今天给大家介绍深度学习中卷积层的工作原理,包括局部连接、权重共享以及卷积操作,强调了卷积核在特征提取中的作用。还讨论了池化层,特别是最大池化和平均池化的效果。激活函数部分提到了Sigmoid、Tanh和ReLU的功能及其优缺点。还简述了Flatten层和全连接层在模型中的作用,全连接层用于将特征综合进行分类。希望对大家学习有帮助!
一、 卷积层
1. 卷积层原理
(1)操作过程:卷积运算又被称为互相关运算,将图像矩阵中,从左到右,从上到下,取与卷积核同等大小的一部分,每一部分中的值与卷积核中的值对应相乘后求和,最后的结果组成一个矩阵。
(2)作用:提取输入的不同特征,通过滑动窗口得到特征图像。
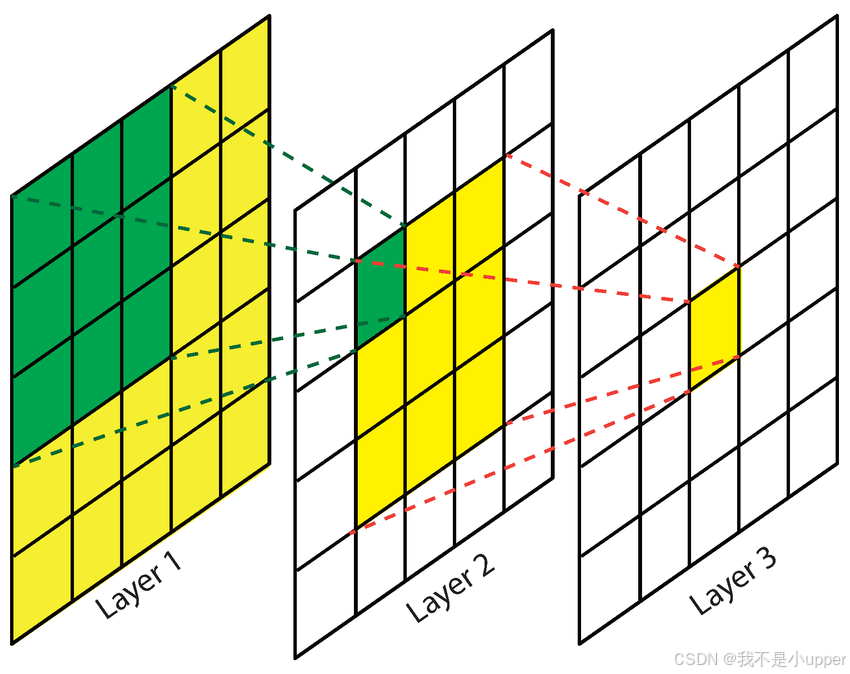
对于图像而言,它能够被分解为低频分量与高频分量。
- 低频分量:对应图像里灰度变化缓慢的区域,像图像中大面积的平坦部分,这类分量在图像里占据主要地位。
- 高频分量:代表灰度变化剧烈的区域,比如图像的边缘以及细节部分,在图像中的占比相对较小。并且,噪声也存在于高频分量当中,这是因为噪声和周围像素点的灰度存在突变,所以能够被观测到。
(3)卷积核的取值对滤出信号的特性有着重要影响:
- 高通滤波:
- 当滤波器为
时,对信号序列
进行卷积操作:
,可近似为信号序列的一阶微分。
- 当滤波器为
时,卷积操作
,能够近似为信号序列的二阶微分。
- 当滤波器为
- 低通滤波:当滤波器为
时,卷积操作
,相当于进行移动平均,从时域角度看是矩形窗,从频域角度看是
函数,反之亦然,用于提取信号的低频分量。
卷积核具有滤波和特征提取的功能,其参数决定了滤波器的性质。 以 Sobel 算子为例,对于 的矩阵
, 将其与输入图像的像素值
进行逐元素相乘并求和,即
,可以得到该图像在竖直方向上的一阶梯度。这个梯度在边缘区域会有较大的值,而在非边缘区域则接近零。
训练完成的神经网络可以看作是一个映射函数,同时也是特征提取器。当卷积核的参数固定时,对于不同类别的两张图片,由众多卷积堆叠而成的特征提取器会对图像的特征进行提取,进而得到不同的输出。结合前面 Sobel 的例子,任何图片经过 Sobel 竖直方向的算子 后,都会被提取出竖直方向的边缘特征,输出竖直方向的边缘特征图。
所以,由于卷积参数自身的特性,不同的图片经过该卷积时,能够提取相同类型的特征,不同图片会输出不同的特征图。当多个卷积组合在一起时,可以提取图像的多种特征;当卷积堆叠起来时,则能够提取不同分量的特征以及更深层次的特征。
