
本文单链表详细,各位看官肯定一看就会(不行ctrl+c,ctrl+v)(^ v ^ )
目录
因为顺序表存在缺点,由此衍生出来了链表,本文介绍链表中的单链表(需要一定的思维量,请做好准备,我尽量描述清楚,建议先学好指针,仔细看图,本文通篇依靠指针(一级指针,二级指针))
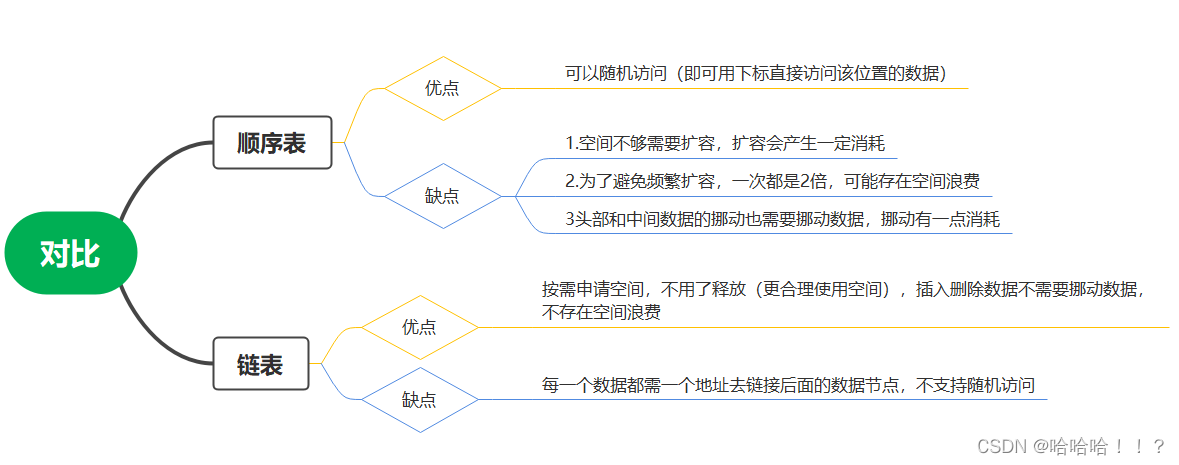
链表和顺序表的优缺对比
单链表展示
(节点即为结构体)
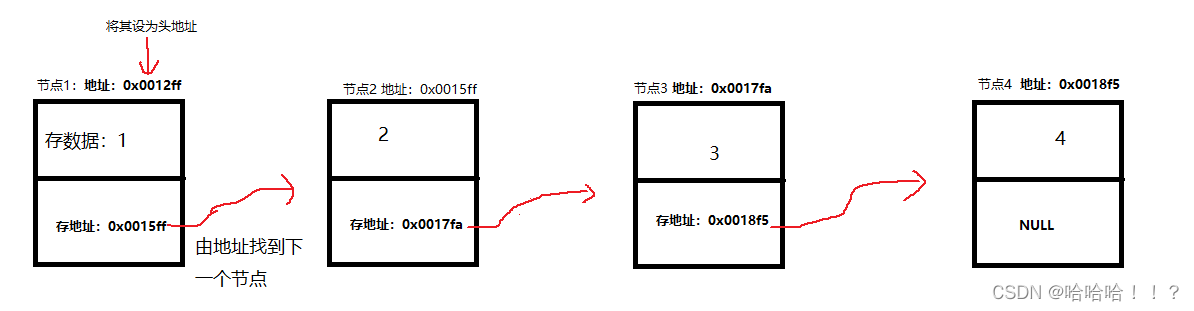
原理:
创建一个有指针的结构体,在前一个结构体的指针中放后一个结构体的地址,从而形成可以链式访问(像链条一样,由第一个结构体可以单向一直访问到最后一个)
学习单链表的意义
1.很多oj题考查的都是单链表,
2.单链表更多作为更复杂数据结构的子结构。如:哈希桶,邻接表
注:但单链表的缺陷很多,单纯增删查改意义不大,链表存储数据还是要看双向链表,but,增删查改是做oj题的基础,写完了这些功能,你就半个脚指头进了链表基础
单链表实现
准备环节:
1.创建结构体
typedef int SLTDateType;//定义int为SLDateType
typedef struct SLTNode
{
SLTDateType data;//用于存放数据
SLTNode* next;//用于存放下一个结构体的地址
}SLTNode;//定义结构体SLTNode为SLTNode
2.创建存储头节点地址的指针plist
(由于未有后面的节点,先将指针变量赋NULL,防止越界访问)
SLTNode* plist = NULL//创建名为plist的头节点的指针(地址),并将其赋空3.可以创建首节点或者扩容的函数
使用malloc来申请空间(不知道malloc的请去看http://t.csdn.cn/TgXqD)
函数需返回SLTNode*(即申请的结构体的地址),用于后面存储地址的操作
SLTNode* BuyListNode(SLTDateType x)//传所需要存的数据x(买内存,有意思)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));//使用malloc向内存申请一个节点空间
//防止内存申请失败(虽然现在操作系统基本不可能出现此情况,但要有安全意识)
assert(newnode != NULL);
newnode->data = x;//在结构体中存x
