目录
准备数据
#创建员工表
表名 emp
表中字段:
eid 员工id,int
ename 姓名,varchar
sex 性别,char
salary 薪资,double
hire_date 入职时间,date
dept_name 部门名称,varchar
#创建员工表
CREATE TABLE emp(
eid INT,
ename VARCHAR(20),
sex CHAR(1),
salary DOUBLE,
hire_date DATE,
dept_name VARCHAR(20)
);
#添加数据
INSERT INTO emp VALUES(1,'孙悟空','男',7200,'2013-02-04','教学部');
INSERT INTO emp VALUES(2,'猪八戒','男',3600,'2010-12-02','教学部');
INSERT INTO emp VALUES(3,'唐僧','男',9000,'2008-08-08','教学部');
INSERT INTO emp VALUES(4,'白骨精','女',5000,'2015-10-07','市场部');
INSERT INTO emp VALUES(5,'蜘蛛精','女',5000,'2011-03-14','市场部');
INSERT INTO emp VALUES(6,'玉兔精','女',200,'2000-03-14','市场部');
INSERT INTO emp VALUES(7,'林黛玉','女',10000,'2019-10-07','财务部');
INSERT INTO emp VALUES(8,'黄蓉','女',3500,'2011-09-14','财务部');
INSERT INTO emp VALUES(9,'吴承恩','男',20000,'2000-03-14',NULL);
INSERT INTO emp VALUES(10,'孙悟饭','男', 10,'2020-03-14','财务部');
INSERT INTO emp VALUES(11,'兔八哥','女', 300,'2010-03-14','财务部');
单表操作
排序
通过 ORDER BY 子句,可以将查询出的结果进行排序(排序只是显示效果,不会影响真实数据)
语法结构:select 字段名 from 表名 [where 字段名 = 值] order by 字段名称 [asc/desc]
- ASC 升序排序(默认升序)
- DESC 降序排序
1) 单列排序 :按照某一个字段进行排序
SELECT * FROM emp ORDER BY salary; -- 默认升序排序
SELECT * FROM emp ORDER BY salary DESC; -- 降序排序
2)组合排序:同时对多个字段进行排序
-- 在薪水排序的基础上,再使用id进行排序, 如果薪水相同就以id 做降序排序
SELECT * FROM emp ORDER BY salary DESC,eid DESC;
组合排序的特点:如果第一个字段值相同,就按照第二个字段进行排序
聚合函数
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵
向查询,它是对某一列的值进行计算,然后返回一个单一的值(另外聚合函数会忽略null空值。)
简单来说就是,将一列数据作为一个整体,进行纵向的计算
语法结构: select 聚合函数(字段名) from 表名 [where 条件]
常用的聚合函数
| 聚合函数 | 作用 |
|---|---|
| count(字段) | 统计记录数 |
| sum(字段) | 求和操作 |
| max(字段) | 求最大值 |
| min(字段) | 求最小值 |
| avg(字段) | 求平均值 |
SQL实现
# 1.查询员工的总数
SELECT COUNT(*) FROM emp;
SELECT COUNT(1) FROM emp;
SELECT COUNT(eid) FROM emp;
-- count 函数在统计的时候会忽略空值,所以不要使用含空值的列
# 2.查看员工总薪水、最高薪水、最小薪水、薪水的平均值
SELECT
SUM(salary) '总薪水',
MAX(salary) '最高薪水',
MIN(salary) '最低薪水',
AVG(salary) '平均值'
FROM emp;
# 3.查询薪水大于4000员工的个数
SELECT COUNT(*) FROM emp WHERE salary > 4000;
# 4.查询部门为'教学部'的所有员工的个数
SELECT COUNT(*) FROM emp WHERE dept_name = '教学部';
# 5.查询部门为'市场部'所有员工的平均薪水
SELECT AVG(salary) FROM emp WHERE dept_name = '市场部';
分组查询
分组查询指的是使用 GROUP BY 语句,对查询的信息进行分组,相同数据作为一组
语法结构: select 分组字段/聚合函数 from 表名 group by 分组字段
分组目的: 是为了做统计操作,一般分组会和聚合函数一起使用,另外查询的时候要查询分组字段。
需求:通过性别字段进行分组,求各组的平均薪资
SELECT sex 性别,AVG(salary) FROM emp GROUP BY sex;
#1.查询所有部门信息
SELECT dept_name AS '部门名称' FROM emp GROUP BY dept_name;
#2.查询每个部门的平均薪资
SELECT dept_name,AVG(salary) FROM emp GROUP BY dept_name;
