文章目录
HTTP协议
本篇文章,我们将来了解一下网络中一种非常常用、也可以说是最常见的网络协议——HTTP
对于协议,其实已经有一定的理解了!在网络实践的自定义协议实现网络计算器已经大概知道了,应用层上的协议是如何进行定制并运行的:
详情参考这篇文章:网络实践——自定义协议
应用层的协议是需要根据特定的需求来进行定制的。所以,这也就是为什么OSI七层模型中,上面三层是没有办法设置到内核中的。
这种应用协议,都是在应用层实现的。说到底,也就是程序员实现的!
这里,我们来理解一下关于HTTP协议:
在互联网世界中,HTTP(HyperText Transfer Protocol,超文本传输协议),一个至关重要的协议。定义了客户端(如浏览器)与服务器之间如何通信,以交换或传输超文本(如 HTML 文档)。
这种协议都是由一些特别顶级的程序员进行设定编写的!可以直接供其他人参考和使用:
HTTP 协议是客户端与服务器之间通信的基础。客户端通过 HTTP 协议向服务器发送请求,服务器收到请求后处理并返回响应。HTTP 协议是一个==无连接、无状态==的协议,即每次请求都需要建立新的连接,且服务器不会保存客户端的状态信息。
Tips:
这里存在着很多关于HTTP的相关概念,这里我们一下子也是解释不清楚的!
后序我们将根据HTTP相关的知识来模拟实现HTTP协议通信的过程。边写代码的同时,来理解其背后的相关原理和相关概念!!!
理解相关概念
这里我们先引入一些相关概念,就是便于后面编写代码的!我们不做理解。我们等到后序编写代码的时候可以再回头理解这些理论知识!
HTTP相关背景知识
认识URL
我们来看这么一串网址:

首先,第一个部分http://,我们把它堪称固定的一部分,这个是指示当前协议的。
第二个部分user:pass,这个是登陆的相关信息。不过有时候可以省略不出现。
第三个部分www.example.jp是域名!即我们要找的网址是哪一个!
第四个部分就是要访问某网址对应服务器的端口号。
第五个部分,我们发现是一个带层次的文件路径!我们发现,以/分割路径!
后面?部分,都是一些相关的参数。
我们现在直接看这个URL(网址),我们肯定是很懵的,不用担心,这些我们后面都会进行讲解!我们只需要知道的是,我们可以通过这么一串URL进行访问网络资源即可!
HTTP协议在网络通信的宏观认识
对于URL来说,虽然其可以被分为很多部分,但其实,最简单的主体应该是:
https://服务器地址:端口号,甚至有些时候,端口号都不用!
然后,我们会有一个疑问?为什么只使用类似于www.example.com,浏览器就能够自动的跳转到正确的网址呢?

首先,对于这个服务器地址,其实还有另外一种我们很熟悉的叫法——域名!
比如前段时间www.ai.com,访问该域名就访问到了Deepseek!(现在被改了)
这里直接揭晓答案:
其实域名,就是服务器对应的IP地址!因为ip地址具有标识唯一地址性!
那么,我们是如何通过这样一个域名来访问对应的服务器呢?
首先,我们一般访问服务器都是通过浏览器这个客户端来进行访问的!浏览器在接收到一个域名后,就会向域名解析器(这个地址浏览器能够找的到,一般是被存储在指定位置),然后通过域名解析器,将常见的域名转化为其服务器对应的ip地址!
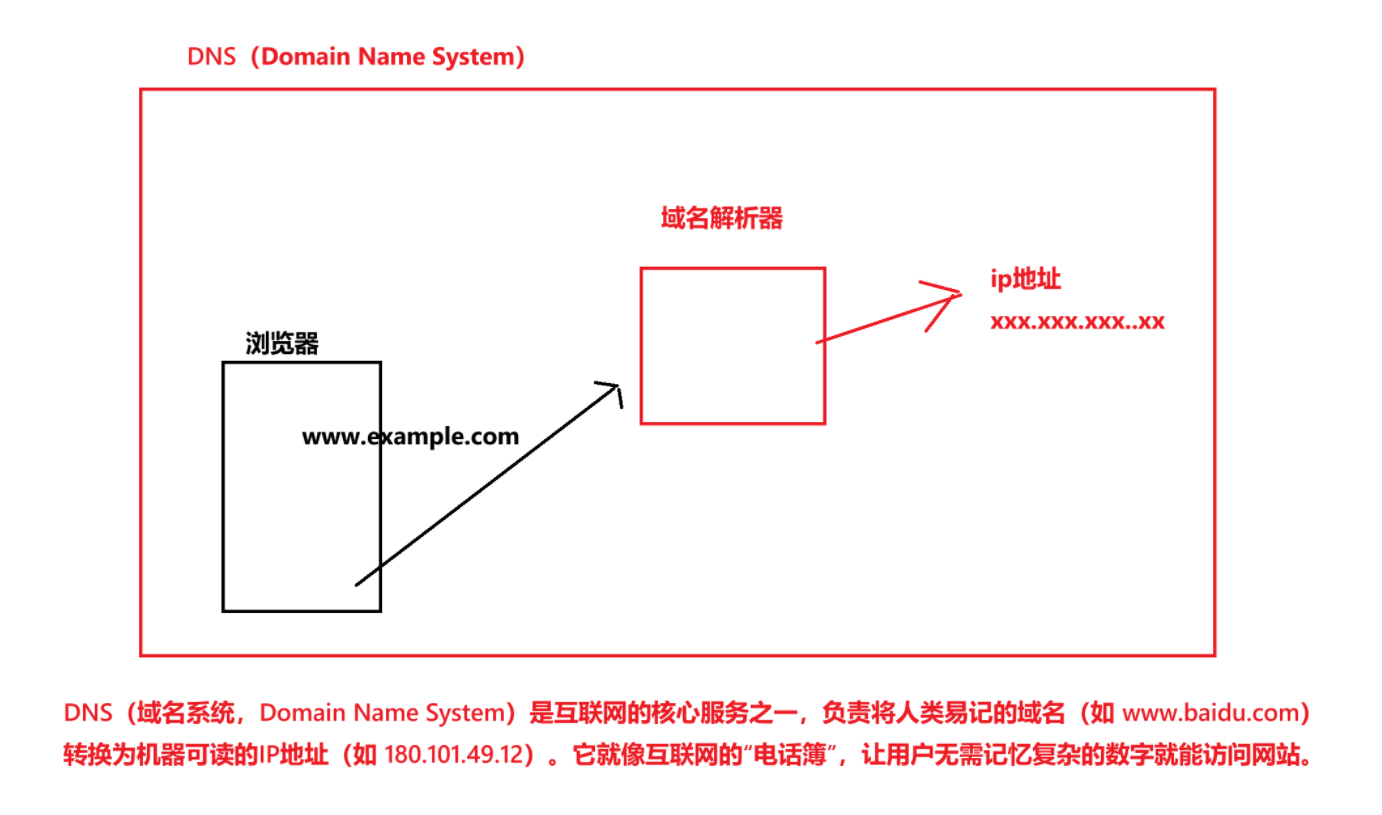
上述的过程,被叫做DNS系统,即域名系统。
这个域名解析器,其实是属于基础设施的!因为它非常重要!有一些大公司,如Google,他们会有自己的域名解析器,用于将域名快速转化为ip地址!
提出一个问题: 为什么不直接使用ip地址呢?非要进行这么一层转化?
因为使用域名更符合我们人类的阅读,能够见名思义!如www.baidu.com
直接使用ip地址其实是不太知道到底要访问哪个服务器的,而且,最大的问题是,不方便记忆和使用。直接使用域名是非常方便的!
我们理解完了域名,还需要在理解使用HTTP通信相关资源:
我们知道:要访问服务器,必须知道它的ip + port!(eg: ./tcpserver*.exe 8080)
我们上网的主要目的是什么?其实就两大点:
1.从服务器中获取资源(网页、css、视频、图片、文本…)
2.把相关资源/数据上传到服务器
本质上,我们上网,就是在拿着客户端和服务器做IO操作罢了!
那么,我们访问的资源存放在服务器哪里呢?我们要上传的资源放在哪里呢?

答案就是在这个URL中可以体现到的带层次的文件路径!它是以/为分隔符的!
进一步了解:这样一个以/为分隔符,有层次的文件路径,我们在哪里见过呢?
答案就是我们学的Linux系统!所以,我们可以大致知道,大部分的URL中,带层次的文件路径都是以/作为分隔符的,所以,它们都是以Linux系统来运行服务器的!
(这和我们一开始学习Linux系统就说,Linux系统常用于企业中做服务器的观点是相吻合的!)
这里还要提出一个问题:
我们已经知道文件路径是Linux下的文件路径,那么第一个/代表的是服务器的根目录吗?
答案:其实不是!这个不可能是Linux服务器的根目录。我们想一下都知道,根目录底下有很多重要的东西,企业是不可能随便让用户访问的!这个其实是要访问的web根目录!
这里不知道没有关系,我们后面写代码的时候能知道!
访问/上传的资源都存在了对应的文件目录下,所以,我们访问的所有资源,都是文件!如视频、网页、音频、文本… 它们都是文件,只不过是不同格式罢了!
所以,我们拿着浏览器访问服务器,访问/上传资源,本质上就是IO操作!服务器是一个进程,我们使用的浏览器,作为客户端,在我们的主机上也是一个进程!
这两个进程是不同主机的,进行通信!这不就是网络通信吗?那就是使用socket进行通信!
而服务器是需要绑定确定的端口号的!但是,很多时候,我们并没有输入端口号,就能访问到正确的网页,这是为什么?
因为,成熟的协议,都是由固定的端口号的!
http:80
https:443
ssh:22
# 可以使用下面这条指令查询ssh服务的固定端口号22
ynp@hcss-ecs-1643:~$ sudo netstat -tulnp | grep sshd # sshd,说明是ssh的守护进程版
但是,未来我们实现的服务器(简单实现),是必须要输入端口号的!因为我们绑定了一个具体的端口号。我们在不升级权限到root的情况下是没有办法绑定0~1023的端口号的!
urlencode & urldecode
有时候我们会发现,网址后面有一长串乱七八糟的东西:
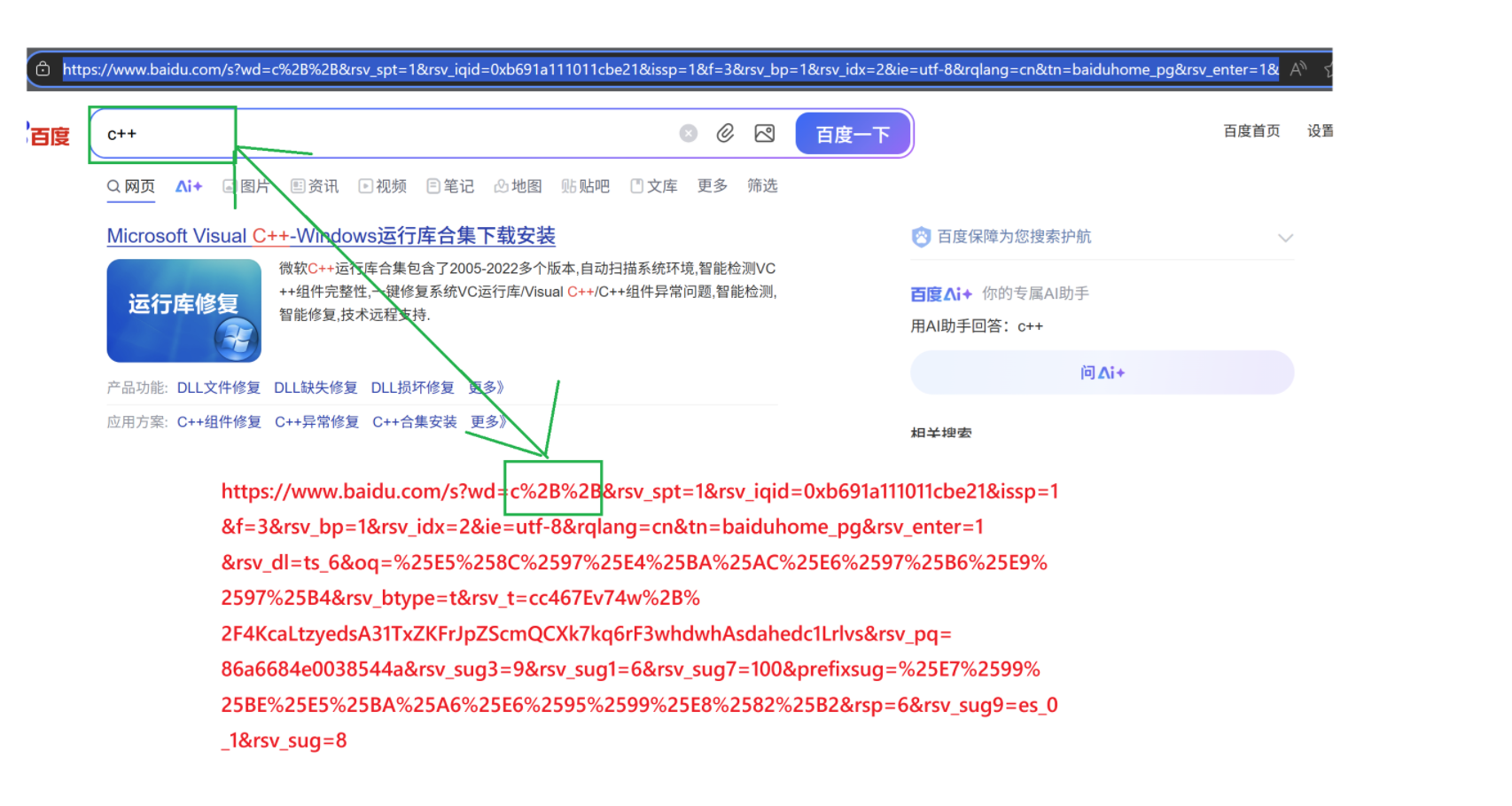
我们可以发现,我们输入的内容,会被解析成其它的内容,如+ -> %2B。
这种情况都是出现在动态交互式的网站的!也就是返回一些动态处理的结果的场景!
