介绍
官网:https://docs.langchain4j.dev/

LangChain4j 的目标是简化与 Java 应用程序 集成大模型。
特性:
- 统一 API: LLM提供程序(如 OpenAI 或 阿里百炼)和嵌入(向量)存储(如 redis 或 ES) 使用专有 API。LangChain4j 提供了一个统一的 API,以避免为每个 API 学习和实现特定的 API。 要试验不同的LLMs存储或嵌入的存储,您可以在它们之间轻松切换,而无需重新编写代码。 LangChain4j 目前支持 15+ 热门LLM 和 20+ 嵌入模型。
- jdk版本:v0.35.0可以在jdk1.8, v0.36.0+迁移到jdk17 , 所以最新版本必须jdk17+
langchain4j vs springAI
维度 |
Spring AI |
LangChain4j |
技术栈绑定 |
强依赖 Spring 生态 |
无框架依赖,可独立使用 |
适用场景 |
SpringBoot应用快速接入单模型 |
多模型(动态模型)平台 |
初识LangChain4j(纯java)
接下来,让我们与LangChain4j初识一下,新建一个Maven工程,然后添加以下依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xs</groupId>
<artifactId>langchain4j-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>17</java.version>
<langchain4j.version>1.4.0</langchain4j.version>
</properties>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>${langchain4j.version}</version>
</dependency>
</dependencies>
</project>引入了langchain4j的核心依赖、langchain4j集成OpenAi各个模型的依赖。和OpenAi的第一次对话
@Test
public void test1() {
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl("http://langchain4j.dev/demo/openai/v1")
.apiKey("demo")
.modelName("gpt-4o-mini")
.build();
String answer = model.chat("Say '圆形的面积怎么计算?'");
System.out.println(answer);
}你会发现, LangChain4j 对于初次接入大模型的开发者来说十分友好,不需要指定模型,不需要指定apikey, 即可对接大模型进行对话,这是怎么做到的呢?
其实我们对ApiKey为"demo" , 底层会做这些事情:
public OpenAiChatModel(String baseUrl, String apiKey, String organizationId, String modelName, Double temperature, Double topP, List<String> stop, Integer maxTokens, Double presencePenalty, Double frequencyPenalty, Map<String, Integer> logitBias, String responseFormat, Integer seed, String user, Duration timeout, Integer maxRetries, Proxy proxy, Boolean logRequests, Boolean logResponses, Tokenizer tokenizer) {
baseUrl = (String)Utils.getOrDefault(baseUrl, "https://api.openai.com/v1");
if ("demo".equals(apiKey)) {
baseUrl = "http://langchain4j.dev/demo/openai/v1";
}
//其他代码
}在底层在构造OpenAiChatModel时,会判断传入的ApiKey是否等于"demo",如果等于会将OpenAi的原始API地址"https://api.openai.com/v1"改为"http://langchain4j.dev/demo/openai/v1",这个地址是langchain4j专门为我们准备的一个体验地址,实际上这个地址相当于是"https://api.openai.com/v1"的代理,我们请求代理时,代理会去调用真正的OpenAi接口,只不过代理会将自己的ApiKey传过去,从而拿到结果返回给我们。
所以,真正开发时,需要大家设置自己的apiKey或baseUrl,可以这么设置:
ChatLanguageModel model = OpenAiChatModel.builder()
.baseUrl("http://langchain4j.dev/demo/openai/v1")
.apiKey("demo")
.build();接入deepseek
@Test
public void test3() {
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl("https://api.deepseek.com")
.apiKey("sk-6c2bdbc74")
.modelName("deepseek-chat")
.build();
String answer = model.chat("Say '圆形的面积怎么计算?'");
System.out.println(answer);
}文生图WanxImageModel
@Test
public void test() {
WanxImageModel wanxImageModel = WanxImageModel.builder()
.modelName("wanx2.1-t2i-plus")
.apiKey(System.getenv("ALI_AI_KEY"))
.build();
Response<Image> response = wanxImageModel.generate("美女");
System.out.println(response.content().url());
}文生语音
package com.xs.langchain4j_demos;
import com.alibaba.dashscope.audio.ttsv2.SpeechSynthesisParam;
import com.alibaba.dashscope.audio.ttsv2.SpeechSynthesizer;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
public class AudioTest {
private static String model = "cosyvoice-v1";
private static String voice = "longxiaochun";
public static void streamAuidoDataToSpeaker() {
SpeechSynthesisParam param =
SpeechSynthesisParam.builder()
// 若没有将API Key配置到环境变量中,需将下面这行代码注释放开,并将your-api-key替换为自己的API Key
.apiKey(System.getenv("ALI_AI_KEY"))
.model(model)
.voice(voice)
.build();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(param, null);
ByteBuffer audio = synthesizer.call("大家好我是徐庶?");
File file = new File("output.mp3");
try (FileOutputStream fos = new FileOutputStream(file)) {
fos.write(audio.array());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) {
streamAuidoDataToSpeaker();
System.exit(0);
}
}整合SpringBoot
先引入SpringBoot:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.4.9</version>
<relativePath/>
</parent>接入百炼官网:
DashScope (Qwen) | LangChain4j
<!--百炼-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>Controller:
package com.xs.langchain4j_demos.controller;
import dev.langchain4j.model.chat.ChatLanguageModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/ai")
public class AiController {
@Autowired
ChatLanguageModel qwenChatModel;
@RequestMapping("/chat")
public String test(@RequestParam(defaultValue="你是谁") String message) {
String chat = qwenChatModel.chat(message);
return chat;
}
}
配置通义千问-Max模型:
langchain4j.community.dashscope.chatModel.apiKey=${ALI_AI_KEY}
langchain4j.community.dashscope.chatModel.modelName=qwen-plus
访问http://localhost:8080/ai/chat:

配置deepseek模型
