项目源于我们开发的一款基于大模型的报告生成工具。由于需要将 Markdown 格式的内容导出为 Word 文档,而市面上缺乏合适的现成工具,所以决定自己开发一个Markdown转Word的工具。
🩷源码地址:daydayup-zyn/md2doc-plus
😀实现思路
md2doc-plus 基于 Java 17 和 Apache POI 构建,采用模块化设计,主要包括以下几个核心组件:
- Markdown 解析器:负责解析 Markdown 内容,识别文本、表格、图表等元素
- 文档生成器:使用 Apache POI 创建和操作 Word 文档
- 模板引擎:支持动态生成文档模板,便于后续内容替换
- 图表转换器:专门处理 ECharts 图表到 Word 图表的转换
😃核心转换流程如下:
- 解析 Markdown 内容,识别各种元素(标题、段落、表格、图表等)
- 基于 Markdown 结构,自动化创建 Word 文档模板,为动态内容预留占位符
- 将解析后的内容填充到模板中
- 生成最终的 Word 文档
😁功能亮点
完整的 Markdown 支持
md2doc-plus 支持常见的 Markdown 语法元素:
- 各级标题(H1-H6)
- 段落文本
- 表格
- ECharts 图表
ECharts 图表支持
这是 md2doc-plus 的一大亮点。它能够解析 Markdown 中的 ECharts 配置代码块,并将其转换为 Word 中的图表对象:```echarts { title: { text: '月度销售数据' }, tooltip: { trigger: 'axis' }, xAxis: { type: 'category', data: ['1月', '2月', '3月', '4月', '5月', '6月'] }, yAxis: { type: 'value', name: '销售额' }, series: [{ name: '销售额', type: 'line', data: [15.32, 15.87, 14.96, 16.23, 13.21, 13.53] }] } ```动态模板生成
工具支持动态生成 Word 模板,能够根据 Markdown 内容自动创建包含占位符的文档结构,便于后续内容填充。高度可定制
通过 WordParams 和 ChartTable 等模型类,用户可以灵活地自定义生成的 Word 文档内容和格式。易于集成
作为基于 Java 的工具库,md2doc-plus 可以轻松集成到现有的 Java 项目中,为应用程序提供 Markdown 到 Word 的转换能力。
🫠核心实现代码解析
Markdown 解析与文档结构创建
md2doc-plus 的核心功能之一是解析 Markdown 内容并创建相应的 Word 文档结构。这主要在 DynamicWordDocumentCreator 类中实现:/** * 解析Markdown内容并创建Word文档结构 * @param document Word文档对象 * @param markdownContent Markdown内容 */ private static void parseAndCreateDocumentStructure(XWPFDocument document, String markdownContent) { // 用于匹配ECharts代码块的正则表达式 Pattern echartsPattern = Pattern.compile("```echarts\\s*\\n(.*?)\\n```", Pattern.DOTALL); // 用于匹配表格的正则表达式 Pattern tablePattern = Pattern.compile("(\\|[^\\n]*\\|\\s*\\n\\s*\\|[-|\\s]*\\|\\s*\\n(?:\\s*\\|[^\\n]*\\|\\s*\\n?)*)", Pattern.MULTILINE); // 用于匹配标题的正则表达式 Pattern headerPattern = Pattern.compile("^(#{1,6})\\s+(.