从函数到神经网络
最开始的时候人们将万事万物都描述成函数的表达形式,但是后来有很多事情并不能够将其描述成函数的形式,于是后来就不在追求找到精确的函数,而是找到一个近似解。
如何从线性函数变为非线性的?
在这个函数的最外层在套入一个非线性运算就可以了,比如套一个平方,套一个sin,这就是 激活函数

当我们一次激活不行的话,将激活函数的整体在进行线性变化,在进行一次激活,这样就可以得到复杂的线性变换关系。
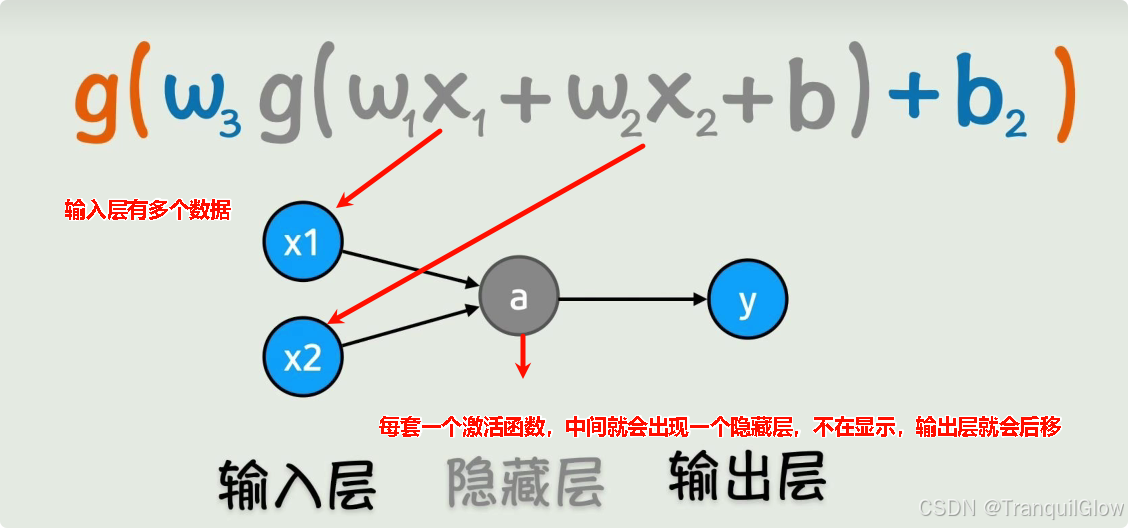
- 这个输入层可以无限增加,隐藏层也可以无限增加,这样就可以构成一个非常复杂的非线性函数了
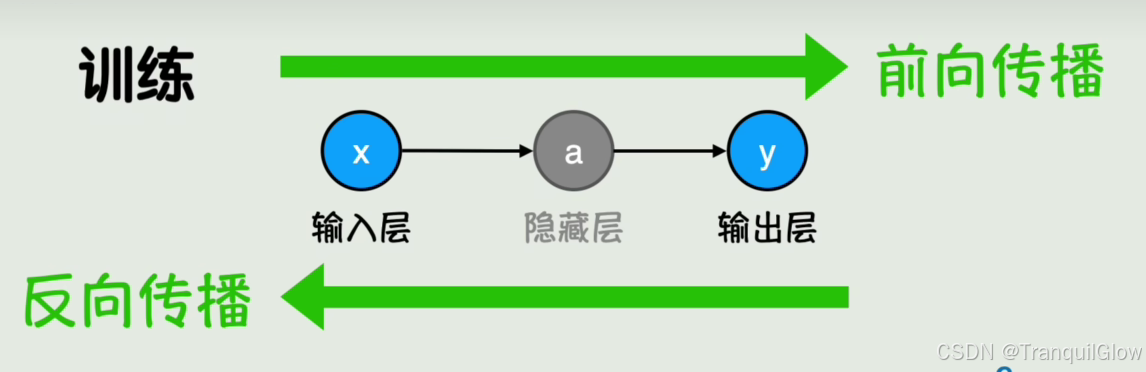
顺着这个神经网络的方向进行计算,就是神经网络的前向传播
如何计算神经网络的参数
- 什么样的参数是好的呢,拟合的好才是真的好
- 人能够凭借感官来得知什么拟合的好,什么拟合的不好,那机器怎么判断什么拟合的好,什么拟合的不好呢
损失函数
机器通过损失函数来判断这个拟合的好坏
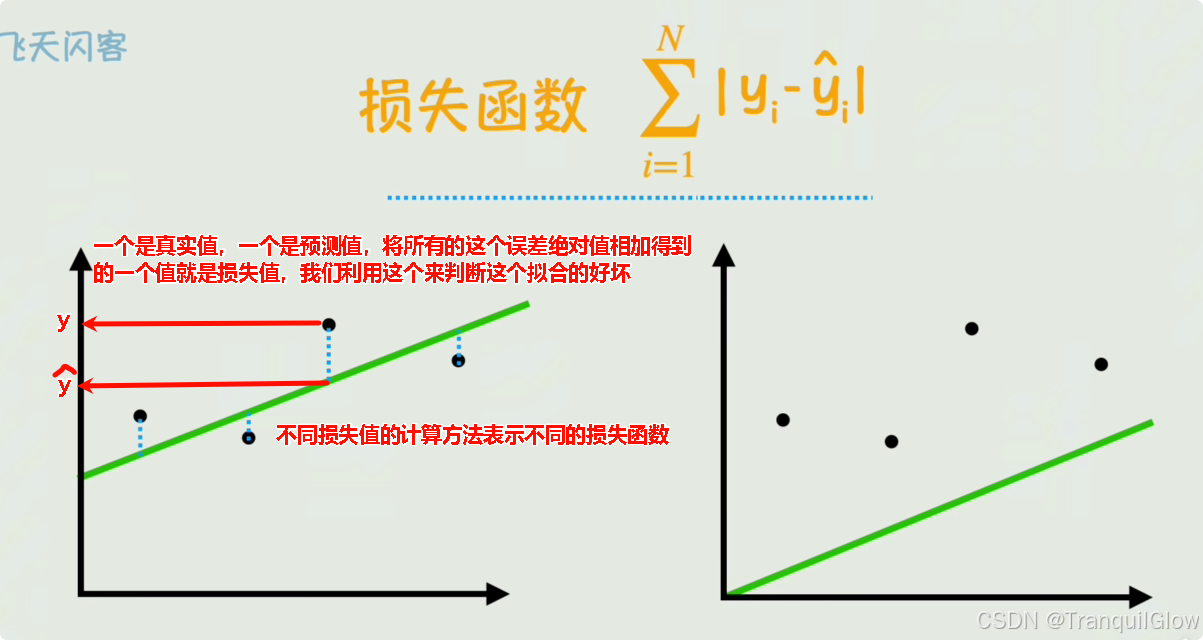
- 后续我们可以将这个绝对值,换成平方,消除绝对值的计算,也可以除以n表示消除样本数量的影响。这样就可以得到一个新的损失函数
如何求解这个w和b呢

- 如何求解这个让L最小的w和b的值呢,我们可以通过这个 导数 求极值点的方式来实现这个。多维函数就求偏导即可。
- 我们将这个w和b向偏导数相反的方向中进行减少
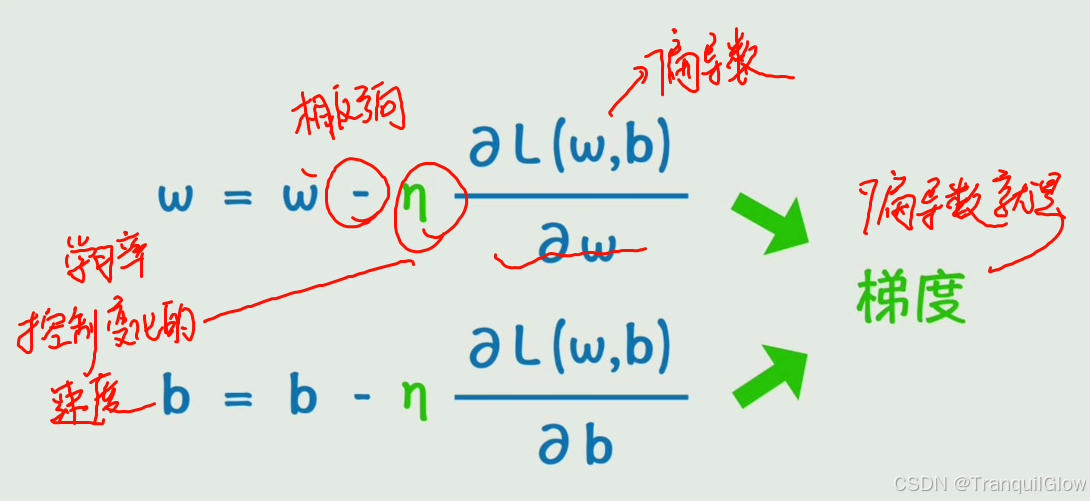
- 这个学习率就是控制这个变换的快慢
- 梯度就是偏导数构成的向量
- 这个计算过程就是 梯度下降
但是上述的函数求导也会出现问题,就是当这个函数很复杂的时候这个偏导会不太好求。
- 可以将各层的偏导数给乘起来,这样就能够计算这个偏导数了
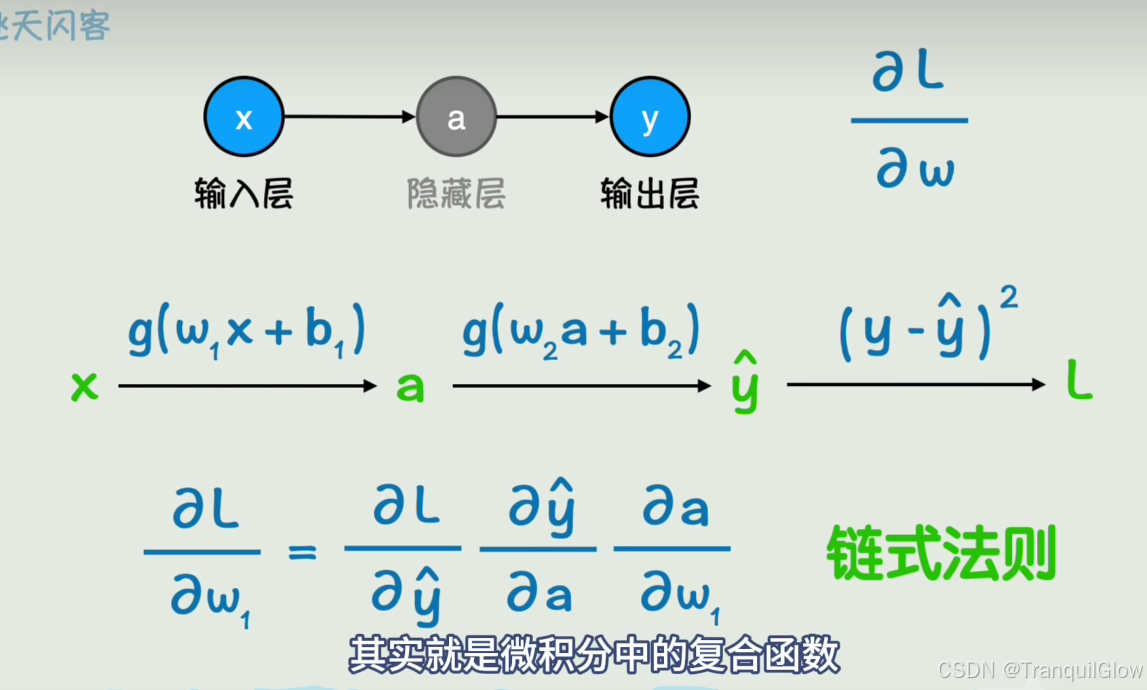
- 从右往左进行计算,一层一层的更新参数,后面一层的偏导数值前面也可以用到,一点一点的传播过来,这个过程称为反向传播
- 可以将各层的偏导数给乘起来,这样就能够计算这个偏导数了
调教神经网络的方法