其实是因为:
像/ ? :等字符,已经被url当做特殊意义理解了。因此这些字符不能随意出现。
比如,某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义。
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式。
比如+,ASCII:43,HEX:0x2B,从右到左取四位(不足直接操作) -> %2B
这个过程,其实就是给报文进行encode的过程。然后发送回来给我们看的,是decode后的。这点我们只需要了解一下就好了!我们不需要深入了解。
这里看这个网址能不能帮助实现url对应编码解码:urlencode & urldecode工具(不一定能用!)
HTTP请求和应答的格式
上面,我们是基本了解清楚了,基于HTTP的相关通信过程、本质、方式。
但是,这里学习的是HTTP协议!而且是一个应用层的协议!
我们是自行实现过这种协议的——网络版本计算器。
我们在协议中,定义了请求、应答,通信的双方就是基于特定的协议来进行网络通信!
这里的HTTP也是一样的,我们来看一下它们的请求和应答的格式:
HTTP请求:
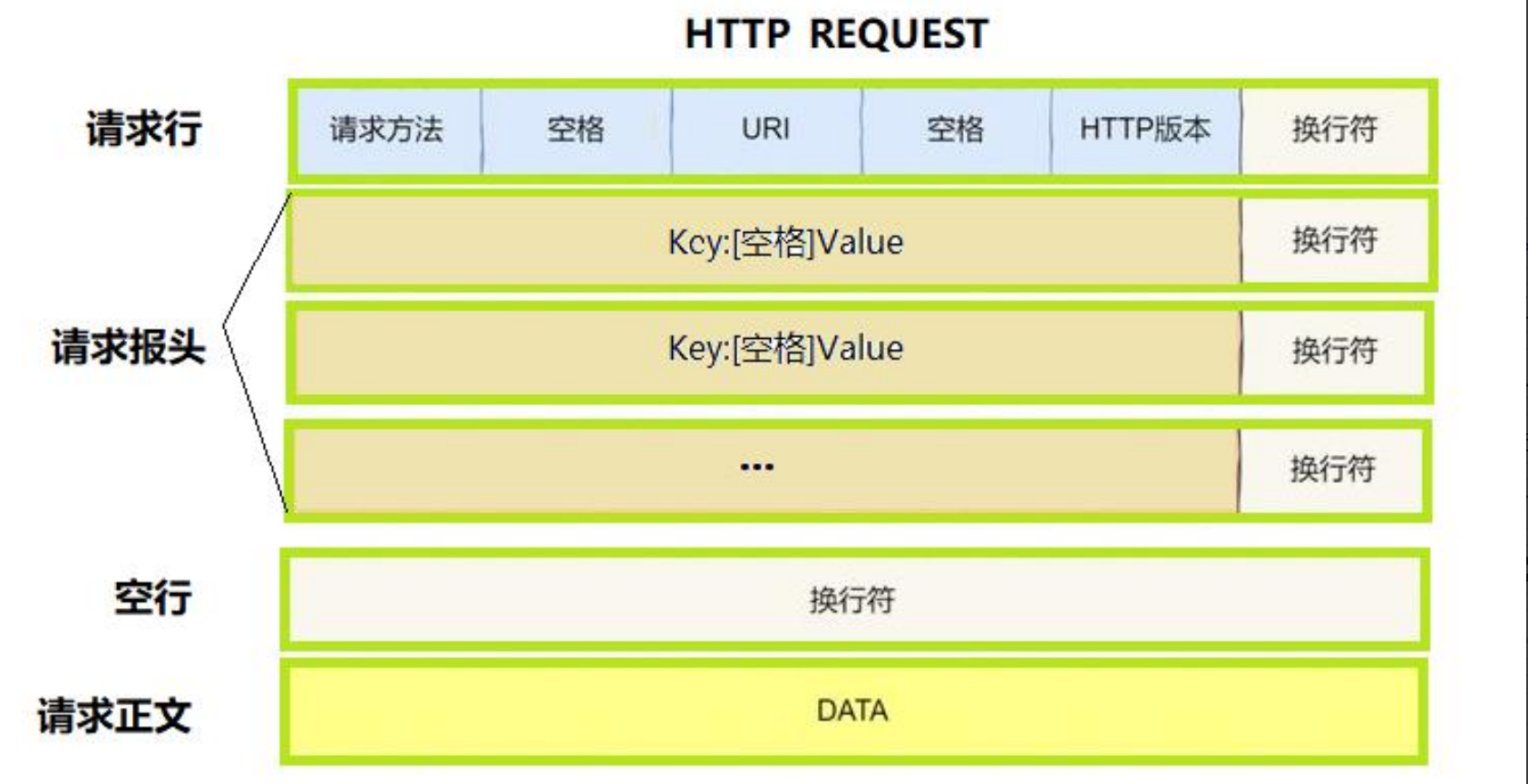
HTTP应答:

中间的报头部分,都是一对对的key&value形式键值对,中间以:[空格]作为分割!
这里我们需要厘清几个细节,方便后序理解:
首先,这个请求和应答的本质是什么?就是个结构体,协议不就是结构化的数据吗?
但是,真正在网络中传输的呢?
因为需要兼容多平台,所以不可能直接传结构化的数据的!所以,这就需要使用到序列化和反序列化的概念,所以,我们是否可以把上面的协议和请求看成一个大字符串?答案是可以!
这里也是提出几个问题:
1.这个协议,报头和有效载荷如何分离?
2.不同行之间如何分割?
3.序列化和反序列化谁来做?
回答这三个问题非常简单:
1.在HTTP请求和应答中,我们发现都会有一行空行。所以,要进行分离有效载荷和报头的分离是很简单地,以空行作为分割即可。
2.不同行之间,都是通过换行符来进行分割的。提取一行是很简单的事情。
3.序列化和反序列化,肯定是在应用层来做!这个我们是非常熟悉的了。
模拟实现浏览器访问自定义服务器
这里我们直接给出整份源码先,然后根据这一份代码来进行相关讲解:HTTP模拟
今天我们就使用HTTP协议来手搓一个简单地服务器,旨在理解HTTP背后的相关原理。
我们前面并没有将HTTP中其它的原理,只认识了请求和应答。但是没有关系,我们后序都会通过写代码的形式来进行理解原理!
今天这里,我们不需要写客户端了!我们只需要写服务器就可以了!因为我们其实已经有现成的基于HTTP/HTTPS协议通信的客户端——浏览器。我们只需要拿着浏览器访问即可!
关于http request
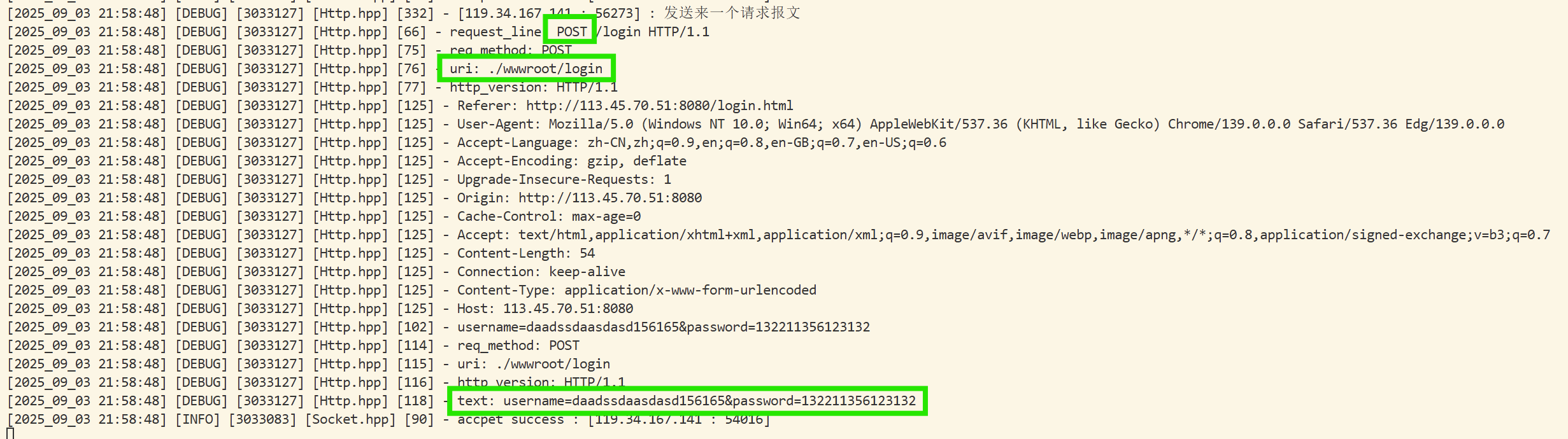
我们现在只是知道了http request的格式,但是并没有见过真的,我们可以来看一下:
这里我们只展示此时添加新的代码,其余的都是以前封装的组件之类的。
Http.hpp:
#pragma once
#include <memory>
#include <unordered_map>
#include <sstream>
#include <fstream>
#include <functional>
#include "Common.hpp"
#include "TcpServer.hpp"
#include "Util.hpp"
#include "Log.hpp"
const std::string space = " ";
const std::string line_break = "\r\n";
const std::string headers_sep = ": ";
using namespace myLog;
const std::string webroot = "./wwwroot";
const std::string homepage = "index.html";
const std::string page_404 = "404.html";
//这里要说明的是:Http协议,是不依赖于第三方库进行序列化和反序列化的!
//Http请求格式
class HttpRequest{
public:
HttpRequest()
:_blank_line(line_break),
_is_interact(false),
_args("")
{}
~HttpRequest(){}
//其实,今天来说,客户端是浏览器!我们可以直接拿浏览器来访问我们写的服务器。所以,请求的序列化写不写都可以!
//但是就不写了,就留一个方法
//因为http协议已经有固定的序列化方式和反序列化格式了!
std::string Serialize(){return "";}
void ParseRequestLine(std::string& request_line){
std::stringstream ss(request_line);
//以空格作为分隔符,将字符串分割后依次插入对应的字段
ss >> _req_method >> _uri >> _http_version;
}
bool GetKV_AndSet(std::string headline){
//key: value
size_t pos = headline.find(headers_sep);
if(pos == std::string::npos) return false;
std::string key = headline.substr(0, pos);
std::string value = headline.substr(pos + headers_sep.size());
_headers[key] = value;
return true;
}
//反序列化还是要写的
bool DeSerialize(std::string& req_str){
//1.提取请求行
std::string request_line;
Util::ReadOneLine(req_str, &request_line, line_break);
LOG(LogLevel::DEBUG) << "request_line: " << request_line;
//2.把请求行放入到对应的字段 -> 使用stringstream
ParseRequestLine(request_line);
//这里要注意,uri对应的就是要访问的服务器上对应的资源
if(_uri == "/") _uri = webroot + _uri + homepage;
else _uri = webroot + _uri;
LOG(LogLevel::DEBUG) << "req_method: " << _req_method;
LOG(LogLevel::DEBUG) << "uri: " << _uri;
LOG(LogLevel::DEBUG) << "http_version: " << _http_version;
if(_req_method == "POST" || _req_method == "post") _is_interact = true;
//3.把报头提取出进行分析
std::string header_line;
Util::ReadOneLine(req_str, &header_line, line_break);
//到这里都正常
//只要不是读出来 "",就表明还是报头
while(header_line != ""){
//此时读到了一行 -> key: value(正常来说,如果是空行读出来就是 "")
GetKV_AndSet(header_line);
header_line.clear();
Util::ReadOneLine(req_str, &header_line, line_break);
}
//此时读到了空行就退出循环了,并且ReadOneLine中已经把读到的给删除了
DebugHeaders();
//如果使用POST来进行传参,那么参数在正文,这里就不管了
//req_str剩下的就是正文了!
