摘要:
随着大型语言模型(LLM)在自然语言处理领域取得显著成功,其“黑箱”特性与可解释性、可靠性不足的矛盾日益凸显。为应对此挑战,引入公理化体系,构建符号主义与连接主义相融合的混合智能模型,成为实现可解释、可推理、高鲁棒性深层语义分析的关键研究方向。本报告旨在深入探讨公理化模型在NLP深层语义分析中的设计思路、关键技术实现要点、设计挑战与未来展望。研究表明,尽管该路径在理论上具备高度可行性,并与神经符号AI等前沿领域高度契合,但在公理的动态扩展、量化评估及计算效率等方面仍面临巨大挑战,需要学术界与工业界共同推动其发展。
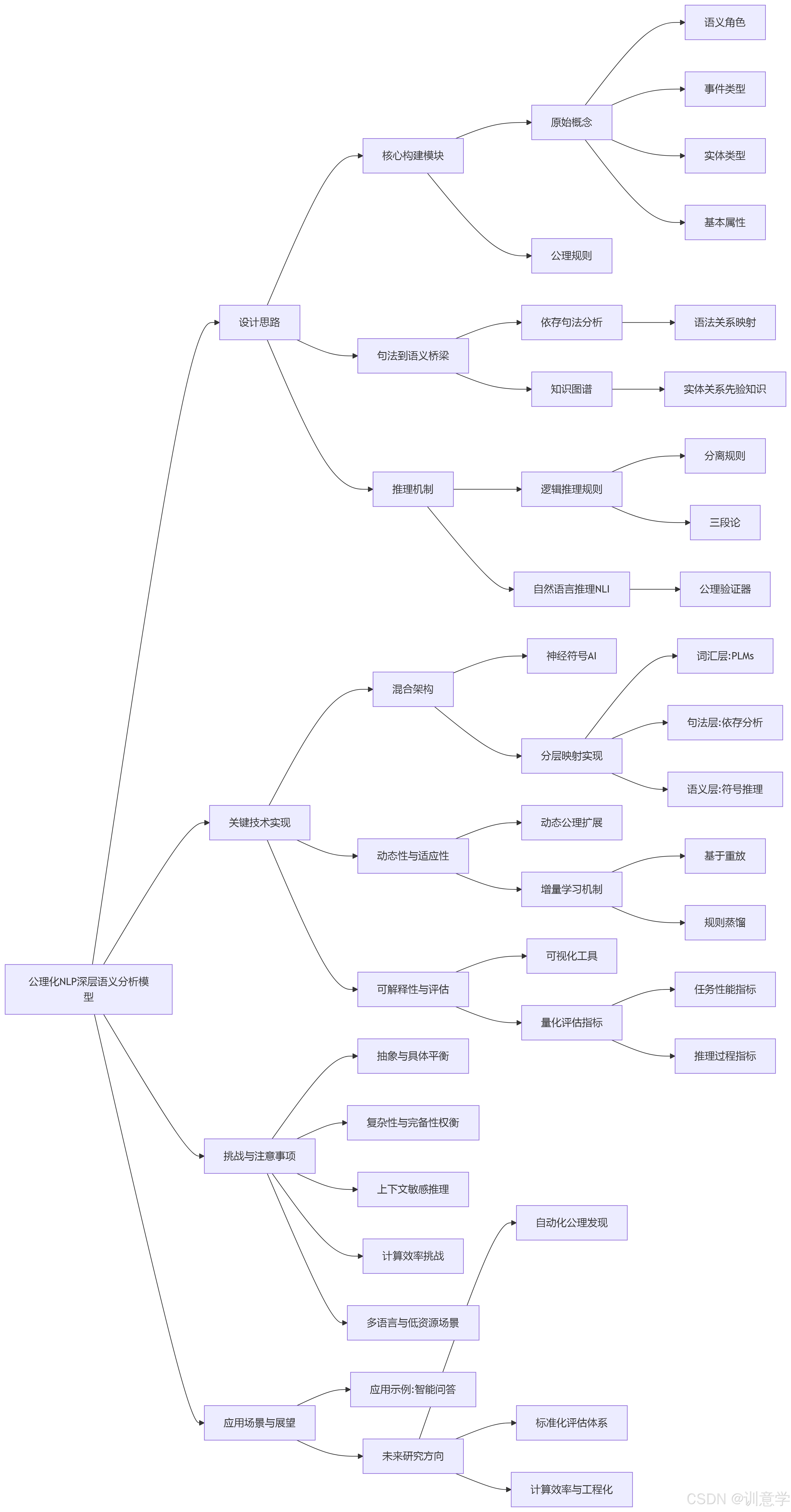
一、公理模型在深层语义分析中的设计思路
将公理化体系引入深层语义分析,其核心目标是将人类知识的逻辑结构与神经网络强大的表征能力相结合,构建一个既能理解语言又能进行逻辑推理的系统。这套设计思路可以分解为以下几个层面:
1.1 核心构建模块:原始概念与公理规则
公理化模型的基础是定义一套形式化的语言来描述世界。
原始概念(Primitives) :这是语义世界的“原子”。它们是不可再分的基础语义单元,例如语义角色(如: 施事者 (Agent) 、 受事者 (Patient) 、 工具 (Instrument) )、事件类型(如:
Create、Transfer、Control)、实体类型(如:Person、Organization、Location)以及基本属性(如:Color、Size)。这些概念构成了语义表示的词汇表。公理规则(Axiomatic Rules) :公理是定义原始概念之间关系的、不证自明的基本命题。这些规则通常采用一阶谓词逻辑(First-Order Logic)或类似的逻辑演算进行形式化表达。例如,一个关于“创立”事件的公理可以表述为:
∀x, y (Founder(x, y) → Person(x) ∧ Organization(y))
这条公理明确指出:“如果x是y的创始人,那么x必须是一个人,而y必须是一个组织。” 这种清晰的逻辑约束,为模型的推理提供了坚实的基础。正如搜索结果中提到的,语义解析的目标就是将自然语言句子转换为这种形式化的结构化表示而公理规则正是这种表示的核心。
1.2 句法到语义的桥梁:依存句法与知识图谱
为了将自然语言文本与抽象的公理系统连接起来,需要借助句法结构和外部知识。
依存句法分析(Dependency Parsing) :依存句法树揭示了句子中词语之间的直接语法关系(如主谓、动宾、定中),为公理模型提供了至关重要的句法约束。例如,一个“主-谓-宾”结构(
nsubj-root-dobj)通常可以初步映射为“施事者-事件-受事者”的语义框架。这种映射关系本身也可以被公理化,作为连接句法层和语义层的桥梁规则。知识图谱(Knowledge Graphs) :知识图谱作为一个大规模、结构化的事实数据库,是公理模型的理想“外部知识库”。它提供了海量的实体关系先验知识,例如(马云,创始人,阿里巴巴)。这些事实可以被视为公理系统在现实世界中的“实例(Instances)”。在推理过程中,模型可以将文本中识别出的实体链接到知识图谱,利用图谱中的关系来验证或补全公理推导,这在神经符号AI的应用中是一个核心方向。
1.3 推理机制:逻辑推导与自然语言推理
拥有了公理和事实之后,系统需要能够进行推理。
逻辑推理规则:经典的逻辑推理规则,如 分离规则(Modus Ponens) 和 三段论(Hypothetical Syllogism) ,是公理系统进行演绎推理的核心引擎。例如,基于公理
