

🔥个人主页: 中草药
不可变集合
如果某个数据不能被修改,把他防御性地拷贝到不可变的集合是个很好的实现,在 Java 中,不可变集合(Immutable Collection) 是指一旦创建后,其内容(元素数量、元素值、结构)就无法被修改的集合。这意味着不能向其中添加、删除元素,也不能修改已有元素的引用(对于可变对象,其内部状态仍可能被修改)。
在List,Set,Map接口中,都存在静态的of方法,去获取一个不可变的集合
| 方法名称 | 说明 |
| static <E> List<E> of(E...elements) | 创建一个有指定元素的List集合对象 |
| static <E> Set<E> of(E...elements) | 创建一个有指定元素的Set集合对象 |
| static <K,V> Map<K,V> of(E...elements) | 创建一个有指定元素的Map集合对象 |
注意:Set和Map的元素不能重复
Map.of参数个数是有限的,最多只能创建10个键值对
两个可变参数不能共存
创建不可变的Map集合,参数个数超过10个要用以下方法
Map<String, String> map=new HashMap<>();
map.put("key1", "value1");
map.put("key2", "value2");
map.put("key3", "value3");
map.put("key4", "value4");
map.put("key5", "value5");
map.put("key6", "value6");
Map.ofEntries(map.entrySet().toArray(new Entry[0])原理是:toArray()方法 会比较集合长度和数组长度,如果集合长度>数组长度,此时会根据实际个数,重新创建数组,如果集合长度<=数组长度,此时数据在数组中放的下,可以直接用
在jdk10后引入了copyOf方法它的源码实现就是

测试Demo
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class demo1 {
public static void main(String[] args) {
Map<String, String> map=new HashMap<>();
map.put("key1", "value1");
map.put("key2", "value2");
map.put("key3", "value3");
map.put("key4", "value4");
map.put("key5", "value5");
map.put("key6", "value6");
//获取所有键值对对象
Set<Map.Entry<String, String>> entries = map.entrySet();
Map.Entry[] arr = new Map.Entry[0];
//此时创建的是一个不可变的数组
//toArray()方法 会比较集合长度和数组长度
//如果集合长度>数组长度,此时会根据实际个数,重新创建数组
//如果集合长度<=数组长度,此时数据在数组中放的下,可以直接用
Map<Object, Object> staticMap = Map.ofEntries(entries.toArray(arr));
//此方法会报错
//staticMap.put("key7", "value7");
//jdk10后
Map<String, String> copyMap = Map.copyOf(map);
copyMap.put("key1", "value1");
}
}
Sream流
Java 8引入了Stream API,它提供了一种高效且易于使用的数据处理方式,特别适合集合对象的操作,如过滤、映射、排序等。Stream API不仅可以提高代码的可读性和简洁性,还能利用多核处理器的优势进行并行处理。让我们通过两个具体的例子来感受下Java Stream API带来的便利,对比在Stream API引入之前的传统做法。
Stream 操作通常分为三个步骤:创建 Stream → 中间操作 → 终止操作。
创建Stream流
| 获取方式 | 方法名 | 说明 |
|---|---|---|
| 单列集合 | default Stream<E> stream() | Collection 中的默认方法 |
| 双列集合 | 一般无法直接获取,一般需要先转化为可用的集合比如Map.EntrySet(),Map.KeySet() | 无法直接使用 stream 流 |
| 数组 | public static <T> Stream<T> stream(T[] array) | Arrays 工具类中的静态方法 |
| 一堆零散数据 | public static<T> Stream<T> of(T... values) | Stream 接口中的静态方法 |
Stream接口中的静态方法 of ,该方法的形参是一个可变参数,可以传递一堆零散的数据,也可以传递数组,但是数组必须是引用数据类型的,如果传递基本数据类型,会把整个数组当做一个元素放到Steam之中
public class demo3 {
public static void main(String[] args) {
int[] list1=new int[]{1,2,3,4,5};
String[] list2=new String[]{"a","b","c","d","e"};
List<Integer> list3=new ArrayList<>();
Collections.addAll(list3,1,2,3,4,5);
Stream.of(list1).forEach(a->System.out.println(a));
}
}
中间方法
中间操作用于对 Stream 进行处理和转换,返回一个新的 Stream。多个中间操作可以链式调用,形成处理管道,且修改Stream流,原数组集合不会受到影响。
| 方法声明 | 说明 |
|---|---|
Stream<T> filter(Predicate<? super T> predicate) |
过滤元素(满足 Predicate 条件的保留) |
Stream<T> limit(long maxSize) |
获取流中前 maxSize 个元素 |
Stream<T> skip(long n) |
跳过流中前 n 个元素 |
Stream<T> distinct() |
元素去重(依赖元素的hashCode()和equals()方法) |
static <T> Stream<T> concat(Stream<T> a, Stream<T> b) |
合并两个 Stream 为一个新流 |
Stream<R> map(Function<T, R> mapper) |
转换流中元素的类型(由 Function 定义转换规则) |
Stream<T> sorted() |
自然排序(元素需实现 Comparable 接口,按自然顺序排序) |
Stream<T> peek(Consumer<? super T> action) |
对每个元素执行操作(如调试打印、修改元素内部状态等),返回原类型流 |
注意
测试demo
public class demo4 {
public static void main(String[] args) {
// 准备原始数据(包含重复元素、不同大小的整数)
List<Integer> originalList = Arrays.asList(1, 2, 2, 3, 4, 5, 6, 6, 7, 8, 9);
System.out.println("原始集合: " + originalList);
// ====================== 1. filter 测试 ======================
System.out.println("\n--- 1. filter (过滤出大于3的元素) ---");
originalList.stream()
.filter(num -> num > 3)
.forEach(System.out::print);
// ====================== 2. limit 测试 ======================
System.out.println("\n--- 2. limit (获取前3个元素) ---");
originalList.stream()
.limit(3)
.forEach(System.out::print);
// ====================== 3. skip 测试 ======================
System.out.println("\n--- 3. skip (跳过前3个元素) ---");
originalList.stream()
.skip(3)
.forEach(System.out::print);
// ====================== 4. distinct 测试 ======================
System.out.println("\n--- 4. distinct (元素去重) ---");
originalList.stream()
.distinct()
.forEach(System.out::print);
// ====================== 5. concat 测试 ======================
System.out.println("\n--- 5. concat (合并两个流) ---");
Stream<Integer> streamA = Stream.of(10, 11);
Stream<Integer> streamB = Stream.of(12, 13);
Stream.concat(streamA, streamB)
.forEach(System.out::print);
// ====================== 6. map 测试 ======================
System.out.println("\n--- 6. map (转换元素类型:Integer -> String,添加前缀) ---");
originalList.stream()
.map(num -> "数字:" + num)
.forEach(System.out::println);
// ====================== 7. sorted 测试 ======================
System.out.println("\n--- 7. sorted把顺序改为从大到小 ---");
originalList.stream()
.sorted((a,b)->b-a)
.forEach(System.out::print);
// ====================== 8. peek 测试 ======================
System.out.println("\n--- 7. peek ---");
List<Integer> result = originalList.stream()
.filter(n -> n % 2 == 0) // 筛选偶数
.peek(n -> System.out.println("过滤后的元素:" + n)) // 窥视中间结果
.map(n -> n * 2) // 乘以2
.peek(n -> System.out.println("乘以2后的元素:" + n)) // 再次窥视
.collect(Collectors.toList()); // 终端操作(触发执行)
System.out.println("最终结果:" + result);
// ====================== 链式编程演示(多个中间操作组合) ======================
System.out.println("\n--- 链式编程:filter(偶数) -> distinct -> limit(2) -> map(加后缀) ---");
