摘要:在机器学习领域,我们常常惊叹于算法的强大威力,但其背后往往隐藏着深刻的数学原理。线性代数作为机器学习的三大数学支柱之一,其核心概念——特征值与特征向量,扮演着至关重要的角色。本文将深入探讨特征值优化的理论、经典应用及其在现代机器学习中的前沿实践,揭示它如何成为理解和驱动数据科学发展的数学基石。
引言:拨开机器学习的数学迷雾
当我们谈论机器学习时,梯度下降、神经网络、决策树等模型和算法往往是讨论的焦点。然而,这些高层应用的根基深植于数学的土壤之中。线性代数、概率论和优化理论共同构成了支撑起整个机器学习大厦的骨架 。其中,特征值和特征向量的概念,以及围绕它们展开的“特征值优化”,不仅是理论上的优雅存在,更是在数据降维、模型分析和算法设计中发挥着不可替代作用的实用工具 。
本文的目标是带领读者进行一次深度探索,从特征值的基本定义出发,逐步深入其在主成分分析(PCA)、谱聚类、深度学习模型理解等领域的经典应用,并最终聚焦于将特征值本身作为优化目标的先进技术,如距离度量学习。通过理论与实践的结合,我们将揭示特征值优化为何是机器学习从业者必须掌握的核心知识。
第一章:特征值与特征向量——线性变换的灵魂
在深入探讨优化之前,我们必须首先理解其核心——特征值与特征向量。它们是理解线性变换本质的钥匙。
1.1 核心定义与几何直观
在线性代数中,一个矩阵可以被看作是一个线性变换的描述。对于一个给定的方阵 ,如果存在一个非零向量 v 和一个标量 λ,使得它们满足以下关系:
Av = λv
那么,我们称 λ 为矩阵 A 的一个 特征值(Eigenvalue) ,而 v 则是对应于 λ 的 特征向量(Eigenvector) 。
这个公式的几何意义非常直观:当矩阵 A 对其特征向量 v 进行变换时,这个变换的效果仅仅是对向量 v 进行了一个缩放,缩放的比例就是特征值 λ,而向量的方向保持不变 。因此,特征向量是线性变换中“不变的”方向,而特征值则量化了在这些方向上的拉伸或压缩程度。正是这种“不变性”使得特征向量成为了描述矩阵变换特性的关键。
1.2 特征值分解 (EVD) 的力量
特征值分解(Eigenvalue Decomposition, EVD)是将一个矩阵分解为其特征值和特征向量的过程。对于一个方阵 A,如果它有足够多的线性无关的特征向量,就可以被分解为:
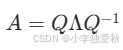
其中,Q 是一个由 A 的特征向量组成的矩阵,Λ 是一个对角矩阵,其对角线上的元素是对应的特征值 。
特征值分解的强大之处在于,它将一个复杂的矩阵变换分解为三个简单的步骤:一次坐标变换(Q^-1)、一次沿着新坐标轴的缩放(Λ)、再加一次坐标变换回原始空间(Q)。这个过程极大地简化了我们对数据和模型的分析,使我们能够洞察矩阵变换的主要方向和强度,为后续的优化和应用奠定了理论基础 。
第二章:特征值在机器学习中的经典应用
特征值的概念并非空中楼阁,它在众多经典的机器学习算法中扮演着核心角色。
2.1 数据降维的基石:主成分分析 (PCA)
主成分分析(Principal Component Analysis, PCA)是特征值应用中最广为人知也最经典的例子 。PCA的目标是在高维数据中找到“最重要”的方向,即数据方差最大的方向,从而用一个更低维度的子空间来表示原始数据,达到降维的目的 。
这背后的数学原理与特征值紧密相连:
- 计算协方差矩阵:首先,计算数据点的协方差矩阵。这个矩阵描述了数据在不同维度上的相关性。
- 特征值分解:对协方差矩阵进行特征值分解。
- 寻找主成分:协方差矩阵的特征向量指向了数据方差变化的方向。而对应的特征值则量化了该方向上的方差大小。特征值越大的特征向量,其所代表的方向(即主成分)保留的原始数据信息就越多 。
- 数据投影:通过选择最大的 k 个特征值对应的特征向量,我们可以构建一个新的 k 维子空间,并将原始数据投影到这个子空间上,从而在最小化信息损失的前提下实现数据降维。
PCA的成功充分证明了,通过分析特征值和特征向量,我们能够有效地识别并利用数据的内在结构 。
2.2 图数据洞察:谱聚类
在处理如社交网络、分子结构等图数据时,谱聚类(Spectral Clustering)是一种非常强大的技术。它并非直接在原始空间对数据点进行聚类,而是利用图的拉普拉斯矩阵的谱(即特征值)来进行降维 。
