十一、视图
视图是一张虚拟表,其内容由一条 SELECT 语句定义。它只保存 SQL 逻辑,不存储实际数据(除非是有物化视图),对数据的操作其实是对基表的数据进行操作。调用视图时,数据库会把视图定义中的 SQL 与外部查询合并,再对基表(base table)执行
视图的优点
逻辑解耦:对外暴露统一接口,底层表结构变化对应用透明。
权限隔离:只授予视图权限,而不暴露基表。
简化查询:把常用 JOIN/聚合封装成视图,SQL 更简洁。
兼容老系统:老代码用旧字段名,可在视图中做列别名/计算列。
视图的缺点
性能损耗:每次查询都要实时执行视图 SQL,复杂视图可能导致全表扫描/重复计算。
维护成本:基表变化(列改名、删列)可能导致视图失效。
更新限制:复杂视图无法直接 DML,需要额外触发器或存储过程。
1、基本语法
-- 创建
CREATE [OR REPLACE] VIEW <视图名称> AS
SELECT <要封装的字段>
FROM <封装语句所处的表> <可加条件>;
-- 查询视图
SELECT * FROM <视图名称> <后面可加条件>
-- 查询建视图语句
SHOW CREATE VIEW <视图名称>; # 包含默认参数
-- 修改视图
# 使用创建语句替换
CREATE OR REPLACE VIEW <视图名称> AS
SELECT <要封装的字段>
FROM <封装语句所处的表> <可加条件>;
# 或使用alter修改
ALTER VIEW <视图名称> AS
SELECT <要封装的字段>
FROM <封装语句所处的表> <可加条件>;
-- 删除
DROP VIEW [IF EXISTS] <视图名称>;2、检查选项
2.1cascaded
当我们通过视图插入或更新数据时,如果没有使用WITH CHECK OPTION:
MySQL只会检查数据是否符合基表的约束(如主键、NOT NULL等)
不会检查数据是否符合视图的WHERE条件
数据会成功插入基表,但可能无法通过该视图查询到
当我们使用了检查语句:
WITH CASCADED CHECK OPTION:检查所有底层视图的条件(默认行为)
-- 给出测试案例即预测结果
create table view_test(
id int primary key not null unique comment '学号',
