目录

在人工智能迅猛发展的时代,前沿模型正不断突破极限。今天,我们深入剖析 xAI 推出的最新力作——Grok-4。这款模型并非AI竞赛中的普通选手,而是以其卓越架构重新定义了推理、编码和科学问题解决的标准。当然,作为任何先驱者,它也并非完美无缺。在这篇博文中,我们将基于最新基准数据,探讨 Grok-4 的显著优势,同时坦诚剖析其潜在短板。无论你是 AI 爱好者、开发者还是研究者,了解 Grok-4 的特性都能帮助你判断它是否适合你的需求。
剖析 Grok-4 的优势:基准领先与多功能性
Grok-4 在众多严苛基准测试中脱颖而出,常常超越 OpenAI、Google 和 Anthropic 等巨头的产品。这些评估涵盖了从多模态理解到高级数学和编码任务的各个领域,展现了 Grok-4 强大的通用智能。
首先,在综合智能指标上,Grok-4 表现出色。以下是其在多项关键基准上的平均得分汇总图表,展示了它与其他模型的比较:
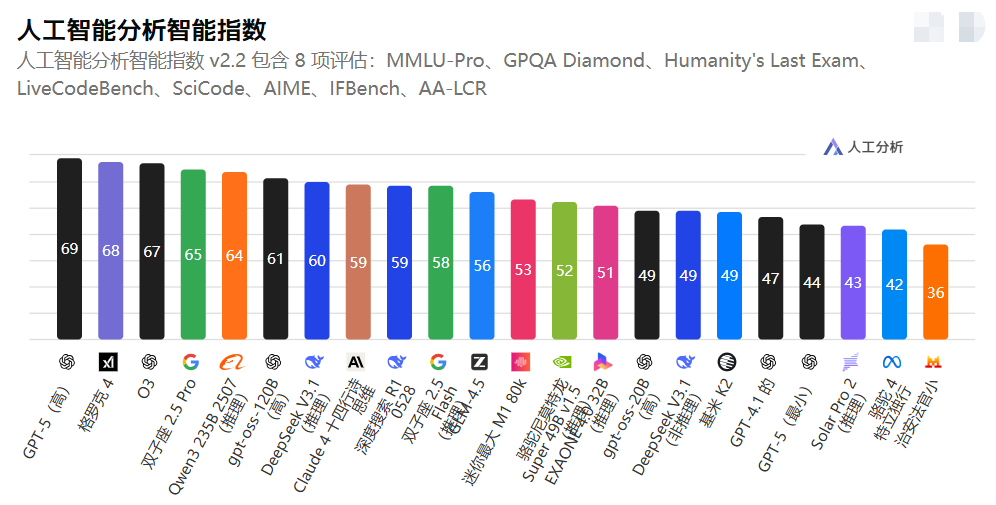
从图中可见,Grok-4 以 68 分位居榜二,领先于OpenAI 的 GPT-o3(67 分)和谷歌的 Gemini 2.5 Pro(65 分)。