langchain4j.community.dashscope.chatModel.apiKey=${ALI_AI_KEY}
langchain4j.community.dashscope.chatModel.modelName=deepseek-r1
访问http://localhost:8080/ai/chat:

接入Ollama
关于Ollama的本地部署: DeepSeek本地部署教程
<!--Ollama-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama-spring-boot-starter</artifactId>
<version>${langchain4j.version}</version>
</dependency>Controller:
package com.xs.langchain4j_demos.controller;
import dev.langchain4j.model.chat.ChatLanguageModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/ai")
public class AiController {
@Autowired
ChatLanguageModel ollamaChatModel;
@RequestMapping("/chat_ollama")
public String chatOllama(@RequestParam(defaultValue="你是谁") String message) {
String chat = ollamaChatModel.chat(message);
return chat;
}
}
配置通Deepseek模型:
langchain4j.community.dashscope.chatModel.apiKey=${ALI_AI_KEY}
langchain4j.community.dashscope.chatModel.modelName=qwen-plus
访问http://localhost:8080/ai/chat:

流式输出
因为langchain4j不是spring家族, 所以我们在wen应用中需要引入webflux
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>通过Flux进行流式响应
@RestController
@RequestMapping("/ai_other")
public class OtherAIController {
@Autowired
StreamingChatLanguageModel qwenStreamingChatModel;
@RequestMapping(value = "/stream_chat",produces ="text/stream;charset=UTF-8")
public Flux<String> test(@RequestParam(defaultValue="你是谁") String message) {
return Flux.create(sink -> {
qwenStreamingChatModel.chat(message, new StreamingChatResponseHandler() {
@Override
public void onPartialResponse(String partialResponse) {
sink.next(partialResponse); // 逐次返回部分响应
}
@Override
public void onCompleteResponse(ChatResponse completeResponse) {
sink.complete(); // 完成整个响应流
}
@Override
public void onError(Throwable error) {
sink.error(error); // 异常处理
}
});
});
}
}到这里你会发现, langchain4j毕竟不是spring家族, 和spring生态一起用真蹩脚。 还是springai舒服
记忆对话(多轮对话)
原生方式
大模型并不会把我们每次的对话存在服务端, 所以他记不住我们说的话
/**
* 测试多轮对话——错误用法
*/
@Test
void test03_bad() {
ChatLanguageModel model = OpenAiChatModel
.builder()
.apiKey("demo")
.modelName("gpt-4o-mini")
.build();
System.out.println(model.chat("你好,我是徐庶老师"));
System.out.println("----");
System.out.println(model.chat("我叫什么"));
}响应:

所以每次对话都需要将之前的对话记录,都发给大模型, 这样才能知道我们之前说了什么:
/**
* 测试多轮对话——正确用法
*/
@Test
void test03_good() {
ChatLanguageModel model = OpenAiChatModel
.builder()
.apiKey("demo")
.modelName("gpt-4o-mini")
.build();
UserMessage userMessage1 = UserMessage.userMessage("你好,我是徐庶");
ChatResponse response1 = model.chat(userMessage1);
AiMessage aiMessage1 = response1.aiMessage(); // 大模型的第一次响应
System.out.println(aiMessage1.text());
System.out.println("----");
// 下面一行代码是重点
ChatResponse response2 = model.chat(userMessage1, aiMessage1, UserMessage.userMessage("我叫什么"));
AiMessage aiMessage2 = response2.aiMessage(); // 大模型的第二次响应
System.out.println(aiMessage2.text());
}但是如果要我们每次把之前的记录自己去维护, 未免太麻烦, 所以提供了ChatMemory
但是他这个ChatMemory没有SpringAi好用、易用, 十分麻烦! 所以说谁在跟我说Langchain4j比SpringAi好我跟谁急!。
通过ChatMemory
在SpringBoot中他要这么用:
@Configuration
public class AiConfig {
public interface Assistant {
String chat(String message);
// 流式响应
TokenStream stream(String message);
}
@Bean
public Assistant assistant(ChatLanguageModel qwenChatModel,
StreamingChatLanguageModel qwenStreamingChatModel) {
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(qwenChatModel)
.streamingChatLanguageModel(qwenStreamingChatModel)
.chatMemory(chatMemory)
.build();
return assistant;
}
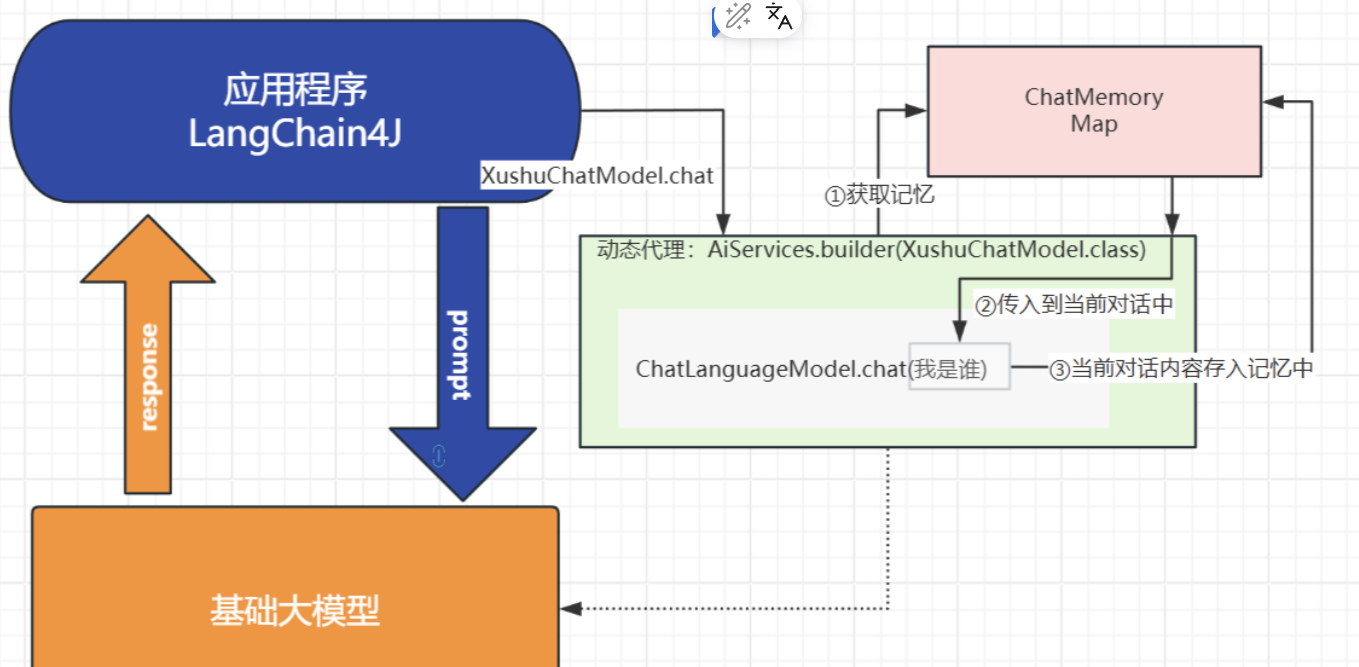
}原理:
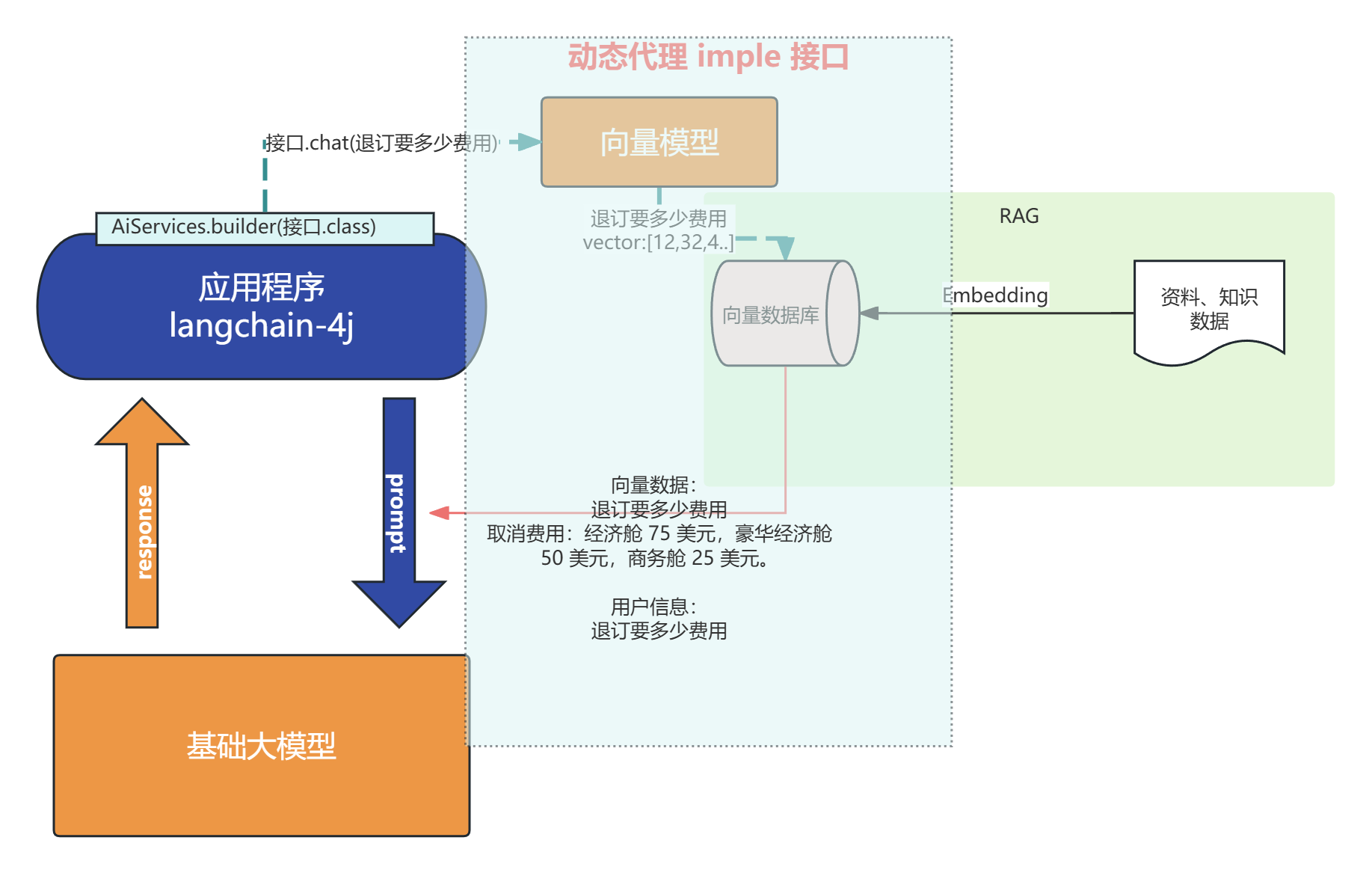
0. 通过AiService创建的代理对象(
![]()
)调用chat方法
![]()
- 代理对象会去ChatMemory中获取之前的对话记录(获取记忆)
- 将获取到的对话记录合并到当前对话中(此时大模型根据之前的聊天记录肯定就拥有了“记忆”)
- 将当前的对话内容存入ChatMemory(保存记忆)
Controller:
@RestController
@RequestMapping("/ai_other")
public class OtherAIController {
@Autowired
AiConfig.Assistant assistant;
@RequestMapping(value = "/memory_chat")
public String memoryChat(@RequestParam(defaultValue="我叫徐庶") String message) {
return assistant.chat(message);
}
}
@RequestMapping(value = "/memory_stream_chat",produces ="text/stream;charset=UTF-8")
public Flux<String> memoryStreamChat(@RequestParam(defaultValue="我是谁") String message, HttpServletResponse response) {
TokenStream stream = assistant.stream(message);
return Flux.create(sink -> {
stream.onPartialResponse(s -> sink.next(s))
.onCompleteResponse(c -> sink.complete())
.onError(sink::error)
.start();
});
}这封装得也太不优雅了! 看看人家Spring-AI 封装得那叫一个优雅, 行吧不吐槽了,我们继续往下面看吧。
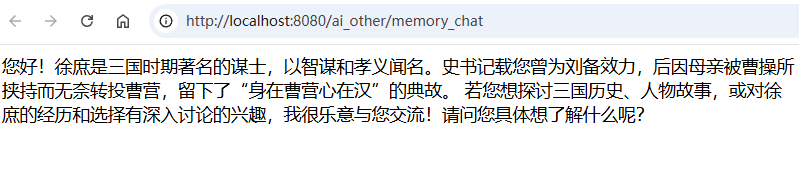
我们通过2种接口体验记忆对话, (当然也可以通过同一个接口)
访问:/memory_chat
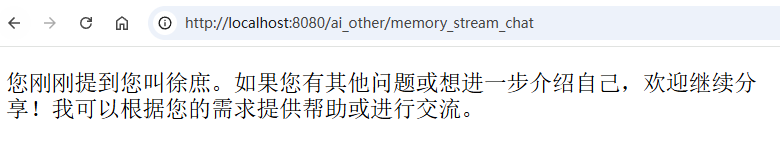
访问:/memory_stream_chat
记忆分离
现在我们再来想另一种情况: 如果不同的用户或者不同的对话肯定不能用同一个记忆,要不然对话肯定会混淆,此时就需要进行区分:
可以通过memoryId进行区分,