_text = req_str;
LOG(LogLevel::DEBUG) << _text;
//如果使用GET方法传内容给服务器,那么参数在uri上,所以得对uri作进一步解析
std::string tmp = "?";
auto pos = _uri.find(tmp);
if(pos != std::string::npos) {
// /login?username=adasdad&password=adaadsasd
_args = _uri.substr(pos + tmp.size());//截取参数
_uri = _uri.substr(0, pos);//获取真正的服务!
_is_interact = true;
}
LOG(LogLevel::DEBUG) << "req_method: " << _req_method;
LOG(LogLevel::DEBUG) << "uri: " << _uri;
LOG(LogLevel::DEBUG) << "http_version: " << _http_version;
if(_args != "") LOG(LogLevel::DEBUG) << "uri args: " << _args;
LOG(LogLevel::DEBUG) << "text: " << _text;
return true;
}
void DebugHeaders(){
for(auto& head : _headers){
LOG(LogLevel::DEBUG) << head.first << headers_sep << head.second;
}
}
std::string GetUri(){return _uri;}
std::string GetText(){return _text;}
bool Is_Interact(){return _is_interact;}
std::string GetArgs(){return _args;}
private:
std::string _req_method;
std::string _uri;
std::string _http_version;
std::unordered_map<std::string, std::string> _headers;
std::string _blank_line;
std::string _text;
bool _is_interact;//判断是否有交互 -> 后序来实现交互功能(如登录请求...) /login /register
std::string _args;//参数(如果使用GET方法,参数会被设置到_uri上)
};
//Http应答格式
class HttpResponse{
public:
HttpResponse()
:_blank_line(line_break),
_http_version("/HTTP/1.0")
{}
~HttpResponse(){}
std::string Serialize(){
std::string status_line = _http_version + space +
std::to_string(_status_code) + space + _code_description + line_break;
std::string head_line;
for(auto& head : _headers){
std::string oneline = head.first + headers_sep + head.second + line_break;
head_line += oneline;
}
return status_line + head_line + _blank_line + _text;
}
//今天来讲,反序列化Response是客户端做 -> 浏览器做,我们不需要写
bool DeSerialize(){return true;}
void SetTargetFile(const std::string target_file){
_target_file = target_file;
}
void SetCodeAndDesc(int code){
_status_code = code;
switch(code){
case 404:
_code_description = "Not Found";
break;
case 200:
_code_description = "OK";
break;
case 301:
_code_description = "Moved Permanently";
break;
case 302:
_code_description = "See Other";
break;
default:
break;
}
}
std::string UriToSuffix(const std::string uri){
auto pos = uri.rfind(".");
if(pos == std::string::npos) return "text/html";
std::string suffix = uri.substr(pos);
MimeTypes mime;
return mime.getMimeType(suffix);
}
void SetHeaders(const std::string& key, const std::string& value){
if(_headers.find(key) != _headers.end()) return;
_headers.emplace(key, value);
}
bool MakeResponse(){
bool res = Util::ReadFileContent(_target_file, &_text);
int text_size = 0;//正文长度,后序设置长度Content-Length
if(!res){
#ifdef TWO
//这里可以尝试试用一下重定向的方式,设置状态码301 / 302
//SetCodeAndDesc(301); //永久重定向
SetCodeAndDesc(302); //短暂重定向
SetHeaders("Location", "/404.html");
#endif
#define ONE
#ifdef ONE
LOG(LogLevel::DEBUG) << "client want get" << _target_file << "but not found";
_text = "";
SetCodeAndDesc(404);
_target_file = webroot + "/" + page_404;
text_size = Util::GetFileSize(_target_file);
Util::ReadFileContent(_target_file, &_text);
//此时读到了内容(404page)就放到正文内了!
//然后需要设置一些字段进入到报头中(这里就先只设置两个)
std::string content_type = UriToSuffix(_target_file);
SetHeaders("Content-Type", content_type);
SetHeaders("Content-Length", std::to_string(text_size));
#endif
}
else{
LOG(LogLevel::DEBUG) << "client read form: " << _target_file;
SetCodeAndDesc(200);
text_size = Util::GetFileSize(_target_file);
std::string content_type = UriToSuffix(_target_file);
SetHeaders("Content-Type", content_type);
SetHeaders("Content-Length", std::to_string(text_size));
}
return true;
}
void SetText(std::string& text){_text = text;}
//为了方便服务端使用,这里的应答相关字段就用public修饰了。要不然进行修改的时候很麻烦!
public:
std::string _http_version;
int _status_code;
std::string _code_description;
std::unordered_map<std::string, std::string> _headers;
std::string _blank_line;
std::string _text;
std::string _target_file;
//要访问的资源 -> 以便后序方便输入正文!
};
using http_route_t = std::function<void(HttpRequest&, HttpResponse&)>;
class Http{
public:
Http(uint16_t port)
:_server(std::make_unique<TcpServer>(port))
{}
~Http(){}
bool RegisterRoute(std::string func_name, http_route_t func){
//如(/login, Login)
func_name = webroot + func_name; //./wwwroot/login
if(_route.find(func_name) == _route.end()){
//该任务不存在于表中 -> 可以插入 //这里就规定,插入的名字就是传入func的对应的小写
auto it = _route.emplace(func_name, func);
return it.second;
}
return false;
}
//这里就默认都是找的到的!
bool AnalyseRequestLine(std::string& reqline, const std::string& key, std::string* value){
//从请求行报文中,根据key读取对应的value
size_t key_pos = reqline.find(key);//key_pos为key字符子串的起始位置
if(key_pos == std::string::npos) return false;
size_t value_pos = key_pos + key.size() + headers_sep.size();//value_pos为value字符子串的起始位置
size_t value_end = reqline.find(line_break, value_pos);//从value_pos开始找"\r\n"
if(value_end == std::string::npos) return false;
*value = reqline.substr(value_pos, value_end - value_pos);
return true;
}
bool ReadAllRequestHeader(std::string& inbuffer, std::string* text){
//我们已经有了从一个大字符串中,切割字符串的能力了
//这里的大报文都是以"\r\n"作为分割的,我们读取的时分隔符前面的
//所以,我们可以一直读取,直到读到空行了,能得到完整的报头!
//header内有一个属性:Content-length,其存储的时正文的长度!
std::string oneline;
//报文可能有若干情况:
//四分之一条,半条、一整条,多条...
//但是,今天是一个客户端对应一个进程 -> 发送来多条那就可能是客户端多次请求
//这里一次只弄一条出来!
while(Util::ReadOneLine(inbuffer, &oneline, line_break)){
//只要为真,就说明还有"\r\n"可以读到,就还有机会出现空格
*text += oneline + line_break;
if(oneline == "") return true;
oneline.clear();
}
return false;
}
//这里不写死循环了,只做短服务
void HandleHttpRequest(std::shared_ptr<Socket> socket, const InetAddr& client){
//大概率是能读到至少一个完整报文的!
std::string readbuffer;
int n = socket->Recv(&readbuffer);
//但是,这里怎么能够保证报文的完整性呢? -> 在Netcal那里实现过,这里模拟一下
//这里只需要实现Decode即可,因为前面已经有一堆的字段了(已经具备Encode了)!(有效载荷在blank_line后面)
if(n > 0){
LOG(LogLevel::DEBUG) << client.GetFormatStr() << ": 发送来一个请求报文";
//首先,得保证读到完整的请求->如果这一次没能成功读到完整请求,就不进行处理了!
std::string all_reqline;
if(ReadAllRequestHeader(readbuffer, &all_reqline) == false) return;
//读到完整的请求报头 -> all_reqline
//all_reqline里面有一个字段是指向正文长度的(前提是,Http请求中,正文部分长度 > 0,要不然其实是看不到的!)
//如果发送来的正文长度 == 0,看不到这个字段!
std::string text_len;
if(AnalyseRequestLine(all_reqline, "Content-Length", &text_len) == false) text_len = "0";
//成功读取长度到text_len -> 需要转成整数
int len = std::stoi(text_len);
//读取正文(从readbuffer中, 长度为len)
if(readbuffer.size() < len) return; //正文长度不对!
std::string text = readbuffer.substr(0, len);
std::string req_str = all_reqline + text;
//反序列化
HttpRequest hreq;
hreq.DeSerialize(req_str);
//应答对应的协议结构
HttpResponse hresp;
//今天这里加多一步,反序列化后,就需要知道当前是否需要进行交互了
if(hreq.Is_Interact()){
//需要进行交互
std::string service_name = hreq.GetUri();
//但是,这个服务可能不存在于_route表中
if(_route.find(service_name) == _route.end()){
//重定向到对应的404网页
hresp.SetCodeAndDesc(301);
hresp.SetHeaders("Location", "/404.html");
socket->Send(hresp.Serialize());
}
else{
_route[service_name](hreq, hresp);
std::string res_str = hresp.Serialize();
socket->Send(res_str);
}
return;
}
//如果不需要进行交互访问,只访问静态资源,就走原来的逻辑!
//分析请求 + 制作应答
//反序列化的时候,已经把要访问的web根目录底下的文件进行处理了!
hresp.SetTargetFile(hreq.GetUri());
hresp.MakeResponse();
//应答进行序列化
std::string resp_str = hresp.Serialize();
//发送应答
socket->Send(resp_str);
}
//用来测试是否能读到报文并反序列化
/* HttpRequest req;
req.DeSerialize(readbuffer); */
}
void HttpServerInit(){
_server->Init();
}
void HttpServerStart(){
_server->Run([this](std::shared_ptr<Socket> socket, const InetAddr& client){
this->HandleHttpRequest(socket, client);
});
}
private:
std::unique_ptr<TcpServer> _server;
std::unordered_map<std::string, http_route_t> _route;
};
Util.hpp:
#pragma once
#include <fstream>
#include "Common.hpp"
#include "Log.hpp"
using namespace myLog;
//用来实现一些常用的方法 -> 全是静态成员函数
class Util{
public:
//从字符串str中,读取出sep前面的串(不包含sep!!!!!),带出去给outbuffer
static bool ReadOneLine(std::string& str, std::string* outbuffer, const std::string sep){
size_t pos = str.find(sep);
if(pos == std::string::npos) return false;
else{
*outbuffer = str.substr(0, pos);
str.erase(0, pos + sep.size());
return true;
}
}
//获取某个文件的大小
static int GetFileSize(const std::string& file_path){
std::ifstream in(file_path, std::ios::binary);
if(!in.is_open()) return -1;
in.seekg(0, in.end);
int filesize = in.tellg();
in.seekg(0, in.beg);
in.close();
return filesize;
}
//以二进制方式,把文件内的内容以字节流方式读取出来!!!
static bool ReadFileContent(const std::string& file_path, std::string* out){
//这里不能单纯的使用文本读取!应当使用二进制读取 -> 因为可能有图片,有视频...这些都是二进制的
std::ifstream in(file_path);
if(!in.is_open()) return false;
//这个时候就知道,大致有多少二进制数据要被读取出来了 -> 可以获取文件的字节数
int readsize = GetFileSize(file_path);
if(readsize <= 0) return false;
out->resize(readsize);
//使用二进制读取
in.read((char*)out->c_str(), readsize);
in.close();
return true;
}
private:
};
//这里搞多一个类,以便于Content-Type字段使用
class MimeTypes {
private:
std::unordered_map<std::string, std::string> mimeTypes;
public:
MimeTypes() {
// 初始化常用 MIME 类型
// 文本类型
mimeTypes[".txt"] = "text/plain";
mimeTypes[".html"] = "text/html";
mimeTypes[".htm"] = "text/html";
mimeTypes[".css"] = "text/css";
mimeTypes[".js"] = "text/javascript";
mimeTypes[".csv"] = "text/csv";
mimeTypes[".xml"] = "text/xml";
// 图像类型
mimeTypes[".jpg"] = "image/jpeg";
mimeTypes[".jpeg"] = "image/jpeg";
mimeTypes[".png"] = "image/png";
mimeTypes[".gif"] = "image/gif";
mimeTypes[".svg"] = "image/svg+xml";
mimeTypes[".webp"] = "image/webp";
mimeTypes[".ico"] = "image/x-icon";
// 应用程序类型
mimeTypes[".json"] = "application/json";
mimeTypes[".pdf"] = "application/pdf";
mimeTypes[".zip"] = "application/zip";
mimeTypes[".doc"] = "application/msword";
mimeTypes[".docx"] = "application/vnd.openxmlformats-officedocument.wordprocessingml.document";
// 多媒体类型
mimeTypes[".mp3"] = "audio/mpeg";
mimeTypes[".ogg"] = "audio/ogg";
mimeTypes[".mp4"] = "video/mp4";
mimeTypes[".mov"] = "video/quicktime";
mimeTypes[".avi"] = "video/x-msvideo";
// 字体类型
mimeTypes[".woff"] = "font/woff";
mimeTypes[".woff2"] = "font/woff2";
mimeTypes[".ttf"] = "font/ttf";
mimeTypes[".otf"] = "font/otf";
}
// 根据文件扩展名获取 MIME 类型
std::string getMimeType(const std::string& fileExtension) const {
auto it = mimeTypes.find(fileExtension);
if (it != mimeTypes.end()) {
return it->second;
}
// 默认返回二进制流类型
return "application/octet-stream";
}
// 添加自定义 MIME 类型
void addMimeType(const std::string& fileExtension, const std::string& mimeType) {
mimeTypes[fileExtension] = mimeType;
}
};
今天的调用逻辑是:
Http类底层包含着一个TCP服务器,今天我们就写一个短连接服务!