newnode->next = NULL;//将新结构体的指针变量赋NULL
return newnode;//返回申请的结构体的地址
}如顺序表一样,单链表也有打印,头插,尾插,头删,尾删,查找,插入,定点删除,销毁
最常用的结构
1.通过遍历找地址(演示代码为找尾地址)
SLTNode* tail = *pphead;//把头节点地址给新变量tail
while (tail->next != NULL)//重点循环找最后一个节点的地址
{
tail = tail->next;
}2.安全检查
#include<assert>
assert(!pphead);用assert断言,为假终止程序并报错,养成好的代码素养
模块函数与思路
1.尾插函数
思路:先遍历找到尾节点,再将新节点连上即可
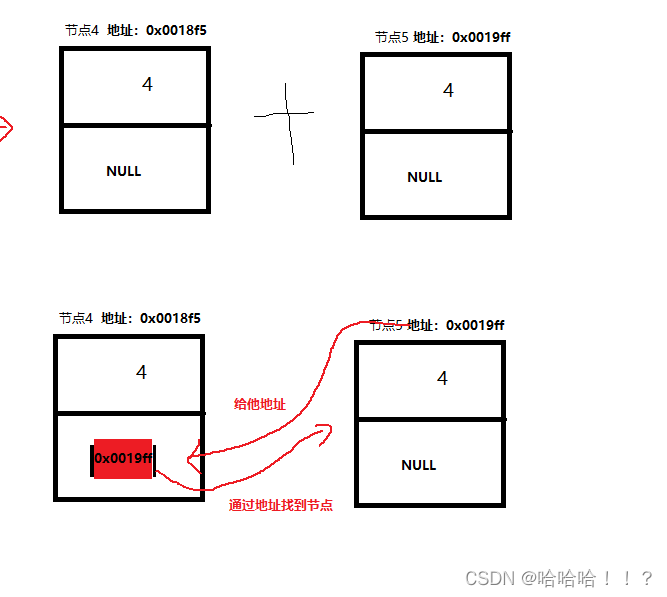
代码实现
//为了可以修改首地址,需要传首地址的地址,即二级指针**pphead,x为所插入的数
void SListPushBack(SLTNode** pphead, SLTDateType x)
{
SLTNode* newnode = BuyListNode(x);//使用刚刚买内存的函数来创建结构体
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
SLTNode* tail = *pphead;
while (tail->next != NULL)//重点循环
{
tail = tail->next;
}
tail->next = newnode;
}
}2.尾删函数
思路:找到尾节点的地址,将其free,并将前一个节点的next附空(尾插的逆过程)
代码实现
void SListPopBack(SLTNode** pphead)
{
assert(*pphead != NULL);//安全检查
if ((*pphead)->next == NULL)//只有一个节点的情况
{
free((*pphead)->next);
*pphead = NULL;
}
else
{
SLTNode* tail = *pphead;
SLTNode* pos = tail;
while (tail->next != NULL)
{
pos = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