Founder(x, y) → Person(x)和事实Founder(马云, 阿里巴巴),系统可以通过分离规则推断出Person(马云)。自然语言推理(NLI) :NLI技术用于判断两个文本片段(前提和假设)之间是否存在蕴含、矛盾或中立关系。在公理化模型中,NLI可以扮演“公理验证器”的角色。当模型通过公理推导出一个结论(例如,“马云是一位企业家”)后,可以利用NLI模型来判断这个结论是否与原始文本或更广泛的语料库知识相蕴含,从而增加推理结果的置信度。相关的基准数据集如SNLI和RTE为训练此类验证器提供了基础。
二、关键技术实现要点
将上述设计思路转化为可运行的系统,需要在模型架构、学习机制和评估体系上进行精心的技术设计。
2.1 混合架构:符号主义与连接主义的深度融合
纯粹的符号系统灵活性差,而纯粹的连接主义系统缺乏可解释性。因此,混合架构成为必然选择。截至2025年, 神经符号AI(Neuro-Symbolic AI) 已成为该领域的主流范式。
- 分层映射实现:一个典型的实现方式是建立一个词汇-句法-语义的分层映射。
- 词汇层:利用BERT、RoBERTa等预训练语言模型生成富含上下文信息的词嵌入(Word Embeddings)。
- 句法层:对输入文本进行依存句法分析,得到句法结构树。
- 语义层:设计一个符号化的推理模块。该模块接收来自连接主义模型(如Transformer)生成的语义表示,并将这些表示(如上下文向量)绑定到谓词逻辑的变量上。例如,将句子“马云创立了阿里巴巴”中的“马云”向量映射到变量
x,“阿里巴巴”向量映射到变量y,然后交由符号化的公理系统进行逻辑校验和推理。最新的研究趋势表明,将大型语言模型嵌入到神经符号框架中,以解决复杂的推理问题,是2023至2025年间的热门方向。
2.2 动态性与领域适应性:动态公理扩展与增量学习
一个固定的公理集无法适应所有领域和不断变化的世界。因此,系统必须具备动态扩展其知识的能力。
动态公理扩展:针对特定领域(如金融、医疗),系统应能动态加载专门的公理模块。例如,在医疗领域,可以加载关于“药物-靶点-疾病”关系的特定公理。这要求架构设计具有模块化和可插拔的特性。
增量学习机制(Incremental Learning) :这是实现动态扩展的关键技术。当系统接触到新的语料或知识时,需要能够自动或半自动地发现潜在的新公理,并将其整合进现有系统,同时避免 灾难性遗忘(Catastrophic Forgetting) 。虽然搜索结果表明,当前关于增量学习的研究主要集中在克服神经网络的遗忘问题并且缺少直接针对“公理NLP系统”的案例(Query result for "incremental learning in axiomatic NLP" was negative),但我们可以借鉴这些方法。例如,可以采用:
- 基于重放的方法:存储发现新公理的典型语料样本,在学习新公理时与旧样本一同训练,以巩固旧知识。
- 基于规则蒸馏的方法:将旧公理系统的推理能力“蒸馏”到一个紧凑的表示中,作为学习新公理时的正则化项。
- 一些增量知识获取框架(如KAFTIE, 允许用户逐步向知识库添加规则,这为实现动态公理扩展提供了初步的工程范例。
2.3 可解释性与评估:可视化与新型评估指标
公理化模型的核心优势在于其可解释性,因此必须有相应的技术来呈现和评估这一点。
可视化工具:为了增强模型的透明度,可以开发可视化工具,将公理推导的逻辑链条与原始文本的依存树、注意力分数等叠加展示。用户可以清晰地看到模型的每一步推理是如何基于文本证据和公理规则得出的。