public interface AssistantUnique {
String chat(@MemoryId int memoryId, @UserMessage String userMessage);
// 流式响应
TokenStream stream(@MemoryId int memoryId, @UserMessage String userMessage);
}
@Bean
public AssistantUnique assistantUnique(ChatLanguageModel qwenChatModel,
StreamingChatLanguageModel qwenStreamingChatModel) {
AssistantUnique assistant = AiServices.builder(AssistantUnique.class)
.chatLanguageModel(qwenChatModel)
.streamingChatLanguageModel(qwenStreamingChatModel)
.chatMemoryProvider(memoryId ->
MessageWindowChatMemory.builder().maxMessages(10)
.id(memoryId).build()
)
.build();
return assistant;
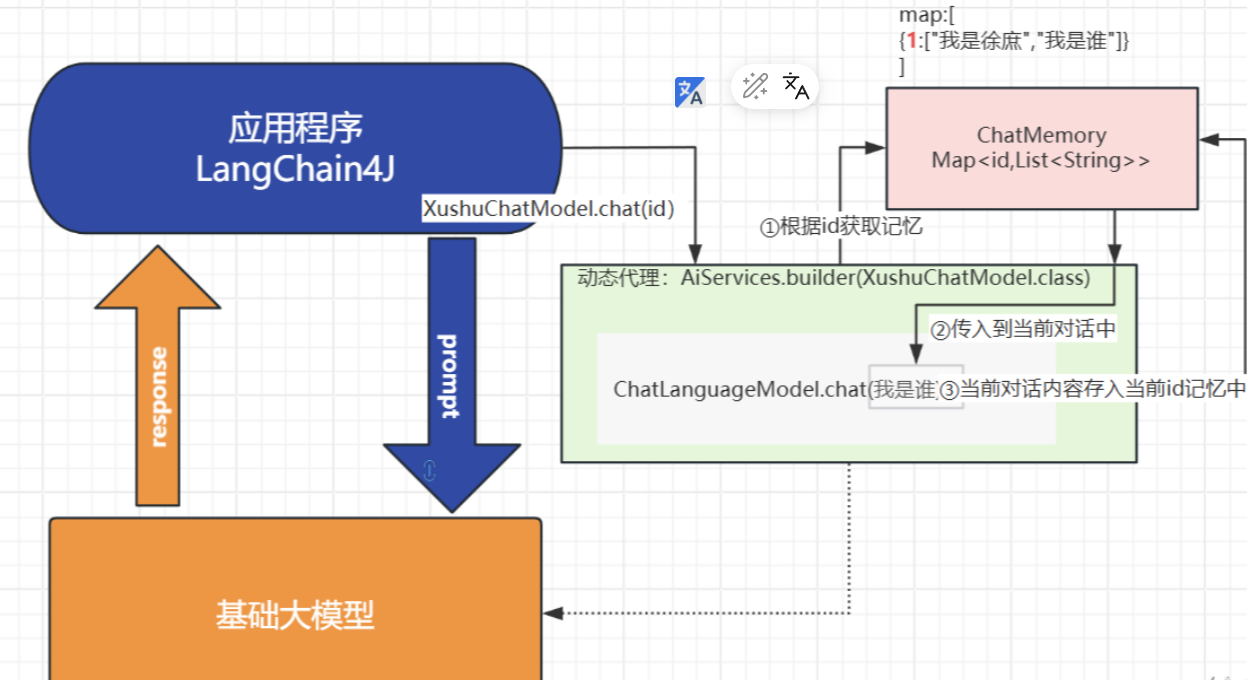
}原理:
0. 通过AiService创建的代理对象(
![]()
)调用chat方法
![]()
传入id
- 代理对象会去ChatMemory中根据id获取之前的对话记录(获取记忆)
- 将获取到的对话记录合并到当前对话中(此时大模型根据之前的聊天记录肯定就拥有了“记忆”)
- 将当前的对话内容根据id存入ChatMemory(保存记忆)
 memoryId可以设置为用户Id, 或者对话Id 进行区分即可:
memoryId可以设置为用户Id, 或者对话Id 进行区分即可:
@Autowired
AiConfig.AssistantUnique assistantUnique;
@RequestMapping(value = "/memoryId_chat")
public String memoryChat(@RequestParam(defaultValue="我是谁") String message, Integer userId) {
return assistantUnique.chat(userId,message);
}
看效果:
userId=1,我叫徐庶

userId=2, 我叫什么
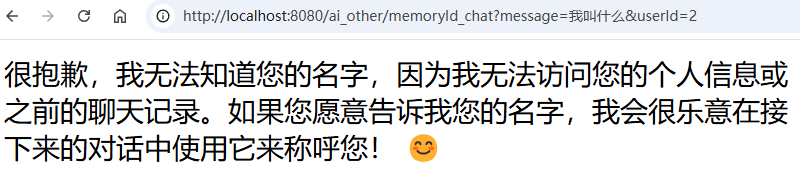
userId=1 ,我叫什么

持久化对话
OK, 完成! 如果要对记忆的数据进行持久化呢? 因为现在的数据其实是存在内存中, 重启就丢了
可以配置一个ChatMemoryStore
默认是InMemoryChatMemoryStore——通过一个map进行存储,

所以如果需要持久化到第三方存储, 可以重新配置ChatMemoryStore :
自定义ChatMemoryStore实现类: 假设持久化到数据库 , 具体代码我不演示了
public class PersistentChatMemoryStore implements ChatMemoryStore {
private final Map<Integer, List<ChatMessage>> map =new HashMap<>();
@Override
public List<ChatMessage> getMessages(Object memoryId) {
// todo 根据memoryId从数据库获取
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
// todo 根据memoryId修改、新增记录
}
@Override
public void deleteMessages(Object memoryId) {
// todo 根据memoryId删除
}
}- 然后配置ChatMemoryStore
@Bean
public AssistantUnique assistantUniqueStore(ChatLanguageModel qwenChatModel,
StreamingChatLanguageModel qwenStreamingChatModel) {
PersistentChatMemoryStore store = new PersistentChatMemoryStore();
ChatMemoryProvider chatMemoryProvider = memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.chatMemoryStore(store)
.build();
AssistantUnique assistant = AiServices.builder(AssistantUnique.class)
.chatLanguageModel(qwenChatModel)
.streamingChatLanguageModel(qwenStreamingChatModel)
.chatMemoryProvider(memoryId ->
MessageWindowChatMemory.builder().maxMessages(10)
.id(memoryId).build()
)
.chatMemoryProvider(chatMemoryProvider)
.build();
return assistant;Function-call(Tools)
对于基础大模型来说, 他只具备通用信息,他的参数都是拿公网进行训练,并且有一定的时间延迟, 无法得知一些具体业务数据和实时数据, 这些数据往往被各软件系统存储在自己数据库中:
比如我问大模型:“中国有多少个叫徐庶的” 他肯定不知道, 我们就需要去调用政务系统的接口。
比如我现在开发一个智能票务助手, 我现在跟AI说需要退票, AI怎么做到呢? 就需要让AI调用我们自己系统的退票业务方法,进行操作数据库。
那这些都可以通过function-call进行完成,更多的用于实现类似智能客服场景,因为客服需要帮用户解决业务问题(就需要调用业务方法)。
function-call的流程:
比如: 我现在需要当对话中用户问的是“长沙有多少个叫什么名字”的对话, 我需要去我程序中获取
- 问大模型 长沙有多少个叫徐庶的
- 大模型在识别到你的问题是: “长沙有多少个叫什么名字”
- 大模型提取“徐庶”
- 调用
changshaNameCount方法 - 通过返回的结果再结合上下文再次请求大模型
- 响应“长沙有xx个叫徐庶的”
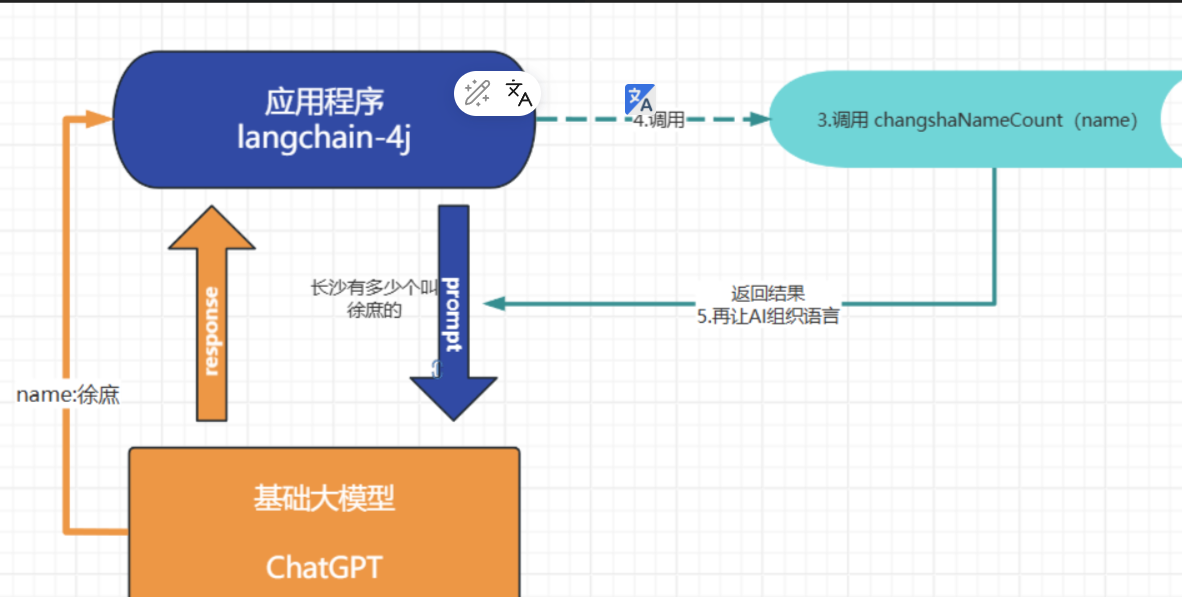
实现:
- 加入回调方法:
@Service
public class ToolsService {
@Tool("长沙有多少个名字的")
public Integer changshaNameCount(
@P("姓名")
String name){
System.out.println(name);
return 10;
}
}
- ToolsService配置为了一个bean
- @Tool 用于告诉AI什么对话调用这个方法
- @P("姓名") 用于告诉AI ,调用方法的时候需要提取对话中的什么信息, 这里提取的是姓名
- 结合通过AiService配置tools , 这里用的是前面记忆对话时配置的Assistant
public interface Assistant {
String chat(String message);
// 流式响应
TokenStream stream(String message);
}
@Bean
public Assistant assistant(ChatLanguageModel qwenChatModel,
StreamingChatLanguageModel qwenStreamingChatModel,
ToolsService toolsService) {
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(qwenChatModel)
.streamingChatLanguageModel(qwenStreamingChatModel)
.tools(toolsService)
.chatMemory(chatMemory)
.build();
return assistant;
}所以, 你如果需要加更多的tool. 只需要在TollsService中加, 比如:
这个langchan4j封装得倒是挺易用的👍
@Tool("长沙的天气")
public String changshaWeather( ){
System.out.println("长沙的天气");
return "下雪";
}
预设角色(系统消息SystemMessage):
基础大模型是没有目的性的, 你聊什么给什么, 但是如果我们开发的事一个智能票务助手, 我需要他以一个票务助手的角色跟我对话, 并且在我跟他说"退票"的时候, 让大模型一定要告诉我“车次”和"姓名" ,这样我才能去调用业务方法(假设有一个业务方法,需要根据车子和姓名才能查询具体车票),进行退票。
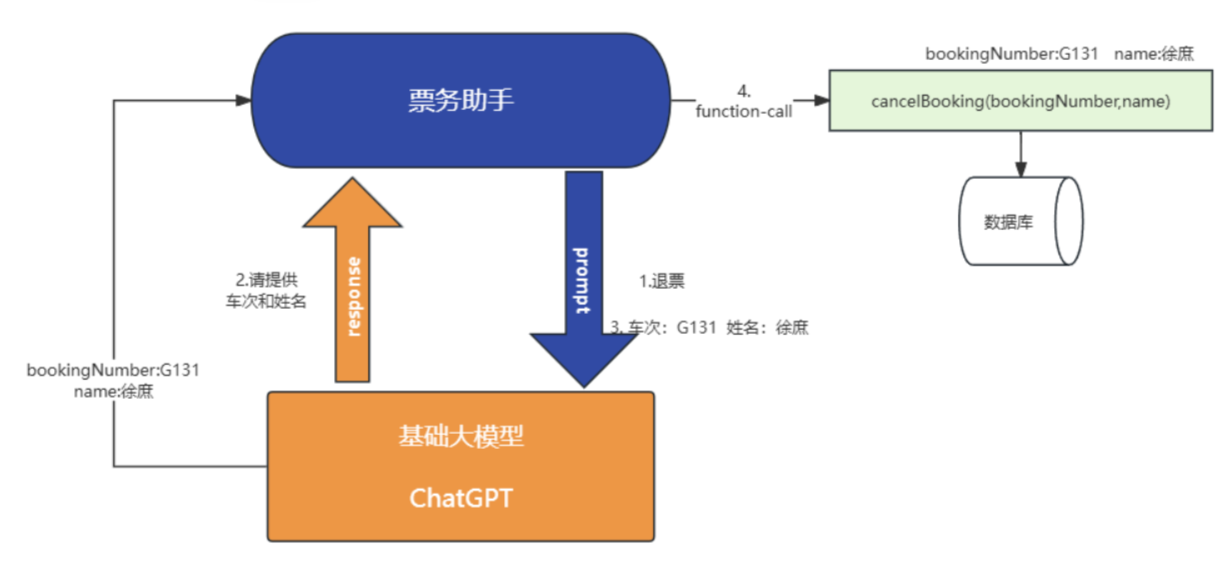
在langchain4j中实现也非常简单 @SystemMessage 系统消息, 一般做一些预设角色的提示词,设置大模型的基本职责可以通过{{current_date}} 传入参数, 因为预设词中的文本可能需要实时变化@V("current_date"), 通过@V传入{{}}中的参数一旦参数不止一个, 就需要通过@UserMessage设置用户信息
public interface Assistant {
String chat(String message);
// 流式响应
TokenStream stream(String message);
@SystemMessage("""
您是“Tuling”航空公司的客户聊天支持代理。请以友好、乐于助人且愉快的方式来回复。
您正在通过在线聊天系统与客户互动。
在提供有关预订或取消预订的信息之前,您必须始终从用户处获取以下信息:预订号、客户姓名。
请讲中文。
今天的日期是 {{current_date}}.