name varchar(20) comment '姓名',
age smallint comment '年龄',
gender varchar(1) comment '性别'
)comment '视图测试表';
INSERT INTO view_test (id, name, age, gender) VALUES
(1, '张三', 12, '男'),
(2, '李四', 22, '女'),
(3, '王五', 15, '男'),
(4, '赵六', 18, '女'),
(5, '孙七', 25, '男');
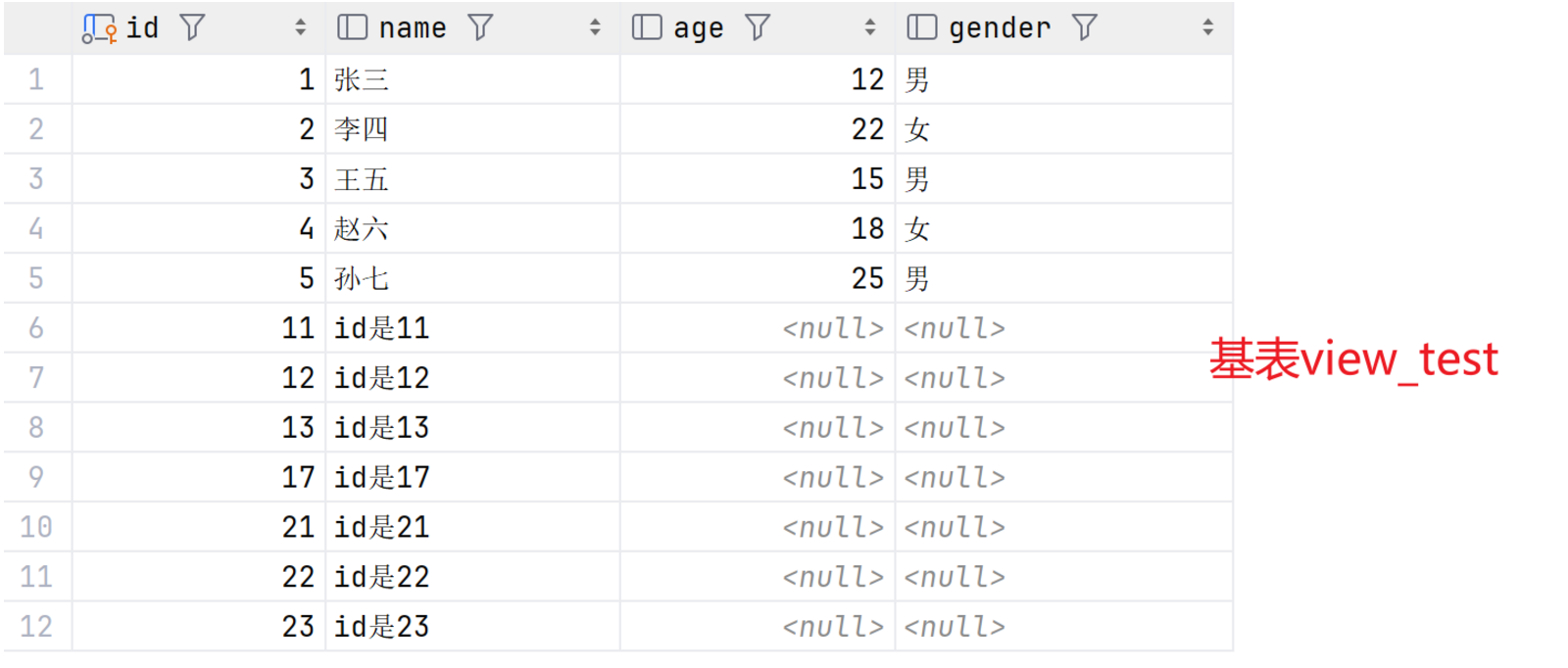
SELECT * FROM view_test;
-- 基于基表创建 view_1 视图
CREATE OR REPLACE VIEW view_1 AS SELECT id, name FROM view_test WHERE id <= 20;
# 预计成功,因为插入id=11 <= 20,满足 view_1 条件
INSERT INTO view_1 VALUES (11,'id是11');
# 预计成功,因为没有使用检查选项,故不检查是否id满足条件,数据实际插入到了基表 view_test 中,但通过view_1 查询不到这条记录
INSERT INTO view_1 VALUES (21,'id是21');
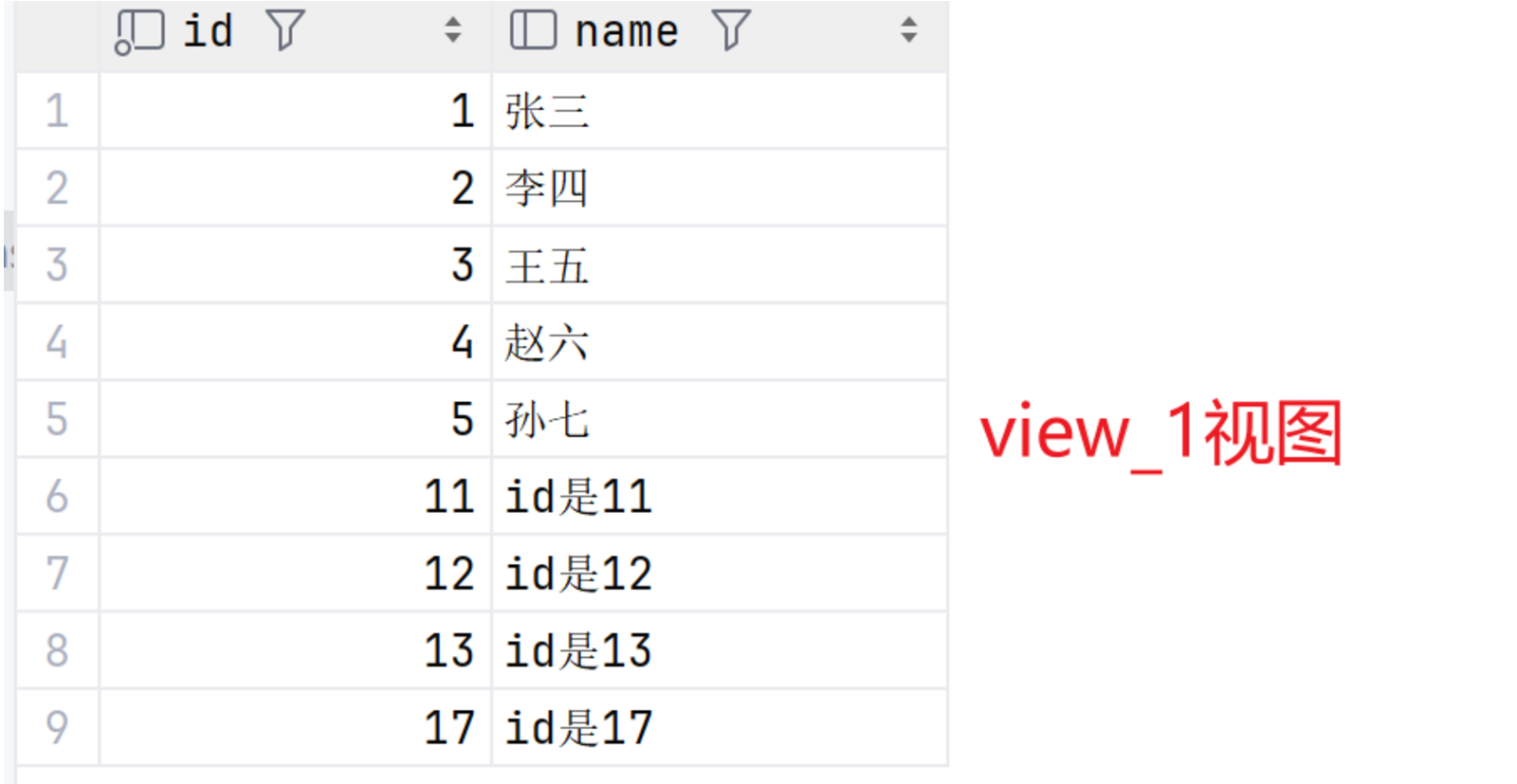
SELECT * FROM view_1;
-- 基于 view_1 视图创建 view_2 视图
CREATE OR REPLACE VIEW view_2 AS SELECT id, name FROM view_1 WHERE id >= 10 WITH CASCADED CHECK OPTION ;
# 预计失败,因为使用了检查选项,插入id=6 < 10,不满足view_2条件
INSERT INTO view_2 VALUES (6,'id是6');
# 预计成功,因为使用了检查选项,插入id=12 > 10,满足view_2条件————>且id=12 < 20,满足view_1条件
INSERT INTO view_2 VALUES (12,'id是12');
# 预计失败,因为使用了检查选项,插入id=22 > 10,满足view_2条件————>且id=22 > 20,不满足view_1条件
INSERT INTO view_2 VALUES (22,'id是22');
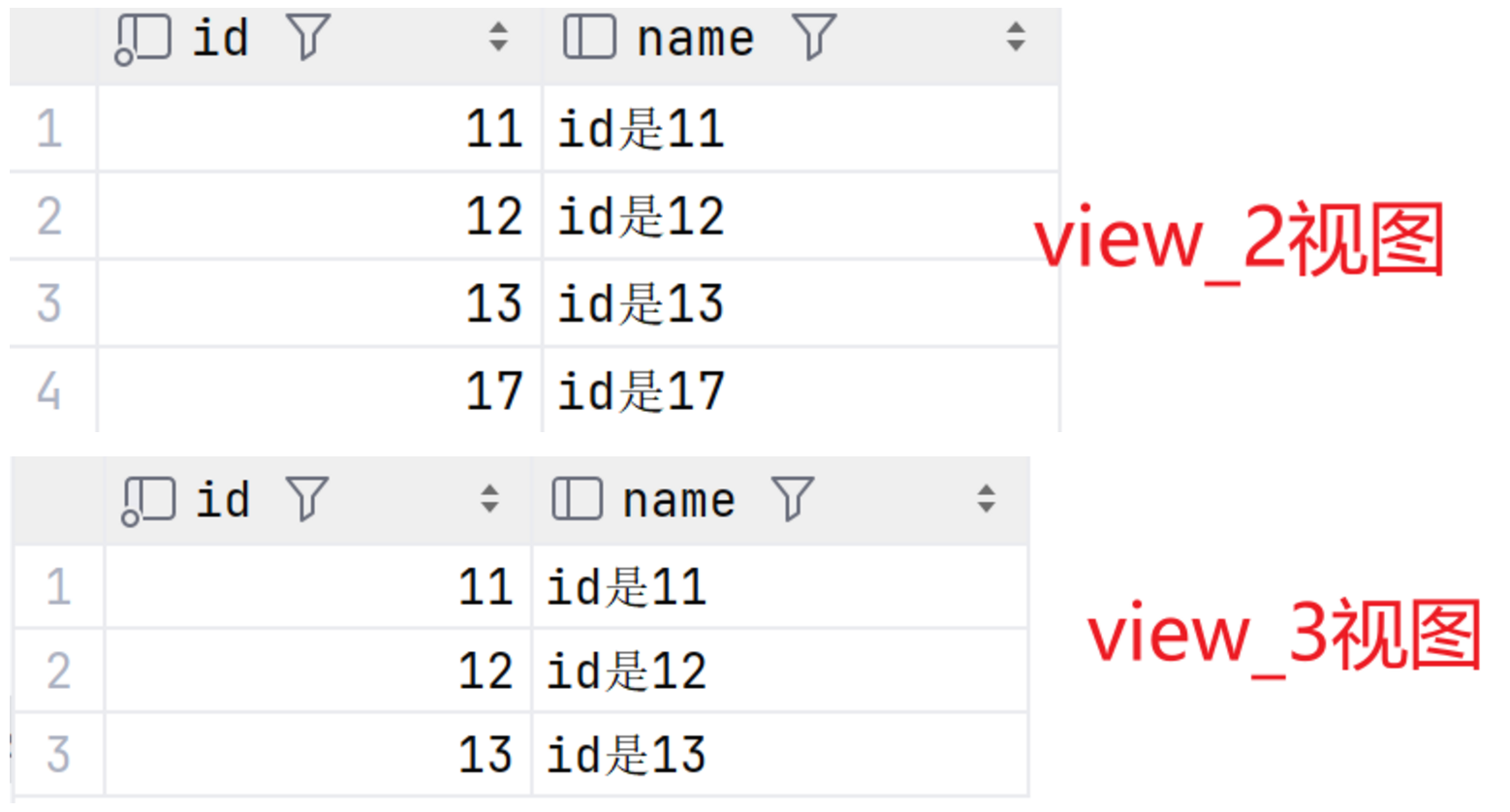
SELECT * FROM view_2;
-- 基于 view_2 视图创建 view_3 视图
CREATE OR REPLACE VIEW view_3 AS SELECT id, name FROM view_2 WHERE id <= 15;
# 预计失败,没有使用检查选项故不检查view_3条件————>因为插入id=7 < 10,不满足view_2条件
INSERT INTO view_3 VALUES (7,'id是7');
# 预计成功,没有使用检查选项故不检查view_3条件————>因为插入id=13 > 10,满足view_2条件————>且id=13 < 20,满足view_1条件
INSERT INTO view_3 VALUES (13,'id是13');
# 预计成功,没有使用检查选项故不检查view_3条件————>因为插入id=17 > 10,满足view_2条件————>且id=17 < 20,满足view_1条件
# 数据实际插入到了基表view_test中,但通过view_3查询不到这条记录,可通过view_2和view_1查看到此记录
INSERT INTO view_3 VALUES (17,'id是17');
# 预计失败,没有使用检查选项故不检查view_3条件————>因为插入id=23 > 10,满足view_2条件————>且id=23 > 20,不满足view_1条件
INSERT INTO view_3 VALUES (23,'id是23');
SELECT * FROM view_3;最终基表、view_1视图、view_2视图、view_3视图结果如图:
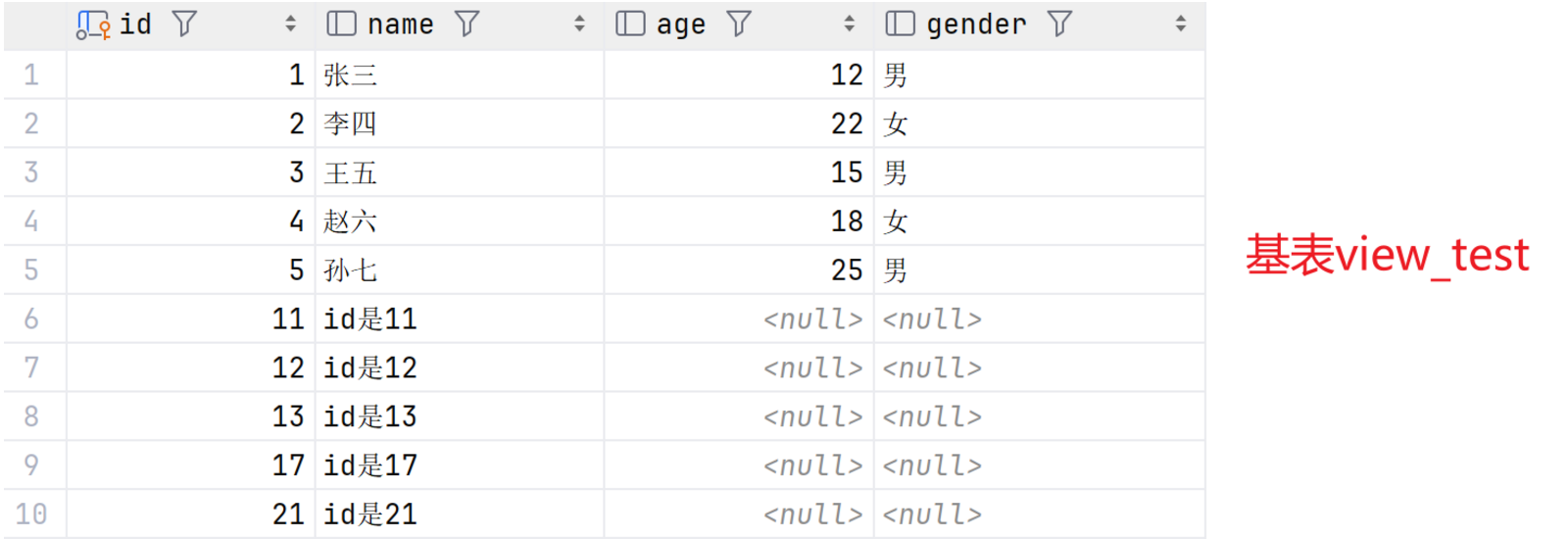
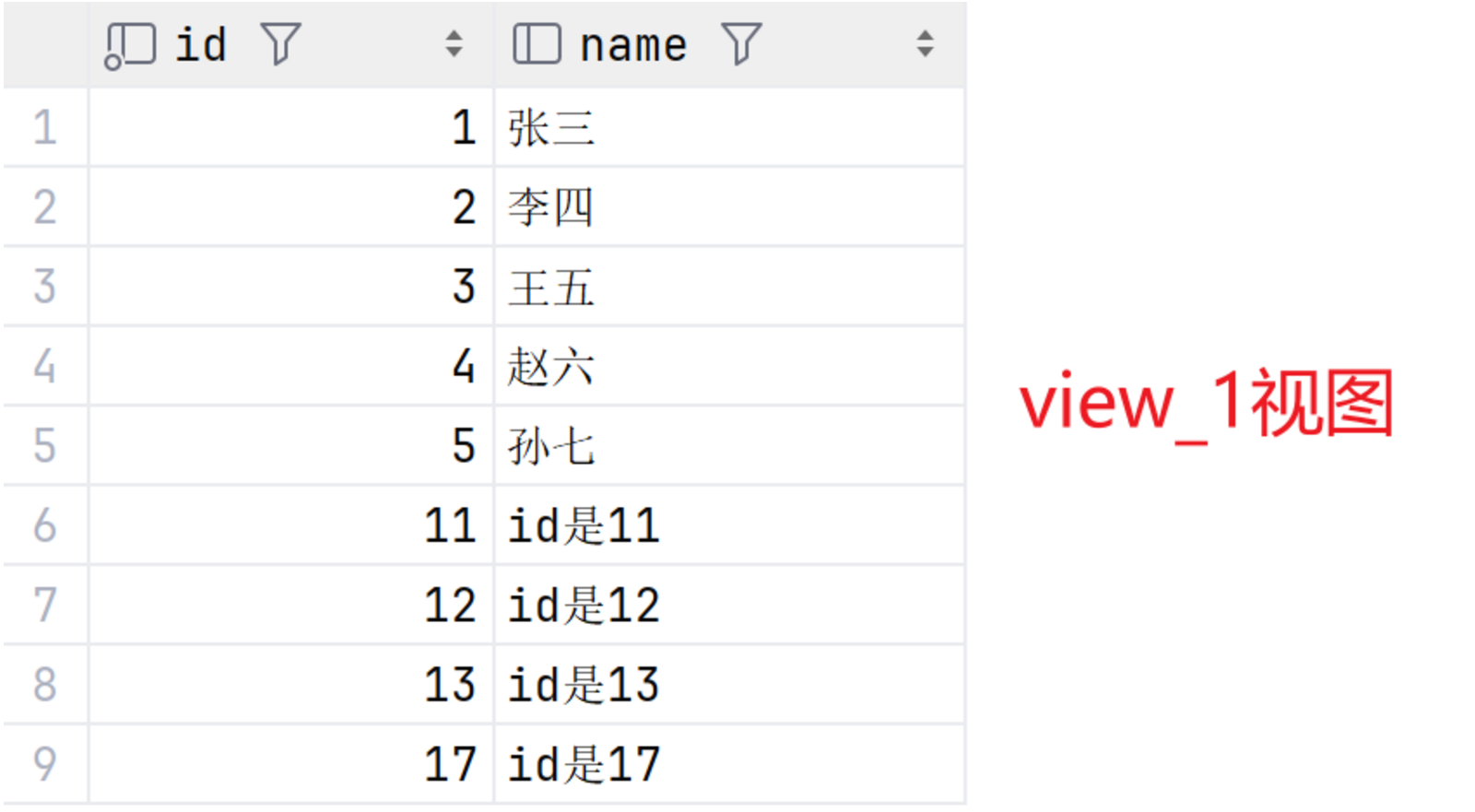
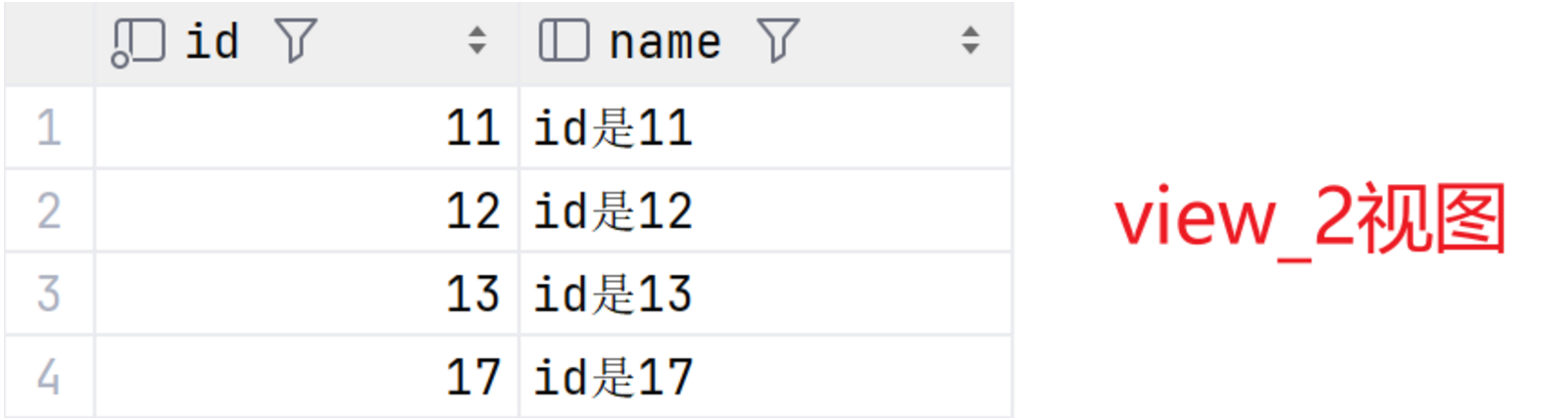
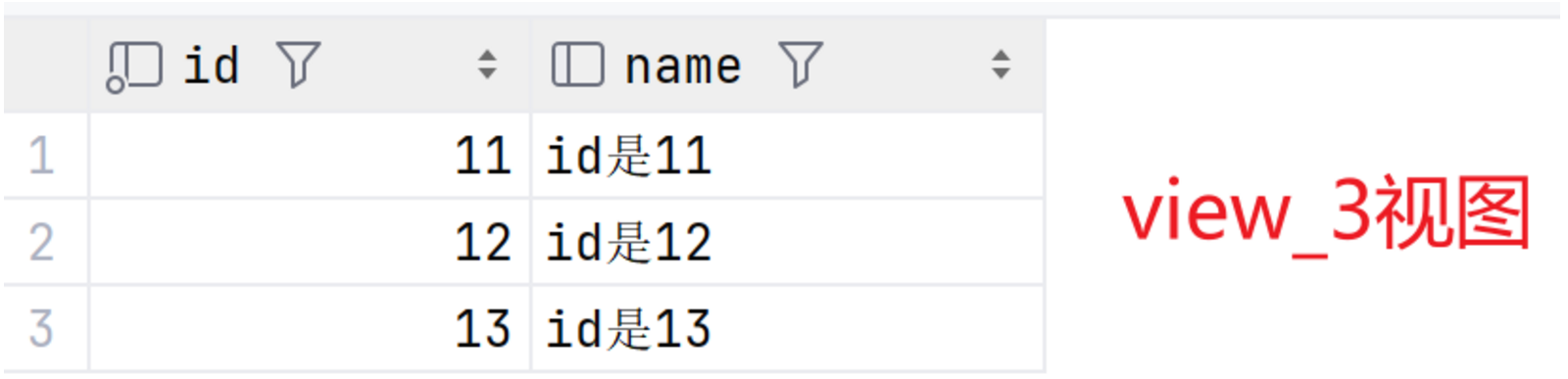
