RAGFlow——知识库检索系统开发实战指南
目录
项目背景与架构设计
在开发xxxx思想文化数智平台的过程中,我们需要构建一个智能对话系统来提升用户体验。经过深入调研和技术选型,最终采用了基于Vue 3 + TypeScript的前端架构,结合流式AI响应技术,做了一个这个网站,里面包含深度思考、联网搜索、本地知识库检索、搜索本地知识库文档等功能。
效果演示
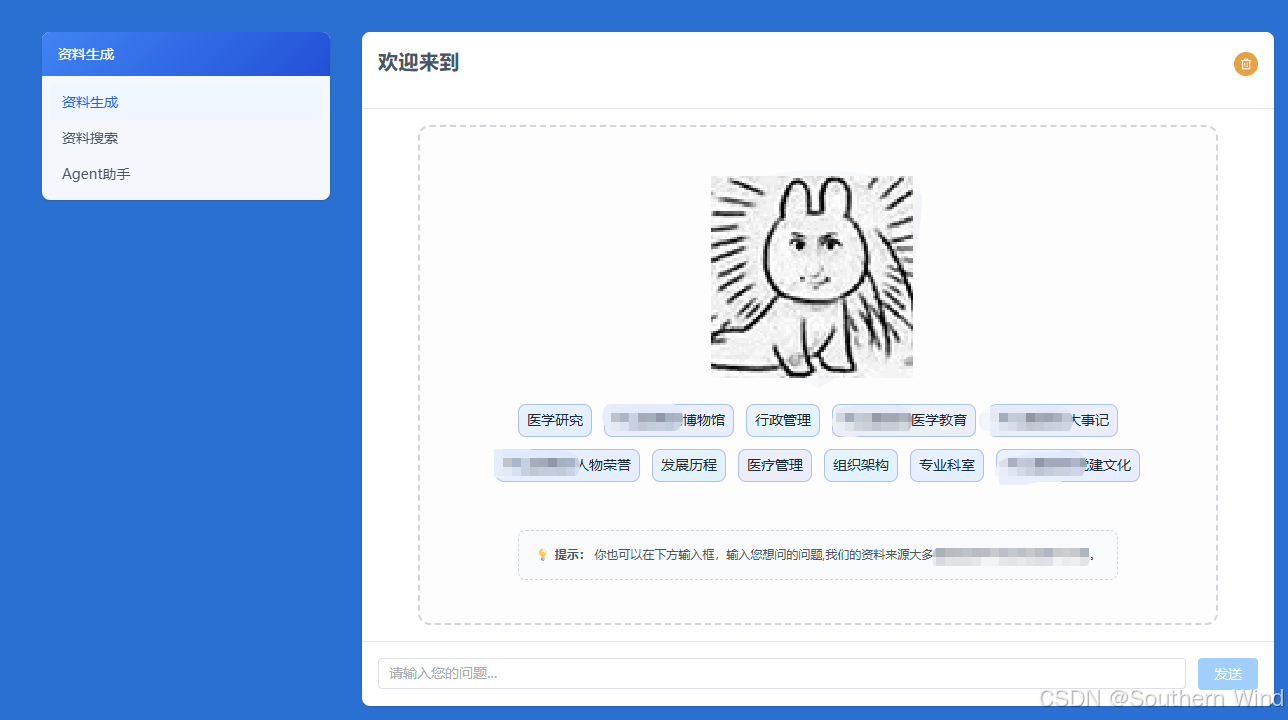
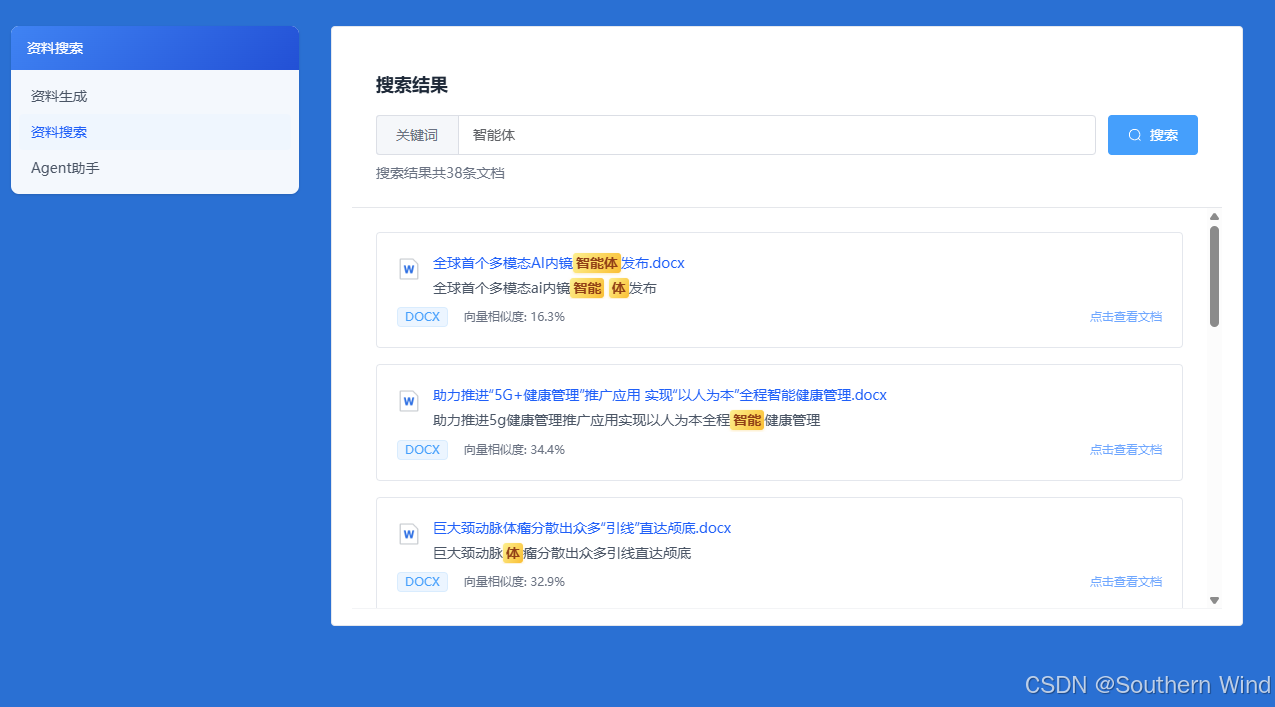
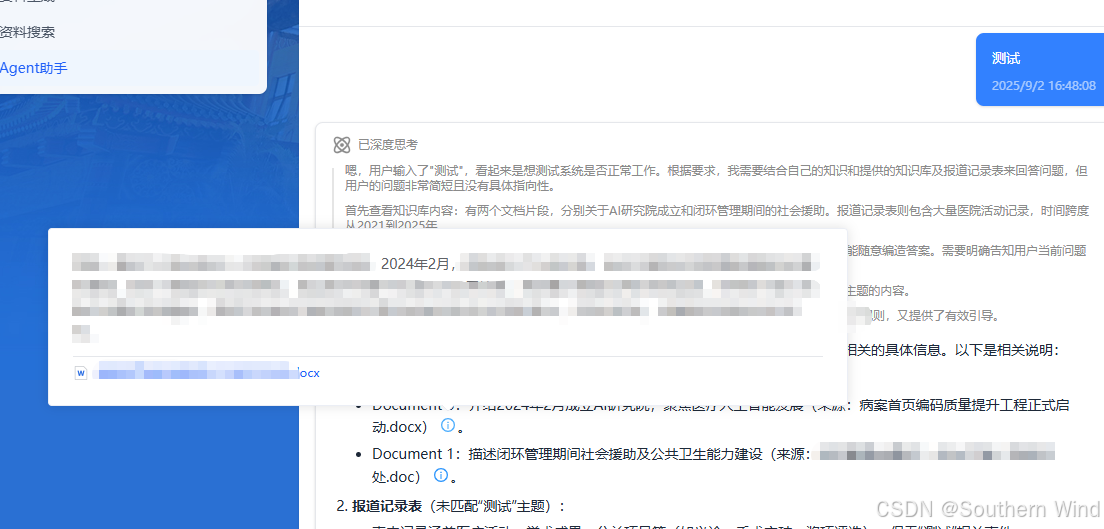
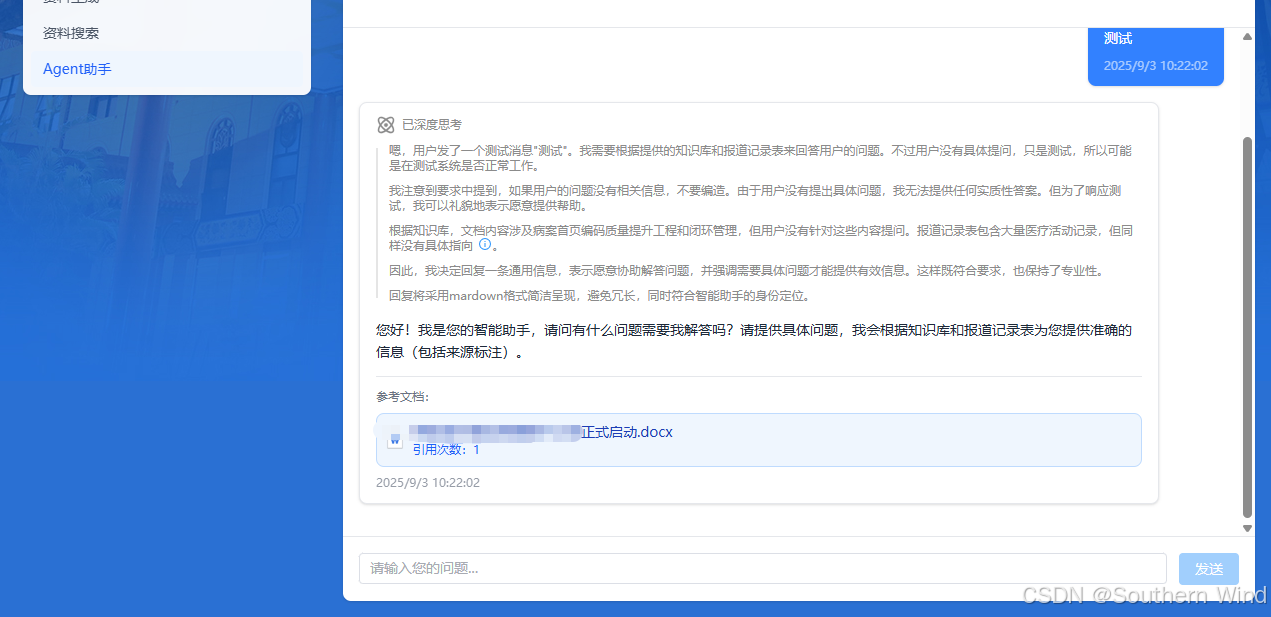
整体架构思路
系统采用模块化设计,将复杂的对话功能拆分为独立的组件和逻辑模块:
src/
├── views/AgentChat.vue # 主页面容器
├── components/
│ ├── AgentChatPanel.vue # 聊天面板核心组件
│ ├── AgentMessageContent.vue # 消息内容渲染器
│ └── common/BaseChatPanel.vue # 通用聊天面板基类
├── hooks/
│ └── useAgentChat.ts # 聊天逻辑封装
└── stores/
└── documentPreview.ts # 文档预览状态管理
路由与页面配置
// router/index.ts
{
path: '/agent-chat',
name: 'agent-chat',
component: () => import('@/views/AgentChat.vue'),
meta: {
title: 'Agent助手',
requiresAuth: true,
keepAlive: true
}
}
值得注意的是,我们启用了keepAlive来保持聊天状态,避免用户切换页面后丢失对话历史。
核心功能实现
智能对话系统的数据结构
在设计消息数据结构时,我们考虑了多种场景的需求:
interface AgentMessage {
id: string
type: 'user' | 'ai' | 'assistant'
content: string
timestamp: string
isLoading?: boolean
error?: string
// 引用系统相关
reference?: {
chunks: Array<{
id: string
content: string
document_id: string
document_name: string
image_id?: string
positions?: number[][]
similarity?: number
vector_similarity?: number
term_similarity?: number
}>
}
// 文档聚合信息
documents?: Array<{
document_id: string
document_name: string
score: number
}>
}
这个数据结构经过多次迭代优化,既支持基础的对话功能,又能处理复杂的引用和文档关联场景。
流式响应处理机制
流式响应是提升用户体验的关键技术。我们的实现方案如下:
const sendMessage = async (content: string) => {
const abortController = new AbortController()
try {
const response = await fetch(`${API_BASE_URL}/api/v1/agents/${AGENT_ID}/chat`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${API_KEY}`
},
body: JSON.stringify({
question: content,
stream: true,
session_id: sessionId.value
}),
signal: abortController.signal
})
const reader = response.body?.getReader()
const decoder = new TextDecoder()
let buffer = ''
while (true) {
const { done, value } = await reader.read()
if (done) break
buffer += decoder.decode(value, { stream: true })
const lines = buffer.split('\n')
buffer = lines.pop() || ''
for (const line of lines) {
if (line.startsWith('data:')) {
const jsonStr = line.slice(5).trim()
if (jsonStr) {
const data = JSON.parse(jsonStr)
updateMessageContent(data)
}
}
}
}
} catch (error) {
handleStreamError(error)
}
}
这种实现方式的优点是能够实时显示AI的回复过程,让用户感受到系统的响应性。
技术实现细节
思考过程可视化系统
在实际开发中,我发现用户希望了解AI的思考过程,因此做了一个类似DeepSeek的思考过程展示功能:
// 思考过程内容提取
const thinkContent = computed(() => {
if (!props.message.content) return ''
const thinkMatch = props.message.content.match(/<think>([\s\S]*?)<\/think>/gi)
if (!thinkMatch) return ''
let thinkText = thinkMatch[0].replace(/<\/?think>/gi, '').trim()
// 处理思考过程中的引用标记
if (props.message.reference?.chunks) {
thinkText = thinkText.replace(/##(\d+)\$\$/g, (_, idNumber) => {
const chunkIndex = parseInt(idNumber)
const chunks = props.message.reference?.chunks || []
if (chunkIndex >= 0 && chunkIndex < chunks.length) {
return `<span class="referenceIcon" data-ref-id="${idNumber}">...</span>`
}
return ''
})
}
// 将内容分段处理
const paragraphs = thinkText.split(/\n\s*\n/).filter(p => p.trim())
return paragraphs.map(p => `<p>${p.trim()}</p>`).join('')
})
这个实现的关键在于将思考过程与正文内容分离,让用户可以选择性地查看AI的推理过程。
引用系统的复杂性处理
引用系统是整个项目中最复杂的部分之一。需要处理多种引用格式,并确保在不同场景下都能正常工作:
const createMultipleVirtualRefs = () => {
nextTick(() => {
virtualRefs.value = {}
// 处理正文内容区域的引用图标
if (contentRef.value) {
const referenceIcons = contentRef.value.querySelectorAll('.referenceIcon')
referenceIcons.forEach((icon, index) => {
const refId = icon.getAttribute('data-ref-id')
if (refId) {
const uniqueKey = `content-${refId}-${index}`
virtualRefs.value[uniqueKey] = icon as HTMLElement
}
})
}
// 处理思考过程区域的引用图标
const thinkContainer = document.querySelector('.deepseek-think-container')
if (thinkContainer) {
const thinkReferenceIcons = thinkContainer.querySelectorAll('.referenceIcon')
thinkReferenceIcons.forEach((icon, index) => {
const refId = icon.getAttribute('data-ref-id')
if (refId) {
const uniqueKey = `think-${refId}-${index}`
virtualRefs.value[uniqueKey] = icon as HTMLElement
}
})
}
})
}
这种分区域处理的方式确保了思考过程和正文内容中的引用都能正常工作。
消息内容的Markdown渲染
我们使用markdown-it来处理消息内容的渲染,但需要特别处理引用标记:
const mainContent = computed(() => {
if (!props.message.content) return ''
// 移除思考过程,只保留正文内容
let content = props.message.content.replace(/<think>[\s\S]*?<\/think>/gi, '').trim()
// 处理引用标记
const referencePlaceholders = new Map<string, string>()
if (props.message.reference?.chunks) {
// 处理 ##x$$ 格式
content = content.replace(/##(\d+)\$\$/g, (_, idNumber) => {
const placeholder = `<!--REF_PLACEHOLDER_HASH_${idNumber}-->`
const iconHtml = generateReferenceIcon(idNumber)
referencePlaceholders.set(placeholder, iconHtml)
return placeholder
})
}
// Markdown渲染
let htmlContent = md.render(content)
// 恢复引用图标
referencePlaceholders.forEach((iconHtml, placeholder) => {
htmlContent = htmlContent.replace(new RegExp(placeholder, 'g'), iconHtml)
})
return htmlContent
})
性能优化与最佳实践
虚拟滚动与内存管理
对于长对话场景,我们实现了消息的懒加载和虚拟滚动:
const visibleMessages = computed(() => {
if (messages.value.length <= 50) {
return messages.value
}
// 只显示最近的50条消息
return messages.value.slice(-50)
})
// 清理旧消息的引用
const cleanupOldReferences = () => {
if (messages.value.length > 100) {
messages.value = messages.value.slice(-80)
// 重新创建虚拟引用
createMultipleVirtualRefs()
}
}
流式响应的错误处理
在实际使用中,网络问题和API错误是不可避免的,我们实现了完善的错误处理机制:
const handleStreamError = (error: Error) => {
if (error.name === 'AbortError') {
// 用户主动取消
updateMessageStatus('cancelled')
} else if (error.message.includes('timeout')) {
// 超时处理
updateMessageStatus('timeout')
showRetryOption()
} else {
// 其他错误
updateMessageStatus('error', error.message)
}
}
移动端性能优化
移动端的性能优化主要集中在减少DOM操作和优化触摸交互:
const isMobile = useResponsive()
// 移动端使用不同的弹窗策略
const popoverTrigger = computed(() => {
return isMobile.value ? 'click' : 'hover'
})
// 移动端减少动画效果
const enableAnimations = computed(() => {
return !isMobile.value || window.innerWidth > 768
})
常见问题与解决方案
引用图标不显示
这是最常见的问题之一,通常有以下几种原因:
- 引用数据格式不正确:确保API返回的reference数据结构正确
- 虚拟引用未创建:检查createMultipleVirtualRefs是否被正确调用
- CSS样式冲突:确保引用图标的样式没有被其他样式覆盖
解决方案:
// 调试用的引用检查函数
const debugReferences = () => {
console.log('Reference data:', props.message.reference)
console.log('Virtual refs:', virtualRefs.value)
console.log('Reference icons in DOM:',
document.querySelectorAll('.referenceIcon').length)
}
流式响应中断
流式响应中断通常是由于网络问题或API限制导致的:
// 实现重试机制
const retryMessage = async (messageId: string) => {
const message = messages.value.find(m => m.id === messageId)
if (message && message.type === 'ai') {
message.content = ''
message.isLoading = true
message.error = undefined
try {
await sendMessage(lastUserMessage.value)
} catch (error) {
message.error = '重试失败,请稍后再试'
message.isLoading = false
}
}
}
内存泄漏问题
长时间使用可能导致内存泄漏,主要原因是事件监听器和定时器没有正确清理:
onUnmounted(() => {
// 清理定时器
if (welcomeInterval) clearInterval(welcomeInterval)
if (titleInterval) clearInterval(titleInterval)
// 清理事件监听器
document.removeEventListener('click', handleDocumentClick)
// 清理虚拟引用
virtualRefs.value = {}
// 中断正在进行的请求
if (abortController.value) {
abortController.value.abort()
}
})
部署与维护
环境配置
项目支持多环境配置,通过环境变量来管理不同环境的API地址:
// config/env.ts
export const envConfig = {
agentBaseUrl: import.meta.env.VITE_AGENT_BASE_URL || 'http://localhost:3000',
agentApiKey: import.meta.env.VITE_AGENT_API_KEY || '',
defaultAgentId: import.meta.env.VITE_DEFAULT_AGENT_ID || 'default'
}
监控与日志
为了便于问题排查,我们实现了详细的日志记录:
const logChatEvent = (event: string, data?: any) => {
console.log(`[Agent Chat] ${event}`, {
timestamp: new Date().toISOString(),
sessionId: sessionId.value,
messageCount: messages.value.length,
data
})
}
性能监控
const performanceMonitor = {
startTime: 0,
startTimer() {
this.startTime = performance.now()
},
endTimer(operation: string) {
const duration = performance.now() - this.startTime
if (duration > 1000) {
console.warn(`[Performance] ${operation} took ${duration}ms`)
}
}
}
这个Agent Chat系统经过多次迭代和优化,已经在生产环境中稳定运行。通过合理的架构设计和细致的性能优化,打造了一个用户体验良好、功能完善的智能对话系统。