在数据库使用过程中经常会遇到一些场景:
- 业务写流量一直相对比较稳定,但随着时间,数据不断增加,数据库的压力也会越来越大,写操作会影响到读请求的性能,做任何优化可能都达不到最终的效果;
- 在应用的用户访问量比较低的时候,一个数据库的读写能力是完全能够胜任的。但是在用户访问量增大的时候,数据库很快会成为瓶颈;
针对这种写少读多的业务可以考虑通过添加数据库节点来使其达到提升性能的目的,但添加节点,往往涉及到数据的搬迁,扩容周期比较长,很难应对徒增的业务流量。这个时候可以考虑采用读写分离的方式,将读写流量做分流,减轻主实例的压力,同时利用只读库横向的扩展能力,快速提升读性能。
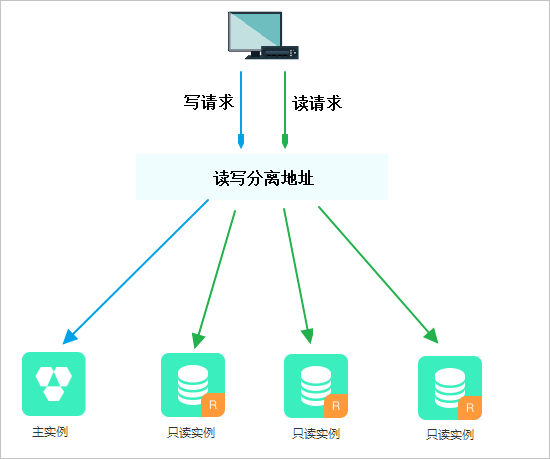
其基本原理是让主数据库处理事务性查询,而从数据库处理select查询。当业务量非常大时,一台服务器的性能无法满足需求,就可以读写分离方式分摊负载,避免因负载太高而造成无法及时响应请求。目前业界实现读写分离的方案主要有两种:
基于程序代码内部实现
在代码中根据select,insert进行路由分类,这类方法也是目前生产环境应用最广泛的,优点是性能好,因为在程序代码中已经将读写的数据源拆分至两个,所以不需要额外的MySQL proxy解析SQL报文,在进行路由至不同数据库节点。缺点是通常该架构较复杂,运维成本相对较高。
基于中间Proxy(odp/mycat等)实现
Proxy一般位于客户端和服务器之间,代理服务器接到客户端请求后通过解析SQL文本再将SQL路由至可用的数据库节点中。优点是程序不需要改造可以实现无缝迁移,可移植性较好。缺点是性能相对前者略微逊色一些,并且并不是所有的读操作都能够被路由至从节点中。
上述方案都不能算是透明的,要不需要对业务代码进行改造,要不需要业务系统依然第三方组件;除此之外,业界主流的读写方案都无法做到一致性读,应用在使用弱一致性读时,要充分考虑主备副本的数据同步延时,并根据具体业务场景考虑延时的业务影响(脏读)是否能够接受。读写分离业务都还需要做额外的改造,以应对只读库异常或者延迟过大的时候下,对业务做降级处理。
为此,PolarDB-X内核侧提出一种提供了透明的强一致的读写分离能力,支持多种读写分离策略满足各类业务需求。
PolarDB-X Native 读写分离
PolarDB-X配置了多种读写策略,提供了透明的强一致的读写分离能力。简单的说其特点有:
- 无论什么状况都不用担心误写了“备副本或只读副本”,因为它不支持写,写操作会被路由到主副本;
- 无论什么时候不用担心“备副本或只读副本”故障,因为它会自动路由给其他正常的副本或者切回主副本;
- 无论什么场景不用担心 “备副本或只读副本”读不到最新的数据,因为它提供的是强一致的读写能力;
- 大查询不用担心打爆“主副本”,因为它支持将大查询路由给”备副本或只读副本“,避免对主副本造成压力。
其整体的方案设计如下:

PolarDB-X存储节点基于X-Paxos复制协议,整合了binary log,实现了统一的consensus log。consensus log不仅扮演了binary log的角色,同时还维护了LogIndex(全局一致性日志位点)。LogIndex中记录了主库了最新修改consensus log位点信息,当只读库做一致性复制的时候,也会不断更新自身的LogIndex信息。通过LogIndex我们可以确保在只读库上读到最新的数据,结合TSO可以确保读到已提交的一致性数据。路由到只读节点的强一致性读查询过程如下:
- 客户端把请求发送到CN;
- CN识别到请求会发送给只读实例,首先会从主实例DN节点获取当前最大LogIndex;
- CN把LogIndex +TSO 请求一起发送给只读节点;
- 只读节点根据接收到的LogIndex判断是否等到只读节点事务状态回放到相应位点;根据TSO判断数据可见性,给CN返回结果。
同时为了降低每次一次只读查询都会分别与主库交互获取LogIndex,我们为此做了异步Grouping Fetch Logindex优化,在高并发下尽可能将多次Fetch Logindex整合成一次请求,大大降低对主库的压力。
读写分离的操作管理
业务上不需要做任何改造,在需要的时候购买只读实例,默认情况下主实例就具备了读写分离的能力。如果要开启,需要在阿里控制台点击主实例上的集群地址-》配置管理。

会进入下只读分离的配置管理页面
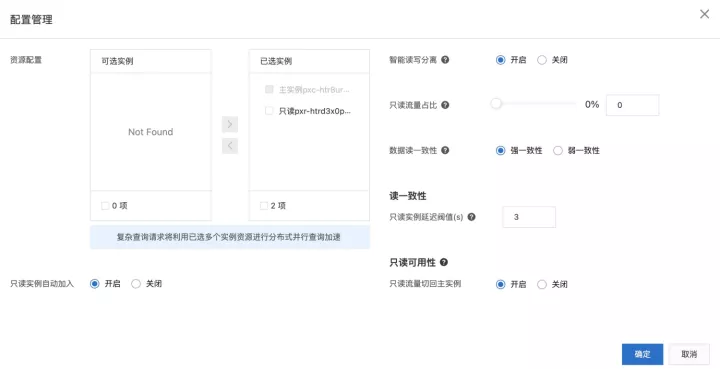
| 操作 | 解释 |
