华为作为全球领先的ICT(信息与通信)基础设施和智能终端提供商,自创立以来,始终坚持“以客户为中心”的核心理念,积极布局线下零售渠道,打造了覆盖全国的“华为旗舰店”及授权体验店销售网络。华为旗舰店不仅是高端产品展示与销售的重要窗口,更是集品牌形象传播、全场景产品体验、专业技术咨询与售后服务于一体的综合性服务平台,成为华为与消费者之间深度互动的重要纽带。华为秉持“构建万物互联的智能世界”的愿景,依托丰富的产品生态体系和强大的研发实力,结合线下门店统一的视觉形象与专业化的服务流程,为消费者提供智能化、场景化、一体化的科技生活解决方案。
在注重技术创新与产品品质的同时,华为旗舰店也高度重视空间设计的现代美学与用户体验的人性化表达。门店采用极简、开放、富有未来感的设计风格,融合灯光、材质与交互装置,营造出兼具科技感与亲和力的沉浸式购物环境,有效提升了消费者在探索与选购过程中的参与感与满意度。华为旗舰店广泛分布于全国一线及重点城市的高端商圈、核心商业街区与大型购物中心,形成了高密度、高品质的终端网络布局,有力支撑了品牌在消费市场的高端形象塑造与影响力拓展。
本文将探讨如何通过POST请求从官方网站或公开接口中获取华为旗舰店的分布信息,并展示使用Python的requests库发送HTTP请求的方法,以提取详细的门店位置数据。这些信息涵盖全国范围内的华为旗舰店及重点授权体验店,通过解析返回的JSON数据或HTML内容,实现对门店名称、地址、所在区域、营业时间、服务功能等关键字段的结构化提取。此类数据采集方式有助于深入分析华为在不同省市的渠道布局策略、市场渗透率及其与区域经济、人口分布的关联性。通过对门店数据的清洗与整理,还可为后续的地理空间可视化、商圈竞争力分析、渠道优化决策及新店选址预测提供坚实的数据支持。
华为旗舰店查询网站:华为旗舰店 - 华为官网
我们第一步先找到门店数据的存储位置,然后看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;
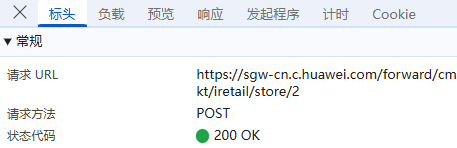
负载:对于POST请求:负载通常包含了传递的参数,因为所有参数都通过URL传递,这里我们可以看到省份每页允许输出的最大值、当前坐标、国家,距离等一些明文,没有进行加密;
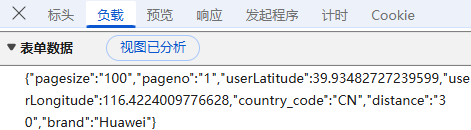
预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段;
接下来就是数据获取部分,先理解原理,完整的查询方式是通过定位坐标点查询周边30公里左右范围内华为旗舰店和智能生活馆,当然也包括其他第三授权店;
先讲一下方法思路,一共三个步骤;
方法思路
- 获取行政区最小外接多边形,生成行政区对应最小矩形;
- 基于六边形密铺生成查询点进行遍历查询,并保留查询得到的去重后的门店信息;
- 可视化,通过xy数据转点,把数据导入ArcGIS进行可视化;
第一步:首先,我们先获取一个城市行政区图层,接下来,我们需要获取这个行政区的最小外接多边形,arcgispro可以直接生成这个最小外接矩形,直接检索【最小边界几何】,几何类型选择【按面积矩形】或者【按宽度矩形】都可,看需求,组选型选【ALL】这样会基于全部结果形成最外层的矩形;
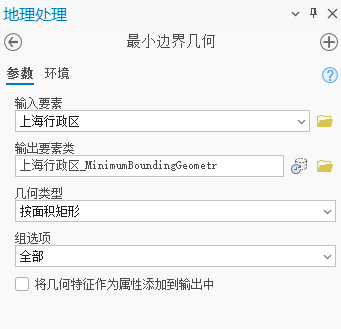
我们以上海市为例,最小外接多边形结果如下,我们把图层另存为新的shp;
接下来,因为查询逻辑是通过多个30km的标准圆进行查询,所以为了把多边形完全覆盖,需要形成一个完全覆盖多边形的圆集合,并且这些圆会尽可能地减少重叠和空隙,这里使用了六边形密铺的形式;
接下来,我们形成对应功能脚本,并把生成的点中心坐标另存为csv;
| 功能 | 已支持 |
|---|---|
| ✅ 读取任意坐标系的 Shapefile(如 Web Mercator) | ✔️ |
| ✅ 自动判断并投影到合适坐标系(UTM 或保持投影) | ✔️ |
| ✅ 使用六边形蜂窝结构密铺,全覆盖多边形 | ✔️ |
| ✅ 生成 30km 缓冲区圆 | ✔️ |
| ✅ 保存圆心点为 Shapefile | ✔️ |
| ✅ 保存缓冲区为 Shapefile | ✔️ |
| ✅ 打印所有圆心坐标(原始坐标系) | ✔️ |
| ✅ 导出圆心点为 CSV(含 ID、X、Y) | ✔️ |
| ✅ 生成交互式 HTML 地图可视化(folium) | ✔️ |
完整代码#运行环境 Python 3.11
# -*- coding: utf-8 -*-
import geopandas as gpd
from shapely.geometry import Point
import numpy as np
import folium
import pandas as pd
# ==================== 配置路径 ====================
input_shp = r'D:\data\上海市最小外接多边形.shp'