#3.查询每个部门的平均薪资, 部门名称不能为null
SELECT dept_name,AVG(salary) FROM emp WHERE dept_name IS NOT NULL GROUP BY dept_name;
需求:查询平均薪资大于6000的部门
# 查询平均薪资大于6000的部门
-- 1. 首先分组求出平均薪资
-- 2. 求出 平均薪资大于6000的部门
-- 在分组之后,进行条件过滤,我们使用 having 条件
SELECT
dept_name,AVG(salary)
FROM emp
WHERE dept_name IS NOT NULL GROUP BY dept_name
HAVING AVG(salary) > 6000;
where 和having 的区别
- where
- 在分组前进行过滤
- where后面不能跟聚合函数
- having
- 在分组后进行过滤
- having后面可以写聚合函数
limit关键字
limit是限制的意思,用于限制返回的查询结果的行数
语法结构: select 字段 from 表名 limit offset,length;
参数说明:
offset:起始行数,默认从0开始
length:返回的行数,即要查询几条数据
需求:
查询emp表中的前 5条数据
查询emp表中 从第4条开始,查询6条
SQL实现
# 查询emp表中的前 5条数据
SELECT * FROM emp LIMIT 0,5;
SELECT * FROM emp LIMIT 5;
# 查询emp表中 从第4条开始,查询6条
SELECT * FROM emp LIMIT 3,6;
需求: 分页操作
SQL实现
-- limit 分页操作,每一页显示3条数据
SELECT * FROM emp LIMIT 0,3; -- 第一页
SELECT * FROM emp LIMIT 3,3; -- 第二页
-- 分页公式:起始行数 = (当前页码 - 1) * 每一页显示条数
SQL约束
约束是对数据进行一定的限制,来保证数据的完整性,有效性以及正确性,违反约束的错误数据,将无法插入到表中。
常见的约束:
| 约束名 | 关键字 |
|---|---|
| 主键约束 | primary key |
| 唯一约束 | unique |
| 非空约束 | not null |
| 外键约束 | foreign key |
主键约束
特点: 不可重复、唯一、非空
作用: 用来表示数据库中的每一条记录
添加主键约束
语法格式:字段名 字段类型 primary key
需求:创建一个带有主键的表
-- 方式一:
CREATE TABLE stu(
sid INT PRIMARY KEY,
sname VARCHAR(20),
sex CHAR(1)
);
-- 方式二:
CREATE TABLE stu(
sid INT,
sname VARCHAR(20),
sex CHAR(1),
PRIMARY KEY(sid) -- 指定sid为主键
);
-- 方式三:创建表之后,在添加主键
CREATE TABLE stu(
sid INT,
sname VARCHAR(20),
sex CHAR(1)
);
-- 通过DDL语句,添加主键约束
ALTER TABLE stu MODIFY sid INT PRIMARY KEY;
ALTER TABLE stu ADD PRIMARY KEY(sid);
desc 查看表结构
DESC stu;

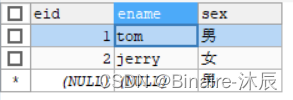
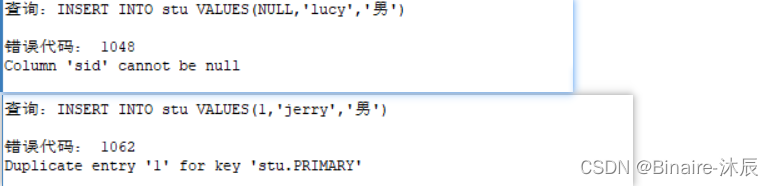
测试主键的唯一性和非空性
# 正常插入一条数据
INSERT INTO stu VALUES(1,'tom','男');
# 插入一条数据,主键为空
INSERT INTO stu VALUES(NULL,'lucy','男');
-- Column 'sid' cannot be null 主键不能为空
# 插入一条数据,主键为1
INSERT INTO stu VALUES(1,'jerry','男');
-- Duplicate entry '1' for key 'stu.PRIMARY' 主键重复
- 哪些字段可以作为主键 ?
- 通常针对业务去设计主键,每张表都设计一个主键id
- 主键是给数据库和程序使用的,只要能够保证不重复就好,比如:身份证就可以作为主键
删除主键约束
-- 删除主键
ALTER TABLE stu DROP PRIMARY KEY;
主键自增
主键自增 :auto_increment 表示自动增长,字段类型必须为整型
- 创建一张主键自动递增的表
-- 创建一张主键自动递增的表
CREATE TABLE stu(
sid INT PRIMARY KEY AUTO_INCREMENT,
sname VARCHAR(20),
sex CHAR(1)
);
- 插入数据,观察主键的自增
INSERT INTO stu(sname,sex) VALUES('tom','男');
INSERT INTO stu(sname,sex) VALUES('lucy','男');
INSERT INTO stu VALUES(NULL,'jerry','男');
INSERT INTO stu VALUES(NULL,'lily','女');
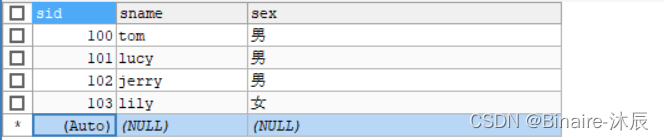
注意: 通过观察发现,主键的值是从 1 开始自增的,然后每次加 1 。那么能不能修改,或者设置主键自增的起始值呢?
