示例
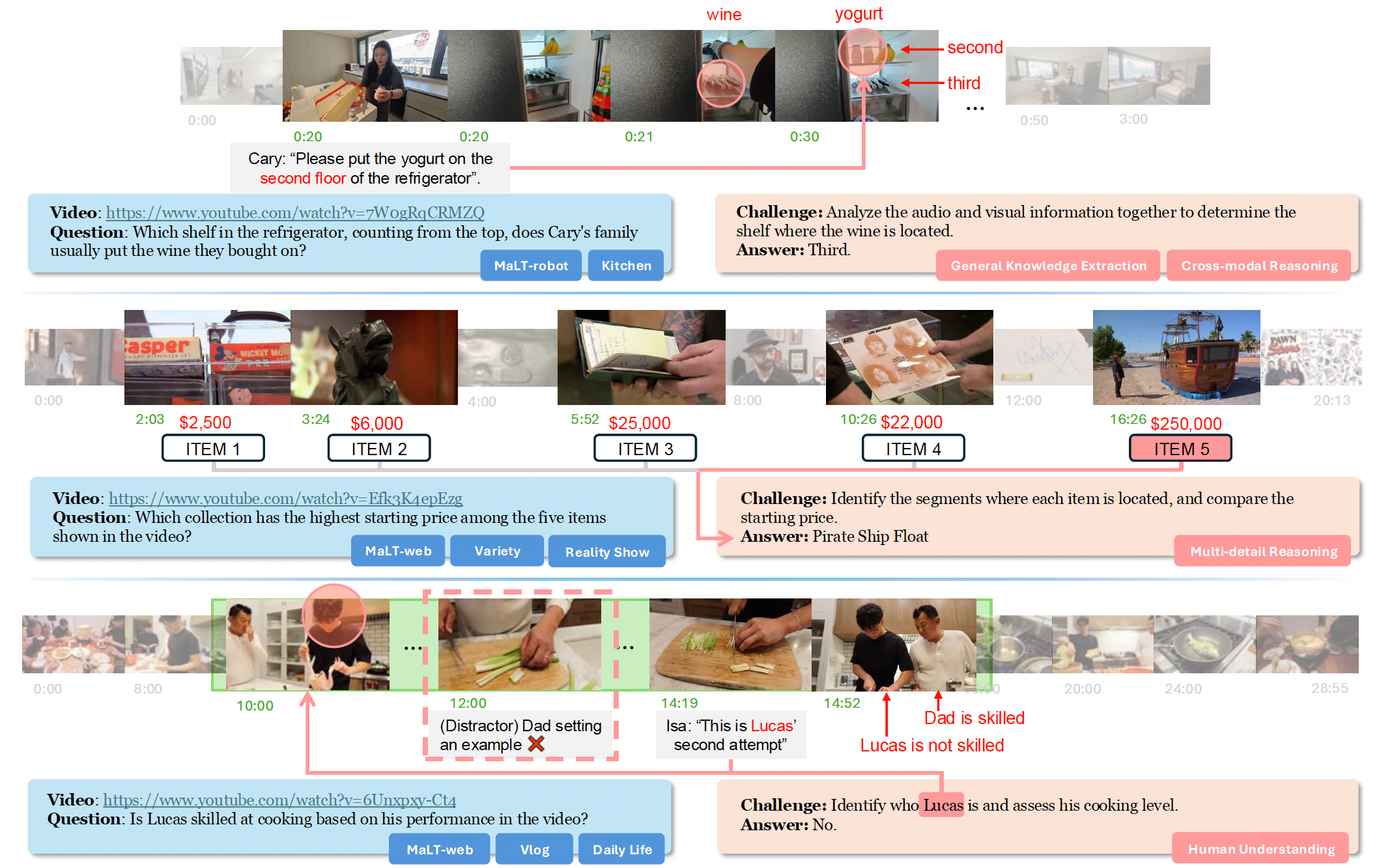
这张图展示了三个不同的视频相关任务,每个任务都涉及从视频中提取信息并回答问题,同时还标注了任务所涉及的挑战类型。
第一部分(关于冰箱置物)
视频与问题:
“Cary 的家人通常把买来的酒放在冰箱的哪一层(从上数)?”
视频链接为https://www.youtube.com/watch?v=7WogRqCRMZQ,
挑战与答案:
需要结合音频和视觉信息来确定酒所在的层架,答案是 “第三层”
涉及 “通用知识提取(General Knowledge Extraction)” 和 “跨模态推理(Cross - modal Reasoning)”
同时分析视频中的声音(比如人物对话)和画面(冰箱内部结构、物品摆放)来得出结论
第二部分(关于物品起拍价)
视频与问题: “视频中展示的五件物品中,哪个藏品的起拍价最高?”
视频链接为https://www.youtube.com/watch?v=Efl3K4epEzg
挑战与答案:需要确定每个物品所在的片段并比较起拍价,答案是 “Pirate Ship Float(海盗船模型)”
任务涉及 “多细节推理(Multi - detail Reasoning)”
要在视频中找到多个物品的价格信息并进行比较
第三部分(关于 Lucas 的厨艺)
视频与问题:问题是 “根据视频中的表现,Lucas 厨艺好(be skilled at)吗?”
视频链接为https://www.youtube.com/watch?v=6Unxpxv - Ct4,
挑战与答案:
需要确定 Lucas 是谁并评估他的厨艺水平,答案是 “不好(No)”。
这涉及 “人类理解(Human Understanding)”
要从视频中人物的行为、互动以及可能的对话等方面,判断人物的技能水平
小节
利用多模态信息(音频、视觉等)来解决视频理解问题的不同场景,涵盖了从信息提取、比较到人物分析等多种任务类型
体现了在视频内容理解中需要综合运用多种推理和分析能力
shelf ʃelf ʃelf
搁板,架子;(尤指水中)陆架,底岩;<非正式>告密者(复数 shelfs);<非正式>告发(某人)
reasoning ˈriːzənɪŋ ˈriːzənɪŋ
推理,推论;推断力,逻辑推理能力
pirate ˈpaɪrət ˈpaɪrət
海盗,海上劫掠者;盗版者,侵犯专利权者;非法制作电视或广播节目的人(或组织);道德败坏者,违法者
盗印,窃用;劫掠(船只);<旧>劫掠(船只)
盗版的
float fləʊt floʊt
(使)漂浮,(使)浮动;轻盈走动,飘然移动;提出(想法或计划);发行(股票)上市;使(货币汇率)自由浮动
彩车;鱼漂,浮子;(学游泳用的)浮板;(公司股票)上市,开始发行
Pirate Ship Float(海盗船模型)
be skilled at bi skɪld æt 擅长于
faces ˈfeɪsɪz ˈfeɪsɪz
表面(face 的复数);脸色;脸面
向;面对;转向(face 的三单形式)
voices ˈvɔɪsɪz ˈvɔɪsɪz
声音
annotation ˌænəˈteɪʃ(ə)n ˌænəˈteɪʃ(ə)n
注释,评注;注释,加注
代码
configs/memory_config.json
{
"max_img_embeddings": 10, // 每个人脸/场景节点最多保留 10 个图像特征向量
"max_audio_embeddings": 20, // 每个说话人节点最多保留 20 个语音特征向量
"img_matching_threshold": 0.3, // 图像相似度阈值(余弦距离 ≤ 0.3 算同一人/场景)
"audio_matching_threshold": 0.6 // 语音相似度阈值(余弦距离 ≤ 0.6 算同一人)
}
mmagent/src/face_extraction.py(人脸提取处理)
ortho ˈɔːθəʊ ˈɔːrθoʊ (黑白胶片)正色性的
# Copyright (2025) Bytedance Ltd. and/or its affiliates
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import cv2
import numpy as np
from tqdm import tqdm
from concurrent.futures import ThreadPoolExecutor
from threading import Lock
import base64
def test(frames, results):
print("request recieved. now responding.")