2.2local
当我们使用了检查语句:
WITH LOCAL CHECK OPTION:只检查当前视图的条件
-- 删除上面的案例,将cascaded改为loacl给出测试案例即预测结果
create table view_test(
id int primary key not null unique comment '学号',
name varchar(20) comment '姓名',
age smallint comment '年龄',
gender varchar(1) comment '性别'
)comment '视图测试表';
INSERT INTO view_test (id, name, age, gender) VALUES
(1, '张三', 12, '男'),
(2, '李四', 22, '女'),
(3, '王五', 15, '男'),
(4, '赵六', 18, '女'),
(5, '孙七', 25, '男');
SELECT * FROM view_test;
-- 基于基表创建 view_1 视图
CREATE OR REPLACE VIEW view_1 AS SELECT id, name FROM view_test WHERE id <= 20;
# 预计成功,因为插入id=11 <= 20,满足 view_1 条件
INSERT INTO view_1 VALUES (11,'id是11');
# 预计成功,因为没有使用检查选项,故不检查是否id满足条件,数据实际插入到了基表 view_test 中,但通过view_1 查询不到这条记录
INSERT INTO view_1 VALUES (21,'id是21');
SELECT * FROM view_1;
-- 基于 view_1 视图创建 view_2 视图
CREATE OR REPLACE VIEW view_2 AS SELECT id, name FROM view_1 WHERE id >= 10 WITH LOCAL CHECK OPTION ;
# 预计失败,因为使用了检查选项,插入id=6 < 10,不满足view_2条件
INSERT INTO view_2 VALUES (6,'id是6');
