public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = "ab";
}常量池最初是存在字节码文件里,当它运行时就会被加载到运行时常量池里(这时a b ab都是常量池中的符号,还没有变成java中的字符串对象)。
等到具体执行到这行代码时

就会找到a符号,把它变成“a”字符串对象
后会准备好一块区域StringTable[],把“a”作为key去StringTable(长度固定不能扩容的hashtable)中去找有没有取值相同的key,没有就会把“a”放入串池。
String s2 = "b";String s3 = "ab";类似。
String s4 = s1 + s2;
先创建一个StringBuilder对象,调用它的无参构造,aload_1拿到局部变量表中的“a”,作为append的参数。b类似,最后调用toString()方法。astore 4就是将转换后的结果存入4号局部变量。
toString()方法:

将拼接好的值又创建了一个新的值为“ab”对象,存人s4。
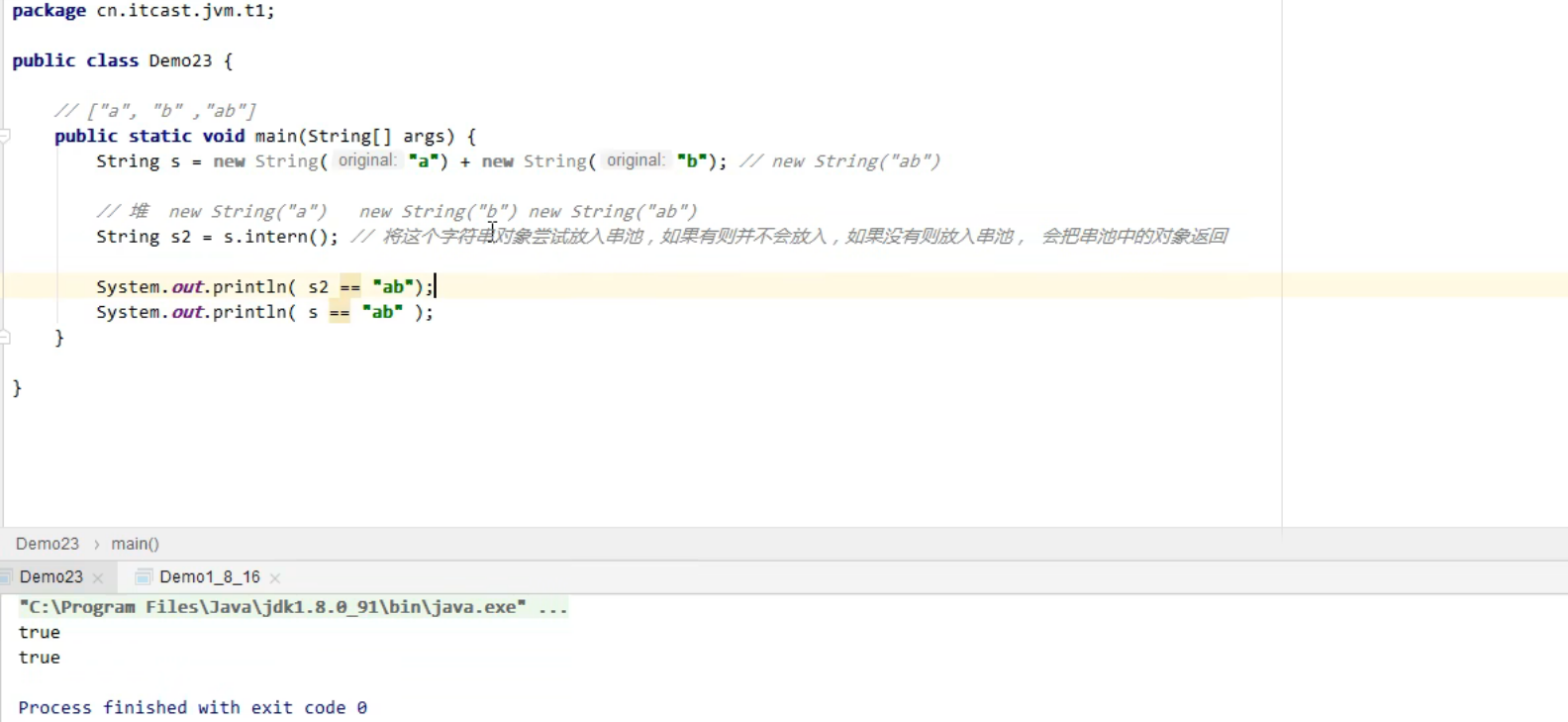
System.out.println( s3 == s4 ); 是true还是false呢?
