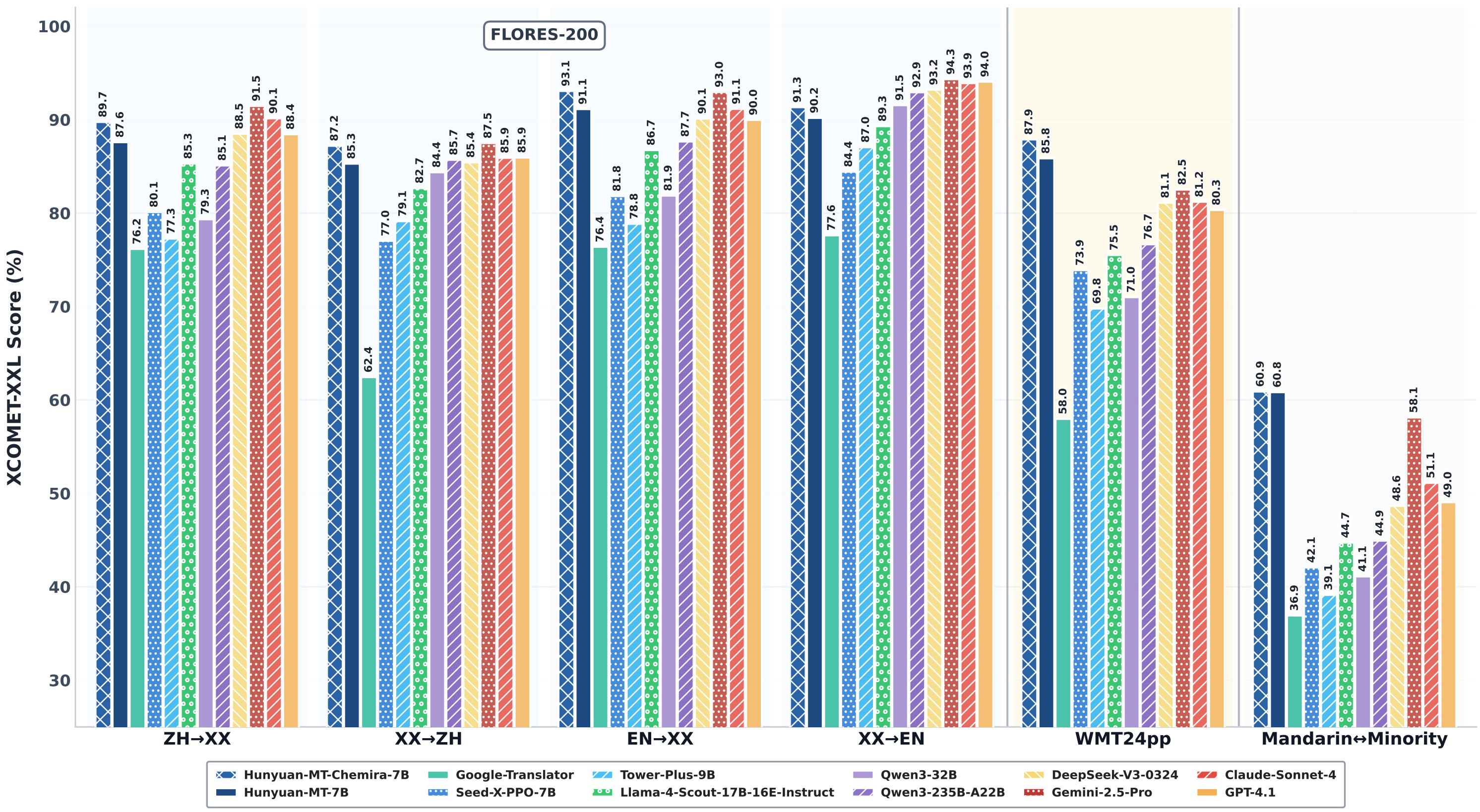
2025年9月2日,腾讯宣布开源其自研的轻量级翻译大模型 Hunyuan-MT-7B,在国际机器翻译领域的权威赛事——WMT2025(国际计算语言学协会机器翻译比赛)中,该模型以绝对优势斩获31个语种中的30项冠军,一举超越众多参数量更大的竞品,成为全球翻译技术的新标杆。更令人惊喜的是,Hunyuan-MT-7B 仅用7亿参数便实现了这一壮举,同时支持33种语言及5种民汉语言/方言互译,真正实现了“小身材、大能量”。
从实验室到开源社区:腾讯混元的技术突围
1. 轻量级设计,性能却碾压大模型
传统观点认为,机器翻译模型的参数量越大,效果越好。但 Hunyuan-MT-7B 却打破了这一认知:
- 参数效率极高:在 WMT2025 比赛中,它以7亿参数的规模,击败了参数量数倍于己的对手,在中文、英语、日语等常见语种,以及捷克语、马拉地语等小语种上均表现优异。
- 推理速度领先:基于腾讯自研的 AngelSlim 大模型压缩工具,Hunyuan-MT-7B 的推理性能提升了 30%,可在相同硬件条件下处理更多翻译请求,尤其适合资源受限的边缘设备部署。
腾讯混元团队负责人表示:“我们追求的不是‘堆参数’,而是让模型更‘聪明’——通过优化算法和训练策略,让小模型也能达到甚至超越大模型的效果。”
2. 懂上下文、会变通:翻译更自然
机器翻译的痛点常在于“直译死板”,尤其是面对俚语、古诗、社交缩写等复杂文本时。Hunyuan-MT-7B 通过大模型预训练+多任务微调,显著提升了上下文理解能力:
- 俚语翻译:例如将英文“Break a leg”译为中文“祝你好运”(而非字面的“打断一条腿”);
- 古诗意境还原:在翻译李白《静夜思》时,能准确传达“举头望明月,低头思故乡”的思乡情感;
- 社交缩写处理:如将“yyds”译为“永远的神”,而非机械拆解。
用户实测反馈:“用 Hunyuan-MT-7B 翻译会议记录,专业术语准确,语气也更贴近人类表达,比传统翻译工具强太多!”
Hunyuan-MT-Chimera-7B:集成多模型,打造翻译智囊团