# 预计成功,因为使用了检查选项,插入id=12 > 10,满足view_2条件————>且 view_1 没有使用检查选项故不检查view_1条件
INSERT INTO view_2 VALUES (12,'id是12');
# 预计成功,因为使用了检查选项,插入id=22 > 10,满足view_2条件————>且 view_1 没有使用检查选项故不检查view_1条件
INSERT INTO view_2 VALUES (22,'id是22');
SELECT * FROM view_2;
-- 基于 view_2 视图创建 view_3 视图
CREATE OR REPLACE VIEW view_3 AS SELECT id, name FROM view_2 WHERE id <= 15;
# 预计失败,没有使用检查选项故不检查view_3条件————>因为插入id=7 < 10,不满足view_2条件
INSERT INTO view_3 VALUES (7,'id是7');
# 预计成功,没有使用检查选项故不检查view_3条件————>因为插入id=13 > 10,满足view_2条件————>且 view_1 没有使用检查选项故不检查view_1条件
INSERT INTO view_3 VALUES (13,'id是13');
# 预计成功,没有使用检查选项故不检查view_3条件————>因为插入id=17 > 10,满足view_2条件————>且 view_1 没有使用检查选项故不检查view_1条件
# 数据实际插入到了基表view_test中,但通过view_3查询不到这条记录,可通过view_2和view_1查看到此记录
INSERT INTO view_3 VALUES (17,'id是17');
# 预计成功,没有使用检查选项故不检查view_3条件————>因为插入id=23 > 10,满足view_2条件————>且 view_1 没有使用检查选项故不检查view_1条件
# 数据实际插入到了基表view_test中,但通过view_3、view_2和view_1查询不到这条记录
INSERT INTO view_3 VALUES (23,'id是23');
SELECT * FROM view_3;最终基表、view_1视图、view_2视图、view_3视图结果如图:
3、视图更新
在MySQL中,视图(View)的更新操作(INSERT/UPDATE/DELETE)有以下基本规则:
视图必须基于单表:不能更新基于多表JOIN的视图
不能包含聚合函数:如COUNT(), SUM(), AVG()等
不能包含DISTINCT、GROUP BY、HAVING子句
不能包含子查询在SELECT列表中
不能包含某些运算符:如UNION, UNION ALL
必须包含基表的所有NOT NULL列:除非这些列有默认值
十二、存储过程
存储过程是MySQL中一组预编译的SQL语句集合,存储在数据库中,可以通过调用来执行。
优点:
提高性能:预编译执行,减少网络传输
代码复用:一次编写,多次调用
安全性:可以限制对基表的直接访问
简化复杂操作:封装复杂业务逻辑
存储过程支持三种参数类型:
IN(输入参数,默认)OUT(输出参数)INOUT(输入输出参数)
1、基本语法
# 创建存储过程
-- 当使用命令行创建存储过程时,会默认以;为结束符
-- 当存储过程体中包含含;的SQL语句,会提示存储过程创建不成功
-- 可使用delimiter <你定义的结束符>来指定结束符不以;结束,而以自定义结束符结束
CREATE PROCEDURE 存储过程名([参数列表])
BEGIN
-- 存储过程体
-- 包含SQL语句和流程控制语句
END ;
-- 或
DELIMITER // # 自定义结束符为 //
CREATE PROCEDURE 过程名([参数列表])
BEGIN
-- 存储过程体
-- 包含SQL语句和流程控制语句
END //
DELIMITER ; # 自定义结束符为 ;
# 使用参数类型
CREATE PROCEDURE example_proc(IN|OUT|INOUT 参数名 参数类型)
BEGIN
-- 过程体
END;
-- 举例
CREATE PROCEDURE example_proc(
IN p_id INT,
OUT p_name VARCHAR(20),
INOUT p_count INT
)
BEGIN
-- 过程体
END;
# 查看所有存储过程
SHOW PROCEDURE STATUS;
# 查看特定存储过程定义
SHOW CREATE PROCEDURE 存储过程名;
# 修改存储过程
-- 先删除再重建
DROP PROCEDURE IF EXISTS 过程名;
CREATE PROCEDURE 过程名() ...
