ARM64 调用约定(AArch64 ABI 简介)
在进入 demo 前,需要交代 ABI,否则读者很难理解寄存器/栈的含义:
通用寄存器
x0–x7:前 8 个函数参数x8:间接结果寄存器(syscall 时保存系统调用号)x9–x15:临时寄存器x19–x28:callee-saved(函数调用后必须恢复)x29:fp(frame pointer)x30:lr(link register, return address)sp:栈指针
返回值
x0存放函数返回值
栈方向
向下生长(高地址→低地址)
Demo 源码(stack_demo.c)
#include <stdio.h>
int add(int a, int b) {
int sum = a + b;
return sum;
}
int mul_and_print(int x, int y) {
int prod = x * y;
int arr[3];
arr[0] = prod;
arr[1] = prod + 1;
arr[2] = prod + 2;
printf("mul_and_print: %d * %d = %d\n", x, y, prod);
return prod;
}
int caller(int p, int q, int r) {
int local = p - q + r;
int r1 = mul_and_print(local, q);
int r2 = add(r1, local);
return r2;
}
int main(void) {
int a = 2, b = 3, c = 5;
int out = caller(a, b, c);
printf("result=%d\n", out);
return 0;
}编译:
aarch64-linux-gnu-gcc -g -O0 -fno-omit-frame-pointer stack_demo.c -o stack_demo
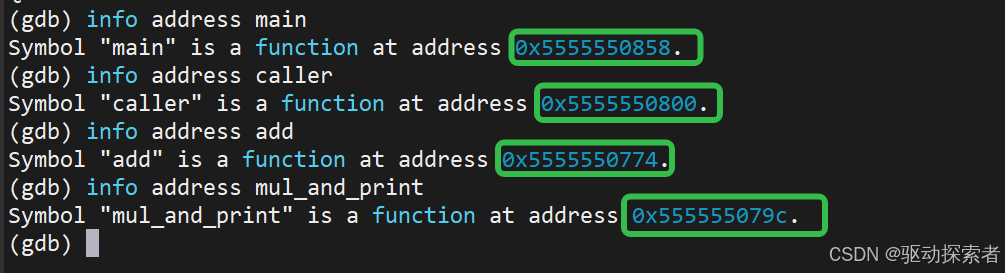
注意这些函数的地址,这些地址是在进程虚拟地址空间映射的text段,或者是动态链接函数的地址,进程的栈一般是vmalloc出来的,cpu看一般都是在i cache看到code段里面的代码,d cache看到栈,所谓的程序的局部性原理都可以用起来,一堆顺手的代码和操作的栈。注意lr一般都是caller的某个偏移的位置上,都是这种地址。
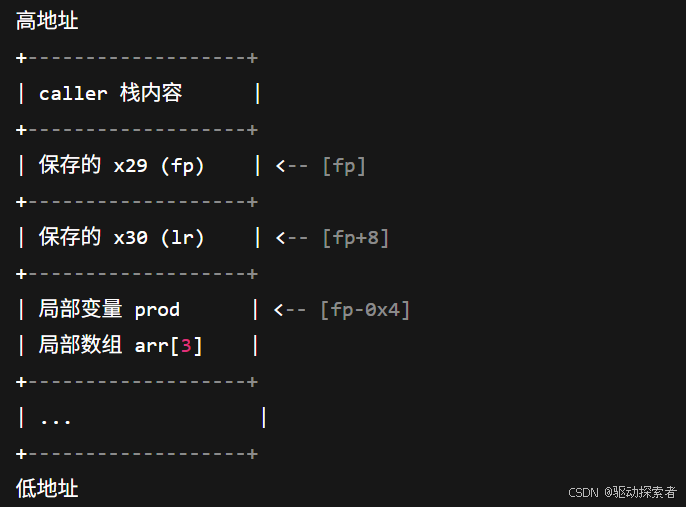
注意caller局部变量:local,r1的地址与值,4,待定
注意mul_and_print局部变量:prod 12,arr[3] 12 13 14
