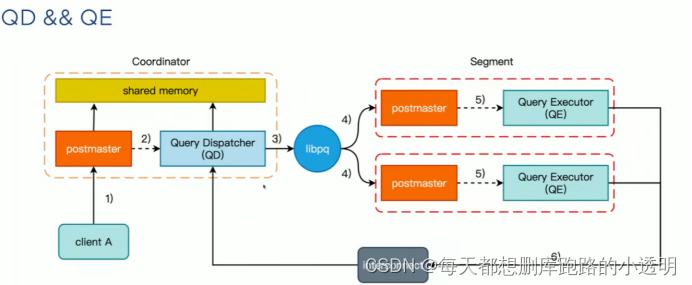
MPP引擎:
面向过去的描述性分析1.0:业务发生了什么,业务为什么会发生
面向未来的预测性分析:告诉企业将要发生什么,市场如何变化,客户的下一步行为是什么,客户的热点是什么
学习内容:深度学习,机器学习,图计算
数据平台:半结构化,非机构化数据
Hadoop:历史数据湖
数据挑战:
- 多个异构数据平台,缺乏统一的企业级视图
- 数据冗余存储,一数多源,存在二义性(数据质量发生问题)
- 平台间数据共享,交换频繁,数据流网状
- 技术路线复杂,增加了开发和运维的工作量
- 集成企业混合数据生态:管理结构化的业务数据,管理数字媒体,半结构化,非结构化数据
- 多种形态,多种时效的数据
现代化数据平台:
构建混合的数据生态
提供多样化的分析能力
支持多元化基础设施
Greenplum
- 满足多种时效的数据需求:数据量大,在有限的时间内,可以把数据加载到gp中去,
提供了外部表接口;支持大量并行,持续化的数据加载(支持文本,csv,xml)
流数据:连续数据,支持断点续传:greenmplum gpserver,可以集成kafka
- 管理多种形态的企业数据
支持几十种数据类型,
结构化:int,char,date等多种常用数据类型
半结构化:hstore,json,json,xml
非结构化及空间数据类型,操作函数:
提供多种类型的分析能力
Greenplum 分布式数据库简介:基于postgre实现的大规模并行处理(Mpp)开源数据平台
具有良好的弹性和线性扩展能力,内置并行存储,并行通信,并行计算和并行优化功能,兼容sql标准。拥有高效的orca优化器,具有强大,高效的PB级数据存储,处理和实时分析能力,同时支持oltp型业务的混合负载
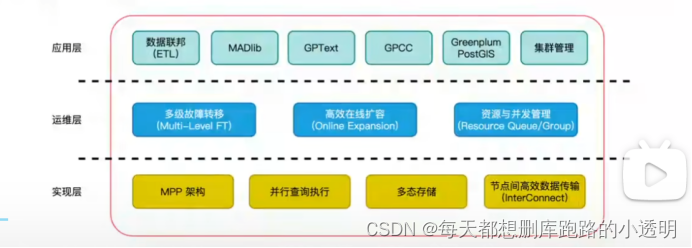
数据联邦:Etl Gpload高效数据抽取转换和加载工具
madlib:机器学习开放平台,机器学习训练
Gptext:gp全局搜索引擎
GPCC:web可视化系统运维工具
GREENMPLUM POSTGIS:索引支持
集群管理:gpcatalog
运维层:
多级故障转移(multi-level FT):协调者,segment
高效在线扩容(online expansion):不停歇的情况下,实现集群节点的增加
资源与并发管理(,resource queue/group)
实现层:
mpp架构:海量分布式数据库
并行查询执行
多态存储
节点间高效数据传输
Geenplum集群化概述
分布式数据存储和多态存储
分布式查询优化器与执行器
集群换:
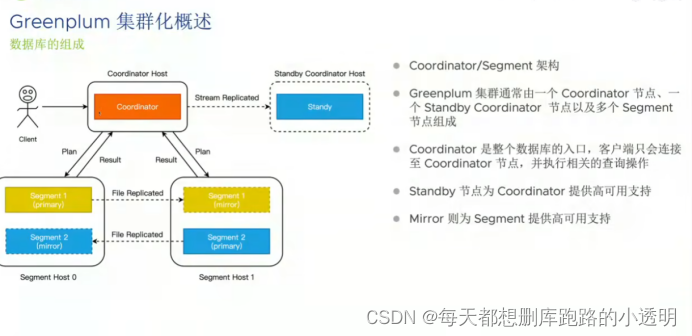
客户和coordinator 进行连接交互(psql协议):co(协调者)不存储数据,只作为数据库的接入点,负责给segment分配任务,收集数据,standyby coordiantorhost(高可用,流复制的方式进行实时同步)
Segment:segment节点直接参与计算,数据存储节点 , mirror(高可用,文件传输)
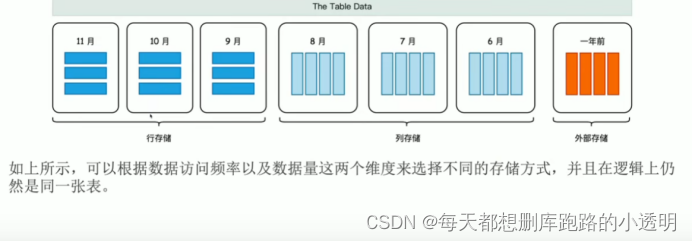
Greenplum 分布式数据存储和多台存储
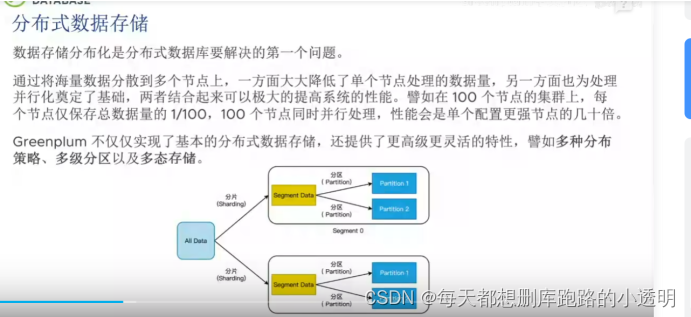
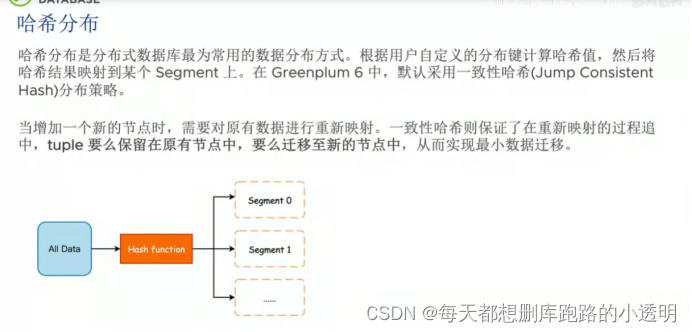
数据分布策略:
哈希分布:取余,改为一致性hash
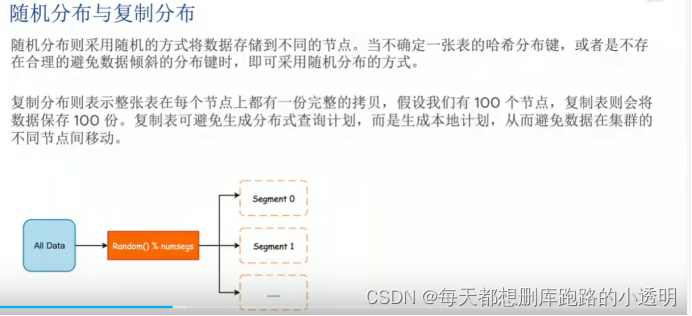
随机分布:
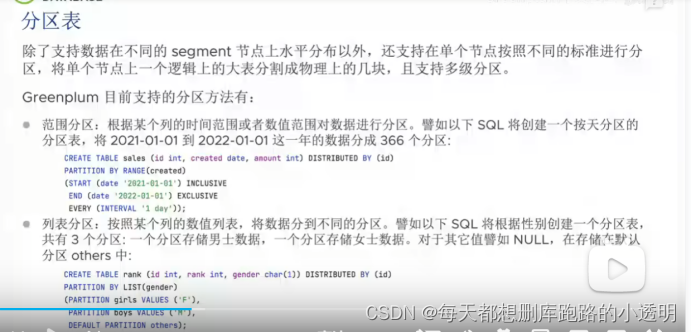