s3是串池中的,s4是在堆中的,俩个不一样的对象为false。
String s5 = "a" + "b";
到常量池中找到值为“ab”的符号,就不会创建新的对象,延用并且存入局部变量表中值为5的位置
System.out.println( s3 == s5 ); 为true
这为javac在编译期间的优化,结果已经在编译期间确定为“ab”
而String s4 = s1 + s2;中s1和s2为变量,可能被修改,结果不能确定,所以必须在运行期间动态拼接。

jdk7以后
可以调用intern方法将这个字符串对象尝试放入串池
在 Java 7 及以后的版本中,intern() 方法做了优化。当调用 s.intern() 时,如果字符串常量池中不存在对应的字符串,会将堆中字符串对象的引用放入常量池,而不是重新创建一个对象。
所以这里 s 指向的堆中的 "ab" 字符串对象,和字符串常量池中的 "ab" 实际上是同一个对象(在 Java 7 及以后 ),因此 s == "ab" 的比较结果也为 true 。如果是在 Java 6 及以前版本,由于 intern() 方法会在常量池中创建新的字符串对象,那么 s 指向堆中的对象,和常量池中的 "ab" 是不同对象,s == "ab" 结果就会是 false 。
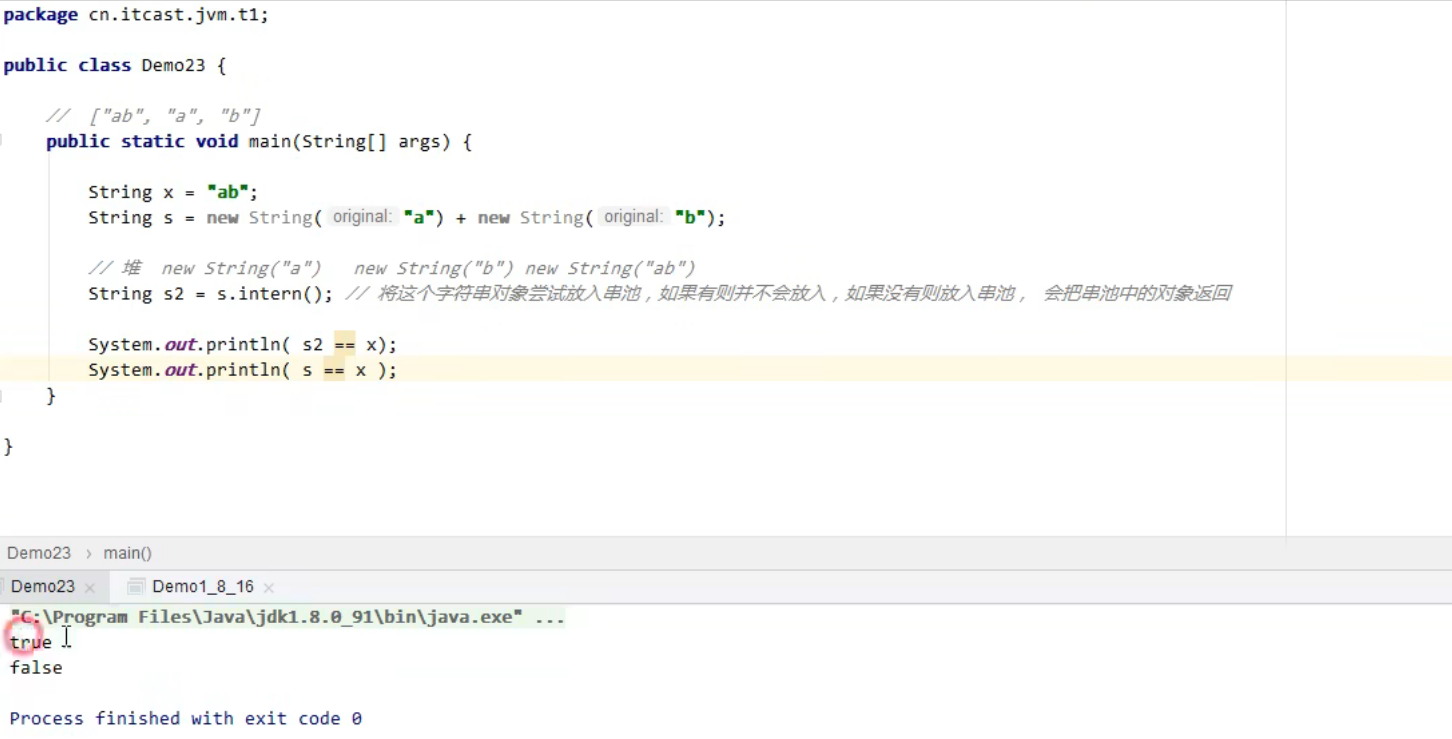
String x = "ab";:直接使用字符串字面值定义,"ab"会被 JVM 放入字符串常量池,x指向常量池中的该字符串对象。
String s = new String("a") + new String("b");:通过new创建字符串对象,"a"、"b"各自在堆内存生成对象,+操作实际由StringBuilder辅助完成,最终会在堆内存生成拼接后的新字符串对象(内容为"ab"),s指向堆里这个新对象。
System.out.println(s2 == x);:
s2是s.intern()返回的常量池引用,x本身就指向常量池的"ab",二者引用相同,所以结果为true。System.out.println(s == x);:
s指向堆内存中拼接产生的"ab"对象,x指向常量池的"ab"对象,二者内存地址不同,所以结果为false。
jdk6
在 JDK 6 中,字符串常量池位于永久代(PermGen),和堆内存是完全独立的内存区域。
- 用
new String("a")创建的对象,会直接在堆内存生成。 - 用
