在Python中需要通过正则表达式对字符串进⾏匹配的时候,可以使⽤⼀个python自带的模块,名字为re。
re模块的使用:import re
一、匹配函数
1-1、re.match函数:返回匹配对象
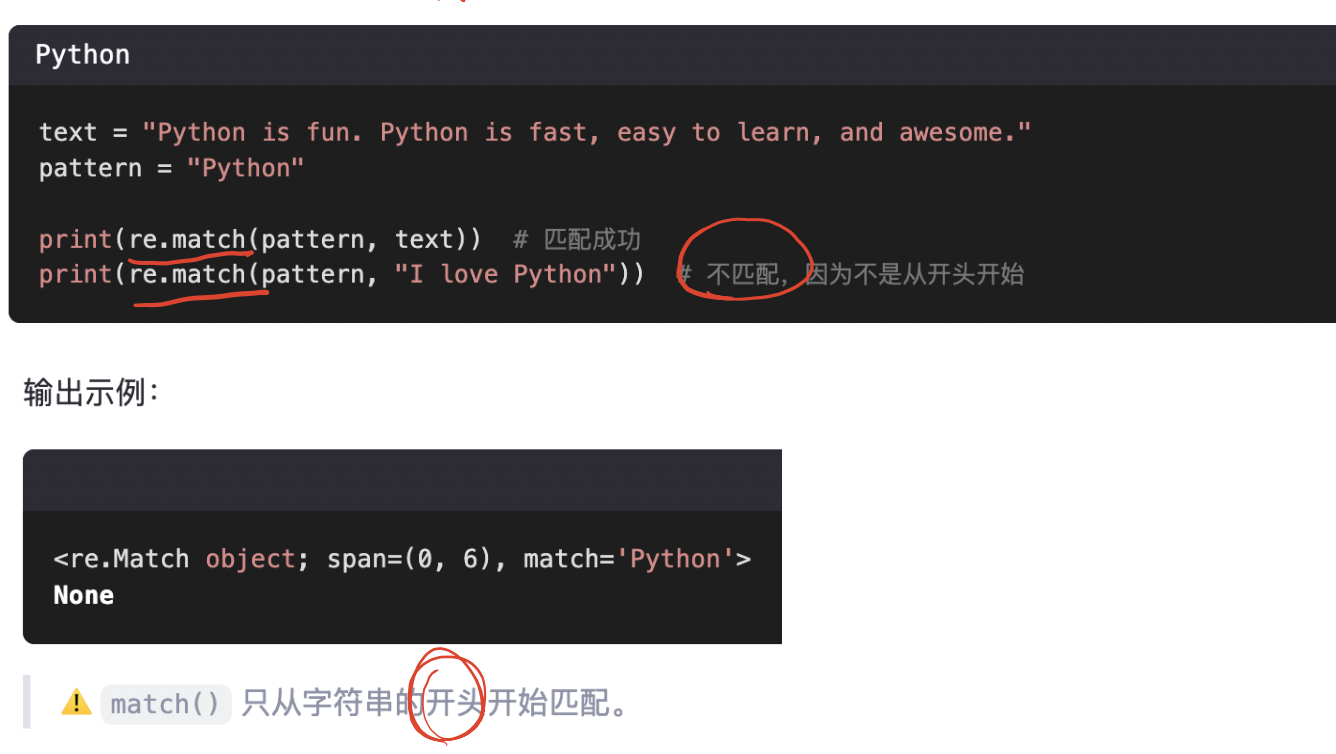
match函数实现的是精准匹配,尝试从字符串的开头匹配模式,如果匹配成功,则返回一个匹配对象,否则返回None。
语法:
re.match(pattern, string)只在 字符串开头 尝试匹配
如果开头不匹配,就直接返回
None
示例:
1-2、re.search函数:返回匹配对象
search()可以在整个字符中查找第一个匹配项,而不仅仅是从开头!返回第一个匹配到的结果!
语法:
re.search(pattern, string)从 整个字符串 中找 第一个匹配
找到就返回
Match对象,没有就None
示例:

【小结】:re.match()函数 VS re.search()函数
re.match()和re.search()都是 只找第一个匹配,一旦找到就停止,不会继续往下找。如果你想要 所有匹配,就得用
re.findall()(直接得到 list)
re.finditer()(得到迭代器,能看位置等更多信息)
| 方法 | 从哪里开始找 | 找到一个后 | 常见用途 |
|---|---|---|---|
re.match() |
从字符串 开头 开始匹配 | 停止,不再继续 | 检查开头是否符合格式(如校验手机号、日期) |
re.search() |
从字符串 任意位置 开始找 | 停止,不再继续 | 找字符串中 第一次 出现的匹配 |
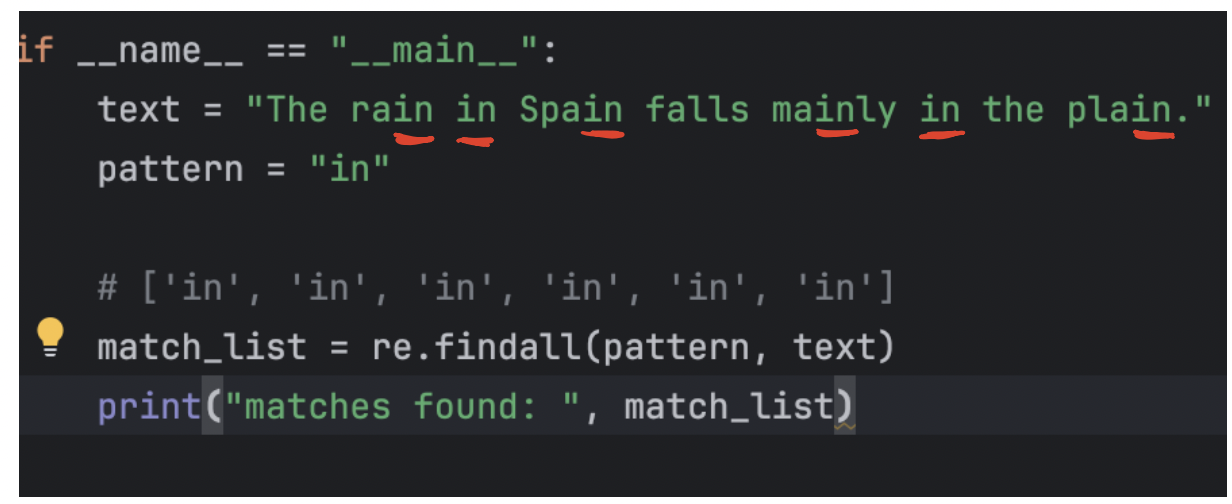
1-3、re.findall函数:直接返回 列表(list)
语法:
re.findall(pattern, string)找到 所有非重叠匹配的列表,直接返回 列表(
list)如果 pattern 中有分组,只返回分组匹配的内容
示例:
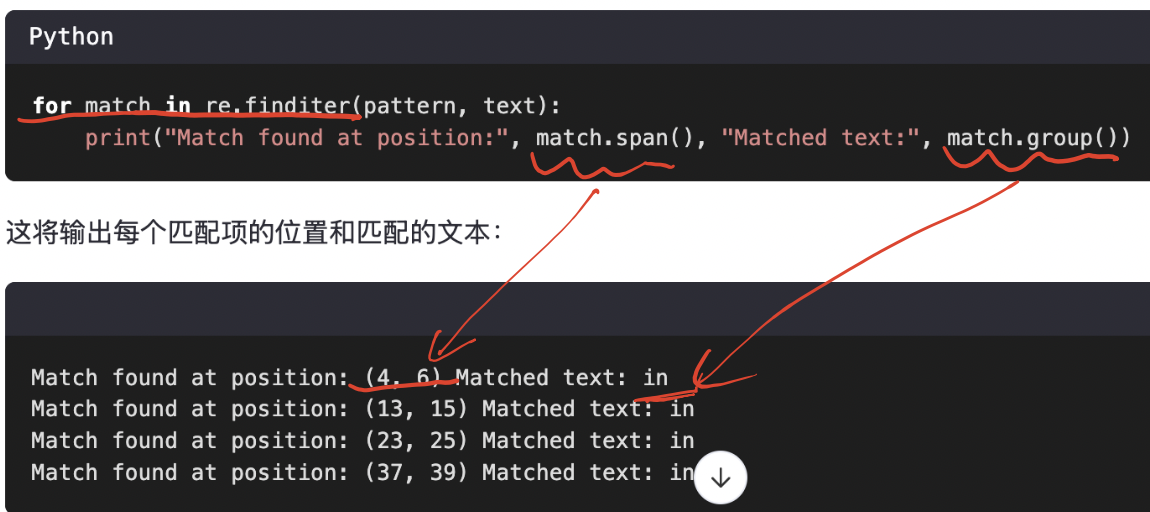
1-4、re.finditer函数:返回一个 迭代器