output_points = r'D:\data\generated_points.shp'
output_buffers = r'D:\data\generated_buffers.shp'
output_csv = r'D:\data\generated_points.csv'
output_map = r'D:\data\visualization.html'
radius_m = 30000 # 30km
# ==================== 1. 读数据并投影 ====================
gdf = gpd.read_file(input_shp)
crs_orig = gdf.crs
if crs_orig is None:
raise ValueError("请确保输入文件有坐标系")
# 转UTM(适用于经纬度)
gdf_proj = gdf.to_crs('EPSG:3857') if crs_orig.is_geographic else gdf.to_crs(crs_orig)
# 获取范围
x_min, y_min, x_max, y_max = gdf_proj.total_bounds
# ==================== 2. 六边形布点 ====================
grid_step = radius_m * 2 / np.sqrt(3) # 间距
points = []
for i, x in enumerate(np.arange(x_min, x_max + grid_step, grid_step)):
for j, y in enumerate(np.arange(y_min, y_max + grid_step, grid_step)):
dx = grid_step / 2 if j % 2 == 0 else 0
pt = Point(x + dx, y)
if gdf_proj.intersects(pt).any():
points.append(pt)
# 转为GeoDataFrame
points_proj = gpd.GeoDataFrame(geometry=points, crs=gdf_proj.crs)
# ==================== 3. 生成缓冲区并过滤 ====================
buffers_proj = points_proj.copy()
buffers_proj['geometry'] = points_proj.buffer(radius_m)
# 仅保留与多边形相交的
valid = buffers_proj.intersects(gdf_proj.geometry.unary_union).values
points_proj = points_proj[valid]
buffers_proj = buffers_proj[valid]
# 转回原始坐标系
points_gdf = points_proj.to_crs(crs_orig)
buffers_gdf = buffers_proj.to_crs(crs_orig)
# ==================== 4. 打印坐标 + 保存文件 ====================
print("圆心坐标(原始坐标系):")
for i, pt in enumerate(points_gdf.geometry):
print(f"Point {i+1}: X={pt.x:.6f}, Y={pt.y:.6f}")
# 保存 Shapefile
points_gdf.to_file(output_points)
buffers_gdf.to_file(output_buffers)
# 保存 CSV
pd.DataFrame({
'ID': range(1, len(points_gdf) + 1),
'X': [pt.x for pt in points_gdf.geometry],
'Y': [pt.y for pt in points_gdf.geometry]
}).to_csv(output_csv, index=False, encoding='utf-8')
# ==================== 5. 生成地图 ====================
m = folium.Map(zoom_start=10)
gdf_wgs84 = gdf.to_crs(4326)
points_wgs84 = points_gdf.to_crs(4326)
buffers_wgs84 = buffers_gdf.to_crs(4326)
# 多边形轮廓
folium.GeoJson(gdf_wgs84, style_function=lambda x: {'color': 'red', 'weight': 2, 'fillOpacity': 0}).add_to(m)
# 每个圆
for _, row in buffers_wgs84.iterrows():