*)$", Pattern.MULTILINE); String[] lines = markdownContent.split("\n"); int chartIndex = 1; int tableIndex = 1; for (int i = 0; i < lines.length; i++) { String line = lines[i]; // 检查是否为标题 Matcher headerMatcher = headerPattern.matcher(line); if (headerMatcher.find()) { int level = headerMatcher.group(1).length(); String title = headerMatcher.group(2); XWPFParagraph headerParagraph = document.createParagraph(); setHeaderStyle(headerParagraph, level); setHeaderParagraphStyle(headerParagraph, level); XWPFRun headerRun = headerParagraph.createRun(); headerRun.setText(title); headerRun.setBold(true); headerRun.setFontFamily("宋体"); // 根据标题级别设置字体大小 int fontSize = 16; // 默认H3 switch (level) { case 1: fontSize = 22; break; // H1 case 2: fontSize = 20; break; // H2 case 3: fontSize = 18; break; // H3 case 4: fontSize = 16; break; // H4 case 5: fontSize = 14; break; // H5 case 6: fontSize = 12; break; // H6 } headerRun.setFontSize(fontSize); continue; } // 检查是否为ECharts图表 if (line.trim().equals("```echarts")) { // 查找图表代码块的结束位置 StringBuilder chartCode = new StringBuilder(); i++; // 移动到下一行 while (i < lines.length && !lines[i].trim().equals("```")) { chartCode.append(lines[i]).append("\n"); i++; } // 创建图表占位符 XWPFParagraph chartTitleParagraph = document.createParagraph(); setDefaultParagraphStyle(chartTitleParagraph); // 图表标题使用默认段落样式 XWPFRun chartTitleRun = chartTitleParagraph.createRun(); chartTitleRun.setText("图表 " + chartIndex + ":"); chartTitleRun.setBold(true); chartTitleRun.setFontFamily("宋体"); // 创建实际的图表对象 try { createChartInDocument(document, "chart" + chartIndex, chartCode.toString()); } catch (Exception e) { // 如果创建图表失败,至少添加占位符 XWPFParagraph chartParagraph = document.createParagraph(); chartParagraph.setAlignment(ParagraphAlignment.CENTER); setDefaultParagraphStyle(chartParagraph); XWPFRun chartRun = chartParagraph.createRun(); chartRun.setText("${chart" + chartIndex + "}"); } chartIndex++; continue; } // 检查是否为表格开始 if (line.startsWith("|")) { // 收集表格的所有行 StringBuilder tableMarkdown = new StringBuilder(line).append("\n"); i++; // 移动到下一行 while (i < lines.length && (lines[i].startsWith("|") || lines[i].trim().matches("^\\|?\\s*[-|:\\s]+\\|?