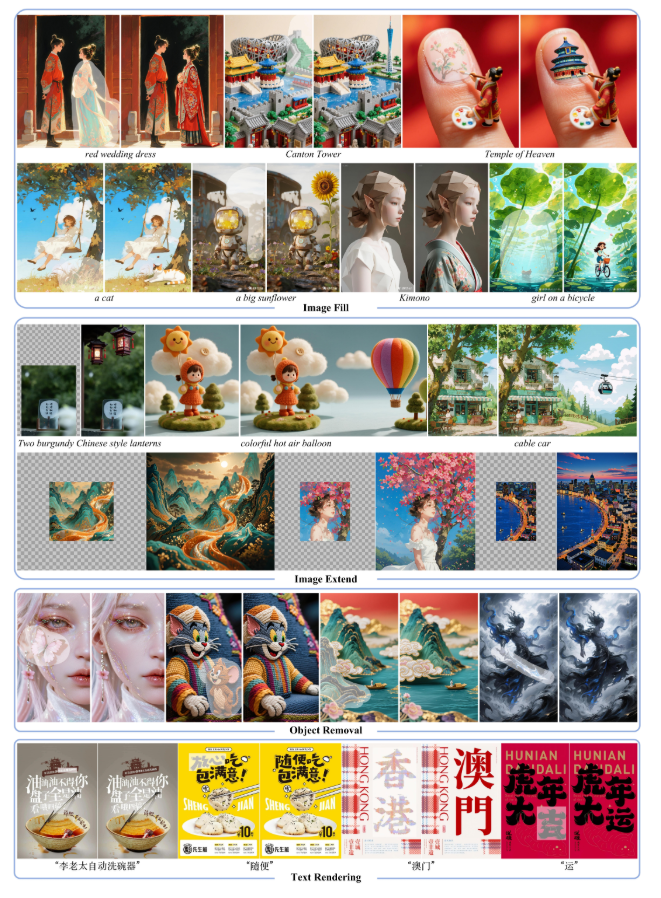
简介
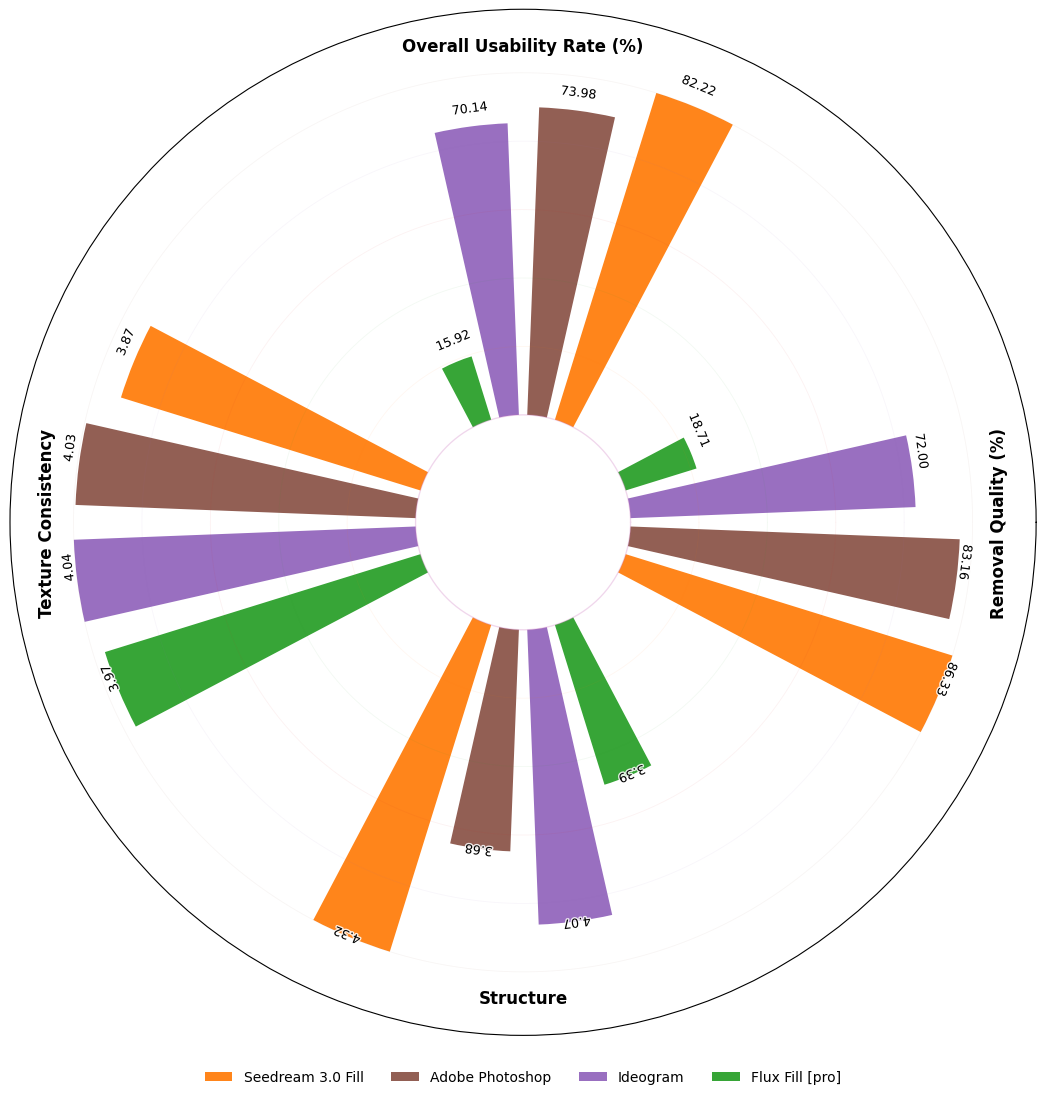
我们提出OneReward——一种基于Qwen2.5-VL生成式奖励模型的全新视觉领域RLHF方法,通过增强多任务强化学习显著提升策略模型在多项子任务中的生成能力。基于OneReward,我们开发出Seedream 3.0 Fill统一图像编辑模型,能高效处理图像填充、延展、物体消除和文字渲染等多样化任务,其表现超越Ideogram、Adobe Photoshop和FLUX Fill [Pro]等多家顶尖商业与开源系统。最后,基于FLUX Fill [dev]版本,我们激动地发布FLUX.1-Fill-dev-OneReward,该模型在修补与扩展绘画任务上性能优于闭源的FLUX Fill [Pro],为未来统一图像编辑研究树立了强大的新基准。
Image Fill
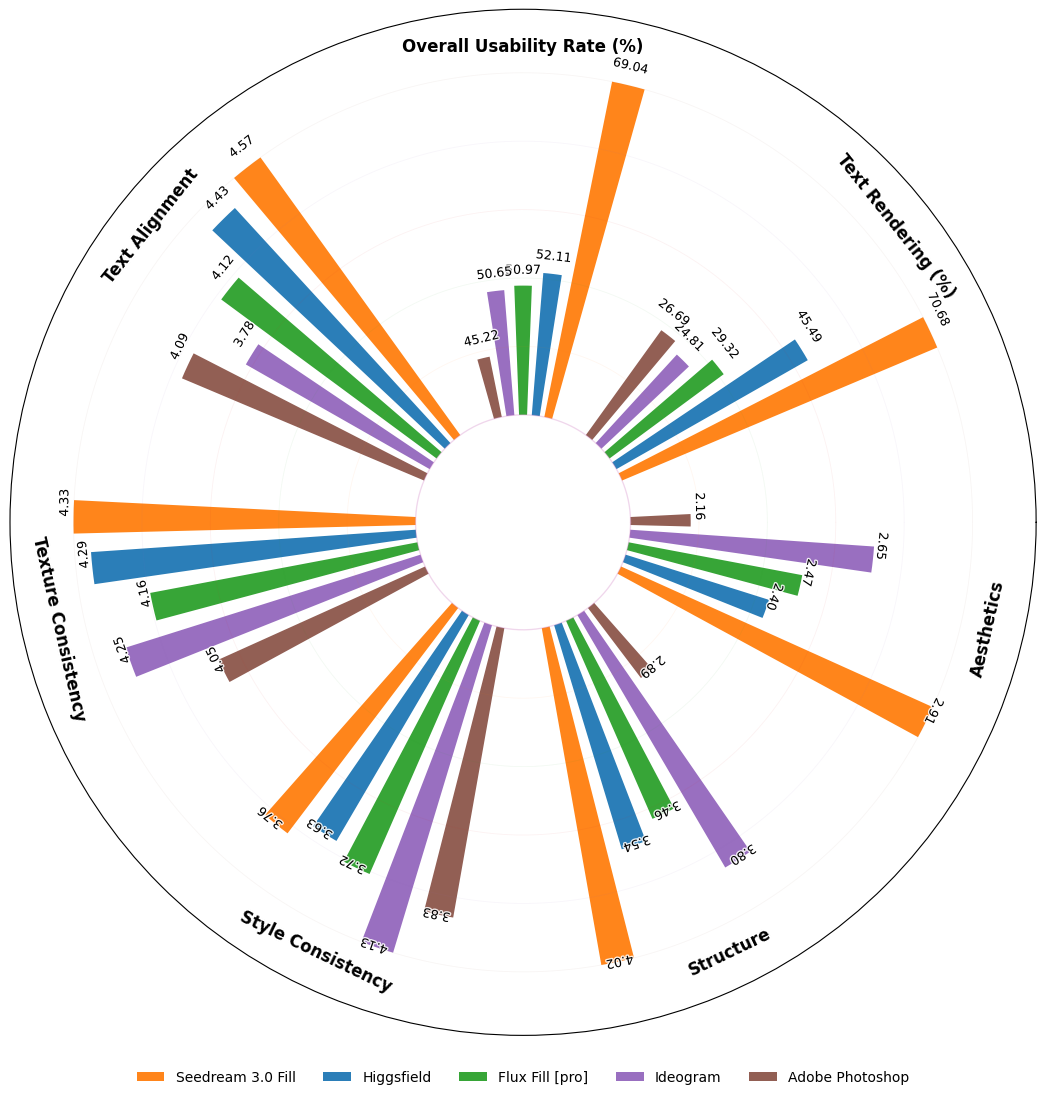
Image Extend with Prompt
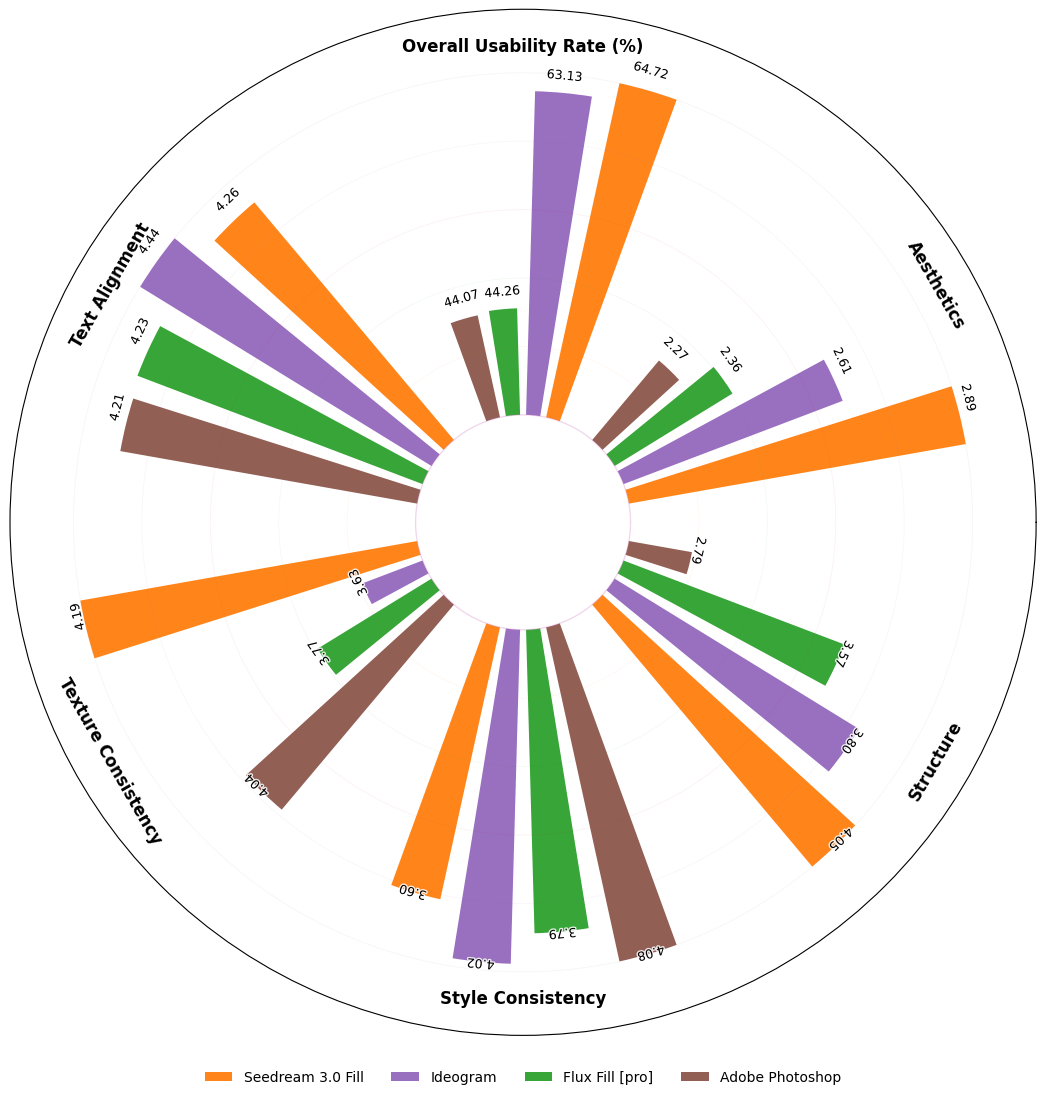
Image Extend without Prompt
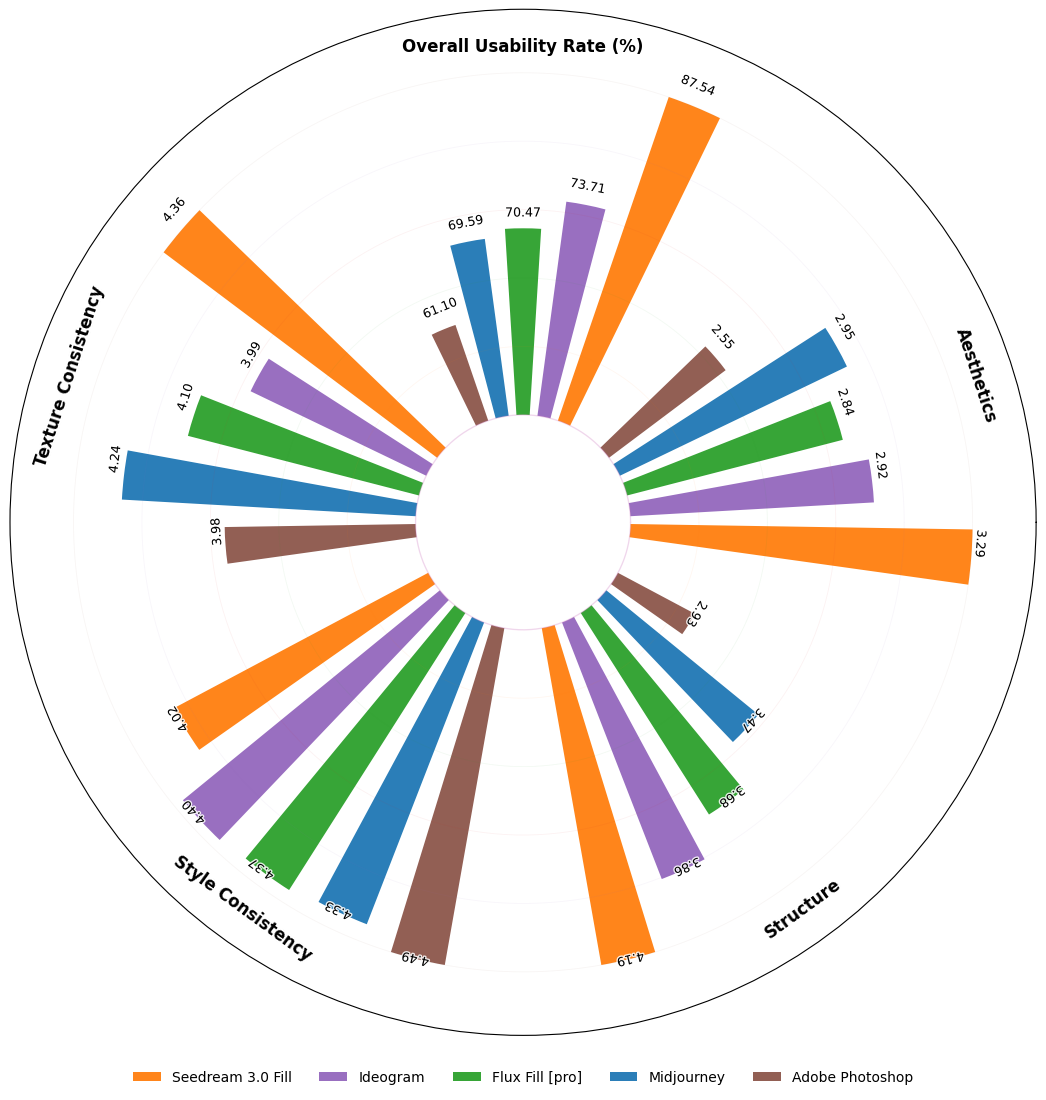
Object Removal
快速开始
确保您的transformers版本≥4.51.3(支持Qwen2.5-VL)
安装最新版本的diffusers
pip install -U diffusers
以下内容包含一段代码示例,展示如何基于文本提示和输入遮罩使用模型生成图像,支持图像修复(inpaint)、图像扩展(outpaint)和对象擦除(object-removal)。由于模型已完全训练,需要使用带cfg的FluxFillCFGPipeline,您可以在我们的GitHub上找到相关代码。
import torch
from diffusers.utils import load_image
from diffusers import FluxTransformer2DModel
from src.pipeline_flux_fill_with_cfg import FluxFillCFGPipeline
transformer_onereward = FluxTransformer2DModel.from_pretrained(
"bytedance-research/OneReward",
subfolder="flux.1-fill-dev-OneReward-transformer",
torch_dtype=torch.bfloat16
)
pipe = FluxFillCFGPipeline.from_pretrained(
"black-forest-labs/FLUX.1-Fill-dev",
transformer=transformer_onereward,
torch_dtype=torch.bfloat16).to("cuda")
# Image Fill
image = load_image('assets/image.png')
mask = load_image('assets/mask_fill.png')
image = pipe(
prompt='the words "ByteDance", and in the next line "OneReward"',
negative_prompt="nsfw",
image=image,
mask_image=mask,
height=image.height,
width=image.width,
guidance_scale=1.0,
true_cfg=4.0,
num_inference_steps=50,
generator=torch.Generator("cpu").manual_seed(0)
).images[0]
image.save(f"image_fill.jpg")

模型
FLUX.1-Fill-dev[OneReward],采用论文中算法1训练
transformer_onereward = FluxTransformer2DModel.from_pretrained(
"bytedance-research/OneReward",
subfolder="flux.1-fill-dev-OneReward-transformer",
torch_dtype=torch.bfloat16
)
pipe = FluxFillCFGPipeline.from_pretrained(
"black-forest-labs/FLUX.1-Fill-dev",
