
Linux 日志分析:用 ELK 搭建个人运维监控平台
🌟 Hello,我是摘星!
🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。
🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
目录
摘要
作为一名在运维一线摸爬滚打多年的技术人,我深知日志分析在系统监控中的重要性。每当凌晨收到告警短信时,第一反应就是查看日志,但传统的 tail -f 和 grep 命令在面对海量日志时显得力不从心。经过不断的实践和踩坑,我发现 ELK Stack(Elasticsearch、Logstash、Kibana)是构建个人运维监控平台的最佳选择。
在这篇文章中,我将分享如何从零开始搭建一个功能完整的 ELK 日志分析平台。我们将从基础的环境准备开始,逐步配置 Elasticsearch 集群、部署 Logstash 数据处理管道、搭建 Kibana 可视化界面,最后通过 Filebeat 实现日志的自动收集。整个过程不仅包含详细的配置步骤,还会分享我在实际部署中遇到的各种问题和解决方案。
通过这套监控平台,你可以实现实时日志搜索、异常告警、性能监控、安全审计等功能。无论是 Web 服务器的访问日志、应用程序的错误日志,还是系统的安全日志,都能在统一的界面中进行分析和可视化。我还会介绍如何通过自定义仪表板来监控关键指标,如何设置告警规则来及时发现问题,以及如何优化 ELK 性能来处理大规模日志数据。
这不仅仅是一个技术教程,更是我多年运维经验的总结。希望通过这篇文章,能帮助更多的技术同行建立起自己的日志分析体系,让运维工作变得更加高效和智能。
1. ELK Stack 架构概览
1.1 核心组件介绍
ELK Stack 是由三个开源项目组成的强大日志分析解决方案:
- Elasticsearch:分布式搜索和分析引擎,负责存储和索引日志数据
- Logstash:数据处理管道,负责收集、转换和输出日志数据
- Kibana:数据可视化平台,提供搜索和图表功能
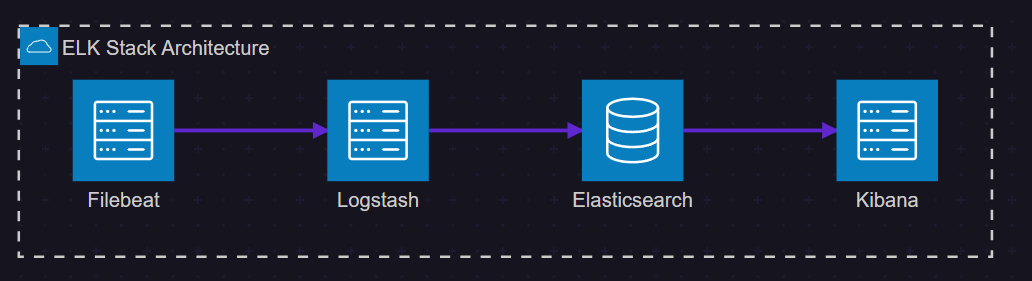
图1:ELK Stack 架构图 - 展示各组件间的数据流向
1.2 数据流处理过程
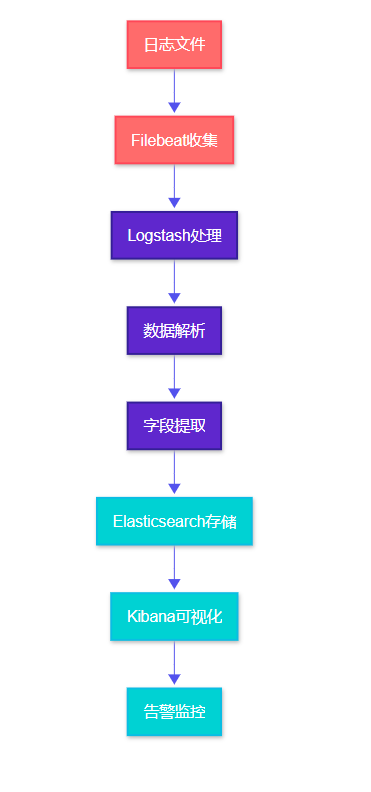
图2:日志处理流程图 - 从收集到可视化的完整流程
2. 环境准备与基础配置
2.1 系统要求
在开始部署之前,我们需要确保系统满足 ELK Stack 的运行要求:
组件 |
最小内存 |
推荐内存 |
磁盘空间 |
Java版本 |
Elasticsearch |
2GB |
8GB |
50GB+ |
JDK 11+ |
Logstash |
1GB |
4GB |
10GB |
JDK 11+ |
Kibana |
1GB |
2GB |
5GB |
Node.js 14+ |
Filebeat |
128MB |
512MB |
1GB |
无需Java |
2.2 Java 环境配置
#!/bin/bash
# 安装 OpenJDK 11
sudo apt update
sudo apt install -y openjdk-11-jdk
# 配置 JAVA_HOME 环境变量
echo 'export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64' >> ~/.bashrc
echo 'export PATH=$JAVA_HOME/bin:$PATH' >> ~/.bashrc
source ~/.bashrc
# 验证 Java 安装
java -version
javac -version这段脚本首先更新系统包管理器,然后安装 OpenJDK 11。配置环境变量是关键步骤,确保 ELK 组件能够找到 Java 运行时。
2.3 系统优化配置
#!/bin/bash
# 优化系统参数以支持 Elasticsearch
echo 'vm.max_map_count=262144' | sudo tee -a /etc/sysctl.conf
echo 'fs.file-max=65536' | sudo tee -a /etc/sysctl.conf
# 配置用户限制
echo 'elasticsearch soft nofile 65536' | sudo tee -a /etc/security/limits.conf
echo 'elasticsearch hard nofile 65536' | sudo tee -a /etc/security/limits.conf
echo 'elasticsearch soft nproc 4096' | sudo tee -a /etc/security/limits.conf
echo 'elasticsearch hard nproc 4096' | sudo tee -a /etc/security/limits.conf