-- 或者使用ALTER(但功能有限)
ALTER PROCEDURE 过程名 [特征...]
# 删除存储过程
DROP PROCEDURE [IF EXISTS] 存储过程名;
# 调用存储过程
CALL 存储过程名([参数列表]);
2、变量
①、系统变量
系统变量是MySQL服务器提供的,又可分为全局变量和会话变量
# 查看系统变量
-- 查看所有系统变量
SHOW VARIABLES;
-- 查看会话(默认)/全局变量
SHOW [SESSION | GLOBAL] VARIABLES;
-- 查看特定系统变量(模糊匹配)
SHOW VARIABLES LIKE '变量名';
-- 查看会话/全局指定变量
SELECT @@[SESSION | GLOBAL] .<系统变量名>;
# 设置变量
-- 设置全局变量(需要管理员权限)
SET GLOBAL 变量名 = 值;
-- 设置会话变量(仅影响当前连接)
SET SESSION 变量名 = 值;
-- 或简写为
SET @变量名 = 值;②、用户自定义变量
用户变量以@开头,仅在当前会话中有效
不区分数据类型
会话结束时自动销毁
不需要预先声明
# 赋值
SET @变量名 = 表达式;
-- 或
SELECT @变量名 := 表达式;
-- 或
SELECT 表达式 INTO @变量名;
# 使用用户变量
SET @变量名;③、局部变量
局部变量仅在存储程序(存储过程、函数、触发器)中使用,需要先声明后使用。
必须在使用前声明
只在BEGIN...END块中有效
有明确的数据类型
# 声明局部变量
DECLARE 变量名 数据类型 [DEFAULT 默认值];
# 赋值
SET 变量名 = 表达式;
-- 或
SET 变量名 := 表达式;3、流程控制
IF语句
CASE语句
循环(WHILE【满足条件进入循环】, REPEAT【满足条件退出循环】, LOOP)
# IF 语句
IF <条件1> THEN
<要执行的语句1>
ELSEIF <条件2> THEN
<要执行的语句2>
ELSE
<要执行的语句3>
END IF;
-- IF 举例
DELIMITER // -- 定义一个存储过程
CREATE PROCEDURE check_age_status(IN s_id INT)
BEGIN
DECLARE s_age INT; -- 定义变量
DECLARE status VARCHAR(20);
SELECT age INTO s_age FROM view_test WHERE id = s_id;
IF s_age < 18 THEN
SET status = '未成年';
ELSEIF s_age >= 18 AND s_age < 60 THEN
SET status = '成年';
ELSE
SET status = '老年';
END IF;
SELECT CONCAT('ID:', s_id, ' 状态:', status) AS result;
END //
DELIMITER ;
CALL check_age_status(1); -- 调用上面创建的存储过程
# CASE 语句
CASE <case 值>
WHEN <条件1> THEN <执行语句1>
WHEN <条件2> THEN <执行语句2>
WHEN <条件3> THEN <执行语句3>
。。。。
ELSE <执行语句>
END CASE;
# WHILE 语句
WHILE <条件> DO
<执行语句>
END WHILE;
-- WHILE循环示例
CREATE PROCEDURE while_example(IN max_num INT)
BEGIN
DECLARE i INT DEFAULT 1; -- 定义变量
WHILE i <= max_num DO
INSERT INTO numbers VALUES (i);
SET i = i + 1;
END WHILE;
END;
# REPEAT 语句
REPEAT
<执行语句>
UNTIL <退出条件>
END REPEAT;
-- REPEAT循环示例
CREATE PROCEDURE repeat_example(IN max_num INT)
BEGIN
DECLARE i INT DEFAULT 1;
REPEAT
INSERT INTO numbers VALUES (i);
SET i = i + 1;
UNTIL i > max_num END REPEAT;
END;
# 不使用 LEAVE/ITERATE 的LOOP 语句(死循环无退出条件)
<标记1:>LOOP
<执行语句>
END LOOP;
# 使用了 LEAVE 的 LOOP 语句
<标记1:>LOOP
<执行语句>
LEAVE <标记1>; -- 相当于break
END LOOP <标记1>;
# 使用了 ITERATE 的 LOOP 语句
<标记1:>LOOP
<执行语句>
ITERATE <标记1>; -- 相当于continue
END LOOP <标记1>;4、游标(cursor)
游标类似变量,只不过变量只可以存储单一数据,游标是存储数据集,是MySQL中用于遍历结果集的一种数据库对象,特别适用于在存储过程和函数中处理多行数据。
①、游标的工作流程:
声明游标:定义要遍历的结果集
打开游标:执行查询并填充结果集
获取数据:逐行读取结果
关闭游标:释放资源
②、基本语法
# 声明游标
DECLARE 游标名称 CURSOR FOR SELECT语句;
# 打开游标
OPEN 游标名称;
# 获取数据
FETCH 游标名称 INTO 变量列表;
# 关闭游标
CLOSE 游标名称;
# 游标异常处理(条件处理程序)
DECLARE handler_type HANDLER FOR condition_value [, condition_value] ... handler_statements
# 处理游标结束(NOT FOUND)
DECLARE CONTINUE HANDLER FOR NOT FOUND SET 结束标志 = TRUE;
-- 举例
DELIMITER // # 自定义结束符为 //
CREATE PROCEDURE update_student_scores() # 创建一个存储过程 update_student_scores
BEGIN
DECLARE done INT DEFAULT FALSE; # 定义整形变量 done ,初始值为FALSE(0)
DECLARE s_id INT; # 定义整形变量 s_id
DECLARE s_score DECIMAL(5,2); # 定义整形变量 s_score
DECLARE new_score DECIMAL(5,2);
-- 声明游标:获取需要更新的学生