2. 局部连接和权重共享
(1)局部连接:在卷积层(假设是第i层)中的每一个神经元都只和前一层(第i−1)中某个局部窗口内的神经元相连,构成一个局部连接网络,卷积层和前一层之间的连接数大大减少,由原来的Mi×Mi-1个连接变为Mi×K个链接,K为卷积核大小
(2)权重共享:作为参数的卷积核Wi对于第i层的所有的神经元都是相同的,权重共享可以理解为一个卷积核只捕捉输入数据中的一种特定的局部特征,因此,如果要提取多种特征就需要使用多个不同的卷积核。
由于局部连接和权重共享,卷积层的参数只有一个K维的权重和1维的偏置,共K+1个参数。
3. 图像卷积操作
假设卷积层输入是6×6×3,即输入为三个通道(构成图片的三原色)的尺寸为6×6大小的图片,卷积核大小为3×3,stride=1,padding=0,卷积核个数为3。则卷积层的输出为(6−3)/1+1=4,数据就是4×4×3
对于每一个3×3的卷积核,在输入的6×6×3上滑动卷积。卷积核的每一次滑动,实质上就是选取它所覆盖的元素,输入到一个神经元(神经元就是一个线性方程f(x)+bias,卷积核参数就是线性方程的权值系数),卷积核选取的元素与神经元参数,即卷积核参数进行点乘求和,这就完成了一次滑动卷积,得到了输出的特征映射的一个元素。
换句话说,输出的特征映射的每一个元素都对应于一个神经元的输出,输出有3个feature map,每个feature map大小为4×4=16个神经元,所以这个卷积层有16×3= 48个神经元。
对于卷积的参数个数,由于每一个feature map都是共享对应的卷积核参数,且卷积核参数为3×3+1=10,共3个卷积核,所以卷积核参数为3×10=30 个参数。
4. 填充Padding与步幅Stride
(1)卷积操作往往具有以下两个缺点:
每进行一次卷积运算,图像就会缩小,卷积很多次后图像就变得非常小;
角落和边缘的像素点信息容易丢失:对于图像中间的像素点会进行多次卷积运算,而图像角落和边缘的像素卷积过程中被使用到的次数非常少,这意味着角落和边缘的数据卷积后就很容易丢失。
(2)引入填充和步幅
填充:在输入特征图的每一边添加一定数目的行列。
步幅:卷积核经过输入特征图的采样间隔。
设置填充的目的:希望每个输入像素都能作为卷积窗口的中心。
设置步幅的目的:希望减小输入参数的数目,减少计算量。
假如Padding=1,Stride=1.卷积运算图示为:
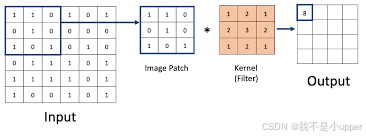
输出矩阵的宽度为:
![]()
(3)在深度学习框架tensorflow中,定义padding有两种方式:valid和same:
当padding=‘valid’时,不会在原有输入的基础上添加新的像素,因此在操作时滤波器可能不能将某个方向上的数据处理完,也就是可能会有valid的部分,其输出矩阵宽度为:
![]()
当padding=‘same’时,尽可能从输入左右两边进行padding从而使卷积核刚好覆盖所有输入,其输出矩阵宽度为:
![]()
举个栗子:
stride=1,padding=0(遍历采样,无填充:padding=‘valid’)
stride=1,padding=1(遍历采样,有填充:padding=‘same’)
stride=2,padding=0(降采样,无填充:尺寸缩小二点五分之一)
stride=2,padding=1(降采样,有填充:尺寸缩小二分之一)
二、池化层
1. 池化层原理
(1)操作过程:池化层的操作是将一个窗口内的像素按照平均值加权或选择最大值来作为输出,一个窗口内仅有一个输出数据。因此,当经过池化层后,图像的尺寸会变小,计算量也会变小,相比于在池化前使用卷积,池化后同样的卷积大小具有更大的感受野。
(2)池化的目的:保持特征不变性、特征维度下降。
特征维度下降:一个图像包含的信息很大,特征很多,有些信息在执行图像任务时很少使用,或是有M=。池化可以去掉这些冗余的信息,提取最重要的特征。但是特征越多,模型就会拟合这些特征,导致模型泛化能力下降,因此进行多层池化后,以前的特征维数减少,训练参数减少,泛化能力提高,进而防止过拟合。
2. 最大池化与平均池化
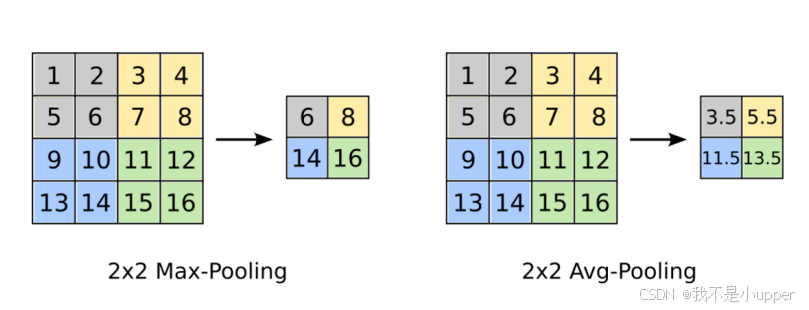
(1)最大池化:选图像区域最大值作为该区域池化后的值。
最大池化具有去除冗余信息、去除噪声的作用,更好保留纹理特征。
(2)平均池化:计算图像区域平均值作为该区域池化后的值。
对于平均池化,也即移动平均,其系统函数h ( n ) h(n)h(n)的长度为N NN,并且对于所有n nn都有h ( n ) = 1 / N h(n)=1/Nh(n)=1/N,在时域上看就是矩形,那么在频域上就是Sa函数,反之亦然,因此是一个低通滤波器。
均池化能保留整体数据的特征,较好的突出背景信息,避免丢失信息。
