什么是机器学习?
机器学习 (ML) 是许多重要技术的助力,从翻译应用到自动驾驶汽车,都离不开机器学习。
机器学习提供了一种新的方式来解决问题、解答复杂问题和创建新内容。
机器学习可以预测天气、估算行程时间、推荐歌曲、自动补全句子、总结文章,以及生成从未见过的图片。
从基本层面来说,机器学习是指训练一款称为“模型”的软件,以便根据数据做出有用的预测或生成内容(例如文本、图片、音频或视频)。
例如,假设我们想要创建一个用于预测降雨量的应用。我们可以使用传统方法或机器学习方法。使用传统方法,我们会创建基于物理特性的地球大气和地表表示法,计算大量的流体动力学方程。这非常困难。
使用机器学习方法,我们会向机器学习模型提供大量天气数据,直到机器学习模型最终学会计算产生不同降雨量的天气模式之间的数学关系。然后,我们会向该模型提供当前天气数据,模型会预测降雨量。
机器学习中的“模型”是什么?
第二个
机器学习系统类型
根据机器学习系统学习预测或生成内容的方式,它们可分为以下一个或多个类别:
- 监督式学习
- 非监督式学习
- 强化学习
- 生成式 AI
下面来分别展开看看这一个个指的是什么?
监督式学习
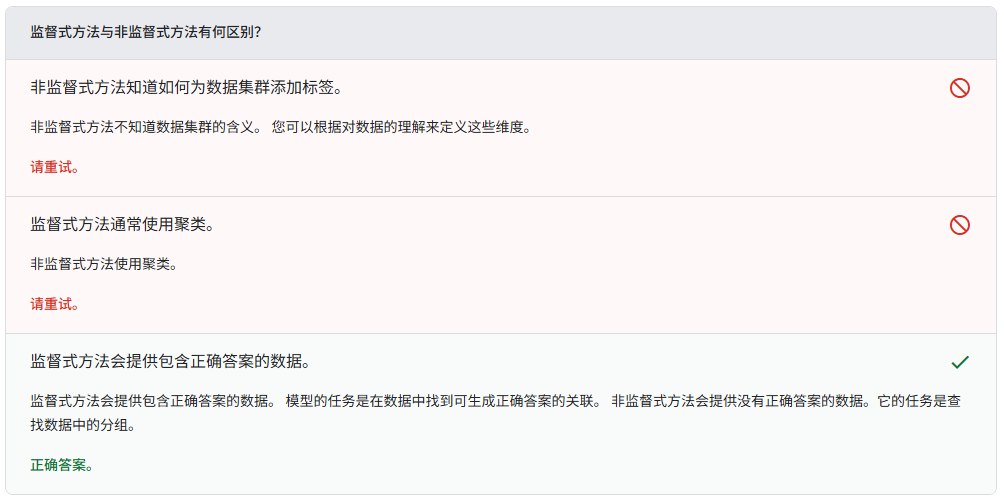
监督式学习模型在查看包含正确答案的大量数据后,可以发现产生正确答案的数据元素之间的关联,然后进行预测。
这就像学生通过研究包含问题和答案的旧考试来学习新材料。学生在使用足够多的旧版考试进行训练后,就可以做好准备参加新版考试了。
这些机器学习系统是“监督式”的,这意味着人类会向机器学习系统提供包含已知正确结果的数据。
监督式学习的两种最常见用例是回归和分类。
回归
回归模型可预测数值。例如,用于预测降雨量(以英寸或毫米为单位)的天气模型就是回归模型。

分类
分类模型可预测某个对象属于某个类别的可能性。与输出为数字的回归模型不同,分类模型输出一个值,用于表明某个对象是否属于特定类别。
例如,分类模型用于预测电子邮件是否为垃圾邮件,或照片中是否有猫。
