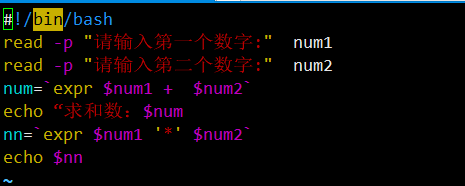
1. 命令小工具使用总结
1.1 cut:按列或字符截取
1. 核心功能
从文本中抽取指定列或字符,仅擅长处理单个字符为间隔的文本。
2. 常用选项
-b:按字节截取-c:按字符截取(中文推荐使用)-d:指定分隔符(默认是 TAB 键)-f:指定要截取的字段(需与-d配合使用)
3. 示例
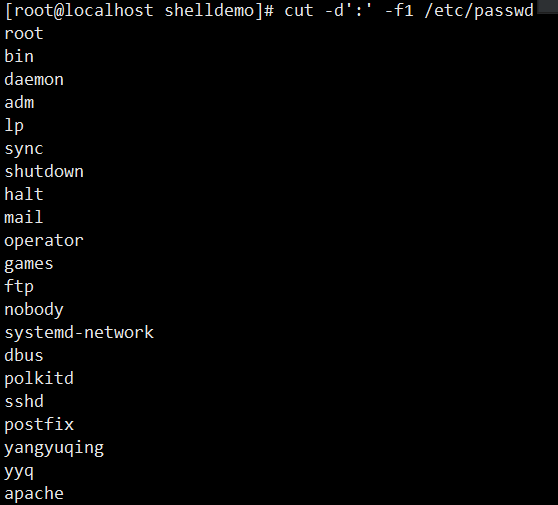
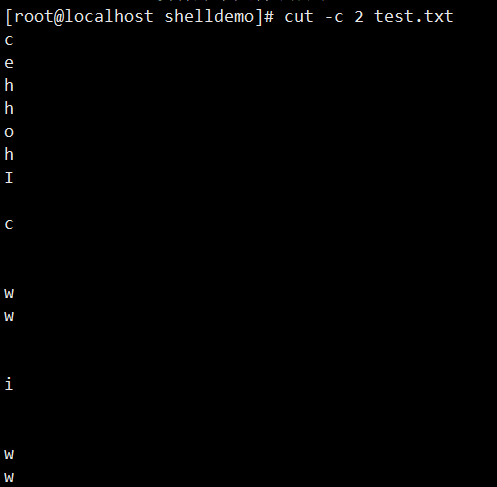
cut -d':' -f1 /etc/passwd:以冒号为分隔符,截取/etc/passwd文件的第 1 列(用户名)cut -d':' -f1,3 /etc/passwd:以冒号为分隔符,截取第 1 列和第 3 列cut -c 2 name.txt:截取name.txt文件中每行的第 2 个字符who | cut -c 3:截取who命令输出结果中每行的第 3 个字符
1.2 sort:文本排序
1. 核心功能
对文本按指定规则排序,默认按行首字符升序排列。
2. 常用选项
-t:指定分隔符-k:指定排序字段-n:按数值排序(默认按字典序)-r:按降序排序-u:去重(功能等价于uniq)-o:将排序结果输出到指定文件
3. 示例
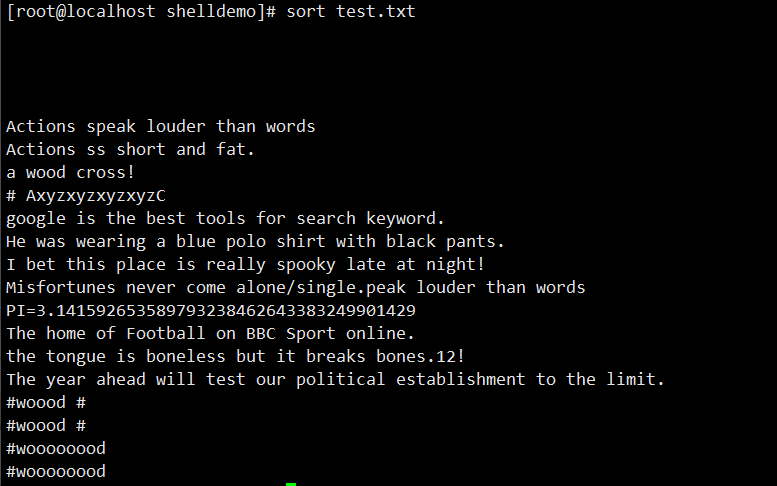
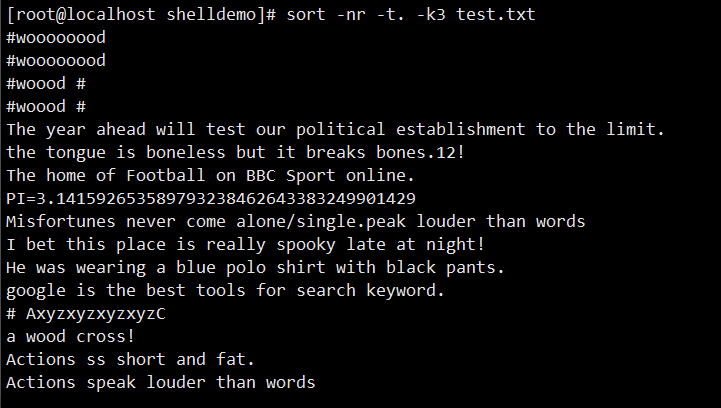