pos->next = NULL;
}
}3.头插函数
思路:先买内存,然后将其的next附头地址,头地址附新节点地址
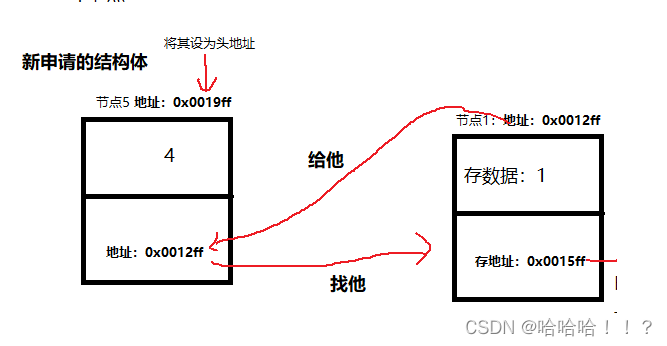
代码实现
void SListPushFront(SLTNode** pphead, SLTDateType x)
{
SLTNode* newnode = BuyListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
v4.头删
思路:头插的逆过程
代码实现
void SListPopFront(SLTNode** pphead)
{
assert(*pphead != NULL);
SLTNode* front = *pphead;
*pphead = (*pphead)->next;
free(front);
}5.打印函数
思路:遍历加打印
代码实现
void SListPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
if (cur == NULL)
{
printf("NULL ");//好看,提醒已经到头了
}
}6.查找函数
思路:遍历+比对
代码实现
//注意需要传回找到数据的地址
SLTNode* SListFind(SLTNode* phead, SLTDateType x)
{
SLTNode* plist = phead;
while (plist != NULL)
{
if (plist->data == x)
{
return plist;
}
else
{
plist = plist->next;
}
}
return NULL;
}7.定点删除
实现方法一:
思路:找到所需要删的数据的地址,用遍历找到他的上一个地址去删除他
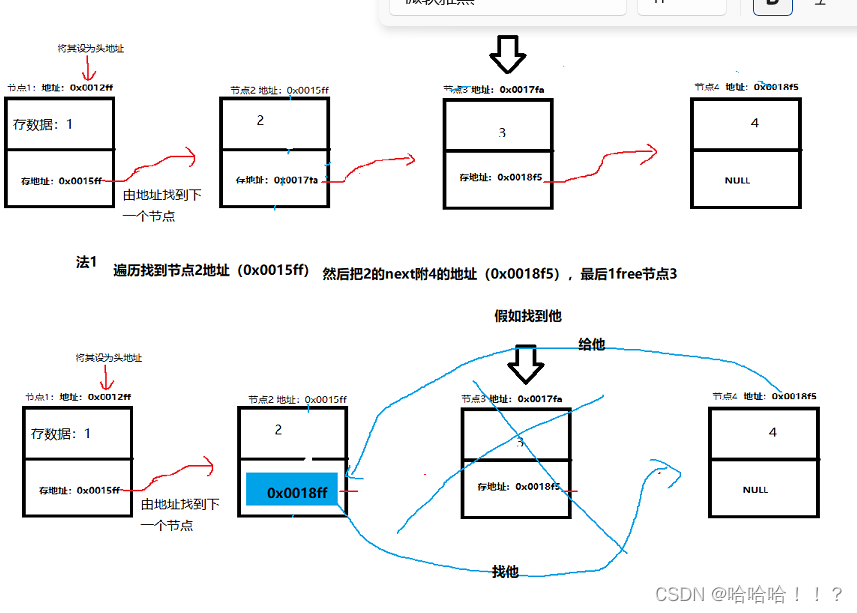
代码实现
//pos即find函数找到的地址
void SListEaserFornt(SLTNode** pphead, SLTNode* pos)
{assert(*pphead!=NULL);
if (*pphead == pos)
{
SListPopFront(pphead);
}
else
{
SLTNode* pos2 = *pphead;
while (pos2 ->next!= pos)
{
pos2 = pos2->next;
}