除单模型外,腾讯还推出了 Hunyuan-MT-Chimera-7B——一款翻译集成模型。它的核心优势在于:
- “集百家之长”:可接入DeepSeek等其他翻译模型,综合多个模型的输出,生成更优质的译文;
- 专业场景适配:尤其适合法律、医学等对准确性要求极高的领域,通过多模型交叉验证减少错误;
- 灵活扩展:开发者可根据需求自定义模型组合,打造专属翻译引擎。
某跨国律所实测:在翻译一份英文合同时,Chimera-7B 整合了 3 个专业模型的输出,将术语错误率从 8% 降至 1.2%,效率提升 40%。
从竞赛到落地:混元翻译已服务亿级用户
技术突破的最终目标是服务用户。目前,Hunyuan-MT-7B 及其变体已广泛应用于腾讯旗下产品:
- 腾讯会议:实时翻译 33 种语言,助力跨国协作无障碍;
- 企业微信:自动生成多语言版工作文档,提升全球化团队效率;
- QQ 浏览器:网页翻译准确率提升 25%,阅读外文更流畅。
数据显示:自 2023 年混元系列模型开源以来,已有超 10 万开发者下载使用,覆盖教育、金融、跨境电商等 20 余个行业。
开源生态:腾讯的“技术共享”哲学
“开源不是终点,而是新起点。”腾讯混元团队表示,未来将持续开放更多模型和技术:
- 降低使用门槛:提供详细的模型训练和部署指南,帮助中小企业快速上手;
- 共建社区生态:鼓励开发者贡献代码、优化模型,形成“技术-应用-反馈”的良性循环;
- 探索前沿方向:如低资源语言翻译、多模态翻译(图文+语音)等,推动行业共同进步。
正如 WMT2025 评委评价:“Hunyuan-MT-7B 的成功证明,轻量级模型也能通过技术创新实现颠覆,这为整个AI领域提供了新思路。”
结语:翻译技术的平民化时代
从“机器直译”到“智能理解”,从“大模型垄断”到“轻量级普惠”,Hunyuan-MT-7B 的开源标志着翻译技术进入了一个新阶段。无论是开发者、企业还是普通用户,都能以更低的成本享受高质量的翻译服务。(本文由AI辅助生成,部分内容人工编辑)
模型体验:腾讯混元
文章来源:AITOP100,原文地址:腾讯混元翻译模型Hunyuan-MT-7B开源:小参数量大能量,获得30项国际冠军-AITOP100,AI资讯