算法的核心思想是,拉普拉斯矩阵的特征向量揭示了图的连通性结构。特别是,对应于最小的几个非零特征值的特征向量,可以将图中的节点映射到一个低维空间。在这个新的空间里,原本连接紧密的节点会聚集在一起,而连接稀疏的节点则会相互远离,从而使得传统的聚类算法(如K-Means)能够轻松地发现簇结构 。
2.3 理解深度学习模型:Hessian矩阵的特征谱
近年来,特征值分析也被用于揭示深度学习这个“黑箱”的内部工作机制。在优化过程中,损失函数的Hessian矩阵(由损失函数对模型参数的二阶偏导数组成)的特征谱(即特征值分布)蕴含了关于损失曲面几何形状的关键信息 。
- 损失曲面的曲率:Hessian矩阵的特征值描述了损失函数在某个点附近的曲率。大的正特征值对应着“尖锐”的最小值点,而小的正特征值则对应着“平坦”的最小值点 。
- 泛化能力:大量研究表明,模型收敛到一个平坦的最小值区域(Hessian特征值较小)时,通常具有更好的泛化能力 。因为在一个平坦的区域,训练集和测试集上损失函数的微小差异不会导致模型输出的巨大变化。
通过分析Hessian矩阵的特征值,研究者们可以更好地理解不同优化算法(如Adam、SGD)的行为、网络架构设计的优劣以及模型的泛化性能,为改进深度学习训练提供了重要的理论指导。
第三章:深入核心:作为优化目标的特征值
除了作为分析工具,特征值本身也可以直接成为优化问题的目标。这类问题被称为特征值优化(Eigenvalue Optimization)问题,它们在控制论、结构设计以及现代机器学习中都有着重要应用。
3.1 什么是特征值优化问题?
一个典型的特征值优化问题,通常旨在寻找某个决策变量,以最小化或最大化一个与该变量相关的矩阵的某个特征值函数 。例如,最小化矩阵的最大特征值![]() 或最大化最小特征值
或最大化最小特征值![]() 。
。
这类问题在数学上具有良好的性质。当处理对称矩阵时,特征值函数通常是凸的,这意味着我们可以利用强大的凸优化技术(如半定规划,Semidefinite Programming, SDP)来寻找全局最优解 。像Lidskii定理等数学理论为这类问题的分析提供了坚实的理论基础 。
3.2 核心案例研究:基于特征值优化的距离度量学习 (DML-eig)
距离度量学习(Distance Metric Learning, DML)是特征值优化在机器学习中一个极具代表性的前沿应用。在许多算法(如k-近邻,k-NN)中,标准的欧氏距离并不能很好地捕捉数据的真实相似性。DML的目标就是学习一个更合适的距离度量,通常是马氏距离,来提升算法性能。
问题设定:我们希望学习一个距离度量,使得属于同一类别的样本点(相似对)之间的距离尽可能小,而属于不同类别的样本点(非相似对)之间的距离尽可能大 。
DML-eig方法:一种名为DML-eig的先进方法巧妙地将这个问题转化为了一个特征值优化问题 。它通过一系列约束条件来表达上述目标,最终推导出其优化问题等价于最小化某个特定构造的对称矩阵的最大特征值 。通过求解这个特征值优化问题,算法能够找到一个最优的距离度量矩阵,从而显著改善分类器的性能。实验证明,DML-eig方法在人脸识别等任务上,其性能与当时最先进的技术相比具有很强的竞争力 。
这个案例完美地展示了如何将一个实际的机器学习问题,通过数学建模,最终归结为一个可以高效求解的特征值优化问题。
第四章:实践指南:Python代码实现
理论的理解最终需要通过实践来巩固。下面我们用Python来演示几个关键概念的实现。
4.1 计算特征值和特征向量
使用NumPy库可以非常方便地计算矩阵的特征值和特征向量。
import numpy as np
# 创建一个对称矩阵
A = np.array([[4, 2],
[2, 7]])
# 使用 numpy.linalg.eig 计算特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(A)
print("矩阵 A:\n", A)
print("\n特征值 (Eigenvalues):\n", eigenvalues)
print("\n特征向量 (Eigenvectors):\n", eigenvectors)
# 验证: A * v = lambda * v
for i in range(len(eigenvalues)):
v = eigenvectors[:, i]
lambda_v = eigenvalues[i] * v
Av = A @ v
# allclose 用于比较浮点数数组是否近似相等
assert np.allclose(Av, lambda_v)
print(f"\n验证第 {i+1} 组特征值/向量: A*v 和 lambda*v 近似相等。")
4.2 PCA降维实战
虽然可以直接使用scikit-learn库,但手动实现PCA有助于我们更深刻地理解其背后的特征值原理。
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
# 1. 加载并标准化数据
iris = load_iris()
X = iris.data
X_scaled = StandardScaler().fit_transform(X)
# 2. 计算协方差矩阵
covariance_matrix = np.cov(X_scaled.T)
# 3. 计算协方差矩阵的特征值和特征向量
eig_vals, eig_vecs = np.linalg.eig(covariance_matrix)
# 4. 选择最大的两个特征值对应的特征向量
# 按照特征值从大到小排序
sorted_indices = np.argsort(eig_vals)[::-1]
top_2_eig_vecs = eig_vecs[:, sorted_indices[:2]]
# 5. 将数据投影到新的二维空间
X_pca = X_scaled @ top_2_eig_vecs
print("原始数据维度:", X_scaled.shape)
print("降维后数据维度:", X_pca.shape)
4.3 (概念性)特征值优化实现思路
完整实现DML-eig较为复杂,但我们可以用SciPy来演示一个简单的特征值优化问题的求解思路:找到一个参数x,使得某个依赖于x的矩阵的最大特征值最小。
from scipy.optimize import minimize
def objective_function(x):
"""
目标函数:返回一个依赖于x的矩阵的最大特征值
这是一个示例,实际问题中的矩阵构造会更复杂
"""
# 构造一个依赖于参数 x 的对称矩阵
M = np.array([[2 + x[[0]]**2, 1 - x[[0]],
[1 - x[[0]], 3 + x[[0]]
# 计算特征值并返回最大的那个
eigenvalues = np.linalg.eigvals(M)
return np.max(eigenvalues)
# 初始猜测值
x0 = np.array([0.0])
# 使用 minimize 函数进行优化
result = minimize(objective_function, x0, method='BFGS')
print("优化结果:", result)
print(f"找到的最优参数 x: {result.x[[0]]:.4f}")
print(f"在该参数下,矩阵的最大特征值最小为: {result.fun:.4f}")
这个简单的例子展示了如何将特征值计算嵌入到优化循环中,这正是特征值优化问题的核心思想。
第五章:总结与展望
5.1 总结核心思想
从数据降维到模型解释,再到高级算法设计,特征值和特征向量无处不在。它们不仅仅是线性代数中的一个抽象概念,更是我们用来理解数据、分析模型、解决问题的强大数学语言。
本文系统地梳理了特征值优化的理论与实践:
- 基础层面:特征值分解为我们提供了洞察矩阵变换本质的工具。
- 应用层面:PCA、谱聚类和Hessian分析等经典技术,都是建立在对特征谱的深刻理解之上。
- 前沿层面:以DML-eig为代表的特征值优化问题,直接将特征值作为优化目标,为解决复杂的机器学习问题开辟了新的道路。
5.2 未来趋势
展望未来,特征值优化的重要性将与日俱增。
- 大模型的可解释性:随着模型规模日益庞大,理解其训练动态和内部机制变得至关重要。对训练过程中关键矩阵(如Hessian、Fisher信息矩阵)的特征谱进行分析,将继续是可解释性研究的核心方向。
- 鲁棒性与泛化:特征值优化在鲁棒优化和对抗性训练等领域有巨大潜力,通过控制相关矩阵的特征谱,可以增强模型的稳定性和对未知数据的泛化能力。
- 算法效率:大规模特征值问题的求解仍然是计算上的挑战。随着硬件的发展和新数值算法的出现,我们期望能够更高效地解决超大规模数据集上的特征值优化问题,从而推动其在更多实际场景中的应用。
总之,无论是作为一名数据科学家、算法工程师还是研究人员,深入理解并掌握特征值优化的相关知识,都将是您在人工智能浪潮中乘风破浪的关键能力。