每次接收到一个请求,我们就让TCP服务器回调Http类中的HandleHttpRequest
方法,这样子,就完成了服务器端和应用层的解耦!
HandleHttpRequest接收请求,然后对其反序列化、分析、制作应答、序列化后在发送给客户端浏览器进行解析展示即可!
到这里,我们就想要做一件事情:看一下真正的http request到底是长什么样子:
启动服务器,然后再浏览器的URL搜索框中输入:服务器主机ip:绑定端口号
(其实就是直接把服务器从套接字收到的字节流提取出来然后打印!)这个我没有在展示的代码中体现,自己加上去看一下就可以了!
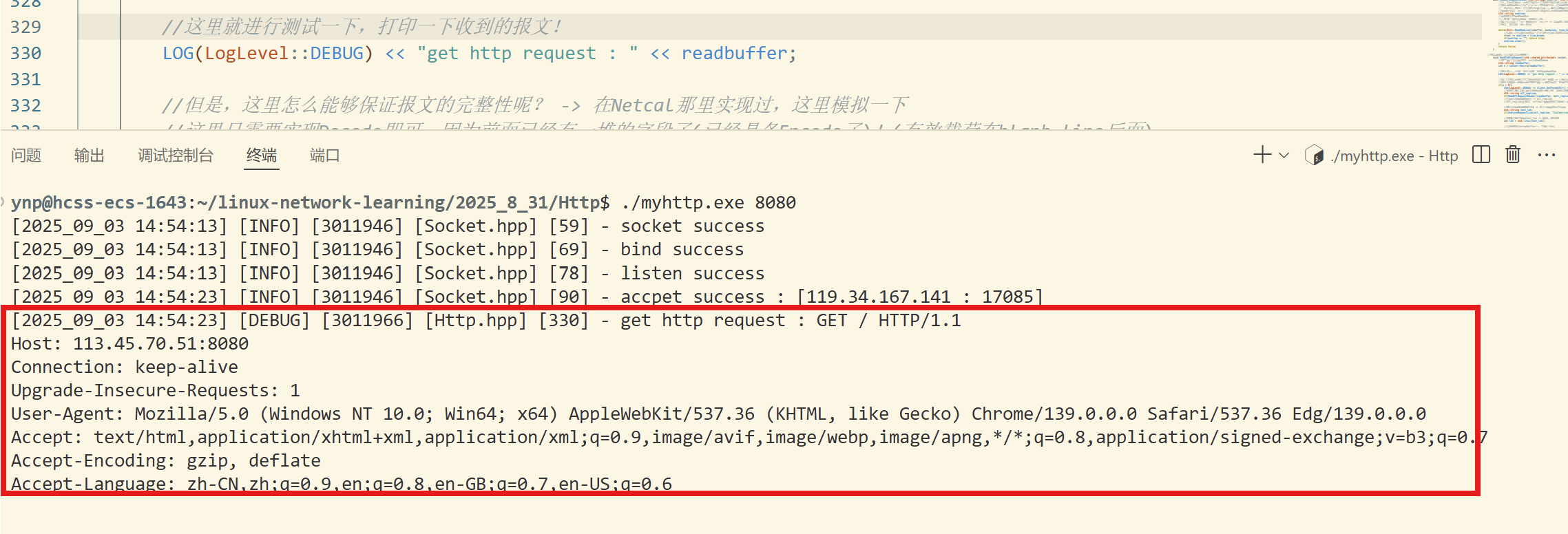
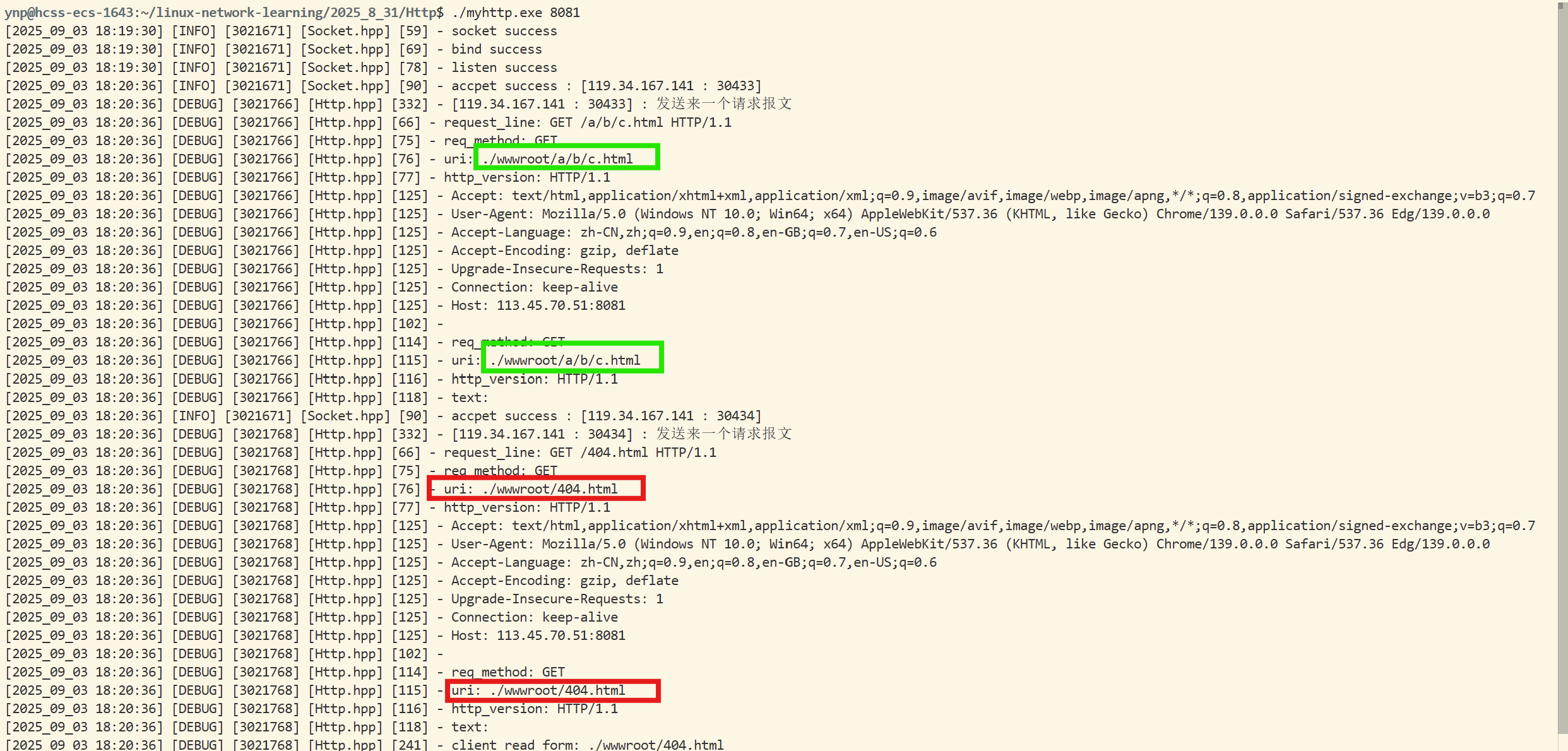
我们可以发现,确实是有这么样的一个请求协议:
GET / HTTP/1.1
Host: 113.45.70.51:8080
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
注意,这里操作的方式并没有通过客户端向服务器传输资源,所以正文部分是空的,所以,我们可以看到打印出来是有两行的空行的!
第一行是请求行,中间以空格作为分隔符。
中间就是以key&value形式的键值对,就是相关的报头属性!
空行作为完整请求报头和有效载荷的分割符号。
这里正文是空的,所以看起来也是空行!
至此,我们就切实感受到了协议是长什么的!后序,我们将根据我们对协议的认识,以及HTTP协议的原理,来进行相关代码编写和结论的认证!
http request的请求行——URI
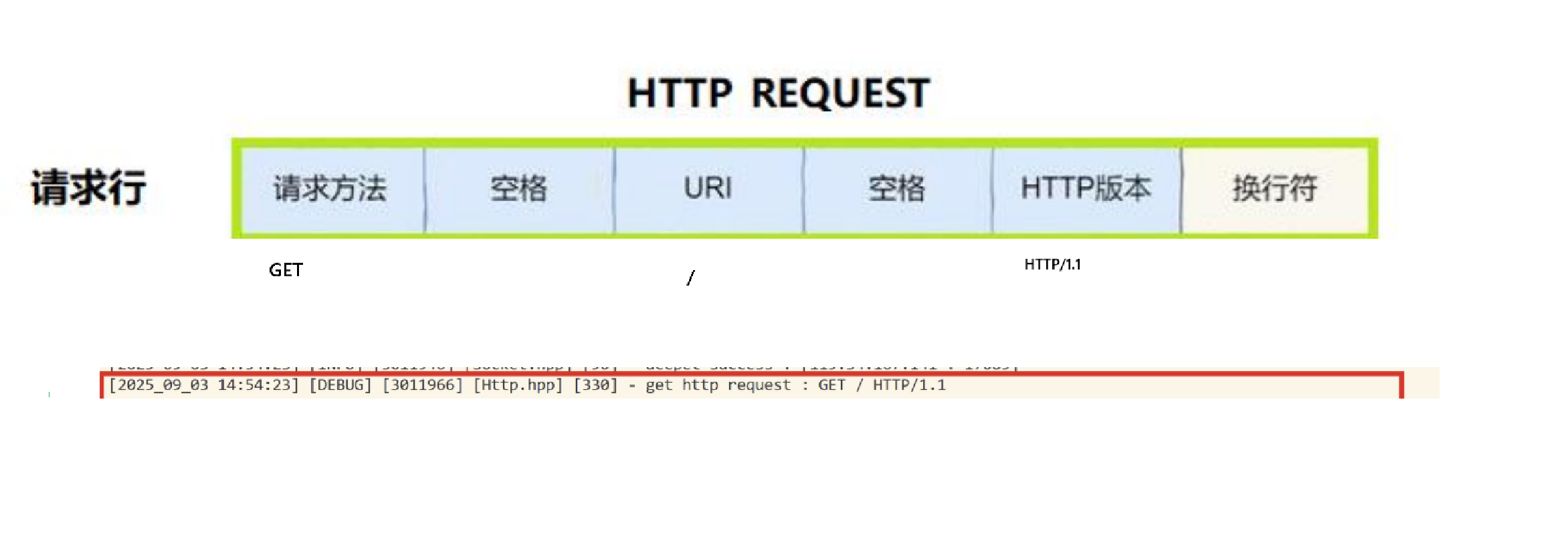
这里我们先不讲请求方法,也先不讲HTTP版本,这些都是客户端发来的。这些我们后序一开始写代码的时候不用太过关注。
但是,请求行的第二个位置,URI,这是一个非常重要的部分!
URI就是我们前面所说的:一个带有层次的文件路径。
这里就是单纯的一个/,前面说了,这个访问的是web根目录,是什么意思呢?
我这里直接展示我的代码结构了,一看就明白:

所以,这里的URI就是我们当前服务器中,存储资源的目录!
后序,我们将让AI形成若干网页,我们就可以实现通过浏览器来访问我们自己的服务器了。
使用浏览器完成静态资源的访问
我们需要先来了解一下,什么是静态资源?
比如我们今天存放在服务器指定目录下的文本、音频、网页,这些都是静态资源!这些是不涉及客户端和服务端的动态交互的。就是申请对应的资源并返回。
我们先把静态资源访问的逻辑写完,到时候再来补充动态交互的内容(如登录、注册)!