sort passwd.txt:对passwd.txt文件按第一列升序排序sort -n -t: -k3 passwd.txt:以冒号为分隔符,按第 3 列数值升序排序sort -nr -t: -k3 passwd.txt:以冒号为分隔符,按第 3 列数值降序排序sort -nr -t: -k3 passwd.txt -o out.txt:排序后将结果保存到out.txt文件
1.3 uniq:去除连续重复行
1. 核心功能
仅能去除相邻的重复行,因此通常需先使用sort排序,再用uniq去重。
2. 常用选项
-c:对重复的行进行计数-d:只显示重复的行-u:只显示唯一的行
3. 示例
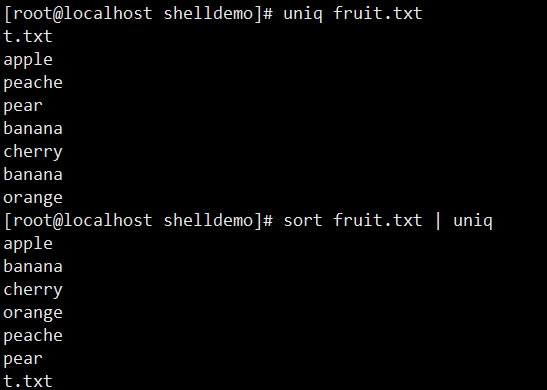
假设fruit.txt含 9 行内容(apple、apple、peache 等):
uniq fruit.txt:去除fruit.txt中相邻的重复行sort fruit.txt | uniq:先排序使重复行相邻,再全局去重sort fruit.txt | uniq -c:统计每行内容出现的次数sort fruit.txt | uniq -d:只显示重复的行last | awk '{print $1}' | sort | uniq | grep -v "^$" | grep -v wtmp:查看登陆过系统的用户(排除空行和 wtmp 相关行)
1.4 tr:字符处理(替换 / 删除 / 压缩)
1. 核心功能
用于单个字符处理,不适合字段级别操作,从标准输入处理字符后输出到标准输出。
2. 常用选项
-d:删除指定字符-s:压缩重复字符,只保留一个
3. 示例
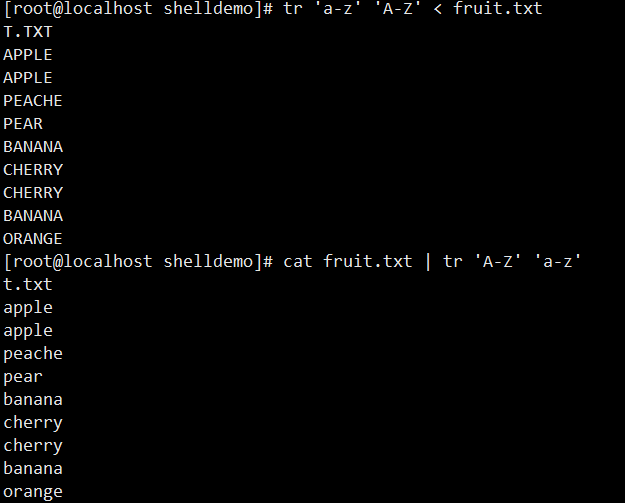