当你在训练数据上表现的很完美,但是对没见过的数据表现的很一般这种情况就是过拟合现象
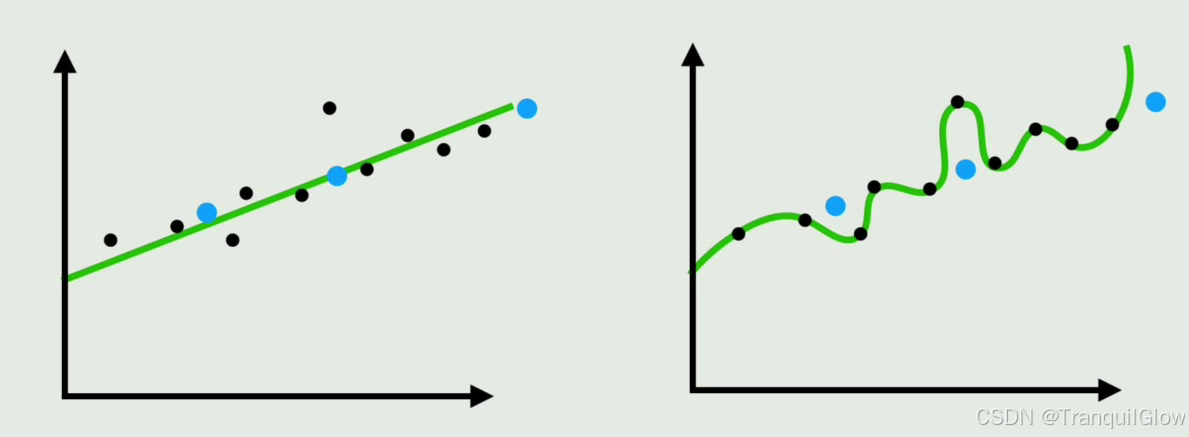
- 在没见过的数据上的表现能力称为泛化能力
- 有的时候明明模型应该很简单的,但是采用的神经网络结构太复杂了,导致神经网络将模型中的噪声和随机波动也给学习了。得出,神经网络不是越大越好。
对于这种过拟合情况解决办法
通过减少模型复杂度,让模型不能够读取到这个数据的各种噪声等特征
增加数据量,我们可以通过加入噪声,旋转,反转,裁剪等操作——这种操作称为数据增强
这样不仅仅增加了模型的数据,还能够让模型不因输入的一点点小的变化,而对结果产生很大的波动, 增强了模型的鲁棒性训练过程本身就是调整参数的过程,只需要让这个参数不在朝着过拟合的方向发展就可以了
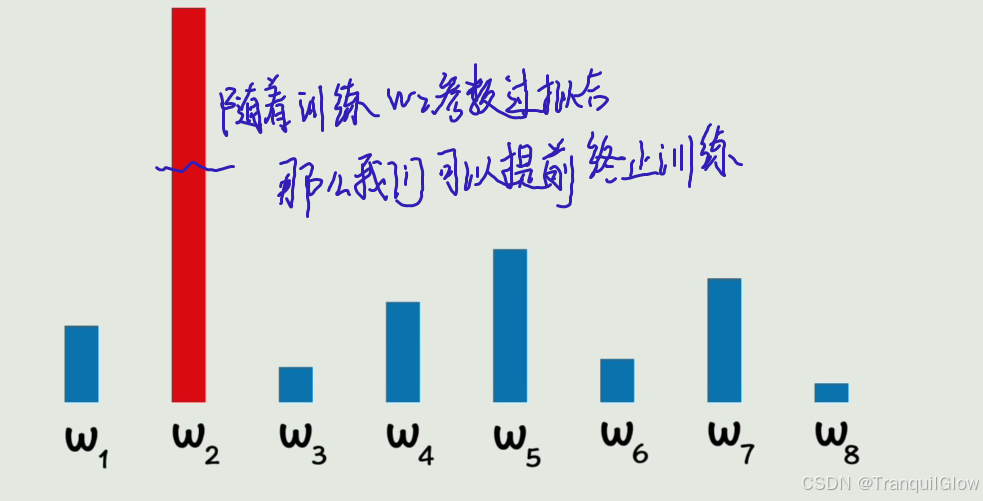
参数是往损失函数变小的方向不断的调整的,这个是梯度下降,之后当参数增加的时候,损失函数减少,当出现过拟合的时候, 这个损失函数最小,这个参数增加的有点过分- 所以有个特别抽象的方法,训练的差不多就行了,提前终止训练
- 还有一种办法就是,损失函数加上这个参数的变化量,这样如果损失函数初始+w参数初始<损失函数减少+w参数增加的话,此时就认为这个w参数不应该在增加了,实现过拟合的修正
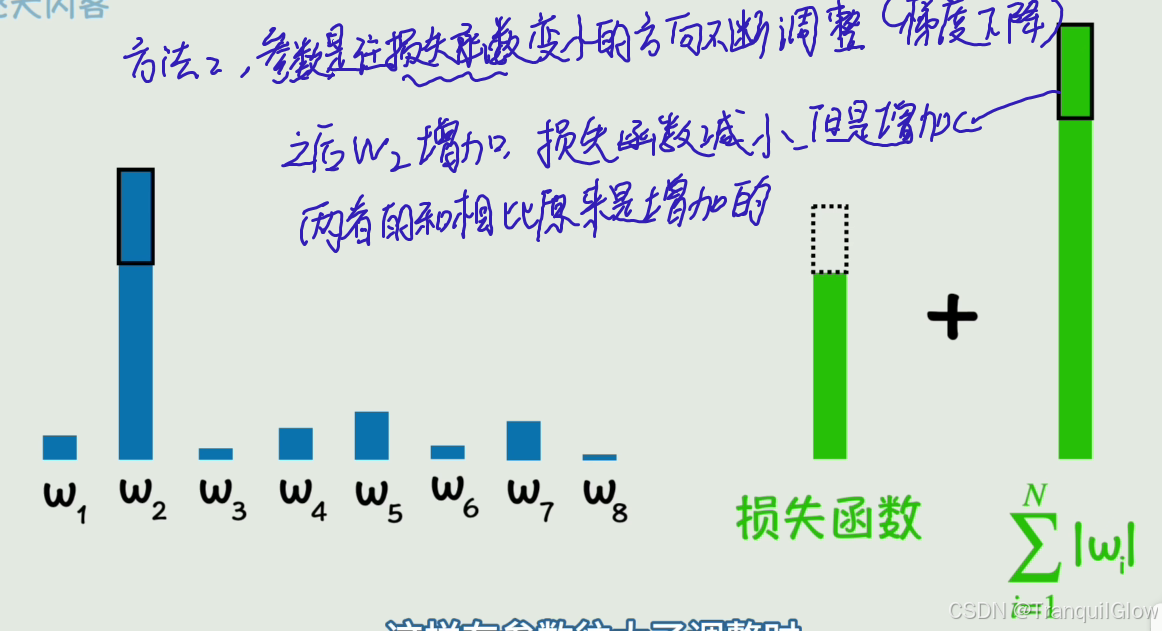
- 对于第二种方法,我们可以向损失函数中加入绝对值,加入平方和,这种向损失函数加入权重,惩罚项,抑制其野蛮增长的方法叫做正则化
- 第三种方法,过拟合的本质就是模型过于依赖某个参数,因此我们可以在训练过程中,每次随机丢弃掉几个参数,让重要的参数偶尔缺席,这样模型就会学会依赖更多的参数。 称为丢弃
- 所以有个特别抽象的方法,训练的差不多就行了,提前终止训练
模型还会遇到其它问题
- 梯度消失,网络越深,梯度反向传播时会越来越小,导致参数更新困难
- 梯度爆炸,梯度数值越来越大,参数的调整幅度失去了控制
- 收敛速度,可能会陷入局部最优,或者来回震荡
- 计算开销,数据规模量太大了,每次完整的前向传播和反向传播都非常耗时
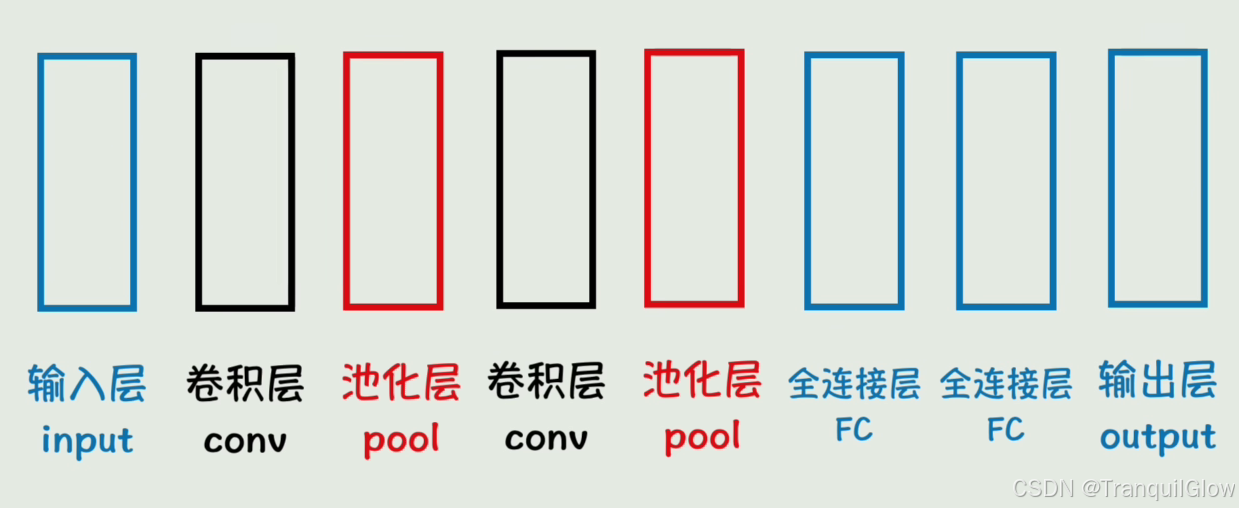
从矩阵到CNN
