一般常见原因总结
| 类别 | 可能原因 | 简单排查命令 |
|---|---|---|
| 服务器资源 | CPU占用高(计算/GC) | top, htop, vmstat 1 |
| 内存不足,使用Swap | free -h, vmstat 1 |
|
| 磁盘I/O瓶颈(日志/数据库) | iostat -x 1 |
|
| 网络带宽打满 | iftop, nethogs |
|
| 数据库 | 慢SQL查询(最最常见) | 查看数据库慢日志 |
| 数据库连接池打满 | show processlist |
|
| 表锁/行锁等待 | show engine innodb status |
|
| 缓存 | Redis慢查询/高延迟 | redis-cli --latency, SLOWLOG GET |
| Redis内存不足 | info memory |
|
| 应用代码 | 异常过多 | 查看应用错误日志 |
| GC频繁 | jstat -gcutil <pid> |
|
| 线程池打满/死锁 | jstack <pid> |
|
| 代码性能问题(循环、算法) | 使用Profiling工具(Arthas, pprof) | |
| 外部依赖 | 第三方API响应慢 | 链路追踪 |
| 中间件(MQ, ES)响应慢 | 查看对应监控 | |
| 其他 | 流量激增(爬虫/活动) | 查看访问日志、监控流量图表 |
| 网络问题(DNS、机房网络) | ping, traceroute, mtr |
|
| 日志级别过低(如DEBUG),大量写日志 | 查看日志配置和磁盘IO |
一、内存排查

我们来分析一下你提供的 free -h 命令的截图信息。
根据你提供的数据:
- Total (总内存): 14G 。
- used (已使用): 2.3G
- free (未使用): 7.3G
- shared (共享内存): 247M (很小,正常)
- buff/cache (缓存/缓冲): 5.3G
- available (可用内存): 12G
结论:这非常正常,而且是健康的状态!
你的系统内存使用情况是 理想状态。下面是详细解释:
1. 核心指标解读:available (可用内存)
这是最关键的一个指标,它的值是 12G。这个数字的含义是:
系统估算出,如果应用程序现在需要申请内存,大概有 12GB 的内存可以立刻分配给它(包括当前空闲的内存和可回收的缓存/缓冲内存)。
这意味着你的系统有非常充足的可用内存资源,完全没有任何内存压力。
2. 关于 buff/cache 占用 5.3 G
这 不是 内存被浪费了,恰恰相反,这证明了你的系统在智能地利用资源提升性能。
- Linux 内核会把暂时用不到的内存(总共约 12G 的
available中的大部分)拿来当做buff/cache,用来缓存磁盘数据。 - 这样做的目的是:极大加速后续的磁盘读写操作。因为从内存读取比从磁盘读取快成千上万倍。
- 当你的应用程序(比如数据库、Web服务)需要更多内存时,内核会瞬间、自动地缩减
buff/cache的大小,把这 5.3G 中的大部分归还给应用程序使用。这个过程对你来说是透明的,无需干预。
二、CPU占用
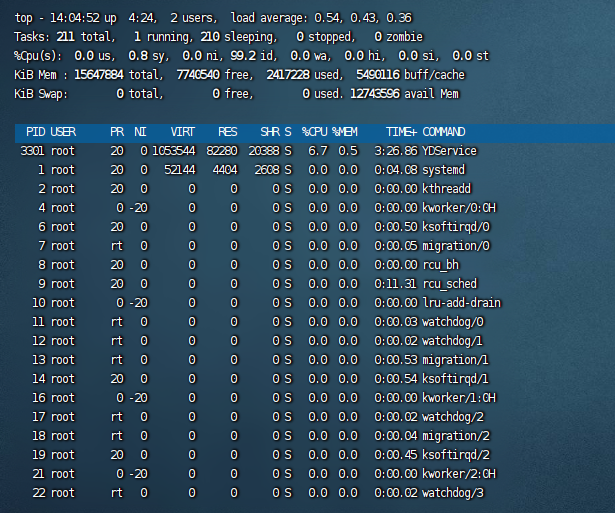
top 命令是排查性能问题的神器。看到有程序CPU占用50%多,这很可能就是导致接口变慢的“元凶”。下面我教你如何一步步看懂 top 并找出这些程序。
第1步:登录服务器,运行 top 命令
直接在SSH终端输入:
top
你会看到一个动态刷新的界面,分为上部汇总信息和下部进程列表。
第2步:看懂顶部的系统汇总信息(关键!)