我们今天就实现简单地短服务!即底层的TCP服务器,accept到一个客户端后,回调处理对应的请求,然后就结束,关闭套接字!下次客户端要访问就得重新connect!
代码主逻辑:
void HandleHttpRequest(std::shared_ptr<Socket> socket, const InetAddr& client){
//大概率是能读到至少一个完整报文的!
std::string readbuffer;
int n = socket->Recv(&readbuffer);
//但是,这里怎么能够保证报文的完整性呢? -> 在Netcal那里实现过,这里模拟一下
//这里只需要实现Decode即可,因为前面已经有一堆的字段了(已经具备Encode了)!(有效载荷在blank_line后面)
if(n > 0){
LOG(LogLevel::DEBUG) << client.GetFormatStr() << ": 发送来一个请求报文";
//首先,得保证读到完整的请求->如果这一次没能成功读到完整请求,就不进行处理了!
std::string all_reqline;
if(ReadAllRequestHeader(readbuffer, &all_reqline) == false) return;
//读到完整的请求报头 -> all_reqline
//all_reqline里面有一个字段是指向正文长度的(前提是,Http请求中,正文部分长度 > 0,要不然其实是看不到的!)
//如果发送来的正文长度 == 0,看不到这个字段!
std::string text_len;
if(AnalyseRequestLine(all_reqline, "Content-Length", &text_len) == false) text_len = "0";
//成功读取长度到text_len -> 需要转成整数
int len = std::stoi(text_len);
//读取正文(从readbuffer中, 长度为len)
if(readbuffer.size() < len) return; //正文长度不对!
std::string text = readbuffer.substr(0, len);
std::string req_str = all_reqline + text;
//反序列化
HttpRequest hreq;
hreq.DeSerialize(req_str);
//应答对应的协议结构
HttpResponse hresp;
//分析请求 + 制作应答
//反序列化的时候,已经把要访问的web根目录底下的文件进行处理了!
hresp.SetTargetFile(hreq.GetUri());
hresp.MakeResponse();
//应答进行序列化
std::string resp_str = hresp.Serialize();
//发送应答
socket->Send(resp_str);
}
上述就是主逻辑。很多接口就是完成具体任务的。这里不讲解实现,只讲功能!
1.读取到客户端的报文后,服务器不能立马反序列化!因为没有办法保证当前读到的是一个完整的http request请求报文!所以,我们需要做一步工作,确保读到的报文正确!
如何保证读到的报文完整呢?
1.我们可以先把完整的请求报头读完【空行之前】
2.对读到的报头进行解析!如果说正文长度>0,在中间报头部分会存在:Content-Length: xxx
这个是用来指示正文长度的。如果长度为0可能会不显示!
3.根据Content-Length读取正文长度
这些工作,都放在了接口Http.ReadAllRequestHeader来做!
今天这里规定,一旦发现保温不完整、正文长度不匹配时,我们都不予受理!
2.讲请求行进行分析,读取到正确的正文长度,并提取正文:

这里为了代码更好的复用性,写了一个接口AnalyseRequestLine,即分析请求行。就是把完整的请求行传入,传入要找的key,最后把value带出给text_len!
经过上面的步骤,我们就可以提取正文了,然后就是拼接处完整的http request报文!

3.对http request进行反序列化

这里需要注意有一个_is_interact,这个是表示当前是否交互用的!这里我们不需要管!这个我们放在后面讲解如何进行交互的时候来说。
注意,这里如果URI是单纯的一个/,我们不可能把整个web根目录下的内容返回给客户端,一般来说,这个是在请求首页,就类似于www.baidu.com的搜索框那样!
4.分析对应的请求,制作应答序列化后返回

那么,要访问的资源,或者上传的资源,都是通过MakeResponse这个接口来进行处理!制作好对应的应答。这里是访问静态资源!!!
(制作应答的逻辑就不展示了,总之就是设置好对应的应答协议字段,把资源设置到正文部分(字节流)即可!)
所以,我们让ai生成一点网页,在我们的资源站上放入一些图片:
我们来运行看一下效果:
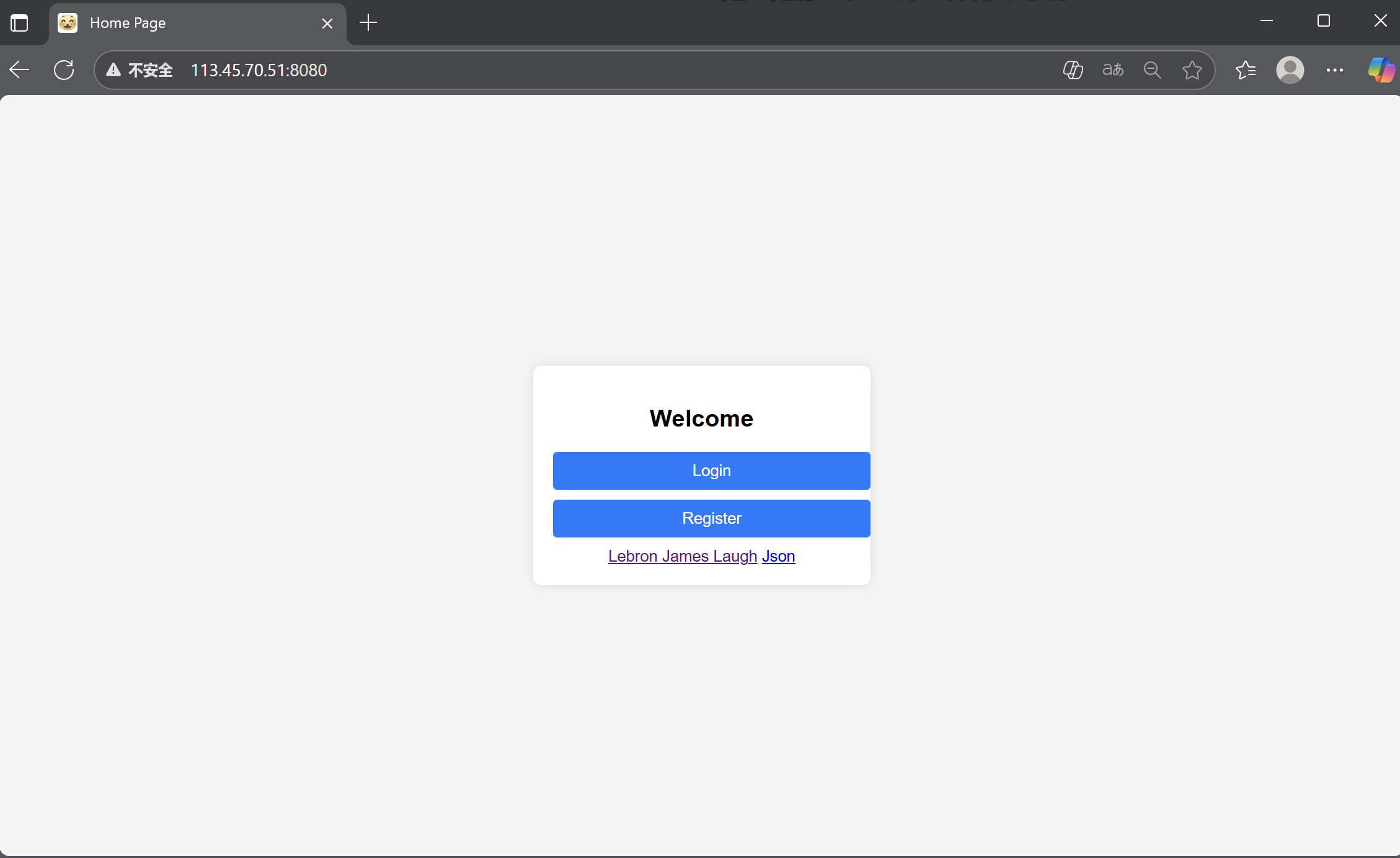
注意,当前路径下有一个favicon.ico文件,这个其实就是图片文件。就像我们打开一个网页,浏览器选项卡左上角的那个小图标:
因为输入对应的ip:端口号访问,其实浏览器不止是申请首页资源(index.html,如果不带任何的路径默认就是访问/,即首页)。同时,浏览器还会申请/favicon.ico资源,就是访问这个小图标。直接网上找一个放在web根目录下即可!
同时,我在首页位置插入了两张图片:
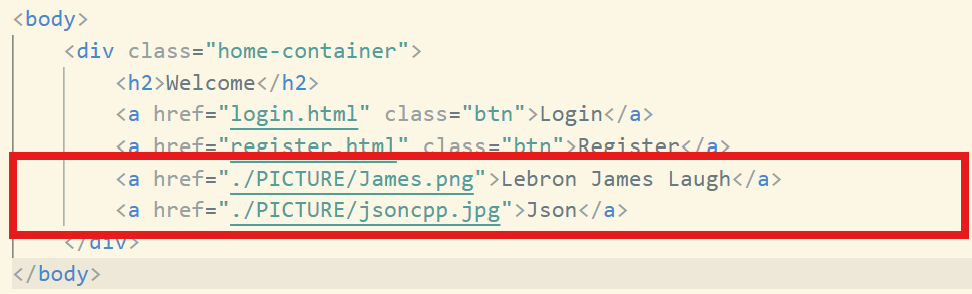
这些是前端的内容,这里就不说了。我们可以到大模型询问使用,或者相关网站:
https://cn.w3schools.com/html/html5_video.asp
常用的报头属性
上述我只是简单地了介绍了,访问服务器静态资源的主要逻辑。并没有说到其中的一些问题:
就是我们今天设置应答的时候,我们是需要返回个别中间报头的!也是常用的。
第一个报头就是Content-Length,这个是指示正文长度的。
也就是今天我们制作应答的时候,返回资源都是放在应答的正文部分,让浏览器去解释。
其实这个报头设置不设置都可以,现在的浏览器很强大,是可以解析出来的。但是可以设置一下,就设置到底层的哈希表中即可。
第二个报头是非常非常重要的!如果不进行设置,会导致一个很严重的问题:
当我们发图片的时候,如果没有设置对应的报头,就会导致浏览器无法显示该图片!
因为有一个报头Content-Type,指示这次发送的资源是什么类型的,这是有常见的转化表的。为了方便使用,定义了一个MimeTypes类进行转化使用:

所以,我们就需要主动的设置报头属性,要不然浏览器解释不了!!!!
还有就是,今天的服务器,只能支持短连接,也就是完成一次请求,服务器处理后就会直接关闭连接。如果说,我们直接把图片,视频等其他资源放到该网页上,服务器是要进行多次请求的。这里就不演示了,知道即可。
但是,我们今天这里全是使用HTML的a标签,这就是一个跳转链接,只有点击它,浏览器会再次进行请求对应的资源。
http response

我们知道,上面是http response的格式。
中间的报头我们已经说了两个了:Content-Length和Content-Type
还有其他的报头,但是我们会放在后面去说。
正文部分就是我们要交给用户端的资源。就是把资源文件以二进制方式读取出来放到正文。
我们最需要了解的就是,第一行状态行!
第一个是服务器版本,我们这里直接默认是HTTP/1.0即可。因为HTTP/1.0使用短连接多,1.1版本才是长连接。这里我们写的是短连接。
这个版本是为了对照服务器和客户端两端版本的。因为有时候一些服务器是没有办法支持过高的标准的,或者服务器不支持一些老标准!所以需要两端版本对照!
第二三个可以一起说,状态码和描述,这是什么意思?
其实就是当前服务器处理请求的时候,可能会出现一些问题,又或是一些特殊的处理方式。这个时候,就有可能需要向客户端返回当前处理的状态!
最常见的就是:404 Not Found!