""")
TokenStream stream(@UserMessage String message,@V("current_date") String currentDate);
}
@RequestMapping(value = "/memory_stream_chat",produces ="text/stream;charset=UTF-8")
public Flux<String> memoryStreamChat(@RequestParam(defaultValue="我是谁") String message, HttpServletResponse response) {
TokenStream stream = assistant.stream(message, LocalDate.now().toString());
return Flux.create(sink -> {
stream.onPartialResponse(s -> sink.next(s))
.onCompleteResponse(c -> sink.complete())
.onError(sink::error)
.start();
});
}另外:假设大模型不支持系统消息(一般都支持),可以用@UserMessage代替@SystemMessage
interface Friend {
@UserMessage("你是一个航空智能助手,你需要帮助用户进行服务: {{it}}")
String chat(String userMessage);
}RAG:
检索增强生成(Retrieval-augmented Generation)
对于基础大模型来说, 他只具备通用信息,他的参数都是拿公网进行训练,并且有一定的时间延迟, 无法得知一些具体业务数据和实时数据, 这些数据往往在各种文件中(比如txt、word、html、数据库...)
虽然function-call、SystemMessage可以用来解决一部分问题
但是它只能少量, 如果你要提供大量的业务领域信息, 就需要给他外接一个知识库:
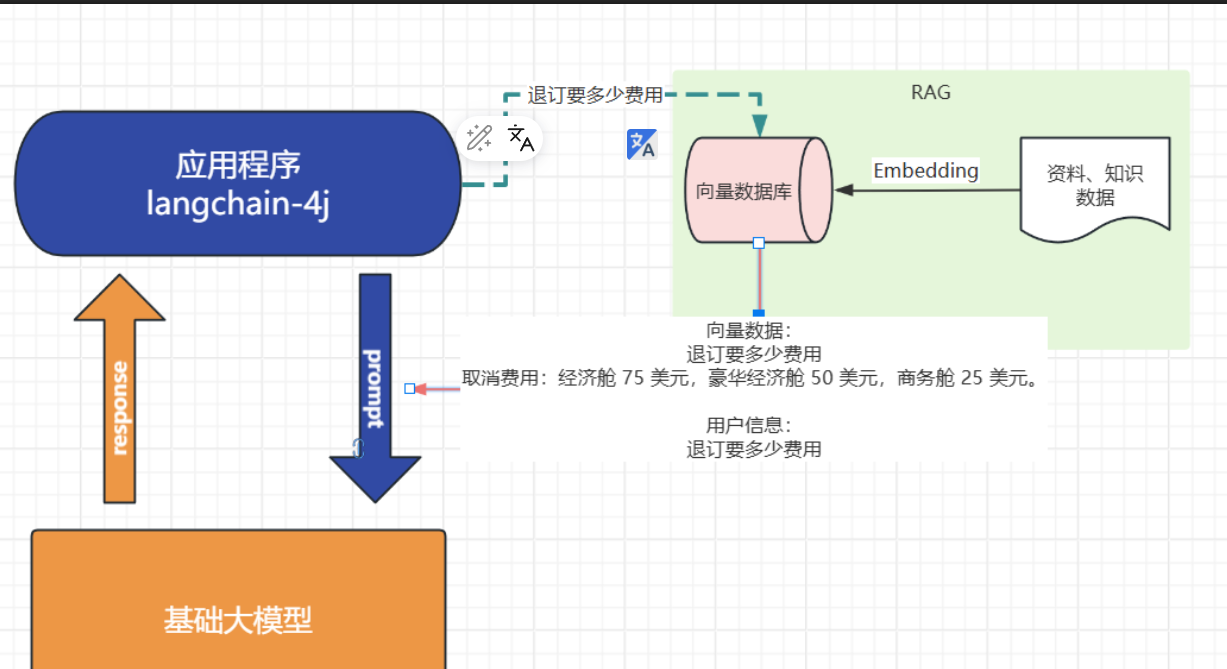
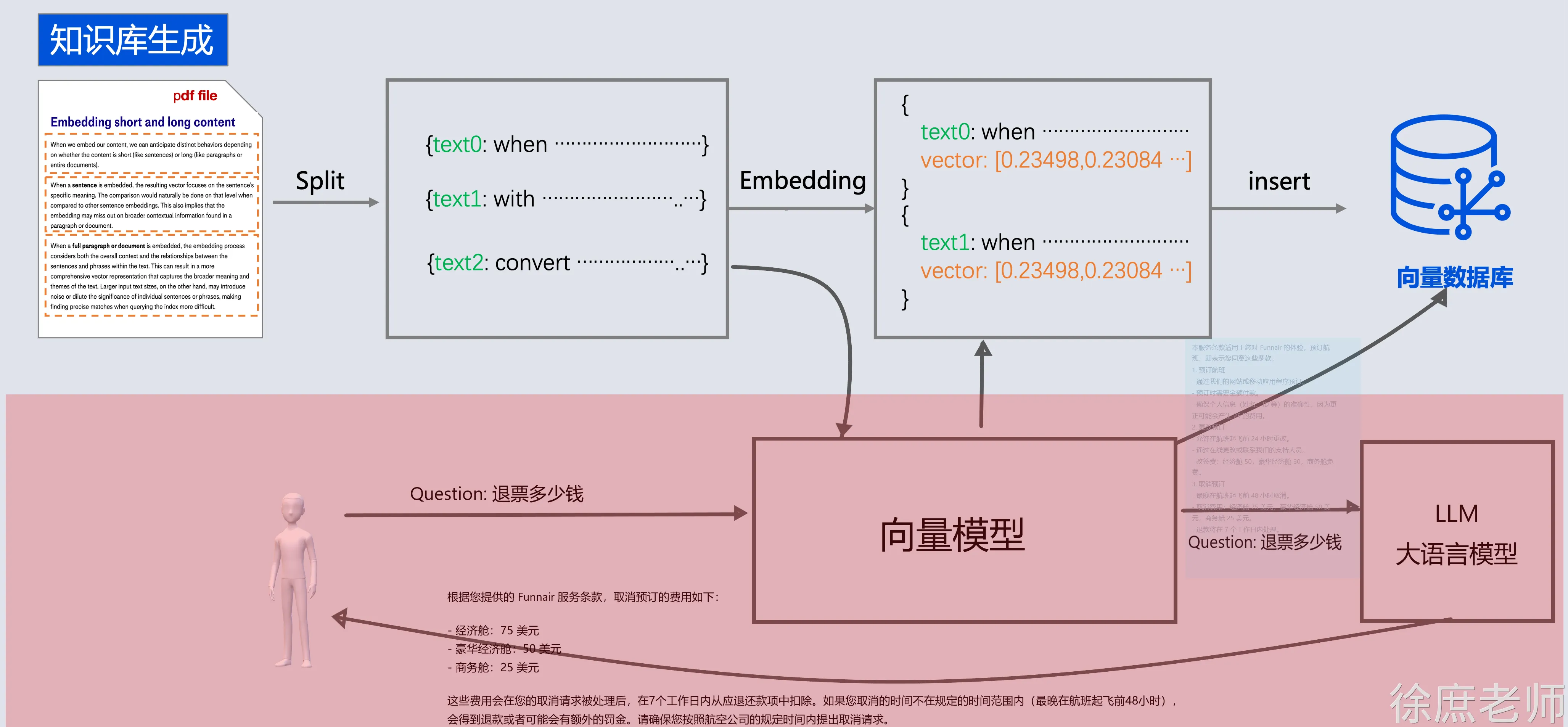
比如
- 我问他退订要多少费用
- 这些资料可能都由产品或者需求编写在了文档中: 📎terms-of-service.txt
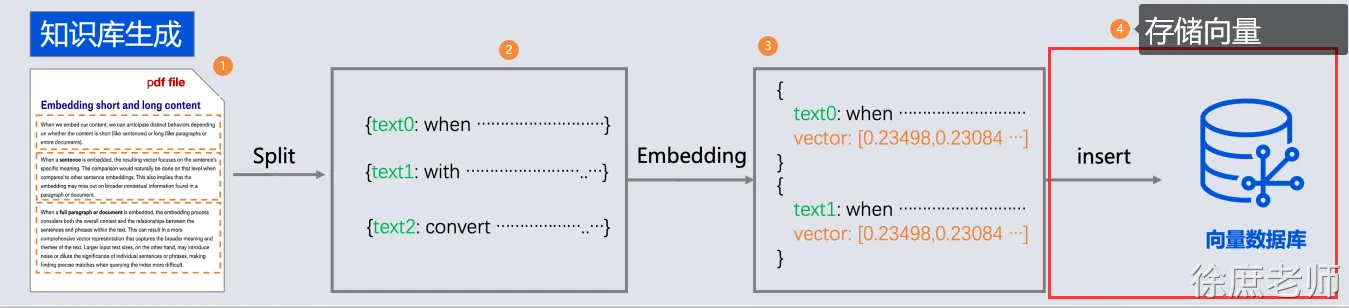
-
- 所以需要现在需求信息存到向量数据库(这个过程叫Embedding, 涉及到文档读取、分词、向量化存入)
- 去向量数据库中查询“退订费用相关信息”
- 将查询到的数据和对话信息再请求大模型
- 此时会响应退订需要多少费用
概念
向量:
向量通常用来做相似性搜索,比如语义的一维向量,可以表示词语或短语的语义相似性。例如,“你好”、“hello”和“见到你很高兴”可以通过一维向量来表示它们的语义接近程度。

然而,对于更复杂的对象,比如小狗,无法仅通过一个维度来进行相似性搜索。这时,我们需要提取多个特征,如颜色、大小、品种等,将每个特征表示为向量的一个维度,从而形成一个多维向量。例如,一只棕色的小型泰迪犬可以表示为一个多维向量 [棕色, 小型, 泰迪犬]。
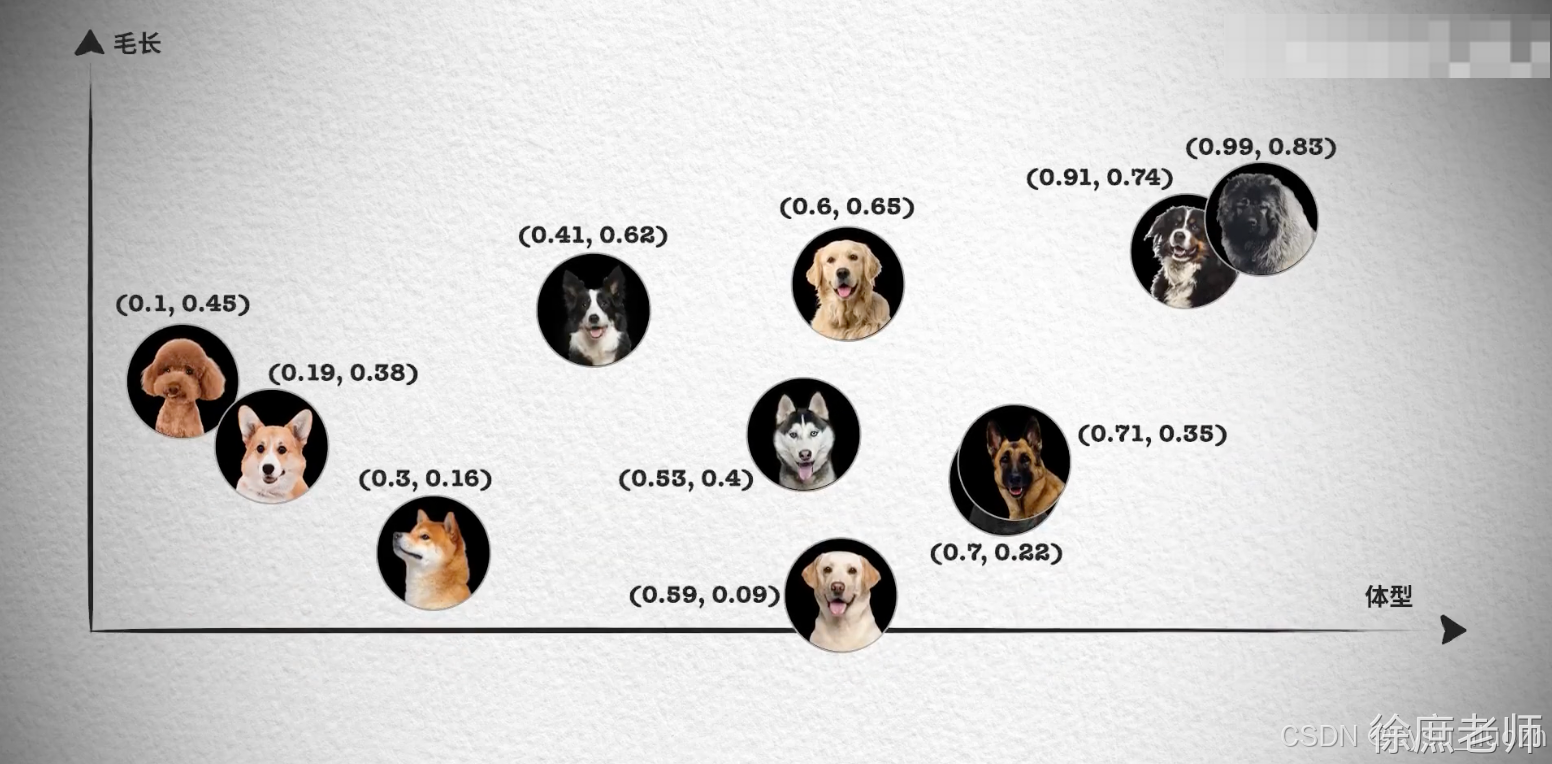
如果需要检索见过更加精准, 我们肯定还需要更多维度的向量, 组成更多维度的空间,在多维向量空间中,相似性检索变得更加复杂。我们需要使用一些算法,如余弦相似度或欧几里得距离,来计算向量之间的相似性。向量数据库会帮我实现。
文本向量化
LangChain4j中来调用向量模型来对一句话进行向量化体验:
package com.xs;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.model.openai.OpenAiEmbeddingModel;
import dev.langchain4j.model.output.Response;
/**
* wx:程序员徐庶
*/
public class _05_Vector {
public static void main(String[] args) {
QwenEmbeddingModel embeddingModel= QwenEmbeddingModel.builder()
.apiKey(System.getenv("ALI_AI_KEY"))
.build();
Response<Embedding> embed = embeddingModel.embed("你好,我叫徐庶");
System.out.println(embed.content().toString());
System.out.println(embed.content().vector().length);
}
}
代码执行结果为:
mbedding { vector = [0.014577684, 0.007282357, 0.030037291, -0.02028425, ...
1536从结果可以知道"你好,我叫徐庶"这句话经过OpenAiEmbeddingModel向量化之后得到的一个长度为1536的float数组。注意,1536是固定的,不会随着句子长度而变化。
那么,我们通过这种向量模型得到一句话对应的向量有什么作用呢?非常有用,因为我们可以基于向量来判断两句话之间的相似度,举个例子:
查询跟秋田犬类似的狗, 在向量数据库中根据每个狗的特点进行多维向量, 你会发现秋田犬的向量数值和柴犬的向量数值最接近, 就可以查到类似的狗。 (当然我这里只是举例,让你对向量数据库有一个印象)
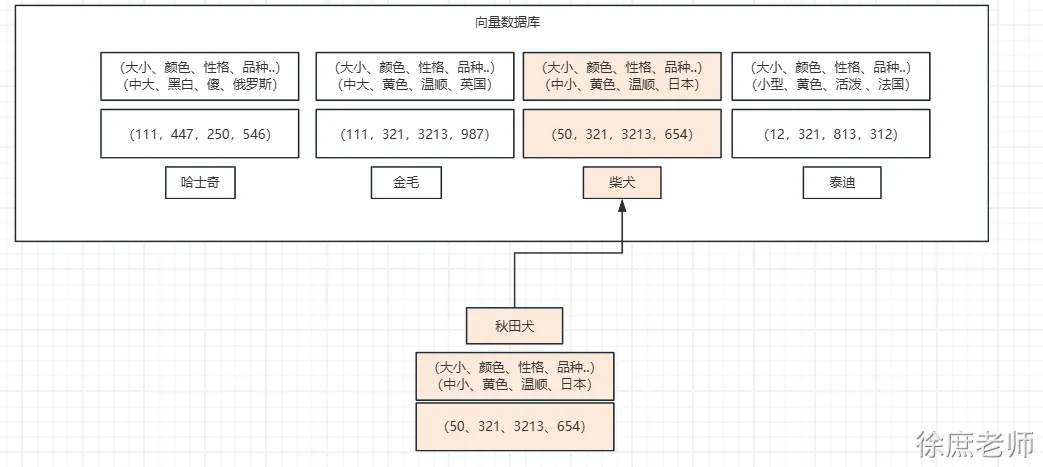
向量数据库
对于向量模型生成出来的向量,我们可以持久化到向量数据库,并且能利用向量数据库来计算两个向量之间的相似度,或者根据一个向量查找跟这个向量最相似的向量。
在LangChain4j中,EmbeddingStore表示向量数据库,它有支持20+ 嵌入模型:
Embedding Store |
Storing Metadata |
Filtering by Metadata |
Removing Embeddings |
✅ |
✅ |
✅ |
|
✅ |
|||
✅ |
✅ |
✅ |
|
✅ |
|||
✅ |
|||
✅ |
|||
✅ |
✅ |
✅ |
|
✅ |
✅ |
✅ |
|
✅ |
✅ |
✅ |
|
✅ |
✅ |
||
✅ |
✅ |
✅ |
|
✅ |
✅ |
✅ |
|
✅ |
|||
✅ |
✅ |
✅ |
|
✅ |
✅ |
✅ |
|
✅ |
|||
✅ |
|||
✅ |
✅ |
✅ |
|
✅ |
✅ |
✅ |
|
✅ |
✅ |
✅ |
|
✅ |
✅ |
✅ |
|
✅ |
|||
✅ |
✅ |
✅ |
|
✅ |
|||
✅ |
✅ |
其中有我们熟悉的几个数据库都可以用来存储向量,比如Elasticsearch、MongoDb、Neo4j、Pg、Redis。
视频主要通过In-memory方式演示完整使用流程
Redis也很简单, 你需要先安装redis7.0+的版本:其他的向量数据库不做介绍
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-redis</artifactId>
<version>${langchain4j.version}</version>
</dependency>然后需要注意的是,普通的Redis是不支持向量存储和查询的,需要额外的redisearch模块,我这边是直接使用docker来运行一个带有redisearch模块的redis容器的,命令为:
docker run -p 6379:6379 redis/redis-stack-server:latest注意端口6379不要和你现有的Redis冲突了。
然后就可以使用以下代码把向量存到redis中了:
RedisEmbeddingStore embeddingStore = RedisEmbeddingStore.builder()
.host("127.0.0.1")
.port(6379)
.dimension(1536)
.build();
// 生成向量
Response<Embedding> embed = embeddingModel.embed("我是徐庶");
// 存储向量
embeddingStore.add(embed.content());dimension表示要存储的向量的维度,所以为1536,如果你不是使用OpenAiEmbeddingModel得到的向量,那么维度可能会不一样。
可以使用以下命令来清空:
redis-cli FT.DROPINDEX embedding-index DD匹配向量
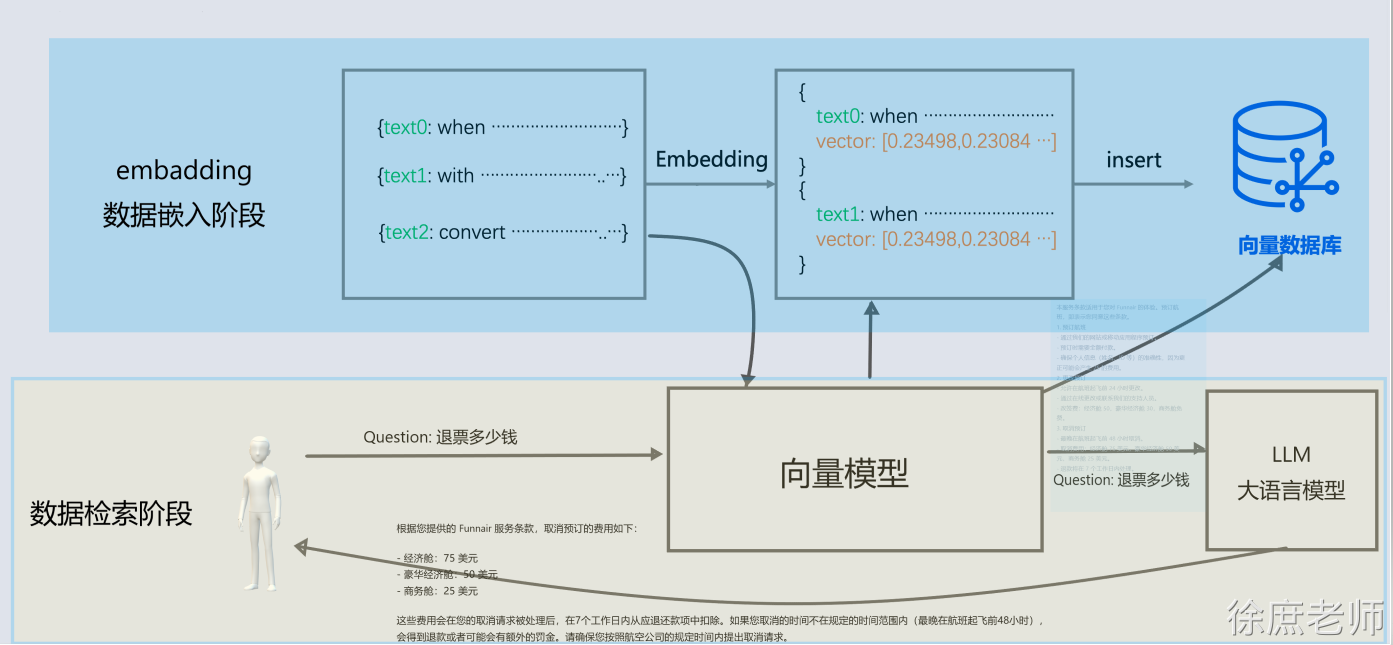
在这个示例中, 我分别存储了预订航班和取消预订2段说明到向量数据库中
然后通过"退票要多少钱" 进行查询
@Test
public void test02() {
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
QwenEmbeddingModel embeddingModel= QwenEmbeddingModel.builder()
.apiKey(System.getenv("ALI_AI_KEY"))
.build();
// 利用向量模型进行向量化, 然后存储向量到向量数据库
TextSegment segment1 = TextSegment.from("""
预订航班:
- 通过我们的网站或移动应用程序预订。
- 预订时需要全额付款。
- 确保个人信息(姓名、ID 等)的准确性,因为更正可能会产生 25 的费用。
""");
Embedding embedding1 = embeddingModel.embed(segment1).content();
embeddingStore.add(embedding1, segment1);
// 利用向量模型进行向量化, 然后存储向量到向量数据库
TextSegment segment2 = TextSegment.from("""
取消预订:
- 最晚在航班起飞前 48 小时取消。
- 取消费用:经济舱 75 美元,豪华经济舱 50 美元,商务舱 25 美元。
- 退款将在 7 个工作日内处理。
""");
Embedding embedding2 = embeddingModel.embed(segment2).content();
embeddingStore.add(embedding2, segment2);
// 需要查询的内容 向量化
Embedding queryEmbedding = embeddingModel.embed("退票要多少钱").content();
// 去向量数据库查询
// 构建查询条件
EmbeddingSearchRequest build = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1)
.build();
// 查询
EmbeddingSearchResult<TextSegment> segmentEmbeddingSearchResult = embeddingStore.search(build);
segmentEmbeddingSearchResult.matches().forEach(embeddingMatch -> {
System.out.println(embeddingMatch.score()); // 0.8144288515898701
System.out.println(embeddingMatch.embedded().text()); // I like football.
});
}
代码执行结果为:
0.7319455553039915
取消预订:
- 最晚在航班起飞前 48 小时取消。
- 取消费用:经济舱 75 美元,豪华经济舱 50 美元,商务舱 25 美元。
- 退款将在 7 个工作日内处理。知识库RAG演练
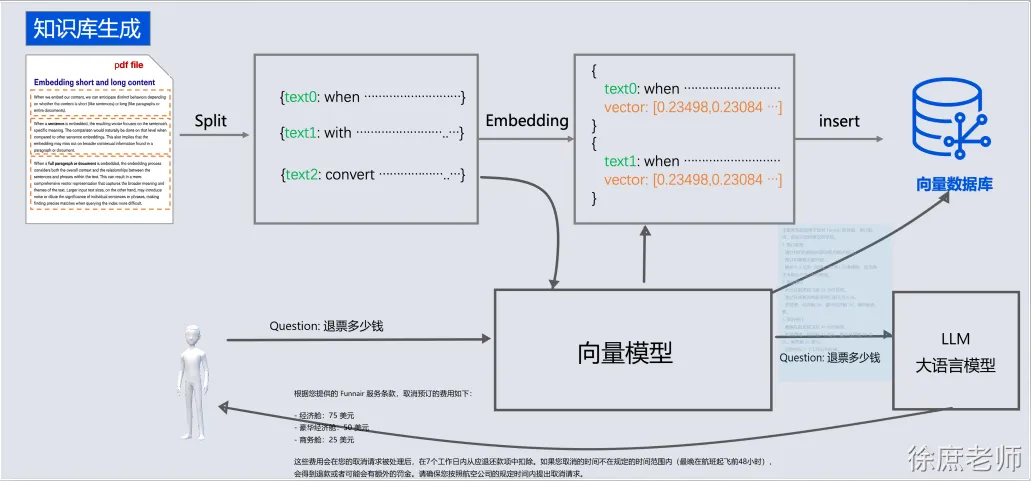
Document Loaders 文档读取器
读取为文档
Document document = ClassPathDocumentLoader.loadDocument("rag/terms-of-service.txt", new TextDocumentParser());1.1. Document Parser 文档解析器
如果要开发一个知识库系统, 这些资料可能在各种文件中, 比如word、txt、pdf、image、html等等, 所以langchain4j也提供了不同的文档解析器:
TextDocumentParser来自langchain4j模块的TextDocumentParser,它可以解析纯文本格式(e.g. TXT、HTML、MD 等)的文件。ApachePdfBoxDocumentParser来自langchain4j-document-parser-apache-pdfbox,它可以解析 PDF 文件ApachePoiDocumentParser来自langchain4j-document-parser-apache-poi,可以解析 MS Office 文件格式(e.g. DOC、DOCX、PPT、PPTX、XLS、XLSX 等)ApacheTikaDocumentParser来自langchain4j-document-parser-apache-tika模块中,可以自动检测和解析几乎所有现有的文件格式
在这里我来解析一份这个txt文件📎terms-of-service.txt, 所以我们用TextDocumentParser
随便放这里吧
代码:
// 读取
Path documentPath = Paths.get(VectorTest.class.getClassLoader().getResource("rag/terms-of-service.txt").toURI());
DocumentParser documentParser = new TextDocumentParser();
Document document = FileSystemDocumentLoader.loadDocument(documentPath, documentParser);2. DocumentSplitter 文档拆分器
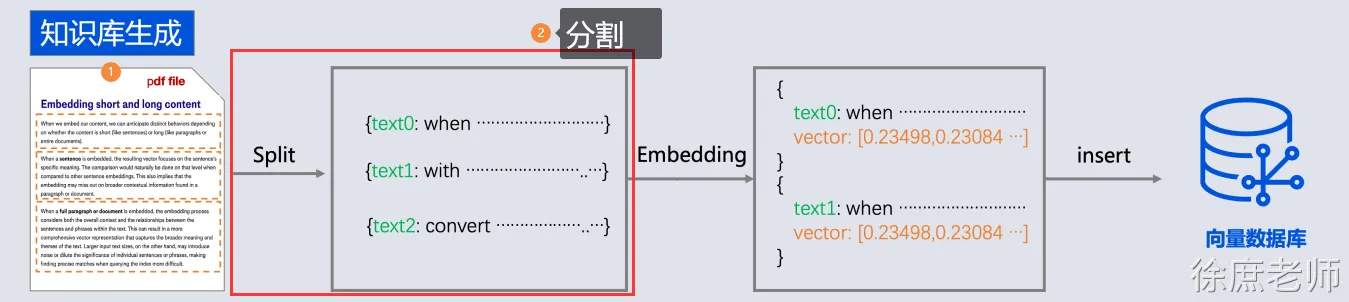
由于文本读取过来后, 还需要分成一段一段的片段(分块chunk), 分块是为了更好地拆分语义单元,这样在后面可以更精确地进行语义相似性检索,也可以避免LLM的Token限制。
langchain4j也提供了不同的文档拆分器:
分词器类型 |
匹配能力 |
适用场景 |
DocumentByCharacterSplitter |
无符号分割 |
就是严格根据字数分隔(不推荐,会出现断句) |
DocumentByRegexSplitter |
正则表达式分隔 |
根据自定义正则分隔 |
DocumentByParagraphSplitter |
删除大段空白内容 |
处理连续换行符(如段落分隔)( |
DocumentByLineSplitter |
删除单个换行符周围的空白, 替换一个换行 |
(
|
DocumentByWordSplitter |
删除连续的空白字符。 |
|
DocumentBySentenceSplitter |
按句子分割 |
该分割器使用Apache OpenNLP 库中的一个类,用于检测文本中的句子边界。它能够识别标点符号(如句号、问号、感叹号等)是否标记着句子的末尾,从而将一个较长的文本字符串分割成多个句子。 |