语法:
re.finditer(pattern, string)找到所有匹配,但返回的是一个 迭代器(每个元素是
Match对象)更适合需要匹配位置或懒加载的场景
若是你想遍历所有的匹配项,并且希望得到每个匹配项更多的信息(如:位置),可以使用re.finditer函数。
二、raw-string 格式(原始字符串)
1. 什么是 raw-string
Python 普通字符串中,
\是 转义符"\n"代表换行"\t"代表制表符
在 raw-string(原始字符串)中,
\不会被当作转义符,而是原样保留写法是在字符串前加
r或R:
s1 = "a\nb"
s2 = r"a\nb"
print(s1) # a 换行 b
print(s2) # a\nb
2. 为什么正则特别需要 raw-string
正则表达式里 反斜杠 \ 本身就是语法的一部分(比如 \d, \w, \s 等),
如果不用 raw-string,就得写双反斜杠来避免 Python 把它当作转义符。
例子:
import re
# 不用 raw-string
pattern1 = "\\d+" # Python 字符串先转义成 \d
print(re.findall(pattern1, "a123b")) # ['123']
# 用 raw-string
pattern2 = r"\d+" # \d 原样传给正则引擎
print(re.findall(pattern2, "a123b")) # ['123']
结果是一样的,但 raw-string 更直观,省得到处写 \\。
3. 什么时候不能用 raw-string
raw-string 里最后一个字符不能是单个反斜杠:
r"abc\" # ❌ 会报错
因为 Python 语法本身需要 \ 转义引号,raw-string 也要遵守。
4. 总结
| 写法 | Python 看到的内容 | 适合场景 |
|---|---|---|
"\\d+" |
\d+ |
正则,但写法麻烦 |
r"\d+" |
\d+ |
正则推荐写法 |
建议你记成一句话:“写正则时,前面加个 r,少写反斜杠,多活十年。”
三、常用正则表达式常见的符号
3-1、匹配单个字符