顶部前几行提供了整个服务器的健康状况概览,这是判断瓶颈在哪的第一步。
第1行:系统概览
top - 18:20:30 up 10 days, 1:15, 1 user, load average: 2.50, 1.80, 1.20
18:20:30:当前时间。up 10 days:系统已运行时间。load average: 2.50, 1.80, 1.20:系统平均负载,这是非常关键的指标!- 3个数字分别代表过去1分钟、5分钟、15分钟的平均负载。
- 如何理解? 假设你的CPU是4核心,那么:
- 负载 ≤ 4.00:比较轻松。
- 负载 > 4.00:表示有进程在排队等待CPU,系统压力大。
- 你例子中的
2.50对于4核CPU来说,表示CPU有压力但未完全饱和。
第2/3行:任务和CPU状态
Tasks: 200 total, 1 running, 199 sleeping, 0 stopped, 0 zombie
%Cpu(s): 50.0 us, 20.0 sy, 0.0 ni, 30.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu(s):这是CPU使用率的明细,至关重要!us (user):用户进程占用CPU的百分比。这个值高,通常就是你的应用程序(如Java, Python程序)吃掉了大量CPU。sy (system):系统内核占用CPU的百分比。这个值高,表示系统调用频繁,可能IO操作多。id (idle):CPU空闲百分比。这个值越小,说明CPU越忙。你希望这个值高。wa (iowait):CPU等待IO完成的百分比。这是另一个关键指标! 如果这个值很高(比如 > 20%),说明磁盘IO是瓶颈,CPU在空转等着读/写数据。- 你的情况:如果
us很高(比如50%),说明是应用程序本身消耗了大量CPU。
第4/5行:内存和交换分区
MiB Mem : 7856.4 total, 100.2 free, 2000.0 used, 5756.2 buff/cache
MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 5600.0 avail Mem
- 这里我们之前分析过了,你的内存很健康,
avail Mem很大,所以问题不在内存。
第3步:找出CPU高的罪魁祸首(排序进程列表)
默认情况下,top 的进程列表可能不是按CPU排序的。你需要做的是:
按下键盘上的
P(大写,Shift+p)。这是按CPU使用百分比排序的命令。列表最上面的进程,就是吃掉CPU最多的那个。你看到的50%多的程序肯定排在前面。现在看进程列表的每一列,重点关注这几列:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1234 mysql 20 0 10.5g 2.1g 1.2g S 55.2 27.4 100:05.66 mysqld
5678 www-data 20 0 123456 9876 1234 R 30.1 0.1 0:10.25 php-fpm
9012 root 20 0 10000 5000 2000 S 1.0 0.1 0:00.01 sshd
PID: 进程ID。USER: 进程所属用户。%CPU: 该进程占用CPU的百分比。这就是你要找的!%MEM: 该进程占用内存的百分比。COMMAND: 进程的名称/命令。这是识别进程的关键(例如mysqld,java,nginx,php-fpm)。
现在,你就能一眼看出是哪个进程(COMMAND)占用了多的CPU了。
第4步:定位具体是哪个 PHP 脚本和哪行代码
首先,让我们看一下这个高CPU的 php 进程到底在运行什么脚本。使用 ps 命令查看进程的完整命令行:
ps aux | grep 25866
或者更精确的:
ps -fp 25866
查看输出中的 COMMAND 或 CMD 列,这通常会显示出执行的PHP脚本路径,例如:
/usr/bin/php /path/to/your/script.php
php /path/to/your/script.php
第5步:检查PHP-FPM/PHP日志
查看PHP的错误日志和慢日志,看是否有大量报错或记录下执行缓慢的脚本。PHP-FPM有一个类似MySQL慢查询日志的功能,它能直接告诉你哪个脚本慢、慢在哪里。
PHP错误日志:通常可以在 php.ini 或 PHP-FPM 池配置中找到 error_log 的路径。
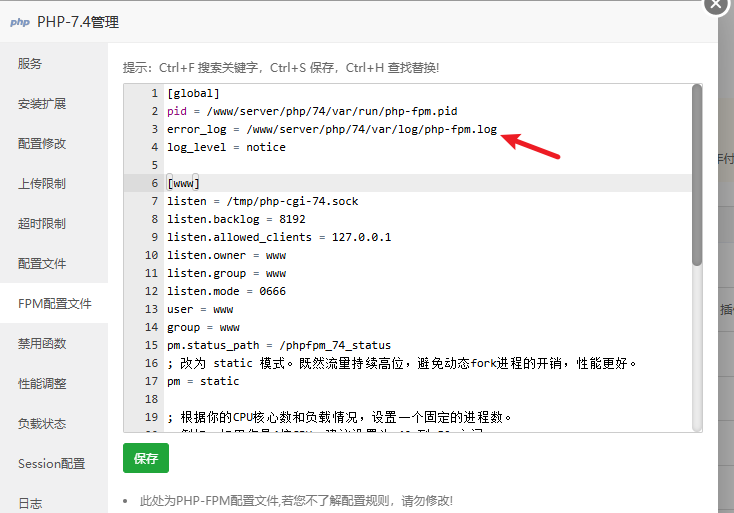
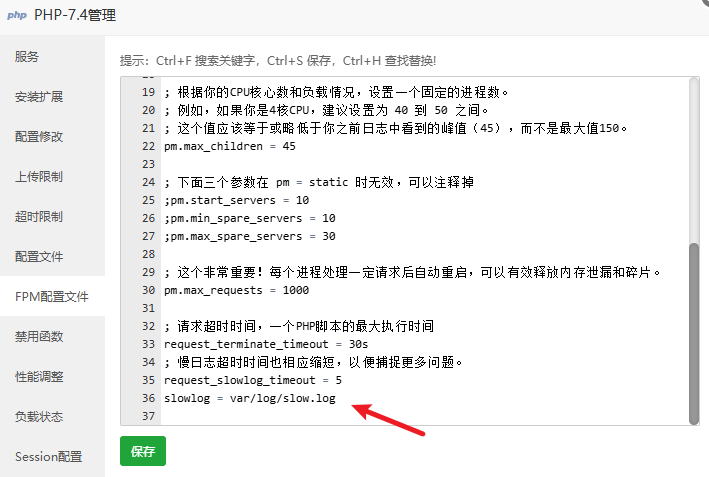
PHP-FPM慢日志:如果你配置了 request_slowlog_timeout,定义一个请求执行超过x秒即为慢请求,慢日志会记录下执行时间过长的请求及其当时的调用栈,这是非常有用的信息。slowlog 定义慢日志文件路径,绝对路径其实是:
/www/server/php/74/var/log/slow.log