引言:为什么要学 “记号体系”?
在数据分析中,“拿到数据” 只是第一步,更重要的是 “按需提取数据”—— 比如从 52 张扑克牌中抽出第一张(发牌)、打乱所有牌的顺序(洗牌),甚至筛选出所有红桃牌。《R 语言入门与实践》第四章 “R 的记号体系”,正是围绕这个核心展开:教你如何通过 “索引” 从 R 对象(如数据框)中精准提取子集,这是后续数据修改、分析的基础,也是 R 编程的 “基本功”。
本章的实战场景依然是 “扑克牌数据框deck”(52 行:52 张牌;3 列:face牌面、suit花色、value点数),所有知识点都围绕 “如何操作这副牌” 展开,非常直观。下面我们一步步拆解核心内容,还会重点讲解新用到的函数及其核心参数。
一、先认识 “原材料”:扑克牌数据框deck
在学习索引前,先确保我们有 “可操作的牌堆”。如果还没有deck数据框,可以用第三章的方法生成(或直接用以下简化代码快速创建):
# 快速创建扑克牌数据框(4种花色×13种牌面)
face <- c("king", "queen", "jack", "ten", "nine", "eight", "seven",
"six", "five", "four", "three", "two", "ace")
suit <- rep(c("spades", "hearts", "diamonds", "clubs"), each = 13)
value <- rep(c(13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1), times = 4)
deck <- data.frame(
face = face,
suit = suit,
value = value,
stringsAsFactors = FALSE # 禁用字符自动转因子
)
# 对于向量,默认返回前六个元素。
head(deck)
# face suit value
# 1 king clubs 13
# 2 queen clubs 12
# 3 jack clubs 11
# 4 ten clubs 10
# 5 nine clubs 9
# 6 eight clubs 8
# 查看前5行,验证数据
head(deck, 5)
# face suit value
# 1 king clubs 13
# 2 queen clubs 12
# 3 jack clubs 11
# 4 ten clubs 10
# 5 nine clubs 9二、R 记号体系核心:六种索引方式
R 的索引语法是对象[行索引, 列索引]—— 逗号前控制 “行”,逗号后控制 “列”,通过不同类型的索引,实现 “想取哪部分就取哪部分”。第四章重点讲了六种索引方式,下面结合deck逐一演示。
2.1 正整数索引:“指定位置,精准定位”
用法:用正整数表示 “要提取的行 / 列位置”,适用于知道具体位置的场景。
示例:
# 1. 取第1行第1列(黑桃K的牌面)
deck[1, 1] # 输出:[1] "king"
# 2. 取第1-3行,第1-2列(前3张黑桃牌的牌面和花色)
# 返回的是一个新的数据框
deck[1:3, 1:2]
# face suit
# 1 king spades
# 2 queen spades
# 3 jack spades
# 3. 重复取同一行(比如重复发第一张牌)
deck[c(1, 1), ] # 输出2行黑桃K
# 4.只取一列,则返回一个向量
deck[1:2, 1]
# "king" "queen"
# 这种情况如果想返回一个数据框,在中括号内添加参数drop = FALSE
# 也可以使用同样的方法从矩阵、数组中取一列数据
deck[1:2, 1, drop = FALSE]
# face
# king
# queen关键注意:R 的索引从1开始(区别于 Python 的 0 开始),这是新手最容易踩的坑!
2.2 负整数索引:“排除指定位置”
用法:用负整数表示 “要排除的行 / 列位置”,适用于 “保留大部分,排除少数” 的场景。
示例:
# 1. 排除第1行,取所有列(剩下51张牌)
deck[-1, ] # 第一行黑桃K被排除
# 2. 排除第2-52行,取所有列(只留第1行,即发牌逻辑)
deck[-(2:52), 1:3] # 仅输出黑桃K禁忌:同一维度不能同时用正、负整数(如deck[c(1, -2), ]会报错)。
2.3 零索引:“啥也不取”
用法:索引用0,返回空对象,几乎没有实际用途,但需要知道存在这种方式。
示例:
deck[0, 0] # 输出空数据框(无行无列)