DECLARE cur CURSOR FOR # 声明一个叫 cur 的游标
# 获取students表中所有分数低于60分的学生ID和分数
SELECT id, score FROM students WHERE score < 60;
# 声明一个异常处理器,当游标读取不到更多数据时(NOT FOUND),将done变量设为TRUE(1)
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
OPEN cur; # 打开游标
update_loop: LOOP # 给循环加入标签 update_loop
FETCH cur INTO s_id, s_score; # 获取 s_id 和 s_score 的数据并赋给游标 cur
IF done THEN
LEAVE update_loop; # 如果读取数据完毕就跳出 LOOP 循环
END IF;
-- 计算新分数(示例:给不及格学生加10分,但不超过60)
SET new_score = LEAST(s_score + 10, 60);
-- 更新记录
UPDATE students SET score = new_score WHERE id = s_id;
# 返回更新完成的提示信息
SELECT CONCAT('已更新ID:', s_id, ' 原分数:', s_score, ' 新分数:', new_score) AS 更新日志;
END LOOP;
CLOSE cur; # 关闭游标,释放相关资源
SELECT '分数更新完成' AS 结果; # 返回操作完成的提示信息
END //
DELIMITER ; # 自定义结束符为 ;③、条件处理程序
# 游标异常处理(条件处理程序)
DECLARE handler_type HANDLER FOR condition_value [, condition_value] ... handler_statementshandler_type:处理程序类型
CONTINUE:执行处理语句后继续程序EXIT:执行处理语句后退出当前BEGIN...END块UNDO:执行处理语句后回滚操作(MySQL中不支持)
condition_value:可捕获的条件
SQLSTATE [VALUE] sqlstate_valuecondition_name:用户定义的命名条件SQLWARNING:以'01'开头的SQLSTATE代码NOT FOUND:以'02'开头的SQLSTATE代码(常用于游标)SQLEXCEPTION:不以'00'、'01'、'02'开头的SQLSTATE代码
handler_statements:触发条件时要执行的语句
④、游标的特性
只读:游标不能用于修改数据
单向:只能向前移动,不能后退
十三、触发器
触发器(Trigger)是MySQL中的一种特殊存储过程,它会在特定数据库事件(INSERT、UPDATE、DELETE)发生时自动执行。
1、基本语法
# 创建触发器
CREATE TRIGGER 触发器名称
触发时机(BEFORE|AFTER) 触发事件(INSERT|UPDATE|DELETE)
ON 表名
FOR EACH ROW -- 行级触发器
BEGIN
-- 触发器逻辑
END;
# 查看触发器
SHOW TRIGGERS;
# 删除触发器
-- 若没指定数据库名称,默认是当前数据库
DROP TRIGGERS <数据库名称>.<触发器名称>;2、组成部分:
①、触发时机:
BEFORE:在操作执行前触发AFTER:在操作执行后触发
②、触发事件:
INSERT:插入数据时触发UPDATE:更新数据时触发DELETE:删除数据时触发
③、FOR EACH ROW:
表示行级触发器(MySQL只支持行级触发器)
3、特殊变量
在触发器内部,可以使用两个特殊变量访问受影响的数据:
NEW:引用新数据(用于INSERT和UPDATE)OLD:引用旧数据(用于UPDATE和DELETE)
4、举例
# BEFORE INSERT
DELIMITER //
CREATE TRIGGER before_student_insert # 创建一个叫 before_student_insert 的触发器
BEFORE INSERT ON students # 在对表 students 进行插入操作之前触发
FOR EACH ROW # 行级触发器
BEGIN
-- 自动设置创建时间为当前时间
SET NEW.created_at = NOW();
-- 验证数据
IF NEW.age < 0 THEN
SIGNAL SQLSTATE '45000'
SET MESSAGE_TEXT = '年龄不能为负数';
END IF;
END //
DELIMITER ;
# AFTER UPDATE
DELIMITER //
CREATE TRIGGER after_student_update # 创建一个叫 after_student_update 的触发器
AFTER UPDATE ON students # 在对表 students 进行更新操作之后触发
FOR EACH ROW
BEGIN
-- 记录变更历史
IF NEW.name != OLD.name THEN
INSERT INTO student_change_log(student_id, changed_field, old_value, new_value)
VALUES(OLD.id, 'name', OLD.name, NEW.name);
END IF;
IF NEW.score != OLD.score THEN
INSERT INTO student_change_log(student_id, changed_field, old_value, new_value)
VALUES(OLD.id, 'score', OLD.score, NEW.score);
END IF;
END //
DELIMITER ;
# BEFORE DELETE
DELIMITER //
CREATE TRIGGER before_student_delete
BEFORE DELETE ON students
FOR EACH ROW
BEGIN
-- 归档被删除的学生记录
INSERT INTO students_archive(id, name, age, score, deleted_at)
VALUES(OLD.id, OLD.name, OLD.age, OLD.score, NOW());
-- 删除相关记录
DELETE FROM student_courses WHERE student_id = OLD.id;
END //
DELIMITER ;