-接入大模
型# python 'M4-2-接入 whisper.py'
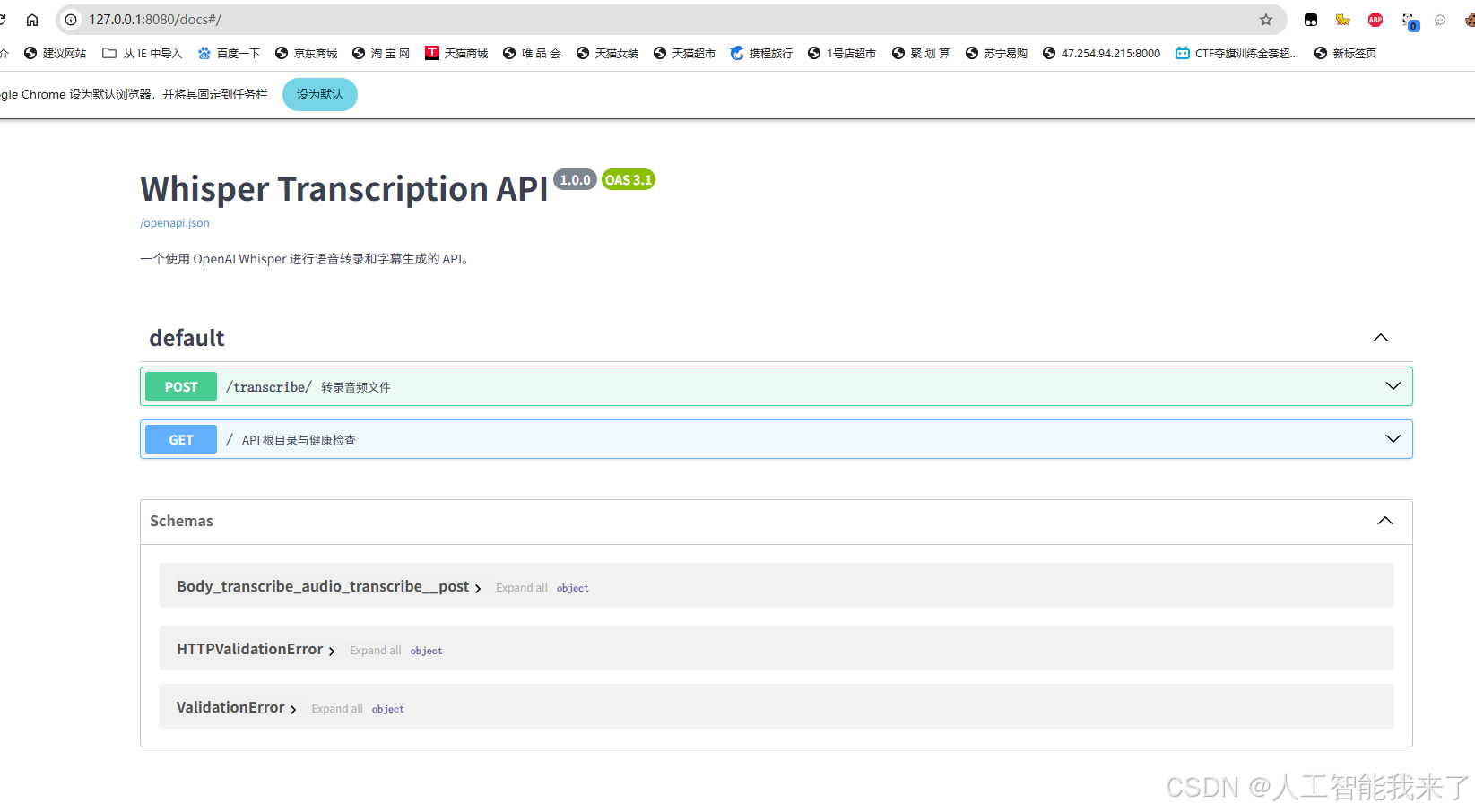
3.1.1 在浏览器中打开 http://127.0.0.1:8080/docs 可以看到自动生成的交互式 API 文档。
3.2 代码
from yt_dlp import YoutubeDL
import os
def get_parent_cookies():
return os.path.join(os.path.dirname(os.path.dirname(__file__)), 'cookies.txt')
def extract_video_metadata(url):
ydl_opts = {
'cookiefile': get_parent_cookies(),
'quiet': True,
'no_warnings': False,
'extract_flat': False,
'extractor_args': {
'youtube': {
'player_client': ['tv_embedded', 'web'],
}
}
}
with YoutubeDL(ydl_opts) as ydl:
try:
info = ydl.extract_info(url, download=False)
return info
except Exception as e:
print(f"提取元数据失败: {e}")
return None
def download_subtitles(url, info):
subtitles = info.get('subtitles', {})
if not subtitles:
return None
print("\n📝 正在下载所有可用字幕...")