这得益于其在 MMLU-Pro、GPQA Diamond、Humanity's Last Exam、LiveCodeBench、SciCode、AIME、IFBench 和 AA-LCR 等 8 项测试中的优异表现,平均得分高达 69%,体现了其在知识密集型任务上的深度理解能力。
在科学编码(SciCode)基准上,Grok-4 的表现尤为突出:
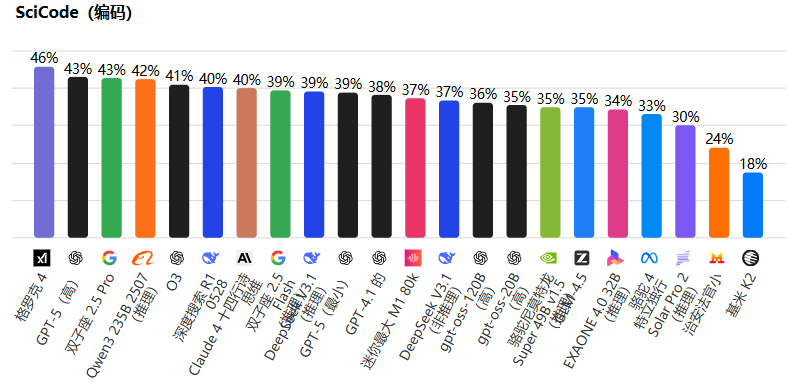
这里,Grok-4 以 46% 的准确率领跑,超越了GPT-5(43%)和 Gemini 2.5 Pro(43%)。这表明 Grok-4 在处理复杂科学计算和代码生成时,具有更高的精确性和效率,适合科研和工程应用。
GPQA Diamond 基准进一步强化了其在研究生级问题解决上的实力:
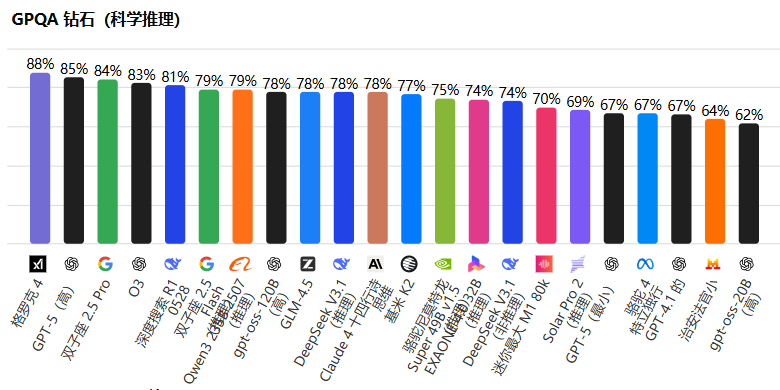
Grok-4 以 88% 的准确率拔得头筹,超越了GPT-5(85%)和 Gemini 1.5 Pro(84%)。
另一个亮点是其在函数调用基准(IFBench)上的性能:
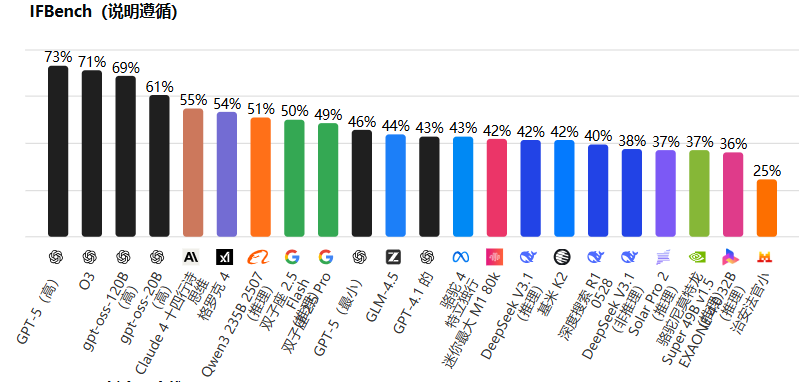
Grok-4 在IFBench上的性能较为中庸,与 GPT-5(73%)和O3(71%)还有一定的差距。它在工具集成和自动化任务中有着相对的的优势,对于构建智能代理系统至关重要。