量化评估指标:传统的黑箱模型评估指标(如准确率、F1分数)不足以衡量公理化系统的性能。搜索结果证实,目前尚无专为“公理化深层语义分析”设计的标准基准数据集和评估指标(Queries for specific benchmarks were negative, returning general NLP benchmarks like GLUE/SQuAD, see 。因此,必须设计新的评估体系:
- 任务性能指标:依然可以使用通用的NLP基准(如GLUE, SuperGLUE)来评估系统在下游任务上的最终表现。
- 推理过程指标:这才是评估公理化系统的关键。可以借鉴ERASER基准的思想,该基准旨在评估可解释NLP模型的“理由(Rationales)”。我们可以设计类似的指标:
- 公理覆盖率(Axiom Coverage Rate) :在测试集上,模型正确推理所激活的有效公理占总公理集的比例。
- 推理忠实度(Faithfulness) :评估模型的输出是否确实由其声称的公理推导链条所决定。
- 推理合理性(Plausibility) :评估模型给出的推理路径是否符合人类的认知和逻辑。
- 矛盾检测率:构建包含逻辑矛盾的测试集,评估模型检测出语义矛盾的能力。
三、设计注意事项与挑战
在构建和应用公理化NLP模型的过程中,必须仔细权衡多个方面的因素,并应对一系列严峻的挑战。
3.1 抽象与具体的平衡
公理的设计需要在通用抽象性和领域适配性之间找到平衡。过于抽象的公理(如 Action(x, y))在实际应用中缺乏指导意义;而过于具体的公理(如 Buy_Stock(trader, stock_symbol, price))则会导致规则库急剧膨胀且难以泛化。一个有效策略是设计分层的公理体系,核心层包含普适的核心语义公理,而外围层则包含可动态加载的领域特定公理。
3.2 复杂性与完备性的权衡
公理集合的设计应遵循数学公理体系的基本原则,如独立性、一致性、完备性。一个关键挑战是定义一个 最小公理集(Minimal Axiom Set) ,即用最少的规则覆盖最广泛的语义现象,避免因规则冗余或冲突导致系统复杂度爆炸和推理效率低下(如提示中引用的相关思想)。
3.3 上下文敏感的动态推理
自然语言具有高度的上下文依赖性。同一个词在不同语境下意义迥异(如“打开门”vs“打开文件”)。这意味着公理的激活不能是静态的,而必须是上下文敏感的。一个可行的解决方案是,利用连接主义模型(如带有注意力机制的Transformer)根据当前语境计算出一个“语境向量”,并用该向量来动态地为不同的公理分配权重,或者选择最合适的公理子集进行推理。
3.4 计算效率与可扩展性
符号推理的计算复杂度极高。例如,基于图的全局优化解析算法(如Eisner算法)虽然精确,但其O(n³)的复杂度在处理长文本时是不可接受的。因此,必须优化计算效率,例如采用基于转移(transition-based)的轻量级解析方法,或者开发高效的符号推理引擎,甚至将部分推理过程编译成神经网络操作,利用GPU进行加速。
3.5 多语言与低资源场景的挑战
如何将公理化模型适配到多种语言,尤其是在低资源语言上,是一个巨大挑战。一种有前景的思路是利用预训练的多语言模型(如mBERT, XLM-R)生成跨语言的、对齐的语义表示。在此基础上,可以先构建一套语言无关的核心公理(如普遍的语义角色关系),然后再注入少量针对特定语言的句法或词汇层面的公理规则。增量学习方法也可以用于逐步将新语言的知识融入现有模型。
四、实际应用场景示例
我们通过一个具体的例子来展示公理化系统的工作流程。
输入问题:“谁创立了阿里巴巴并出生在杭州?”
