在电商行业激烈竞争的背景下,精准挖掘市场增长点是企业保持竞争力的关键。本文基于拜耳官方旗舰店驱虫剂市场分析项目,先对原文核心内容进行梳理与解读,再续写关键的竞争分析模块,形成完整的市场增长点挖掘闭环,为企业决策提供数据支撑。
1. 业务背景:奠定分析逻辑基础
业务背景模块明确了市场分析的核心理论与方法论,是后续数据分析的 “指南针”,关键要点如下:

1.1 分析流程概述
某电商产品数据分析流程
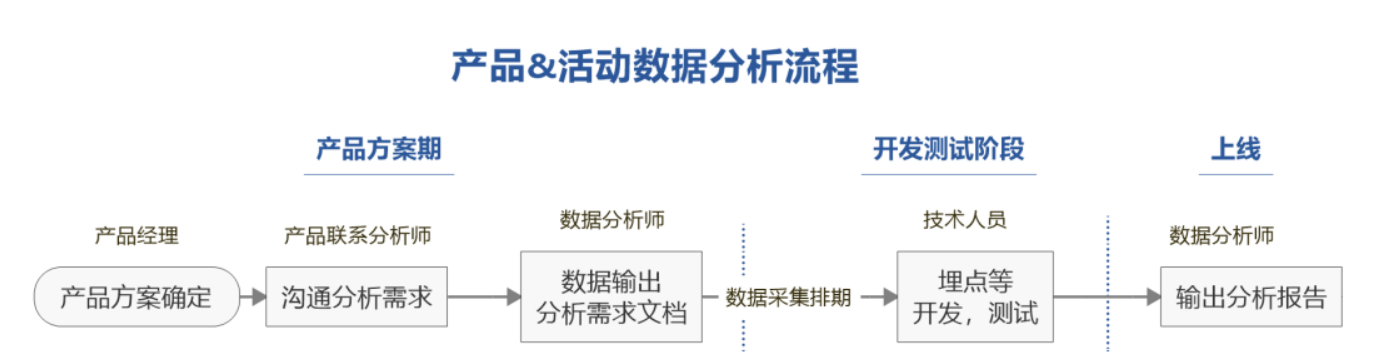
- 每个环节都有具体的要求,例如需求文档要求包含:目的,分析思路,预期效果
- 业务部门出问题和需求,以及对算法&数据部门输出报告的理解和应用
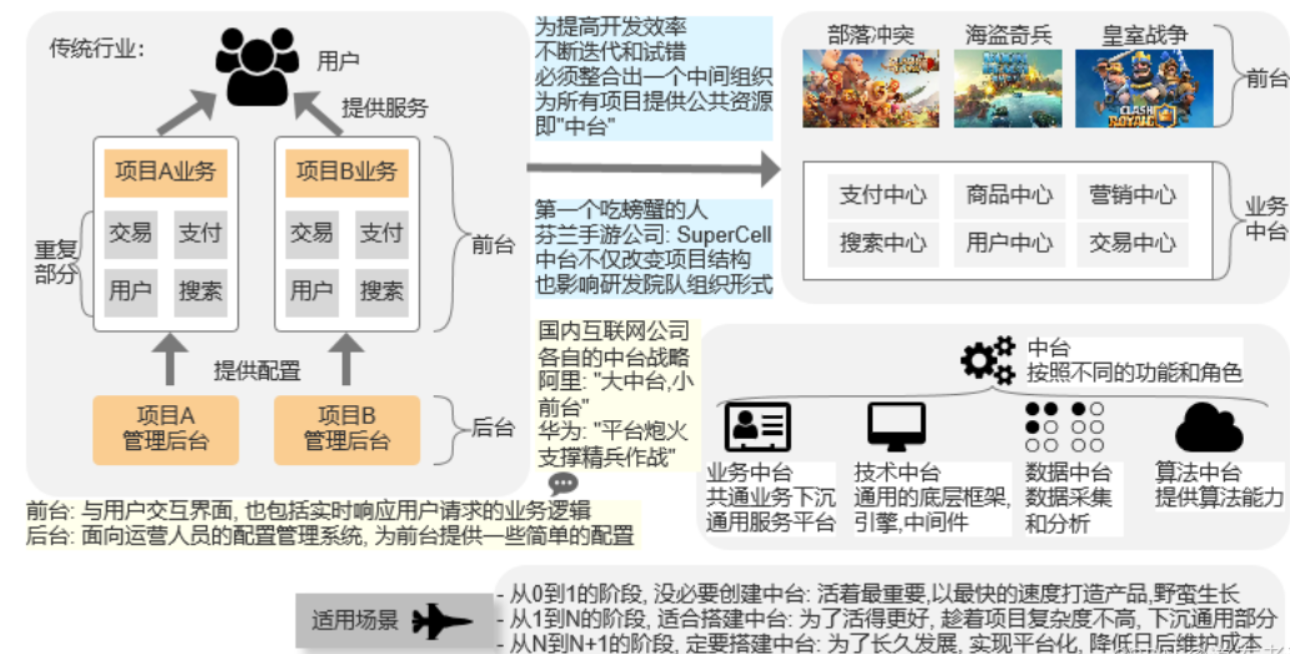
1.2 中台
1.3 市场类别
评判市场和品牌的发展趋势和增长情况,从宏观到微观,从大市场到细分市场。互联网产品由关注用户增量到用户存量,判断产品或市场是用户增量还是存量,判断有新的需求出现即可:
增量市场:从无到有,以前关注哪些需求没有被满足,快速迭代抢占市场,考虑最多的
不是用户体验.流量=新增客户.例如:智能手机潮开始时的市场.小米面对的是增量
市场
存量市场:从有到优,现在关注如何更好的满足需求,考虑更多的是用户体验.产品价
值=新体验-旧体验-替换成本,新体验没有突破性大幅增加,产品价值很难实现.流量
=用户时间(停留时间越久,利益价值越大).例如:现在人手一台智能手机,小米面对
存量市场,如何让需要换手机的用户换成小米,从有到优
创新:想要用产品价值撬动一个用户,同纬度竞争别家的先发优势门槛太高,如果别家
体量很大,基本可以放弃;创新可能就是剩下的活路,而面对互联网的高速发展,线下需
求基本都被互联网化,切入点可能就转移到细分市场.例如:微信QQ是社交领域的霸
主,陌陌探探在陌生人社交上也分了一杯羹,这些已存在的需求,没有被充分实现,也算
增量市场
1.4 产品结构-波士顿矩阵(BCG Matrix)
- BCG: Boston Consulting Group
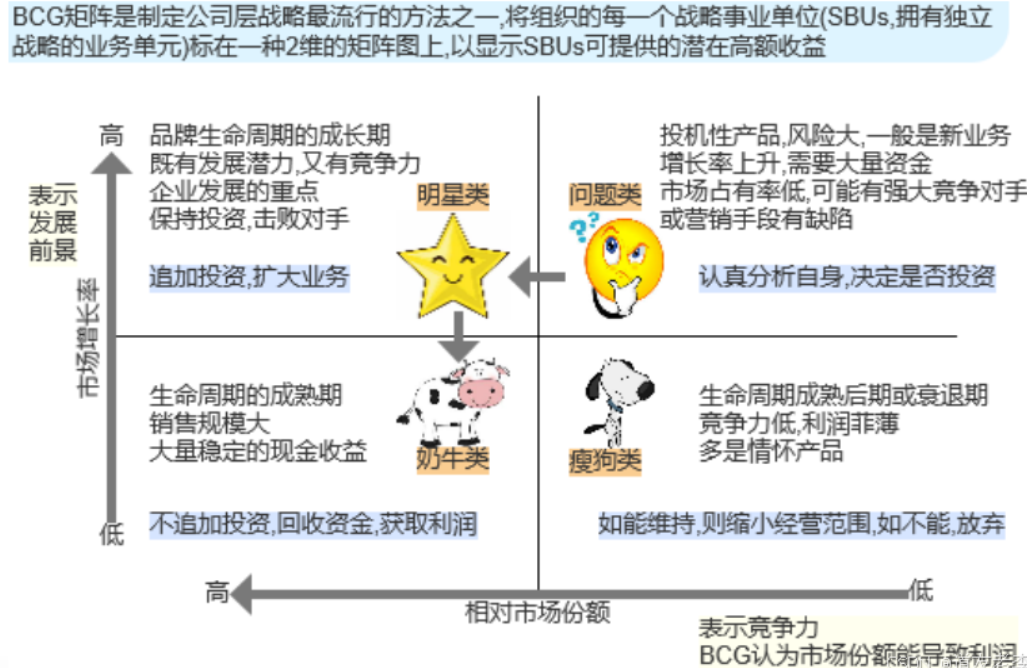
