关注gongzhonghao【CVPR顶会精选】
视觉感知,CVPR舞台的 “常驻 C 位”,未来图景堪称 “万象更新”。这赛道向来是论文高产地,但要想叩开顶会顶刊大门,就得懂得绕路,盲目堆砌数据行不通!
今天小图给大家精选3篇CVPR有视觉感知方向的论文,请注意查收!
论文一:PF3Det: A Prompted Foundation Feature Assisted Visual LiDAR 3D Detector
方法:
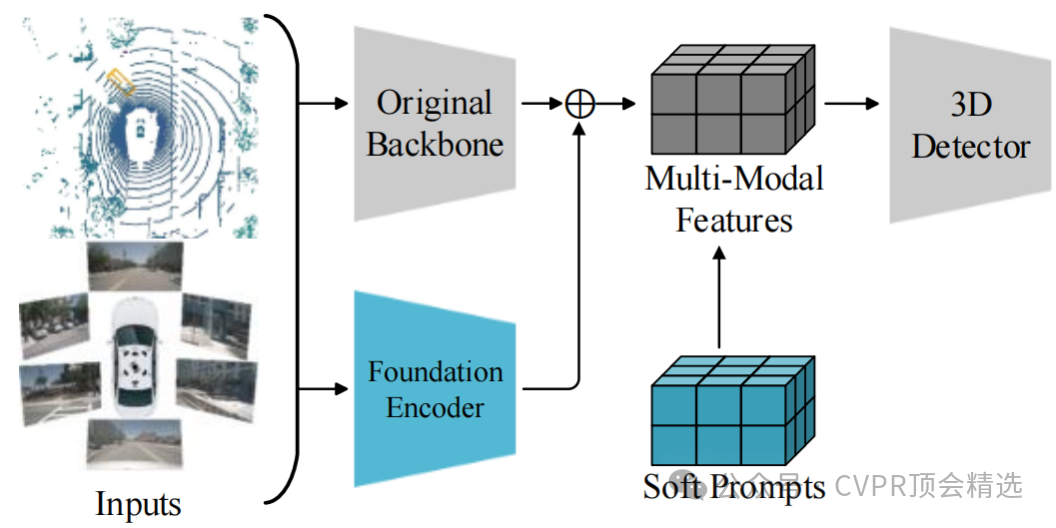
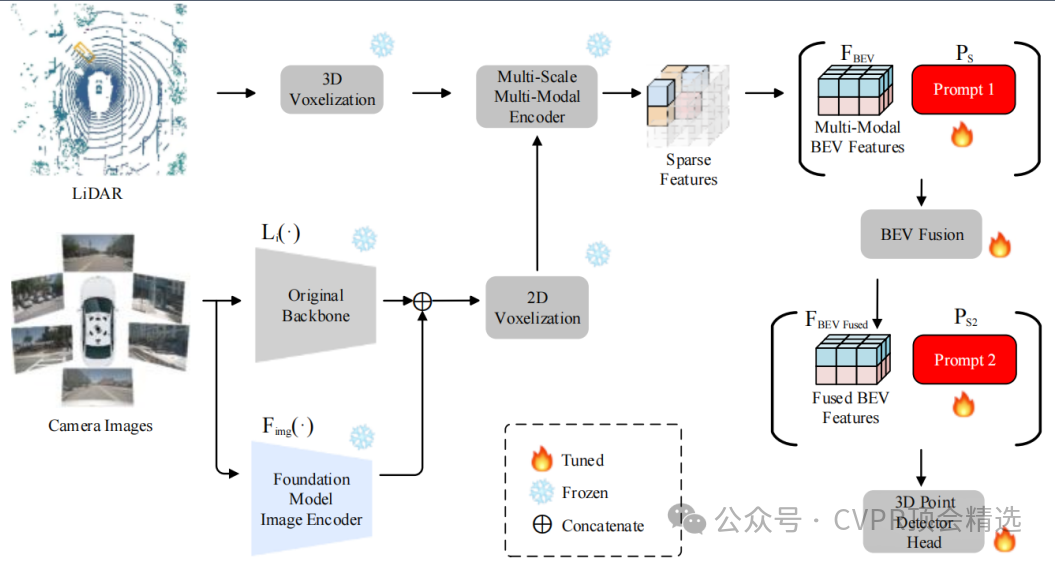
作者在图像输入并行方向,通过常规图像主干将其高层语义特征向量拼接并融合到常规图像特征金字塔中。在生成鸟瞰图特征后,将可学习的提示张量,尺寸与原始BEV特征拼接,并通过修改后续卷积层输入维度或添加对齐卷积层来融合信息。再然后,文章基于MSMDFusion框架融合LiDAR点云、常规图像特征和基础图像特征生成BEV特征;最后采用多阶段训练策略,最终利用融合特征预测3D边界框。
创新点:
引入多模态基础模型的预训练特征,增强图像语义理解能力,弥补常规图像特征不足。
创新性地在BEV特征层插入可学习的多模态软提示,动态适配并弥合LiDAR与相机特征间的领域差异。
构建了首个结合基础模型特征与提示工程的3D检测框架,在极少量训练数据下显著超越现有SOTA方法。