这个函数多的话,计算起来太复杂了,我们可以使用矩阵来表示
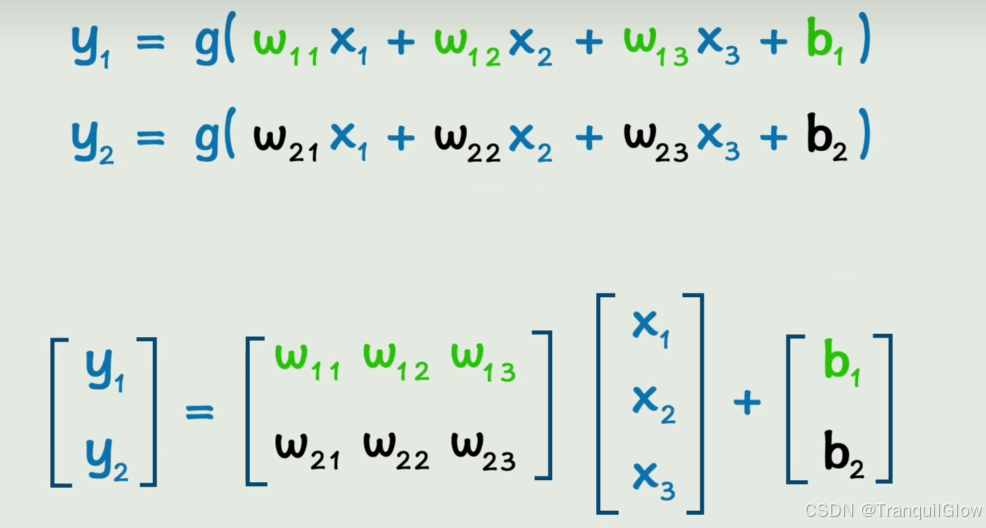
我们用W来表示第一个矩阵,X表示第二个矩阵,b表示第三个矩阵,这样我们就实现了这个Y=g(WX+b)这个是只有一层的情况,当我们出现了很多层的情况时,就可以用一个递推公式来表示
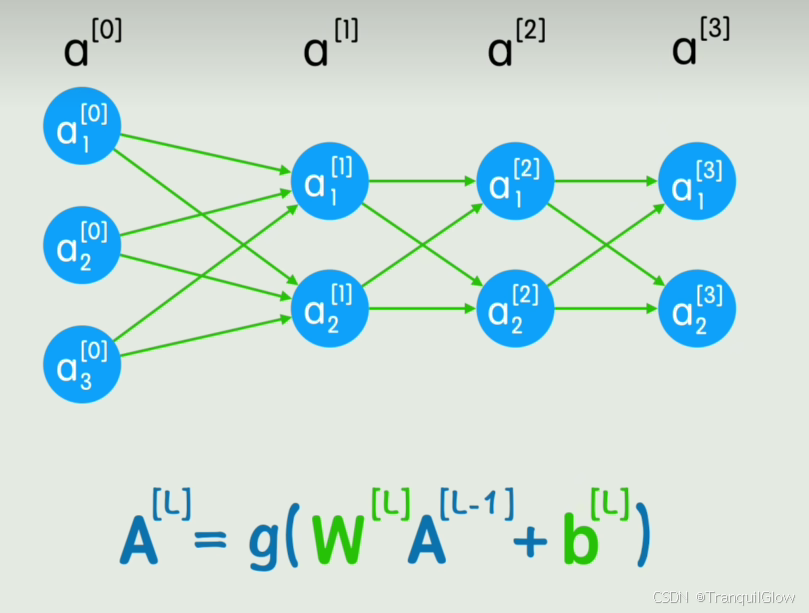
利用矩阵运算,可以充分利用GPU的并行运算性能,加速推理过程
我们观察神经网络结构发现,每一个神经元都和前面所有神经元相连,这一层称为 全连接层(FC)
卷积的诞生
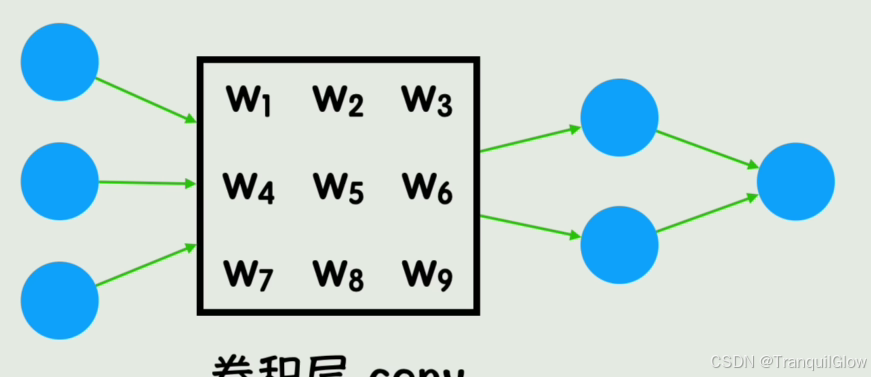
对于一个30 * 30的图像,输入给神经网络的有900个神经元,加入下一层有1000个神经元构成全连接层,那么就会有900000个参数,太大了,并且当图片产生了移动,变暗,这些参数又会全部变化,没有局部性,因此诞生了卷积
将图像中的固定大小的区域的灰度值与卷积核相乘,得到一个结果,填到结果当中,这样一个结果就会与周围色块产生联系
不同的卷积核的值可以实现不同的效果,比如说锐化,模糊等
深度学习中卷积核的值是未知的, 是被训练出的一组值
我们在深度学习模型训练的时候,把其中的一个全连接层替换成一个卷积层
卷积层之后还有池化层,作用是对卷积层后的特征图像进行 降维 ,减少计算量,同时 保留主要特征
从词嵌入到RNN
判断后续的字是什么,判断这个词的褒贬意思
想要对字进行判断,首先将字转换为计算机能够识别的数据
- 如果维度过低,一个数字表示一个字这样看不出来关系
- 如果维度过高,定义一个几万维的,每一个数字中各维度中只有一个是1其余是0,此时数字之间还是没有关系
- 维度不高不低的,词嵌入,每一个维度都可以表示一个特征
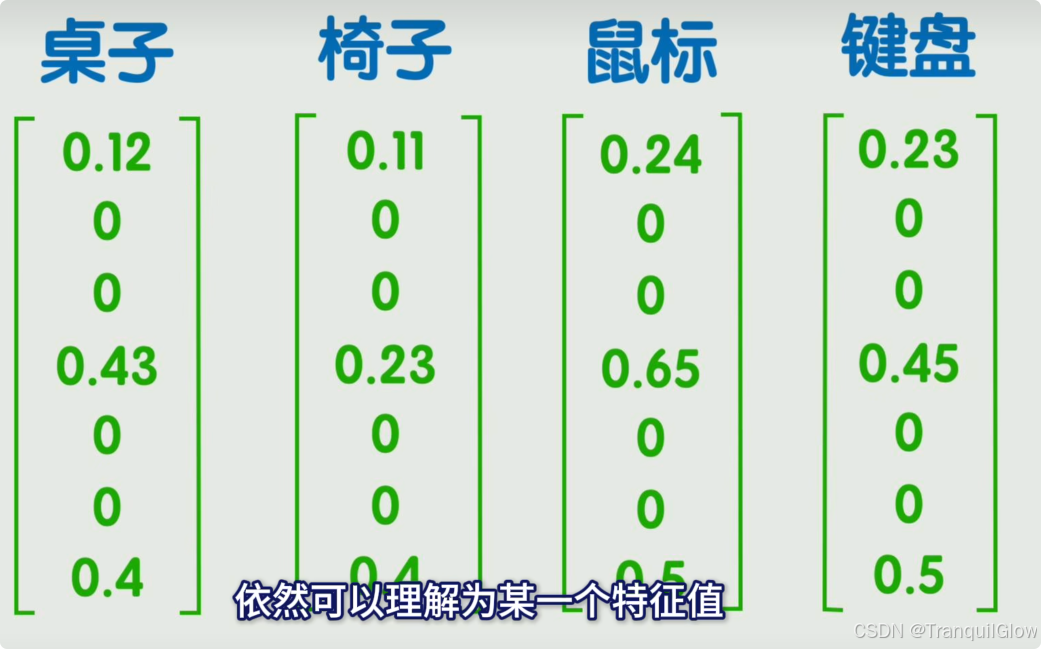
- 我们可以通过两个向量的点积,或者余弦相似度来表示这两个词语之间的相关性

如何建立词语词之间的顺序关系和联系呢
- 我们可以在矩阵上面做一个序号标记,同时让上一个词语产生的结果不急着输出,而是作为一个隐藏层加入到下一层的计算中
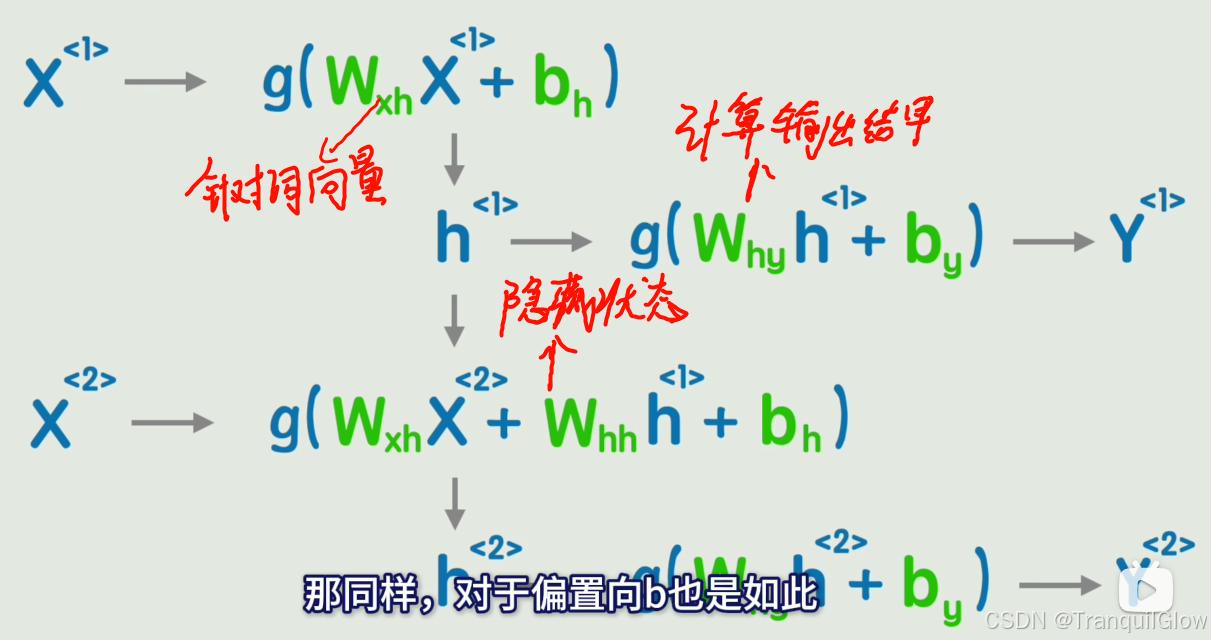
- 将这个图简化以下,就成了循环神经网络