String x = "ab"这种字面值创建的字符串,会在永久代的常量池生成。 s.intern()的逻辑是:- 先去永久代的常量池找是否有内容匹配的字符串。
- 如果有,直接返回常量池中的字符串引用;
- 如果没有,会在常量池新增一个字符串对象(把堆里的字符串内容拷贝到永久代 ),再返回常量池中新对象的引用。
// 1. 字面值定义,"ab" 会直接在【永久代的常量池】生成对象,x 指向常量池的引用
String x = "ab";
// 2. new String("a") + new String("b") 的过程:
// - 先在堆里创建 "a"、"b" 两个对象;
// - 拼接时通过 StringBuilder 生成新的字符串,最终在【堆】里创建内容为 "ab" 的对象,s 指向堆里的这个对象。
String s = new String("a") + new String("b");
// 3. 调用 s.intern():
// - JDK 6 中,常量池(永久代)里还没有 "ab"(因为 x 的 "ab" 是在常量池,但这里要注意:x 的 "ab" 是程序启动时就有的吗?不,x 是代码里定义的,会触发常量池生成 "ab"? 不,等一下,代码执行顺序是:
// - 先执行 String x = "ab":此时常量池(永久代)会生成 "ab" 对象,x 指向常量池的引用。
// - 再执行 s = new String("a") + new String("b"):堆里生成拼接后的 "ab" 对象。
// - 然后执行 s.intern():去常量池找 "ab",发现已经存在(因为 x 已经触发常量池创建了 "ab"),所以 s2 直接返回常量池里 x 指向的引用。
String s2 = s.intern();
// 4. 比较 s2 == x:
// - s2 是常量池的引用,x 也是常量池的引用 → 地址相同 → 输出 true
System.out.println(s2 == x);
// 5. 比较 s == x:
// - s 指向【堆】里的 "ab" 对象,x 指向【永久代常量池】里的 "ab" 对象 → 地址不同 → 输出 false
System.out.println(s == x); 
总结
- 常量池特性
- 常量池中的字符串仅是符号,第一次用到时才变为对象
- 利用串池的机制,来避免重复创建字符串对象
- 字符串拼接原理
- 字符串变量拼接的原理是