状态码
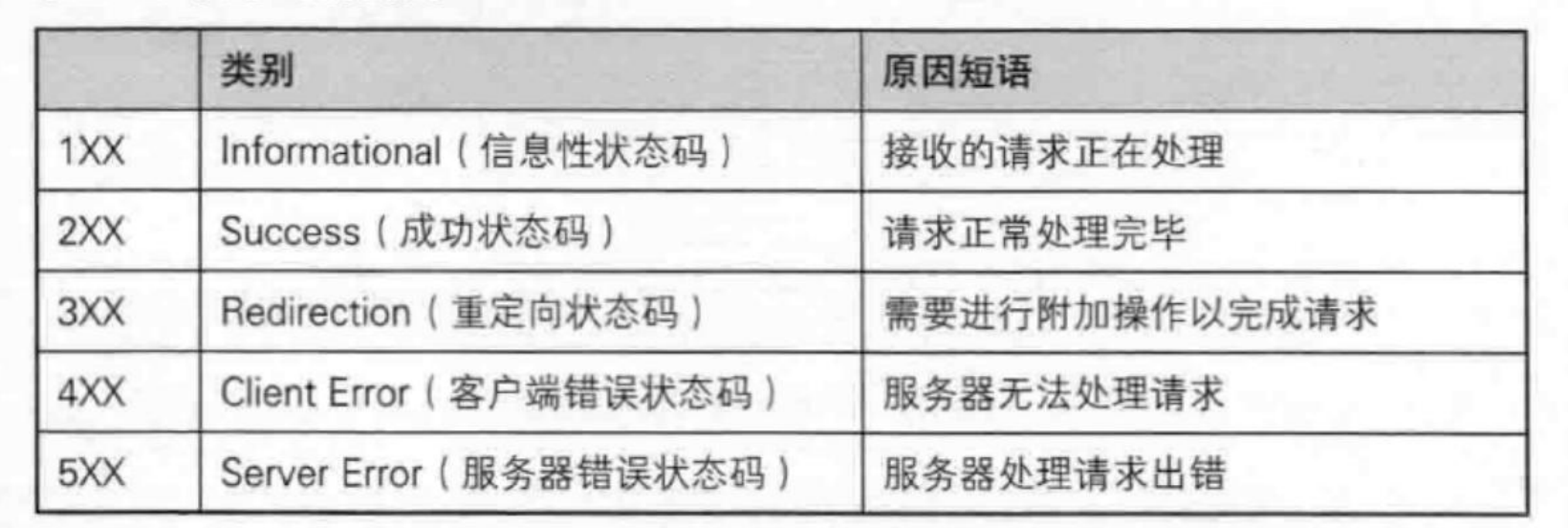
1开头的就是可能当前服务器还在处理客户端发来的请求。
2开头的一般都是处理请求成功
3重定向,这个我们需要好好了解一下。比如我们有时候可以发现,我们访问一个网站,突然换网址了,需要我们跳转到另外一个网站,这就是简单地重定向!
又比如我们在某些app里面的摇一摇跳转,这也是属于重定向!
当然,第三点也不止局限于这里。也有可能是某些服务器不是真正提供服务的,可能是代理服务器。就是客户端向该代理服务器发送请求,服务器会返回重定向的网址和信息给客户端,此时浏览器一旦接收到重定向的信息,就会立马再次向新的服务器申请服务!
4开头表示的是客户端错误!比如最常见的404,找不到资源。
5.这个表示的是服务器的错误,比如服务器过载、进程创建失败等。
但是,这里要说的是,其实很多公司内部是对于返回状态码是写的比较随意的。特别像是5开头的,如果返回这个错误码,就等同于告诉外界公司服务器的软肋了!所以,有可能有时候服务器错误返回200都是有可能的事情。
重定向
我们需要来重点了解一下重定向:
| 状态码 | 状态短语 | 说明 |
|---|---|---|
| 300 | Multiple Choices | 请求的资源有多个选择,用户或浏览器需要选择其中一个进行访问。 |
| 301 | Moved Permanently | 请求的资源已永久移动到新位置,未来所有请求应使用新URI。 |
| 302 | Found | 请求的资源临时从不同URI响应请求,客户端应继续使用原始URI。 |
| 303 | See Other | 对当前请求的响应可以在另一个URI找到,且必须使用GET方法获取。 |
| 304 | Not Modified | 资源未修改(用于缓存重定向),客户端可以继续使用缓存的版本。 |
| 307 | Temporary Redirect | 临时重定向,与302类似,但明确要求方法和主体不能更改。 |
| 308 | Permanent Redirect | 永久重定向,与301类似,但明确要求方法和主体不能更改。 |
我们就举两个例子来说:
301 Moved Permanently 请求的资源已永久移动到新位置,未来所有请求应使用新URI。
302 Found/See Other 求的资源临时从不同URI响应请求,客户端应继续使用原始URI。
这两个其实真正使用起来,区别是不大的。但是我们还是要讲解一下他们的区别:
| 状态码 | 类型 | 搜索引擎行为 | 浏览器行为 | 形象比喻 |
|---|---|---|---|---|
| 301 | 永久重定向 | 更新权重到新URL | 缓存跳转,后续直接访问新地址 | “永久搬家” |
| 302 | 临时重定向 | 保留原URL权重 | 每次访问都重新跳转 | “临时借住” |
关键区别:
- 永久性:301是永久变更,302是临时变更
- SEO影响:301转移权重,302保留原权重
- 缓存行为:301会被浏览器缓存,302每次重新跳转
| 类型 | 工作流程 | 缓存机制 |
|---|---|---|
| 301 | 1. 客户端首次请求 → 服务器返回301和新地址 2. 浏览器自动缓存该重定向 3. 后续所有请求直接跳转新地址(不再询问服务器) |
永久缓存(直到清除浏览器缓存) |
| 302 | 1. 每次请求 → 服务器都返回302和新地址 2. 浏览器不会缓存重定向 3. 每次都要完整走请求流程 |
不缓存 |
重定向使用效果
其实重定向的方式有很多种,但是真正使用起来是肉眼看不出区别的:
在HttpResponse的MakeResponse接口中,我们对于找不到的内容是做了处理的。即让正文部分返回一个404 Not Found的网页。现在,我们其实也可以直接重定向过去该网页。


其实经过实验,使用301进行重定向或者302都是差不多的!看不出区别。
简单理解重定向的原理
我们需要了解的是,重定向的过程是什么?为什么浏览器能够找到对应的资源进行重定向呢?
其实是因为,在Http Response的Header内,有一个字段叫做:Location: xxx。
这个是要配合3xx的状态码来进行使用的!
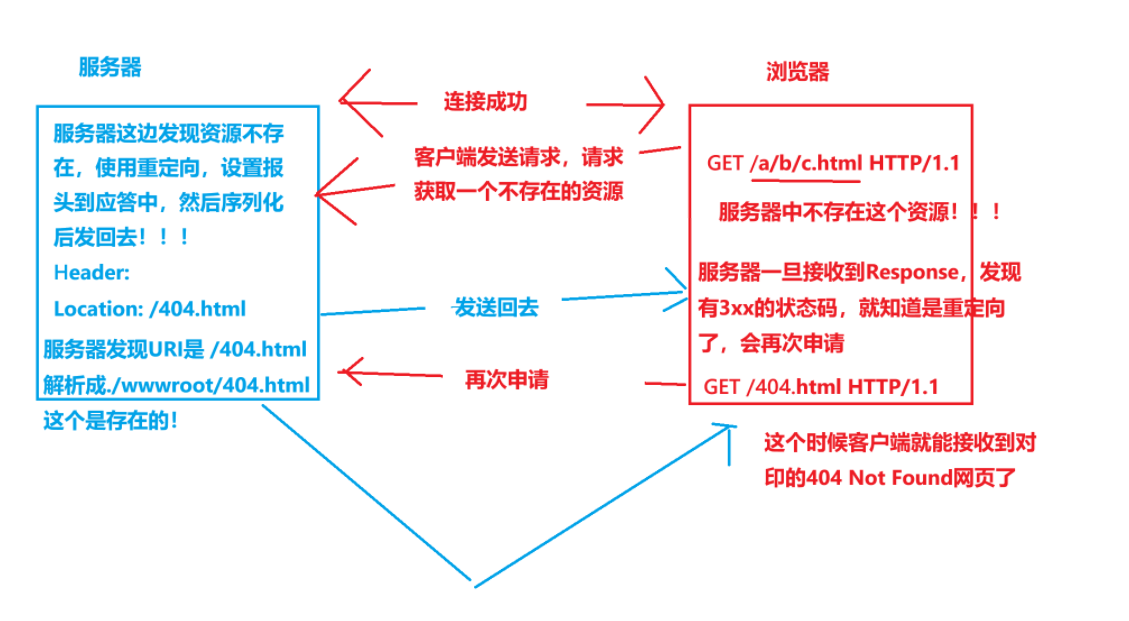
具体的过程如上所示!
理解请求方法
现在,我们需要来理解一下http request中的请求方法。
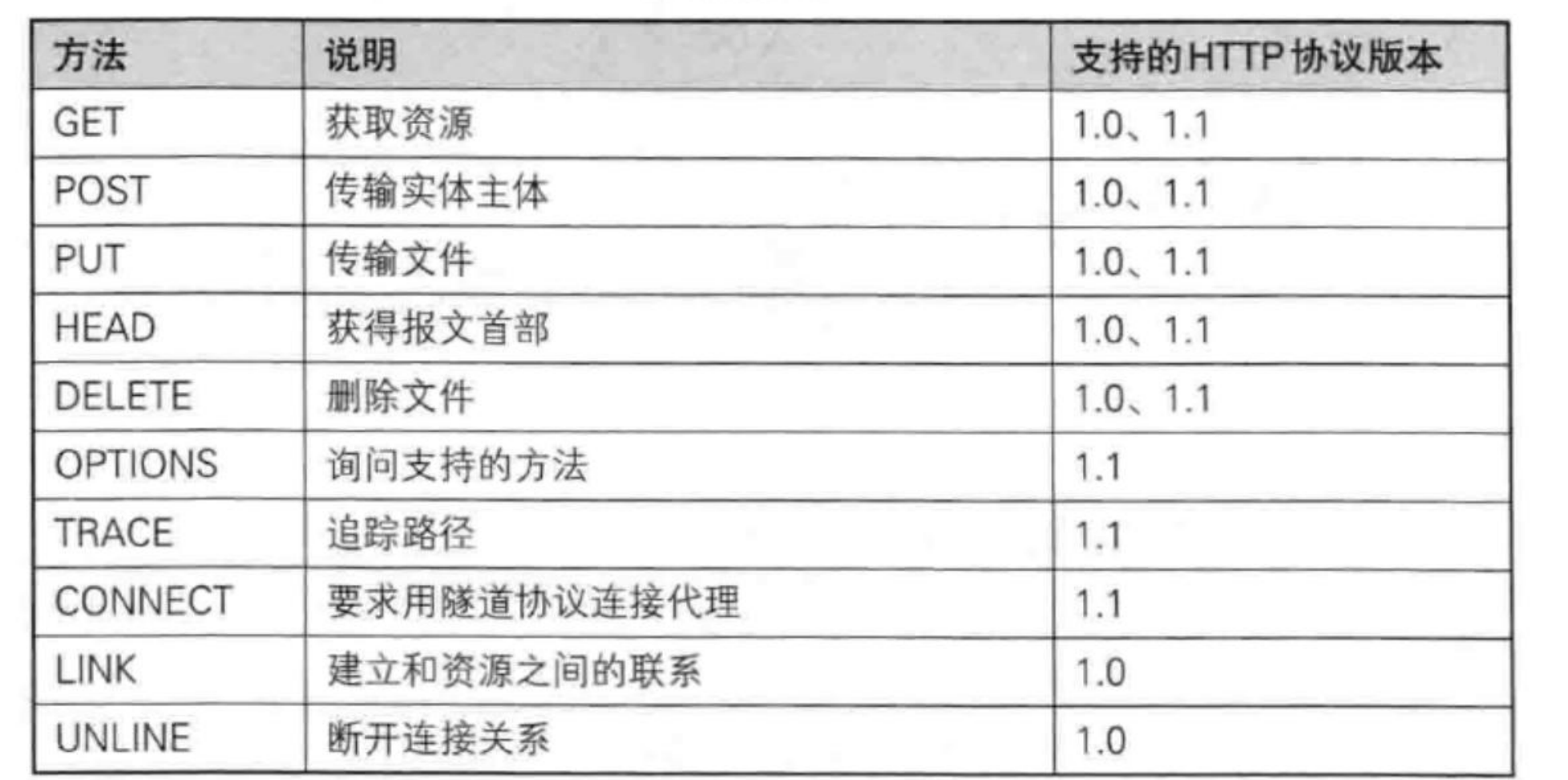
我们先来看最重要的两个:GET / POST。
先直接说区别:
它们二者最大的区别就是,在与服务器进行动态交互的时候,客户端需要提交一些参数。GET方法提交的参数会放在URL,POST方法是放在正文中!