这里我们选DocumentByLineSplitter吧, 因为内容不多, 所以其实没有特别大的关系, 后面如果大家有兴趣我详细讲解每一种的应用场景。
代码:
将第1步读取到的文档进行分割
DocumentByCharacterSplitter splitter = new DocumentByCharacterSplitter(
20, // 每段最长字数
10 // 自然语言最大重叠字数
);
List<TextSegment> segments = splitter.split(document);chunk_size(块大小)指的就是我们分割的字符块的大小;chunk_overlap(块间重叠大小)就是下图中加深的部分,上一个字符块和下一个字符块重叠的部分,即上一个字符块的末尾是下一个字符块的开始。

在使用按字符切分时,需要指定分割符,另外需要指定块的大小以及块之间重叠的大小(允许重叠是为了尽可能地避免按照字符进行分割造成的语义损失)。
比如
- 最晚在航班起飞前 48 小时取消。取消费用:经济舱 75 美元,豪华经济舱 50 美元,
商务舱 25 美元。退款将在 7 个工作日内处理。
按照chunksize可能会分隔成:
最晚在航班起飞前 48 小时取消。取消费用:经济舱 7
如果设置了重叠可能会:
-最晚在航班起飞前 48 小时取消。取消费用:经济舱 75 美元,豪华经济舱 50 美元,商务舱 25 美元。
-取消费用:经济舱 75 美元,豪华经济舱 50 美元,商务舱 25 美元。退款将在 7 个工作日内处理。整个流程如下:
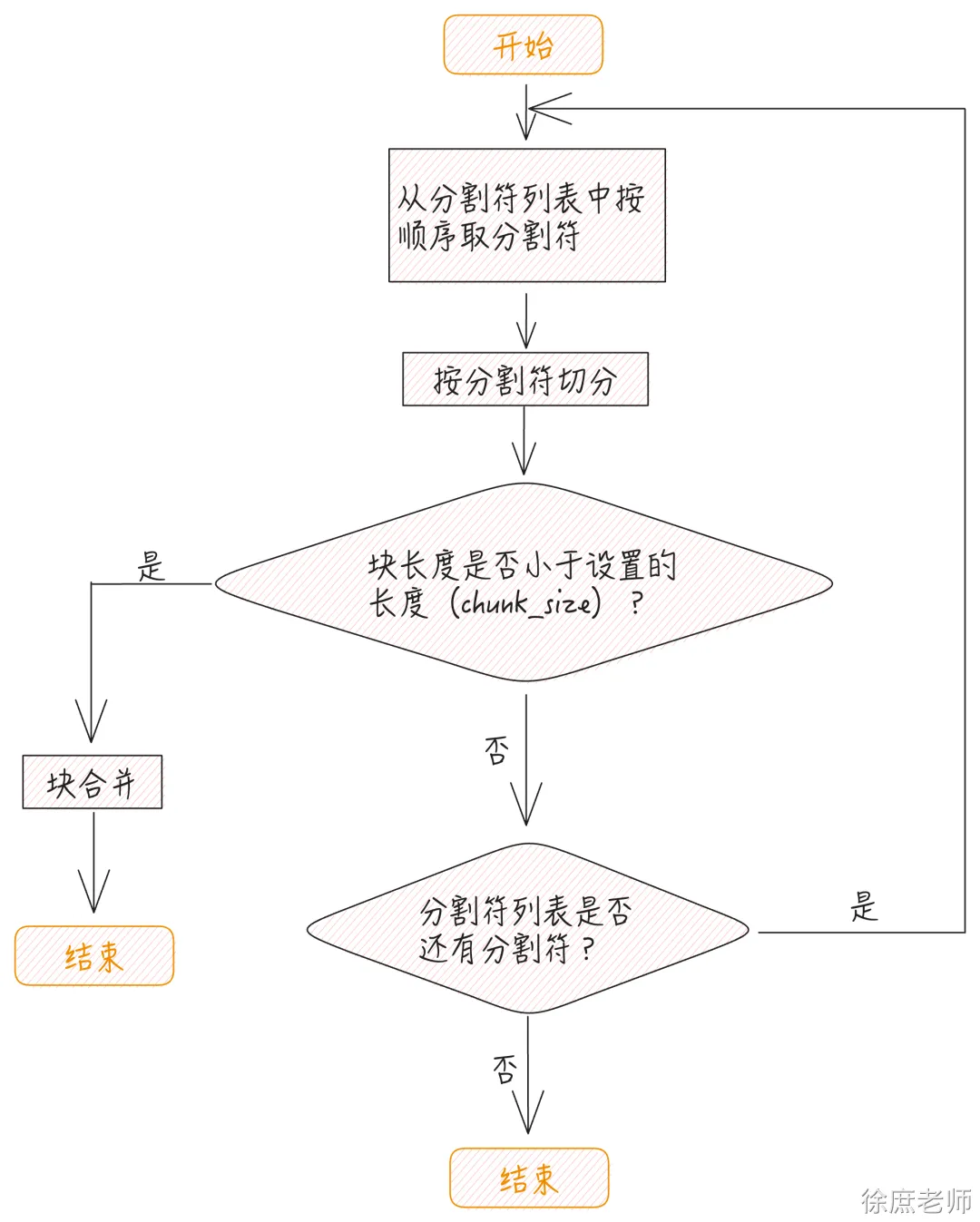
先按照指定的分割符进行切分,切分过之后,如果块的长度小于 chunk_size 的大小,则进行块之间的合并。在进行合并时,遵循下面的规则:
1. 如果相邻块加在一起的长度小于或等于chunk_size,则进行合并;否则看你有没有子分割器,如果没有报错。
2. 在进行合并时,如果块的大小小于或等于chunk_overlap,并且和前后两个相邻块合并后,两个合并后的块均不超过chunk_size,则两个合并后的块允许有重叠
在RAG系统中,文本分块的粒度需要平衡语义完整性与计算效率,并非越细越好。以下是关键考量点:
2.1. 分隔经验:
2.1.1. 过细分块的潜在问题
- 语义割裂: 破坏上下文连贯性,影响模型理解 。
- 计算成本增加:分块过细会导致向量嵌入和检索次数增多,增加时间和算力开销。
- 信息冗余与干扰:碎片化的文本块可能引入无关内容,干扰检索结果的质量,降低生成答案的准确性。
2.1.2. 分块过大的弊端
- 信息丢失风险:过大的文本块可能超出嵌入模型的输入限制,导致关键信息未被有效编码。
- 检索精度下降:大块内容可能包含多主题混合,与用户查询的相关性降低,影响模型反馈效果。
场景 |
分块策略 |
参数参考 |
微博/短文本 |
句子级分块,保留完整语义 |
每块100-200字符 |
学术论文 |
段落级分块,叠加10%重叠 |
每块300-500字符 |
法律合同 |
条款级分块,严格按条款分隔 |
每块200-400字符 |
长篇小说 |
章节级分块,过长段落递归拆分为段落 |
每块500-1000字符 |
- 固定长度分块
-
- 字符数范围:通常建议每块控制在 100-500字符(约20-100词),以平衡上下文完整性与检索效率12。
- 重叠比例:相邻块间保留 10-20%的重叠内容(如块长500字符时重叠50-100字符),减少语义断层34。
- 语义分块
-
- 段落或章节:优先按自然段落、章节标题划分,保持逻辑单元完整14。
- 动态调整:对于长段落,可递归分割为更小单元(如先按段落分块,过长时再按句子拆分)46。
- 专业领域调整
-
- 高信息密度文本(如科研论文、法律文件):采用更细粒度分块(100-200字符),保留专业术语细节14。
- 通用文本(如新闻、社交媒体):适当放宽分块大小(300-500字符)12
3. 文本向量化
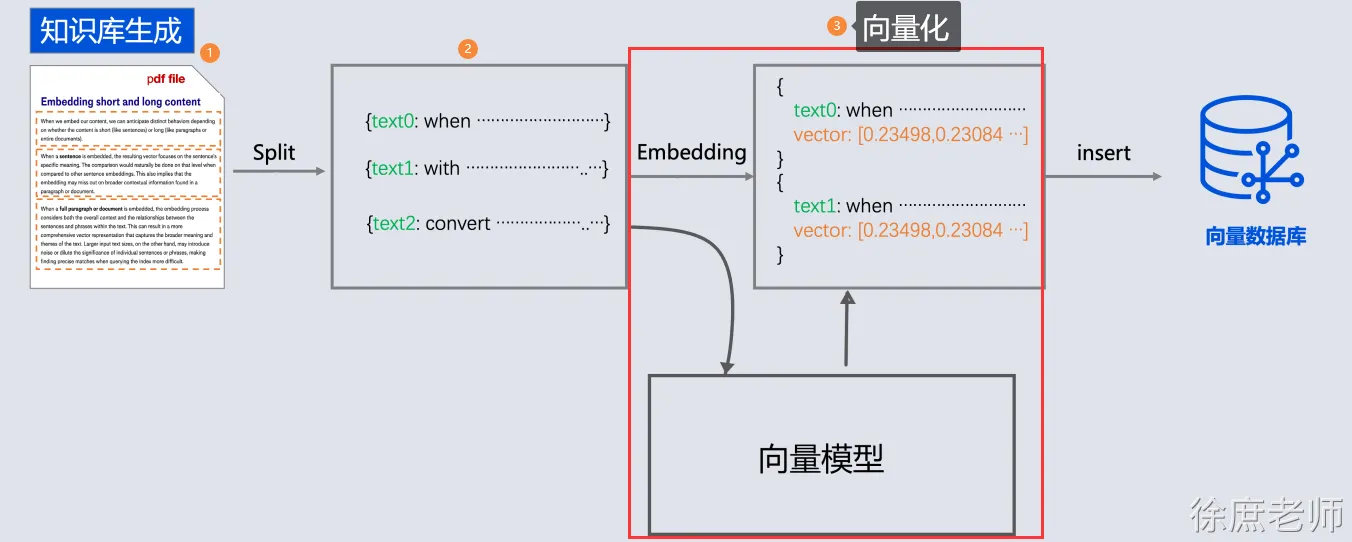
向量化存储之前在“文本向量化”介绍了, 就是通过向量模型库进行向量化
代码:
依然通过Qwen向量模型进行向量化: 将第2步分割的chunk进行向量化
QwenEmbeddingModel embeddingModel= QwenEmbeddingModel.builder()
.apiKey(System.getenv("ALI_AI_KEY"))
.build();
// 向量化
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();4. 存储向量
选择向量数据库进行存储即可
代码:
// 存入
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore.addAll(embeddings,segments);5. 向量数据库检索
代码:
需要先将文本进行向量化, 然后去向量数据库查询,
// 生成向量
Response<Embedding> embed = embeddingModel.embed("退费费用");
EmbeddingSearchRequest build = EmbeddingSearchRequest.builder().queryEmbedding(embed.content()).build();
// 查询
EmbeddingSearchResult<TextSegment> results = embeddingStore.search(build);
for (EmbeddingMatch<TextSegment> match : results.matches()) {
System.out.println(match.embedded().text() + ",分数为:" + match.score());
}完整代码:
@Test
public void test03() throws URISyntaxException {
// 读取
Path documentPath = Paths.get(VectorTest.class.getClassLoader().getResource("rag/terms-of-service.txt").toURI());
DocumentParser documentParser = new TextDocumentParser();
Document document = FileSystemDocumentLoader.loadDocument(documentPath, documentParser);
DocumentByLineSplitter splitter = new DocumentByLineSplitter(
20, // 每段最长字数
10 // 自然语言最大重叠字数
);
List<TextSegment> segments = splitter.split(document);
QwenEmbeddingModel embeddingModel= QwenEmbeddingModel.builder()
.apiKey(System.getenv("ALI_AI_KEY"))
.build();
// 向量化
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
// 存入
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore.addAll(embeddings,segments);
// 生成向量
Response<Embedding> embed = embeddingModel.embed("退费费用");