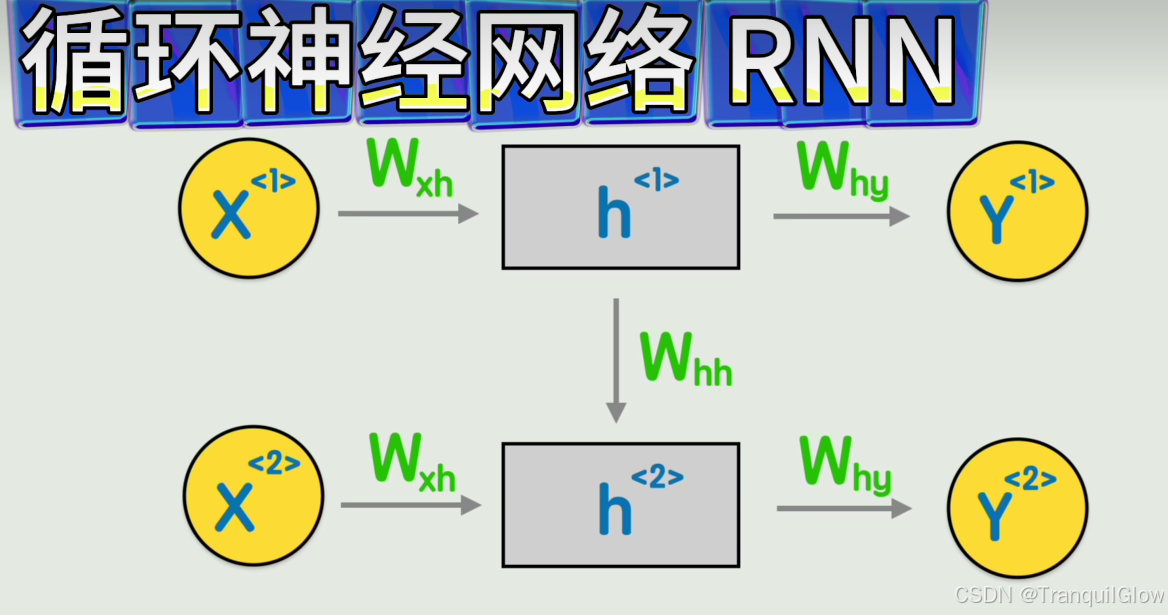
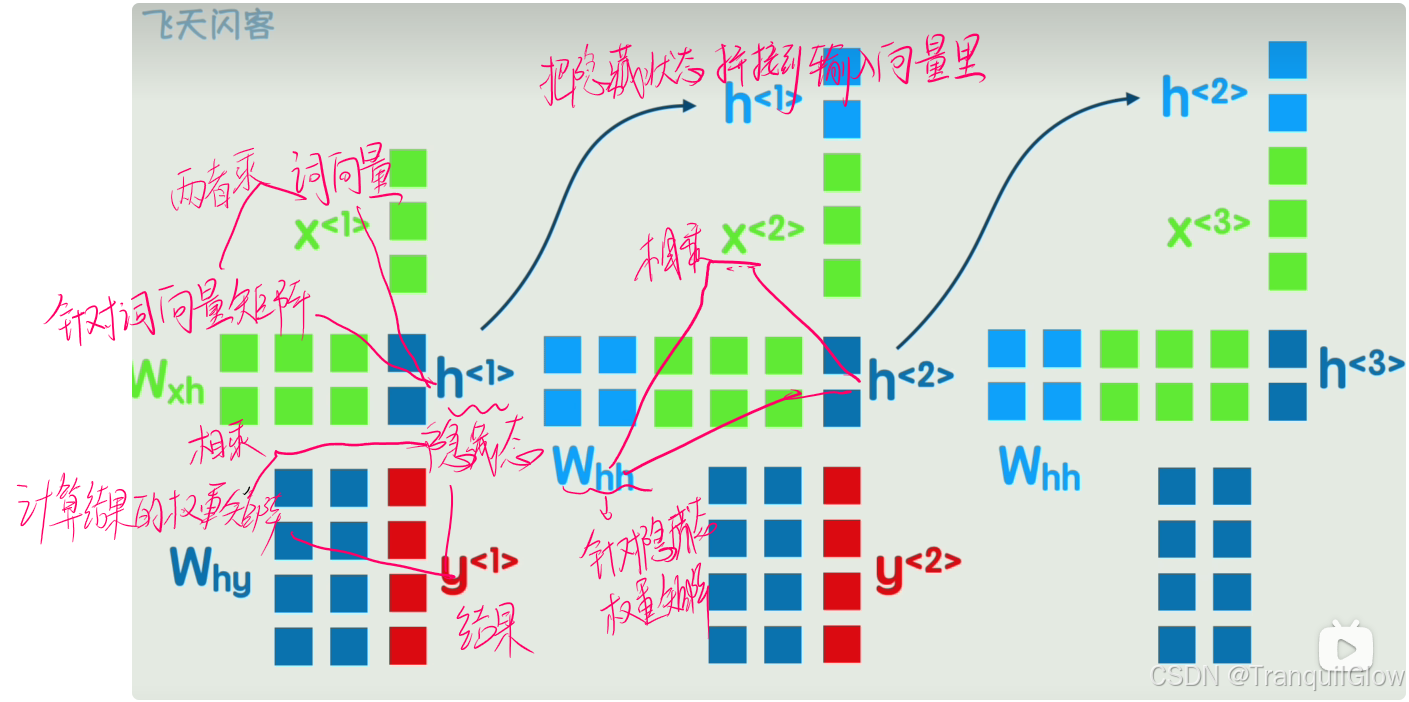
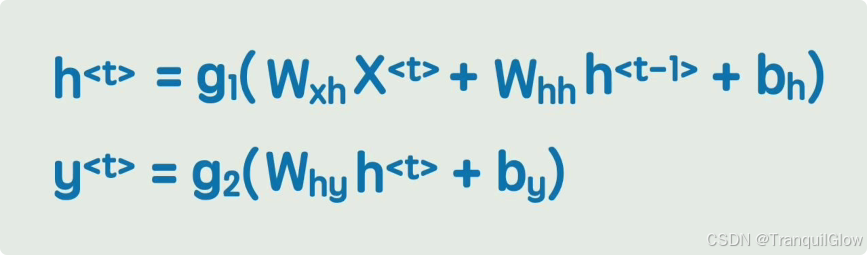
- 我们可以在矩阵上面做一个序号标记,同时让上一个词语产生的结果不急着输出,而是作为一个隐藏层加入到下一层的计算中
简单而强大的Transformer
RNN会出现当句子过长,会出现长期依赖困难的问题
于是就诞生了Transformer
给每一个词添加一个位置编码,并将位置编码添加到词向量里,现在每一个词就有了位置信息
此时每个词还没有其它词的上下文信息,注意不到其他词的存在用训练得到的Wq,Wk,Wv三个矩阵和向量相乘,得到三个矩阵q,k,v
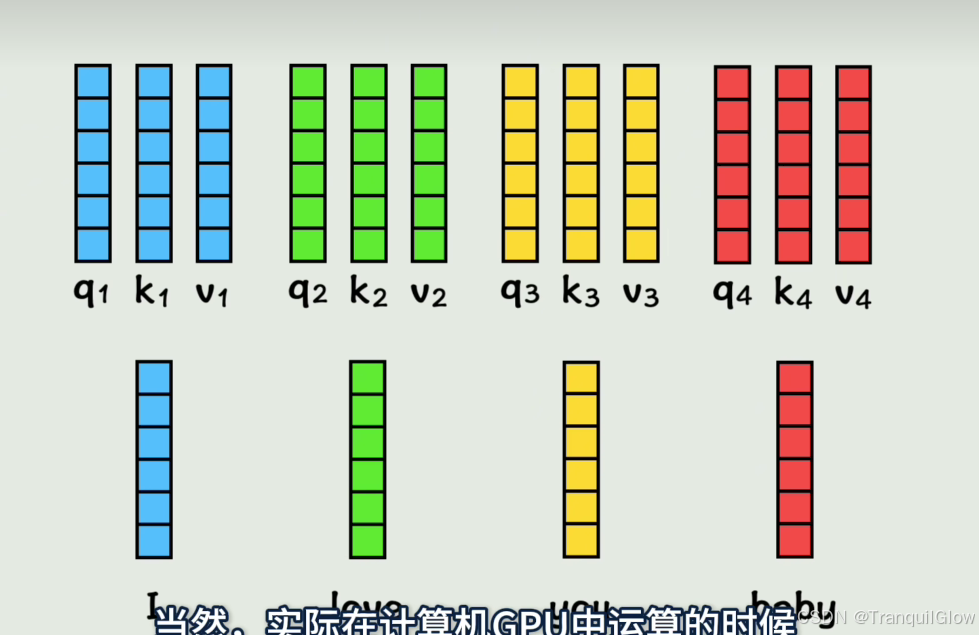
将第一个q矩阵和第二个k矩阵做点积可以得到这个词与词的相似度
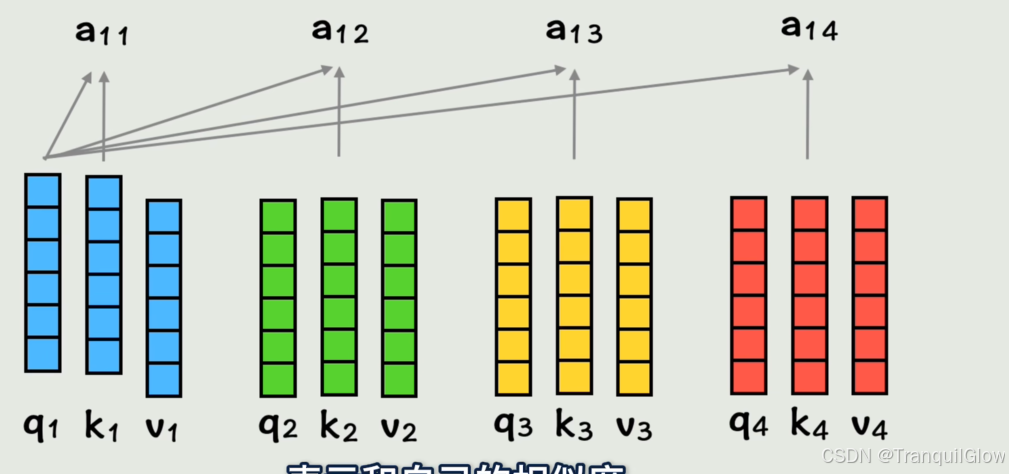
然后得到这个系数之后让其与v系数相乘,在相加得到A1矩阵看,这样A1中就包含,第一个词视角下 ,按照和它相似度大小(a1i),按权重(v矩阵)把每个词的词向量加到了一块,这就把全部上下文的信息都包含在第一个词当中了
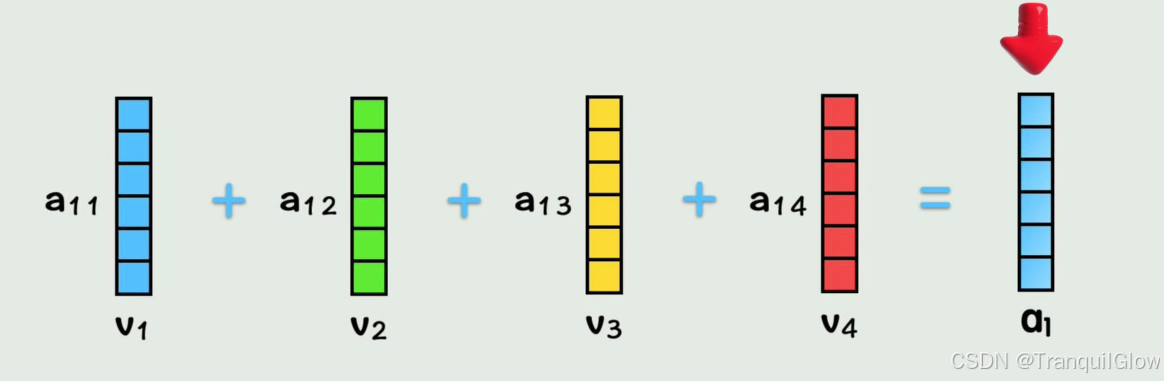

这里省略了归一化操做有的时候只计算一次,灵活性太低,所以我们可以通过计算得到多组q,k,v
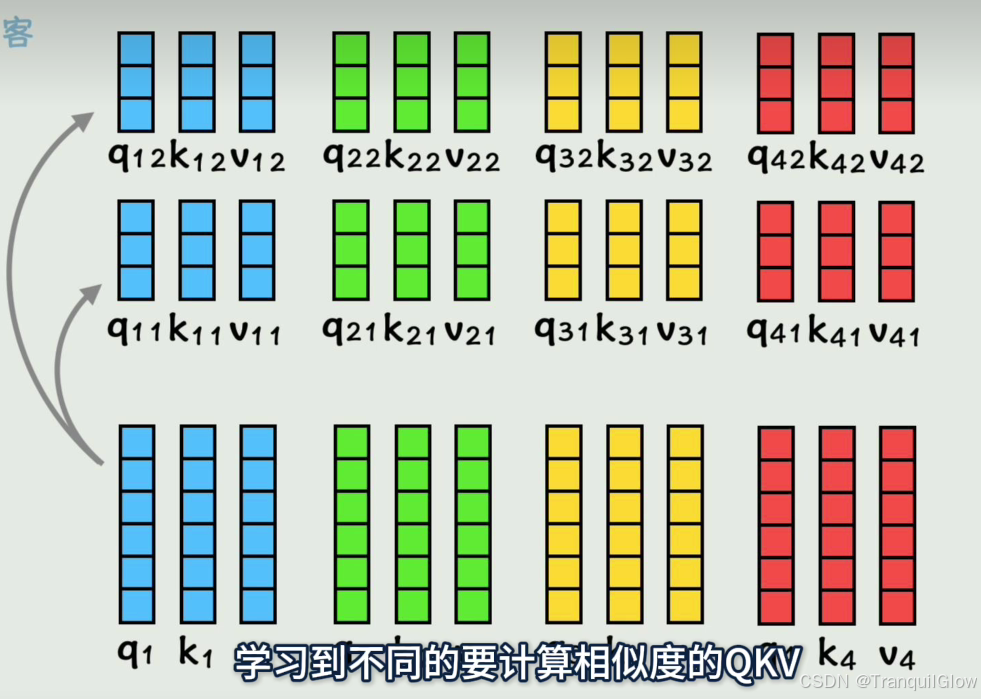
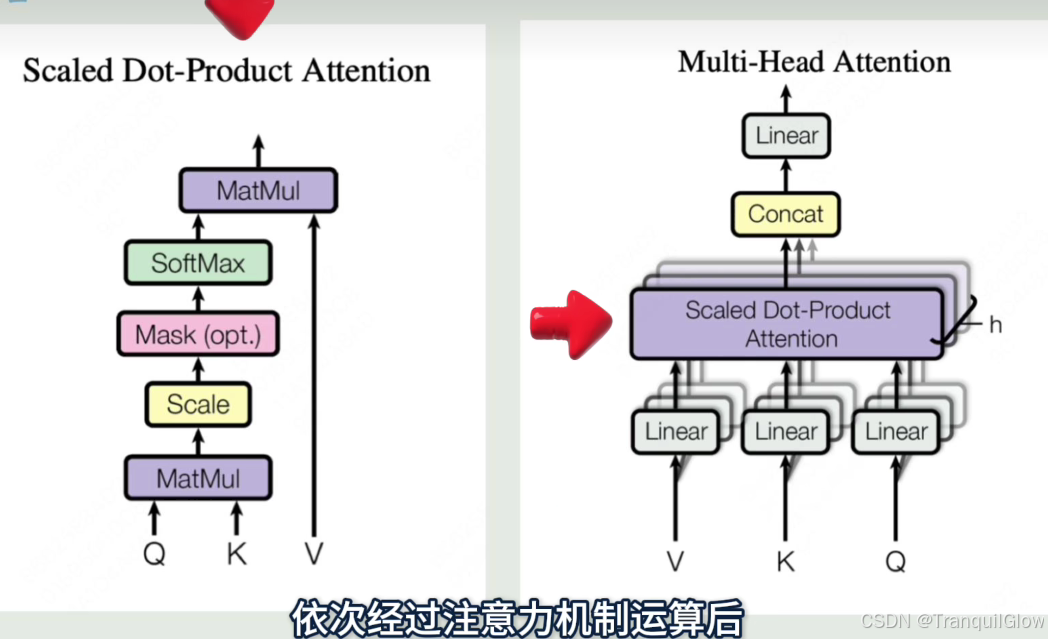
然后每一组q,k,v得到的a拼接起来,就是多头注意力
常见的大模型词
1. 函数万物皆函数,早期人们用符号主义的思想找到精确函数,试图解释一切原理,但遇到了瓶颈,
2. 联结主义,先啥都不管,弄一个非常复杂的函数,然后根据计算出的预测值与真实值的误差,不断调整里面的未知参数。
3. 联结主义中的这个函数叫做模型,
4. 模型里的参数叫做权重
5. 如果模型中的参数量特别大,就叫做大模型
6. 用于自然语言处理的大模型就叫做大语言模型,
7. 调整参数的过程就是模型的训练