论文链接:
https://arxiv.org/abs/2504.03563
图灵学术论文辅导
论文二:SemiDAViL: Semi-supervised Domain Adaptation with Vision-Language Guidance for Semantic Segmentation
方法:
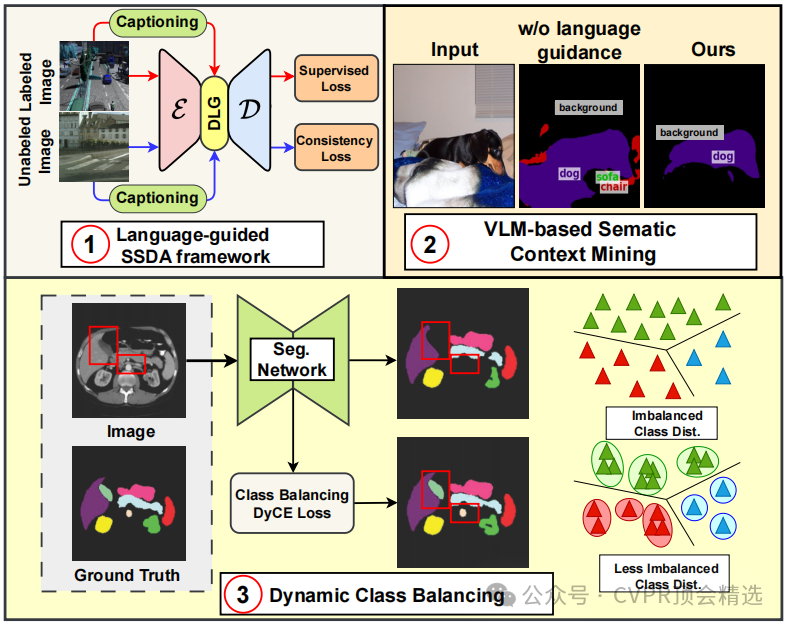
文章首先利用视觉-语言预训练模型初始化分割网络的编码器,获取丰富的语义先验知识。接着通过密集语言引导模块,将视觉特征与语言特征进行融合,生成多模态特征表示。最后结合一致性训练和动态交叉熵损失,对模型进行优化,同时利用少量标记数据和大量未标记数据进行训练,从而实现对目标领域的自适应语义分割。
创新点:
首次提出语言引导的SSDA框架,利用预训练的视觉-语言模型的语义泛化能力,建立协同框架,增强跨领域的特征表示。
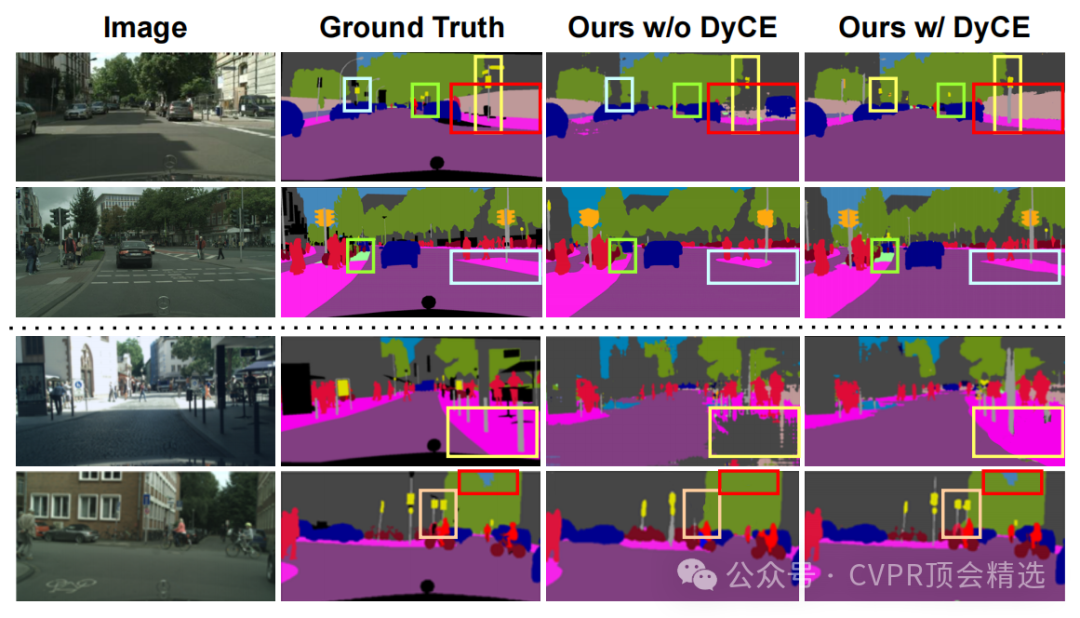
引入动态交叉熵损失,动态校准少数类别的学习权重,有效解决类别不平衡问题,提升尾部类别的分割精度。
设计了密集语言引导模块,通过图像级视觉-语言预训练生成的文本描述,将视觉特征与密集语言嵌入融合,改善分割性能。
论文链接:
https://www.alphaxiv.org/overview/2504.06389v1