修改主键自增起始值
默认的 AUTO_INCREMENT 的开始值是 1,如果希望修改起始值,修改方式如下:
- 重新创建一张表
CREATE TABLE stu(
sid INT PRIMARY KEY AUTO_INCREMENT,
sname VARCHAR(20),
sex CHAR(1)
)AUTO_INCREMENT=100;
- 插入数据,观察主键起始值
INSERT INTO stu(sname,sex) VALUES('tom','男');
INSERT INTO stu(sname,sex) VALUES('lucy','男');
INSERT INTO stu VALUES(NULL,'jerry','男');
INSERT INTO stu VALUES(NULL,'lily','女');
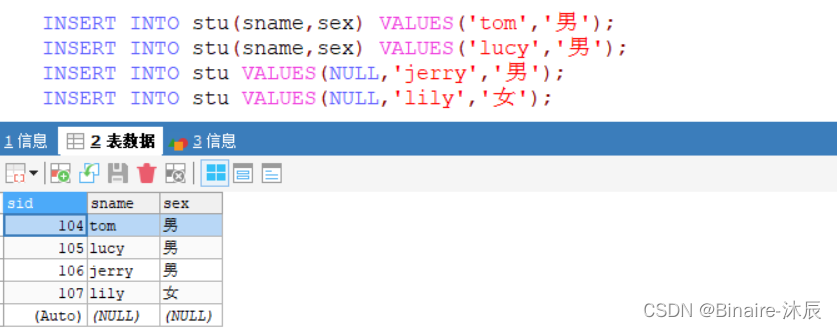
DELETE 和 TRUNCATE 对主键自增的影响
删除表中所有数据
- delete删除表中所有数据,将表中的数据逐条删除
- truncate 删除表中所有数据,先删除整张表,再创建一个结构相同的表
方式一: delete
- 删除表中所有数据
-- delete 方式删除表中所有数据
DELETE FROM stu; -- 删除对自增没有影响
- 插入数据,观察主键
INSERT INTO stu(sname,sex) VALUES('tom','男');
INSERT INTO stu(sname,sex) VALUES('lucy','男');
INSERT INTO stu VALUES(NULL,'jerry','男');
INSERT INTO stu VALUES(NULL,'lily','女');
方式二: truncate
-- truncate 方式删除表中所有数据
TRUNCATE TABLE stu;
-- 自增从 1 开始
非空约束
数据表中的某一列不能为空
语法格式: 字段名 字段类型 not null
- 创建一个emp表,给ename添加非空约束
CREATE TABLE emp(
eid INT PRIMARY KEY,
-- 这里是指名字不能为空
ename VARCHAR(20) NOT NULL,
sex CHAR(1)
);
- 测试
INSERT INTO emp VALUES(1,'jerry','男');
-- 插入成功
INSERT INTO emp VALUES(2,NULL,'女');
-- Column 'ename' cannot be null 名字不能为空
唯一约束
表中的某一列不能够重复(对null值 不做唯一判断)
语法格式: 字段名 字段类型 unique
- 创建一张表,设置给ename添加唯一约束
CREATE TABLE emp2(
eid INT PRIMARY KEY,
-- 这里是指名字唯一,不能重复
ename VARCHAR(20) UNIQUE,
sex CHAR(1)
);
- 测试
INSERT INTO emp2 VALUES(1,'jerry','男');
-- 插入成功
INSERT INTO emp2 VALUES(2,'jerry','女');
-- Duplicate entry 'jerry' for key 'emp2.ename' 名字重复,插入失败
主键约束和唯一约束的区别
- 主键约束,唯一且不能为空
- 唯一约束,唯一但可以为空
- 一个表中只能有一个主键,但可以有多个唯一约束
外键约束
空
默认值
用来指定某一列的默认值
语法格式: 字段名 字段类型 default 默认值
- 创建emp表,给sex添加默认值为’男’
CREATE TABLE emp1(
eid INT PRIMARY KEY,
ename VARCHAR(20),
sex CHAR(1) DEFAULT '男'
);
- 测试
-- 添加数据,使用默认值
INSERT INTO emp1(eid,ename) VALUES(1,'tom'); -- 插入成功
-- 不使用默认值
INSERT INTO emp1(eid,ename,sex) VALUES(2,'jerry','女'); -- 插入成功