连接主义模块(NLU)处理:
- 实体识别与链接:识别出“阿里巴巴”(Organization)、“杭州”(Location)。
- 关系抽取:识别出两个核心意图:
创立(X, 阿里巴巴)和出生于(X, 杭州)。
符号主义模块(推理)处理:
- 变量绑定:将未知的“谁”绑定到变量
X。查询被形式化为:Founder(X, alibaba_inc) ∧ Born_In(X, hangzhou_city)。 - 公理激活:
- 激活公理1:
∀x, y (Founder(x, y) → Person(x) ∧ Organization(y)) - 激活公理2:
∀x, z (Born_In(x, z) → Person(x) ∧ Location(z))
- 激活公理1:
- 知识图谱/数据库查询:系统在知识库中执行查询,寻找同时满足
Founder(X, alibaba_inc)和Born_In(X, hangzhou_city)的实体X。 - 推理与验证:知识库返回候选实体“马云”。系统利用公理进行验证:
- 从
Founder(马云, 阿里巴巴)和公理1,推断出Person(马云)和Organization(阿里巴巴)。 - 从
Born_In(马云, 杭州)和公理2,推断出Person(马云)和Location(杭州)。 - 所有推断与实体链接的结果一致,无矛盾。
- 从
- 变量绑定:将未知的“谁”绑定到变量
答案生成:系统输出最终答案:“马云”。整个推理路径(使用了哪些事实和公理)可以一并输出,提供了完全的可解释性。
总结
在2025年的今天,构建基于公理的深层语义分析系统,代表了NLP从纯粹数据驱动向知识与数据双轮驱动范式转变的重要方向。这一路径以形式化逻辑为核心,以神经符号混合架构为支撑,有望从根本上解决当前深度学习模型在可解释性、逻辑一致性和常识推理方面的固有缺陷。
然而,理论的优雅与实践的鸿沟依然巨大。未来的研究必须在以下方面取得突破:
- 自动化公理发现与增量学习:如何从海量非结构化文本中高效、准确地挖掘和更新公理规则,是决定该技术能否大规模应用的前提。
- 标准化评估体系:迫切需要建立如ERASER般的、能够衡量推理过程忠实度和合理性的基准和指标,以引导研究方向。
- 计算效率与工程化:开发可扩展、高效率的混合推理引擎,使其能够处理真实世界的复杂文本和应用场景。
未来,随着小样本学习、多模态语义理解等技术的进一步发展,公理模型与连接主义模型的融合将更加深入。我们有理由相信,这种融合了“学习”与“推理”的AI范式,将在智能问答、司法文本分析、金融风控、科学知识发现等对可靠性和可解释性有严苛要求的领域中,发挥不可替代的作用。

神经符号推理代码示例
class NeuroSymbolicSystem:
def __init__(self):
# 初始化神经网络组件
self.ner_model = load_pretrained_ner_model()
self.relation_extractor = load_relation_extractor()
# 初始化符号推理组件
self.knowledge_base = KnowledgeGraph()
self.axiom_base = AxiomBase()
def answer_question(self, question):
# 神经网络处理:实体识别和关系抽取
entities = self.ner_model.extract_entities(question)
relations = self.relation_extractor.extract_relations(question, entities)
# 变量绑定和查询构建
query = self.build_query(entities, relations)
# 知识库查询
candidate_answers = self.knowledge_base.query(query)
# 公理验证和推理
verified_answers = []
for candidate in candidate_answers:
if self.verify_with_axioms(candidate, relations):
verified_answers.append(candidate)
# 生成可解释的输出
explanation = self.generate_explanation(verified_answers[0], relations)
return verified_answers[0], explanation
def verify_with_axioms(self, candidate, relations):
# 应用公理验证候选答案
for relation in relations:
axiom = self.axiom_base.get_relevant_axiom(relation)
if not axiom.apply(candidate, relation):
return False
return True