# data frame with 0 columns and 0 rows2.4 空格索引:“全选某维度”
用法:行或列的位置留空,表示 “提取该维度的所有元素”,是 “全选” 的快捷方式。
示例:
# 1. 取第1行,所有列(发牌时取第一张牌)
deck[1, ] # 输出黑桃K的完整信息
# face suit value
# 1 king spades 13
# 2. 取所有行,第3列(所有牌的点数)
deck[, 3] # 返回长度为52的数值向量2.5 逻辑值索引:“按条件筛选”
用法:用TRUE/FALSE组成的逻辑向量指定行 / 列,TRUE保留,FALSE排除。数据分析中最常用,因为不需要知道具体位置,按条件筛选即可。
示例:筛选所有 “ACE 牌”
# 1. 生成逻辑向量:哪些行的face是"ace"(TRUE=是ACE,FALSE=不是)
is_ace <- deck$face == "ace" # 结果是长度为52的逻辑向量
# [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
# [9] FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE
# [17] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
# [25] FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
# [33] FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE
# [41] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
# [49] FALSE FALSE FALSE TRUE
# 2. 用逻辑向量取子集
deck[is_ace, ] # 输出4张ACE牌
# face suit value
# 13 ace spades 1
# 26 ace hearts 1
# 39 ace diamonds 1
# 52 ace clubs 1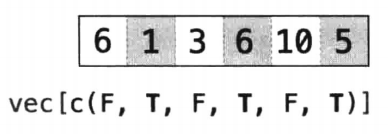
核心:R会匹配索引值为TRUE的行/列位置的相应元素,忽略所有索引值为FALSE的位置元素;逻辑向量的长度必须与 “要筛选的维度长度一致”(如筛选行,逻辑向量长度 = 行数 52)。
2.6 名称索引:“按名称提取,可读性高”
用法:如果对象有名称属性(如数据框的列名),用名称代替位置,代码更易读。
示例:
# 1. 取"face"和"suit"列,所有行(所有牌的牌面和花色)
deck[, c("face", "suit")]
# 2. 取第1行,"value"列(黑桃K的点数)
deck[1, "value"] # 输出:[1] 13优势:不需要记列的位置(比如不用记 “点数是第 3 列”),直接用列名,适合列多的数据框。
三、实战:用索引写 “发牌” 和 “洗牌” 函数
学完索引,就可以落地到实际场景:用代码模拟 “发牌” 和 “洗牌”,这是第四章的核心实战。
3.1 发牌函数:deal()—— 提取第一行
需求:每次从牌堆顶部发一张牌(即提取数据框第一行)。
代码实现:
deal <- function(cards) {
# 输入:cards(牌堆数据框)
# 输出:第一行(第一张牌)
cards[1, ] # 空格索引=取所有列
}
# 测试:发一张牌
deal(deck) # 输出黑桃K核心逻辑:用 “正整数索引(1 行)+ 空格索引(所有列)”,精准提取第一张牌。
3.2 洗牌函数:shuffle()—— 打乱行顺序
需求:随机打乱 52 张牌的顺序,核心是用sample()函数生成随机行号,再重新排列数据框。
先重点讲sample()函数的核心参数
sample()是 R 中生成随机抽样的核心函数,第四章在洗牌场景中深化了其用法,核心参数如下:
| 参数 | 作用说明 |
|---|---|
x |
待抽样的向量(必填):这里用1:nrow(cards),代表所有牌的行号(1~52) |
size |
抽样数量(必填):这里设为nrow(cards),即抽取所有行号,实现 “全打乱” |
replace |
是否放回抽样(可选,默认FALSE):这里必须为FALSE,避免重复行号 |
洗牌函数代码实现
# 方式一:
# 生成1-52个随机数
random <- sample(1:52, size = 52)