接下来我们来做个实验看,首先我们要知道,如何通过浏览器,从前端传递参数到后端:
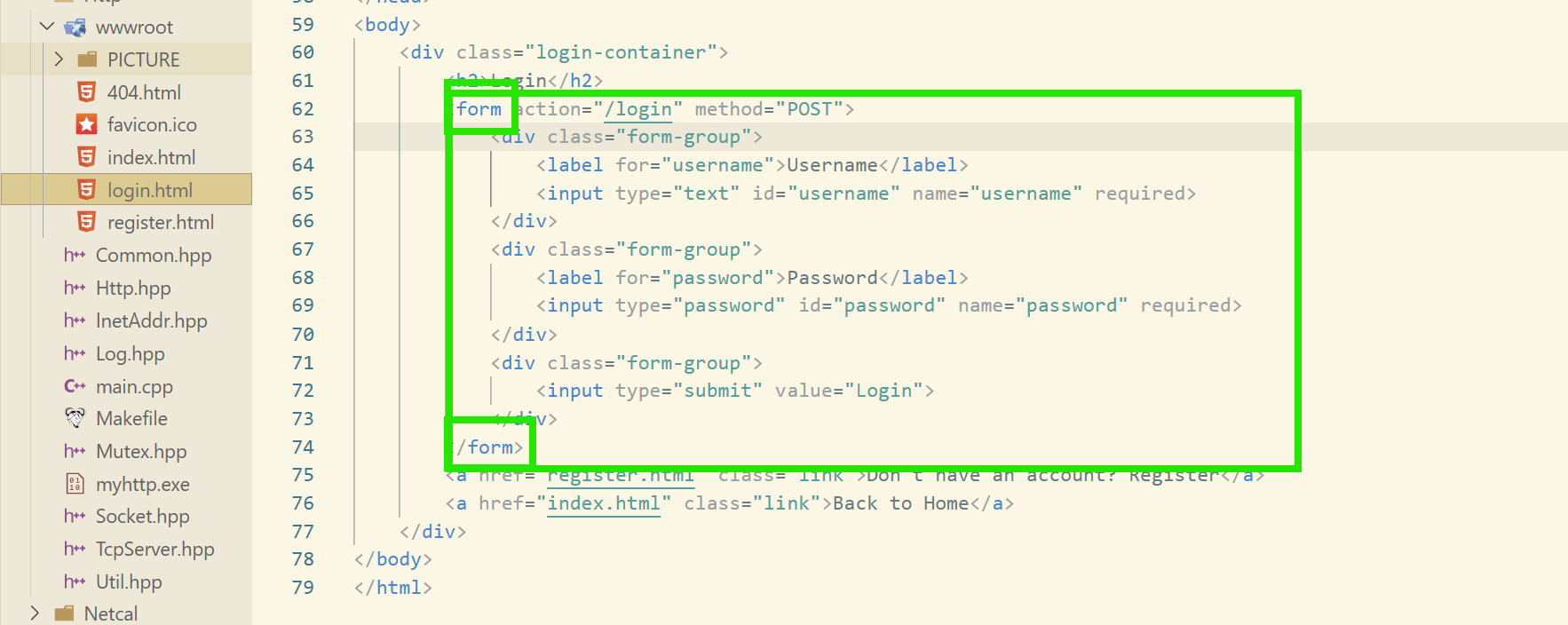
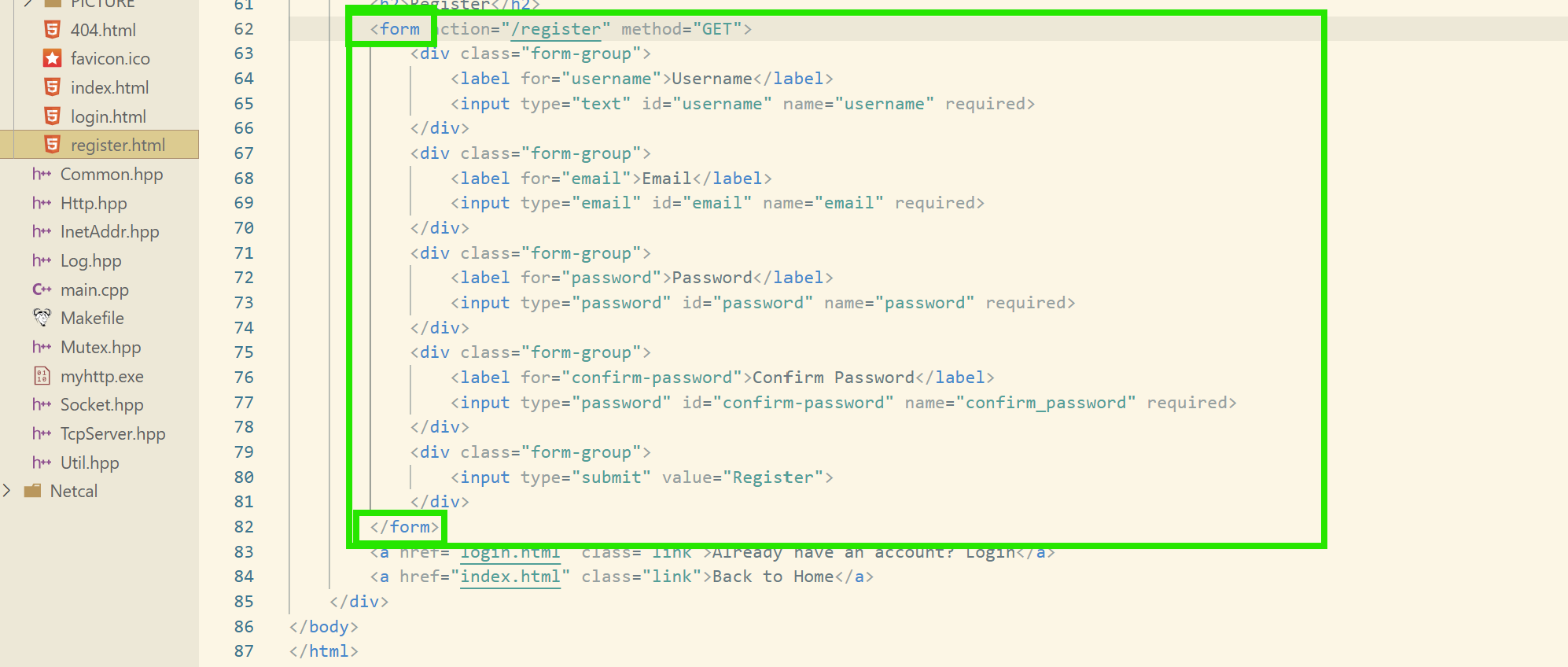
我们看这里ai生成的登录注册网页,使用到了一个叫form表单的东西:
其实,我们在浏览器中的一些登录界面也是使用这个表单的,我们可以看看:
然后,通过这个表单,就可以把输入的参数(如我们这里的账户密码)传送给后端进行验证了!
接下来,我们就以登陆注册模块来看看这两个方法的不同!!!
login和regsiter是类似的这里,我们就拿登录网页来试一下就好了。
(这里需要注意,这种服务一般是需要进行交互的。我们之前说的都是静态资源的获取。所以,对于HTTP来说,需要多一个交互的服务。所以我在HTTP类中加入了一个_route哈希,用来进行检索交互任务的。逻辑其实很简单,看代码是一定能看得懂的。这里就不说代码了,直接上演示结果。)
method = GET:
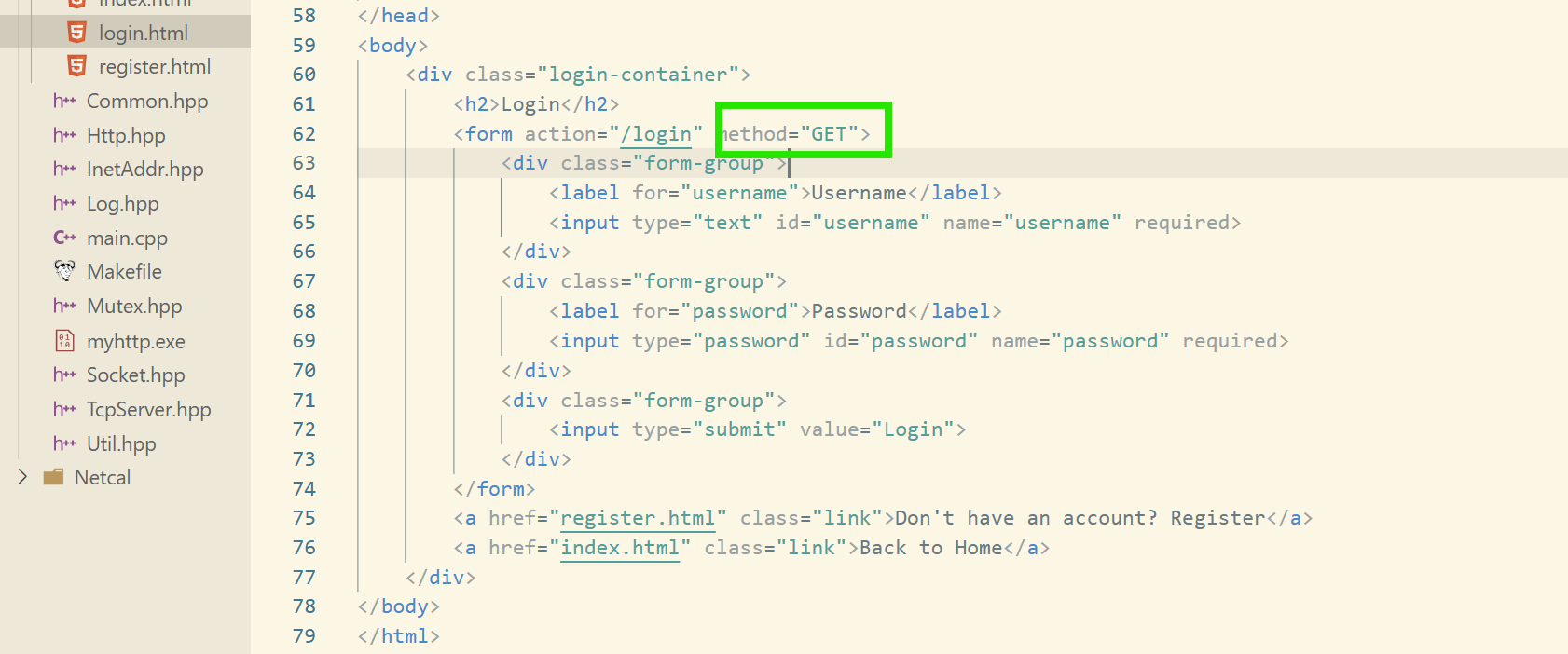
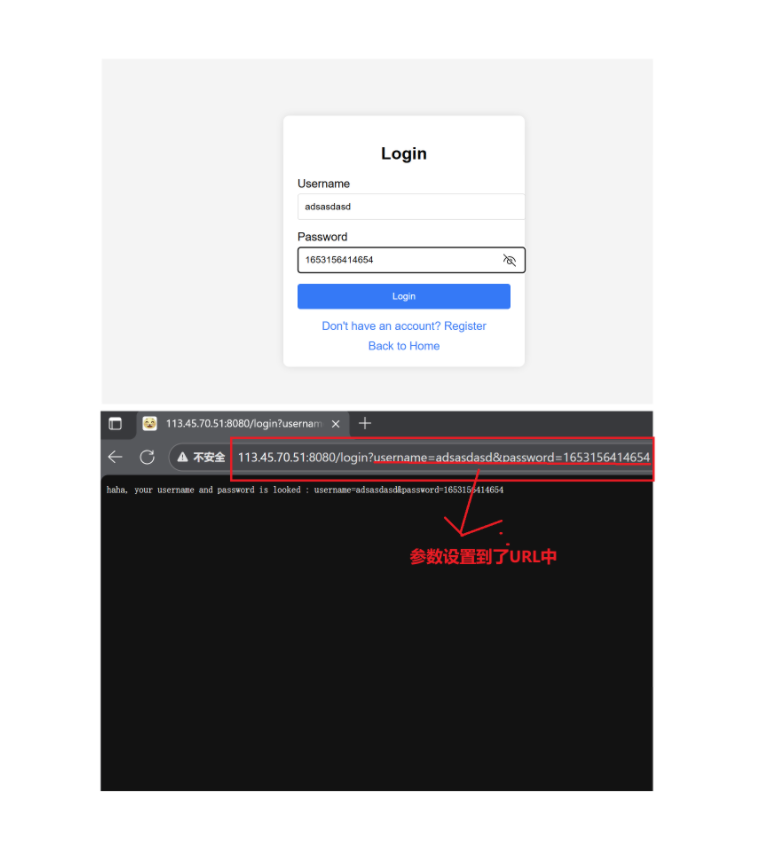
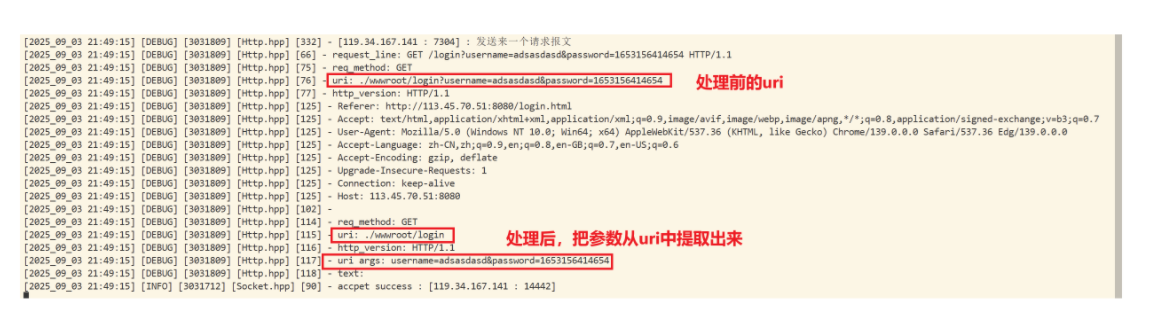
method = POST
我们只需要修改网页即可,服务器是不用重新启动的!因为网页和服务器是互相独立的。
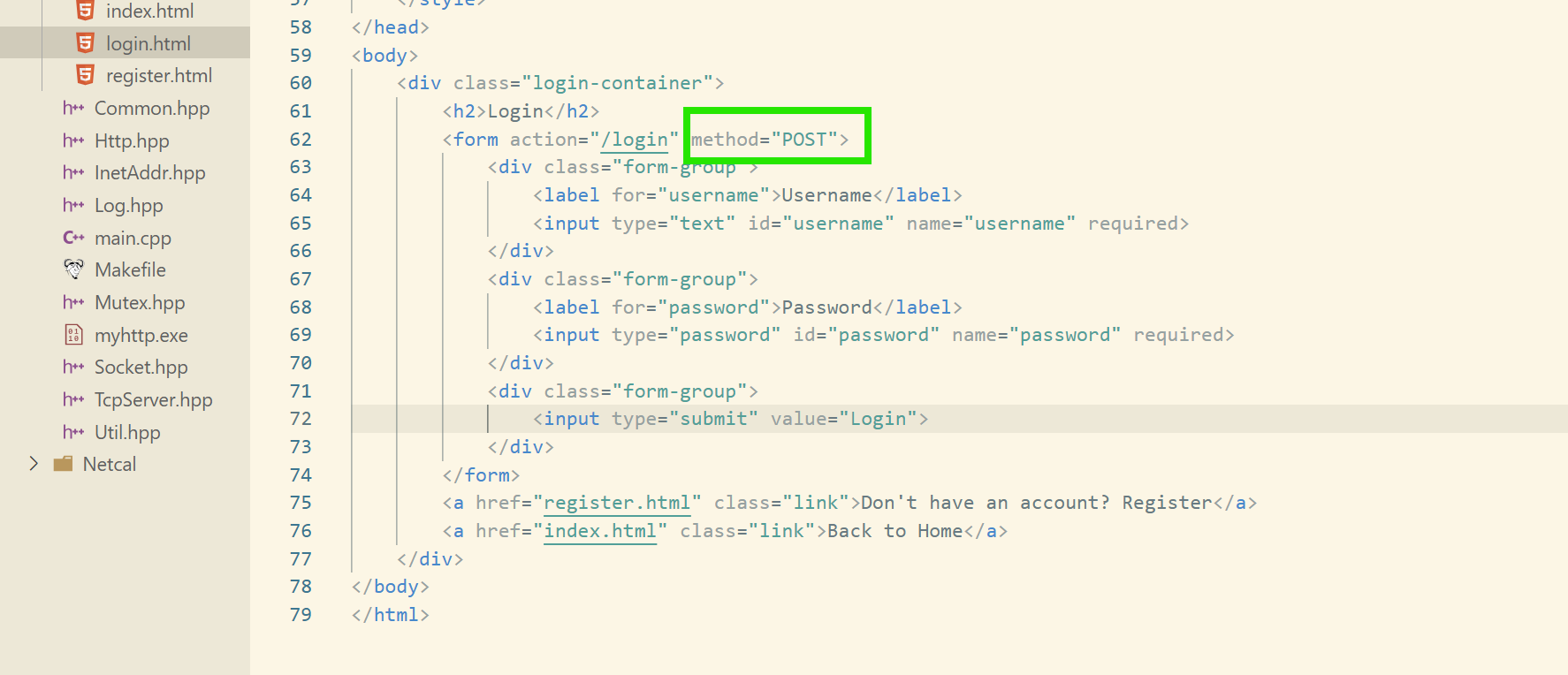
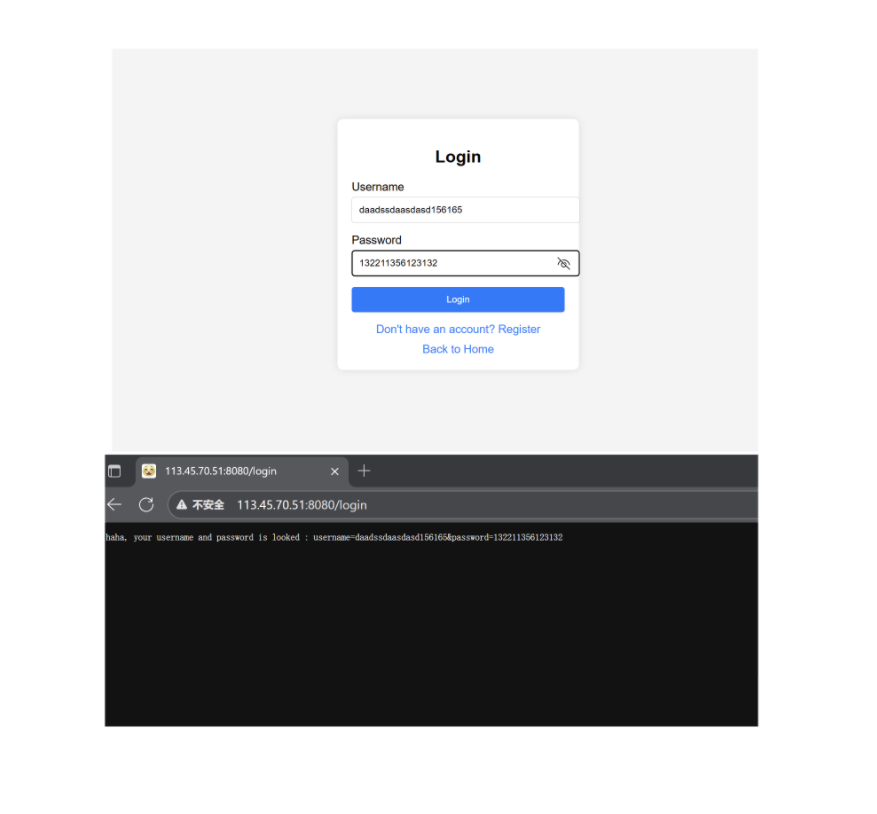
最后我们发现,事实确实如此。二者的区别就是在于传参的不同。
只不过说,一般来说更习惯用GET来进行资源获取,POST来进行参数提交。相对于GET来说,POST把参数(隐私信息)放在正文内,私密性可能更好一些些吧。
但其实,二者这样提交都是不安全的!因为可以被别人抓包,这里推荐使用一款工具叫做fiddler classic,它可以进行抓包!这里就不演示了。
其他方法(选几个进行介绍):
PUT方法:
用途:用于传输文件,将请求报文主体中的文件保存到请求 URL 指定的位置。
示例:PUT /example.html HTTP/1.1
特性:不太常用,但在某些情况下,如 RESTful API 中,用于更新资源。
(常用的是POST或者GET)
DELETE方法:
用途:用于删除文件,是 PUT 的相反方法。
示例:DELETE /example.html HTTP/1.1
特性:按请求 URL 删除指定的资源。
但是,一般来说,DELETE是不被允许的!因为一些公司不希望用户能够随意删除服务器内的一些资源,所以可能会拒绝该请求!
HEAD方法
用途:与 GET 方法类似,但不返回报文主体部分,仅返回响应头。
