系列文章目录
文章目录

我们知道数据库之间调用代码相差很大,如果我们同一个项目只需要换数据库,在不同数据库的语法不同会冲突,包括一些关键字也是不同的,我们如何用抽象工厂模式来解决呢?
最基本的数据访问程序
我们写一段原来数据访问的做法,例如新增用户和得到用户。
用户类,假设只有ID和Name两个字段,其余省略
//用户类
public class User{
//用户ID
private int _id;
public int getId(){
return this._id;
}
public void setId(int value){
this._id = value;
}
//用户姓名
private String _name;
public String getName(){
return this._name;
}
public void setName(String value){
this._name = value;
}
}
SqlServerUser类 ---- 用于操作User表,假设只有新增用户和得到用户方法,其余方法以及具体SQL语句省略。
//SqlServerUser类
public class SqlServerUser{
//新增一个用户
public void insert(User user){
System.out.println("在SQL Server中给User表添加一条记录");
}
//获取一个用户信息
public User getUser(int id){
System.out.println("在SQL Server中根据用户ID得到User表中的一条数据");
return null;
}
}
客户端代码:
//客户端代码
public static void main(String[] args) {
User user = new User();
SqlServerUser su = new SqlServerUser();
su.insert(user);
su.getUser(1);
}
这里之所以不能换数据库,原因就在于SqlServerUser su = new SqlServerUser()使得su这个对象被框死在SQL Server上了,他本质上也是在使用SQL Server的SQL语句代码,这里毫无疑问存在耦合。如果这里是灵活的,是多态的,那么在执行‘su.insert(user)’和’su.getUser(1)'时就不用考虑是在用SQL Server还是在用Access.
所以,我们可以用工厂方法模式来封装new SqlServerUser()所造成的变化。**工厂方法模式是定义一个用于创建对象的接口,让子类决定实例化哪一个类。 **
工厂方法模式的数据访问程序
IUser接口:用于客户端访问,解除与具体数据库访问的耦合
//用户类接口
public interface IUser{
public void insert(User user);
public User getUser(int id);
}
SqlserverUser类:用于访问SQL server的User
public class SqlserverUser implements IUser{
//新增一个用户
@Override
public void insert(User user) {
System.out.println("在SQL Server中给User变增加一条记录");
}
//获取一个用户信息
@Override
public User getUser(int id) {
System.out.println("在SQL Server中根据用户ID得到User表一条记录");
return null;
}
}
AccessUser类:用于访问Access的User。
public class AccessUser implements IUser{
//新增一个用户
@Override
public void insert(User user) {
System.out.println("在Access中给User表增加一些记录");
}
//获取一个用户信息
@Override
public User getUser(int id) {
System.out.println("在Access中根据用户ID得到User表一条记录");
return null;
}
}
IFactory接口:定义一个创建访问User表对象的抽象工厂接口
public interface IFactory{
public IUser createUser();
}
SqlServerFactory类:实现IFactory接口,实例化SqlserverUser。
public class SqlserverFactory implements IFactory{
@Override
public IUser createUser() {
return new SqlserverUser();
}
}
AccessFactory类:实现IFactory接口,实例化AccessUser。
public class AccessFactory implements IFactory{
@Override
public IUser createUser() {
return new AccessUser();
}
}
客户端代码:
public static void main(String[] args) {
User user = new User();
IFactory factory = new SqlserverFactory();
IUser iu = factory.createUser();
iu.insert(user);
iu.getUser(1);
}
现在如果非要换数据库,只需要把new SqlserverFactory()改成new AccessFactory(),此时由于多态的关系,使得声明IUser接口的对象iu事先根本不知道是在访问那个数据库,却可以在运行时很好的完成工作,这就是所谓的业务数据与数据访问的解耦
但是这样在代码里还是有指明‘new SqlserverFactory()’,所以我们在更换数据库时,更改的还是很多。另外数据库不可能只有一个user表,如果有多个表应该怎么办的,我们接下来一一为大家解释。
若有多个表:
public class Department{
//部门id
private int _id;
//部门名称
private String _name;
public int get_id() {
return _id;
}
public void set_id(int _id) {
this._id = _id;
}
public String get_name() {
return _name;
}
public void set_name(String _name) {
this._name = _name;
}
}
此时我们需要增加好多类,但是还是有一定灵活性
抽象工厂模式的数据访问程序
增加了关于部门表的处理
IDepartment接口:用于客户端访问,解除与具体数据库访问的耦合
public interface IDepartment{
public void insert(Department department);
public Department getDepartment(int id);
}
SqlserverDepartment类:用于访问SQL Server的Department。
public class SqlserverDepartment implements IDepartment{
//新增一个部门
@Override
public void insert(Department department) {
System.out.println("在SQL Server中给Department表添加一条数据");
}
//获取一个部门信息
@Override
public Department getDepartment(int id) {
System.out.println("在Access中根据部门id得到Department表一条记录");
return null;
}
}
AccessDepartment类:用于访问Access的Department。
public class AccessDepartment implements IDepartment{
@Override
public void insert(Department department) {
System.out.println("在Access表中添加一条记录");
}
@Override
public Department getDepartment(int id) {
System.out.println("在Access中根据部门ID得到Department表一条记录");
return null;
}
}
IFactory接口:定义一个创建访问Department表对象的抽象的工厂接口
public interface IFactory{
public IUser createUser();
public IDepartment createDepartment();
}
SqlServerFactory类:实现IFactory接口,并实例化SqlserverUser和SqlserverDepartment.