(3)对于一张图,在识别或者处理的时候,如果需要的是背景,或者说是整幅图的一个相对平均的情况那么用平均池化比较好。如果需要将图像中的一些物体特征提取出来,那么用最大池化好。
(4)池化的作用:特征降维、压缩数据和参数的数量,减小过拟合。
(5)池化的结果:特征减少、参数减少。
三、归一化层
(1)归一化:归一化值数据减去均值除以方差,变成均值为0方差为1的正态分布。
(2)归一化的目的:在机器学习领域中,特征向量中的不同特征往往具有不同的量纲和量纲单位,这样导致数量级相差过大,计算起来大数的变化会掩盖掉较小数据的变化,同时在进行梯度下降时如果学习率较大会难以找到最优点,收敛缓慢,需要对数据进行数据标准化处理,以解决数据指标之间的可比性,因此,进行归一化,使数据被限定在一定的范围内,加快梯度下降求最优解的速度,避免设置较大学习率而导致网络无法收敛的风险,提高网络稳定性。
同时,通过normalize操作让数据落在梯度非饱和区,就可以允许网络使用饱和性激活函数(Sigmoid、Tanh等)。
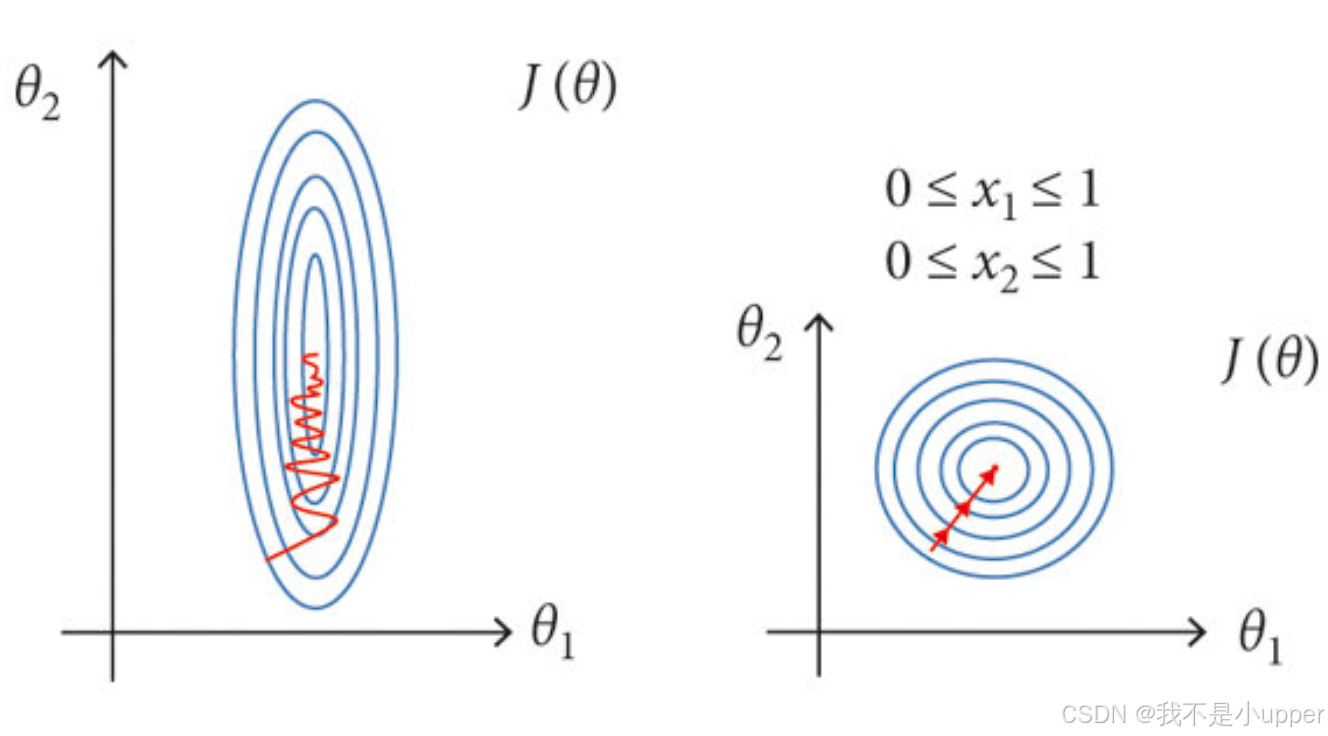
(3)批归一化(Batch Normalization,BN):将送入网络的每一个Batch进行归一化,使得每个Batch数据的特征都具有均值为0,方差为1的分布。
BN层通过对数据进行归一化,避免数据出现很大数量级差,防止了小的改变通过多层网络传播被放大的问题,可以有效防止梯度消失和梯度爆炸。
四、激活函数
激活层的提出主要是为了解决神经网络的线性不可分问题。如果没有激活层,无论神经网络有多少层,输出都是输入的线性组合,网络的逼近能力十分有限,因此需要在每一个隐藏层后加一个激活层,引入非线性因素。
1. Sigmoid激活函数
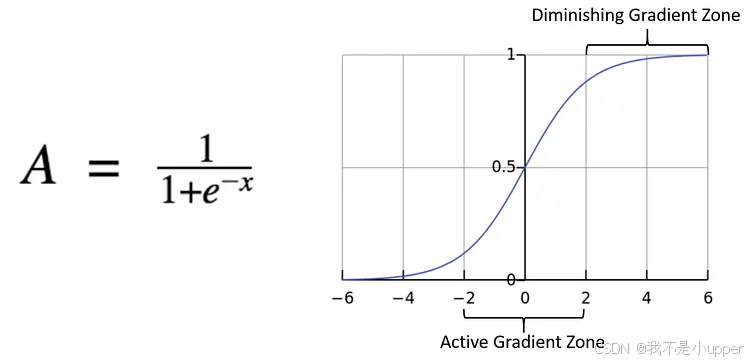
(1)特点:能够把输入的连续实值变换为0和1之间的输出,如果是非常大的负数,则输出为0,如果是非常大的正数,则输出为1。
(2)不足:在深度神经网络中梯度反向传播时导致梯度爆炸和梯度消失,其中梯度爆炸发生的概率非常小,而梯度消失发生的概率比较大。输出不是0均值,对权重求局部梯度则都为正,反向传播过程中w要么都往正方向更新,要么都往负方向更新,使得收敛缓慢。且解析式中含有幂运算,运算计算量大,比较耗时。
2. Tanh激活函数
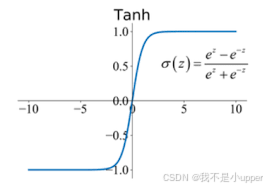
(1)优点:解决了Sigmoid函数输出不是零均值,导致收敛缓慢的问题。