EmbeddingSearchRequest build = EmbeddingSearchRequest.builder().queryEmbedding(embed.content()).build();
// 查询
EmbeddingSearchResult<TextSegment> results = embeddingStore.search(build);
for (EmbeddingMatch<TextSegment> match : results.matches()) {
System.out.println(match.embedded().text() + ",分数为:" + match.score());
}
}6. 对话阶段
ChatLanguageModel model = QwenChatModel
.builder()
.apiKey(System.getenv("ALI_AI_KEY"))
.modelName("qwen-max")
.build();
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(5) // 最相似的5个结果
.minScore(0.6) // 只找相似度在0.6以上的内容
.build();
// 为Assistant动态代理对象 chat ---> 对话内容存储ChatMemory----> 聊天记录ChatMemory取出来 ---->放入到当前对话中
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(model)
.contentRetriever(contentRetriever)
.build();
System.out.println(assistant.chat("退费费用"));
public interface Assistant {
String chat(String message);
}
AiService向量检索原理:
7. 整合SpringBoot
最终其实还会将查询到的内容, 和对话上下文组合起来, 发给LLM为我们组织语言进行回答。
这一步我们直接整合进SpringBoot进行实战:
- 配置一个Content Retriever 内容检索器
-
- 提供向量数据库和向量模型及其他参数
- 将内容检索器绑定到AiServices
- 当我们进行LLM对话时, 底层会自动为我们检索向量数据库进行回答。
public interface Assistant {
String chat(String message);
// 流式响应
TokenStream stream(String message);
}
@Bean
public Assistant assistant(ChatLanguageModel qwenChatModel,
StreamingChatLanguageModel qwenStreamingChatModel,
ToolsService toolsService,
EmbeddingStore embeddingStore,
QwenEmbeddingModel qwenEmbeddingModel) {
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(qwenEmbeddingModel)
.maxResults(5) // 最相似的5个结果
.minScore(0.6) // 只找相似度在0.6以上的内容
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(qwenChatModel)
.streamingChatLanguageModel(qwenStreamingChatModel)
.tools(toolsService)
.contentRetriever(contentRetriever)
.chatMemory(chatMemory)
.build();
return assistant;
}当然我们还需要提前存储向量数据到向量数据库
@Bean
CommandLineRunner ingestTermOfServiceToVectorStore(QwenEmbeddingModel qwenEmbeddingModel,
EmbeddingStore embeddingStore) throws URISyntaxException {
// 读取
Path documentPath = Paths.get(Langchain4jDemosApplication.class.getClassLoader().getResource("rag/terms-of-service.txt").toURI());
return args -> {
DocumentParser documentParser = new TextDocumentParser();
Document document = FileSystemDocumentLoader.loadDocument(documentPath, documentParser);
DocumentByLineSplitter splitter = new DocumentByLineSplitter(
500,
200
);
List<TextSegment> segments = splitter.split(document);
// 向量化
List<Embedding> embeddings = qwenEmbeddingModel.embedAll(segments).content();
// 存入
embeddingStore.addAll(embeddings,segments);
};
}我们依然利用之前的/memory_stream_chat进行测试: 不需要改任何代码
@RequestMapping(value = "/memory_stream_chat",produces ="text/stream;charset=UTF-8")
public Flux<String> memoryStreamChat(@RequestParam(defaultValue="我是谁") String message, HttpServletResponse response) {
TokenStream stream = assistant.stream(message);
return Flux.create(sink -> {
stream.onPartialResponse(s -> sink.next(s))
.onCompleteResponse(c -> sink.complete())
.onError(sink::error)
.start();
});
}完成:✿✿ヽ(°▽°)ノ✿

希望大家能掌握利用langchan4j进行function-call和RAG开发。
Chain多个ServiceAI
在一个应用中, 可能需要多个模型共同一起协作完成一个任务。
为什么要这样:
您的LLM可能不需要始终了解您拥有的每个tools。例如,当用户只是向LLM打招呼或说再见时,让 LLM 访问数十或数百个tools的成本很高,有时甚至很危险(LLM 调用中包含的每个tools都会消耗大量token),并且可能会导致意想不到的结果(LLM 可能会产生幻觉或被操纵以使用非预期的输入来调用tools)。
关于 RAG:同样,有时需要为 LLM 提供一些上下文,但并非总是如此,因为它会产生额外的成本(更多上下文 = 更多token)并增加响应时间(更多上下文 = 更高的延迟)。
关于模型参数:在某些情况下,您可能想不通的对话使用不同的 LLM ,以利用不同LLM的最佳特性。
- 您可以一个接一个地调用 AI 服务(又称链接-chain)。
- 您可以使用确定性和 LLM 支持的
if/else语句(AI 服务可以返回boolean)。 - 您可以使用确定性和 LLM 支持的