pos2->next = pos->next;
free(pos);
}
}
实现方法二:
思路:找到所需要删的数据的地址,直接删除他的下一个节点的内容
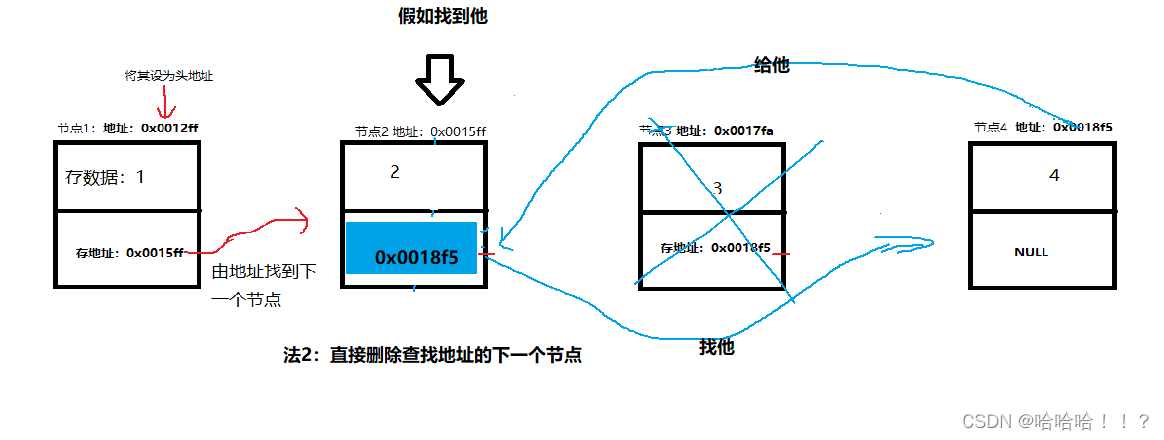
//pos即为find函数找到的函数地址
void SListEaserback(SLTNode* pos)
{
assert(pos != NULL);
SLTNode* next = pos->next;
pos->next = next->next;
free(next);
}两种方法各有优劣
方法一:理解操作简单,但时间复杂度是O(n)
方法二:时间复杂度是O(1)
8.插入函数
思路:找到所需要的位置,返回地址,通过地址插入节点
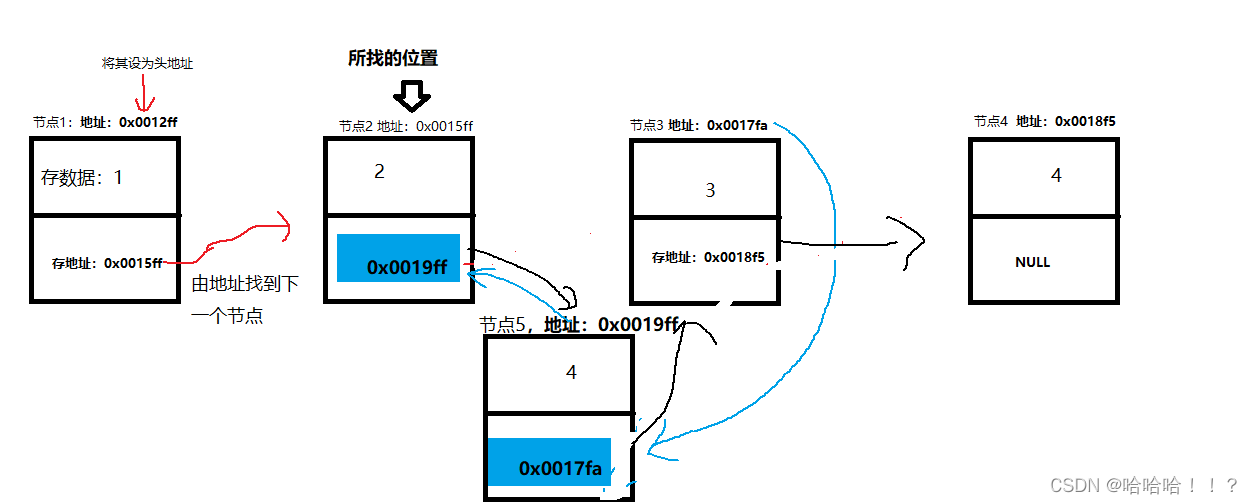
代码实现
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDateType x)
{
if (pos == *pphead)
{
SLTNode* newnoda = BuyListNode(x);
newnoda->next = *pphead;
*pphead = newnoda;
}
else {
SLTNode* newnoda = BuyListNode(x);
SLTNode* prev = *pphead;
while (prev->next != pos) {
prev = prev->next;
}
prev->next = newnoda;
newnoda->next = pos;
}
}
9.销毁函数
思路:双指针,遍历加销毁,并将头指针附NULL,
代码实现
//思路:用pos定位当前节点,next定位下一个节点,free(pos),再把next赋给pos,next向下走一个
void SListDestroy(SLTNode** pphead)
{
SLTNode* pos = *pphead;//将头节点地址传给pos和pphead
SLTNode* next = *pphead;
while (next != NULL)
{ pos = next;
next = next->next;
free(pos);
}
*pphead = NULL;
}以上就是单链表整体函数的讲解,链表这玩意主要靠细节和画图,注意当前指针是哪个节点,next包含哪个节点,链表就没有难点