| 资源配置 | 选择购买的只读实例加入到读写分离集群,只有在读写分离集群的实例才可以分担主实例的流量 |
| 智能读写分离 | 基于统计信息做代价估算,将偏AP的复杂查询路由给只读实例做MPP加速。非混合负载场景,可以选择关闭 |
| 只读流量占比 | 将只读流量设置按一定的比例路由给只读实例 |
| 数据一致性 | 强一致性: 路由到只读实例的请求可以读到已提交最新鲜的数据,但如果只读实例延迟大的话,路由到只读实例弱一致性: 路由到只读实例的请求只是读到实例上可见的最新数据。 |
| 只读实例延迟阀值 | 只读实例延迟超过阈值,那么流量会打到其他延迟正常的只读实例上或者切回主实例。 |
| 只读可用性 | 当只读实例延迟超过阈值或者只读实例 HA时,则认为当前只读实例处于不可用的状态,流量自动切回主实例或者其他正常的只读实例上去。 |
用户真正在使用的时候,业务上完全不需要改造任何代码,一般只需要调整只读流量占比,调整为0意味着流量全部路由给主库;调整成>0,只读流量将按照设置的比例自动分流给只读实例。在这个基础上结合只读实例延迟阀值和只读可用性,可以做到在只读实例异常状态下,流量自动切回主实例或者其他正常的只读实例上去。除了数据库级别的配置,PolarDB-X也支持session级别和query级别的读写配置,可灵活控制某个session下只读查询或者某个具体query的路由分发。
读写分离的可用性测试
为了衡量PolarDB-X 读写分离能力的可用性,我们利用sysbench 从正确性 性能角度设计了三种实验场景来验证。
测试环境
- 测试所用实例规格
主实例规格2*16C128G (CN)+2*4C32G(DN), 2个只读实例规格 2*4C32G(CN) + 2*4C 32G(DN)
- 测试所用压力机规格
ecs.g7ne.8xlarge(24 vCPU,48 GB内存)
测试参数配置
- 修改参数ENABLE_COROUTINE的值为true,XPROTO_MAX_DN_CONCURRENT的值为4000,详细操作步骤请参见参数设置。
- 通过命令行连接到PolarDB-X实例,在同一会话内执行如下SQL语句,关闭日志记录与CPU采样统计:
set ENABLE_SET_GLOBAL = true;
set global RECORD_SQL = false;
set global MPP_METRIC_LEVEL = 0;
set global ENABLE_CPU_PROFILE = false;
测试数据准备
nohup sysbench --config-file='sysb.conf' --create-table-options='partition by key(id)' --tables='16' --threads='16' --table-size='10000000' oltp_point_select prepare &
实验一:一致性读的正确性
从附件中下载这次测试的oltp_insert_read_verify.lua脚本,该脚本逻辑比较简单,就是在主实例插入一条数据,测试在不同并发下在一致性读开启和关闭条件下,是否可以正确读到。一次实验的执行流程如下:
#准备表
sysbench --config-file='sysb.conf' --db-ps-mode='disable' --skip-trx='on' --mysql-ignore-errors='all' --tables='8' --threads={并发度} --time=60 oltp_insert_read_verify prepare
#运行
sysbench --config-file='sysb.conf' --db-ps-mode='disable' --skip-trx='on' --mysql-ignore-errors='all' --tables='8' --threads={并发度} --time=60 oltp_insert_read_verify run
#清理
sysbench --config-file='sysb.conf' --db-ps-mode='disable' --skip-trx='on' --mysql-ignore-errors='all' --tables='8' --threads={并发度} --time=60 oltp_insert_read_verify cleanup
测试结果
| 并发 | 不一致性次数(弱一致性读) | 不一致性次数(强一致性读) |
| 4 | 2 | 0 |
| 8 | 5 | 0 |
| 16 | 16 | 0 |