ydl_opts = {
'cookiefile': get_parent_cookies(),
'skip_download': True,
'writesubtitles': True,
'allsubtitles': True,
'subtitlesformat': 'srt',
'outtmpl': 'downloads/%(title).80s.%(ext)s',
'quiet': False,
}
with YoutubeDL(ydl_opts) as ydl:
ydl.download([url])
downloads_dir = os.path.join(os.path.dirname(__file__), 'downloads')
srt_files = [f for f in os.listdir(downloads_dir) if f.endswith('.srt')]
if not srt_files:
print("❌ 没有找到下载的字幕文件")
return None
srt_path = os.path.join(downloads_dir, srt_files[0])
print(f"✅ 已下载字幕: {srt_path}")
return srt_path
def download_audio(url):
print("\n🔊 没有字幕,正在下载音频...")
ydl_opts = {
'cookiefile': get_parent_cookies(),
'format': 'bestaudio/best',
'outtmpl': 'downloads/%(title).80s.%(ext)s',
'quiet': False,
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'mp3',
'preferredquality': '192',
}],
}
with YoutubeDL(ydl_opts) as ydl:
ydl.download([url])
downloads_dir = os.path.join(os.path.dirname(__file__), 'downloads')
audio_files = [f for f in os.listdir(downloads_dir) if f.endswith('.mp3')]
if not audio_files:
print("❌ 没有找到下载的音频文件")
return None
audio_path = os.path.join(downloads_dir, audio_files[0])
print(f"✅ 已下载音频: {audio_path}")
return audio_path
def transcribe_with_whisper(audio_path):
print("\n📝 正在用 whisper HTTP 接口转写音频 ...")
import subprocess
import shutil
# 1. 转为 wav 格式
wav_path = audio_path.rsplit('.', 1)[0] + ".wav"
if not os.path.exists(wav_path):
print(f"🔄 正在转换为 wav 格式: {wav_path}")
subprocess.run([
"ffmpeg", "-y", "-i", audio_path, "-ar", "16000", "-ac", "1", wav_path
], check=True)
else:
print(f"已存在 wav 文件: {wav_path}")
# 2. 调用 whisper HTTP 接口
srt_path = audio_path.rsplit('.', 1)[0] + ".srt"
print("⏳ 正在调用 whisper HTTP 服务 ...")
curl_cmd = [
"curl", "-X", "POST", "http://127.0.0.1:8080/transcribe/",
"-F", f"audio_file=@{wav_path};type=audio/wav",
"-F", "model_name=large-v3",
"-F", "language=zh"
]
try:
result = subprocess.run(curl_cmd, capture_output=True, check=True)
# 假设接口直接返回 SRT 字符串
srt_content = result.stdout.decode("utf-8")
with open(srt_path, "w", encoding="utf-8") as f:
f.write(srt_content)
print(f"✅ Whisper HTTP 转写完成: {srt_path}")
return srt_path
except subprocess.CalledProcessError as e:
print("❌ Whisper HTTP 转写失败")
print(e.stderr.decode("utf-8"))
return None
def summarize_with_ollama(srt_path):
print(f"\n🤖 正在用 ollama 的 qwen3:14b 总结字幕 ...")
try:
import ollama
except ImportError:
import sys, subprocess
subprocess.check_call([sys.executable, '-m', 'pip', 'install', 'ollama'])
import ollama
def srt_to_text(srt_content):
import re
lines = srt_content.splitlines()
text_lines = []
for line in lines:
if re.match(r"^\d+$", line):
continue
if re.match(r"^\d{2}:\d{2}:\d{2},\d{3} --> ", line):
continue
if line.strip() == '':
continue
text_lines.append(line.strip())
from itertools import groupby
merged = [k for k, _ in groupby(text_lines)]
return ' '.join(merged)
with open(srt_path, 'r', encoding='utf-8') as f:
srt_content = f.read()
clean_text = srt_to_text(srt_content)
prompt = f"""
你是一名专业的视频内容总结助手,请对下列中文视频字幕内容进行总结。
目标:让用户能在30秒内了解这期视频的核心内容。
请按以下格式输出:
1. 🎯 本期主要话题(用一句话概括主题)
2. 📌 内容要点(3-5条,每条 1 句话)
3. 🌟 精彩片段或亮点(选出最值得一提的内容,1-2条)
⚠️ 不要加入你的思考过程,不要说“我认为”或“可能”,只根据字幕原文总结。
字幕内容如下:
———
{clean_text}
———
/no_think
"""
try:
response = ollama.chat(
model='qwen3:14b',
messages=[{"role": "user", "content": prompt}]
)
print("\n=== 总结结果 ===\n")
print(response['message']['content'])
except Exception as e:
print(f"调用 ollama 失败: {e}")
def main():
url = "https://www.youtube.com/watch?v=LmdE4DBLc1o"
print("🔍 正在提取视频元数据...")
info = extract_video_metadata(url)
if not info:
print("❌ 无法获取视频信息")
return
srt_path = download_subtitles(url, info)
if srt_path:
summarize_with_ollama(srt_path)
else:
audio_path = download_audio(url)
if not audio_path:
print("❌ 无法下载音频")
return
srt_path = transcribe_with_whisper(audio_path)
summarize_with_ollama(srt_path)
if __name__ == "__main__":
main()