results.put('1')
# 从图像列表中提取人脸信息
# 接收一个人脸检测应用实例和图像列表,通过多线程并行处理,从每张图像中检测人脸
# 提取人脸特征(如边界框、嵌入向量、质量分数等),并将结果整理成统一格式返回
# face_app:人脸检测与处理的应用实例(提供get方法用于检测图像中的人脸)
# image_list:Base64 编码的图像字符串列表,每张图像对应一个字符串
# num_workers:并行处理的线程数量,默认值为 4
def extract_faces(face_app, image_list, num_workers=4):
lock = Lock()
# faces列表用于存储最终提取的所有人脸信息
faces = [] # 初始化结果列表
def process_image(args):
frame_idx, img_base64 = args
try:
# 将base64解码为图片
# Base64解码为字节数据
img_bytes = base64.b64decode(img_base64)
# 转换为NumPy数组
img_array = np.frombuffer(img_bytes, dtype=np.uint8)
# 解码为OpenCV格式的彩色图像
img = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
if img is None:
return []
# 调用人脸检测接口获取图像中的所有人脸
detected_faces = face_app.get(img)
frame_faces = []
# 人脸信息提取(对每张检测到的人脸)
for face in detected_faces:
# 边界框处理:将人脸边界框坐标转换为整数列表
bbox = [int(x) for x in face.bbox.astype(int).tolist()]
# 人脸检测置信度 detection_score(检测算法给出)
dscore = face.det_score
embedding = [float(x) for x in face.normed_embedding.tolist()]
embedding_np = np.array(face.embedding)
# 人脸质量分数 quality_score (通过嵌入向量的 L2 范数计算)
qscore = np.linalg.norm(embedding_np, ord=2)
# 人脸类型判断:根据边界框的宽高比判断是正脸还是侧脸
height = bbox[3] - bbox[1]
width = bbox[2] - bbox[0]
aspect_ratio = height / width
# ortho 表示正脸,side 表示侧脸
face_type = "ortho" if 1 < aspect_ratio < 1.5 else "side"
# 裁剪人脸区域并转换为 Base64 编码字符串
# 从原图裁剪人脸区域
face_img = img[bbox[1]:bbox[3], bbox[0]:bbox[2]]
# 编码为JPG格式
_, buffer = cv2.imencode('.jpg', face_img)
# 转换为Base64字符串
face_base64 = base64.b64encode(buffer).decode('utf-8')
# 整理人脸信息字典:包含帧索引、边界框、嵌入向量、聚类 ID(初始为 - 1)和额外数据
face_info = {
"frame_id": frame_idx,
"bounding_box": bbox,
"face_emb": embedding,
"cluster_id": -1,
"extra_data": {
"face_type": face_type,
"face_base64": face_base64,
"face_detection_score": str(dscore),
"face_quality_score": str(qscore)
},
}
frame_faces.append(face_info)
return frame_faces
except Exception as e:
print(f"处理图片 {frame_idx} 时出错: {str(e)}")
return []
indexed_inputs = list(enumerate(image_list))
with ThreadPoolExecutor(max_workers=num_workers) as executor:
# tqdm用于显示处理进度条,提升用户体验
# tqdm 跟踪多线程处理图像的进度:executor.map 会并行处理 indexed_inputs 中的所有图像(即 image_list 中的所有图像)
# tqdm 包裹它后,会实时显示 “已处理图像数 / 总图像数”
# 由于 executor.map 是生成器,tqdm 无法自动获取总任务数,需要手动指定 total 为图像列表的长度,才能正确计算进度百分比和剩余时间
#
# 提升用户体验:在处理大量图像时(如几十 / 几百张),进度条可以避免 “黑屏等待”,让开发者清楚知道任务是否在正常运行、还需等待多久
for frame_faces in tqdm(
executor.map(process_image, indexed_inputs), total=len(image_list)
):
faces.extend(frame_faces)
return faces
人脸检测的核心信息提取与标准化处理逻辑,它在 “检测到人脸” 的基础上,进一步补充了人脸的关键特征、质量评估、类型分类和可视化数据,为后续的人脸分析(如聚类、识别、筛选)提供标准化的结构化数据。
边界框坐标标准化:从 “算法输出” 到 “可用格式”
人脸检测算法(face_app.get(img))返回的 face.bbox 通常是浮点型数组(如 [x1, y1, x2, y2],代表人脸矩形框的左上角和右下角坐标)
但图像裁剪、坐标存储需要整数格式,因此标准化如下:
face.bbox.astype(int):将浮点型坐标强制转换为整数(如 320.8 → 320),避免后续裁剪时因小数坐标报错.tolist() + [int(x) for x in ...]:将 NumPy 数组转为 Python 列表,同时二次确认整数类型(防止算法输出格式异常)
最终得到的 bbox 是标准的整数列表 [x1, y1, x2, y2],可直接用于 OpenCV 图像裁剪(如img[bbox[1]:bbox[3], bbox[0]:bbox[2]])
检测置信度(dscore):判断 “是否真的是人脸”
dscore = face.det_score 提取的是人脸检测算法自带的置信度分数,核心作用是评估 “检测到的区域是人脸的概率”:
- 取值范围通常为 [0, 1](或 [0, 100],取决于算法),分数越高,说明该区域是 “真实人脸” 的可信度越高
- 可基于 dscore 筛选有效人脸(如过滤 dscore < 0.8 的低置信度结果,避免把 “误检的背景区域” 当作人脸)
人脸嵌入向量(embedding):给人脸 “生成唯一特征码”
embedding = [float(x) for x in face.normed_embedding.tolist()] 提取的是标准化人脸嵌入向量,这是人脸 “数字身份” 的核心:
什么是嵌入向量?
人脸算法会将人脸图像的特征(如五官位置、轮廓、纹理)压缩成一个固定长度的数值数组(如 128 维、256 维),该数组就是 “嵌入向量”
相似的人脸,嵌入向量的数值差异小;不同的人脸,差异大,可用于后续的人脸聚类(分组相同人脸)、人脸识别(匹配已知人脸)
为什么用 normed_embedding?
“标准化嵌入向量”(Normed Embedding)是对原始嵌入向量做了 “L2 归一化” 处理,确保向量的模长为 1
这样后续计算向量相似度(如余弦相似度)时结果更稳定,不受图像尺寸、亮度等因素干扰
格式转换:
从 NumPy 数组转为 Python 浮点列表,方便后续 JSON 序列化(如网络传输、存储到数据库)
质量分数(qscore):评估 “人脸质量好不好”
qscore = np.linalg.norm(embedding_np, ord=2) 是自定义的人脸质量评估指标
核心作用是判断 “人脸图像是否清晰、完整”(质量差的人脸可能影响后续聚类 / 识别效果):
计算逻辑:
通过 NumPy 的 linalg.norm 计算原始嵌入向量(face.embedding)的L2 范数(即向量的 “模长”,所有元素平方和的平方根)
原理:
质量好的人脸(清晰、正脸、无遮挡),其嵌入向量的特征更 “突出”,模长通常在一个合理区间内
质量差的人脸(模糊、侧脸严重、遮挡多),特征不明显,模长可能过大或过小
与 dscore 的区别:
dscore 评估 “是不是人脸”,是 “存在性” 判断;
qscore 评估 “人脸质量好不好”,是 “可用性” 判断。
例如:一张模糊的人脸,dscore 可能很高(算法确定是人脸),但 qscore 很低(质量差,不适合后续处理)。
人脸类型分类(face_type):区分 “正脸 / 侧脸”
通过边界框的宽高比(aspect_ratio) 实现简单的正脸 / 侧脸分类,核心是利用 “正脸和侧脸的矩形框形状差异”:
计算逻辑:
边界框高度 height = bbox[3] - bbox[1](y2 - y1)
边界框宽度 width = bbox[2] - bbox[0](x2 - x1)
宽高比 aspect_ratio = height / width(高度除以宽度)
分类规则:
正脸(ortho):宽高比在 1 ~ 1.5 之间(正脸的高度和宽度相对接近,不会特别 “瘦长” 或 “扁平”)
侧脸(side):宽高比超出 1 ~ 1.5 范围(侧脸的高度通常远大于宽度,导致宽高比偏大;或因拍摄角度导致宽度过大,宽高比偏小)
实际价值:
后续处理中可针对性优化(如正脸更适合人脸识别,侧脸适合场景分析),也可用于筛选(如仅保留正脸数据)
人脸图像 Base64 编码:便于 “存储与传输”
face_base64 = base64.b64encode(buffer).decode('utf-8') 将裁剪后的人脸图像转为 Base64 字符串,解决 “二进制图像数据的文本化处理” 问题:
处理流程:
第一步:cv2.imencode('.jpg', face_img) 将裁剪后的人脸图像编码为 JPG 格式的二进制缓冲区(buffer),压缩图像体积
第二步:base64.b64encode(buffer) 将二进制数据转为 Base64 字节串
第三步:.decode('utf-8') 将字节串转为 UTF-8 字符串
核心优势:
Base64 字符串可直接嵌入 JSON、XML 等文本格式中(如通过 API 传输给前端展示),也可直接存储到数据库(无需单独处理二进制文件),避免了 “图像文件路径管理” 的麻烦
例如:前端拿到 face_base64 后,可通过 <img src="data:image/jpeg;base64,{face_base64}"> 直接渲染人脸图像
核心价值
它将人脸检测算法的 “原始输出”(仅包含边界框和基础特征),加工成结构化、可解释、可复用的人脸信息字典
涵盖了 “位置、可靠性、特征、质量、类型、可视化”6 大维度
相当于为每一张检测到的人脸 “建立了完整的信息档案”,是连接 “人脸检测” 和 “下游应用(聚类、识别、筛选)” 的关键桥梁
mmagent/src/face_clustering.py(人脸聚合)
对提取的人脸信息(含 128 维特征向量)进行聚类分组—— 将 “属于同一人的人脸” 归为同一类别,同时过滤低质量人脸以保证聚类准确性
数据准备→质量筛选→聚类计算→结果整理
# Copyright (2025) Bytedance Ltd. and/or its affiliates
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import numpy as np
import hdbscan