| 字符 | 功能 | |
| . | 匹配除换行符\n以外的任意单个字符。 | |
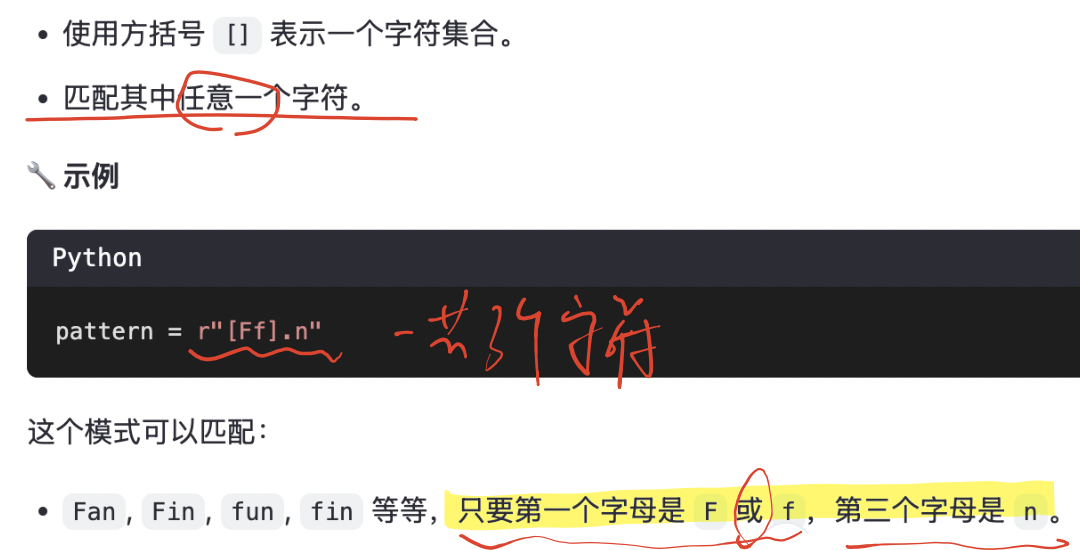
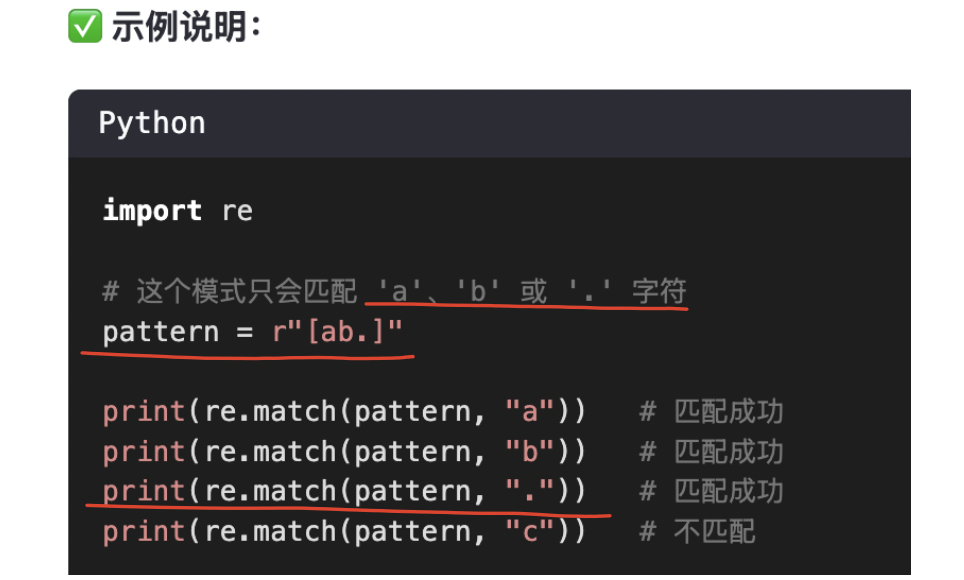
| [ ] | 匹配[ ]中列举的字符 | [abc]: 匹配 a 或 b 或 c 中的一个字符
|
| [^ ] | 匹配不是[ ]中列举的字符 | [^abc]:匹配 不是 a/b/c 的一个字符 |
| \d | 匹配数字 | 等价于:[0-9] |
| \D | 匹配非数字 | 等价于:[^0-9] |
| \s | 匹配空白符(空格、制表符\t、换行\n,换页\f、回车\r 等) | 等价于:[ \t\n\r\f\v] |
| \S | 匹配非空白字符 | [^ \t\n\r\f\v] |
| \w | 匹配单词字符(字母、数字、下划线) | [a-zA-Z0-9_] |
| \W | 匹配非单词字符 | [^a-zA-Z0-9_] |
记忆技巧
d→ digit(数字)
s→ space(空格)
w→ word(单词字符)大写版本(
\D \S \W)就是取反
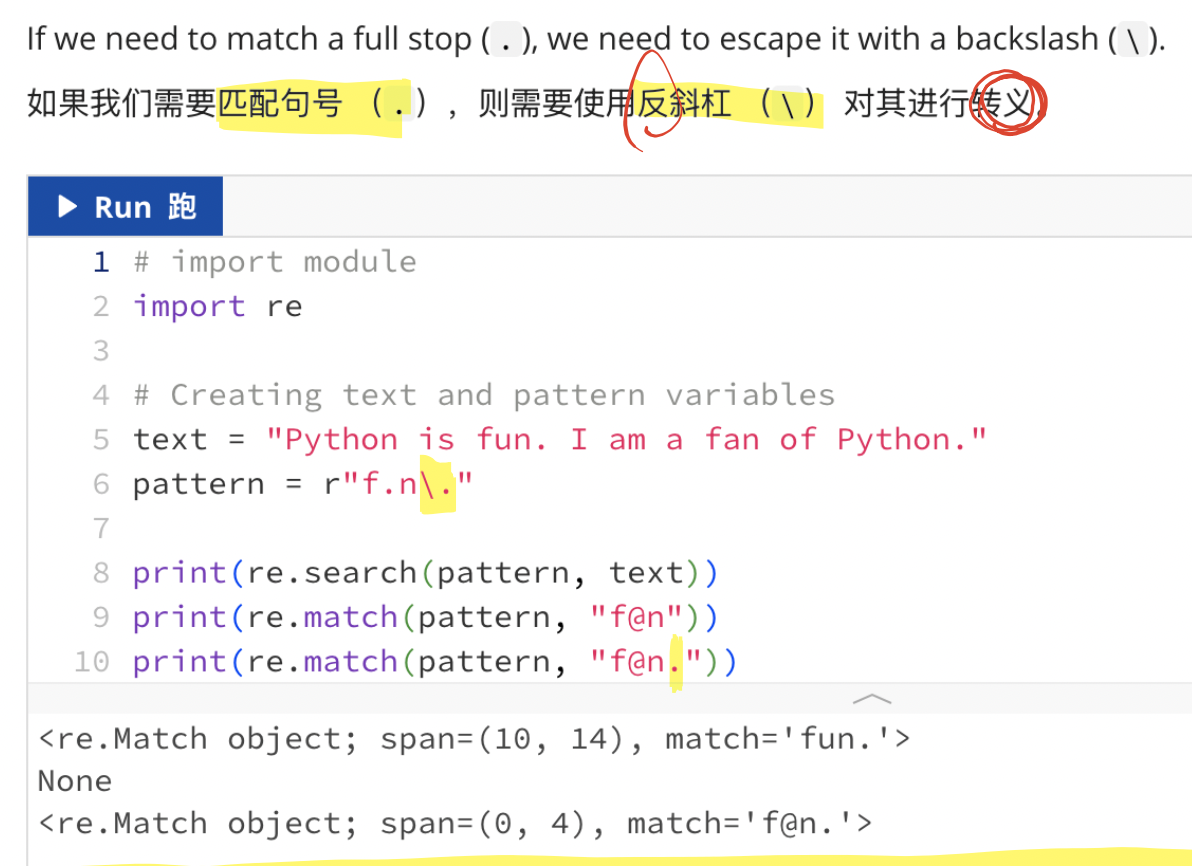
1、.(点号)
匹配除换行符\n以外的任意单个字符。
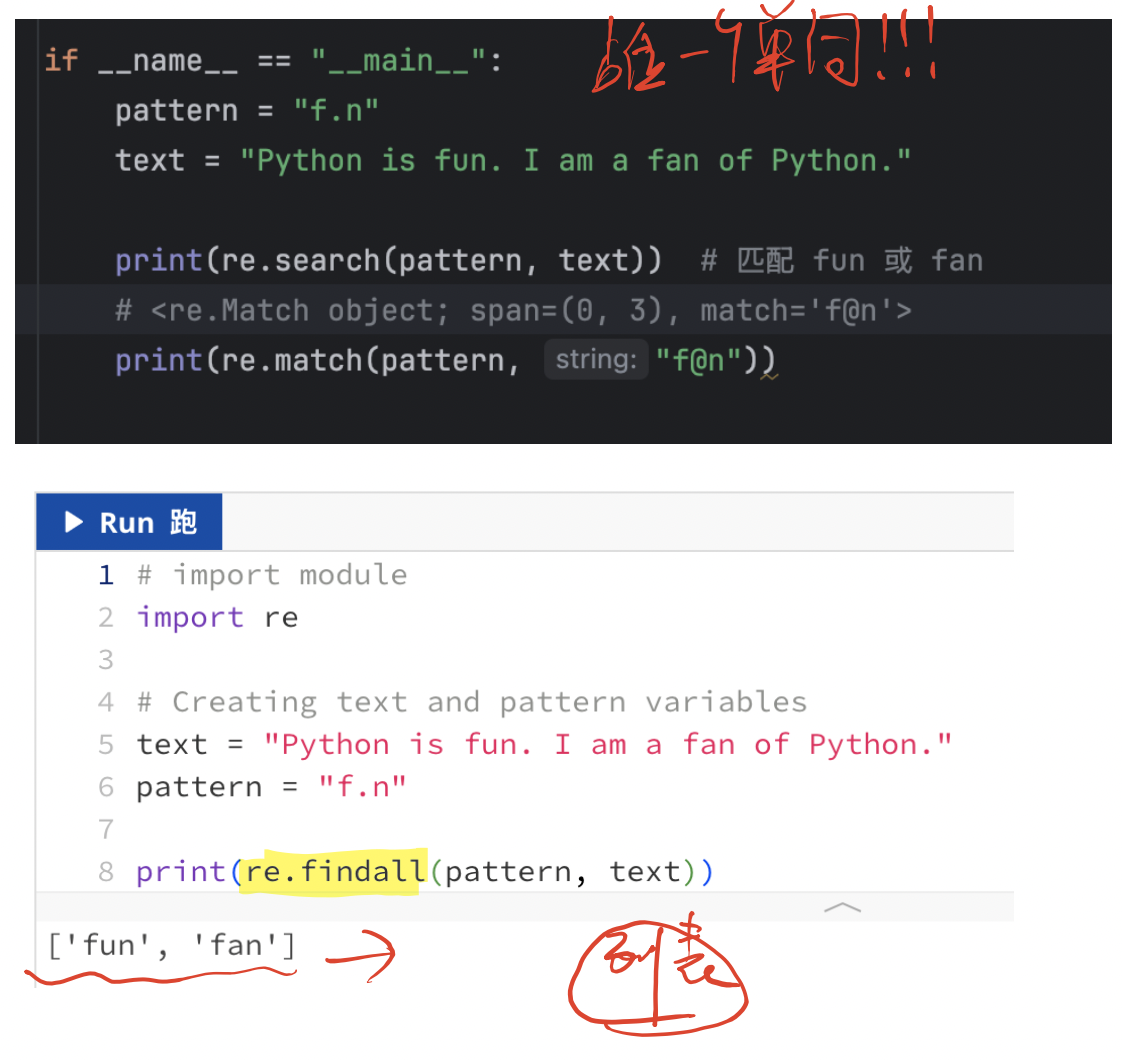
【注意】:
2、匹配一组字符:[ ]
【注意】:

【注意1】:
在 正则表达式 里,方括号 [ ] 不是用来表示数值范围的,而是用来表示 “字符集合”。
正则里的 [] 永远是匹配单个字符:
[abc]→ 匹配a或b或c中的一个字符[0-9]→ 匹配 0 到 9 中的一个数字字符[50-99]→ 不是匹配两位数,而是:匹配
5或匹配 0~9 之间的单个数字字符,实际等价于
[0-9],只是多写了个5,没啥区别。
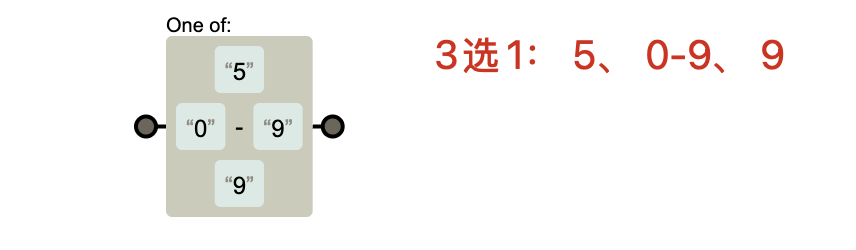
如果你要匹配 50 到 99 的数字,不能用 [50-99],而是:
5[0-9]|9[0-9] # 两位数写法【记住】:
[ ]→ 字符集合,一次只匹配一个字符!!!!
【注意2】:
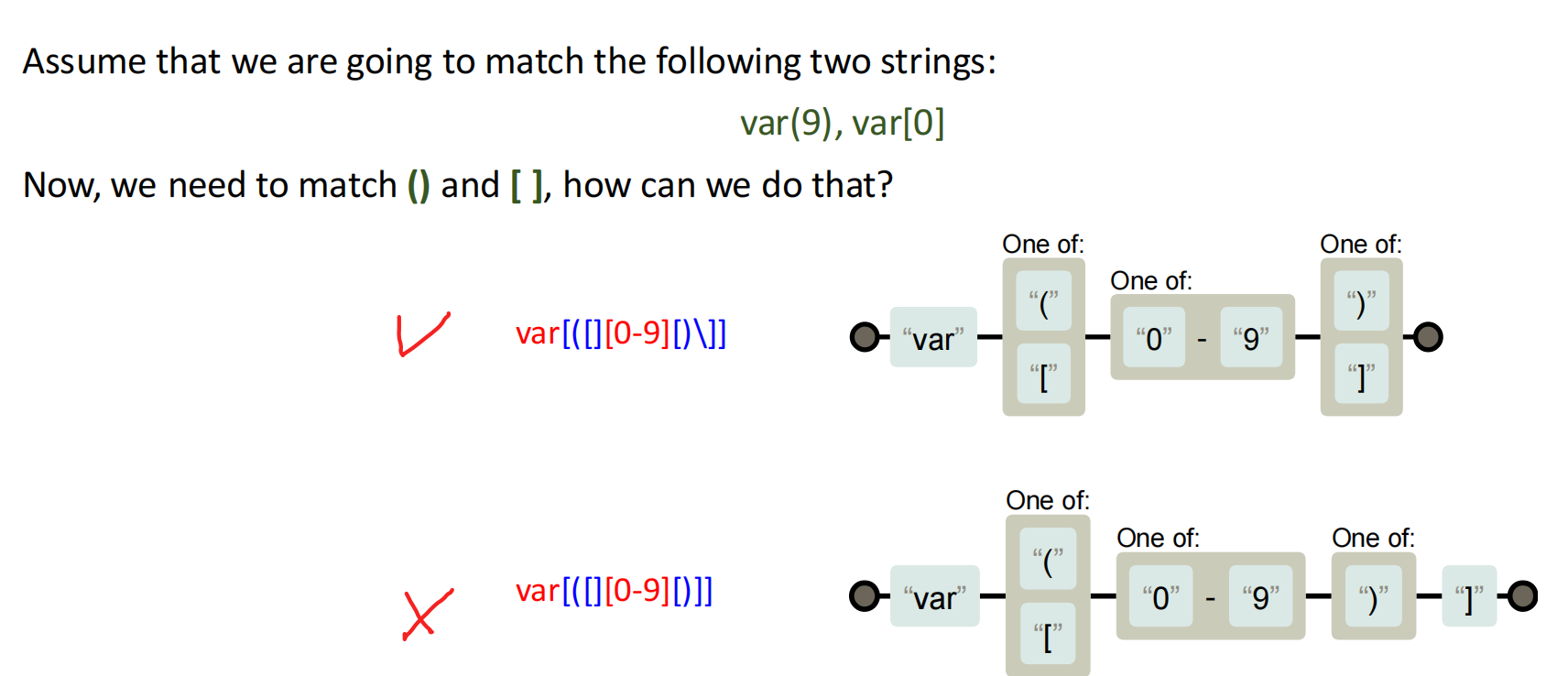
]在集合里如果不是第一个字符,需要用\]转义,否则会被当作结束方括号。
3、排除一组字符[^...]

4、匹配一组范围:[x-z]
5、综合练习

3-2、匹配多个字符
| 数量词 | 含义 | 示例 | 匹配效果(字符串 "aaab") |
|---|---|---|---|
* |
0 次或多次 | a* |
'aaa' |
+ |
1 次或多次 | a+ |
'aaa' |
? |
0 次或 1 次 | a? |
'a' |
{n} |
恰好 n 次 | a{2} |
'aa' |
{n,} |
至少 n 次 | a{2,} |
'aaa' |
{n,m} |
n 到 m 次 | a{1,3} |
'aaa' |
以上这些字符也称为量词!
在正则表达式里,数量词(Quantifier)就是用来描述 某个模式重复出现多少次 的符号。
1、*和+
- *:匹配前⼀个字符出现 0次或者多次;(>= 0)
- +:匹配前⼀个字符出现 一次或者多次。(>= 1)
示例:
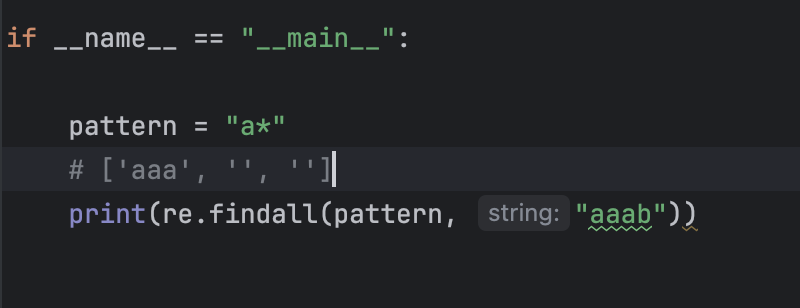
结果分析:
a*表示:匹配 零个或多个连续的a可以匹配空字符串(零个
a)
| 起始位置(index) | 当前字符 | a* 匹配结果 |
说明 |
|---|---|---|---|
| 0 | 'a' |
'aaa' |
从开头连续匹配了 3 个 'a',停在 index=3(字符 'b' 之前) |
| 3 | 'b' |
'' |
'b' 不是 'a',匹配 0 个 'a'(空字符串) |
| 4 | 结束 | '' |
到了字符串末尾,匹配 0 个 'a'(空字符串) |
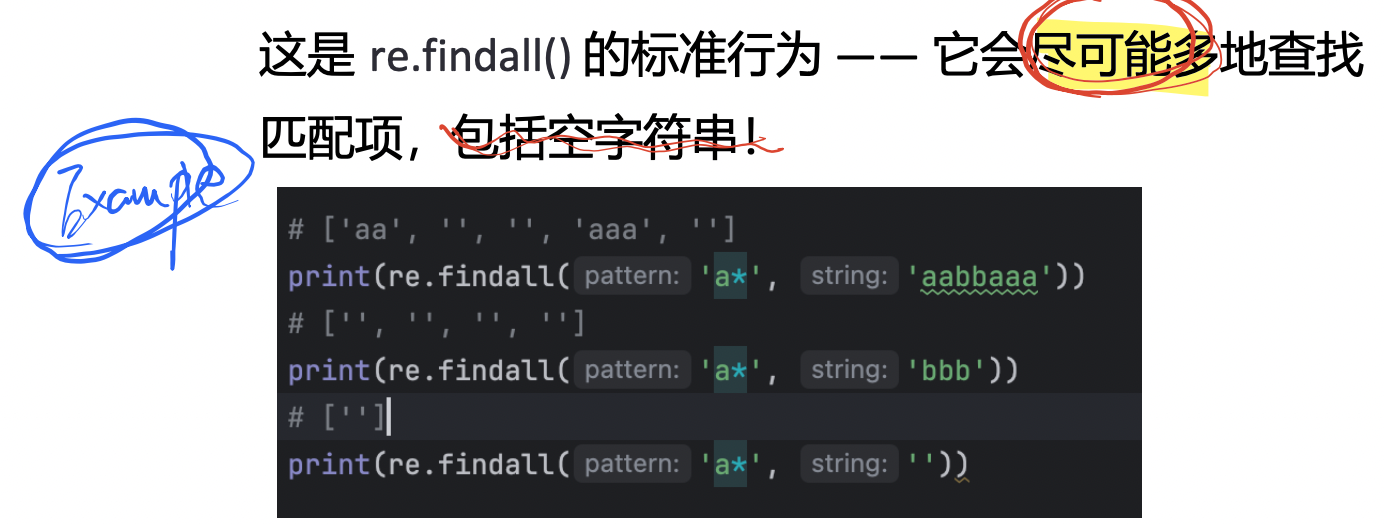
如果不想要空匹配,可以改成 a+(至少一个 a):
import re
pattern = "a+"
print(re.findall(pattern, "aaab")) # ['aaa']【注意】:
.*表示“匹配任意数量的任意字符(除了换行)
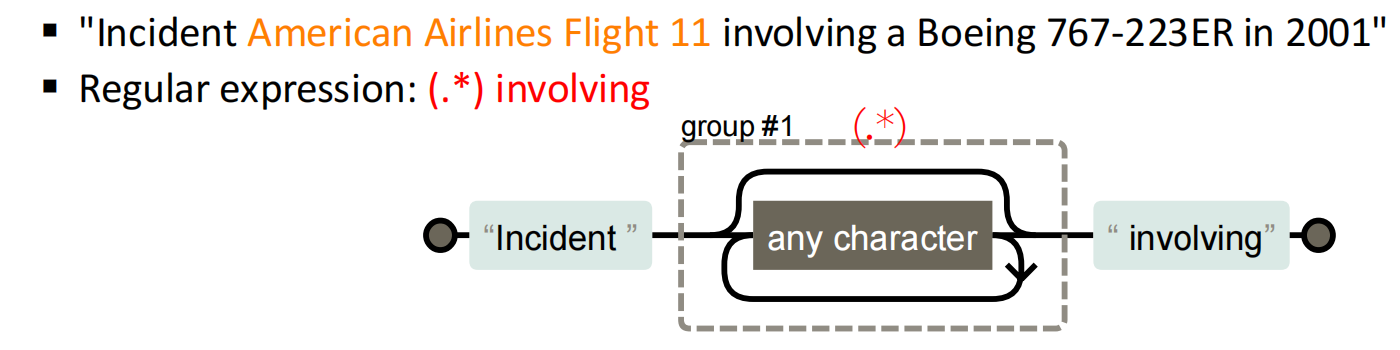
2、?(问号)
匹配前⼀个字符出现1次或者0次,即要么有1次,要么没有。
示例:

【小结】:+、*、?

3、{m, n}
匹配前⼀个字符出现从m到n次。
m必须要有,但是可以是0;
n是可选的,若省略n,则{m, }匹配m到无限次。
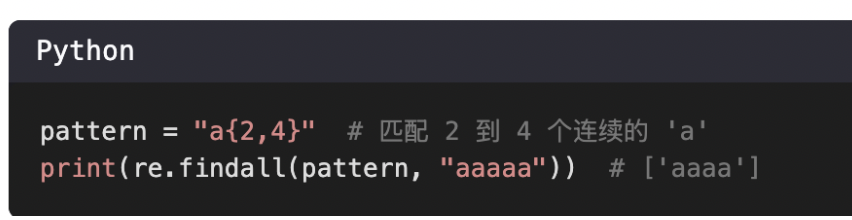
{m, n}是贪婪匹配,尽可能多的匹配。
3-3、贪婪匹配和⾮贪婪匹配
Python⾥数量词默认是贪婪的(在少数语⾔⾥也可能是默认⾮贪婪),总是尝试匹配尽可能多的字符;⾮贪婪则相反,总是尝试匹配尽可能少的字符。
| 贪婪量词 | 非贪婪量词 | 含义 |
|---|---|---|
* |
*? |
0 次或多次 |
+ |
+? |
1 次或多次 |
? |
?? |
0 次或 1 次 |
{m,n} |
{m,n}? |
m 到 n 次 |
记住规律:只要在量词后面加 ?,就变成非贪婪(懒惰)模式。

示例:

3-4、匹配开头结尾
| 字符 | 功能 |
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
在 Python 正则里,匹配开头和结尾主要用两个锚点(Anchor):
1. ^ —— 匹配开头
匹配字符串的开始位置
如果开启了
re.MULTILINE,还会匹配每一行的开头
例子:
import re
s = "hello\nworld"
print(re.findall(r"^h", s))
# ['h'] → 只匹配整个字符串的开头
print(re.findall(r"^w", s, re.MULTILINE))
# ['w'] → 匹配第二行的开头,因为 MULTILINE 模式
【注意】:

2. $ —— 匹配结尾
匹配字符串的结束位置
如果开启了
re.MULTILINE,还会匹配每一行的结尾
例子:
print(re.findall(r"d$", s))
# ['d'] → 只匹配整个字符串的结尾
print(re.findall(r"o$", s, re.MULTILINE))
# ['o'] → 匹配第一行的结尾
3. 常用组合
| 模式 | 含义 | 示例 |
|---|---|---|
^abc |
以 "abc" 开头 |
"abc123" ✅, "1abc" ❌ |
abc$ |
以 "abc" 结尾 |
"123abc" ✅, "abc1" ❌ |
^$ |
匹配空字符串或空行 | 在 MULTILINE 模式下可匹配空行 |
4、综合应用:使用^...$实现完全匹配

四、替换函数
re.sub()和re.subn(),它们都是 Python 正则模块re里用来做替换的函数。
4-1、re.sub()函数
语法:
re.sub(pattern, repl, string, count=0, flags=0)
将string中所有匹配pattern的部分用repl替换掉。
pattern:正则表达式repl:替换的内容(字符串,或函数)string:原文本count:替换次数,默认0表示替换所有flags:正则匹配模式(re.IGNORECASE等)
示例:

4-2、re.subn()函数
语法:
re.subn(pattern, repl, string, count=0, flags=0)和
sub一样,也是替换,但它多返回一个替换次数。
返回值:一个 元组 (new_string, number_of_subs)
new_string:替换后的字符串number_of_subs:实际替换的次数。
五、好用的正则函数可视化的方法
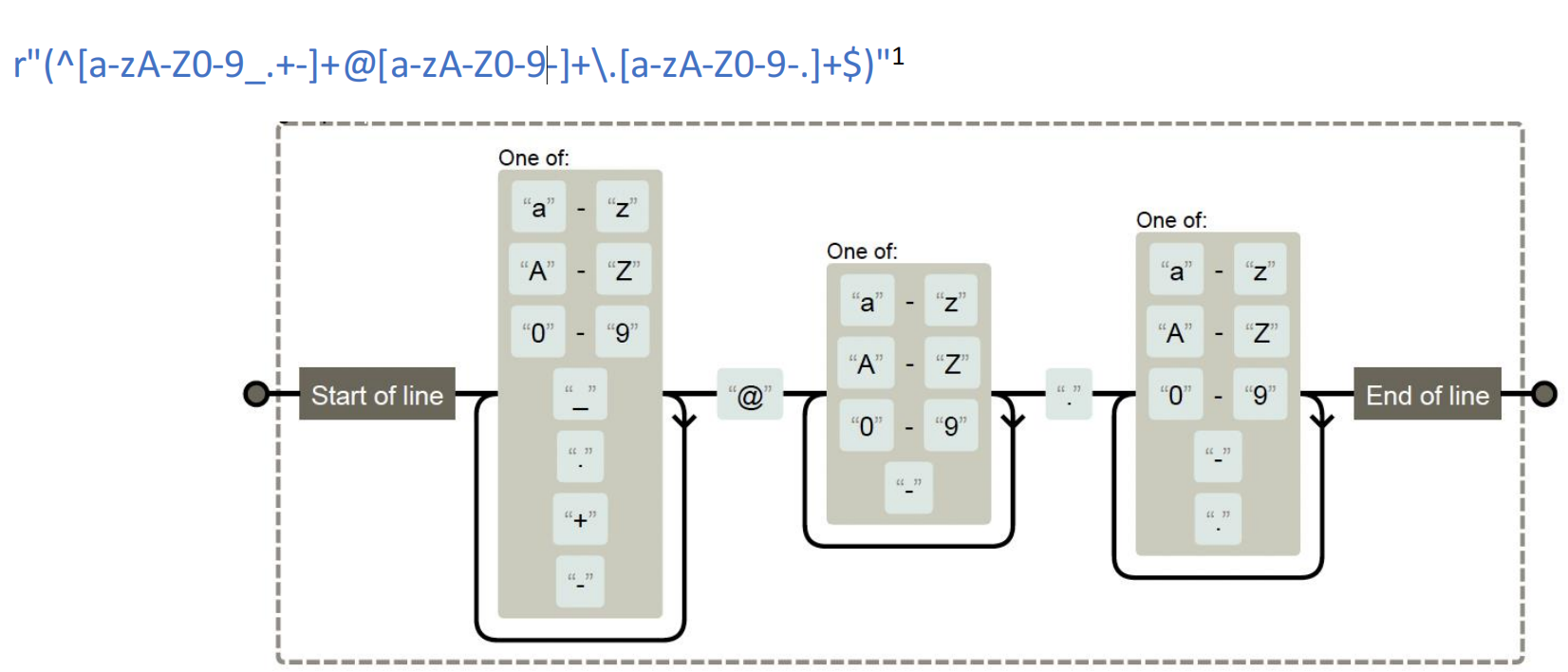
推荐使用检验网站:https://regexper.com/
【分析】:
这个正则是一个 邮箱地址的匹配模式:
(^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$)
1. 外层括号 ( … )
把整个邮箱模式放进一个捕获分组里(其实这里不分组也可以,只是会让
group(1)直接得到整个邮箱地址)。
2. ^
锚点:匹配字符串的开头位置。
这样保证邮箱必须从开头就符合这个模式,而不是出现在中间。
3. [a-zA-Z0-9_.+-]+
字符集:匹配邮箱用户名(@ 前面)的合法字符。
a-z→ 小写字母A-Z→ 大写字母0-9→ 数字_ . + -→ 下划线、点、加号、减号
+→ 匹配 1 次或多次(不能为空)。
4. @
字面量
@符号,分隔用户名和域名。
5. [a-zA-Z0-9-]+
匹配域名第一部分(@ 后、
.前)允许字母、数字和
-+→ 至少一个字符。
6. \.