# 应用配置
sudo sysctl -p这些优化配置对于 Elasticsearch 的稳定运行至关重要,特别是 vm.max_map_count 参数,它决定了进程可以拥有的内存映射区域的最大数量。
3. Elasticsearch 集群部署
3.1 安装与基础配置
#!/bin/bash
# 下载并安装 Elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.11.0-linux-x86_64.tar.gz
tar -xzf elasticsearch-8.11.0-linux-x86_64.tar.gz
sudo mv elasticsearch-8.11.0 /opt/elasticsearch
# 创建专用用户
sudo useradd -r -s /bin/false elasticsearch
sudo chown -R elasticsearch:elasticsearch /opt/elasticsearch3.2 Elasticsearch 配置文件
# /opt/elasticsearch/config/elasticsearch.yml
cluster.name: personal-monitoring
node.name: node-1
path.data: /opt/elasticsearch/data
path.logs: /opt/elasticsearch/logs
# 网络配置
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
# 集群配置
discovery.type: single-node
cluster.initial_master_nodes: ["node-1"]
# 安全配置
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
xpack.security.http.ssl.enabled: false
xpack.security.transport.ssl.enabled: false
# 性能优化
indices.memory.index_buffer_size: 10%
indices.memory.min_index_buffer_size: 48mb这个配置文件针对单节点部署进行了优化,关闭了 X-Pack 安全功能以简化初始配置。在生产环境中,建议启用安全功能。
3.3 启动服务脚本
#!/bin/bash
# /opt/elasticsearch/bin/start-elasticsearch.sh
# 设置 JVM 堆内存
export ES_JAVA_OPTS="-Xms2g -Xmx2g"
# 启动 Elasticsearch
sudo -u elasticsearch /opt/elasticsearch/bin/elasticsearch -d
# 等待服务启动
sleep 30
# 检查服务状态
curl -X GET "localhost:9200/_cluster/health?pretty"JVM 堆内存设置遵循"不超过系统内存的50%,且不超过32GB"的原则。-d 参数表示以守护进程方式运行。
4. Logstash 数据处理管道
4.1 Logstash 安装配置
#!/bin/bash
# 下载并安装 Logstash
wget https://artifacts.elastic.co/downloads/logstash/logstash-8.11.0-linux-x86_64.tar.gz
tar -xzf logstash-8.11.0-linux-x86_64.tar.gz
sudo mv logstash-8.11.0 /opt/logstash
sudo chown -R elasticsearch:elasticsearch /opt/logstash4.2 日志处理配置
# /opt/logstash/config/logstash.conf
input {
# 接收 Filebeat 数据
beats {
port => 5044
}
# 直接读取日志文件
file {
path => "/var/log/nginx/access.log"
start_position => "beginning"
type => "nginx-access"
}
file {
path => "/var/log/nginx/error.log"
start_position => "beginning"
type => "nginx-error"
}
}
filter {
# 处理 Nginx 访问日志
if [type] == "nginx-access" {
grok {
match => {
"message" => "%{NGINXACCESS}"
}
}
# 解析时间戳
date {
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
}
# 转换数据类型
mutate {
convert => {
"response" => "integer"
"bytes" => "integer"