8. 事先训练好一个基础模型的方式叫做预训练
9. 基于预训练的模型继续训练,让模型学会具体的任务的方式叫做微调参数
10.调整好后,根据函数的输入计算输出结果,这个过程叫做推理
11. 这些概念在大模型时代到来之后,逐渐火热了起来,当模型参数量足够大的时候,对话能力有了质的提升,产生了一定程度的推理能力,这种量变引起质变,而突然出现的之前没有的能力的现象叫做涌现
12. 大语言模型爆火的产品是2023年的chatgpt,它是一款用于聊天的产品,而它背后使用的代言模型是GPT是个系列,开发这个模型的公司是OpenAI产品模型公司,这也是一开始很多人搞混淆的概念,而由于这家公司推出的产品,一直保持不开放源代码,也就是闭源,所以也正式更名为close AI,开个玩笑,一个模型需要有训练它的代码,有了代码就可以训练出一组权重,有了权重就可以进行推理,也就是可以对外提供服务了,不开放源代码,也不开放权重,只对外提供服务的模型叫做闭源模型,如ChatGPT cloud germany y等开放模型,权重可以直接下载到自己电脑上,部署的模型叫做开源模型,但实际上大部分现在说的开源模型,只是开放了权重,而不开放训练代码和训练数据,所以准确说其实叫开放权重模型,比如最近爆火的deep seek以及划时代的la等,不但开放了模型结构和权重,还开放了训练代码的模型,可以叫完全开源模型,比如说miss f,当然了,有了模型权重,其实就可以下载到本地进行部署,并且使用了,很少有人需要重新训练它
13. 这个不依赖于他人的服务,而是把模型下载到本地进行使用的过程,叫做私有化部署,私有化部署依赖很多复杂的环境配置,就是需要装很多依赖的软件和工具包,而且需要性能较为强劲的GPU的支持
14. 对于仅仅想尝鲜的个人,专门为此去买一台电脑不太合适,因此就有了云桌面的概念
15. 你可以直接使用别人打包好的环境和软件,这个打包好的东西就叫做镜像
16. 大语言模型的本质就是个大函数,根据前面的一句话,持续不断地计算下一个词是什么,这种基于输入内容,自动生成新内容的人工智能系统叫做生成式AI,
17. 当然除了文本,也包含图像,声,音视频等等,这里的每一个分割成最小力度的词叫做token
18. 对话时所有给到大模型的信息叫做上下文,不同的模型有不同的上下文,长度限制越大,就越能记住前面的信息