# faces:输入的人脸信息列表
# 每个元素是之前 extract_faces 函数输出的 face_info 字典(含 face_emb 特征向量、face_type 人脸类型、检测 / 质量分数等)
#
# min_cluster_size:
# 聚类的 “最小簇规模”,即一个有效聚类(同一人)至少需要包含的人脸数量,默认值为 2(避免单张人脸形成无意义聚类)
#
# distance_threshold:
# 代码中未直接使用(预留参数),用于后续扩展 “距离阈值筛选”(如过滤聚类内距离过大的异常值)
def cluster_faces(faces, min_cluster_size=2, distance_threshold=0.5):
face_embeddings = []
face_types = []
face_indices = []
face_detection_scores = []
face_quality_scores = []
# 【数据提取 —— 从人脸信息中拆分关键特征】
for i, face in enumerate(faces):
# 128维人脸特征向量(核心聚类依据)
face_embeddings.append(face["face_emb"])
# 正脸/侧脸类型(未直接用,预留)
face_types.append(face["extra_data"]["face_type"])
# 人脸在原始列表中的索引(未直接用,预留)
face_indices.append(i)
# # 检测置信度
face_detection_scores.append(float(face["extra_data"]["face_detection_score"]))
# 质量分数(L2范数)
face_quality_scores.append(float(face["extra_data"]["face_quality_score"]))
# 将 face_embeddings 转为 NumPy 数组(np.array),因为后续矩阵运算(如相似度计算)需要 NumPy 格式支持
face_embeddings = np.array(face_embeddings)
# 【质量筛选 —— 过滤低质量人脸,提升聚类准确性】
# detection_threshold = 0.8:检测置信度≥0.8 的人脸才视为 “有效人脸”(排除误检的背景区域)
# quality_threshold = 20:质量分数(特征向量 L2 范数)≥20 的人脸才视为 “高质量人脸”(排除模糊、特征不稳定的人脸)
detection_threshold = 0.8
quality_threshold = 20
# good_mask:布尔列表,True 表示该人脸 “同时满足检测和质量阈值”(高质量有效人脸)
# bad_mask:布尔列表,True 表示该人脸 “至少一项不满足阈值”(低质量人脸,需排除出聚类)
good_mask = [(face_detection_scores[i] >= detection_threshold and face_quality_scores[i] >= quality_threshold) for i in range(len(face_types))]
bad_mask = [(face_detection_scores[i] < detection_threshold or face_quality_scores[i] < quality_threshold) for i in range(len(face_types))]
# 用于聚类的高质量特征向量
# NumPy 数组的布尔索引(Boolean Indexing) 特性,专门用于从二维数组中筛选出 “符合条件的行 / 列”
# 核心逻辑是 “True 对应位置的元素保留,False 对应位置的元素剔除”
good_embeddings = face_embeddings[good_mask]
# 低质量特征向量,不参与聚类
bad_embeddings = face_embeddings[bad_mask]
# 初始化 all_labels 所有人脸默认标签为 -1(未聚类)
all_labels = [-1] * len(face_types)
max_label = -1
# 【聚类计算 —— 用 HDBSCAN 算法对高质量人脸分组】
# 采用 HDBSCAN 算法(层次密度聚类)对高质量特征向量进行聚类
# HDBSCAN 适合 “无预设聚类数量” 的场景(如不知道视频中有多少人)且能自动识别 “噪声点”(不属于任何聚类的异常人脸)
if len(good_embeddings) >= min_cluster_size:
#(1)计算特征向量的 “距离矩阵”
# 聚类需要 “衡量人脸之间的相似度”,通过以下相似度计算步骤将特征向量转为 “距离”:
# 由于 good_embeddings 是归一化后的 128 维向量(模长 = 1),向量点积(dot)的结果等价于 “余弦相似度”,取值范围为 [-1, 1]
# 值越接近 1,两张人脸的相似度越高
# 通过矩阵点积运算,批量计算所有高质量人脸特征向量之间的相似度,得到一个 “相似度矩阵”,为后续聚类的 “距离计算” 提供基础
good_similarity = np.dot(good_embeddings, good_embeddings.T) # good_embeddings.T 是原向量的转置,dot是用于计算点积
# good_similarity 是一个点积矩阵,也是余弦相似值
# 距离转换:good_distances = 1 - good_similarity
# 将相似度转为 “距离”(相似度越高→距离越小),取值范围为 [0, 2]
# 用标量 1 减去 good_similarity 这个 M×M 矩阵中的每一个元素,属于 NumPy 中的 “广播运算(Broadcasting)” 特性
# 无需手动遍历矩阵元素,直接通过简洁的语法完成批量计算,同时保持矩阵的形状不变(仍为 M×M)
good_distances = 1 - good_similarity
# 后续 np.maximum(good_distances, 0) 是 “防负处理”(避免浮点误差导致的极小负值,确保距离非负)
good_distances = np.maximum(good_distances, 0).astype(np.float64)
# 经过这三行代码处理后,good_distances 既不是单个值,也不是一维向量,而是一个 M×M 的二维 NumPy 数组(距离矩阵)
#(2)HDBSCAN 聚类执行
good_clusterer = hdbscan.HDBSCAN(
min_cluster_size=min_cluster_size, # 每个有效簇至少含2张人脸
metric="precomputed" # 表示输入的是“预计算好的距离矩阵”(而非原始特征向量)
)
# 执行聚类,得到每个高质量人脸的“簇标签”
# 簇标签(good_labels)含义:
# 整数(如 0、1、2):表示该人脸属于第 N 个簇(同一整数代表同一人)
# -1:表示该人脸是 “噪声点”(不属于任何簇,可能是偶尔出现的路人脸)
good_labels = good_clusterer.fit_predict(good_distances)
# (3)记录最大簇标签
# 记录所有有效簇的最大标签(如聚类出 3 个簇,标签为 0、1、2,max_label=2)
# 后续可用于扩展 “簇数量统计”
max_label = (
max(good_labels)
if len(good_labels) > 0 and max(good_labels) > -1
else -1
)
# 【标签映射 —— 将聚类结果关联回原始人脸列表】
# 之前的聚类仅针对 “高质量人脸”,需要将聚类标签(good_labels)映射到原始 faces 列表每个元素,同时低质量人脸的标签设为默认的 -1
good_idx = 0
for i, is_good in enumerate(good_mask):
if is_good:
# 赋值聚类标签
all_labels[i] = good_labels[good_idx]
good_idx += 1
result_faces = []
# 返回的 result_faces 中,同一人的人脸会有相同的 cluster_id(如 0、1),低质量或噪声人脸的 cluster_id 为 -1
# 遍历原始 faces 列表,为每个 face_info 字典添加 cluster_id(聚类标签),生成最终结果
for i, face in enumerate(faces):
face_copy = face.copy()
# 写入聚类标签
face_copy["cluster_id"] = all_labels[i]
result_faces.append(face_copy)
return result_faces
为什么用 HDBSCAN 而不是 K-Means
K-Means 需要提前指定聚类数量(K 值),但视频中 “有多少人” 是未知的,HDBSCAN 无需预设 K 值,能自动发现簇数量
HDBSCAN 能识别 “噪声点”( -1 标签),适合处理 “有路人脸混入” 的场景,而 K-Means 会强制将所有点分配到某个簇,导致聚类误差
HDBSCAN 对 “非球形簇”(如同一人不同角度的人脸形成的不规则分布)适应性更强,聚类准确性更高
归一化特征向量的作用
代码中 face_emb 是归一化后的 128 维向量(来自 extract_faces 中的 normed_embedding),这使得 “点积 = 余弦相似度” 的计算成立
若未归一化,点积结果会受向量模长影响,无法直接代表相似度,进而导致距离计算错误
低质量人脸的处理逻辑
低质量人脸(bad_mask 为 True)不参与聚类,其 cluster_id 保持 -1
后续应用中可过滤这些人脸(如仅保留有有效 cluster_id 的人脸进行分析),避免干扰结果
函数整体作用
cluster_faces 是 “人脸分析流水线” 的核心环节,承上启下:
承上:接收 extract_faces 输出的结构化人脸数据,筛选高质量样本;
启下:通过 HDBSCAN 聚类,为 “同一人的人脸” 分配相同 cluster_id,后续可基于该标签做进一步分析(如:统计视频中出现的人数、提取某个人的所有人脸帧、生成人物轨迹等)。
例如:
视频中出现 A、B 两个人,聚类后 A 的所有人脸 cluster_id=0,B 的所有人脸 cluster_id=1,路人脸 cluster_id=-1
后续可轻松筛选出 A 或 B 的所有人脸数据。
mmagent/utils/video_processing.py(视频处理工具函数)
consecutive kənˈsekjətɪv kənˈsekjətɪv 连续的,不间断的
视频处理和验证,包含获取视频信息、提取帧、处理视频片段以及验证视频分割结果等功能
# Copyright (2025) Bytedance Ltd. and/or its affiliates
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import base64
import logging
import os
import tempfile
import math
# cv2(OpenCV):用于视频帧处理
import cv2
# numpy:用于数值计算
import numpy as np
# moviepy:用于视频文件处理
from moviepy import VideoFileClip
# subprocess:用于调用外部命令(如 ffprobe)
import subprocess
# Disable moviepy logging
logging.getLogger('moviepy').setLevel(logging.ERROR)
# Disable moviepy's tqdm progress bar
logging.getLogger('moviepy.video.io.VideoFileClip').setLevel(logging.ERROR)
logging.getLogger('moviepy.audio.io.AudioFileClip').setLevel(logging.ERROR)
# Configure logging
logger = logging.getLogger(__name__)
# 获取视频 / 音频文件的基本信息,返回包含媒体元数据的字典
def get_video_info(file_path):
"""Get video/audio information using appropriate libraries.
Args:
file_path (str): Path to video or audio file
Returns:
dict: Dictionary containing media metadata
"""
file_info = {}
file_info["path"] = file_path
file_info["name"] = file_path.split("/")[-1]
file_info["format"] = os.path.splitext(file_path)[1][1:].lower()
# Handle video files using moviepy
# 使用 moviepy 的 VideoFileClip 获取视频属性:
# 帧率 (fps)、总帧数、时长、宽度和高度
video = VideoFileClip(file_path) # Disable logging for this instance
# Get basic properties from moviepy
file_info["fps"] = video.fps
file_info["frames"] = int(video.fps * video.duration)
file_info["duration"] = video.duration
file_info["width"] = video.size[0]
file_info["height"] = video.size[1]
video.close()
return file_info
# 从视频中按指定间隔提取帧,并转换为 base64 编码的 JPG 格式,默认一秒抽10帧,目前行业上25fps(老电影)~120fps(游戏)
def extract_frames(video, start_time=None, interval=None, sample_fps=10):
# if start_time and interval are not provided, sample the whole video at sample_fps
if start_time is None and interval is None:
start_time = 0
interval = video.duration
frames = []
# 采样间隔
frame_interval = 1.0 / sample_fps
# Extract frames at specified intervals
# np.arange():这是 NumPy 库的函数,用于生成一个等差数列(均匀间隔的数值序列)
# 视频帧 → 格式转换 → JPG 编码 → Base64 编码 → 存储
for t in np.arange(start_time, min(start_time + interval, video.duration), frame_interval):
# 得到的frame通常是 RGB 格式的图像数组(三维数组,包含像素的颜色信息)
frame = video.get_frame(t)
# Convert frame to jpg and base64
# 使用 OpenCV 的颜色空间转换函数,将 RGB 格式的帧转换为 BGR 格式
# 这是因为 OpenCV 默认处理的图像格式是 BGR,而视频帧可能以 RGB 格式返回,需要统一格式才能正确编码
# 将转换后的 BGR 图像编码为 JPG 格式的二进制数据
# 返回值是一个元组(retval, buffer),retval是布尔值表示编码是否成功,buffer是编码后的 JPG 二进制数据(numpy 数组)
_, buffer = cv2.imencode(".jpg", cv2.cvtColor(frame, cv2.COLOR_RGB2BGR))
# 先将 JPG 二进制数据通过 Base64 编码转换为字节串,再通过decode("utf-8")转换为字符串形式
# Base64 编码可以将二进制数据转换为可打印的 ASCII 字符,方便在文本协议(如 JSON、HTML)中传输图像数据
frames.append(base64.b64encode(buffer).decode("utf-8"))
return frames
# 处理视频文件并提取其视频、帧图像和音频数据,并将这些数据转换为 Base64 编码格式
# video_path:视频文件的路径,是函数处理的输入源
# fps=5:提取视频帧的帧率(每秒提取的帧数),默认值为 5
# audio_fps=16000:音频的采样率,默认值为 16kHz(适合语音处理的常见采样率)
# 返回:
# 视频流video、音频流audio、视频抽帧frames
def process_video_clip(video_path, fps=5, audio_fps=16000):
try:
base64_data = {}
# 使用VideoFileClip(video_path)加载视频文件
video = VideoFileClip(video_path)
# 读取整个视频文件的二进制数据并进行 Base64 编码,存储到base64_data["video"]
base64_data["video"] = base64.b64encode(open(video_path, "rb").read())
# 调用extract_frames函数按照指定的sample_fps(即fps参数)从视频中提取帧,存储到base64_data["frames"]
base64_data["frames"] = extract_frames(video, sample_fps=fps)
# 首先检查视频是否包含音频(video.audio is None)
if video.audio is None:
base64_data["audio"] = None
else:
# 创建临时 WAV 文件(tempfile.NamedTemporaryFile)
# 将视频中的音频提取出来,按指定采样率(audio_fps)和 PCM 编码(pcm_s16le,16 位线性 PCM,无损编码)写入临时文件
# 读取临时文件的二进制数据并进行 Base64 编码,存储到base64_data["audio"]
with tempfile.NamedTemporaryFile(suffix=".wav") as audio_tempfile:
video.audio.write_audiofile(audio_tempfile.name, codec="pcm_s16le", fps=audio_fps)
audio_tempfile.seek(0)
base64_data["audio"] = base64.b64encode(audio_tempfile.read())
video.close()
return base64_data["video"], base64_data["frames"], base64_data["audio"]
except Exception as e:
logger.error(f"Error processing video clip: {str(e)}")
raise
# 验证视频是否被正确分割为多个片段,通过检查片段数量及(可选的)严格条件(如音视频流完整性、是否包含静态片段)来判断处理是否成功
def verify_video_processing(video_path, output_dir, interval, strict=False):
"""Verify that a video was properly split into clips by checking the number of clips.
Args:
video_path (str): Path to original video file
# 包含分割后视频片段的目录
output_dir (str): Directory containing the split clips
# 分割视频时使用的时间间隔(秒)
interval (float): Interval length in seconds used for splitting
Returns:
bool: True if verification passes, False otherwise
"""
# 检查视频文件是否同时包含视频流和音频流
def has_video_and_audio(file_path):
def has_stream(stream_type):
# 使用 ffprobe 工具(FFmpeg 的组件)检查文件中是否存在指定类型的流
# 当视频同时包含视频流和音频流时返回 True,否则返回 False
# -v error:仅输出错误信息
# -select_streams stream_type:选择要检查的流类型(v:0 表示第一个视频流,a:0 表示第一个音频流)
# -show_entries stream=codec_name:仅显示流的编码名称
# 若命令输出非空字符串,则表示存在该类型的流
result = subprocess.run(
["ffprobe", "-v", "error", "-select_streams", stream_type,
"-show_entries", "stream=codec_name", "-of", "default=noprint_wrappers=1:nokey=1", file_path],
capture_output=True, text=True
)
return bool(result.stdout.strip())
return has_stream("v:0") and has_stream("a:0")
# 检查视频中是否包含长时间的静态片段(画面无变化的片段)
# min_static_duration:最小静态片段时长(秒),默认 5 秒
# diff_threshold:帧差异阈值,低于此值认为帧无变化
def has_static_segment(
video_path,
min_static_duration=5.0,
diff_threshold=0.001,
) -> bool:
# 使用 OpenCV 打开视频文件
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
raise IOError(f"Cannot open {video_path}")
# 计算视频帧率(fps)和总帧数
fps = cap.get(cv2.CAP_PROP_FPS)
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 将最小静态时长转换为对应的帧数(min_static_frames)
min_static_frames = int(min_static_duration * fps)
prev_gray = None
consecutive_static_frames = 0
# 逐帧处理:
# 将当前帧转换为灰度图
# 与前一帧计算差异(cv2.absdiff)并求平均差异值
# 若连续差异值低于阈值的帧数达到 min_static_frames,则判定存在静态片段
for _ in range(frame_count):
ret, frame = cap.read()
if not ret:
break
# 将当前帧转换为灰度图
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 与前一帧计算差异(cv2.absdiff)并求平均差异值
if prev_gray is not None:
# 像素值越大表示两帧对应位置的亮度变化越明显,像素值为 0 表示完全没有变化
diff = cv2.absdiff(prev_gray, gray)
# 对差异图像 diff 中的所有像素值求平均,得到一个标量 mean_diff
# 值越接近 0,表示两帧画面越相似(变化越小)
# 值越大,表示两帧画面差异越明显(变化越大)
mean_diff = np.mean(diff)
# 若连续差异值低于阈值的帧数达到 min_static_frames,则判定存在静态片段
if mean_diff < diff_threshold:
consecutive_static_frames += 1
if consecutive_static_frames >= min_static_frames:
cap.release()
return True
else:
consecutive_static_frames = 0
prev_gray = gray
cap.release()
return False
try:
# 检查原始视频文件是否存在,不存在则记录错误日志并返回 False
if not os.path.exists(video_path):
with open("logs/video_processing_failed.log", "a") as f:
f.write(f"Error processing {video_path}: Video file not found.\n")
logger.error(f"Error processing {video_path}: Video file not found.")
return False
# Get expected number of clips based on video duration
# 调用 get_video_info 函数获取视频信息(包含时长)
video_info = get_video_info(video_path)
# 计算预期的片段数量:预期片段数 = 视频时长 ÷ 分割间隔(向上取整)
expected_clips_num = math.ceil(int(video_info["duration"]) / interval)
# Get actual number of clips in output directory
clip_dir = output_dir
# 外部指定的 clip_dir 必须存在
if not os.path.exists(clip_dir):
with open("logs/video_processing_failed.log", "a") as f:
f.write(f"Error processing {video_path}: Clip directory {clip_dir} not found.\n")
logger.error(f"Error processing {video_path}: Clip directory {clip_dir} not found.")
return False
# 统计目录中实际的视频片段数量(仅统计 mp4、mov、webm 格式)
actual_clips = [f for f in os.listdir(clip_dir) if os.path.isfile(os.path.join(clip_dir, f)) and f.split('.')[-1] in ['mp4', 'mov', 'webm']]
actual_clips_num = len(actual_clips)
# 对比实际片段数与预期片段数,不相等则记录错误并返回 False
if actual_clips_num != expected_clips_num:
with open("logs/video_processing_failed.log", "a") as f:
f.write(f"Error processing {video_path}: Expected {video_info['duration']}/{interval}={expected_clips_num} clips, but found {actual_clips_num} clips.\n")
logger.error(f"Error processing {video_path}: Expected {video_info['duration']}/{interval}={expected_clips_num} clips, but found {actual_clips_num} clips.")
return False
# 严格模式
if strict:
# 对每个视频片段进行额外检查
clip_files = [os.path.join(clip_dir, clip) for clip in actual_clips]
for clip_file in clip_files:
clip_id = clip_file.split("/")[-1].split(".")[0]
# 调用 has_video_and_audio 检查是否同时包含视频流和音频流
if not has_video_and_audio(clip_file):
with open("logs/video_processing_failed.log", "a") as f:
f.write(f"Error processing {clip_file}: No video or audio streams found.\n")
logger.error(f"Error processing {clip_file}: No video or audio streams found.")
return False
# 检查除最后两个片段外的所有片段是否包含静态片段(通过 has_static_segment)
if int(clip_id) < len(clip_files)-2 and has_static_segment(clip_file):
with open("logs/video_processing_failed.log", "a") as f:
f.write(f"Error processing {clip_file}: Has static segment.\n")
logger.error(f"Error processing {clip_file}: Has static segment.")
return False
return True
except Exception as e:
with open("logs/video_processing_failed.log", "a") as f:
f.write(f"Error verifying {video_path}: {e}\n")
logger.error(f"Error verifying {video_path}: {e}")
return False
m3_agent/memorization_memory_graphs.py 记忆图构建器
读取目录下的短视频片段 → 提取人脸/语音/画面 → 生成并存储记忆图,为后续检索/问答/推荐等下游任务做数据准备
(1)把一批已经切分好的视频片段(clips)逐一读取
(2)对每段片段做人脸、语音、画面内容的多模态分析
(3)把分析结果转换成“情景记忆(episodic memories)”和“语义记忆(semantic memories)”
(4)把这些记忆节点写进一个 VideoGraph 图数据库
(5)最后把整图序列化到磁盘,供其他模块使用
# Copyright (2025) Bytedance Ltd. and/or its affiliates
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import json
import logging
import argparse
import glob
import pickle
# VideoGraph:图数据库,存节点(人脸、语音、记忆)和边(等价、时序等)
# process_video_clip:把本地 clip 编码成 base64 的视频流、帧序列、音频
from mmagent.videograph import VideoGraph
from mmagent.utils.video_processing import process_video_clip
# process_faces:对帧做人脸检测,返回 id→face 的 dict
# process_voices:对音频做说话人识别,返回 id→voice 的 dict
from mmagent.face_processing import process_faces
from mmagent.voice_processing import process_voices
# process_memories:把记忆 JSON 真正写进 VideoGraph
# generate_memories:根据帧、人脸、语音生成两类记忆 JSON
from mmagent.memory_processing_qwen import process_memories, generate_memories
logger = logging.getLogger(__name__)
# 参数配置
processing_config = json.load(open("configs/processing_config.json"))
memory_config = json.load(open("configs/memory_config.json"))
# 预处理,预留
preprocessing = []
# 一次处理一个 clip 的全部流程
def process_segment(
video_graph,
base64_video,
base64_frames,
base64_audio,
clip_id,
sample,
clip_path
):
save_path = sample["intermediate_outputs"]
# process_voices → id2voices.json
id2voices = process_voices(
video_graph,
base64_audio,
base64_video,
save_path=os.path.join(save_path, f"clip_{clip_id}_voices.json"),
preprocessing=[],
)
# process_faces → id2faces.json
id2faces = process_faces(
video_graph,
base64_frames,
save_path=os.path.join(save_path, f"clip_{clip_id}_faces.json"),
preprocessing=[],
)
# episodic_memories:事件级记忆(谁在什么时间做了什么)
# semantic_memories:概念级记忆(人物属性、场景类别等)
episodic_memories, semantic_memories = generate_memories(
base64_frames,
id2faces,
id2voices,
clip_path,
)
# 把记忆节点写入图
process_memories(video_graph, episodic_memories, clip_id, type="episodic")
process_memories(video_graph, semantic_memories, clip_id, type="semantic")
# 以指定时间间隔和帧率(specified intervals with given fps)处理视频片段
# 参数
# video_graph (VideoGraph):用于存储 video 信息的图对象
# 返回值
# None:函数就地更新 video_graph,把处理后的片段信息(segments)写入其中
# sample 字典,至少包含
# "clip_path":一个目录,里面放的是已经切好的视频片段(如 00001.mp4、00002.mp4 …)
# "mem_path":最终图对象要保存到的 pickle 文件路径
def streaming_process_video(video_graph, sample):
"""Process video segments at specified intervals with given fps.
Args:
video_graph (VideoGraph): Graph object to store video information
Returns:
None: Updates video_graph in place with processed segments
"""
# 扫描片段,列出目录下所有文件
clips = glob.glob(sample["clip_path"] + "/*")
# 逐个处理
for clip_path in clips:
# 从文件名提取数字作为 clip_id(00023.mp4 → 23)
clip_id = int(clip_path.split("/")[-1].split(".")[0])
# process_video_clip(clip_path) 把视频转成:
# base64_video:整段视频的 base64 字符串
# base64_frames:帧序列 base64 列表
# base64_audio:音频 base64
base64_video, base64_frames, base64_audio = process_video_clip(clip_path)
# 只要拿到帧,就调用 process_segment(...) 完成“人脸-语音-记忆”整条流水线
# Process frames for this interval
if base64_frames:
process_segment(
video_graph,
base64_video,
base64_frames,
base64_audio,
clip_id,
sample,
clip_path
)
# 在图内做节点合并、等价关系更新
video_graph.refresh_equivalences()
# 用 pickle.dump 把整图写入 sample["mem_path"],后续可直接 pickle.load 复用
with open(sample["mem_path"], "wb") as f:
pickle.dump(video_graph, f)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--data_file", type=str, default="data/data.jsonl")
args = parser.parse_args()
video_inputs = []
with open(args.data_file, "r") as f:
for line in f:
sample = json.loads(line)
if not os.path.exists(sample["mem_path"]):
video_graph = VideoGraph(**memory_config)
streaming_process_video(video_graph, sample)
m3-agent/visualization.py(记忆图谱可视化)
affiliates əˈfɪlieɪts; əˈfɪliəts 附属公司;联播电台
in compliance with kəmˈplaɪəns 遵守(条约),按照
加载并可视化记忆图谱(VideoGraph)中指定片段(clip_id)的记忆信息:
包括文本记忆(episodic/semantic,情景记忆 / 语义记忆)、关联的人脸和语音数据
通过命令行参数指定记忆图谱路径和片段 ID,输出格式化的记忆内容
# Copyright (2025) Bytedance Ltd. and/or its affiliates
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import pprint
import pickle
import argparse
from mmagent.retrieve import translate
ONLY = None # "episodic" / "semantic" / None(all)
MAX_LEN = None # How many characters are displayed in one line, None for no truncation
SHOW_FACES = True # False if there is no graphical environment
# 打印指定片段的完整记忆信息
# only: str | None = None 这种参数的含义是:是一个字符串,可选,默认为None
def print_clip_full(vg, clip_id:int, only:str|None=None, max_len:int|None=None, show_faces:bool = True)->None:
# 获取该片段对应的文本节点
node_ids = vg.text_nodes_by_clip.get(clip_id)
if not node_ids:
print(f"[Warning] clip_id={clip_id} 不存在或无文本节点")
return
print(f"\n======= 片段 {clip_id} 记忆 =======")
# 打印文本节点信息( episodic/semantic 类型)
for nid in node_ids:
node = vg.nodes[nid]
if only and node.type != only:
continue
contents = node.metadata.get("contents", [])
contents = translate(vg, contents) # 翻译内容(如需要)
contents = [truncate(c, max_len) for c in contents] # 截断长文本
# 使用print(f"...")的 f-string 格式化字符串语法,将多个元素组合成一行输出
# [{node.type:^8}]部分:
# node.type:获取节点的类型属性值
# :^8:格式化指令,表示居中对齐(^),总宽度为 8 个字符
# 外层[]:将类型信息用方括号包裹,最终类似[ VIDEO ]这样的效果
# id={nid:<4}部分:
# nid:节点 ID 变量
# :<4:格式化指令,表示左对齐(<),总宽度为 4 个字符
# 输出类似id=123 (如果 nid 是 123,会补一个空格到 4 位宽度)
# pprint.pformat(contents, compact=True)部分:
# pprint是 Python 的 Pretty Print 模块,用于格式化输出复杂数据结构
# pformat()将数据转换为格式化的字符串
# contents是要打印的具体内容(可能是字典、列表等复杂结构)
# compact=True参数让输出更紧凑,适合在单行显示更多内容
print(f"[{node.type:^8}] id={nid:<4} | " + pprint.pformat(contents, compact=True))
# 关联的人脸和语音节点
face_nodes, voice_nodes = set(), set()
for nid in node_ids:
face_nodes.update(vg.get_connected_nodes(nid, type=['img']))
voice_nodes.update(vg.get_connected_nodes(nid, type=['voice']))
# 打印人脸节点信息
if face_nodes:
print(f"\n======= 片段 {clip_id} 人脸(共 {len(face_nodes)} 个) =======")
if show_faces:
vg.print_faces(face_nodes, print_num=3) # 显示人脸(图形化)
else:
for fid in face_nodes:
imgs = vg.nodes[fid].metadata.get("contents", [])
print(f"[face] id={fid:<4}|数量={len(imgs)}|base64:{imgs[0][:50]+'…' if imgs else 'N/A'}")
else:
print("\n(无相关人脸)")
# 打印语音节点信息
if voice_nodes:
print(f"\n======= 片段 {clip_id} 语音(共 {len(voice_nodes)} 个) =======")
for vid in voice_nodes:
audios = vg.nodes[vid].metadata.get("contents", [])
print(f"[voice]id={vid:<4}|数量={len(audios)}|内容:{truncate(str(audios[0]), max_len) if audios else 'N/A'}")
else:
print("\n(无相关语音)")
# 主函数:加载记忆图谱并可视化指定片段
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--mem_path", type=str, default="data/memory_graphs/robot/bedroom_01.pkl")
parser.add_argument("--clip_id", type=int, default=0)
args = parser.parse_args()
with open(args.mem_path, "rb") as f:
# pickle 是 Python 标准库中模块,主要用于实现对象的序列化(serialization)和反序列化(deserialization)
# 核心功能:
# 序列化(pickling):将 Python 对象(如字典、列表、类实例等)转换为字节流,便于存储到文件或通过网络传输
# 反序列化(unpickling):将字节流恢复为原来的 Python 对象
graph = pickle.load(f)
graph.refresh_equivalences()
print_clip_full(graph, clip_id=args.clip_id, only=ONLY, max_len=MAX_LEN, show_faces=SHOW_FACES)
附录
帧率

FFmpeg
介绍
FFmpeg 是一套功能极强的跨平台音视频处理工具集,几乎涵盖了音视频编解码、转换、剪辑、封装、流媒体传输等所有核心环节,被广泛应用于专业软件(如 Adobe 系列、剪映)、服务器流媒体服务(如直播平台)、嵌入式设备(如监控摄像头)等场景,是音视频领域的 “基础设施级” 工具。
FFmpeg 并非单一工具,而是由 4 个核心部分 组成,各自承担不同职责,协同完成音视频处理:
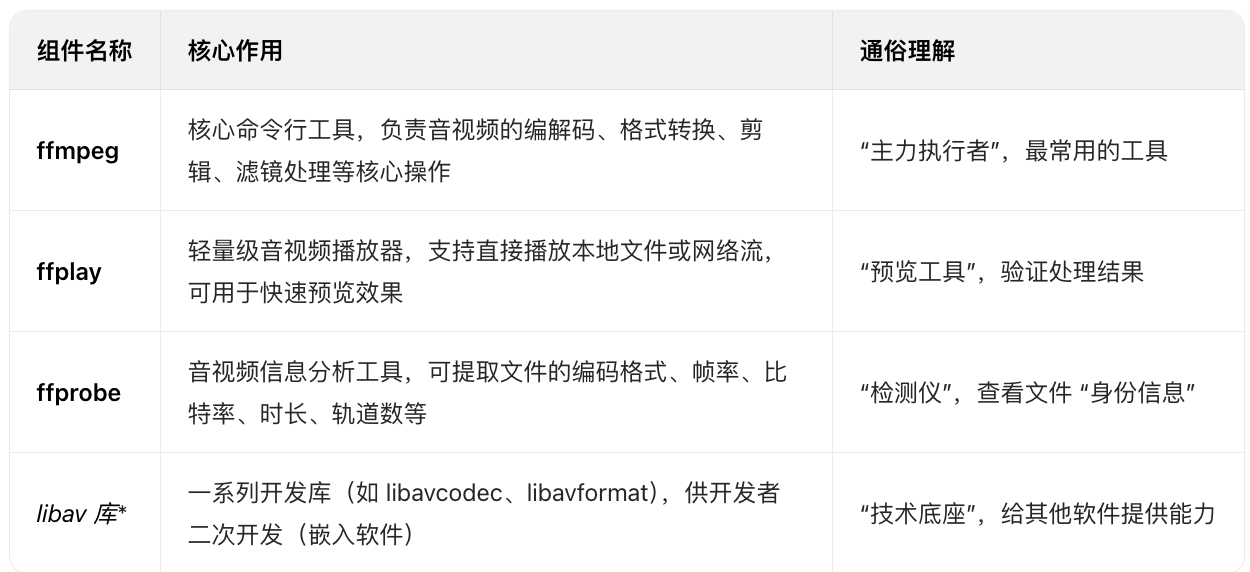
核心功能
- 音视频格式转换(封装 / 解封装)
音视频文件的 “格式”(如 MP4、MKV、FLV)本质是封装格式(容器),内部包含视频流(如 H.264)、音频流(如 AAC)。
FFmpeg 可实现 “不重新编码” 的快速格式转换(仅换容器),或 “重新编码” 的深度转换(适配设备兼容性)。
示例:将 MKV 格式转为 MP4(快速封装,无画质损失)
ffmpeg -i input.mkv -c copy output.mp4
(-i 指定输入文件,-c copy 表示 “流复制”,不重新编码,速度极快)
- 编解码处理(压缩 / 解压)
音视频原始数据体积大(如1080P raw视频每秒数十GB),需要通过编码器压缩(如 H.264、H.265/HEVC、AV1)
播放时需通过解码器解压
FFmpeg 支持几乎所有主流编解码器,是编解码的 “万能工具”
示例:将高码率 H.264 视频转为 H.265(减小体积,保持画质)
ffmpeg -i input.mp4 -c:v libx265 -c:a aac -crf 28 output_hevc.mp4
(-c:v 指定视频编码器,-crf 控制画质 / 码率,数值越小画质越好)
- 音视频剪辑与截取
支持精确到 “帧” 的时间截取、画面裁剪、分辨率缩放,无需打开复杂剪辑软件,通过命令行即可快速完成轻量化剪辑
示例 1:截取视频第 10 秒到第 30 秒的片段
ffmpeg -i input.mp4 -ss 00:00:10 -to 00:00:30 -c copy cut.mp4
(-ss 开始时间,-to 结束时间,-c copy 快速截取)
示例 2:将视频分辨率从 1080P 缩放到 720P
ffmpeg -i input.mp4 -s 1280x720 -c:v libx264 scaled.mp4
(-s 指定目标分辨率)
- 滤镜处理(画面 / 音频效果)
FFmpeg 内置数百种 滤镜(Filter),可实现画面调色、加水印、去水印、音频降噪、变速等效果,支持多滤镜组合使用
示例 1:给视频添加文字水印(右下角,白色字体,黑色边框)
ffmpeg -i input.mp4 -vf "drawtext=text='My Watermark':fontcolor=white:fontsize=24:bordercolor=black:borderw=2:x=w-tw-10:y=h-th-10" watermarked.mp4
(-vf 指定视频滤镜,drawtext 是文字水印滤镜,x/y 控制位置)
示例 2:视频画面旋转 90 度
ffmpeg -i input.mp4 -vf "transpose=1" rotated.mp4
(transpose=1 表示顺时针旋转 90 度)
- 流媒体处理(推流 / 拉流)
支持 RTMP(直播常用)、HLS(网页视频常用)、RTSP(监控常用) 等主流流媒体协议
可实现 “本地文件推流到直播平台”、“拉取网络流保存为本地文件” 等操作
是直播、监控领域的核心工具
示例 1:将本地视频推流到 RTMP 直播服务器(如 OBS 推流的底层逻辑)
ffmpeg -i input.mp4 -c copy -f flv rtmp://server_ip/live/stream_key
(-f flv 指定输出格式为 FLV,rtmp:// 是推流地址)
示例 2:拉取 HLS 网络流并保存为 MP4
ffmpeg -i https://example.com/stream.m3u8 -c copy saved_stream.mp4
FFmpeg 命令的核心逻辑:“输入→处理→输出”
所有 FFmpeg 命令都遵循 “输入源(-i)→ 处理参数(编解码、滤镜、剪辑等)→ 输出文件(output)” 的逻辑
结构可概括为:
ffmpeg [全局参数] -i [输入文件] [输入参数/处理参数] [输出文件]
- 全局参数:对输入和输出都生效的参数(如 -y 覆盖已有输出文件,无需确认)
- 输入参数:仅对当前输入文件生效的参数(如 -ss 若放在 -i 前,截取速度更快)
- 处理参数:编解码(-c)、滤镜(-vf/-af)、分辨率(-s)等核心操作
- 输出文件:指定最终生成的文件路径和格式(格式由后缀名或 -f 参数决定)
FFmpeg 的应用场景
由于强大的功能和跨平台特性(支持 Windows、macOS、Linux、Android、iOS),FFmpeg 的应用几乎覆盖所有音视频相关领域:
- 个人用户:快速转换视频格式、截取片段、添加水印
- 专业剪辑:作为 Premiere、DaVinci Resolve 等软件的底层编解码引擎
- 直播平台:主播推流、平台转码(如将 1080P 转成多清晰度的 720P/480P)
- 监控安防:摄像头视频录制、RTSP 流转存为 MP4
- 嵌入式设备:智能电视、机顶盒的音视频播放功能
- 软件开发:开发者通过
libav*库开发音视频相关应用(如视频编辑器、播放器)
总结
FFmpeg 是音视频领域的 “瑞士军刀”—— 它不提供图形界面(需通过命令行或二次开发使用),但胜在功能全面、性能高效、兼容性极强
无论是个人轻量化处理,还是企业级专业应用,FFmpeg 都是不可或缺的核心工具
入门时可从简单的格式转换、截取命令开始,逐步学习滤镜和流媒体相关操作,深入后能满足几乎所有音视频处理需求
流类型
FFmpeg 体系中,视频文件里的音、视频、字幕等流会被分别编号(索引),索引从 0 开始,格式为 [流类型]:[流索引]:
- 流类型:v 代表视频流(video),a 代表音频流(audio),s 代表字幕流(subtitle)等
- 流索引:从 0 开始的整数,代表该类型下的第 N 条流
大部分普通视频只有「1 条视频流 + 1 条音频流」,此时:
唯一的视频流就是 v:0,唯一的音频流就是 a:0(这也是之前代码用 v:0/a:0 的原因,覆盖多数常规场景)
以下场景会出现多条同类型流,此时就需要用 v:1、a:1 甚至更高索引来指定:

tqdm
from tqdm import tqdm
Python 中用于显示任务进度条的核心导入语句,它依赖于第三方库 tqdm(发音类似 “ta-ka-dum”)
该库的核心作用是为循环、迭代任务生成实时可视化进度条,帮助开发者或用户直观了解任务的执行进度、剩余时间和完成效率
尤其适合处理批量数据(如循环处理大量图像、文件、API 请求等)的场景。
tqdm 的本质是一个迭代器包装器
它可以将任何可迭代对象(如 list、range、生成器等)包裹起来,在迭代过程中自动计算并显示进度信息。
from tqdm import tqdm
import time
# 1. 包装普通列表迭代
items = ["a", "b", "c", "d", "e"]
for item in tqdm(items, desc="处理数据"):
time.sleep(0.5) # 模拟耗时操作(如数据处理、文件读取)
# 2. 包装range迭代(更常见于循环计数场景)
for i in tqdm(range(100), desc="进度演示"):
time.sleep(0.05)
运行上述代码时,终端会显示类似如下的实时进度条:
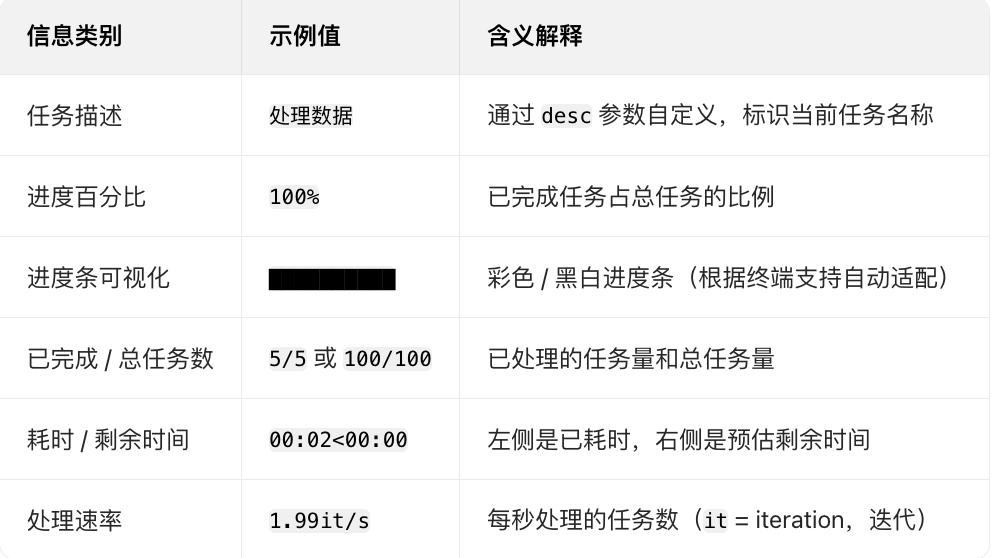
处理数据: 100%|███████████████████████████████████| 5/5 [00:02<00:00, 1.99it/s]
进度演示: 100%|████████████████████████████████| 100/100 [00:05<00:00, 19.98it/s]
进度条默认显示 5 类核心信息(从左到右):
128 维人脸特征向量~人脸的数字身份证
人脸图像本身是二维像素矩阵(如 224×224 像素的图像,维度是 224×224×3,包含宽、高、RGB 三通道)
但直接用像素矩阵无法用于 “区分不同人脸”
比如两张不同人脸的像素矩阵差异可能很小,同一张人脸的像素矩阵因角度、光照变化差异可能很大
128 维特征向量是通过深度学习模型对人脸图像进行 “抽象提取” 后的结果:
- 每个维度都对应一个 “人脸的抽象特征”,比如第 1 维可能对应 “眼睛宽度”、第 5 维对应 “鼻梁高度”,但具体维度的物理含义通常不明确,是模型自动学习的)
- 不同人脸的 128 维向量差异显著(比如你和他人的向量在多个维度上数值不同),同一人脸的向量在不同场景下(轻微角度、光照变化)则保持稳定
这就是它能作为 “人脸数字身份证” 的核心原因
为什么是 128 维?
这是行业长期实践中平衡 “区分能力” 和 “计算效率” 的结果:
- 维度太少(如 32 维):特征表达能力不足,可能无法区分长相相似的人
- 维度太多(如 512 维):会增加存储成本和后续计算量(如人脸比对时的向量距离计算),且可能引入冗余信息
128 维:既能保证足够的区分能力,又能兼顾存储和计算效率,成为主流人脸模型的默认输出维度
128 维向量在代码后续流程中的核心作用
代码中把 128 维向量(face_emb)存入 face_info 字典,为后续的人脸聚类 / 比对任务铺垫
人脸聚类:比如要从多帧视频中 “找出同一人的所有人脸”,就需要计算不同 face_emb 之间的 “距离”(如欧氏距离、余弦距离)—— 距离越近,说明两张人脸是同一人的概率越高。代码中初始 cluster_id=-1,后续会基于 128 维向量的距离,将同一人的人脸分配到相同的 cluster_id(比如你在视频中出现的 10 张人脸,最终 cluster_id 都会被设为 1,他人的设为 2、3 等)
人脸比对:
比如要判断 “某张人脸是否是数据库中的某人”,就将待比对人脸的 128 维向量与数据库中目标人脸的 128 维向量计算距离
若距离小于设定阈值(如 0.6),则判定为 “同一人”
矩阵点积
good_similarity = np.dot(good_embeddings, good_embeddings.T) 是通过矩阵点积运算,批量计算所有高质量人脸特征向量之间的相似度
得到一个 “相似度矩阵”,为后续聚类的 “距离计算” 提供基础
这行代码的核心是利用 “归一化特征向量的点积 = 余弦相似度” 的数学特性,高效完成批量相似度计算
执行前的关键数据前提
good_embeddings 是 NumPy 二维数组,形状为 (M, 128),其中:
M 是 “高质量人脸的数量”(经过 good_mask 筛选后剩余的人脸数)
128 是每个人脸特征向量的维度(128 维嵌入向量)
例如:若筛选后有 50 张高质量人脸,good_embeddings.shape 就是 (50, 128)
向量已归一化:
good_embeddings 中的每一行(即每个人脸的 128 维向量)都是L2 归一化后的向量
(归一计算来自之前 extract_faces 函数的 normed_embedding)
归一化的定义是:向量的 “L2 范数(模长)= 1”,即对任意一行向量 v,满足 np.linalg.norm(v, ord=2) = 1
这个前提是 “点积 = 余弦相似度” 的关键(后面会推导)


数学原理:为什么点积能表示相似度?
这行代码的核心是利用 “向量点积” 与 “余弦相似度” 的数学关系,先明确两个基础概念:
- 向量点积的定义
对两个向量 a(128 维)和 b(128 维),它们的点积为:
a · b = a₁b₁ + a₂b₂ + ... + a₁₂₈b₁₂₈(对应元素相乘后求和,结果是一个标量)
- 余弦相似度的定义
余弦相似度用于衡量两个向量的 “方向相似性”(与向量模长无关),公式为:
cosθ = (a · b) / (||a||₂ × ||b||₂)
其中 ||a||₂ 是向量 a 的 L2 范数(模长),||b||₂ 是向量 b 的 L2 范数
- 归一化后的简化:点积 = 余弦相似度
由于 good_embeddings 中的每一行向量都已 L2 归一化(||a||₂= 1,||b||₂= 1),代入余弦相似度公式后:
cosθ = (a · b) / (1 × 1) = a · b
即:归一化向量的点积结果,直接等于它们的余弦相似度
余弦相似度的取值范围是 [-1, 1]:
越接近 1:两个向量方向越一致 → 对应的两个人脸越相似(大概率是同一人)
越接近 0:两个向量方向无关 → 人脸相似度低
越接近 -1:两个向量方向相反 → 人脸相似度极低(几乎不可能是同一人)
矩阵点积的结果:相似度矩阵的含义
np.dot(good_embeddings, good_embeddings.T) 是矩阵层面的点积运算,需要结合矩阵形状理解运算过程和结果:
矩阵点积的形状计算
矩阵点积要求 “前一个矩阵的列数 = 后一个矩阵的行数”,运算后结果矩阵的形状为 “前一个矩阵的行数 × 后一个矩阵的列数”:
前一个矩阵 good_embeddings:形状 (M, 128)(M 行,128 列)
后一个矩阵 good_embeddings.T:是 good_embeddings 的转置矩阵,形状从 (M, 128) 变为 (128, M)(128 行,M 列)
点积结果 good_similarity:形状为 (M, M)(M 行,M 列),即一个 “M×M 的方阵”相似度矩阵的元素含义
good_similarity 中的每个元素 good_similarity[i][j],代表:
第 i 个高质量人脸的特征向量(good_embeddings[i]),与第 j 个高质量人脸的特征向量(good_embeddings[j])的余弦相似度;
特殊元素:
对角线元素 good_similarity[i][i] 是 “第 i 个人脸与自身的相似度”,由于向量归一化,结果恒为 1(符合 “自己与自己完全相似” 的逻辑)
举个具体例子:若 M=3(3 张高质量人脸),good_similarity 的形式如下:
# 行:第i个人脸;列:第j个人脸;元素:i和j的余弦相似度
[
[1.0, 0.85, 0.2], # 第0张脸与第0、1、2张脸的相似度(与自身1.0,与第1张0.85(相似),与第2张0.2(不相似))
[0.85, 1.0, 0.15], # 第1张脸与第0、1、2张脸的相似度(与第0张0.85(相似),与自身1.0)
[0.2, 0.15, 1.0] # 第2张脸与第0、1、2张脸的相似度(与前两张都不相似)
]
从矩阵可直接看出:第 0 张和第 1 张脸高度相似(大概率是同一人),第 2 张脸与前两张都不相似(是另一人)
这行代码在聚类流程中的核心作用
这行代码是连接 “特征向量” 和 “聚类距离” 的关键桥梁,后续聚类依赖这个相似度矩阵:
为距离计算提供输入:
聚类需要 “衡量样本间的差异(距离)”,而相似度与距离是互补关系 —— 相似度越高,距离越小。
代码通过 good_distances = 1 - good_similarity 将 “相似度矩阵” 转为 “距离矩阵”(距离范围 [0, 2]),
满足 HDBSCAN 聚类算法对 “距离” 的输入要求;
批量计算提升效率:
若用循环逐个计算 M 个人脸之间的相似度,需要 M×M 次循环,效率极低;
而 NumPy 的矩阵点积是底层优化的向量化运算(用 C 语言实现),能大幅提升计算速度(尤其当 M 较大,
如几百、几千张人脸时,效率差距会非常明显);
保证相似度计算的一致性:
基于归一化向量的点积,能确保相似度仅反映 “人脸特征的方向差异”,不受向量模长(如人脸图像亮度、尺寸)的干扰,为后续聚类的准确性提供保障
总结
利用 “归一化向量点积 = 余弦相似度” 的数学特性;通过 NumPy 向量化运算,高效生成 M×M 的相似度矩阵;
为后续 HDBSCAN 聚类的 “距离计算” 提供标准化输入,是实现 “同一人聚类” 的核心前置步骤