分布式查询优化器:
Motion:

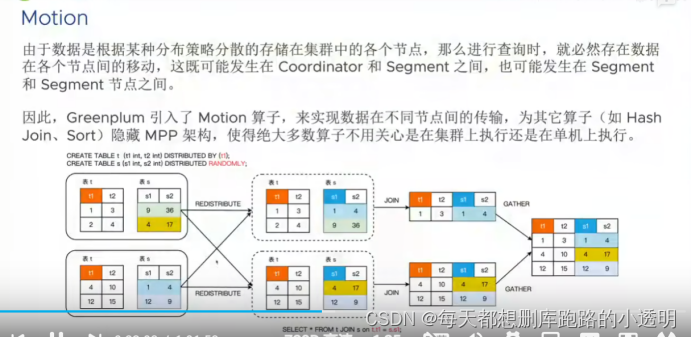




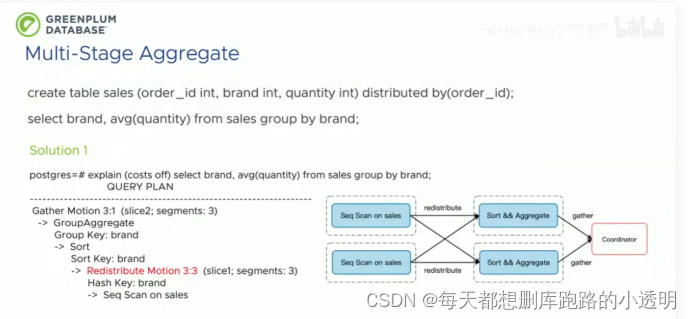
先进行数据重分布,根据brand将数据同一个brand值的放在一个节点上,然后再进行计算
缺点:
1.容易出现,多个服务器,只有两个有值其余空闲的状态
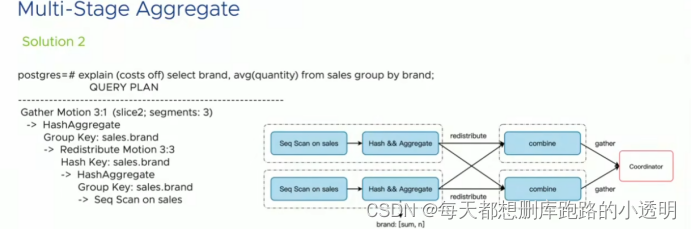
先在每一个节点上,计算出不同brand 的数据量以及sum和,形成一个hash 表
,然后对hash表进行重分布然后在到主节点点上进行汇总计算
分布式执行器