tr 'a-z' 'A-Z' < fruit.txt或cat fruit.txt | tr 'a-z' 'A-Z':将fruit.txt中小写字母转为大写cat fruit | tr 'a' ' ':将fruit文件中的所有 “a” 替换为空格tr -d 'a' < fruit.txt:删除fruit.txt中所有 “a” 字符tr -d '\n' < fruit.txt:删除fruit.txt中的所有换行符tr -s 'p' < fruit.txt:将fruit.txt中连续的 “p” 压缩成一个
2. sed 命令使用总结
2.1 sed 概述
sed 是一款通过脚本处理文本文件的工具,核心用途包括自动编辑单个 / 多个文件、简化文件重复操作、编写文本转换程序。
2.2 sed 工作原理
1. 核心流程(读→执→显循环)
- 读取:从输入流(文件、管道、标准输入)读取一行内容,存入临时缓冲区 “模式空间(pattern space)”。
- 执行:默认所有 sed 命令在模式空间顺序执行;若指定行地址,仅对目标行执行命令。
- 显示:将处理后的内容输出到输出流,随后清空模式空间。
上述过程重复,直至所有文本行处理完毕。
2. 详细步骤
- 读入新行至模式空间;
- 取第一条操作指令,判断是否匹配 pattern;
- 不匹配:忽略后续编辑命令,返回步骤 2 取下一条指令;
- 匹配:执行编辑命令,返回步骤 2 取下一条指令;
- 所有指令执行完毕后,输出模式空间内容,返回步骤 1 读入下一行;
- 所有行处理完,流程结束。
3. 关键说明
默认情况下,sed 仅在模式空间操作,输入文件不会被修改,需通过重定向(如>)保存输出结果。
2.3 sed 命令基础用法
1. 基本语法
- 直接指定操作:
sed [选项] '操作' 参数 - 通过脚本文件操作:
sed [选项] -f scriptfile 参数