\.匹配一个 字面量点.(因为普通的.在正则里是“任意字符”,要用反斜杠转义才能表示“点”)。
7. [a-zA-Z0-9-.]+
匹配域名后缀部分,比如:
comco.ukxn--fiqs8s(国际化域名 punycode)
包含:
字母
a-zA-Z数字
0-9点
.减号
-
+→ 至少一个字符。
8. $
锚点:匹配字符串的结尾位置。
确保整个字符串正好是邮箱,而不是包含邮箱的长文本。
9. 总结匹配规则
这个正则匹配的邮箱格式类似:
用户名@域名.后缀
示例匹配成功:
test.email+alex@leetcode.com
user_name@my-domain.co.uk
示例匹配失败:
test@.com # 域名第一部分为空
test@domain # 缺少点和后缀
六、分组(...)
1. 分组是什么
( ... ) 就像数学里的括号,把里面的正则看作一个整体。
它不会像字符集
[ ... ]那样只是“列出单个可选字符”,而是把一个完整的子模式包起来。这样你可以:
整体重复(数量词作用在整个括号上)
整体作为一个单位处理
捕获里面的内容(匹配结果可以取出来)
2. 整体重复的例子
假设你想匹配:
ab abab ababab
不能直接用 ab+,因为 + 只会让 b 重复,而不是 ab 整体重复。
你需要:
(ab)+
解释:
(ab)→ 把a和b作为一个整体+→ 重复这个整体一次或多次
匹配效果:
(ab)+ → "ab", "abab", "ababab"
3. 捕获分组
分组会把匹配到的内容存起来,方便后续使用。
例子:
import re
m = re.match(r"(ab)+(\d+)", "abab123")
print(m.group(1)) # ab
print(m.group(2)) # 123
说明:
第一个
(ab)+里的ab是捕获组 1第二个
(\d+)是捕获组 2你可以用
.group(n)取出对应的匹配内容
4. 不能放进字符集 [ ... ]
方括号 [ ... ] 是“字符集合”,它只能写单个字符或字符范围,不能在里面放一个完整的分组:
[ (ab) ] ❌ 会被当作匹配字符 '('、'a'、'b'、')'
(ab) ✅ 这是分组,能当一个整体用
5. 小总结
| 功能 | 举例 | 说明 |
|---|---|---|
| 作为整体 | (ab)+ |
+ 作用在整个 ab 上 |
| 捕获内容 | (ab)(\d+) |
可以用 .group(1)、.group(2) 取出 |
| 提高可读性 | `(?:abc | def)` |
| 不能在字符集里 | [()] |
只能匹配 ( 或 ) 这样的单个字符 |
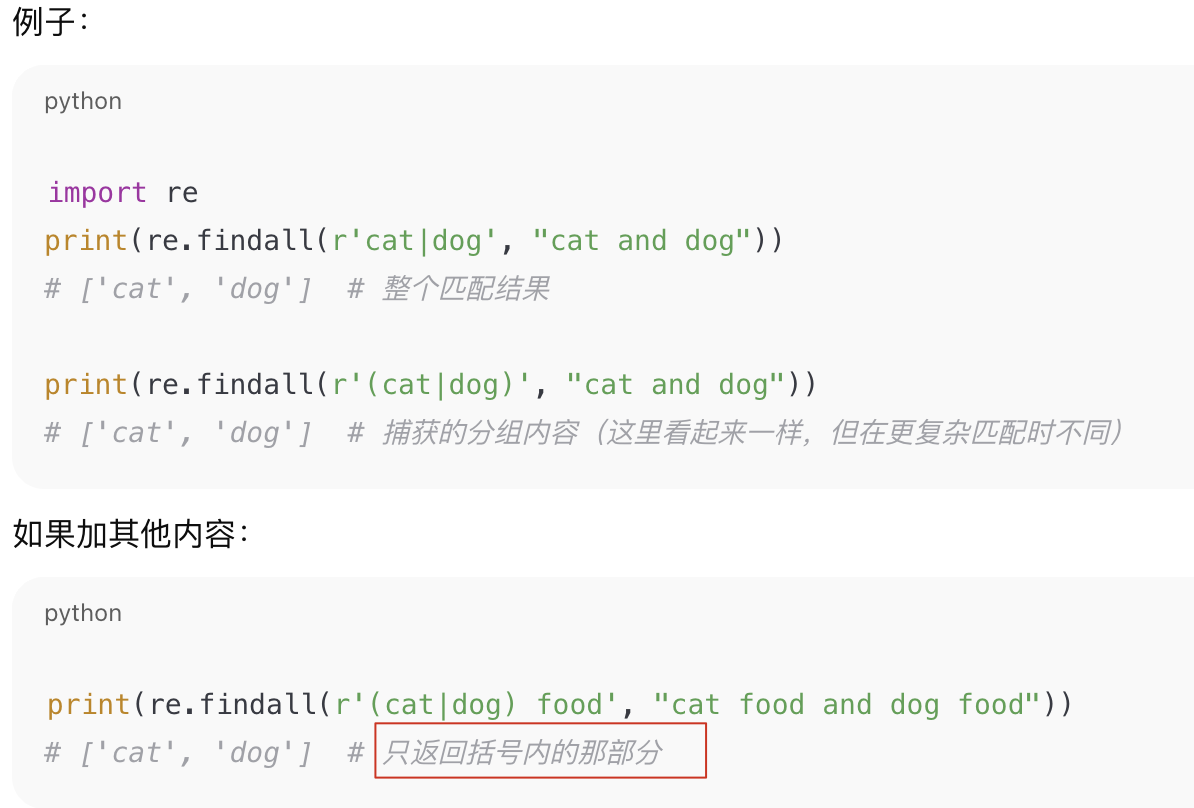
七、Alternation(交替匹配)|
1. 基本概念
|在正则中是**“或”**运算符(OR)。A|B会匹配 A 或 B 任意一个能匹配成功的模式。
例子:
apple|orange
匹配 "apple" 或 "orange"。
2. 匹配顺序(优先级)
从左到右匹配,第一个能匹配的就用它,不会去尝试右边的。
这叫左侧优先(leftmost precedence)。
例子:
cat|cater
匹配 "cat" 时就会停,不会去匹配 "cater",因为 "cat" 在左边先匹配成功了。
3. 多个模式可连续连接
你可以把很多模式用
|串起来,比如:
dog|cat|bird
匹配 "dog"、"cat" 或 "bird"。
4. 用括号分组以避免歧义
如果直接写:
apple|orange juice
它匹配的是 "apple" 或 "orange juice",并不会匹配 "apple juice"。

如果你想让
"juice"在两种水果后面都适用,需要用分组:
(apple|orange) juice
匹配 "apple juice" 和 "orange juice"。
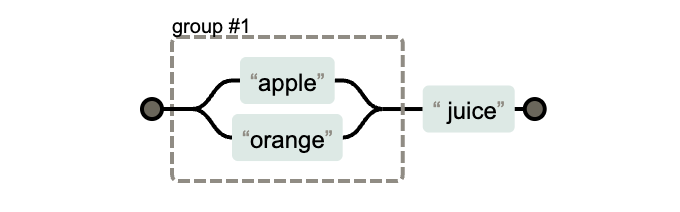
【注意】:
|左右是整个模式,所以哪怕有空格,它也会把空格算进匹配里。
5. 例子解析
apple|orange→"apple"或"orange"(apple|orange) juice→"apple juice"或"orange juice"w(ei|ie)rd→"weird"或"wierd"(括号内是两个可选的字母组合)
要点总结
| 写法 | 含义 | 注意事项 |
|---|---|---|
A|B |
逻辑 OR(交替),findall 不会单独返回捕获值 |
左侧优先 |