StringBuilder(1.8) - 字符串常量拼接的原理是编译期优化
- 字符串变量拼接的原理是
intern方法- 作用:可以使用
intern方法,主动将串池中还没有的字符串对象放入串池 - JDK 1.8 行为:将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回
- JDK 1.6 行为:将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池,会把串池中的对象返回
- 作用:可以使用
StringTable位置
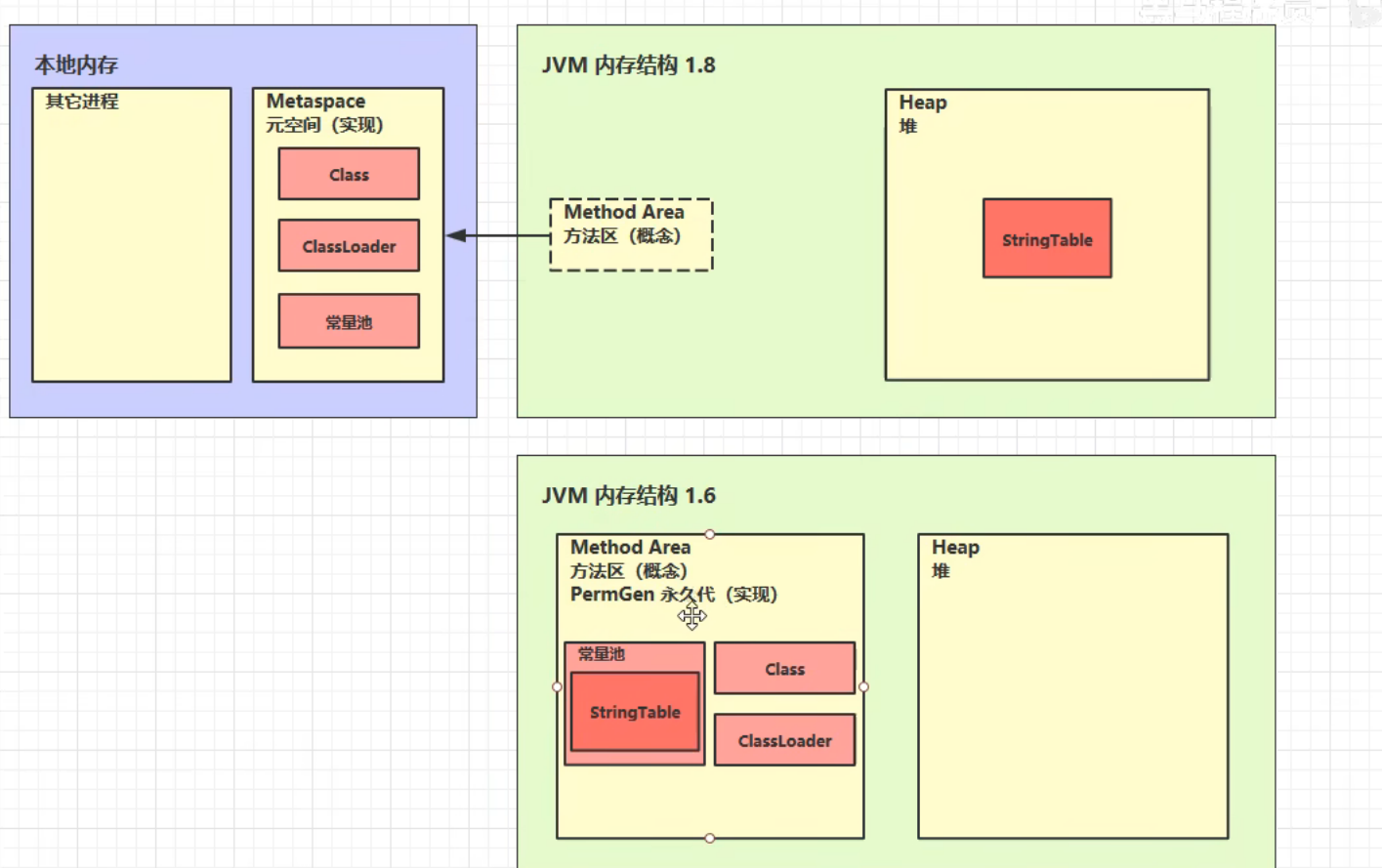
JDK1.6,StringTable用的非常频繁,永久代垃圾回收要在老年代Full GC时才触发,导致永久代垃圾回收效率并不高,占用大量内存。
调优
![]()
1. StringTable 的 HashTable 原理
StringTable 采用哈希表(HashTable)数据结构来存储字符串。当向 StringTable 中添加字符串时,会根据字符串的哈希值来确定其在哈希表中的存储位置。如果多个字符串的哈希值经过计算后,映射到了哈希表的同一个位置,就会产生哈希冲突,此时会通过链表(在 Java 8 中,当链表长度达到一定阈值后会转换为红黑树)来解决冲突。
2. 默认 HashTable 大小及问题
在 Java 8 及以后版本中,StringTable 的默认大小是 60013。当存储的字符串数量不断增加,接近或超过这个默认大小时,哈希冲突的概率就会显著上升。大量的哈希冲突会导致在查找字符串时,需要遍历更长的链表(或树结构),从而增加查找时间,降低性能。
3. 调整 HashTable 大小的方式
可以通过 JVM 参数 -XX:StringTableSize 来调整 StringTable 的大小
![]()
如果某些字符串会被大量重复使用(比如系统固定配置、枚举值、通用提示语 ),通过 intern 入池后,所有引用都会指向常量池同一份对象,能大幅减少堆内存占用,还能加速 == 比较(直接比引用 )。
若字符串是运行时动态拼接 / 生成(如业务编码、缓存 key ),但会被多次使用,可通过 intern 入池。
若字符串体积特别大(如几 MB 的文本 ),且仅用几次,入池反而可能浪费常量池空间(常量池回收难 )。这种场景不建议入池,让其在堆里按需创建、及时回收更合理。