# 按照随机数取出deck中的牌赋值给deck1
deck1 <- deck[random,]
head(deck1)
# 方式二(推荐):封装洗牌方法,后续可以随时调用
# 在后续的编程学习中这种思维很重要,避免各处需要用同种方法时重复编写,会造成大量冗余
shuffle <- function(cards) {
# 步骤1:生成1~nrow(cards)的随机行号(无重复)
random_rows <- sample(
x = 1:nrow(cards), # 待抽样的行号向量
size = nrow(cards) # 抽取所有行号
)
# 步骤2:按随机行号重新排列数据框
cards[random_rows, ]
}
# 测试:调用shuffle打乱牌堆方法,deck作为入参
shuffled_deck <- shuffle(deck)
head(shuffled_deck, 5) # 查看打乱后的前5张牌效果:每次运行shuffle(deck),都会得到不同顺序的牌堆,完美模拟现实中的洗牌。
四、特殊提取符号:$与[[ ]]—— 高效取元素
除了[ ]索引,第四章还介绍了两种更便捷的提取方式,专门用于数据框和列表。
4.1 美元符号$:数据框列的 “快捷键”
用法:数据框$列名,直接提取指定列,返回向量(无需写括号和逗号)。
示例:
# 1. 提取所有牌的点数列
deck$value # 返回长度为52的数值向量
# 2. 计算所有牌的平均点数
mean(deck$value) # 输出:[1] 7(符合扑克牌点数分布:1~13的平均是7)优势:比deck[, "value"]更简洁,是日常提取数据框列的首选方式。
4.2 双中括号[[ ]]:提取 “单个元素” 的利器
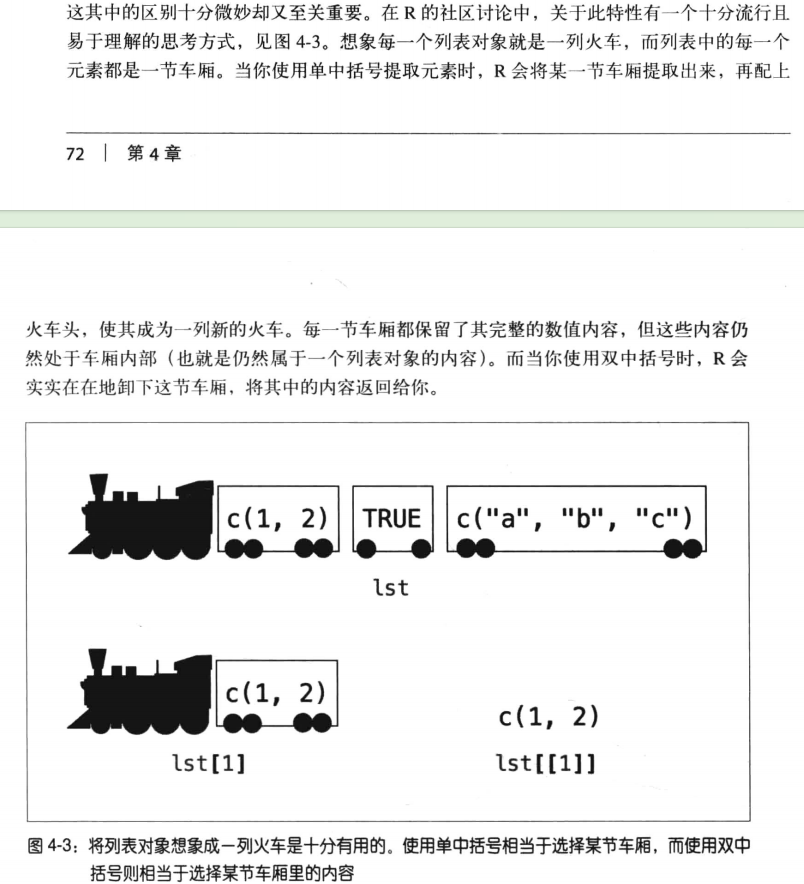
核心区别:
[ ]:提取后返回 “原对象类型”(如列表用[ ]取元素,返回子列表;数据框用[ ]取列,返回数据框);[[ ]]:提取后返回 “元素本身类型”(如列表用[[ ]]取元素,返回向量;数据框用[[ ]]取列,返回向量)。
示例(以列表为例):
# 创建一张牌的列表(包含牌面、花色、点数)
card_list <- list(face = "ace", suit = "hearts", value = 1)
# 1. 用[[ ]]按名称提取“点数”,返回数值型
card_list[["value"]] # 输出:[1] 1
# 2. 用$提取([[ ]]的简化版,按名称)
card_list$value # 输出:[1] 1
# 3. 用[ ]提取,返回子列表(不是数值)
card_list["value"]
# $value
# [1] 1适用场景:当你需要 “提取元素本身”(如用于计算)时用[[ ]]或$;当你需要 “保留原对象结构” 时用[ ]。直接附上原书该段内容的解释,帮助大家理解。
五、第四章新函数 / 操作核心参数汇总
为了方便查阅,整理本章涉及的新函数和操作的核心信息:
| 函数 / 操作 | 核心参数 / 用法 | 作用说明 |
|---|---|---|
sample(x, size, replace) |
x:待抽样向量;size:抽样数量;replace:是否放回 | 生成随机抽样,用于洗牌打乱行号 |
deal(cards) |
cards:输入数据框(牌堆) | 提取第一行,实现 “发牌” |
shuffle(cards) |
cards:输入数据框(牌堆) | 打乱行顺序,实现 “洗牌” |
数据框$列名 |
列名:数据框的列名称 | 提取指定列,返回向量(便捷方式) |
对象[[索引/名称]] |
索引:位置或名称 | 提取单个元素,返回元素原始类型 |
head(x, n) |
x:输入对象;n:查看行数(默认 6) | 查看数据前 n 行,辅助验证数据 |
tail(x, n) |
x:输入对象;n:查看行数(默认 6) | 查看数据后 n 行,辅助验证数据 |
六、小结:第四章的 “承上启下”
- 本章核心:掌握六种索引方式,实现 “从数据框中精准取子集”—— 这是后续修改数据(如第五章调整 A 的点数为 14)、分析数据的基础;
- 实战价值:通过
deal()和shuffle()函数,将索引知识落地到 “扑克牌” 场景,理解 “代码如何模拟现实操作”; - 后续铺垫:下一章(第五章)会基于本章的索引知识,学习 “对象改值”,比如根据不同游戏规则调整扑克牌点数,进一步深化数据处理能力。
动手练习:试着修改deal()函数,实现 “一次发 5 张牌”;或者用逻辑索引筛选出所有 “红桃牌”,巩固本章知识吧!