前言:上一篇文章我们介绍了C++入门的一些基础的语法,将了命名空间,缺省参数等。这篇文章我们就来介绍剩余的语法。

文章目录
一,函数重载
函数重载:函数重载(Function Overloading)允许在同一个作用域内定义多个同名函数,但这些函数的参数列表必须不同(参数类型、数量或顺序)。编译器根据调用时传递的实参类型和数量选择最匹配的函数版本。紫
举个例子:
void func1(int x,int y)
{
printf("%d %d",x,y);
}
void func2(double x,double y)
{
printf("%lf %lf",x,y);
}
int main()
{
int a = 10;
int b = 20;
double c = 10.0;
double d = 20.0;
//同样在调用加法函数时调用的是不同的func函数
//int类型的都调用func1
func1(a,b);
//double类型的就调用func2
func2(c,d);
return 0;
}
在C语言的学习过程中,功能相同的函数由于它们的参数类型不同,我们就要再创建一个函数并用数字区别开来,从而保证编译器能区分不同函数。本质上就是函数名不能相同。这种行为一方面增加了代码的冗余度,另一方面很麻烦如果有很多不同的类型那么我们要根据不同类型创建函数从效率上来说是很低的。
C++的祖师爷本贾尼博士觉得这个问题很麻烦,每次调用都要指定func1,func2。说能不能搞一个func函数,且可以创建多个func函数函数内部的区别就是参数不同,这样每次调用只用写func就好了,具体比较什么类型的参数由func函数自己去匹配。
于是祖师爷就创造出了函数重载。
函数重载有几种情况
情况一:参数类型不同
#include<iostream>
using namespace std;
int Add(int x,int y)
{
cout<<"int Add(int x,int y)"<<endl;
return x+y;
}
double Add(double x,double y)
{
cout<<"double Add(double x,double y)"<<endl;
return x+y;
}
int main()
{
int a = 10;
int b = 20;
double c = 10.0;
double d = 20.0;
//Add进行了函数重载 同名函数参数与返回类型不同
Add(a, b);
Add(c, d);
return 0;
}
情况二:参数顺序不同
void func(int a,char b)
{
cout<<"func(int a,char b)"<<endl;
}
void func(char a,int b)
{
cout<<"func(char a,int b)"<<endl;
}
情况三:参数的个数不同
void func()
{
cout<<"func()"<<endl;
}
void func(int a)
{
cout<<"func(int a)"<<endl;
}
情况四:返回类型不同
void func(int x,int y)
{
cout<<"func(int x,int y)"<<endl;
}
int func(int x,int y)
{
return x+y;
}
注意,仅仅是返回值不同,参数相同的同名函数是不构成函数重载的。因为在调用函数的时候也分不清到底是调用有返回值的那个还是没有返回值的那个。
情况五,在情况三的基础上加上缺省值
void func()
{
cout<<"func()"<<endl;
}
void func(int a=10)
{
cout<<"func(int a)"<<endl;
}
int main()
{
//传指定参数就直接调用第二个func函数
func(20);
//不串参数这时编译器就搞不清楚了 到底是第一个还是第二个
func();
return 0;
}
注意,这里如果不传参调用func函数就会存在歧义,因为不传参的话无参的func函数能调用,有缺省值的func函数也能调用,编译不清楚要调用哪个所以会报错。
特别注意:
- 仅仅是返回值不同,参数类型相同的同名函数不构成重载!
- 函数重载只发生在相同域或作用域里面,不同域的同名函数不叫函数重载!
二,引用
引用是C++中一个非常重要且使用的语法,且贯穿着整个C++的学习包括后面的STL部分都会使用到引用,所以学好引用是非常有必要的。
2.1引用的概念和定义
- 引用是C++中一种特殊的变量类型,本质是已存在变量的别名。它与指针类似,但更安全且语法更简洁。引用必须在声明时初始化,且无法重新绑定到其他变量。
- 在引用时使用的是C语言中的
&取地址运算符,使用方法是类型& 引用的别名=引用的对象举个例子:
#include<iostream>
using namespace std;
int main()
{
int a = 10;
//给a取一个别名叫b
int& b = a;
//也可以给b取一个别名叫c 此时c也相当于是a的别名
int& c = b;
cout << "a=" << a << endl;
++b;
cout << "++b=" << a << endl;
++c;
cout << "++c=" << a << endl;
cout<<"&a="<<&a<<endl;
cout<<"&b="<<&b<<endl;
cout<<"&c="<<&c<<endl;
return 0;
}

通过运行结果可以看到对b和c进行加加改变的是a的值,并且它们的地址还是同一个。由此我们可以得出一个结论:引用没有开新空间,引用就是给变量起了一个新的别名,对别名的操作就是对被引用对象的操作。
2.2引用的特性
- 引用在定义时必须初始化:告诉那个引用它是谁的别名,这就是对引用的初始化。
#include <iostream>
using namespace std;
int main()
{
int p=2;
//这样做是不行的 没初始化会报错
//int& rp;//至少要告诉rp引用的是谁 rp找不到引用对象就报错
int a = 1;
//对ra初始化 告诉ra它引用的是a
int& ra = a;
return 0;
}
- 一个变量可以有多个引用:就像人西游记中的孙悟空一样,有齐天大圣,弼马温,猴哥等别名,变量也一样可以有多个。
- 引用一旦引用了一个实体就不可能再引用其他的实体。就像一个狗子一般它一旦认定了一个主人就不会再认其他的主人了。
#include <iostream>
using namespace std;
int main()
{
int a=10;
int& b=a;
int& c=a;
int& d=a;
//其中bcd都是a的别名
cout << &a << endl;
cout << &b << endl;
cout << &c << endl;
cout << &d << endl;
int p=100;
d=p;
//这里要注意p是赋值给d 而不是d是p的别名
//因为d已经是a的别名了已经有一个实体了 它就不可能是另外一个变量的别名了
return 0;
}
既然引用这么重要这么有用。那我们来看看引用的引用场景。
2.3引用的引用场景
2.3.1做函数形参,修改形参影响实参
回忆一下过去在C语言中,我们通过形参来影响实参是通过指针间接来控制的,比如:
#include<stdio.h>
void swap(int*x,int*y)
{
int tmp=*x;
*x=*y;
*y=tmp;
}
int main()
{
int a=10;
int b=20;
printf("交换前:\n");
printf("a=%d\n",a);
printf("b=%d\n",b);
swap(&a,&b);
printf("交换后:\n");
printf("a=%d\n",a);
printf("b=%d\n",b);
return 0;
}
在C语言阶段,我们通过形参影响实参的方式只有通过指针交换指针指向的内容从而实现实参的交换,那C++有了引用之后就可以使用引用来平替指针比如:
#include<iostream>
using namespace std;
void swap(int&x,int&y)
{
int tmp=x;
x=y;
y=tmp;
}
int main()
{
int a = 10;
int b = 20;
swap(a, b);
cout << "a=" << a << endl;
cout << "b=" << b << endl;
return 0;
}
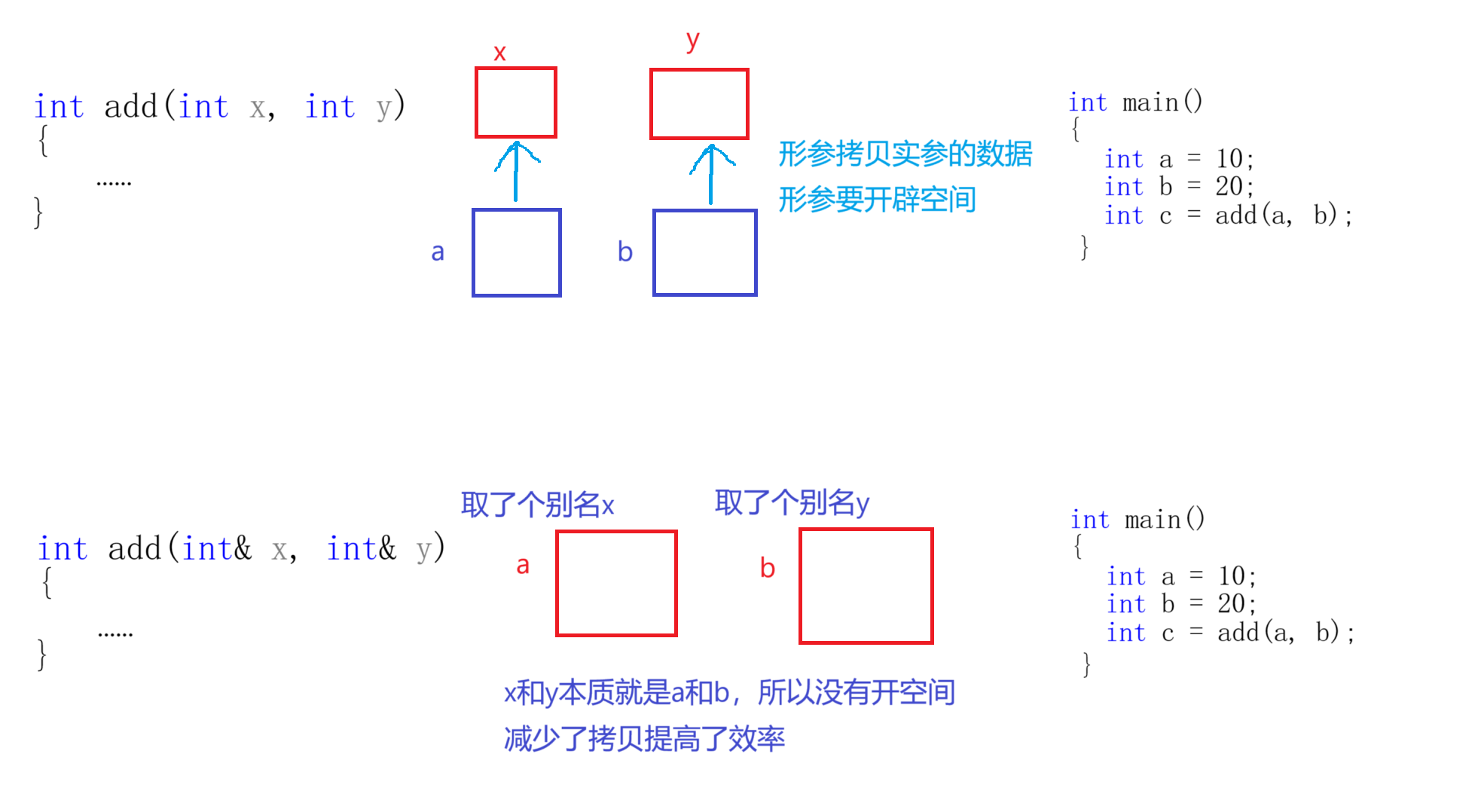
因为引用就是别名,形参中的x和y就是实参对应的别名,操作它们就相当于操作实参,所以形参的改变可以影响实参。
2.3.2 做函数形参时减少拷贝,提高效率
这个很好理解,举个例子:
int add(int x,int y)
{
return x+y;
}
int main()
{
int a=10;
int b=20;
int c=add(a,b);
}
上面这段代码是我们在C语言段会写的代码,且在C语言阶段我们知道形参是实参的临时拷贝,形参会自己开空间所以形参与实参不一样。但是C++不一样:
int add(int&x,int&y)
{
return x+y;
}
int main()
{
int a=10;
int b=20;
int c=add(a,b);
}
2.3.3 引用做返回值类型,修改返回对象,减少拷贝提高效率
首先回顾一下我们在C语言阶段学过的返回值类型有哪些?无非就是有返回值和没有返回值。有返回值一般返回的是内置类型像int char double和struct定义的结构体。
比如:
int func()
{
int ret=10;
//......
return ret;
}
int main()
{
int x=func();
//尝试修改一下返回值
func()=20;
//10=20
//被const修饰的tmp具有常量的属性不能再被修改
//const int tmp = 10;
//tmp = 20;
return 0;
}
通过上面的代码我们来看看有返回值的传值返回本质是什么?当我们尝试去修改返回值的时候,这个时候编译器就会报错:
那什么情况下会报这种左操作数为左值的错误呢?将上面那一小段将20赋值给10以及给const变量赋值的代码去编译就会出现这种错误,因此我们可以推测出:传值返回传回来的是一个临时变量(因为ret出了函数栈帧会销毁 ),该变量不能被修改的原因可能是被const修饰了,具有了常量的属性不能再被修改。

了解完了传值返回,接着我们再来看看C++支持的传引用返回:
#include<iostream>
using namespace std;
typedef struct SList
{
int* arr;
int size;
int capacity;
}SL;
void SLInit(SL& sl,int n=4)
{
int* tmp = (int*)malloc(sizeof(int) * n);
sl.arr = tmp;
sl.size = 0;
sl.capacity = 4;
}
void SLPush(SL& sl,int x)
{
if (sl.size == sl.capacity)
{
sl.arr = (int*)realloc(sl.arr, 2 * sl.capacity);
}
sl.arr[sl.size] = x;
sl.size++;
}
int& SLAt(SL& sl, int i)
{
assert(i < sl.size);
return sl.arr[i];
}
int main()
{
SL sl1;
SLInit(sl1);
SLPush(sl1, 1);
SLPush(sl1, 2);
SLPush(sl1, 3);
//传引用返回可以对返回值进行修改
SLAt(sl1, 0) += 2;
return 0;
先来分析一下
SLAt(sl1,0)+=2这段代码:
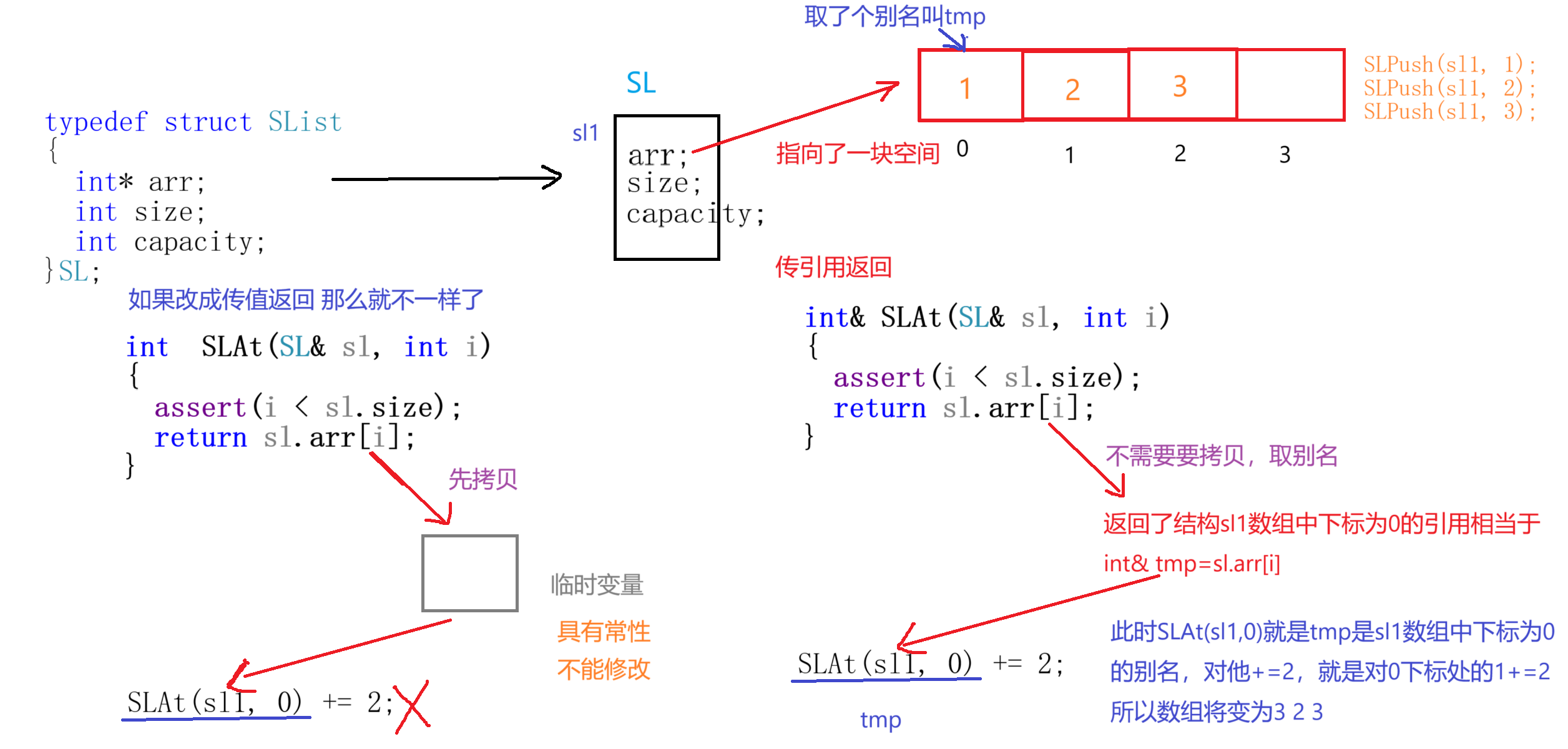
同样在上面的分析中,我们看到传值返回是要经过拷贝成临时变量才返回的,而引用返回本质就是给变量取了一个别名不需要拷贝不会浪费空间极大的提高了效率。试想:如果返回的是一个占用内存很大的结构体,使用传值返回或者做函数形参,拷贝的时候要花费多少空间?所以从节省空间这方面来说引用还是很香的!
2.4引用返回的坑
引用返回既然这么香,那么以后是否就只使用引用就好了?当然不是,引用和指针一样是一把双刃剑用的好可以快捷高效,用不好会造成一定后果。
举个例子:
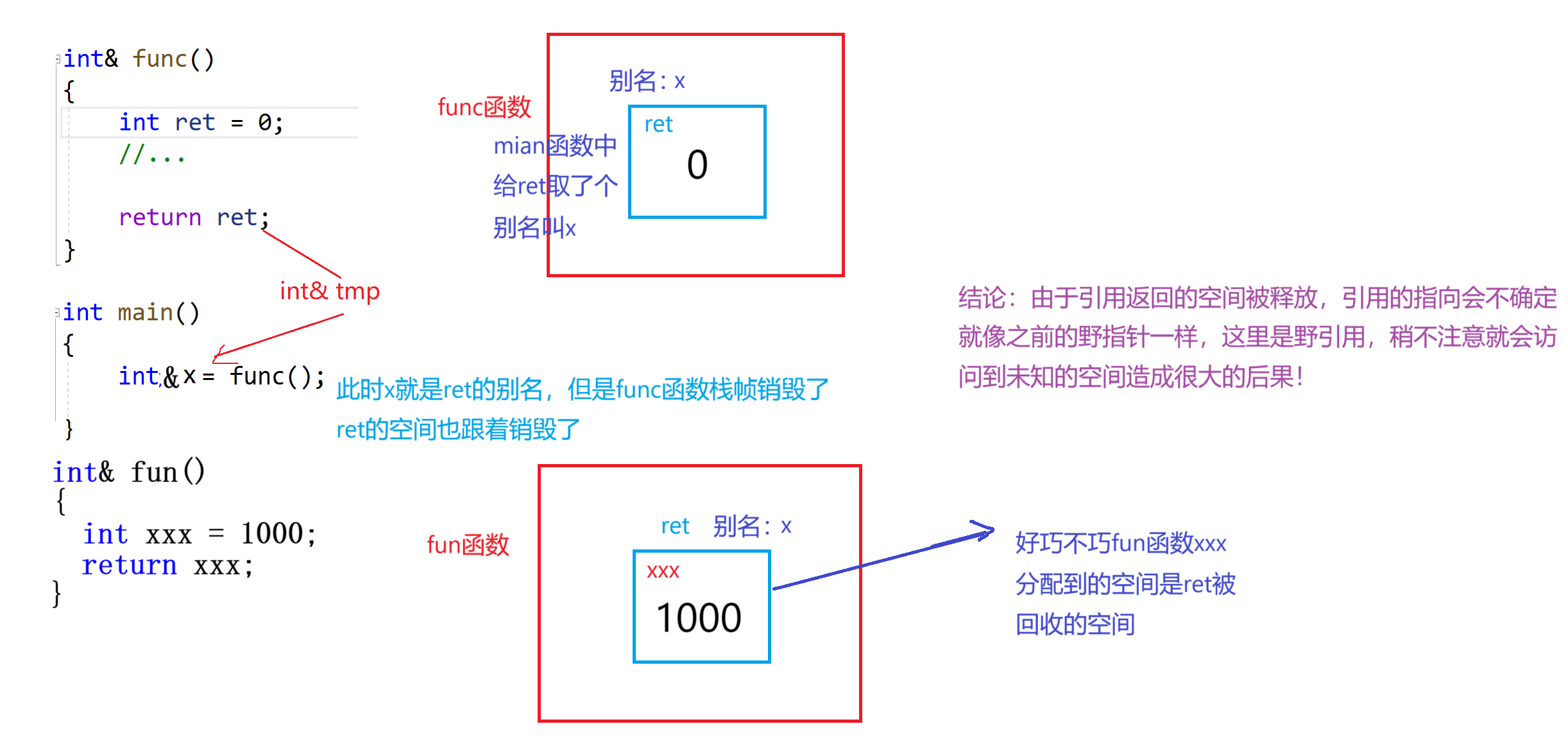
int& func()
{
int ret = 0;
//...
return ret;
}
int& fun()
{
int xxx = 1000;
//...
return xxx;
}
int main()
{
//传值返回
/*int x = func();
cout << x << endl;*/
int& x = func();
cout << x << endl;
fun();
cout << x << endl;
//野引用对越界的空间进行访问 在vs编译器下可能查不到
//因为vs编译器对越界读的行为是抽查行为
int arr[10];
//越界读不一定报错
cout<<arr[12]<<endl;
//越界写可能会报错 也有可能不会报错 vs仅在数组末尾一两个位置上设置了检查
arr[20]=1;
return 0;
}

两次打印
x,我们发现x的值竟然被fun函数中的xxx给修改了,这时为什么呢?
首先,func函数是传引用返回给了x那么x就是ret的别名没跑。第二次打印的x的值与xxx一样为1000,这很难不让人联想到x可能是xxx的别名,为什么会造成这种情况呢?原因是ret是在函数栈帧中创建的,栈帧销毁后ret的空间被回收,被回收的空间被起了一个别名叫x,好巧不巧的是当fun函数执行的时候xxx分配到的空间就是原来ret的空间,此时这个空间还有一个别名叫x,所以我们打印x就是xxx的值本质上x与xxx就是同一块空间。
这里还有一点要注意就是,上面
SLAt的引用返回能够使用是因为sl1中的数组是在堆上开辟的空间,函数栈帧的销毁不影响它的销毁;只有被手动释放才会销毁所以引用返回是没有问题的!
3.1 const引用
提到const在C语言阶段就会想到被限制的问题。例如:被const修饰过的指针其指向的内容或其本身就会受到限制,那么在C++中我们就习惯称之为权限问题:
int main()
{
//引用
int x = 10;
int& a = x;
int y = 20;
//权限可以缩小
const int& a1 = x;//a1虽然是x的别名 但是加上const修饰后 a1就不能改了
a1 = y;
//权限相同
const int z = 10;
const int& c = z;
c = x; //同样c虽然是z的别名 但是c被const修饰定死了 不能被修改 这主要是在后面函数传参的时候用到
//权限不能被放大
const int r = 10;
int& b = r;//这是对权限的放大 这样做是不行的 因为r本身已经被限制 再给r取别名的时侯也因该对别名进行修饰
const int y=10;
int z=y;
//权限有没有放大?