19. 上下文从另一个角度理解,也可以叫提示词,prompt可以指导模型的回答流程和风格,但其实就是个上下文而已,早期出现很多提示词工程师和提示词教程,其实本质就是教你怎么跟大模型说话而已,现在AI的对话越来越贴近人的方式了,所以你和人沟通起来有啥毛病,那么跟AI沟通也有啥毛病,你真正缺的是怎么表达清楚自己的意思,而不是prompt技巧
20. 大模型就是个大函数,函数是死的,所以根据前面的词输出的下一个词是固定的,但是我们可以一定程度的调整模型,输出的随机性,让下一个词的生成,并不总是取前面概率最高的那个词,控制输出的随机性的参数叫做温度控制范围
21. 从概率最高的cake词中选择叫做top k,随机性太高,模型容易胡说,八道太低又会过于保守,也可能说错,这种在语言上说得通,但是在事实上狗屁不通,甚至虚假信息的现象叫做大模型的幻觉
22. 为了解决幻觉问题,大模型或者一些套壳产品提供了联网能力,其实呢就是在大模型回答问题前,先去互联网上查找一些相关信息,把这些信息和你的问题拼接在一起,共同先发给大模型,然后进行回答,相当于带着答案回答问题了,之前很多自媒体的震惊体,炸裂体,天塌体的文章说,大模型拥有联网能力是有了重大突破,人类就要完蛋了,那实际上呢就是这么个玩意儿,
23. 有些数据网络上可能查不到,或者企业的数据不方便公开地放在互联网上,希望大模型去这些私有的数据库中查找答案,这种方式叫做检索,增强生成RAG和联网的思路一样,也是先查资料再回答问题,只不过查询的内容不在互联网上,而是在有一个私有的数据库中,我们通常叫它知识库,
24. 为了让模型和知识库中的语义进行匹配,知识通常会以向量的形式存储在向量数据库中,把文字转换成磁向量的方式叫做词嵌入对比
25. 词向量之间的相似度,已在知识库中找到相关问题的答案的方式,叫做向量检索
26. 解决了大模型的幻觉问题后,AI就可以真正的介入生产和生活中了,在内容创作领域,传统的由专业机构如影视公司,媒体机构,权威专家等创作的内容叫做pgc,
27. 随着移动互联网时代的到来,和自媒体时代的到来,由普通用户,比如说我创作的内容叫做UGC,而在AI时代,由AI创作或辅助创作的内容叫做AIGC,
28. 比较正向的案例呢,就是内容公司通过AI,加快产出速度和提升内容质量,而比较反面的案例呢,就是很多人用AI洗稿并疯狂产出内容,污染互联网的内容生态