"responsetime" => "float"
}
}
# 添加地理位置信息
geoip {
source => "clientip"
target => "geoip"
}
}
# 处理应用程序日志
if [type] == "application" {
# 解析 JSON 格式日志
json {
source => "message"
}
# 提取错误级别
if [level] {
mutate {
uppercase => [ "level" ]
}
}
}
}
output {
# 输出到 Elasticsearch
elasticsearch {
hosts => ["localhost:9200"]
index => "logs-%{type}-%{+YYYY.MM.dd}"
}
# 调试输出
stdout {
codec => rubydebug
}
}这个配置文件定义了完整的数据处理管道:输入阶段接收多种数据源,过滤阶段进行数据解析和转换,输出阶段将处理后的数据发送到 Elasticsearch。
4.3 Grok 模式定义
# /opt/logstash/patterns/nginx
NGINXACCESS %{IPORHOST:clientip} - %{DATA:auth} \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{DATA:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response:int} (?:%{NUMBER:bytes:int}|-) "(?:%{DATA:referrer}|-)" "%{DATA:agent}" %{NUMBER:responsetime:float}自定义 Grok 模式可以精确解析特定格式的日志,提取出有价值的字段信息。
5. Kibana 可视化平台搭建
5.1 Kibana 安装与配置
#!/bin/bash
# 下载并安装 Kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-8.11.0-linux-x86_64.tar.gz
tar -xzf kibana-8.11.0-linux-x86_64.tar.gz
sudo mv kibana-8.11.0 /opt/kibana
sudo chown -R elasticsearch:elasticsearch /opt/kibana5.2 Kibana 配置文件
# /opt/kibana/config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
server.name: "personal-monitoring-kibana"
# Elasticsearch 连接配置
elasticsearch.hosts: ["http://localhost:9200"]
elasticsearch.requestTimeout: 30000
elasticsearch.shardTimeout: 30000
# 日志配置
logging.appenders.file.type: file
logging.appenders.file.fileName: /opt/kibana/logs/kibana.log
logging.appenders.file.layout.type: json
# 性能优化
server.maxPayload: 1048576
elasticsearch.pingTimeout: 15005.3 启动脚本
#!/bin/bash
# /opt/kibana/bin/start-kibana.sh
# 设置 Node.js 内存限制
export NODE_OPTIONS="--max-old-space-size=2048"
# 启动 Kibana
sudo -u elasticsearch /opt/kibana/bin/kibana &
# 等待服务启动
echo "等待 Kibana 启动..."
sleep 60
# 检查服务状态
curl -I http://localhost:56016. Filebeat 日志收集配置
6.1 Filebeat 安装
#!/bin/bash
# 下载并安装 Filebeat
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.11.0-linux-x86_64.tar.gz
tar -xzf filebeat-8.11.0-linux-x86_64.tar.gz
sudo mv filebeat-8.11.0-linux-x86_64 /opt/filebeat
sudo chown -R root:root /opt/filebeat6.2 Filebeat 配置
# /opt/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/*.log
- /var/log/apache2/*.log
fields:
logtype: webserver