//没有 就是普通的赋值
}
通过上面代码要注意:可以引⽤⼀个const对象,但是必须⽤const引用(相同权限下)。const引用也可以引用普通对象,因为对象的访问权限在引用过程中可以缩小,但是不能放大。
void func(const int& x)
{
//这里形参要用const修饰 因为实参已经被const修饰了 不能存在权限的放大
}
int main()
{
int x = 1;
const int y = 2;
double d = 1.1;
const int& r1 = x;
const int& r2 = y;
const int& r3 = 10;
const int& r4 = x * 10;//编译器会将x*10给存在一个临时变量中 再将这个临时变量赋给r4 所以r4的改变不会影响x
//int& r5=d; 这样是不行的,因为d会将临时变量给r5 临时变量具有常性 如果要引用临时变量要怎么办? 加上const修饰限制权限
const int& r5 = d;//这里要注意 d给r5是一个普通的赋值
func(x);
func(y);
func(10);
func(x*10);//这里的实参是 x*10后的值
func(d);
return 0;
}
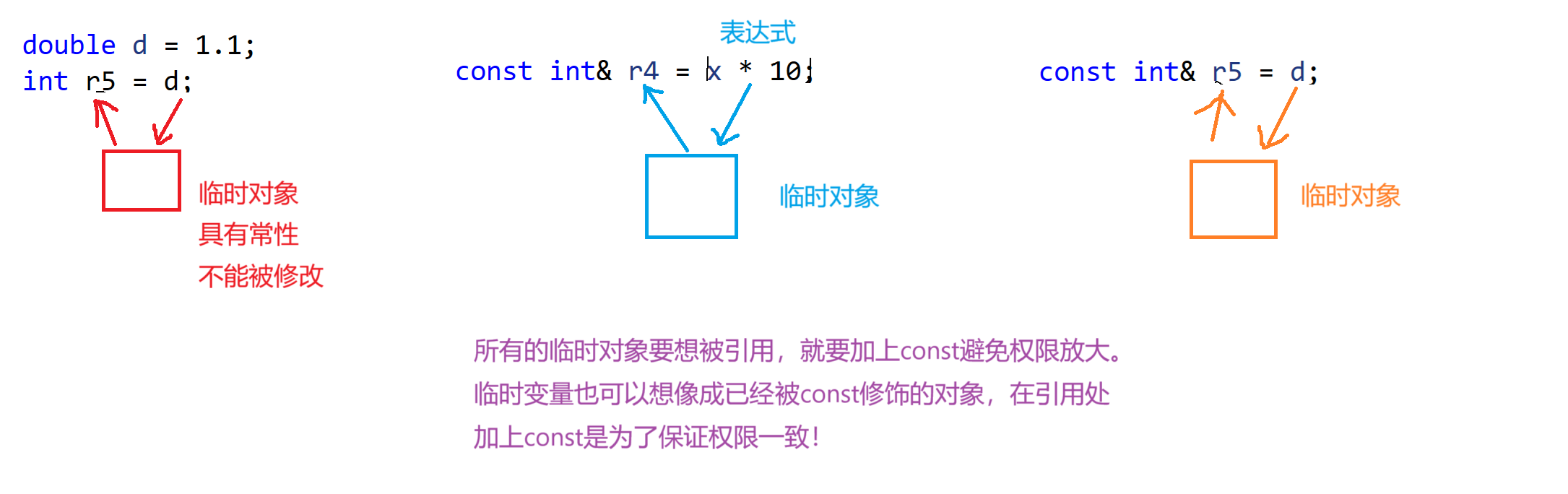
为什么要加const控制权限呢?比如上面的函数传参,如果不用const修饰那么临时变量都是传不过去的,因为临时变量具有常性不能被修改如果不加const修饰就引用就是权限放大了,所以这些都是为了以后传参更加方便。 注意:权限问题只有在指针和引用的时候才会出现!!!
4.1指针和引用的关系
首先要明确一点:C++中出现的引用就是为了优化指针在C语言上的不足;换句话说引用就是优化指针的复杂度,但却不能替代彼此。比如在链式结构和属性结构中只有指针才能改变指向引用不能所以必须使用指针。
那么引用与指针的关系到底是什么呢?
在将引用返回的坑那里的时候,代码编译有两个警告:
这里就有人疑问了?明明是引用返回怎么警告说是返回局部变量的地址?

我们打开反汇编代码:
我们看到指针与引用在汇编代码层面是极其的相似,所以不难推出引用它就是使用指针来实现的,就像上面的两个警告一样引用返回的是局部变量的地址,按照上面的分析也说得过去。

以上就是本章的全部内容啦!
最后感谢能够看到这里的读者,如果我的文章能够帮到你那我甚是荣幸,文章有任何问题都欢迎指出!制作不易还望给一个免费的三连,你们的支持就是我最大的动力!