GDB 实战流程
启动:
gdb -q ./stack_demo (gdb) break mul_and_print (gdb) run
Step 1: 看寄存器(参数/返回值)
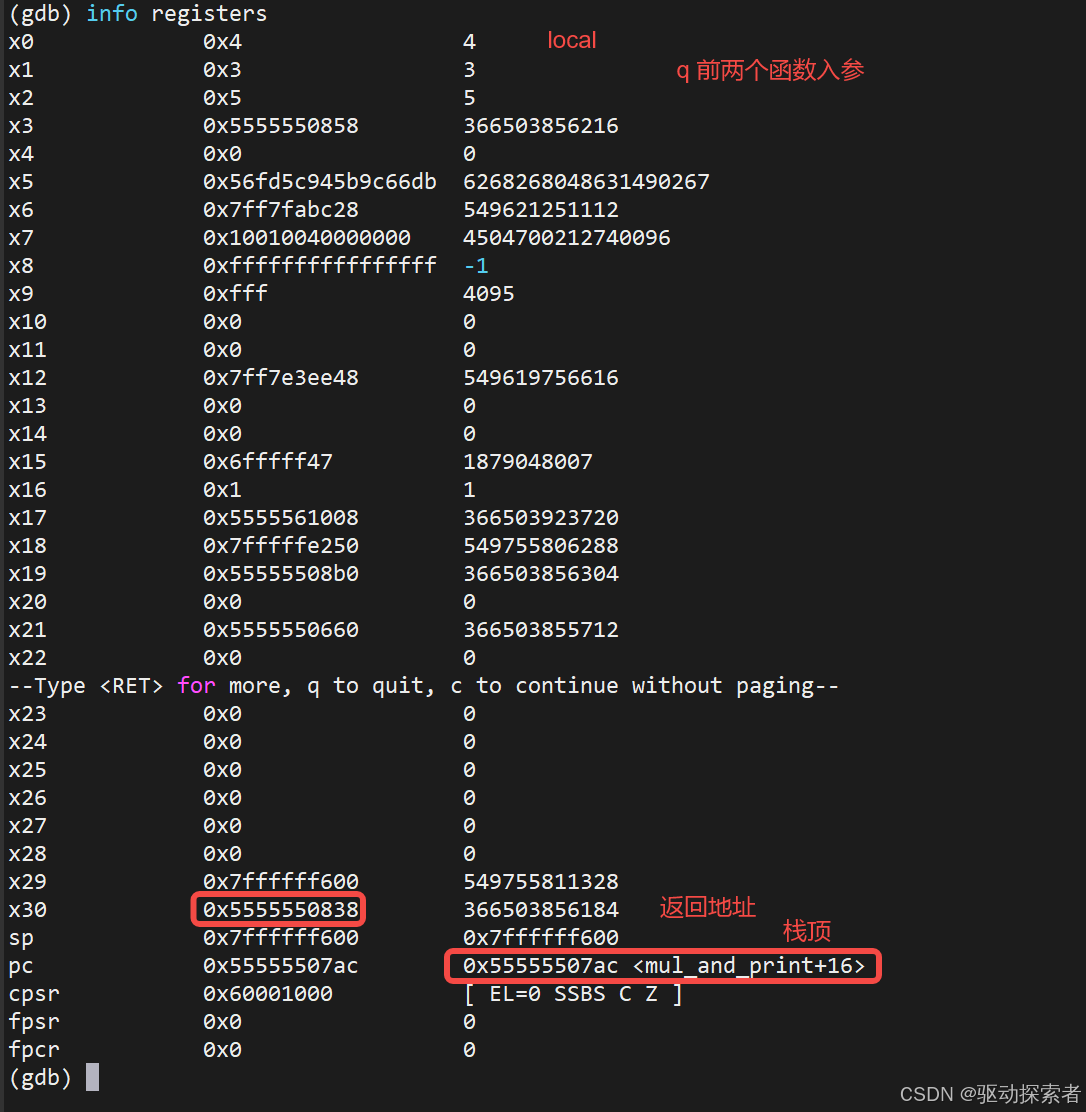
(gdb) info registers
重点:
x0=local,x1=q(前两个参数)x30(lr):返回地址x29(fp):当前栈帧基址sp:栈顶
Step 2: 回溯(栈帧链)
(gdb) bt
输出:
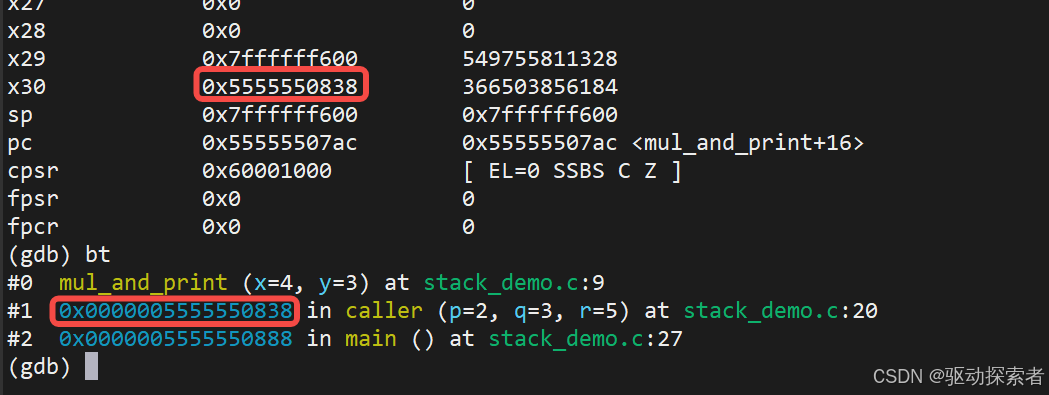
这里就是 ARM64 的 fp 链 在起作用。
caller的地址是800这里为啥是838,看一下反汇编
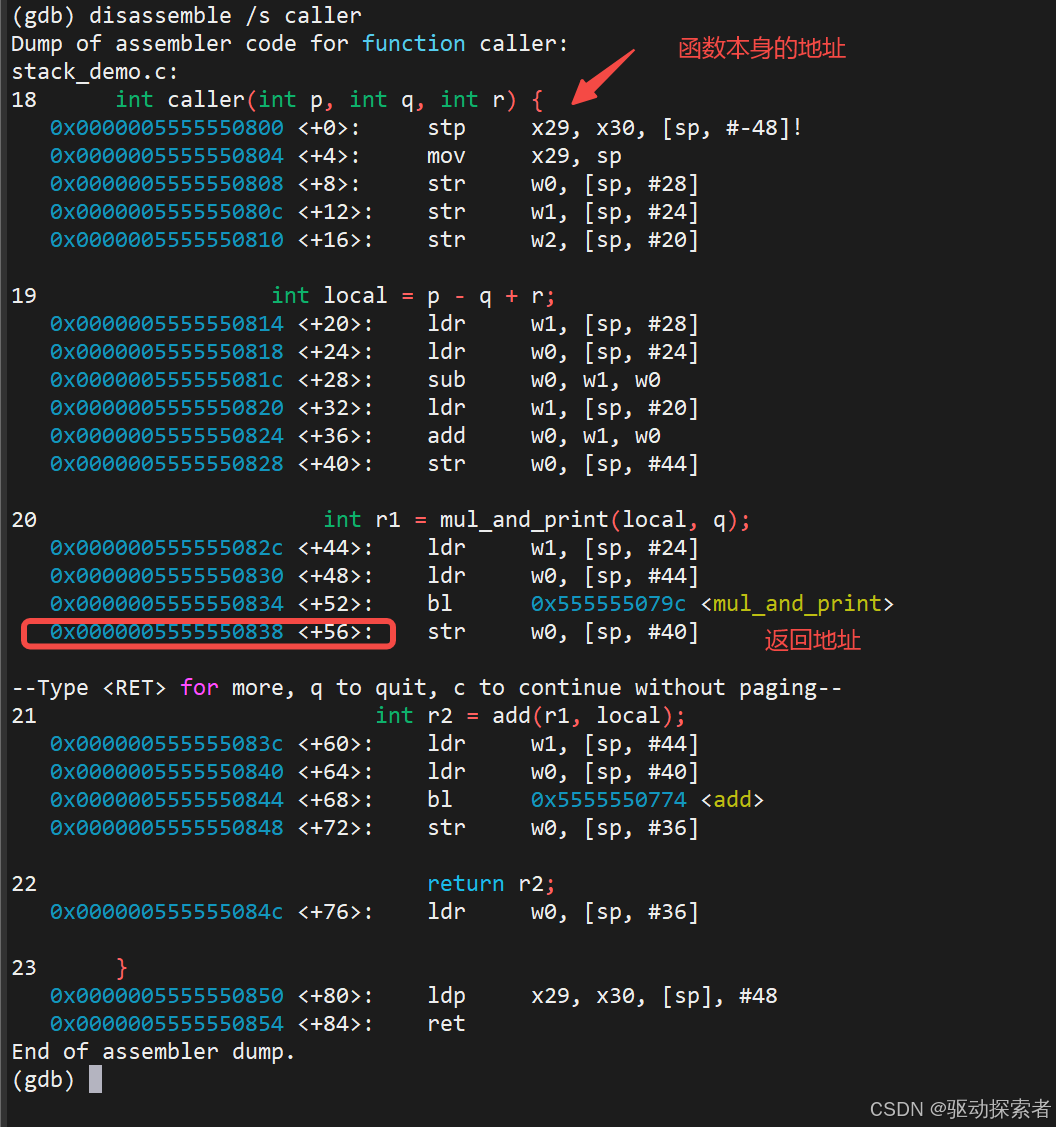