1.5 产品生命周期
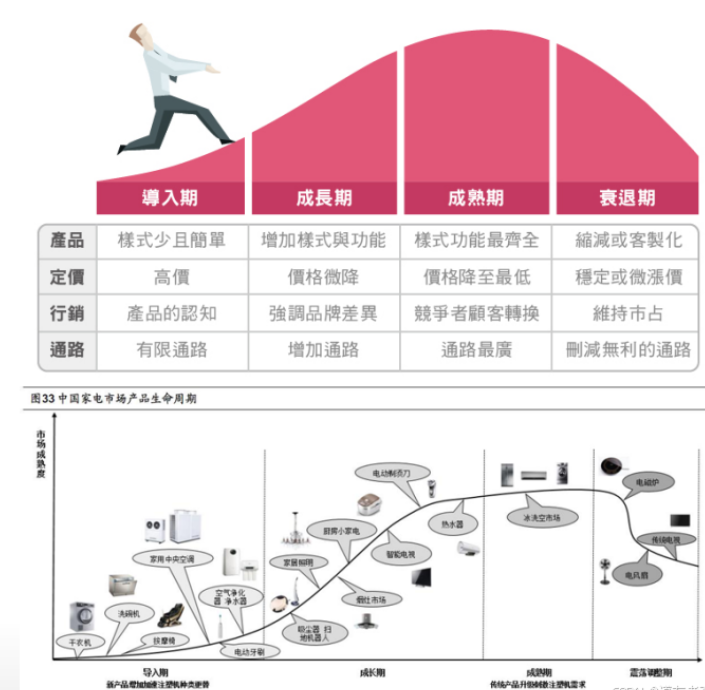
1.6 处理项目需求的基本思路
了解项目公司的背景和对接人员情况
公司的产品结构,市场环境,对接人的角色和权利等级等
沟通明确实际的项目需求
团队内部理解项目需求
和业务方沟通需求:从业务的角度理解需求可能的解决方案
优化项目需求
和业务核对项目需求
根据项目需求梳理分析思路:每一步分析的目标,需要的数据支持,反复优化
确定分析工具和人员配置,进行数据分析
撰写分析结论和方案
1.7 项目需求例子
问题:销售额下降,怎么办?(问题太大,方法也多:优化老客户,扩大流量,提升转化率)
1.了解涉及项目相关的所有的业务部门的需求,逻辑,问题点
2.拆分:销售额=流量转化率客单价
3.待沟通部门:营销部门(活动),推广部门(流量),客服,售后,供应链
4.沟通之前出想法,沟通之后优化,确认项目需求
5.数据收集:确认每一步需求的数据(可能用到爬虫)
2、项目背景&产品架构
客户介绍: 拜耳官方旗舰店(拜耳公司,总部位于德国的勒沃库森,在六大洲的200个地点建有750家生产厂;拥有120,000名员工及350家分支机构,几乎遍布世界各国.高分子,医药保健,化工以及农业是公司的四大支柱产业.公司的产品种类超过10000种)
客户需求: 拜耳官方旗舰店寻求市场增长点
产品架构:
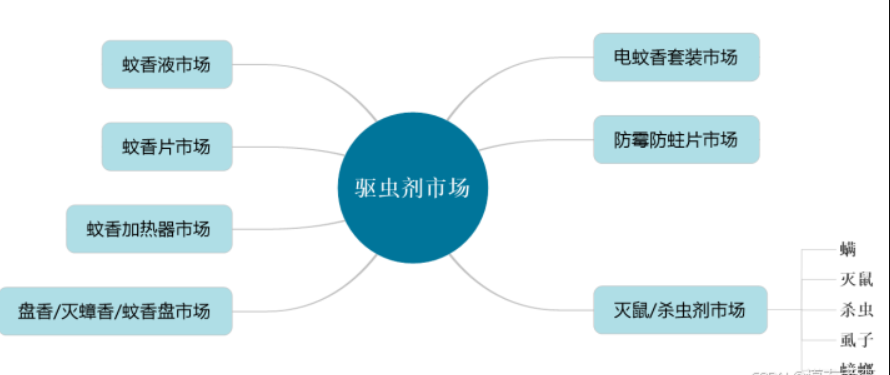
3、数据说明
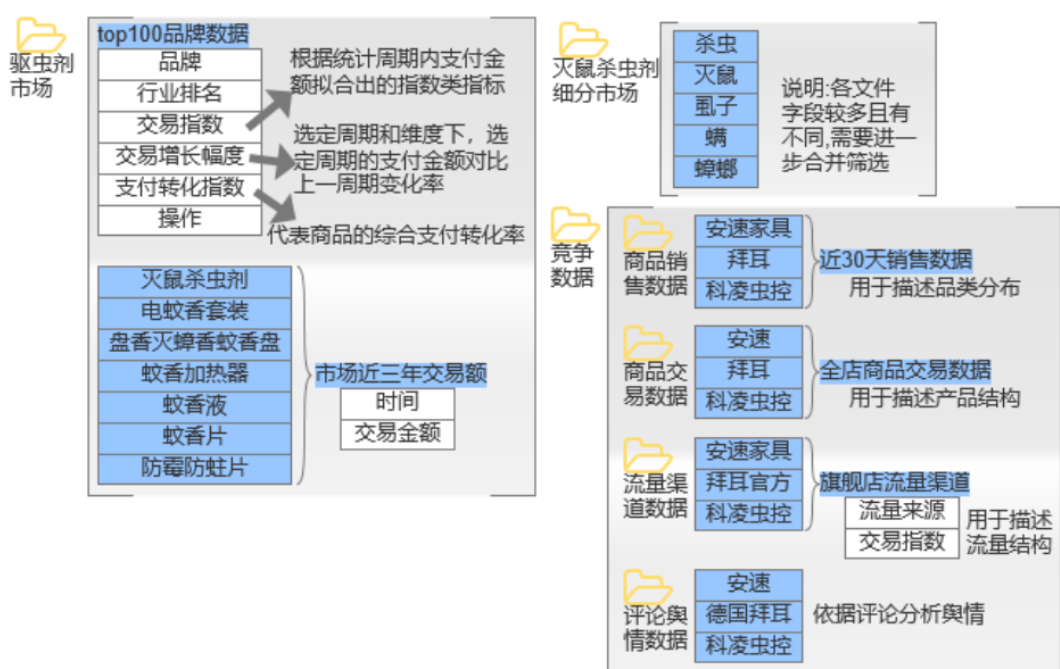
4、分析挖掘
4.1 数据查看、加载
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
# 更改当前路径
# os.chdir(r'./data/驱虫剂市场')
# 按照windows路径写法
os.chdir('.\\data\\驱虫剂市场')
pd.read_excel('电蚊香套装市场近三年交易额.xlsx')
pd.read_excel('防霉防蛀片市场近三年交易额.xlsx')
pd.read_excel('灭鼠杀虫剂市场近三年交易额.xlsx')
# 把时间格式统一一下
temp = pd.read_excel('防霉防蛀片市场近三年交易额.xlsx')
pd.to_datetime(temp['时间'], unit='D', origin='1899-12-30')
0 2018-10-01
1 2018-09-01
2 2018-08-01
3 2018-07-01
4 2018-06-01
5 2018-05-01
6 2018-04-01
7 2018-03-01
8 2018-02-01
9 2018-01-01
10 2017-12-01
11 2017-11-01
12 2017-10-01
完整代码:
import glob
# 允许在glob中写linux的模式匹配 ls *.txt
filenames = glob.glob('*市场近三年交易额.xlsx')
# 取出具体市场的名字.
# 从filename中就可以取
import re
def read_data(filename):
temp = pd.read_excel(filename)
# 列名
colname = re.search(r'(.*?)市场.*', filename).group(1)
if temp.时间.dtype == 'int64':
# 修改时间类型
temp['时间'] = pd.to_datetime(temp['时间'], unit='D', origin='1899-12-30')
# 改名
temp.rename(columns={'交易金额': colname}, inplace=True)
# 把时间改成index
temp.set_index(keys='时间', inplace=True)
return temp
dfs = [read_data(filename) for filename in filenames]
df = pd.concat(dfs, axis=1).reset_index()
4.2 补充数据
观察得知, 15年只有2个月数据, 16, 17年是完整数据, 18年少了11, 12的数据.