public class SqlserverFactory implements IFactory{
@Override
public IUser createUser() {
return new SqlserverUser();
}
@Override
public IDepartment createDepartment() {
return new SqlserverDepartment();
}
}
AccessFactory类:实现IFactory接口,并实例化AccessFactory和AccessDepartment
public class SqlserverFactory implements IFactory{
@Override
public IUser createUser() {
return new SqlserverUser();
}
@Override
public IDepartment createDepartment() {
return new SqlserverDepartment();
}
}
客户端代码:
public static void main(String[] args) {
User user = new User();
Department department = new Department();
IFactory factory = new SqlserverFactory();
IUser iu = factory.createUser();
iu.insert(user);
iu.getUser(1);
IDepartment department1 = factory.createDepartment();
department1.insert(department);
department1.getDepartment(1);
}
结果显示:
在SQL Server中给User表增加一条记录
在SQL Server中根据用户ID得到User表一条记录
在SQL Server中给Department表添加一条数据
在SQL server中根据部门id得到Department表一条记录
这样的话,就可以做到,只需更改IFactory factory = new SqlServerFactory()为IFactory factory = new AccessFactory(),就实现了数据库访问的切换了。
这里我们已经通过需求的不断演化,重构除了一个非常重要的设计模式。现在我们数据库中有很多表,而SQL server与Access又是两大不同的分类,所以解决这种多个产品系列的问题,有一个专门的工厂模式叫抽象工厂模式。
抽象工厂模式