29. 这里有个比较容易混淆的词叫AGI,它的意思是人们对于人工智能最终形态的畅想,及通用人工智能大模型借鉴发展,不单单能处理文本内容,也能处理图片,声音视频等多种形式的内容
30. 这种处理多种模式内容的能力叫做多模态
31. 有的时候呢我们需要多次使用大模型的能力,比如第一步将口播稿分段,第二步给每个段落写成一个文生图的提示词,第三步生成一张合适的图片,这种把多个步骤编排成一个流程的能力,叫做工作流
32. 包括可以在页面上进行傻瓜操作,编排工作流的工具,比如扣子,以及用代码的方式编排工作流的框架,如long unchain,按照工作流封装大模型和一整套工具集,用于自动完成某一类复杂任务的程序,叫做一个智能体,多个智能体互相协作,完成更复杂的任务的程序叫做多智能体
33. chat gbt的插件系统,早期昙花一现的auto gbt,以及最近又昙花一现的minus都属于智能体,智能体,需要操作各种应用,比如打开浏览器上网,打开计算器进行算术,或者操作手机上的微信,发送一条信息等,实现托管,为了更方便操作外部数据源和工具,as throi公司于2024年底,为AI系统提供了一个标准化的接口,或者说协议叫做MC,给了AI一个操作外部世界的统一标准
34. 而谷歌于2025年4月推出的另一个协议,用于agent和agent之间的通信,叫做a to a协议,至此大模型的生态开始百花齐放,未来的想象空间是无限的,别看这么多工作流啊,智能体啊,MCP等概念兴起,但其实都是老一套工程方面的事情,大模型本身的能力已经发展的快到极限了,一方面呢模型大小到了极限,一个顶级大语言,模型的训练成本已经超过1亿美元了,另一方面模型的能力也快到达了极限,前十名模型能力的差距,已经从两年前的12%,缩小到了25年年初的5.4%,前两名更是从4.9%,缩小到了0.7%,模型之间已经快拉不出差距了
35. 正所谓边际收益递减,所以呢就开始卷其他方向寻找出路,比如让模型更小,以便减少成本和方便个人使用的模型压缩方法,包括把模型中的浮点数用更低精度表示,以减少显存和计算的量化,用参数量较大的大模型,指导参数量较小的小模型的蒸馏,删除模型中不重要的神经元,让模型更稀疏,以提高速度的减脂,用更低成本改善微调方式的方法,如laura klaura adapter等,从推理能力方向增强模型能力的方式,如思维链,通过人类反馈的强化学习,让模型说的话更合人的心意的方法叫RLHF