对于缺失数据, 有两种处理办法, 如果缺的太多, 直接弃用, 如果缺的不多, 想办法补足.
所以15年的11, 12月数据, 要弃用, 18年的数据需要想办法补上.
现在的问题: 如何比较合理补足18年11月12月的数据.
# 取11月的数据
# datetime 可以通过.dt把pandas中datetime类型变成python中datetime数据类型.
month_data = df.loc[df.时间.dt.month == 11]
# 设置seaborn画图风格
sns.set()
# 设置显示中文
plt.rcParams['font.sans-serif'] = 'SimHei'
# 画图观察趋势. 4行2列
plt.figure(figsize=(2 * 6, 4 * 5))
for i, col in enumerate(month_data.columns[1:]):
axes = plt.subplot(4, 2, i + 1)
axes.plot([2015, 2016, 2017], month_data[col][::-1], marker='o')
_ = axes.set_xticks([2015, 2016, 2017])
_ = axes.set_xticklabels([2015, 2016, 2017])
axes.set_title(col)
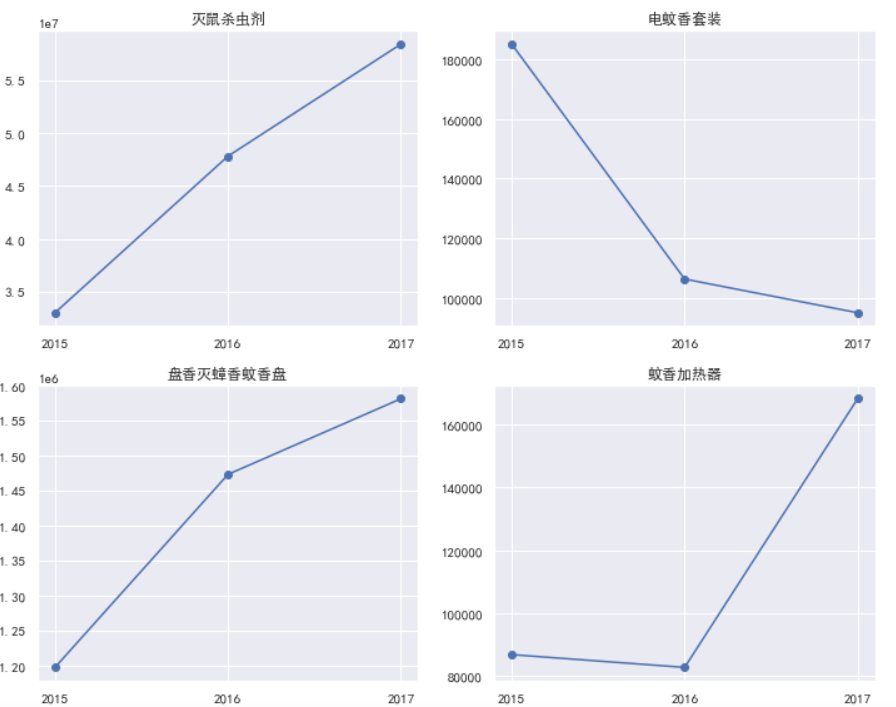
- 通过画图, 经过观察, 得知, 15, 16, 17这年份的数据都近似符合线性的趋势
- 那么我们就可以通过线性回归来预测18年的数据, 用预测数据作为我们填充的数据.
import datetime
from sklearn.linear_model import LinearRegression
from pandas import DataFrame, Series
for i in [11, 12]:
month_data = df.loc[df.时间.dt.month == i]
# 用年作为训练数据
X_train = month_data.时间.dt.year.values.reshape(-1, 1)
# 循环取每一列数据
data_2018 = [datetime.datetime(year=2018, month=i, day=1)]
for j in range(1, len(month_data.columns)):
y_train = month_data.iloc[:, j]
# 训练
linear = LinearRegression()
linear.fit(X_train, y_train)
# 预测
X_test = np.array([2018]).reshape(-1, 1)
y_ = linear.predict(X_test)[0]
data_2018.append(y_)