center = row.geometry.centroid
folium.Circle(
location=[center.y, center.x],
radius=radius_m,
color='blue',
fill=True,
fill_color='blue',
fill_opacity=0.1,
weight=1
).add_to(m)
# 圆心点
for _, row in points_wgs84.iterrows():
folium.CircleMarker(
location=[row.geometry.y, row.geometry.x],
radius=3,
color='darkred',
fill=True,
fill_color='darkred'
).add_to(m)
m.save(output_map)
print(f"\n完成!共生成 {len(points_gdf)} 个圆,已保存到:")
print(f"点: {output_points}")
print(f"缓冲区: {output_buffers}")
print(f"CSV: {output_csv}")
print(f"地图: {output_map}")这里,我们就获取到了对应的点图层和圆缓冲区的图层,这个图层的作用是为了确定缓冲区的覆盖范围是否对我们生成的多边形形成了全覆盖;
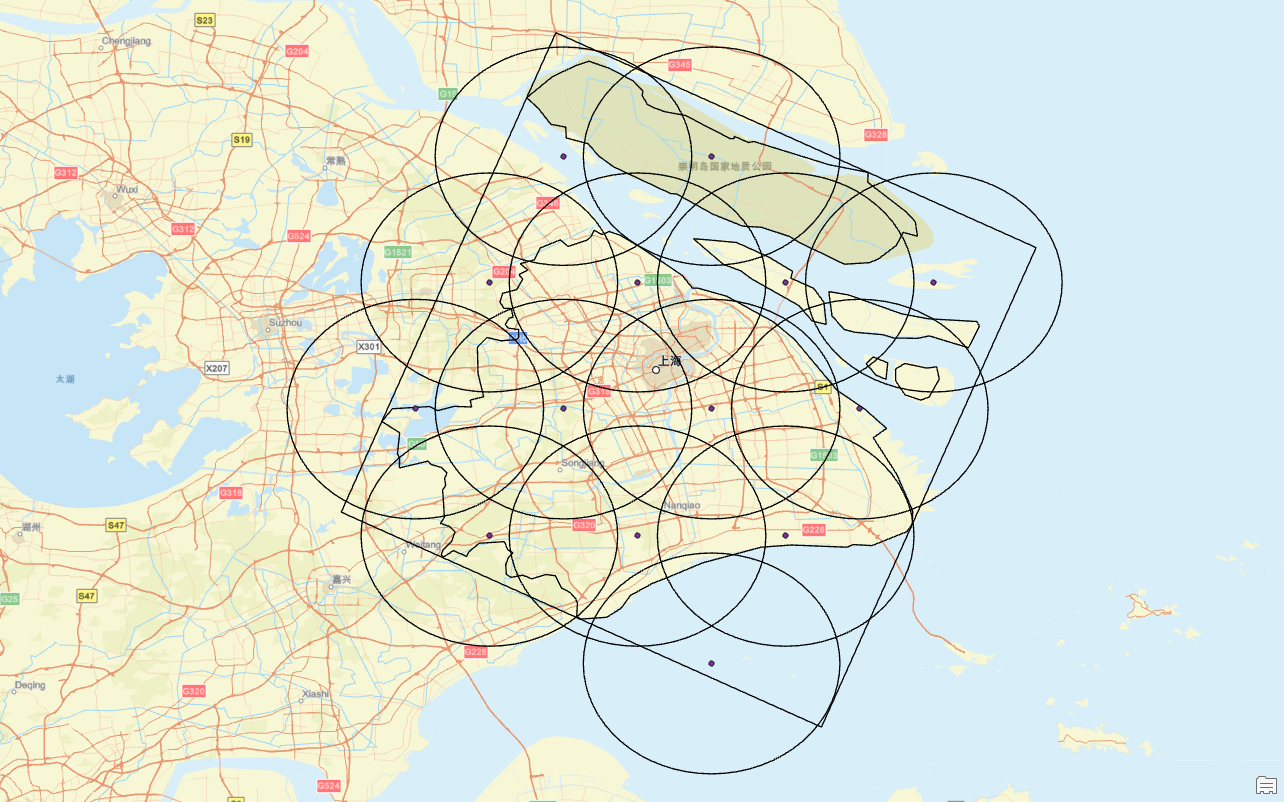
对应的点数据还是这个generated_points.csv表;
第二步:我们通过遍历generated_points.csv表的坐标点进行查询上海市的华为旗舰店的店铺数据,并且进行对结果去重;
完整代码#运行环境 Python 3.11
# -*- coding: utf-8 -*-
import requests
import json
import csv
import time
import pandas as pd
# ================== 配置 ==================
url = "https://sgw-cn.c.huawei.com/forward/cmkt/iretail/store/2"
headers = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"connection": "keep-alive",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"host": "sgw-cn.c.huawei.com",
"origin": "https://consumer.huawei.com",
"pragma": "no-cache",
"referer": "https://consumer.huawei.com/",
"sec-ch-ua": '"Not;A=Brand";v="99", "Microsoft Edge";v="139", "Chromium";v="139"',
"sec-ch-ua-mobile": "?1",
"sec-ch-ua-platform": '"Android"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"sgw-app-id": "替换成自己当前访问的时候的id",
"user-agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Mobile Safari/537.36 Edg/139.0.0.0"
}
# 搜索参数模板
payload_template = {
"pagesize": "100",
"pageno": "", # 动态页码
"userLatitude": 0.0, # 动态坐标
"userLongitude": 0.0,
"country_code": "CN",
"distance": "30",
"brand": "Huawei"
}
# 输入:之前生成的中心点 CSV
input_coords_csv = r'D:\data\generated_points.csv'
# 输出:所有门店去重后保存位置
output_csv = r'D:\data\huawei_stores_from_grid.csv'
max_retries = 3
delay_per_request = 0.5 # 每个中心点请求后延迟
delay_per_page = 0.3 # 同一中心点翻页时的延迟
# ==========================================
def save_to_csv(stores, filename):
"""保存门店数据到 CSV"""
if not stores:
print("没有数据可保存。")
return
fieldnames = [
"门店名称", "简称", "门店编码", "地址",