2. 常用选项(详细版 / 简版对照)
| 选项 | 详细含义 | 简版含义 |
|---|---|---|
-e/--expression= |
用指定命令 / 脚本处理文本 | 进行多次编辑 |
-f/--file= |
用指定脚本文件处理文本 | 指定 sed 文件名 |
-h/--help |
显示帮助信息 | - |
-n/--quiet/silent |
仅显示处理后的结果 | 取消默认输出 |
-i.bak |
直接编辑文件,同时创建.bak备份文件 |
直接在源文件修改 |
-r/-E |
使用扩展正则表达式 | 使用扩展正则表达式 |
-s |
将多个文件视为独立文件,而非连续长流 | - |
3. 常用操作(动作)
操作格式可加行地址:[n1[,n2]]动作(如5,20d表示删除 5-20 行),常用动作如下:
| 动作 | 含义 |
|---|---|
a |
在当前行下方新增指定内容 |
c |
替换选定行的全部内容 |
d |
删除选定行 |
i |
在当前行上方插入指定内容 |
p |
打印内容(指定行则打指定行,未指定则打全部;常与-n搭配避免重复输出) |
s |
替换指定字符(如s/旧/新/) |
y |
字符转换(按字符一一对应转换) |
2.4 sed 命令实操示例(以demo文件为主)
1. 输出符合条件的文本(p动作)
- 输出所有内容:
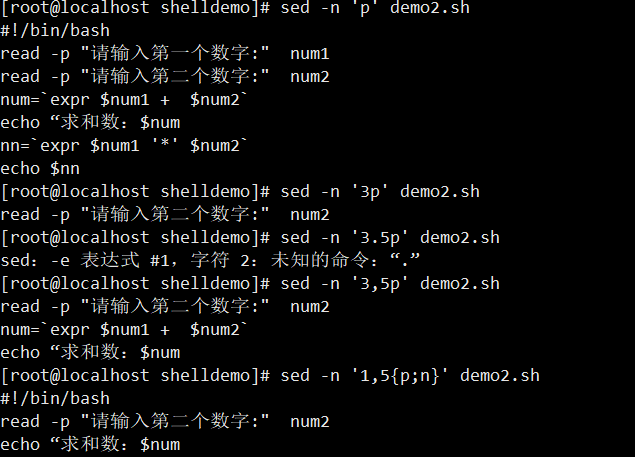
sed -n 'p' demo(等价于cat demo) - 输出指定行:
sed -n '3p' demo(第 3 行)、sed -n '3,5p' demo(3-5 行) - 输出奇偶行:
sed -n 'p;n' demo(奇数行)、sed -n 'n;p' demo(偶数行) - 结合正则:
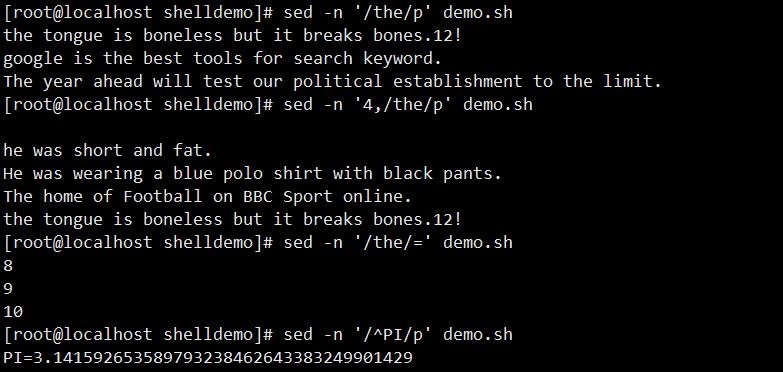
- 输出含 “the” 的行:
sed -n '/the/p' demo - 输出含 “the” 的行号:
sed -n '/the/=' demo - 输出以 “PI” 开头的行:
sed -n '/^PI/p' demo - 输出以数字结尾的行:
sed -n '/[0-9]$/p' demo
- 输出含 “the” 的行:
2. 删除符合条件的文本(d动作)
建议先备份文件,可结合nl命令查看行号:
- 删除指定行:
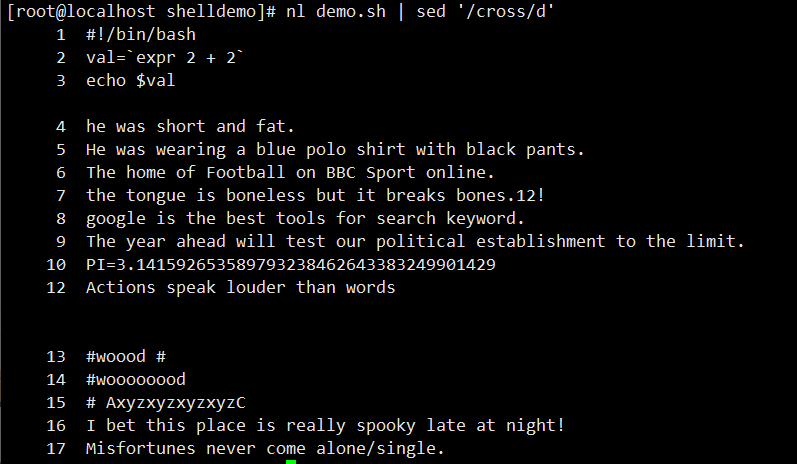
nl demo | sed '3d'(第 3 行)、nl demo | sed '3,5d'(3-5 行) - 按内容删除:
nl demo | sed '/cross/d'(删含 “cross” 的行) - 按正则删除:
sed '/^[a-z]/d' demo(删小写字母开头的行)、sed '/^$/d' demo(删空行)
3. 替换符合条件的文本(s/c/y动作)
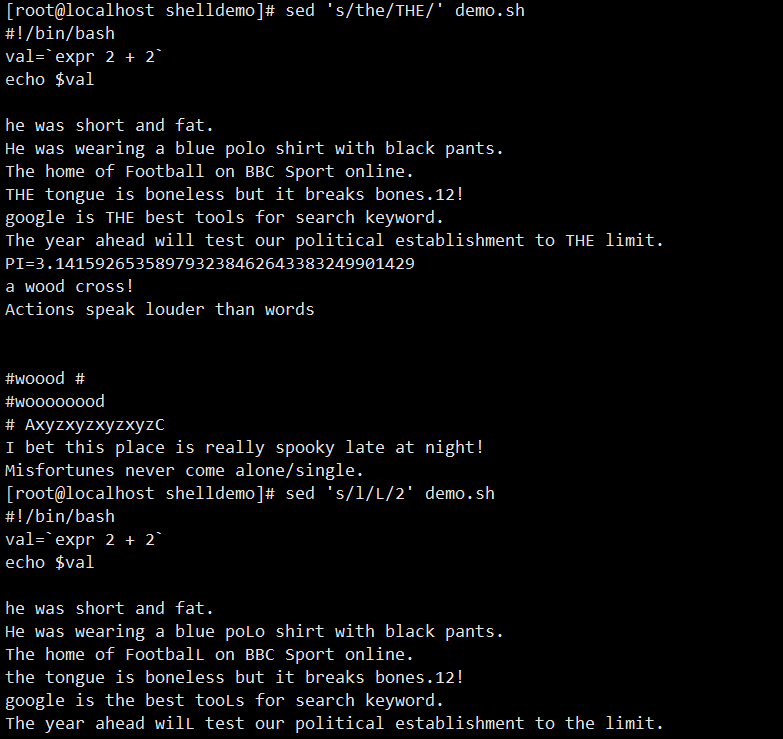
- 替换字符:
sed 's/the/THE/' demo(每行第一个 “the” 换 “THE”)、sed 's/the/THE/g' demo(全局替换,g表全局) - 指定行替换:
sed '3,5s/the/THE/g' demo(3-5 行全局替换) - 行首 / 行尾添加内容:
sed 's/^/#/' demo(行首加 “#”)、sed 's/$/EOF/' demo(行尾加 “EOF”) - 直接修改文件:
sed -i.bak 's/SELINUX=disabled/SELINUX=enable/' /etc/selinux/config(修改 SELinux 配置,备份原文件)
4. 迁移符合条件的文本(H/g/G/w/r/a动作)
- 迁移行至末尾:
sed '/the/{H;d};$G' demo(含 “the” 的行移到文件尾) - 保存行到新文件:
sed '/the/w out.file' demo(含 “the” 的行存到out.file) - 插入内容:
sed '3aNew' demo(第 3 行后插 “New”)、sed '3aNew1\nNew2' demo(第 3 行后插多行)
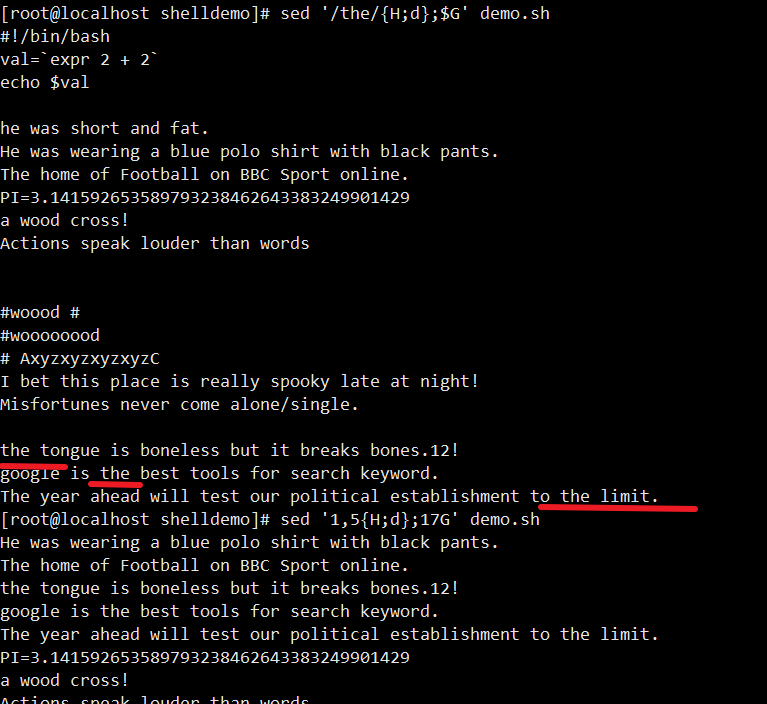
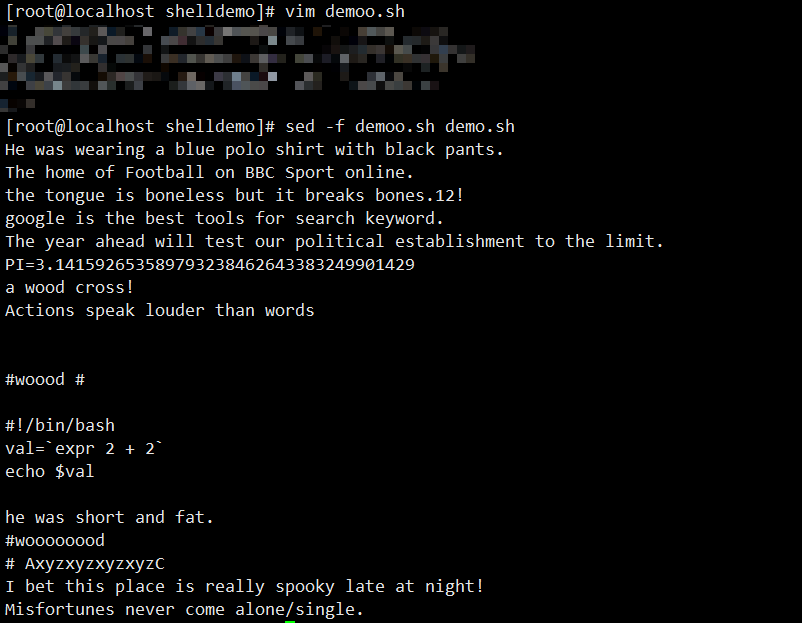
5. 用脚本编辑文件(-f选项)
将多个指令写入脚本文件,通过-f调用:
- 创建脚本
opt.list:1,5H 1,5d 16G - 执行脚本:
sed -f opt.list demo(将 1-5 行移到第 16 行后)
3. 总结
Linux 文本处理工具分两类:
• 小工具(cut、sort、uniq、tr):
◦ cut:按字节、字符、分隔符提取列/字段;
◦ sort:指定分隔符、字段排序,支持数值/降序,能去重、输出到文件;
◦ uniq:统计重复行、只显重复/唯一行;
◦ tr:删字符、压缩重复字符。
• sed(流编辑器):逐行读文本,用规则(替换、删、插等)快速处理。选项可多编辑、改源文件等;动作有打印、删行、插入、替换等。