36. 当然啥方向都卷不动的时候,铁还可以封装现有的大模型接口,并对外提供服务,通俗的说法呢就是套壳或者提供AI工具,AI服务,AI课程,AI社区等,帮助别人开发和使用AI能力的周边产品,这种在AI淘金热里帮助别人淘金,来赚取金币的方式叫做卖铲子,可别看不上卖铲子的,这可是要对AI各领域的产品和生态,都了如指掌才行,和文字相关的就是自然语言处理,有名的包括刚刚说的chat gbt以及cloud Gemini,Deep sick,豆包腾讯元宝等
37. 和图片相关的是计算机视觉,包括很多AI绘画的应用,比如闭源的mid journey,开源的stable diffusion,绘画工作流软件CONFEUI等,和语音相关的,包括文字转语音的TTS和,语音转文字的AS2,和视频相关的包括SORA,可灵及梦等AI视频生成应用,以及各种数字人应用等,除了帮助普通用户外,你还可以帮助开发者更好地使用AI,包括像英伟达一样提供好的显卡,也就是GPU以及配套的开发框架KA,或者提供专门针对人工智能的处理器,比如专门用于大规模神经网络训练与推理的,TPU和专门用于终端设备推理的AI加速芯片,NPU等软件方面,你可以提供适合AI的编程语言
38. Python提供针对AI编程的库,Pytorch tensorflow,建设AI开源平台和社区,Hugging face,方便开发者本地运行大模型的工具,
39. 欧拉马,提升大语言模型推理速度的推理引擎,VLMAI编程助手,包括单独以软件形式存在的cursor,或者以插件形式存在的github copilot等等等等,太多可以做的事情了,
40. 从最底层的线性代数,微积分,概率论,最优化等数学知识,到深度学习中,用神经网络表示函数,用损失函数最小化为目标,通过反向传播训练参数,再到后面的经典神经网络结构,MLP用于图像数据处理的卷积神经网络,CNN用于序列数据处理的循环神经网络,Rn,以及引爆整个大模型时代的attention机制和,基于attention机制发明的transformer架构,他们共同撑起了现代AI技术的大厦,恭喜你,坚持到了现在,你已经超过了99%的人了,