Step 3: 当前帧的详细信息
(gdb) info frame
输出:
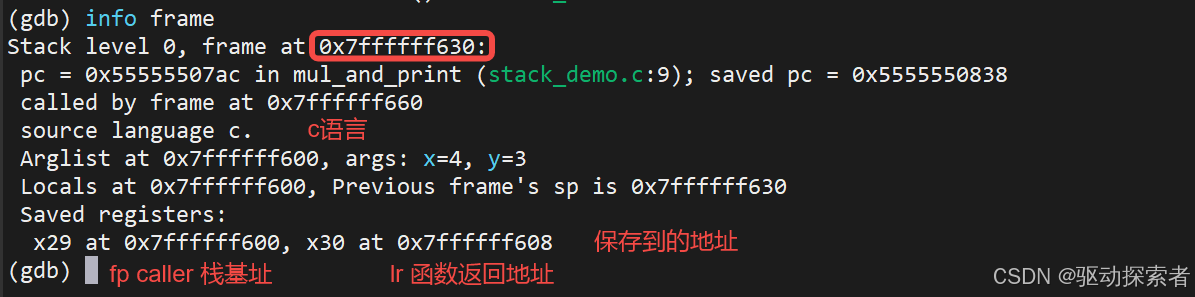
解释:
saved fp(x29):caller 的栈基址saved lr(x30):函数返回地址局部变量在
fp - offset处
入参一般只在x0-x7,具体操作看汇编的结果
局部变量是肯定在栈开始就分配的
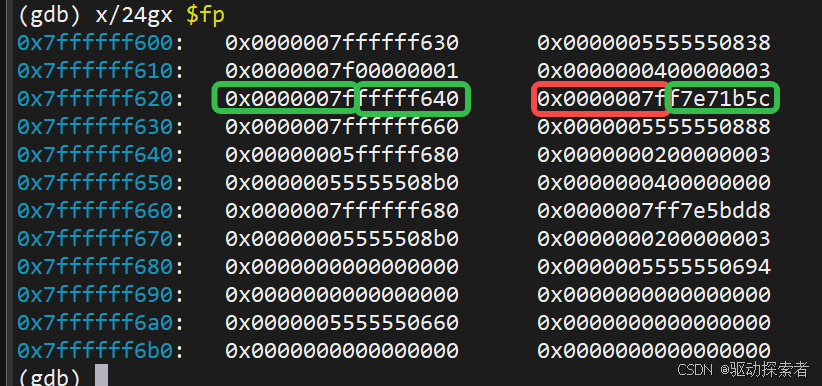
Step 4: 栈内存十六进制展开
(gdb) x/24gx $fp
你会看到:
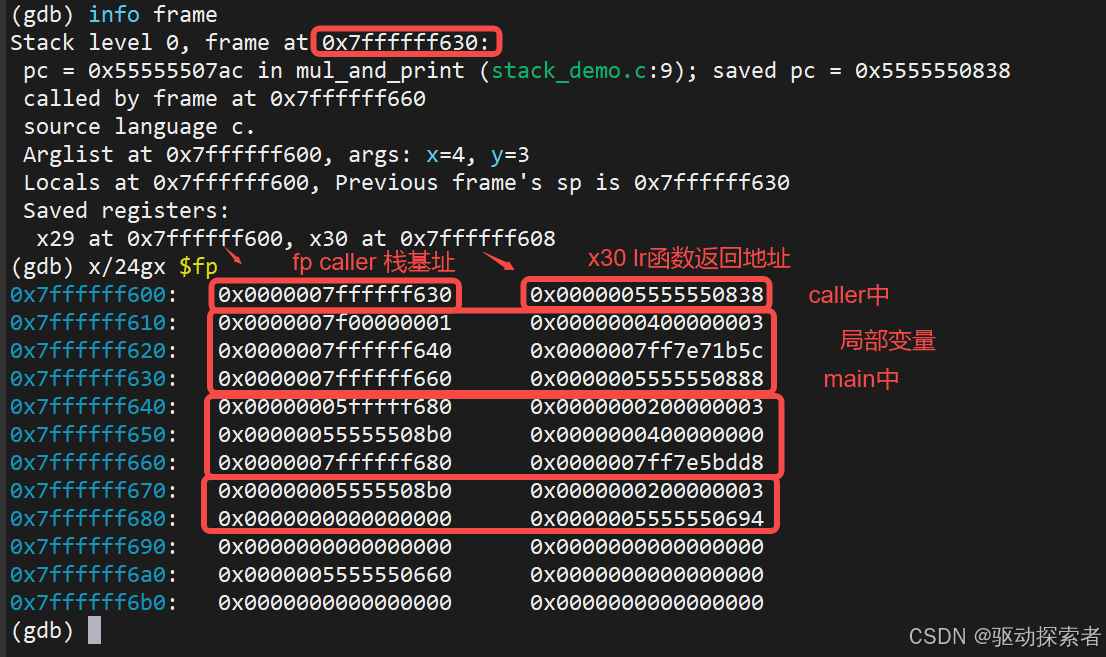
解释:
[fp]保存旧fp[fp+8]保存lr[fp-0x10]等位置放局部变量 (prod,arr[...])
Step 5: 反汇编
(gdb) disassemble /m mul_and_print