# 把数据添加到原始数据中.
# 用data_2018生成一个dataframe, 然后再把原始数据追加到data_2018后面
# dataframe是要求data必须是二维的.
newrow = DataFrame(data=np.array(data_2018).reshape(1, -1), columns=month_data.columns)
df = newrow.append(df)
# 删除15年的数据
df = df.loc[df.时间.dt.year != 2015].copy()
# 重置索引
df.reset_index(inplace=True)
# 设置时间为行索引
df.set_index('时间', inplace=True)
df.drop(columns='index', inplace=True)
# 计算总金额
df['总金额'] = df.sum(axis=1)
# 重新把时间变为列
df.reset_index(inplace=True)
# 因为要按年分析, 所以插入一个年份
# 使用insert在指定的位置插入新的一列
df.insert(1, 'year', df['时间'].dt.year)
# 按照年份分组聚合
total_sum = df.groupby(by='year').sum()
total_sum.plot(marker='o', figsize=(6, 6))
plt.xticks([2016, 2017, 2018])
plt.title('近三年交易总额的变化趋势')
plt.ylabel('近三年交易总额')
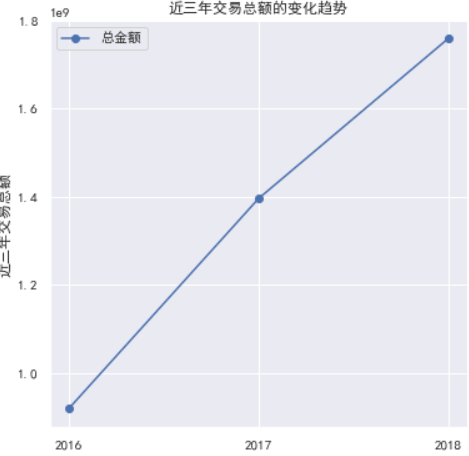
结论: 通过观察的值, 整体市场近三年都是增长, 整体市场趋势不错. 处在成长期或成熟期
4.3 各类目市场销售额总和变化趋势
# 查看各类目市场近三年内销售额总和的变化趋势
cat_sum = df.groupby(by='year')[['灭鼠杀虫剂', '电蚊香套装', '盘香灭蟑香蚊香盘', '蚊香加热器', '蚊香液', '蚊香片',
'防霉防蛀片']].sum()
cat_sum.plot(figsize=(10, 8), marker='o')
plt.title('近三年各类目交易总额的变化趋势')
plt.ylabel('近三年各类目交易总额')
_ = plt.xticks([2016, 2017, 2018])
_ = plt.text(2016 - 0.1, 0.57 * 1e9, cat_sum['灭鼠杀虫剂'].values[0])
_ = plt.text(2017 - 0.1, 0.8 * 1e9, cat_sum['灭鼠杀虫剂'].values[1])
_ = plt.text(2018 - 0.1, 1.1 * 1e9, cat_sum['灭鼠杀虫剂'].values[2])
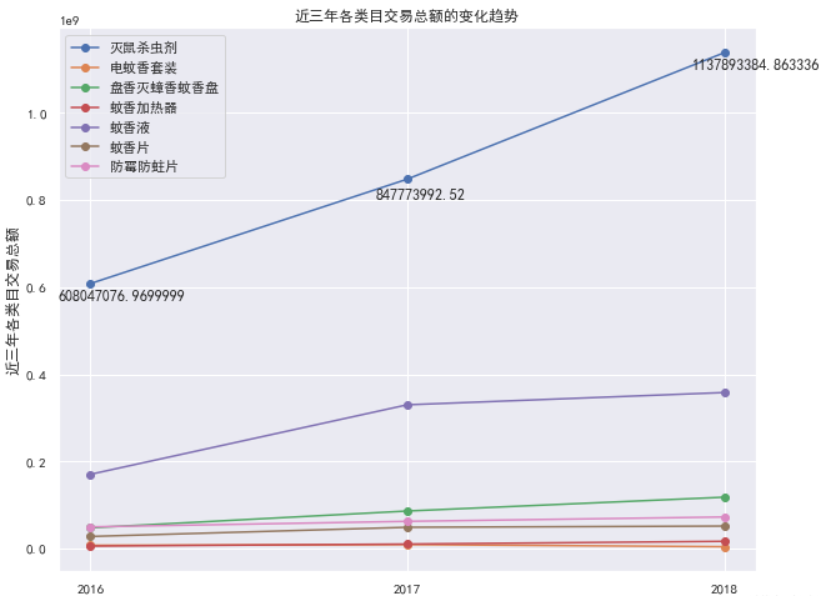
结论: 灭鼠杀虫剂和蚊香液比较有市场
4.4 驱虫市场潜力分析
# 转化成数字类型
for col in df.columns[2:-1]:
df[col] = df[col].astype('float64')
# 各市场的占比
cat_sum = df.groupby(by='year').sum().copy()
cat_ratio = df.groupby(by='year').sum().iloc[:, :-1].copy()
# 使用pandas指定的运算函数,可以修改默认的运算轴,默认是按列来算的, 我们要按行来算.
ratio_result = cat_ratio.div(cat_sum['总金额'], axis='index')
ratio_result.plot(kind='bar', figsize=(10, 6), stacked=True)
plt.title('近三年各类目销售额占比')
plt.xlabel('年份')
plt.ylabel('销售额占比')
for i in range(3):
plt.text(i, ratio_result['灭鼠杀虫剂'].values[i] / 2 + 0.1, str(round(ratio_result['灭鼠杀虫剂'].values[i] * 100, 2)) + '%')
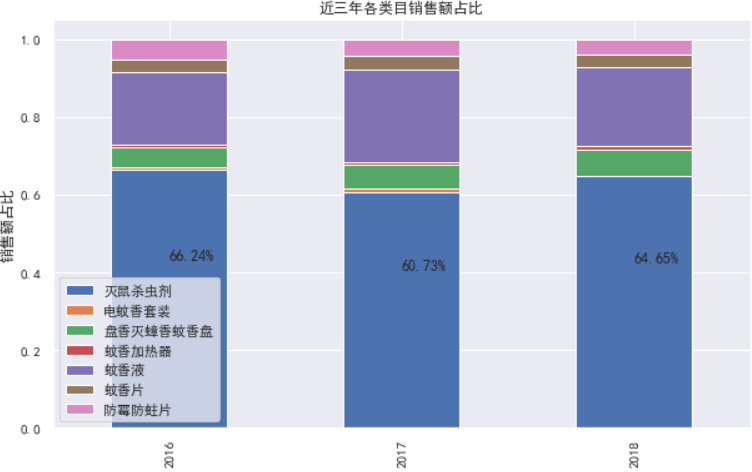
4.5 各个市场年增幅
# 按行操作
# 这里是dataframe和dataframe进行运算, 相同索引(行索引和列索引都相同)才会进行运算.
cat_incr = cat_sum.diff().iloc[1:].reset_index(drop=True) / cat_sum.iloc[:2].reset_index(drop=True)