示例:HEAD /index.html HTTP/1.1
特性:用于确认 URL 的有效性及资源更新的日期时间等。
但是这个方法,也大部分情况是被禁止的!而且也很少用。
OPTION方法
用途:用于查询针对请求 URL 指定的资源支持的方法。
示例:OPTIONS * HTTP/1.1
特性:返回允许的方法,如 GET、POST 等。
HTTP的Header
Content-Type: 数据类型(text/html 等) • Content-Length: Body 的长度
Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
User-Agent: 声明用户的操作系统和浏览器版本信息;
referer: 当前页面是从哪个页面跳转过来的;
Location: 搭配 3xx 状态码使用, 告诉客户端接下来要去哪里访问;
Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
Cookie我们放在后序的cookie和session话题来讲解。
这里需要讲一下connection报头相关的内容。
我们今天写的HTTP协议通信,是短连接的。也就是,客户端发送来一个请求,服务端处理完该请求后,然后立马断开连接。如果服务端还有内容要申请,那就需要继续请求!
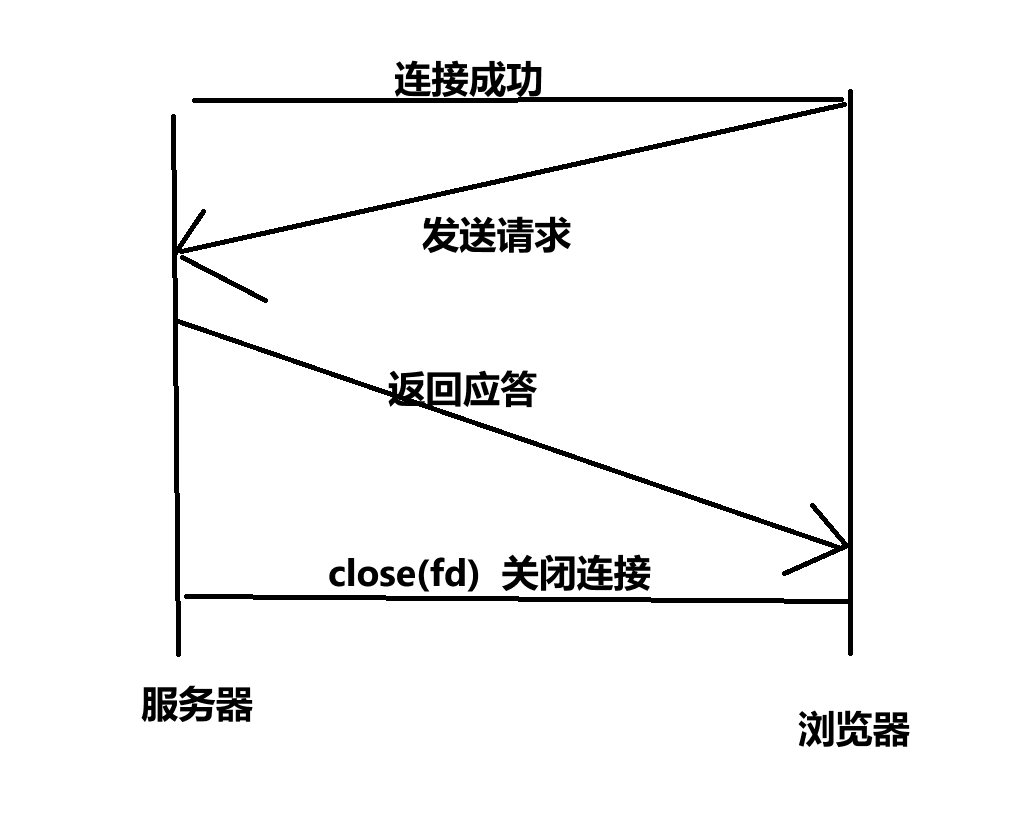
这种是短服务!也就是服务器一次只处理一个请求。这种在早期的HTTP/1.0协议中用的比较多。因为早期的HTTP协议中,一个网页内是没有像现在这样如此多的资源的。
但是,如果像是今天的浏览器中的一张网页,有大量的连接、视频、图片…如果还是采用短连接的方式,那么光是申请一张网页,服务器就要不断地进行:连接、创建子进程/线程,处理、关闭连接。更何况,建立连接也不是没有成本的!
所以这就导致,如果对于一些资源比较多的网页来讲,使用短连接的服务肯定是不行的!所以,在HTTP/1.1协议后,就引入了这么一个报头:connection。
HTTP 中的 Connection 字段是 HTTP 报文头的一部分,它主要用于控制和管理客户端与服务器之间的连接状态。可以做到管理持久连接:Connection 字段还用于管理持久连接(也称为长连接)。持久连接允许客户端和服务器在请求/响应完成后不立即关闭 TCP 连接,以便在同一个连接上发送多个请求和接收多个响应。
语法格式
- Connection: keep-alive:表示希望保持连接以复用 TCP 连接。
- Connection: close:表示请求/响应完成后,应该关闭 TCP 连接。
其实我们自主实现的网络版本计算器,就是长连接形式的!因为服务器是一直在进行服务,不会主动断开与客户端的连接!