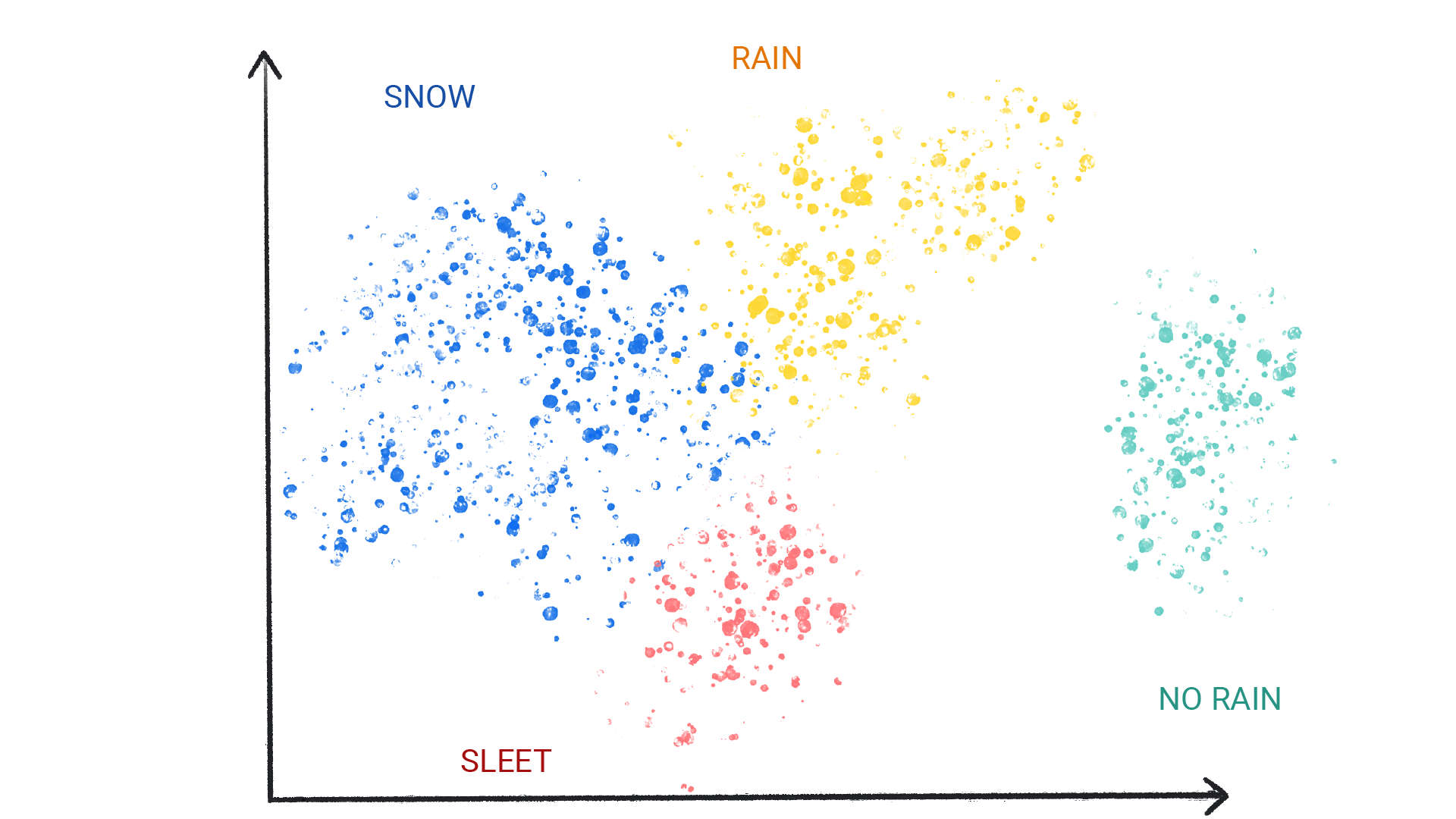
分类模型分为两类:二元分类和多类分类。
二元分类模型会输出仅包含两个值的类中的值,例如,输出 rain 或 no rain 的模型。多类分类模型会从包含多个值的类中输出一个值,例如,可以输出 rain、hail、snow 或 sleet 的模型。
非监督式学习
非监督式学习模型通过获得不含任何正确答案的数据来进行预测。非监督式学习模型的目标是找出数据中具有意义的模式。
换句话说,模型没有关于如何对每项数据进行分类的提示,而是必须推断自己的规则。
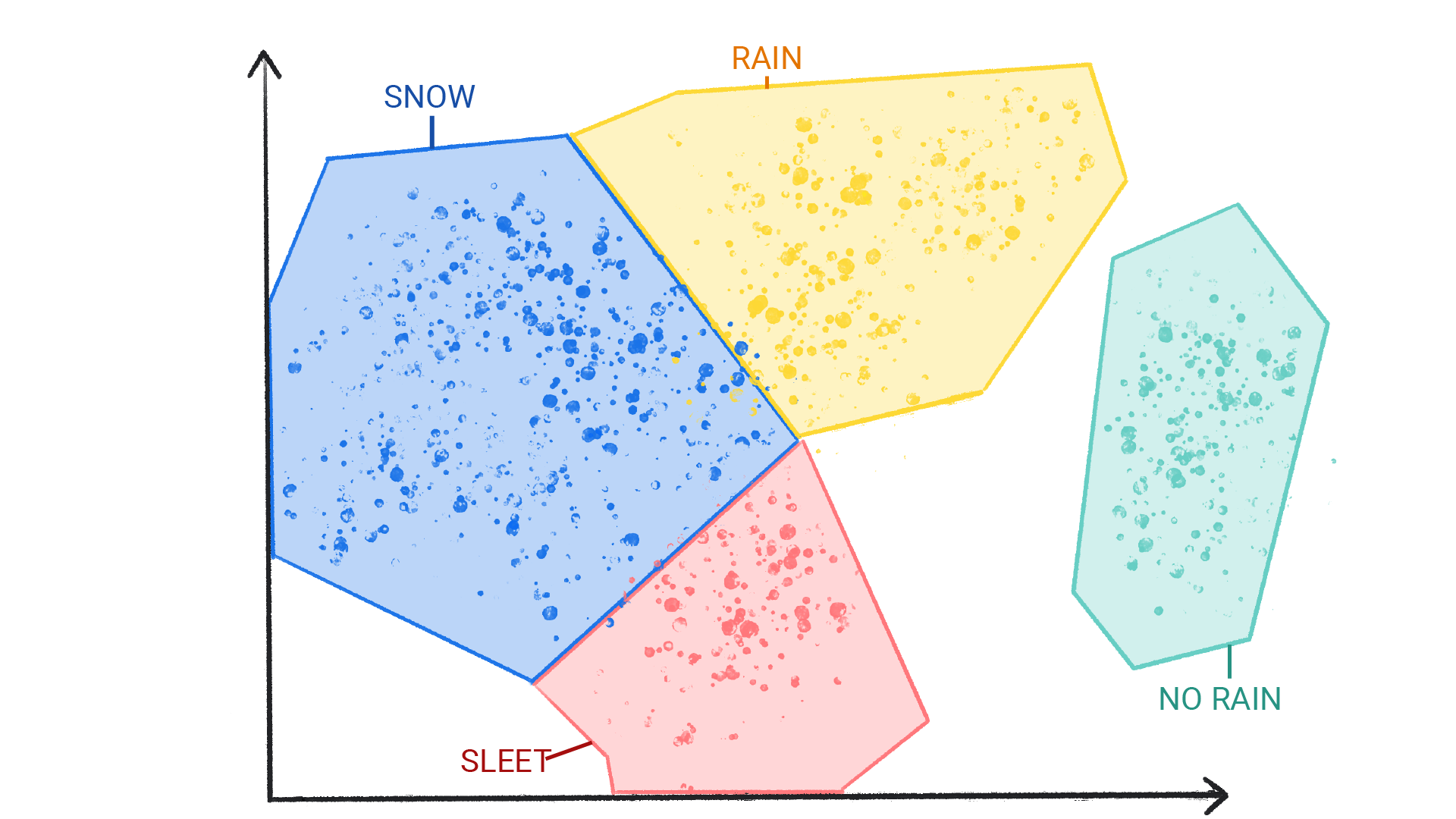
一种常用的非监督式学习模型采用了一种称为聚类的技术。该模型会查找可划分自然分组的数据点。
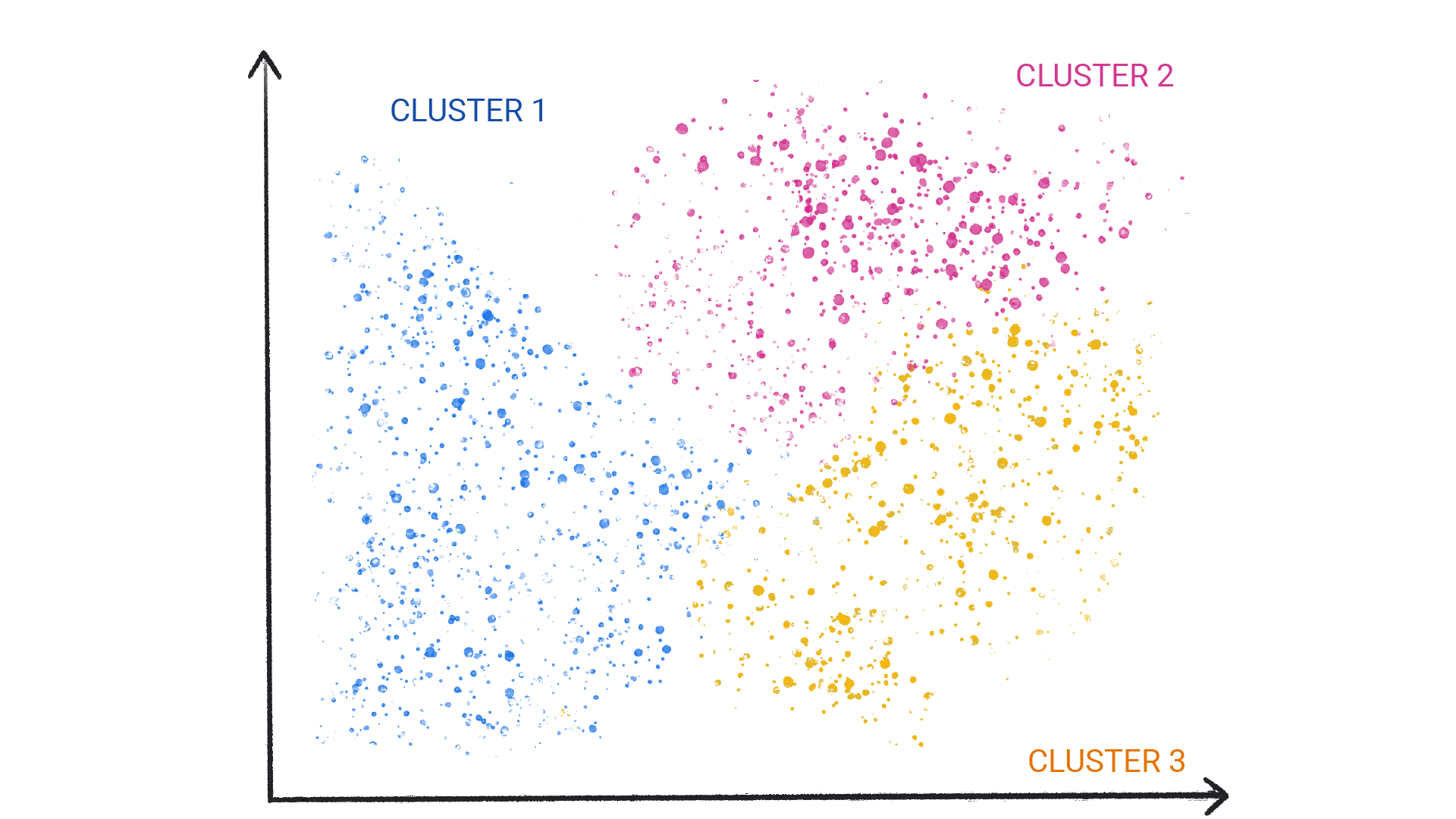
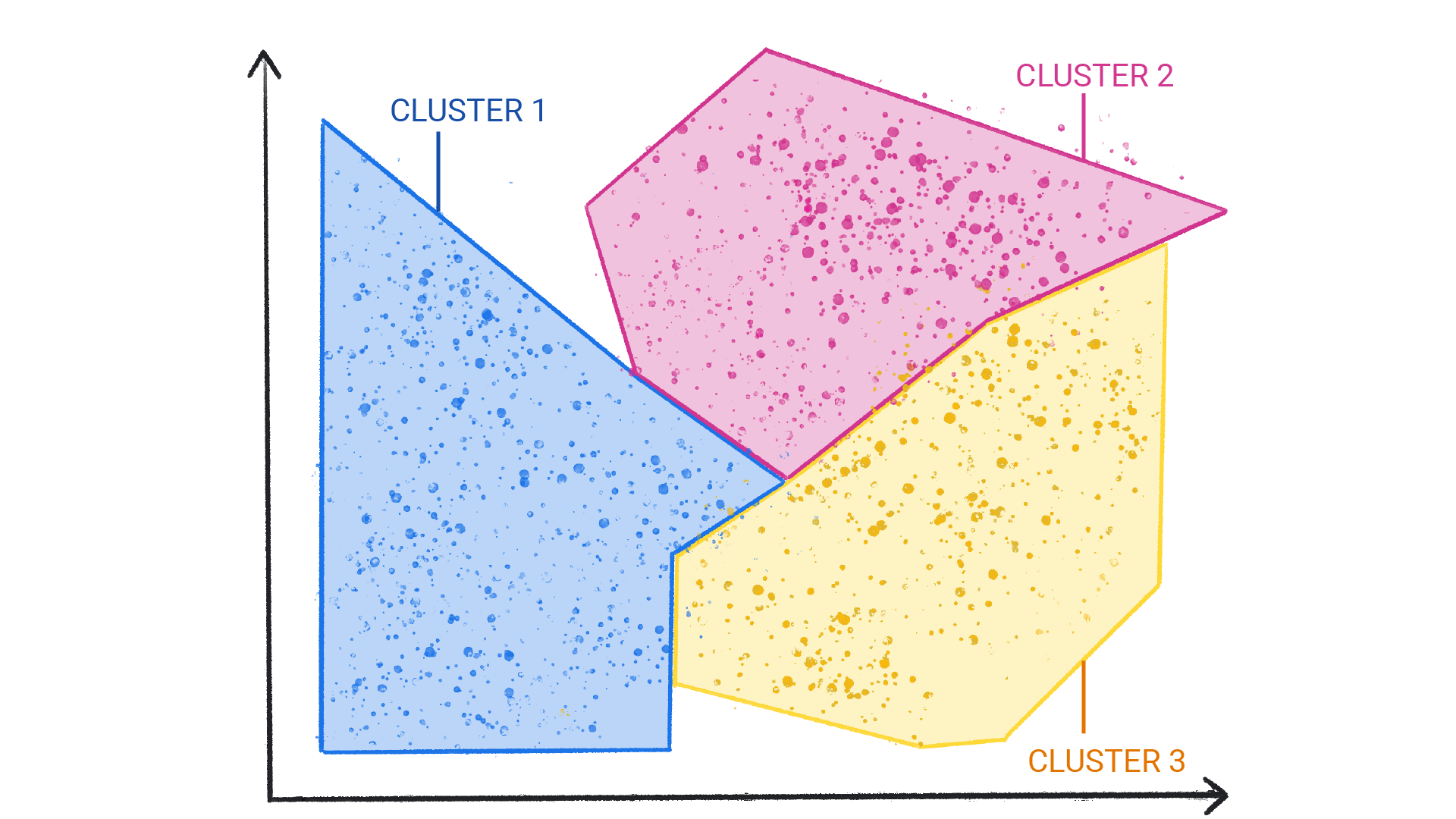