# 中文字体中, 负号不能正常显示.
plt.rcParams['axes.unicode_minus'] = False
# 画出每一个类目的增长幅度
cat_incr.plot(figsize=(10, 6))
plt.xticks([0, 1], ['16-17', '17-18'])
plt.title('近三年各类目市场销量年增幅')
plt.xlabel('年份')
plt.ylabel('增幅占比')
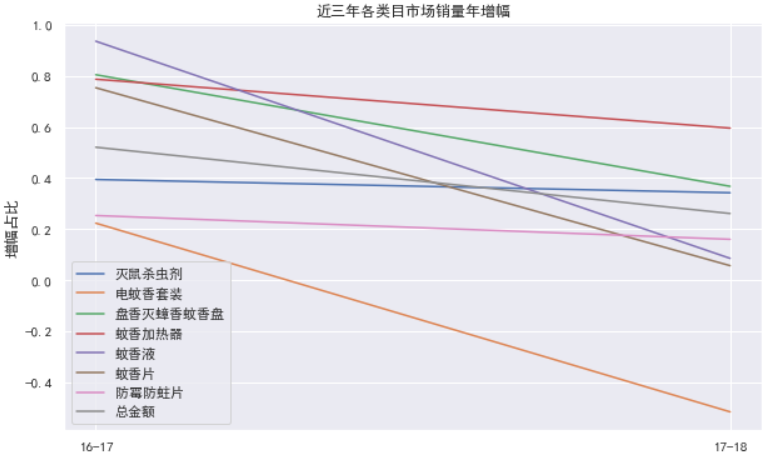
结论: 灭鼠杀虫剂的增长幅度比较稳定.
4.6 TOP100品牌数据
top100 = pd.read_excel('top100品牌数据.xlsx')
top100.plot(x='品牌', y='交易指数', kind='barh', figsize=(6, 18))
# 计算HHI
# 先算市场份额
top100_share = top100['交易指数'] / top100['交易指数'].sum()
HHI = sum(top100_share ** 2)
0.013546334007208914
驱虫剂市场不存在垄断, 是一个不集中的行业.
5、灭鼠杀虫剂市场机会点分析
# 换目录
os.chdir(r'../灭鼠杀虫剂细分市场')
filelist = glob.glob('*.xlsx')
# 把这五个表格读进来, 拼到一起.
dfs = [pd.read_excel(filename) for filename in filelist]
df = pd.concat(dfs, axis=0)
# 查看缺失值
df.isnull().any()
# 丢弃全部是null的列丢弃掉
df.dropna(axis=1, how='all').shape
df.isnull().mean()
df.dropna(axis=1, how='all', inplace=True)
# 删缺失值数据超过98%的.
cond = (df.isnull().mean() > 0.98)
df = df.loc[:, ~cond].copy()
df.isnull().mean()
# 经过观察发现, 药品登记号后面的特征, 缺失太多, 删除.
df.columns.get_loc('药品登记号')
# 去掉没用的特征
useless = ['时间','页码', '排名', '链接', '主图链接', '主图视频链接', '宝贝标题', '下架时间', '运费', '旺旺']
df.drop(columns=useless, inplace=True)
# 担心index有重复的, 重新整理一下索引
df.reset_index(drop=True, inplace=True)
df.drop(columns='类目', inplace=True)
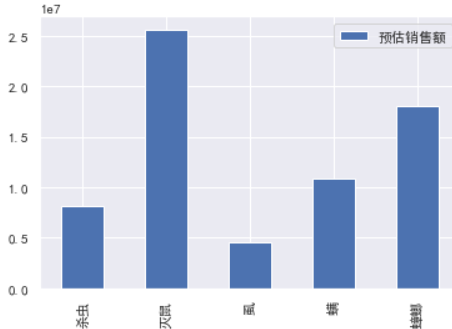
# 查看一下具体哪个类别预测销售额比较大
df.groupby(by='类别')[['预估销售额']].sum().plot(kind='bar')
画个饼图, 查看各个类别占总体预估销售额的比例
# 画个饼图, 查看各个类别占总体预估销售额的比例
temp = df.groupby(by='类别')[['预估销售额']].sum()
temp['预估销售额'].plot(kind='pie', autopct='%.2f%%', shadow=True, explode=[0.1, 0.2, 0.1, 0.1, 0.1])
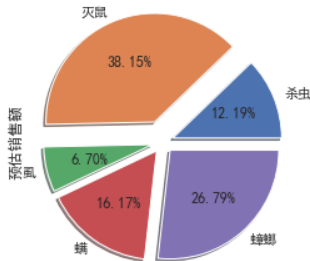
可以看出, 重点需要研究灭鼠和灭蟑螂两个细分市场. 以灭鼠为例.
# 提取灭鼠数据
mouse = df.loc[df['类别'] == '灭鼠'].copy()
bins = [0, 50, 100, 150, 200, 250, 300, 650]
labels = ['0_50', '50_100', '100_150', '150_200', '200_250', '250_300', '300以上']
mouse['价格区间'] = pd.cut(mouse.售价, bins=bins, labels=labels, include_lowest=True)
# 根据价格区间进行分组
predict_amount = mouse.groupby(by='价格区间')[['预估销售额']].sum()
# 计算预估销售额占比
predict_amount['预估销售额占比'] = predict_amount['预估销售额'] / predict_amount.sum().values
# 宝贝数是通过统计宝贝ID来计算的, 宝贝ID是有可能出现重复的.
mouse.宝贝ID.nunique()