"纬度", "经度", "高德纬度", "高德经度",
"距离(km)", "联系电话", "营业时间",
"省份", "城市", "门店类型"
]
with open(filename, mode='w', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for store in stores:
writer.writerow({
"门店名称": store.get("store_name", ""),
"简称": store.get("retail_store_name_for_short", ""),
"门店编码": store.get("store_code", ""),
"地址": store.get("store_addr", ""),
"纬度": store.get("latitude", ""),
"经度": store.get("longitude", ""),
"高德纬度": store.get("glatitude", ""),
"高德经度": store.get("glongitude", ""),
"距离(km)": store.get("distance", ""),
"联系电话": store.get("fixed_line_phone_number", ""),
"营业时间": store.get("workinghour", ""),
"省份": store.get("provincial", ""),
"城市": store.get("city", ""),
"门店类型": store.get("regional_image_level", "")
})
print(f"所有 {len(stores)} 家去重门店已保存至:{filename}")
def fetch_page(payload, pageno):
"""获取单页数据"""
payload = payload.copy()
payload["pageno"] = str(pageno)
data = json.dumps(payload, separators=(',', ':'))
for attempt in range(max_retries):
try:
response = requests.post(url, data=data, headers=headers, timeout=10)
if response.status_code == 200:
json_data = response.json()
if isinstance(json_data, list):
return json_data
elif isinstance(json_data, dict):
if json_data.get("errCode") == 0:
return json_data.get("data", [])
else:
print(f"返回错误: {json_data.get('errMsg')}")
return []
else:
print(f"响应格式异常")
return []
else:
print(f"请求失败,状态码: {response.status_code}")
time.sleep(1)
continue
except Exception as e:
print(f"请求失败 (第 {attempt+1} 次): {e}")
time.sleep(2)
continue
print(f"重试 {max_retries} 次均失败,跳过该中心点。")
return []
def fetch_stores_around(lat, lon):
"""获取某个坐标点周边 30km 门店"""
print(f"正在搜索坐标 ({lat:.6f}, {lon:.6f}) 周边 30km 门店...", end="")
all_stores = []
pageno = 1
while True:
stores = fetch_page({
"pagesize": "100",
"pageno": str(pageno),
"userLatitude": lat,
"userLongitude": lon,
"country_code": "CN",
"distance": "30",
"brand": "Huawei"
}, pageno)
if not stores:
if pageno == 1:
print("无数据")
else:
print()
break
all_stores.extend(stores)
print(f" 第{pageno}页({len(stores)}家)", end="", flush=True)
if len(stores) < 100: # 不足100条,说明最后一页
print()
break
pageno += 1
time.sleep(delay_per_page)
return all_stores
def main():
print("开始读取中心点并遍历搜索华为门店...")