transformer=transformer_onereward,
torch_dtype=torch.bfloat16).to("cuda")
FLUX.1-Fill-dev[OneRewardDynamic],采用论文中的算法2进行训练
transformer_onereward_dynamic = FluxTransformer2DModel.from_pretrained(
"bytedance-research/OneReward",
subfolder="flux.1-fill-dev-OneRewardDynamic-transformer",
torch_dtype=torch.bfloat16
)
pipe = FluxFillCFGPipeline.from_pretrained(
"black-forest-labs/FLUX.1-Fill-dev",
transformer=transformer_onereward_dynamic,
torch_dtype=torch.bfloat16).to("cuda")
Object Removal
image = load_image('assets/image.png')
mask = load_image('assets/mask_remove.png')
image = pipe(
prompt='remove', # using fix prompt in object removal
negative_prompt="nsfw",
image=image,
mask_image=mask,
height=image.height,
width=image.width,
guidance_scale=1.0,
true_cfg=4.0,
num_inference_steps=50,
generator=torch.Generator("cpu").manual_seed(0)
).images[0]
image.save(f"object_removal.jpg")
Image Extend with prompt
image = load_image('assets/image2.png')
mask = load_image('assets/mask_extend.png')
image = pipe(
prompt='Deep in the forest, surronded by colorful flowers',
negative_prompt="nsfw",
image=image,
mask_image=mask,
height=image.height,
width=image.width,
guidance_scale=1.0,
true_cfg=4.0,
num_inference_steps=50,
generator=torch.Generator("cpu").manual_seed(0)
).images[0]
image.save(f"image_extend_w_prompt.jpg")
许可协议
代码采用 Apache 2.0 许可。模型采用 CC BY NC 4.0 许可。