聚类与分类不同,因为类别不是由您定义的。例如,无监督模型可能会根据温度对天气数据集进行分组,从而揭示定义季节的分片。然后,您可以尝试根据对数据集的理解为这些集群命名。
强化学习
强化学习模型根据在环境中执行的操作获得奖励或惩罚,从而进行预测。强化学习系统会生成政策,定义用于获得最多奖励的最佳策略。
强化学习用于训练机器人执行任务(例如在房间内四处走动),以及训练 AlphaGo 等软件程序玩围棋。
生成式 AI
生成式 AI 是一类根据用户输入生成内容的模型。例如,生成式 AI 可以创作独特的图片、音乐作品和笑话;它可以总结文章、说明如何执行任务或编辑照片。
生成式 AI 可以接受各种输入,并生成各种输出,例如文本、图片、音频和视频。它还可以接受和创建这些内容的组合。例如,模型可以接受图片作为输入,并创建图片和文本作为输出,也可以接受图片和文本作为输入,并创建视频作为输出。
我们可以通过生成模型的输入和输出来讨论它们,通常以“输入类型”到“输出类型”的形式写出。例如,以下是生成式模型的部分输入和输出列表:
- 文本到文本
- 文本到图像
- 文本到视频
- 文本转代码
- 文本转语音
- 图片和文本到图片

成式 AI 如何运作?概括来讲,生成式模型会学习数据中的模式,目标是生成新的但类似的数据。生成式模型如下所示:
- 喜剧演员,通过观察他人的行为和说话风格来学习模仿他人
- 通过研究大量采用特定风格的画作,学习以特定风格绘画的艺术家
- 翻唱乐队,通过大量聆听特定音乐团体的音乐,学习模仿其声音
为了生成独特且富有创意的输出,生成式模型最初使用非监督式方法进行训练,在这种方法中,模型会学习模仿其训练数据。
有时,系统会使用监督学习或强化学习,针对与模型可能被要求执行的任务(例如总结文章或编辑照片)相关的特定数据,对模型进行进一步训练。
生成式 AI 是一项快速发展的技术,不断有新的应用场景被发现。例如,生成式模型可以自动移除干扰性背景或提高低分辨率图片的质量,帮助企业优化其电子商务商品图片。