fields_under_root: true
multiline.pattern: '^\d{4}-\d{2}-\d{2}'
multiline.negate: true
multiline.match: after
- type: log
enabled: true
paths:
- /var/log/syslog
- /var/log/auth.log
fields:
logtype: system
fields_under_root: true
- type: log
enabled: true
paths:
- /opt/applications/*/logs/*.log
fields:
logtype: application
fields_under_root: true
# 输出配置
output.logstash:
hosts: ["localhost:5044"]
# 处理器配置
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
# 日志配置
logging.level: info
logging.to_files: true
logging.files:
path: /opt/filebeat/logs
name: filebeat
keepfiles: 7
permissions: 0644这个配置文件定义了多种日志输入源,包括 Web 服务器日志、系统日志和应用程序日志,并通过处理器添加了主机元数据。
7. 监控仪表板设计
7.1 系统性能监控
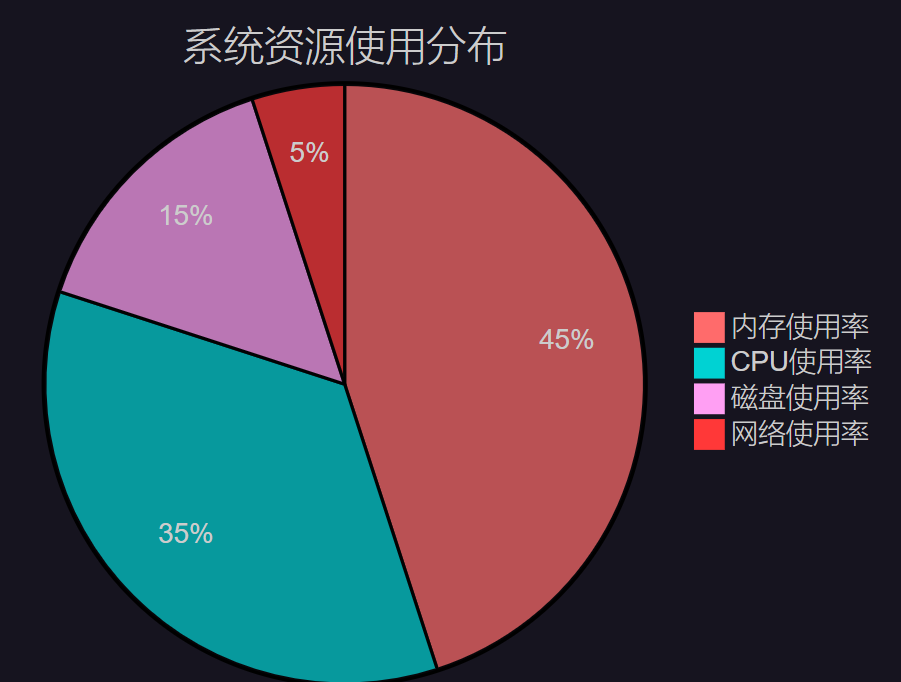
图3:系统资源使用分布饼图 - 展示各项资源的占用比例
7.2 告警规则配置
{
"trigger": {
"schedule": {
"interval": "1m"
}
},
"input": {
"search": {
"request": {
"search_type": "query_then_fetch",
"indices": ["logs-*"],
"body": {
"query": {
"bool": {
"must": [
{
"range": {
"@timestamp": {
"gte": "now-5m"
}
}
},
{
"match": {
"level": "ERROR"
}
}
]
}
}
}
}
}
},
"condition": {
"compare": {
"ctx.payload.hits.total": {
"gt": 10
}
}
},
"actions": {
"send_email": {
"email": {
"to": ["admin@example.com"],
"subject": "错误日志告警",
"body": "在过去5分钟内检测到超过10条错误日志"
}
}
}
}这个告警规则监控错误级别的日志,当5分钟内出现超过10条错误日志时触发邮件告警。
8. 性能优化与最佳实践
8.1 索引生命周期管理
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "5GB",
"max_age": "1d"
}
}
},
"warm": {
"min_age": "7d",
"actions": {
"allocate": {
"number_of_replicas": 0
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"allocate": {
"number_of_replicas": 0
}
}
},
"delete": {
"min_age": "90d"
}
}
}
}8.3 集群健康检查脚本
#!/bin/bash
# elk-health-check.sh
# 检查 Elasticsearch 集群健康状态
check_elasticsearch() {
echo "检查 Elasticsearch 健康状态..."
health=$(curl -s "localhost:9200/_cluster/health" | jq -r '.status')
case $health in
"green")
echo "✅ Elasticsearch 状态:健康"
;;
"yellow")
echo "⚠️ Elasticsearch 状态:警告"
;;
"red")
echo "❌ Elasticsearch 状态:严重"
exit 1
;;
*)
echo "❌ Elasticsearch 无响应"
exit 1
;;
esac
}
# 检查 Logstash 状态
check_logstash() {
echo "检查 Logstash 状态..."
if pgrep -f logstash > /dev/null; then
echo "✅ Logstash 运行正常"
else
echo "❌ Logstash 未运行"
exit 1
fi
}
# 检查 Kibana 状态
check_kibana() {
echo "检查 Kibana 状态..."