(A|B) |
分组交替,捕获分组,findall 会返回匹配的那一部分 |
括号能避免歧义 |
A|B|C |
多个交替 | 可以无限串联 |
八、re.compile 函数
在 Python 的 re 模块中,re.compile() 函数用于将正则表达式模式编译为一个正则表达式对象(RegexObject),以便后续重复使用。
这种编译操作可以提高正则表达式的匹配效率,尤其适合需要多次使用同一模式的场景。
1、基本语法
re.compile(pattern, flags=0)
pattern:必填,字符串类型的正则表达式模式。flags:可选,用于修改正则表达式行为的标志(如忽略大小写、多行模式等)。
主要作用
提高效率:
当同一个个正则表达式需要被多次使用时(例如在循环中匹配),提前用re.compile()编译可以避免重复解析模式,从而提升性能。复用正则对象:
编译后返回的正则对象可以直接调用match()、search()、findall()等方法,语法更简洁。
2、使用示例
示例 1:基础用法
import re
# 编译正则表达式(匹配邮箱格式)
pattern = re.compile(r'\w+@\w+\.\w+')
# 使用编译后的对象进行匹配
text1 = "我的邮箱是test@example.com"
text2 = "联系我:abc123@gmail.com"
# 查找匹配项
print(pattern.findall(text1)) # 输出:['test@example.com']
print(pattern.findall(text2)) # 输出:['abc123@gmail.com']
示例 2:使用标志(flags)
常用标志包括:
re.IGNORECASE(re.I):忽略大小写匹配。re.MULTILINE(re.M):多行模式,使^和$匹配每行的开头和结尾。
import re
# 忽略大小写匹配 "hello"
pattern = re.compile(r'hello', re.IGNORECASE)
print(pattern.findall("Hello World")) # 输出:['Hello']
print(pattern.findall("HELLO Python")) # 输出:['HELLO']
与直接使用函数的区别
不编译模式时,也可以直接使用 re.findall(pattern, text) 等函数,但本质上这些函数内部会隐式编译模式。因此:
- 单次使用:两种方式效率差异不大。
- 多次使用:
re.compile()编译后复用的方式更高效。
总结
re.compile() 是优化正则表达式性能的重要工具,尤其适合在循环或批量处理中重复使用同一模式的场景。编译后的正则对象提供了与 re 模块函数对应的方法(如 match()、search()),使用起来更加灵活。
好的,我们来翻译并讲解这一段 “The Backslash Plague” 的意思。
九、反斜杠灾难(The Backslash Plague)
反斜杠
\用来表示特殊形式(special forms),或者让特殊字符失去它原本的特殊含义(转义)。因此,如果要在正则表达式中匹配一个真正的反斜杠,你必须写成
'\\\\'作为正则表达式字符串。那么,我们能不能简化这种写法呢?
这个“灾难”是因为反斜杠在 Python 字符串 和 正则表达式 里都被当作转义符号:
Python 字符串解析阶段
在普通字符串
"\\n"中,\\会被 Python 解析成一个反斜杠字符\,而\n则会被解析成换行符。所以如果你想在字符串里写一个“正则表达式里的反斜杠”,就得先把它在 Python 里转义成
\\。
正则表达式解析阶段
在正则里,反斜杠本身也有特殊含义,比如
\d是数字、\w是单词字符。如果你想匹配反斜杠本身,还得在正则层面再转义一次,所以是
\\(正则层面)。
叠加效果
在 Python 普通字符串里写正则匹配反斜杠,要写成:
"\\\\"前两层
\\→ Python 转义成\后两层
\\→ 正则转义成 “匹配一个反斜杠”
9-1、如何简化?
用 原始字符串
r"..."
pattern = r"\\"
这样:
Python 不会解析
\,直接把\\交给正则引擎只需要一层
\\表示“匹配一个反斜杠”
对比表
| 想匹配内容 | 普通字符串写法 | 原始字符串写法 |
|---|---|---|
一个反斜杠 \ |
"\\\\" |
r"\\" |
数字字符 \d |
"\\d" |
r"\d" |
点号 . |
"\\." |
r"\." |
十、捕获组(...)