抽象工厂模式,提供一个创建一系列相关或相互依赖对象的接口,而不需指定它们具体的类。
抽象工厂模式UML结构图
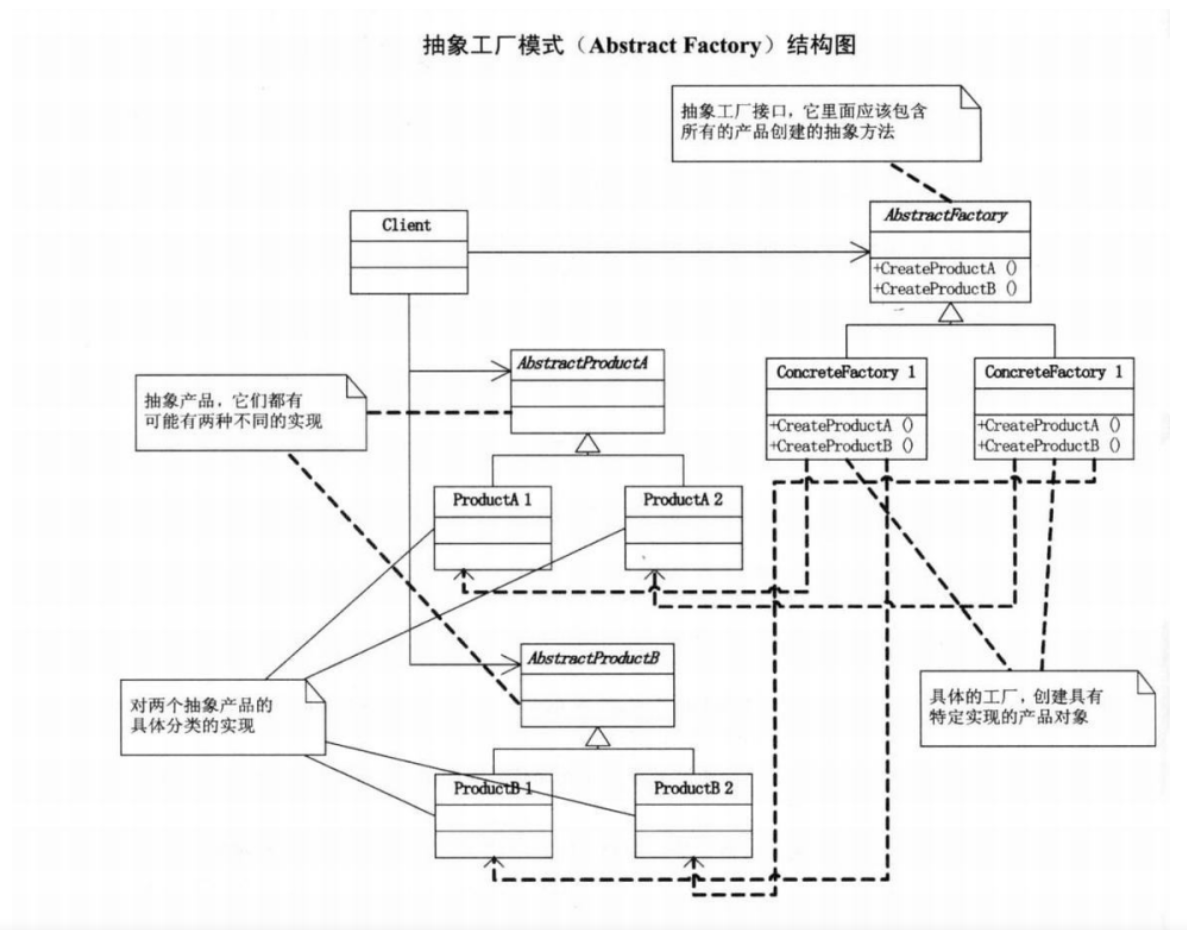
AbstractProductA和AbstarctProductB是两个抽象产品 ,之所以抽象,是因为它们都有可能有两种不同的实现,就刚才的例子来说就是User和Department,而ProductA1、ProductA2和ProductB1、ProductB2就是对两个抽象产品的具体实现, 比如ProductA1可以理解为是SqlserverUser,而ProductB是SqlserverDepartment。
也就是说IFactory是一个抽象工厂接口,它里面应该包含所有的产品创建的抽象方法。而ConcreteFactory1和ConcreteFactory2就是具体的工厂了。 就像SqlserverFactory和AccessFactory一样。通常是在运行时刻再创建一个ConcreteFactory类的实例,这个具体的工厂再创建具有特定实现的产品对象,也就是说,为创建不同的产品对象,客户端应使用不同的具体工厂。
抽象工厂模式的优点与缺点
抽象工厂这样做的最大好处就是易于交换产品系列 ,由于具体工厂类,例如IFactory factory = new AccessFactory(),在一个应用中只需要在初始化的时候 出现一次,这就使得改变一个应用的具体工厂变得非常容易,它只需要改变具体工厂即可使用不同的产品配置。 我们的设计不能去防止需求的更改,那么我们的理想便是让改动变得最小,现在如果你要更改数据库访问,我们只需更改具体工厂就可以做到。**第二大好处是,**它让具体的创建实例过程与客户端分离,不会出现在客户代码中。
抽象工厂模式虽然可以很方便的切换两个数据库访问的代码,但是如果你的需求来自增加功能,比如我们现在要增加项目表Project,我们至少需要增加三个类,IProject、SqlserverProject、AccessProject,还需要更改IFactory、SqlserverFactory和AccessFactory才可以完全实现, 这步骤十分繁琐。另外,就是我们客户端程序类显然不会是只有一个,有很多地方都在使用IUser或IDepartment,而这样的设计,其实在每一个类的开始都需要声明IFactory factory = new SqlserverFactory(),如果我们需要有100个调用数据库访问的类,是不是就要更改100次IFactory factory = new AccessFactory(),显然这么做会很蠢,大批量的改动,是不符合编程这门艺术的。那么我们要如何修改呢?
用简单工厂来改进抽象工厂
代码示例如下:
public class DataAccess{
private static String db = "Sqlserver"; //数据库名称可以替换为Access
//创建用户对象工厂
public static IUser createUser(){
IUser result = null;
switch(db){
case "Sqlserver":
result = new sqlserverUser();
break;
case "Access":
result = new AccessUser();
break;
}
return result;
}
//创建部门对象工厂
public static IDepartment createDepartment(){
IDepartment result = null;
switch(db){
case "Sqlserver":
result = new SqlserverDepartment();
break;
case "Access":
result = new AccessDepartment();
break;
}
return result;
}
}
//客户端
public static void main(String[] args) {
User user = new User();
Department department = new Department();
IUser iu = DataAccess.createUser();
iu.insert(user);
iu.getUser(1);
IDepartment idept = DataAccess.createDepartment();
idept.insert(department);
idept.getDepartment(2);
}
上述代码中,我们直接抛弃了IFactory、SqlserverFactory和AccessFactory三个工厂类, 取而代之用DataAccess类,事先声明db值,所以简单工厂的方法都不需要参数,这样在客户端就只需要DataAccess.createUser()和DataAccess.createDepartment()来生成具体的数据库访问类实例,客户端没有出现任何一个SQL server或Access的字样,达到了解耦的目的。
但这里如果我们要增加一个新的数据库访问Oracle,抽象工厂只需要增加OracleFactory工厂类就可以了,但如果这样的话,就只能在DataAccess类中每个方法的switch加Case了。
用反射 + 抽象工厂的数据访问程序
我们要考虑的就是可不可以不在程序里写明如果是Sqlserver就去实例化SQLServer数据库相关类,如果是Access就去实例化Access相关类这样的语句,而是根据字符串db的值去某个地方找应该要实例化的类是哪一个。
这就是我们说了一种编程方式: 依赖注入。关键如何用这种方法来解决我们的switch问题,本来依赖注入是需要专门的Ioc容器提供,比如Spring,显然当前这个程序不需要这么麻烦,我们需要了解Java技术–反射。
//反射格式
Object result = Class.forName("包名.类名").getDeclaredConstructor().newInstance()
有了反射我们获得实例可以用以下两种写法
//常规写法
IUser result= new SqlserverUser();
//反射写法
IUser result = (IUser)Class.forName("chouxianggongchang.SqlserverUser").getDeclaredCOnstructor().newInstance();
实例化的效果是一样的,但常规方法写明了要实例化SqlserverUser对象,反射的写法,在包名.类名中用的是字符串,可以用变量来处理,也就可以根据需求更换。
我们可以用DataAccess类,用反射技术,取代IFactory、SqlserverFactory和AccessFactory。
public class DataAccess{
private static String assemblyName = "chouxianggongchang.SqlserverUser"; //数据库名称可以替换为Access
private static String db = "Sqlserver"; //数据库名称可以替换为
//创建用户对象工厂
public static IUser createUser(){
return (IUser) getInstance(assemblyName + db + "User");
}
//创建部门对象工厂
public static IDepartment createDepartment(){
return (IDepartment)getInstance(assemblyName + db +"Department");
}
public static Object getIntance(String className){
Object result = null;
try{
result = Class.forName(className).getDeclaredConstructor().newInstance();
}catch (ClassNotFoundException e) {
throw new RuntimeException(e);
} catch (InvocationTargetException e) {
throw new RuntimeException(e);
} catch (InstantiationException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
} catch (NoSuchMethodException e) {
throw new RuntimeException(e);
}
return result;
}
}
现在如果我们增加了Oracle数据访问,相关的类增加是不可避免的,这点我们无法改变,不过这叫扩展,开放 --封闭原则告诉我们,对于扩展,我们开放,但对于修改,我们要尽量关闭,就目前而言,我么只需要更改private static String db = “Sqlserver”;
为private static String db = “Oracle”;也就是
return (IUser)getIntance("chouxianggongchang" + "Sqlserver" + "User");
return (IUser)getIntance("chouxianggongchang" + "Oracle" + "User");
这样的结果就是DataAccess.createUser()本来得到的是SqlserverUser()的实例,而现在变成OraclaUser的实例了。
当我们增加Project的产品时,我们可以增加三个与Project相关的类,再修改DataAccess,在其中增加一个public static IProject createProject()方法就可以了。现在我们在更改数据库访问时,只需去更改db这个字符串的值就可以了。
用反射 + 配置文件实现数据访问程序
添加一个db.properties文件,内容如下:
db=Sqlserver
再更改DataAccess类,添加与读取文件内容相关的包
import java.io.BufferedReader;
import java.io.FileReaderl
import java.io.IOException;
import java.util.properties;
public class DataAccess{
private static String assemblyName = "chouxianggongchang.SqlserverUser";
public static String getDb(){
String result = "";
try{
Properties properties = new Properties();
//编译后,请将db.properties文件复制到要编译的class目录里,
// 并确保下面path路径与实际db.properties文件路径是否一致,否则会报No Such file or directory错误
String path = System.getProperty("chouxianggongchang") + "/db.properties";
BufferReader bufferedReader =new BufferReader(new FileReader(path));
properties.load(bufferReader);
result = properties.getProperty("db");
}catch(IOException e){
e.printStackTrace();
}
return result;
}
将来要更新数据库,无须重新编译任何代码,只需要更改配置文件就可以了 。
我们应用了反射 + 抽象工厂模式 解决了数据库访问时的可维护可扩展问题。
所以从这里来看,所有在用简单工厂的地方,都可以考虑用反射技术来去除switch或if,解除分支判断带来的耦合。
总结
以上就是本文全部内容,本文主要向大家介绍了设计模式中的抽象工厂模式,通过更换数据库的例子介入,介绍抽象工厂模式,接着介绍了反射相关概念,以及反射和抽象工厂模式的结果运用! 感谢各位能够看到最后,如有问题,欢迎各位大佬在评论区指正,希望大家可以有所收获!创作不易,希望大家多多支持!