\\s*$"))) { tableMarkdown.append(lines[i]).append("\n"); i++; } i--; // 回退一行,因为循环会自动增加i // 创建表格占位符 XWPFParagraph tableTitleParagraph = document.createParagraph(); setDefaultParagraphStyle(tableTitleParagraph); // 表格标题使用默认段落样式 XWPFRun tableTitleRun = tableTitleParagraph.createRun(); tableTitleRun.setText("表格 " + tableIndex + ":"); tableTitleRun.setBold(true); tableTitleRun.setFontFamily("宋体"); XWPFParagraph tableParagraph = document.createParagraph(); setDefaultParagraphStyle(tableParagraph); XWPFRun tableRun = tableParagraph.createRun(); tableRun.setText("${table" + tableIndex + "}"); tableIndex++; continue; } // 普通段落 if (!line.trim().isEmpty()) { XWPFParagraph paragraph = document.createParagraph(); setDefaultParagraphStyle(paragraph); // 内容段落使用默认样式 XWPFRun run = paragraph.createRun(); run.setText(line); run.setFontFamily("宋体"); run.setFontSize(12); // 小四号字体 } } }ECharts 图表转换
EChartsToWordConverter 类负责将 ECharts 配置转换为 Word 图表数据:public static void convertEChartsToWordChart(WordParams params, String chartKey, String echartsConfig) throws IOException { try { // 预处理ECharts配置,将其转换为有效的JSON格式 String jsonConfig = convertEChartsToJson(echartsConfig); JsonNode rootNode = objectMapper.readTree(jsonConfig); // 获取图表标题 String title = rootNode.path("title").path("text").asText("默认标题"); // 创建图表 ChartTable chartTable = params.addChart(chartKey).setTitle(title); // 处理 X 轴数据 JsonNode xAxisNode = rootNode.path("xAxis"); if (xAxisNode.isArray()) { xAxisNode = xAxisNode.get(0); // 多个 x 轴时取第一个 } if (!xAxisNode.isMissingNode()) { JsonNode xAxisData = xAxisNode.path("data"); if (!xAxisData.isMissingNode()) { List<String> xAxisLabels = new ArrayList<>(); for (JsonNode dataNode : xAxisData) { xAxisLabels.add(dataNode.asText()); } chartTable.getXAxis().addAllData(xAxisLabels); } } // 处理 Y 轴数据和系列数据 JsonNode seriesNode = rootNode.path("series"); if (seriesNode.isArray()) { for (JsonNode serie : seriesNode) { String seriesName = serie.path("name").asText("数据系列"); JsonNode seriesData = serie.path("data"); if (!seriesData.isMissingNode() && seriesData.isArray()) { List<Number> dataValues = new ArrayList<>(); for (JsonNode dataNode : seriesData) { if (dataNode.isNumber()) { dataValues.add(dataNode.numberValue()); } else { dataValues.add(0); } } chartTable.newYAxis(seriesName).addAllData(dataValues); } } } // 如果有 Y 轴名称设置,更新第一个 Y 轴的标题 JsonNode yAxisNode = rootNode.path("yAxis"); if (yAxisNode.isArray()) { yAxisNode = yAxisNode.get(0); // 多个 y 轴时取第一个 } if (!yAxisNode.isMissingNode()) { String yAxisName = yAxisNode.path("name").asText(""); if (!yAxisName.isEmpty() && !chartTable.getYAxis().isEmpty()) { // 获取第一个 Y 轴并设置标题 String firstKey = chartTable.getYAxis().keySet().iterator().next(); chartTable.getYAxis(firstKey).setTitle(yAxisName); } } } catch (Exception e) { // 如果解析失败,创建一个默认的空图表 ChartTable chartTable = params.addChart(chartKey).setTitle("默认图表标题"); chartTable.getXAxis().addAllData("数据1", "数据2", "数据3"); chartTable.newYAxis("默认系列").addAllData(10, 20, 30); throw new IOException("解析ECharts配置时出错: " + e.getMessage(), e); } }表格解析
MarkdownTableParser 类负责解析 Markdown 表格:public static List<List<String>> parseTable(String markdownTable) { List<List<String>> tableData = new ArrayList<>(); String[] lines = markdownTable.split("\n"); for (String line : lines) { line = line.trim(); // 跳过分隔行(只包含|和-的行) if (line.matches("^\\|?\\s*[-|:\\s]+\\|?\\s*$") && line.contains("-")) { continue; } if (line.startsWith("|")) { line = line.substring(1); } if (line.endsWith("|")) { line = line.substring(0, line.length() - 1); } String[] cells = line.split("\\|"); List<String> row = new ArrayList<>(); for (String cell : cells) { row.add(cell.trim()); } // 只有当行不为空时才添加到表格数据中 if (!row.isEmpty() && !(row.size() == 1 && row.get(0).isEmpty())) { tableData.add(row); } } return tableData; }
🥰使用示例
使用 md2doc-plus 非常简单,只需要几行代码:
public class Test {
public static void main(String[] args) throws Exception {
MarkdownToWordConverter.convertMarkdownFileToWord("./markdown/未命名.md",
"./word/未命名_output.docx");
}
}
😜效果验证
原始markdown文件:
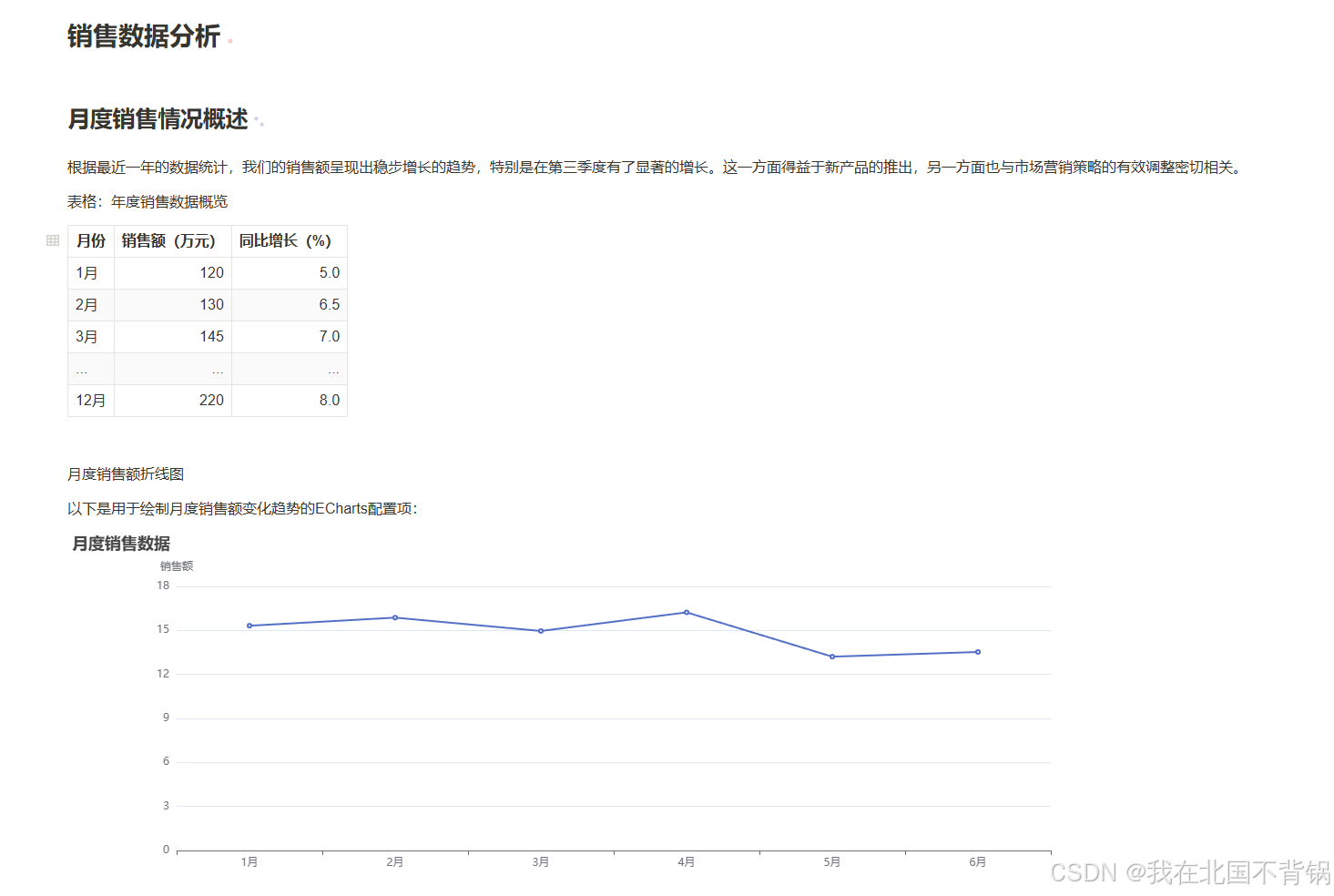
转换后的Word文档
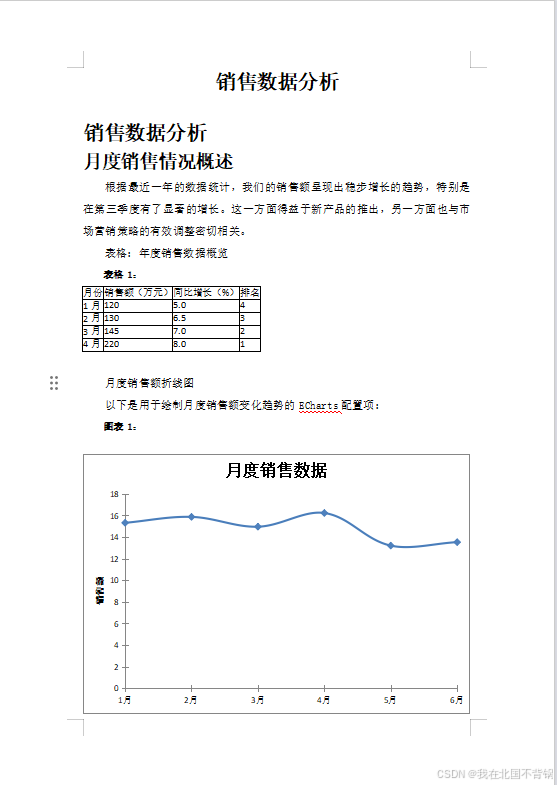
🤨存在的问题
- word章节标题样式缺失,无法自动生成目录;
- 图表样式缺失,图表显示不全,需手动调整;