# 1. 读取坐标文件
try:
coords_df = pd.read_csv(input_coords_csv)
print(f"成功读取 {len(coords_df)} 个中心点")
except Exception as e:
print(f"读取坐标文件失败: {e}")
return
# 2. 验证列名
if 'X' not in coords_df.columns or 'Y' not in coords_df.columns:
print("错误:CSV 文件必须包含 'X' 和 'Y' 列")
return
# 3. 总体结果收集
all_stores = []
seen_codes = set()
# 4. 遍历每个中心点
for idx, row in coords_df.iterrows():
lon = row['X']
lat = row['Y']
if not isinstance(lat, (int, float)) or not isinstance(lon, (int, float)):
print(f"第 {idx+1} 行坐标无效,跳过")
continue
stores = fetch_stores_around(lat, lon)
# 去重后加入总列表
for store in stores:
code = store.get("store_code")
if code and code not in seen_codes:
seen_codes.add(code)
all_stores.append(store)
time.sleep(delay_per_request) # 控制请求频率
print(f"全部完成!共获取 {len(all_stores)} 家去重门店。")
# 5. 保存结果
save_to_csv(all_stores, output_csv)
if __name__ == "__main__":
main()
这里二个tips:1、这里需要在请求头 headers 中添加一个关键字段:SGW-APP-ID,这个字段是华为内部服务网关(SGW = Service Gateway)用于标识调用方身份的应用 ID,没有它,请求会被直接拒绝(500 错误);
2、我们根据负载可以发现,一页是包含100条数据,但是根据响应的内容,并不能判断数据一共有多少页,于是就想到了在一个循环中递增 pageno 并检查每页返回的数据,如果遍历到那页为没有返回任何门店数据,则可以认为已到达最后一页,停止请求;