switch语句(AI 服务可以返回enum)。 - 您可以使用确定性和 LLM 驱动的
for/while循环(AI 服务可以返回int和其他数字类型)。 - 您可以在单元测试中模拟 AI 服务(因为它是一个接口)。
- 您可以单独地对每个 AI 服务进行集成测试。
并且我们可以自由的进行任务编排:
大家平常应该见过一些AI智能体, 由多个(LLM)任务组合编排为一个智能体,

其实利用langchain4j的chain特性, 也可以完成这种类似的效果, 不过你需要自己完成前端编排以及不同任务的初始化和具体实现。 这不是一两句话能讲清楚的。
这里我们利用langchain4j的chain特性你让你得到更多的灵感。 其实langchain4j也可以实现类似智能体,只不过目前没有特别优秀的开源项目,期待你去实现它!:
代码
以下演示2个模型协调合作,但是实际非常灵活, 甚至可以手搓一个langchain4j版的manus(无非就是多个模型相互协作, 1个负责任务拆分, 1个模型负责任务tools回调执行,但是需要大量提示词不是一句话说清楚的, 有机会带大家手写一个manus)。
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
/**
* @author wx:程序员徐庶
* @desc 测试多模型智能体
**/
public class _04TestAgent {
interface GreetingExpert {
@UserMessage("以下文本是什么任务: {{it}}")
TASKTYPE isTask(String text);
}
interface ChatBot {
@SystemMessage("你是一名航空公司客服代理,请为客户服务:")
String reply(String userMessage);
}
class MilesOfSmiles {
private GreetingExpert greetingExpert;
private ChatBot chatBot;
public MilesOfSmiles(GreetingExpert greetingExpert, ChatBot chatBot) {
this.greetingExpert = greetingExpert;
this.chatBot = chatBot;
}
public String handle(String userMessage) {
TASKTYPE task = greetingExpert.isTask(userMessage);
switch (task) {
case MODIFY_TICKET:
case QUERY_TICKET:
case CANCEL_TICKET:
return task.getName() + "调用service方法处理";
case OTHER:
return chatBot.reply(userMessage);
}
return null;
}
}
ChatLanguageModel qwen;
ChatLanguageModel deepseek;
@BeforeEach
public void init() {
qwen = QwenChatModel
.builder()
.apiKey(System.getenv("ALI_AI_KEY"))
.modelName("qwen-max")
.build();
deepseek = OpenAiChatModel
.builder()
.baseUrl("https://api.deepseek.com")
.apiKey(System.getenv("DEEP_SEEK_KEY"))
.modelName("deepseek-reasoner")
.build();
}
@Test
void test() {
GreetingExpert greetingExpert = AiServices.create(GreetingExpert.class, deepseek);
ChatBot chatBot = AiServices.create(ChatBot.class, qwen);
MilesOfSmiles milesOfSmiles = new MilesOfSmiles(greetingExpert, chatBot);
String greeting = milesOfSmiles.handle("我要退票!");
System.out.println(greeting);
}
}
MCP
mcp其实很简单, 就是tools的一种外部调用的方式(既然要外部调用,肯定就需要遵循一种通信协议, 这里的协议就MCP,利用一种json-rpc2.0的json格式告知用有哪些tools什么参数, 调用哪个tool, 返回什么数据)。之前我们在自己程序中实现了tools, 但是这种tools无法提供给其他应用调用, 形成了应用孤岛, 无法提供外部共享。
图像演示:
代码:
langchain4j 没有提供mcp server的实现, 但是提供的mcp client的实现:
当然mcpserver哪怕纯java也可以单独实现,下次有时间单独给大家讲解(如果有兴趣的话)
<!--mcp-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-mcp</artifactId>
<version>${langchain4j.version}</version>
</dependency>
public class _05TestMCP {
// 测试npx 方式百度地图
@Test
public void test() throws Exception {
// 1.构建模型
ChatLanguageModel model = QwenChatModel
.builder()
.apiKey(System.getenv("ALI_AI_KEY"))
.modelName("qwen-max")
.build();
// 2.构建MCP服务传输方式 有sse和stdio两种, 这里演示的是stdio
McpTransport transport = new StdioMcpTransport.Builder()
.command(List.of("cmd",
"/c",
"npx",
"-y",
"@baidumap/mcp-server-baidu-map",
"mcp/github"))
.environment(Map.of("BAIDU_MAP_API_KEY",
System.getenv("BAIDU_MAP_API_KEY")))
.logEvents(true)
.build();
// 3.构建MCP客户端, 指定传输方式
McpClient mcpClient = new DefaultMcpClient.Builder()
.transport(transport)
.build();
// 4.构建MCP工具提供者, 指定MCP客户端
ToolProvider toolProvider = McpToolProvider.builder()
.mcpClients(List.of(mcpClient))
.build();
// 5.构建服务代理, 指定模型和工具提供者
Bot bot = AiServices.builder(Bot.class)
.chatLanguageModel(model)
.toolProvider(toolProvider)
.build();
try {
// 对话请求
String response = bot.chat("规划长沙到武汉骑行路线");
System.out.println("RESPONSE: " + response);
} finally {
mcpClient.close();
}
}
interface Bot {
String chat(String userMessage);
}
}