status=$(curl -s -o /dev/null -w "%{http_code}" "localhost:5601/api/status")
if [ "$status" = "200" ]; then
echo "✅ Kibana 运行正常"
else
echo "❌ Kibana 状态异常 (HTTP: $status)"
exit 1
fi
}
# 执行所有检查
check_elasticsearch
check_logstash
check_kibana
echo "🎉 ELK Stack 整体状态良好"这个健康检查脚本可以定期执行,确保 ELK Stack 各组件正常运行。
9. 安全加固与访问控制
9.1 网络安全配置
#!/bin/bash
# 配置防火墙规则
sudo ufw allow 22/tcp # SSH
sudo ufw allow 5601/tcp # Kibana
sudo ufw deny 9200/tcp # Elasticsearch (仅内网访问)
sudo ufw deny 5044/tcp # Logstash (仅内网访问)
# 启用防火墙
sudo ufw --force enable9.2 SSL/TLS 配置
# elasticsearch.yml SSL 配置
xpack.security.enabled: true
xpack.security.http.ssl.enabled: true
xpack.security.http.ssl.key: /opt/elasticsearch/config/certs/elasticsearch.key
xpack.security.http.ssl.certificate: /opt/elasticsearch/config/certs/elasticsearch.crt
xpack.security.http.ssl.certificate_authorities: /opt/elasticsearch/config/certs/ca.crt10. 故障排查与维护
10.1 常见问题诊断
问题类型 |
症状 |
可能原因 |
解决方案 |
内存不足 |
服务频繁重启 |
JVM堆内存设置过小 |
调整ES_JAVA_OPTS参数 |
磁盘空间 |
索引创建失败 |
磁盘空间不足 |
清理旧索引或扩容 |
网络连接 |
组件间通信失败 |
防火墙阻断 |
检查端口配置 |
配置错误 |
服务启动失败 |
配置文件语法错误 |
验证YAML语法 |
10.2 日志轮转配置
#!/bin/bash
# /etc/logrotate.d/elk-logs
/opt/elasticsearch/logs/*.log {
daily
missingok
rotate 30
compress
delaycompress
notifempty
create 644 elasticsearch elasticsearch
postrotate
/bin/kill -USR1 `cat /opt/elasticsearch/logs/elasticsearch.pid 2> /dev/null` 2> /dev/null || true
endscript
}
/opt/logstash/logs/*.log {
daily
missingok
rotate 14
compress
delaycompress
notifempty
create 644 elasticsearch elasticsearch
}最佳实践提醒
"在运维监控中,预防胜于治疗。定期的健康检查、合理的资源规划和及时的告警响应,是保障系统稳定运行的三大支柱。"
总结
通过这次 ELK Stack 个人监控平台的搭建实践,我深刻体会到了日志分析在现代运维中的重要价值。从最初的环境准备到最终的性能优化,每一个环节都充满了技术挑战和学习机会。
在整个部署过程中,我遇到了许多典型问题:Elasticsearch 的内存配置需要根据实际硬件资源进行调优,Logstash 的 Grok 模式需要针对不同的日志格式进行定制,Kibana 的仪表板设计需要平衡美观性和实用性。这些问题的解决过程让我对 ELK Stack 的架构原理有了更深入的理解。
特别值得一提的是索引生命周期管理策略的设计。通过合理的热温冷数据分层存储,不仅能够有效控制存储成本,还能保证查询性能。我设置的90天数据保留策略在满足业务需求的同时,也避免了磁盘空间的无限增长。
在安全方面,虽然为了简化初始部署关闭了 X-Pack 安全功能,但在生产环境中,我强烈建议启用 SSL/TLS 加密和基于角色的访问控制。网络层面的防火墙配置也是必不可少的安全措施。
性能监控和告警机制的建立让这个平台具备了真正的实用价值。通过自定义的仪表板,我可以实时监控系统的关键指标;通过灵活的告警规则,能够在问题发生的第一时间收到通知。这种主动式的监控方式大大提升了运维效率。
回顾整个项目,我认为最大的收获不仅仅是技术技能的提升,更是对监控体系建设的系统性思考。一个优秀的监控平台不仅要能够收集和展示数据,更要能够从海量信息中提取有价值的洞察,为业务决策提供数据支撑。
未来,我计划在这个基础平台上继续扩展功能,比如集成机器学习算法进行异常检测,添加更多的数据源支持,以及开发自定义的监控插件。技术的学习永无止境,但正是这种持续的探索和实践,让我们在技术的道路上不断前行。
我是摘星!如果这篇文章在你的技术成长路上留下了印记
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
关键词标签
ELK Stack 日志分析 Elasticsearch Logstash Kibana 运控 系统监控 日志收集 数据可视化 性能优化维监