获取数据标签如下:store_name(店铺名称)、store_addr(店铺地址)、distance(离查询位置距离)、provincial(所在省)、city(所在城市)、store_addr(店铺地址)、lng & lat(地理坐标)、fixed_line_phone_number(电话)、workinghour(营业时间)、regional_image_level(门店类型),其他一些非关键标签,这里省略;
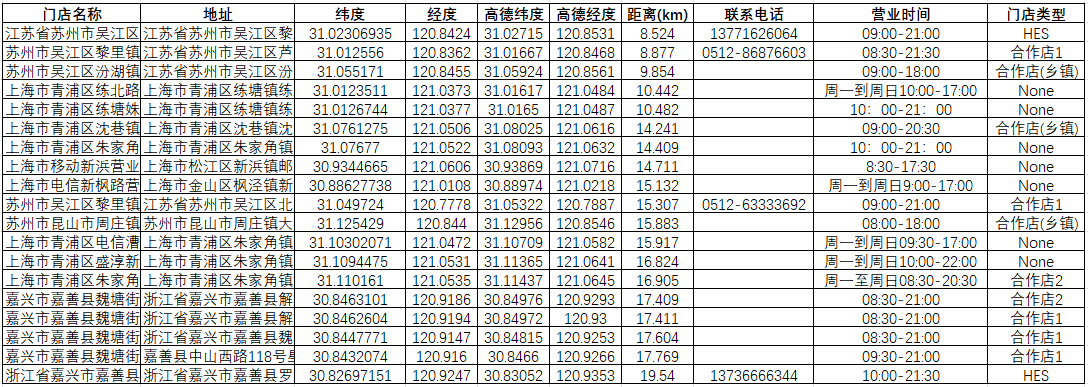
第三步:可视化,由于华为旗舰店门店数据包含二个坐标系高德坐标系(GCJ02)和GPS坐标系,所以我们可以直接使用对应wgs84坐标系;
对CSV文件中的门店坐标数据进行插入,进行xy数据转点,至此我们就完成了ArcGIS的可视化;
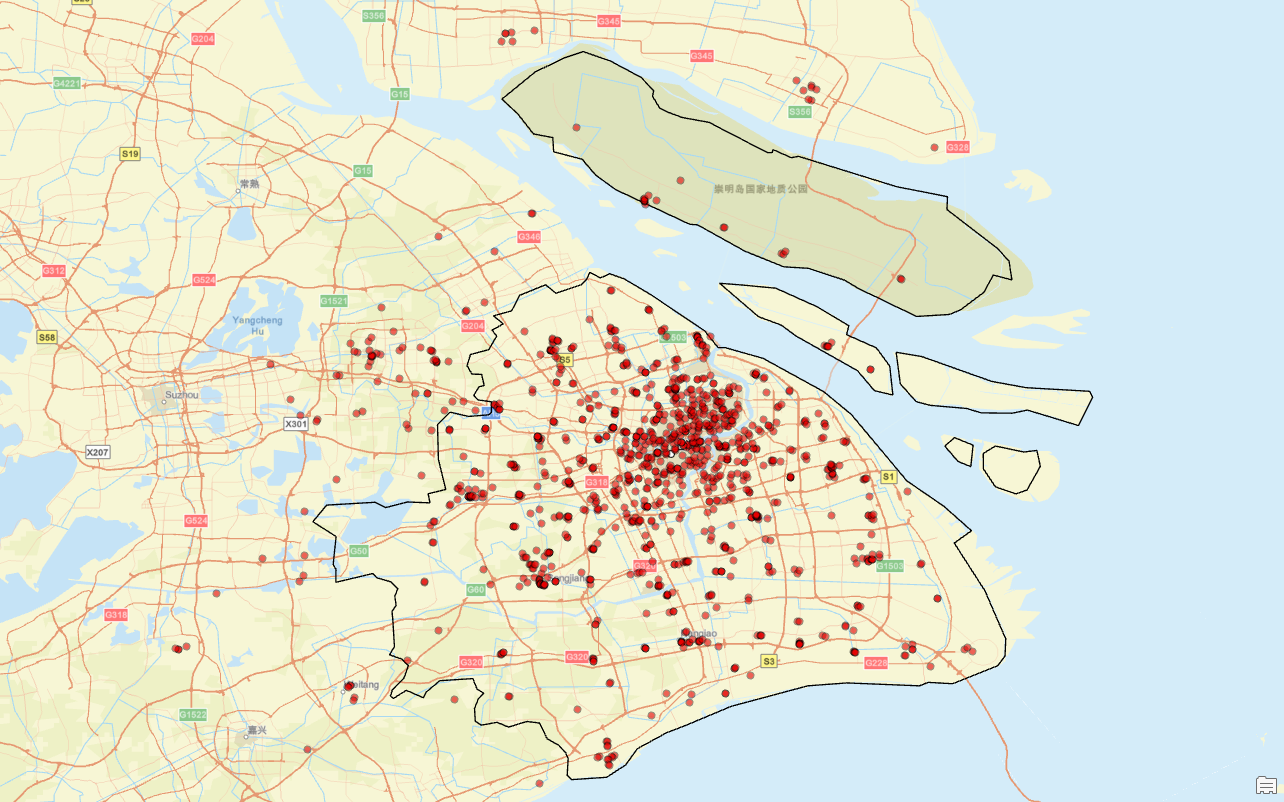
接下来,我们进行看图说话:
从整体分布来看,华为旗舰店的布局呈现出明显的“中心集聚、外围扩散”的空间特征。在上海市中心区域,如浦东新区、黄浦区、徐汇区和静安区等核心城区,门店分布极为密集,几乎覆盖了主要商圈、购物中心和人流密集地段。这些区域不仅是上海的政治、经济与文化中心,也是高端消费和科技产品需求最为旺盛的地区。因此,华为在此类高流量、高曝光区域密集布点,旨在强化品牌形象、提升市场渗透率,并为消费者提供便捷的购机与售后服务体验。
相比之下,随着距离市中心的距离增加,门店密度逐渐降低。在闵行区、宝山区、嘉定区、松江区等郊区,门店数量明显减少,分布较为零散;而在更远的崇明区以及长三角毗邻城市如苏州、嘉兴等地,门店则更为稀疏,呈现出“点状分布”的特点。这种由内而外递减的分布模式,深刻反映了人口密度、消费能力与城市功能分区对商业布局的决定性影响。市中心人口高度集中,商业氛围浓厚,是品牌争夺市场份额的战略要地;而郊区及周边城市虽然人口密度较低,但随着城市扩张和轨道交通的发展,部分新兴居住区和产业新城也具备了一定的市场潜力,因此华为仍会通过选择性设点实现适度覆盖。
值得注意的是,华为旗舰店在选址上高度重视交通可达性与区位优势。许多门店沿G15沈海高速、G40沪陕高速、G50沪渝高速等主要交通干道分布,尤其集中在大型交通枢纽附近,如虹桥综合交通枢纽、浦东国际机场、地铁换乘站周边等。这些位置不仅便于来自全市乃至长三角其他城市的消费者到访,也极大提升了门店的辐射能力和服务范围。此外,在一些大型购物中心、城市综合体内部设立门店,也体现了华为对“场景化消费”和“体验式零售”的重视。
从战略层面看,该分布格局不仅服务于当前的销售目标,也为未来的市场拓展预留了空间。例如,在苏州工业园区、嘉兴南湖新区等长三角重点发展区域设立门店,表明华为正积极布局区域一体化发展趋势,借助城市群协同效应扩大品牌影响力。同时,这种分布也为后续的售后服务网络、物流配送体系和数字化运营提供了有力支撑。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。