| 32 | 33 | 0 |
| 64 | 57 | 0 |
从测试结果看,强一致性读下,可以保证路由到只读实例的流量读到最新的数据;而非强一致性读下,无法保证。
实验二:高并发下吞吐表现
我们分别利用oltp_point_select和oltp_read_only两个脚本,测试了下在当前规格下高并发下的性能数据。
- 点查场景
sysbench --config-file='sysb.conf' --db-ps-mode='disable' --skip-trx='on' --mysql-ignore-errors='all' --tables='16' --table-size='10000000' --threads=512 oltp_point_select run
测试了在不同只读实例个数,不同配置下的性能数据,其QPS表现如下
| 只读实例查询占比 | 主实例+一个只读实例(强一致性) | 主实例+一个只读实例(弱一致性) | 主实例+两个只读实例(强一致性) | 主实例+两个只读实例(弱一致性) |
| 0% | 88201.17 | 88201.17 | 88201.17 | 88201.17 |
| 50% | 124269.63 | 171935.56 | 171783.84 | 208648.34 |
| 100% | 62891.86 | 89213.13 | 117133.83 | 169352.07 |
- oltp_read场景
sysbench --config-file='sysb.conf' --db-ps-mode='disable' --skip-trx='on' --mysql-ignore-errors='all' --tables='16' --table-size='10000000' --range-size=5 --threads=512 oltp_read_only run
测试了在不同只读实例个数,不同配置下的性能数据,其QPS表现如下
| 只读实例查询占比 | 主实例+一个只读实例(强一致) | 主实例+一个只读实例(弱一致) | 主实例+两个只读实例(强一致) | 主实例+两个只读实例(弱一致) |
| 0% | 29145.43 | 29145.43 | 29145.43 | 29145.43 |
| 50% | 44084.40 | 55399.80 | 61698.85 | 73161.11 |
| 100% | 23115.23 | 29235.73 | 42160.54 | 56393.54 |
从测试结果看:
1. 在强一致性读下,在TP读场景下流量从主实例切换到只读实例上吞吐的性能衰减20~30%,但是通过添加只读实例个数,性能可以做到一定的线性增加;
2.在弱一致性读下,在TP读场景下流量从主实例切换到只读实例上吞吐的性能未衰减,且通过添加只读实例的个数,性能可以做到线性增加;
实验三:低并发下RT表现
同样的我们分别利用oltp_point_select和oltp_read_only两个脚本,测试了下在(一个主实例+只读实例)下在强一致性读条件下,不同并发的RT表现
- 点查场景(ms)
| 并发 | 只读查询比例0% | 只读查询比例100% | 只读查询比例50% |
| 4 | 0.61 | 0.89 | 0.87 |
| 8 | 0.62 | 0.91 | 0.89 |
| 16 | 0.64 | 0.94 | 0.90 |
| 32 | 0.71 | 1.04 | 0.99 |
| 64 | 1.18 | 1.27 | 1.27 |
- oltp_read场景(ms)
| 并发 | 只读查询比例0% | 只读查询比例100% | 只读查询比例50% |
| 4 | 11.65 | 21.89 | 17.63 |
| 8 | 12.21 | 22.69 | 17.29 |
| 16 | 14.21 | 23.95 | 18.23 |
| 32 | 20 | 27.17 | 21.50 |
| 64 | 40.5 | 50.7 | 31.37 |
从测试结果看:
- 低并发场景下,只读实例和主实例压力都不大,流量从主实例切换到只读实例上,RT衰减近30%~40%, 但都是在业务可以接受的RT范围内抖动;
- 随着并发增加,流量从主实例切换到只读实例上RT衰减会变得不明显,主实例的资源会成为影响RT的主要因素。
本文的读写分离路由的是非事务下的只读流量,这里给大家提一个问题:事务下的读查询是否可以做读写分离?
本文为阿里云原创内容,未经允许不得转载。