originalList.stream()
.filter(num -> num % 2 == 0) // 过滤偶数
.distinct() // 去重
.limit(2) // 取前2个
.map(num -> num + "-偶数") // 转换为带后缀的字符串
.forEach(System.out::println);
// ====================== 验证“不影响原集合” ======================
System.out.println("\n--- 验证:修改Stream数据不会影响原集合 ---");
System.out.println("原集合(修改前): " + originalList);
// 在Stream中修改元素(乘以10)
originalList.stream()
.map(num -> num * 10)
.forEach(modifiedNum -> System.out.println("Stream中修改后:" + modifiedNum));
System.out.println("原集合(修改后): " + originalList); // 原集合无变化
}
}
终止操作
| 方法声明 | 作用说明 | 特点 |
|---|---|---|
void forEach(Consumer action) |
遍历流中所有元素,对每个元素执行 action 操作(如打印、修改属性等) |
无返回值,纯粹的消费操作;并行流中可能乱序执行 |
long count() |
统计流中元素的数量 | 返回 long 类型结果,是一个终端操作(执行后流关闭) |
Object[] toArray() |
将流中元素收集到一个 Object 数组中 |
返回类型固定为 Object[],如需指定类型需用重载方法 toArray(IntFunction) |
collect(Collector collector) |
将流中元素收集到集合(如 List、Set)或其他容器中,支持复杂收集逻辑 |
灵活性最高,可通过 Collectors 工具类实现多种收集需求(分组、拼接等) |
注意:toArray()方法负责创建一个指定类型的数组
此外还有进行查找和匹配的方式进行终结
| 法声明 | 作用说明 | 特点 |
|---|---|---|
boolean allMatch(Predicate<T> predicate) |
判断流中 所有元素 是否都满足 predicate 指定的条件 |
终端操作,支持 短路求值(发现不满足元素时立即终止遍历) |
boolean anyMatch(Predicate<T> predicate) |
判断流中 是否存在至少一个元素 满足 predicate 指定的条件 |
终端操作,支持 短路求值(发现满足元素时立即终止遍历) |
boolean noneMatch(Predicate<T> predicate) |
判断流中 所有元素 是否都 不满足 predicate 指定的条件 |
终端操作,支持 短路求值(发现满足元素时立即终止,返回 false) |
Optional<T> findFirst() |
返回流中 第一个元素(按遍历顺序),结果包装为 Optional<T> |
终端操作;顺序流中稳定返回首元素,并行流中也优先取首元素(但需注意并行遍历的顺序影响) |
Optional<T> findAny() |
返回流中 任意一个元素,结果包装为 Optional<T> |
终端操作;并行流中效率更高(无需严格顺序),顺序流中通常返回首元素,但无严格保证 |
Optional<T> max(Comparator<T> comparator)Optional<T> min(Comparator<T> comparator) |
根据 comparator 规则,返回流中的 最大 / 最小元素,结果包装为 Optional<T>(空流时为 empty) |
终端操作;需提供比较器,空流时返回 Optional.empty() |
测试demo
import java.util.Arrays;
import java.util.List;
public class demo6 {
public static void main(String[] args) {
List<Integer> originalList = Arrays.asList(1, 2, 2, 3, 4 , 6, 6, 8 );
System.out.println("原始集合: " + originalList);
System.out.println("allMatch");
if(originalList.stream().skip(3).allMatch(x->x%2==0)){
System.out.println("true");
}else{
System.out.println("false");
}
if(originalList.stream().skip(4).allMatch(x->x%2==0)){
System.out.println("true");
}else{
System.out.println("false");
}
System.out.println();
System.out.println("anyMatch");
if(originalList.stream().skip(3).anyMatch(x->x%2!=0)){
System.out.println("true");
}else{
System.out.println("false");
}
if(originalList.stream().skip(4).allMatch(x->x%2!=0)){
System.out.println("true");
}else{
System.out.println("false");
}
System.out.println();
System.out.println("findFirst");
System.out.println(originalList.stream().skip(1).findFirst());