(2)缺点:梯度消失和幂运算的问题仍然存在。
3. ReLU激活函数
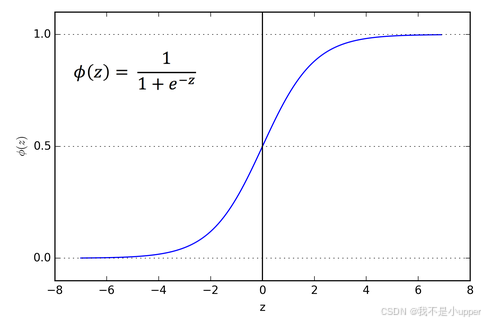
(1)为什么分两段:神经网络是仿人脑研究,大脑在同一时间大概只有1%-4%的神经元处于活跃状态,由于神经元数量的原因,为了更有效的利用到输入特征,同时避免过拟合,一般情况下,大概有50%的神经元处于激活态。对于能够成功激活的神经元,为了解决梯度消失和梯度爆炸问题,取斜率为1。在输入为负值的情况下,会输出为0,则神经元不会被激活,意味着同一时间只有部分神经元可以被激活,从而使得网络很稀疏,提高计算效率。
(2)优点:解决梯度消失问题;计算速度非常快,只需要判断输入是否大于0,可以有效降低计算量;收敛速度快;因为ReLU会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,可以缓解过拟合问题的发生。
(3)缺点:输出不是0均值;某些神经元永远不会被激活,导致相应参数永远不能被更新,但是这样产生的稀疏性导致神经网络激活矩阵有很多0,可以节约计算成本,提高运算效率。
ReLU函数的一系列变体(LReLU,PReLU,RReLU,ELU,SELU等等):变体主要针对ReLU函数输出不是0均值以及死亡ReLU问题,但是应用比较少。
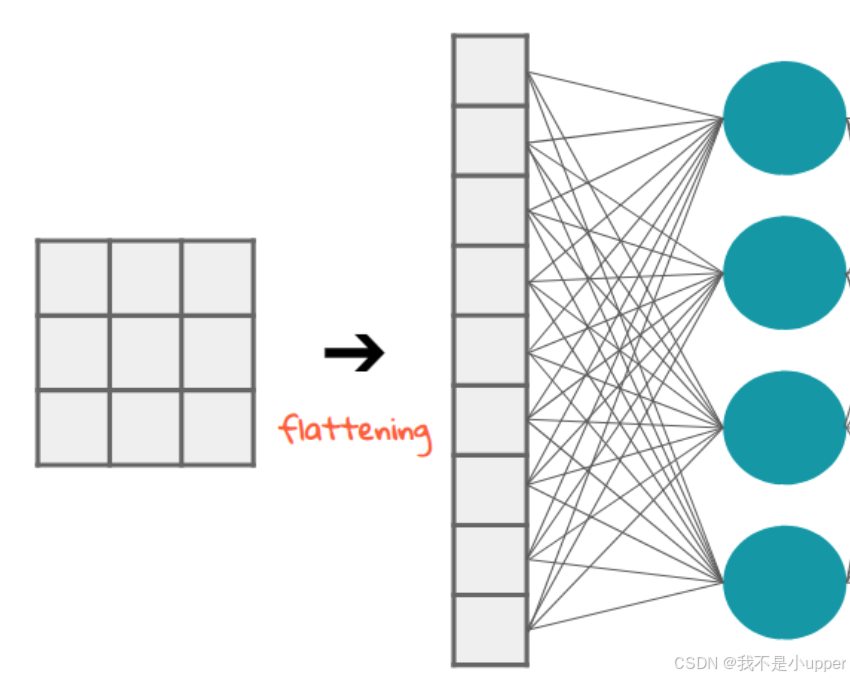
五、Flatten层
Flatten层用来将输入“压平”,即把卷积层输出的多维特征拉为一维向量,常用于从卷积层到全连接层的过渡。
六、全连接层
全连接层:全连接层是一个列向量,用于深度神经网络的后面几层,是将每一个节点都与上一层的所有节点相连,把前面提取到的特征综合起来。全连接层就是相当于一个超平面,将各个类别在特征空间将它们分开。
全连接层的作用:对数据进行分类。
第一层全连接层并激活符合特征存在的部分神经元,而这个层的作用就是根据提取到的局部特征进行相关操作进行组合并输出到第二个全连接层的某个神经元处,如上图,经过组合我们可以知道这是个猫头。第二层全连接层,假设猫的身体其他部位特征也都被上述类似的操作提取和组合出来,得到整体图像。
采用多层全连接,与数据输出为一维数据相对应,每通过一层全连接,综合前一层的特征,通过4层全连接将最重要的特征与输出对应。
总结:卷积层、池化层、激活函数层将原始数据映射到隐层特征空间;全连接层将学到的分布式特征表示映射到样本标记空间。