此外,在长上下文阅读理解(AA-LCR)基准中,Grok-4 同样领先:
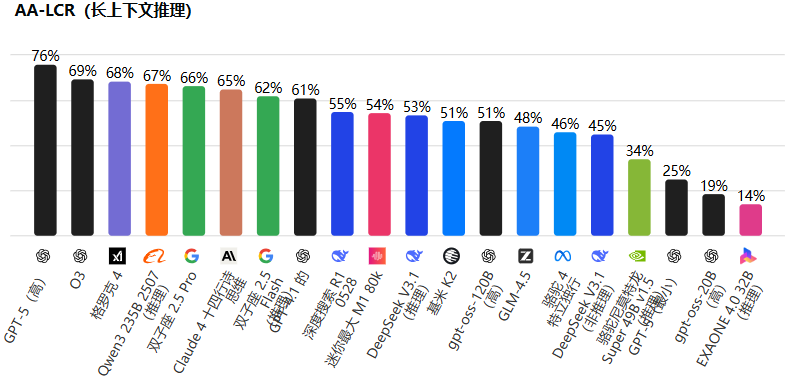
以 68% 的得分名列前茅,稍逊于GPT-5(76%)和 O3(69%)。这证明了 Grok-4 在处理长篇文本时的强大上下文保持能力,避免了常见的信息丢失问题。
在多模态理解基准(MMLU-Pro)上:
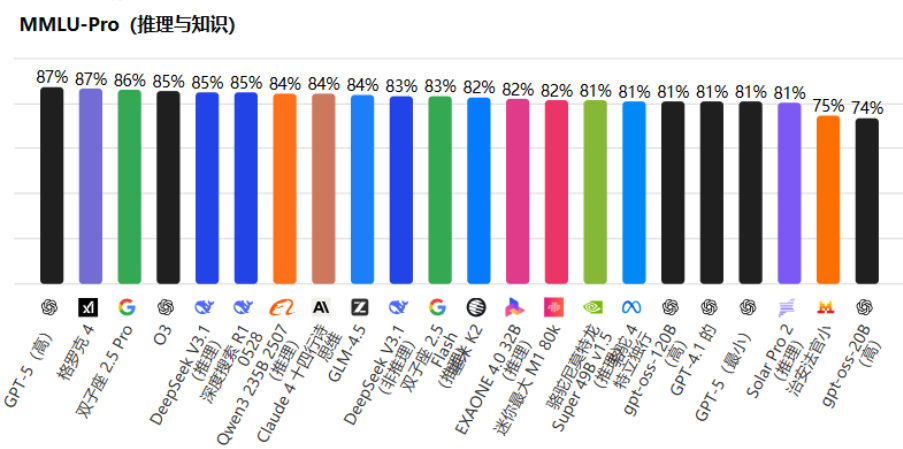
Grok-4 以 87% 的得分与GPT-5并列第一,领先于 Gemini 2.5 Pro(86%)和 O3(85%)。这反映了其在多语言、多领域知识融合方面的全面性。
LiveCodeBench 测试则展示了其实时编码能力:
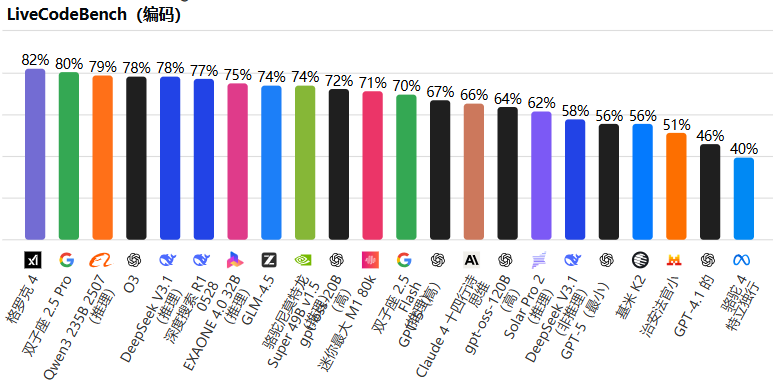
Grok-4 以 82% 的得分领先,证明了它在动态编程环境中的适应性。
Grok-4 的短板:高性能背后的权衡
尽管 Grok-4 在基准和速度上大放异彩,但并非没有短板。首先,从基准数据看,虽然它在大多数测试中领先,但在某些特定子领域(如某些开源模型在 niche 任务上的表现)可能并非绝对霸主。例如,在输出速度基准中:
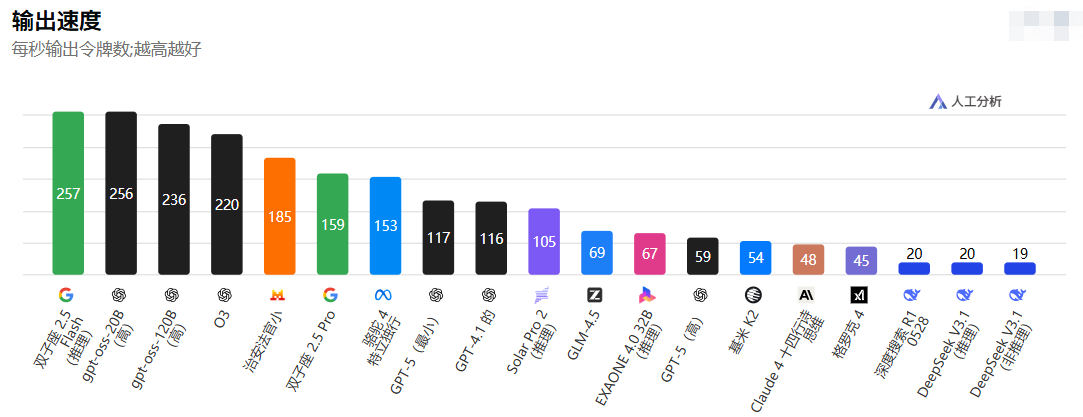
Grok-4 的45 tokens/秒排名靠后,这表明在高负载场景下,其优势可能被缩小,尤其当资源受限时。
更重要的是,高性能往往伴随着高成本。Grok-4 的训练和推理过程需要海量计算资源,这可能导致部署成本高企。对于小型团队或个人开发者来说,访问 Grok-4(尤其是预览版)可能受限于订阅模式,如 xAI 的 SuperGrok 或 PremiumPlus 计划。此外,作为预览版,它可能存在稳定性问题,如在边缘案例中的幻觉或偏见风险高于成熟模型。
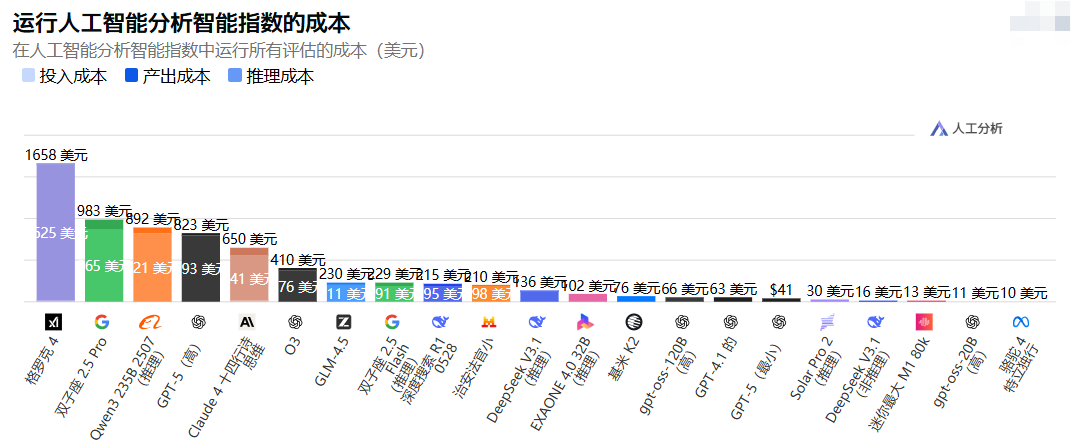
另一个潜在短板是模型规模带来的环境影响:训练此类前沿模型消耗大量能源,引发可持续性担忧。最后,在隐私和伦理方面,Grok-4 如其他大型模型一样,可能面临数据偏见或滥用风险,尽管 xAI 强调透明,但实际应用中需谨慎。运行人工智能分析智能指数的成本:
Grok-4 的未来潜力
总体而言,Grok-4 预览版以其基准霸主地位和闪电般的速度,标志着 AI 向更智能、更高效的方向迈进。它适合需要高精度推理的任务,如科学研究、代码开发和复杂决策。但在选择时,必须权衡其成本和潜在局限。如果你正寻求前沿 AI 工具,希望这篇博客可以帮助到你。欢迎在评论区分享你的看法!