# 说明确实存在重复宝贝.
mouse.drop_duplicates(subset=['宝贝ID'])
# 计算宝贝数
predict_amount['宝贝数'] = mouse.drop_duplicates(subset=['宝贝ID']).groupby(by=['价格区间'])['宝贝ID'].count()
predict_amount['宝贝数占比'] = predict_amount['宝贝数'] / predict_amount['宝贝数'].sum()
predict_amount['单宝贝平均销售额'] = predict_amount['预估销售额'] / predict_amount['宝贝数']
# 计算相对竞争度
predict_amount['相对竞争度'] = 1 - ((predict_amount['单宝贝平均销售额'] - predict_amount['单宝贝平均销售额'].min()) / (predict_amount['单宝贝平均销售额'].max() - predict_amount['单宝贝平均销售额'].min()))
# 按照相对竞争度的顺序来排序
predict_amount.sort_values(by='相对竞争度', inplace=True)
# 按照价格区间查看预估销售额占比和相对竞争度
predict_amount['预估销售额占比'].plot(kind='bar', figsize=(12, 5), color='wheat', label='预估销售额占比')
predict_amount['相对竞争度'].plot(marker='o', label='相对竞争度')
plt.legend()
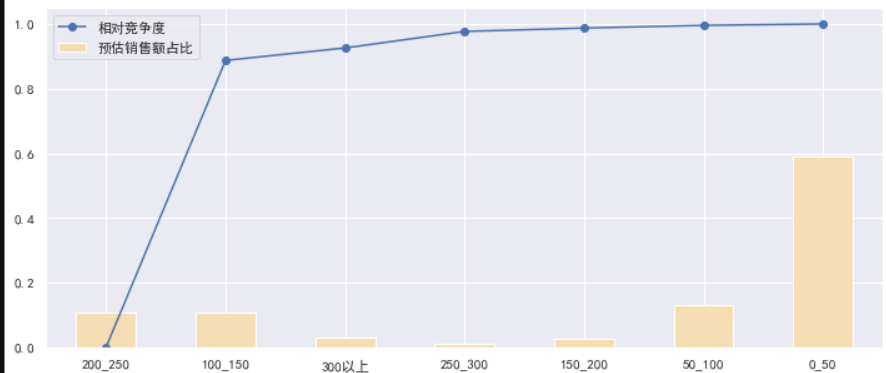
# 再研究0到50这个价格区间的细分市场
price50 = mouse.loc[mouse.价格区间 == '0_50'].copy()
bins = [0, 10, 20, 30, 40, 50]
labels = ['0-10', '10-20', '20-30', '30-40', '40-50']
price50['细分价格区间'] = pd.cut(price50['售价'], bins=bins, labels=labels)
def process_data(df, by):
predict_amount = df.groupby(by=by)[['预估销售额']].sum()
predict_amount['预估销售额占比'] = predict_amount['预估销售额'] / predict_amount.sum().values
# 计算宝贝数
predict_amount['宝贝数'] = df.drop_duplicates(subset=['宝贝ID']).groupby(by=by)['宝贝ID'].count()
predict_amount['宝贝数占比'] = predict_amount['宝贝数'] / predict_amount['宝贝数'].sum()
predict_amount['单宝贝平均销售额'] = predict_amount['预估销售额'] / predict_amount['宝贝数']
predict_amount['相对竞争度'] = 1 - ((predict_amount['单宝贝平均销售额'] - predict_amount['单宝贝平均销售额'].min()) / (predict_amount['单宝贝平均销售额'].max() - predict_amount['单宝贝平均销售额'].min()))
# 按照相对竞争度的顺序来排序
predict_amount.sort_values(by='相对竞争度', inplace=True)
return predict_amount
process_data(mouse, by='价格区间')
predict50 = process_data(price50, by='细分价格区间')
def draw(predict_amount):
predict_amount['预估销售额占比'].plot(kind='bar', figsize=(12, 5), color='wheat', label='预估销售额占比')
predict_amount['相对竞争度'].plot(marker='o', label='相对竞争度')
plt.legend()
draw(predict50)
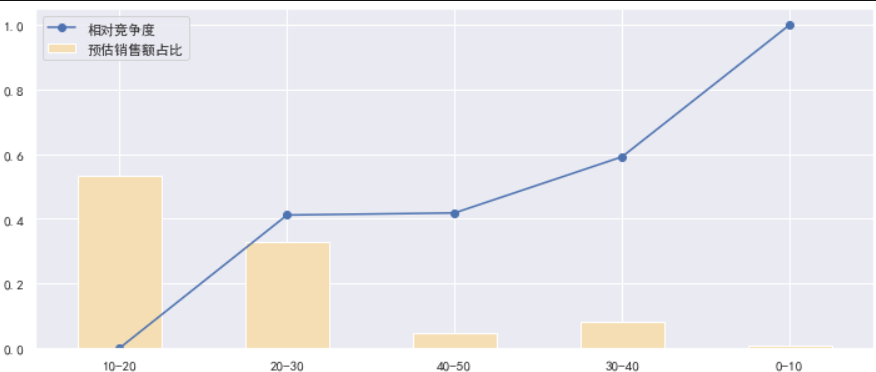
store_type = process_data(price50, by='店铺类型')
draw(store_type)
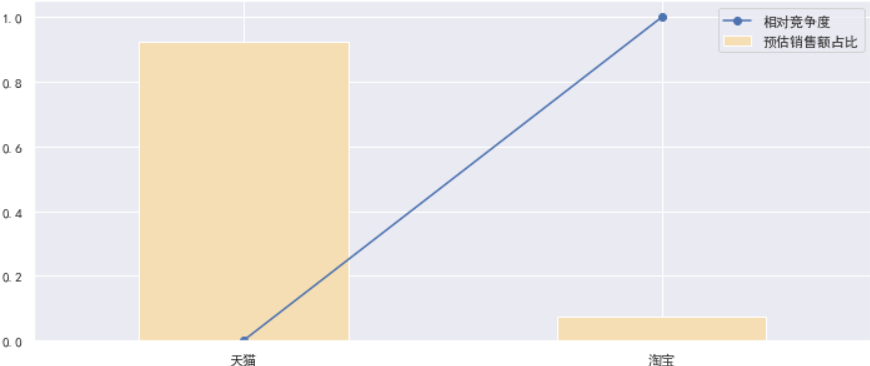
# 产品型号分析
product_type = process_data(price50, by='型号')
product_type.sort_values(by='预估销售额占比', ascending=False, inplace=True)
def draw(predict_amount):
predict_amount['预估销售额占比'].plot(kind='bar', figsize=(12, 5), color='wheat', label='预估销售额占比')
predict_amount['相对竞争度'].plot(marker='o', label='相对竞争度', rot=90)
plt.legend()
draw(product_type[:19])
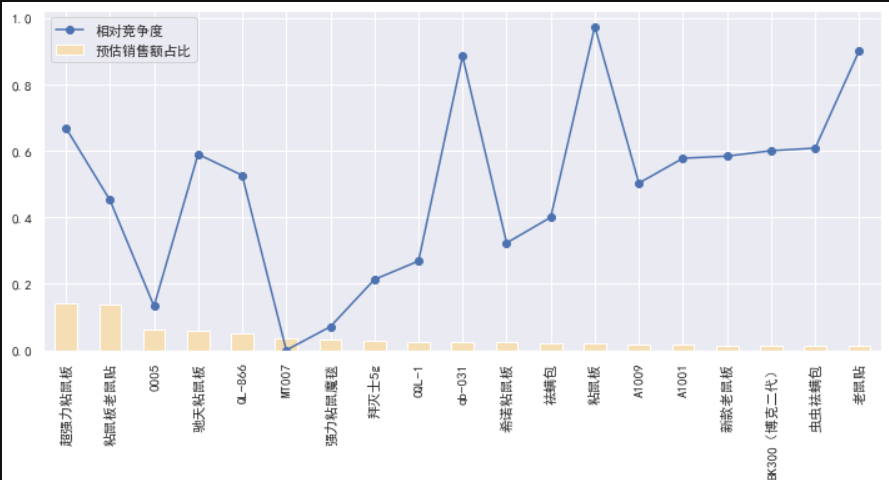
product_form = process_data(price50, by='物理形态')
draw(product_form)
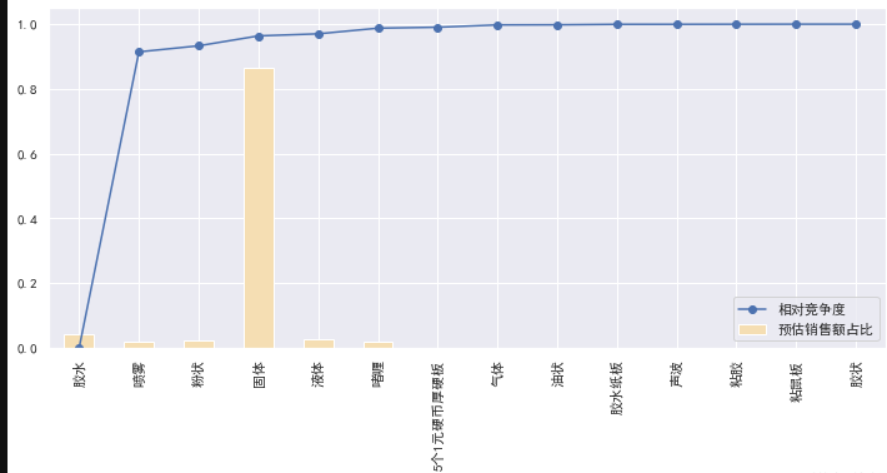
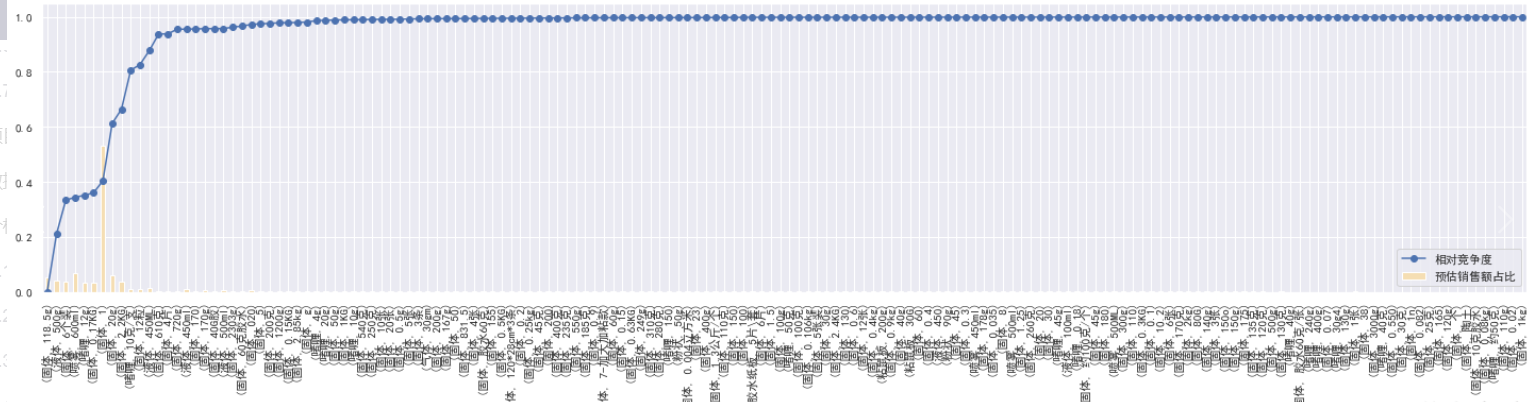
物理形态和净含量分析
# 物理形态和净含量分析
form_net = process_data(price50, by=['物理形态', '净含量'])
def draw(predict_amount):
predict_amount['预估销售额占比'].plot(kind='bar', figsize=(25, 5), color='wheat', label='预估销售额占比')
predict_amount['相对竞争度'].plot(marker='o', label='相对竞争度', rot=90)
plt.legend()
draw(form_net)