System.out.println(originalList.stream().skip(2).findFirst());
System.out.println();
System.out.println("max min");
System.out.println(originalList.stream().skip(1).max((a, b) -> a - b));
System.out.println(originalList.stream().skip(1).max((a, b) -> b - a));
}
}
collect
collect是比较全能的终止操作,通过Collectors工具类可以将 Stream 转换为集合、Map 或进行分组等复杂操作。
测试demo-转化为list,set,map
import java.util.*;
import java.util.function.Function;
import java.util.stream.Collectors;
public class demo7 {
public static void main(String[] args) {
ArrayList<String> list1 = new ArrayList<>();
Collections.addAll(list1, "张无忌-男-15", "周芷若-女-14", "赵敏-女-13",
"张强-男-20", "张三丰-男-100", "张翠山-男-40", "张良-男-35", "王二麻子-男-37", "谢广坤-男-41");
ArrayList<String> list2 = new ArrayList<>();
Collections.addAll(list2, "张无忌-男-15","张无忌-男-15", "周芷若-女-14", "赵敏-女-13",
"张强-男-20", "张三丰-男-100", "张翠山-男-40", "张良-男-35", "王二麻子-男-37", "谢广坤-男-41");
//目标提取男性的年龄
List<String> collect = list1.stream().filter(x -> "男".equals(x.split("-")[1]))
.collect(Collectors.toList());
System.out.println(collect);
//转化为set可以去重
Set<String> collect1 = list2.stream().filter(x -> "男".equals(x.split("-")[1]))
.collect(Collectors.toSet());
System.out.println(collect1);
//转化为map
Map<String, Integer> collect2 = list1.stream().filter(x -> "男".equals(x.split("-")[1]))
.collect(Collectors.toMap(
new Function<String, String>() {
@Override
public String apply(String s) {
return s.split("-")[0];
}
},
new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.parseInt(s.split("-")[2]);
}
}
));
Map<String, Integer> collect3 = list1.stream().filter(x -> "男".equals(x.split("-")[1]))
.collect(Collectors.toMap(s -> s.split("-")[0],
s -> Integer.parseInt(s.split("-")[2])));
System.out.println(collect2);
System.out.println(collect3);
}
}
并行流
并行流(ParallelStream)就是将源数据分为多个子流对象进行多线程操作,然后将处理的结果再汇总为一个流对象,底层是使用通用的 fork/join 池来实现,即将一个任务拆分成多个 “小任务” 并行计算,再把多个 “小任务” 的结果合并成总的计算结果,它是 Stream 实现并行计算的关键,它能自动利用多核处理器的优势,无需手动创建线程池。
ForkJoinPool 是 Java 中专为 “分而治之” 并行计算设计的线程池,其核心是将大任务拆分为可并行执行的小任务(Fork),待所有小任务完成后合并结果(Join);它通过 “工作窃取” 算法让空闲线程主动获取其他线程的任务,提高线程利用率,默认使用全局共享的公共池(并行度为 CPU 核心数 - 1),适合处理 CPU 密集型任务,不适合包含大量阻塞操作的场景。
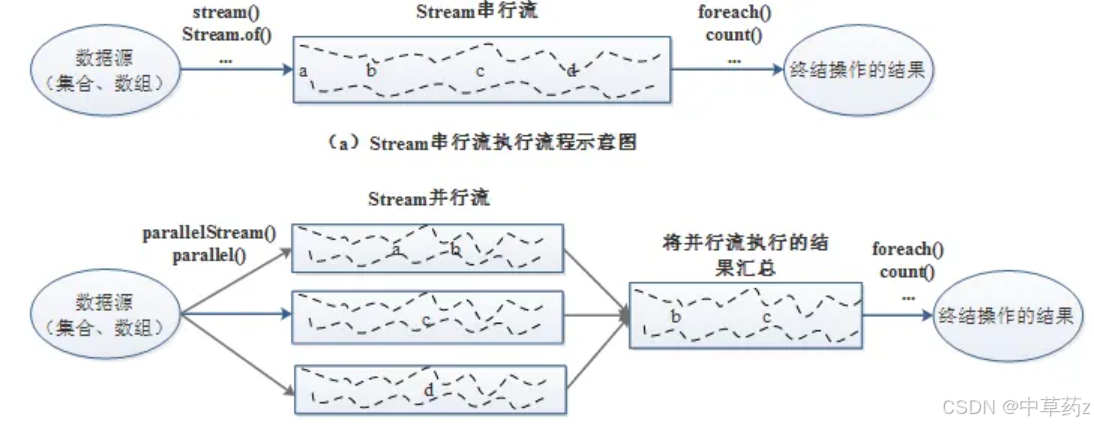
使用并行流
只需将stream()替换为parallelStream(),或调用stream().parallel():
// 并行计算1到1000万的和
long sum = IntStream.rangeClosed(1, 10_000_000)
.parallel() // 转为并行流
.sum();注意事项
- 避免在并行流中操作共享变量(可能导致线程安全问题)
- 并非所有场景都适合并行流:小规模数据或计算密集型任务可能因线程开销反而变慢
- 并行流使用
Fork/Join框架,默认线程数为 CPU 核心数 - 有序集合(如 List)的并行流会保持顺序,但会增加开销;无序集合可使用
unordered()提升性能
要为重活而高兴,不要为死去的忧伤。 ——林清玄
🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀
以上,就是本期的全部内容啦,若有错误疏忽希望各位大佬及时指出💐
制作不易,希望能对各位提供微小的帮助,可否留下你免费的赞呢🌸