用(...)括起来,希望匹配结果中提取出特定的部分。
10-1、不捕获组 VS 分组
所有的捕获组都是分组,但并不是所有的分组都是捕获组。
1. 分组(Grouping)
括号 () 在正则里的第一个作用就是把多个模式当作一个整体,方便:
改变运算优先级
给整个模式应用数量词(
*,+,{m,n}等)
例子:
import re
print(re.findall(r'(ab)+', "abababx")) # ['ab']
这里 (ab)+ 表示“ab 这个整体重复一次或多次”。
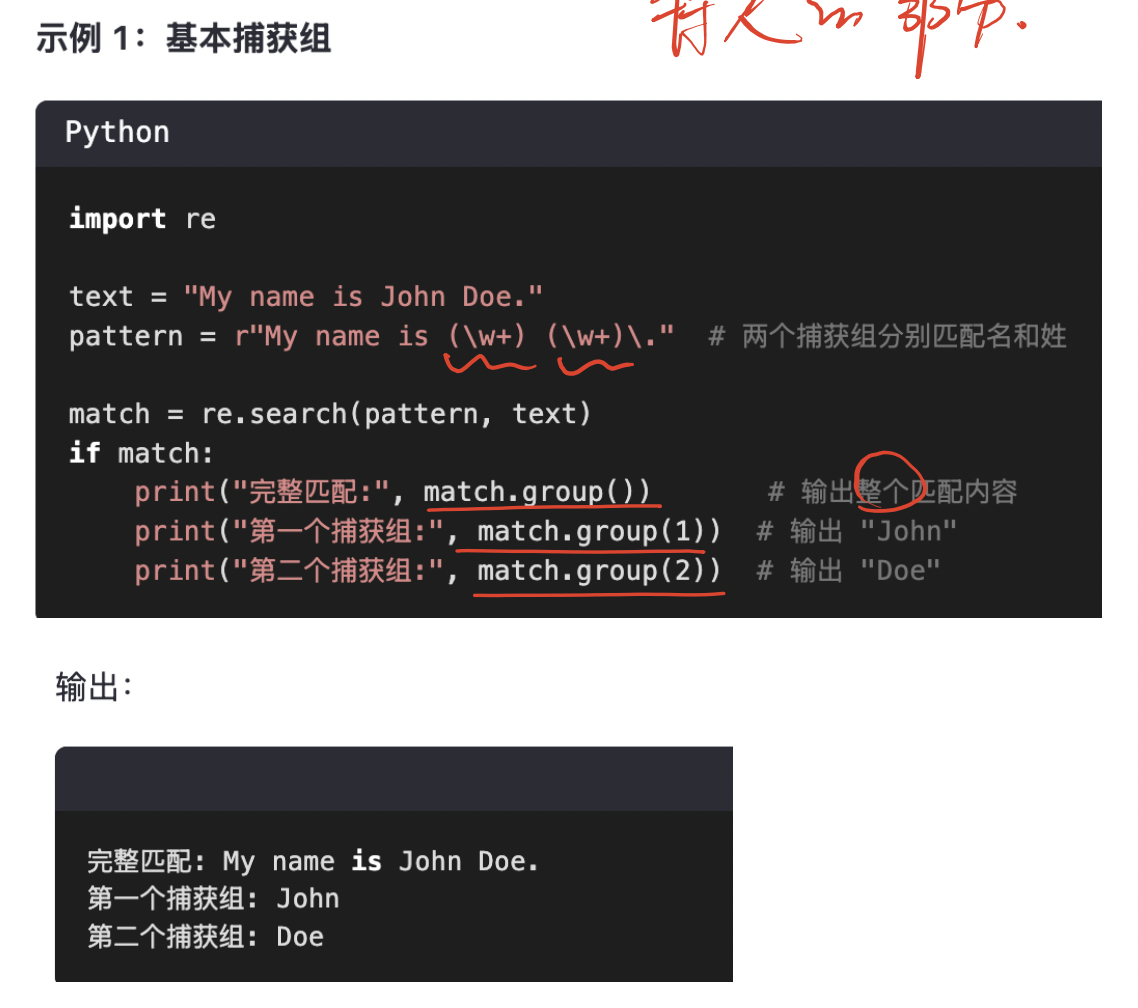
2. 捕获组(Capturing Group)
括号的第二个作用是捕获匹配到的内容,以便之后使用:
通过
re.findall()返回分组内容在
re.search()里用.group(n)获取在
re.sub()中通过\1,\2引用
例子:
示例字符串
text = "John Smith, Alice Brown"
目标:匹配 "名字 姓氏" 的模式,并把名字和姓氏分别作为分组。
1️⃣ 通过 re.findall() 返回分组内容
findall() 如果正则里有捕获组,会只返回组的内容(如果有多个组,就返回元组)。
import re
pattern = r"(\w+)\s+(\w+)" # 第1组=名字, 第2组=姓氏
matches = re.findall(pattern, text)
print(matches)
输出:
[('John', 'Smith'), ('Alice', 'Brown')]
每个元组
(group1, group2)对应一次匹配的两个分组内容。
2️⃣ 在 re.search() 里用 .group(n) 获取
search() 只找第一个匹配,.group(0) 是整个匹配,.group(1) 是第1组,依此类推。
m = re.search(pattern, text)
print(m.group(0)) # 整个匹配:John Smith
print(m.group(1)) # 第1组:John
print(m.group(2)) # 第2组:Smith
输出:
John Smith
John
Smith
3️⃣ 在 re.sub() 中通过 \1, \2 引用
sub() 的替换字符串里,可以用 \1, \2 引用捕获组的内容。
result = re.sub(pattern, r"\2, \1", text)
print(result)
输出:
Smith, John, Brown, Alice
这里
\2是姓氏,\1是名字,所以替换成了 “姓, 名” 的形式。
总结表格
| 用法 | 获取方式 | 返回值特点 |
|---|---|---|
findall() |
返回列表 | 有分组时返回元组列表 |
search().group(n) |
数字 n | 只获取第一个匹配,0 是全部 |
sub() 替换字符串 \n |
反斜杠加组号 | 在替换时插入对应组内容 |
10-2. 非捕获组(Non-Capturing Group)
如果只想分组但不想捕获,可以用 (?:...)。这样括号只负责逻辑分组,不会把内容保存到组里:
import re
print(re.findall(r"(?:ab)+", "abababx")) # ['ababab']
不会产生 .group(1) 等捕获内容。
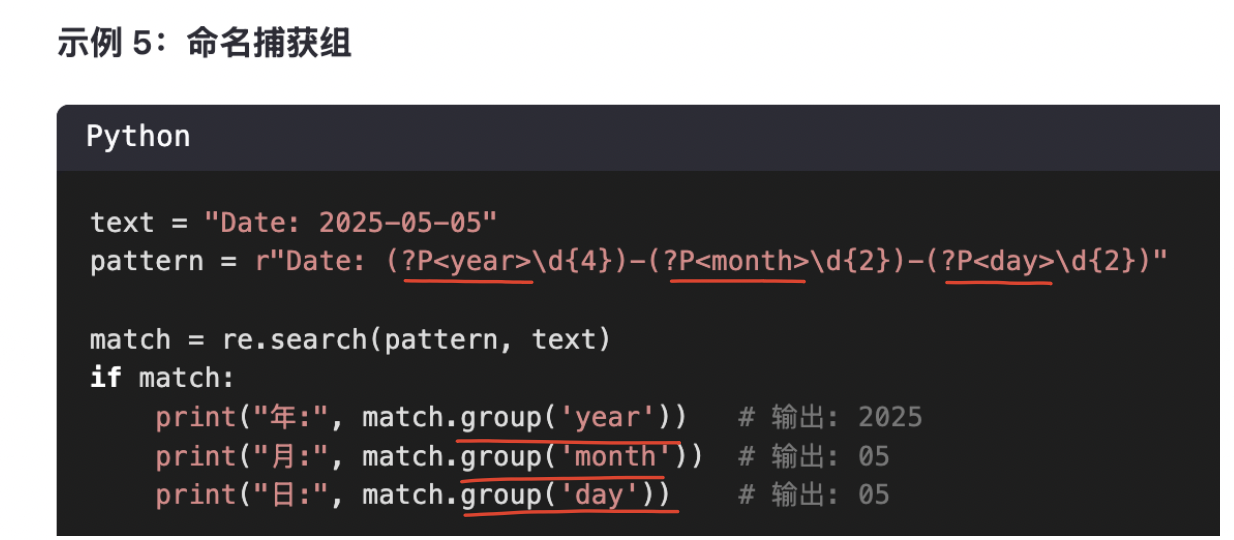
10-3、命名捕获组(?P<name>)
使用(?P<name>)给捕获组命名,然后在re.search()中,通过.group('name')引用
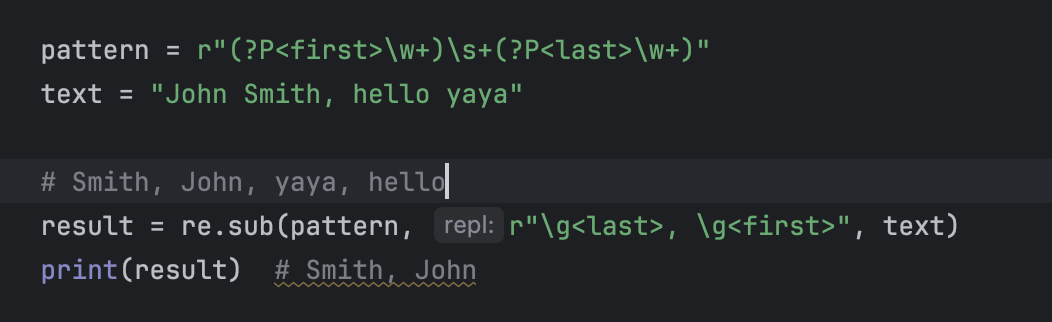
在re.sub()替换字符串里,可以用 \g<name> 来引用命名组(比数字引用更直观)。
总结
| 写法 | 是否分组 | 是否捕获 | 常用用途 |
|---|---|---|---|
( ... ) |
✅ | ✅ | 捕获内容、数量词作用范围 |
(?: ... ) |
✅ | ❌ | 仅用于逻辑分组 |
(?P<name>...) |
✅ | ✅(命名) | 捕获并用名字引用 |