图灵学术论文辅导
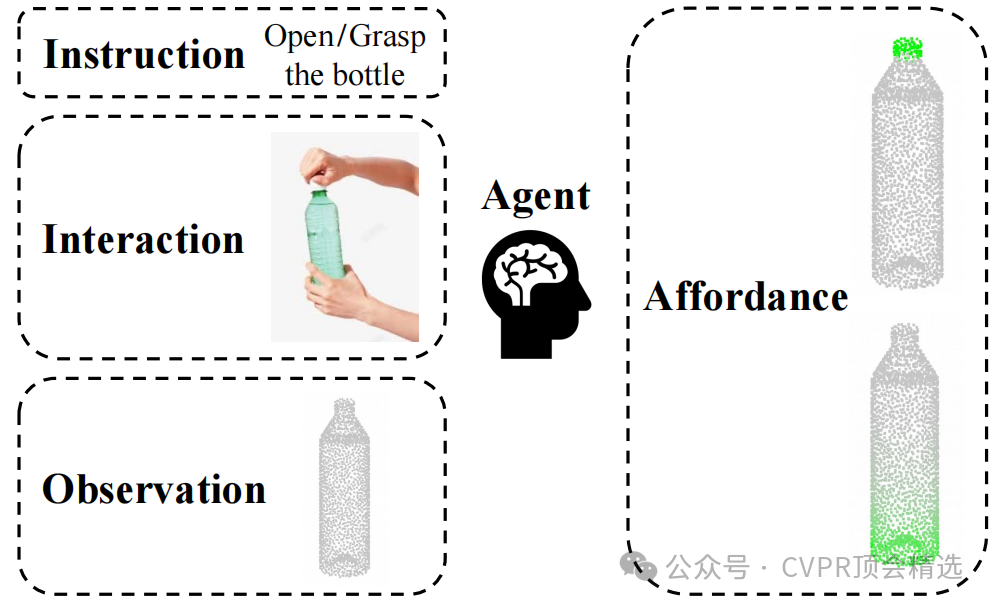
论文三:Grounding 3D Object Affordance with Language Instructions, Visual Observations and Interactions
方法:
文章首先设计了一个多模态视觉编码器,分别利用ResNet18和PointNet++提取图像和点云数据的二维、三维特征,并通过MLP和自注意力机制将它们融合为多模态空间特征。然后将这些特征投影到语义空间,并与经过分词器处理的语言指令特征一起输入到视觉-语言模型中,通过解码器进一步融合得到功能特征,最后利用分割头预测出三维物体的功能区域。
创新点:
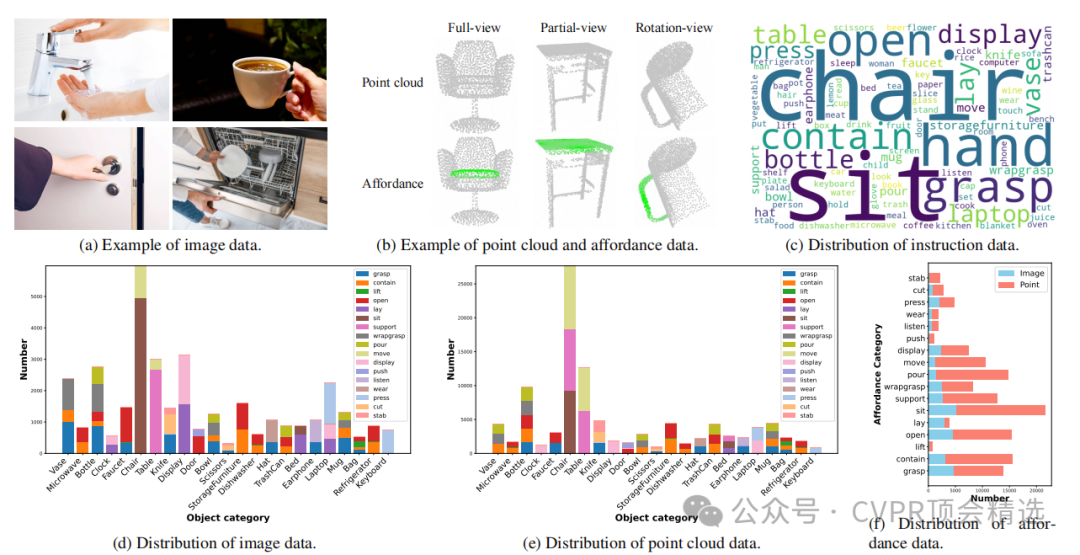
首次构建了包含点云、图像和语言指令的多模态、多视角三维功能定位数据集AGPIL,为该任务提供了丰富的训练和测试素材。
提出了一种新颖的端到端多模态、语言引导的三维功能定位框架LMAffordance3D,显著提升了模型对三维物体功能的定位精度。
在包含已见和未见物体类别及功能的多种实验设置下,全面验证了该方法的有效性和泛化能力。
论文链接:
https://arxiv.org/abs/2504.04744
本文选自gongzhonghao【CVPR顶会精选】