ARM64 的典型 prologue / epilogue:
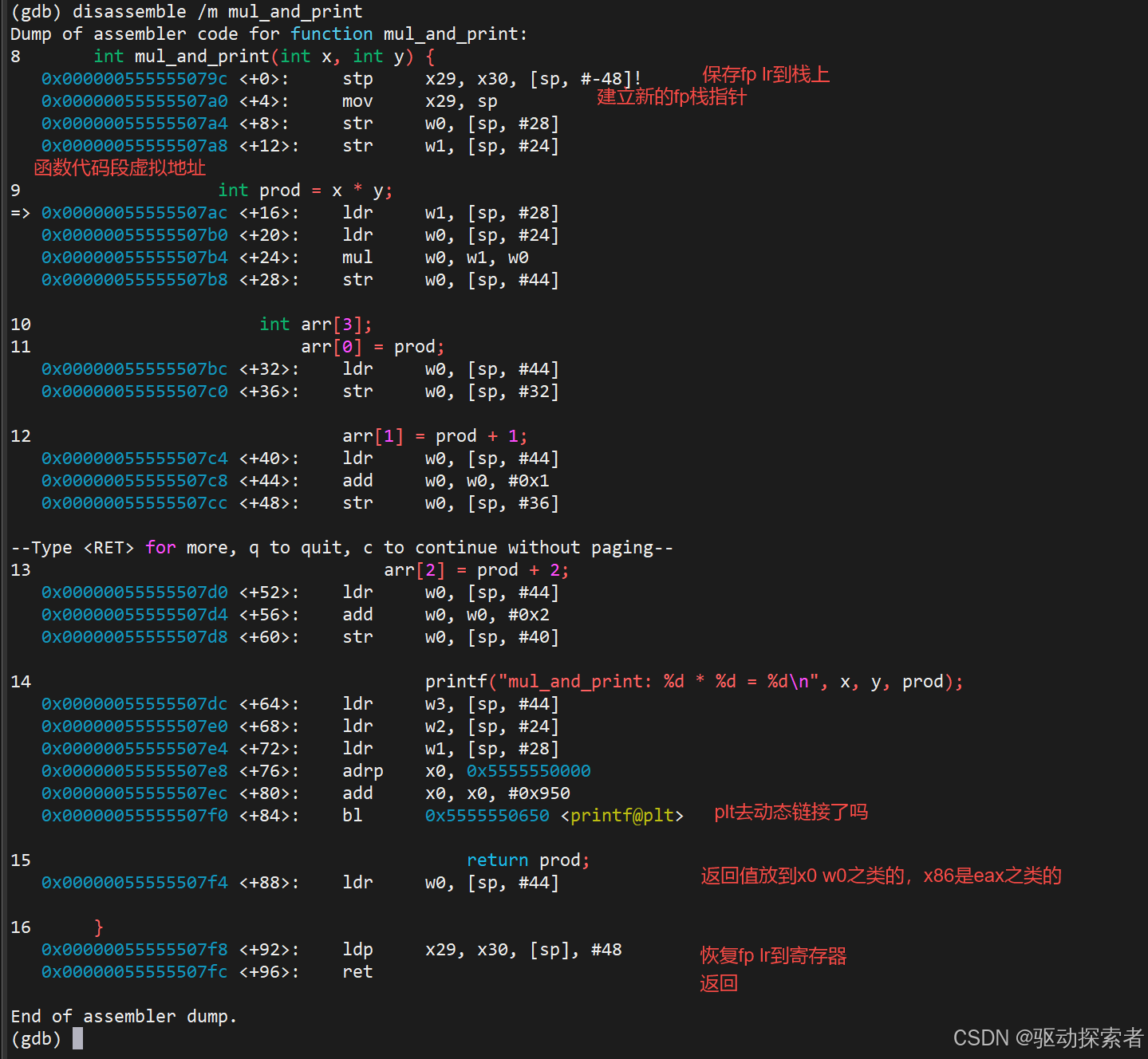
截图建议:截 prologue/epilogue,箭头标出 fp/lr 保存/恢复动作。
Step 6: 局部变量定位
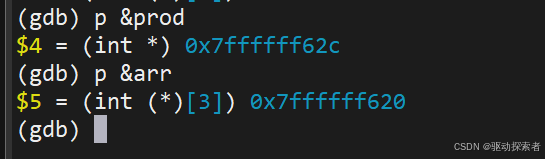
对比 fp 地址:可见 prod 在 [fp - offset]。
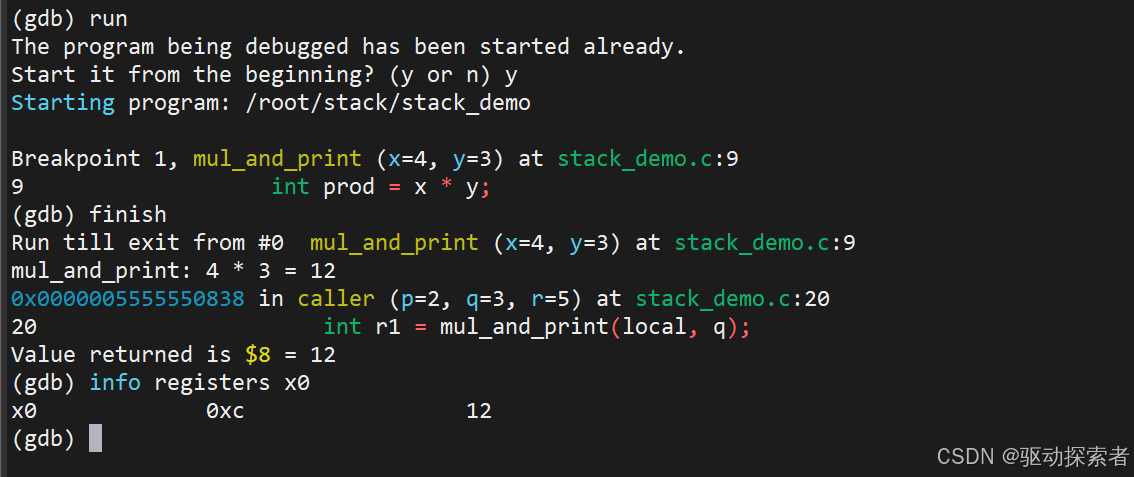
Step 7: 返回值检查
继续执行到 ret,看 x0:
(gdb) stepi # 单步到函数结束 (gdb) info registers x0 x0 0x0000000c
ARM64 栈帧总结构
调用时,mul_and_print 的栈布局大致是: