Linux内核源码分析《进程管理》
前言
本文简单介绍些关于进程管理相关的知识
本专栏知识点是通过零声教育的线上课学习,进行梳理总结写下文章,对c/c++linux课程感兴趣的读者,可以点击链接 C/C++后台高级服务器课程介绍 详细查看课程的服务。
1. Linux 内核源码分析架构
linux内核并不是孤立,要把它放到整个系统中去研究更容易理解,如下图所示内核在操作系统中的位置。最上面是用户层,通过系统调用接口进入内核空间层,最下面是硬件设备这一层。
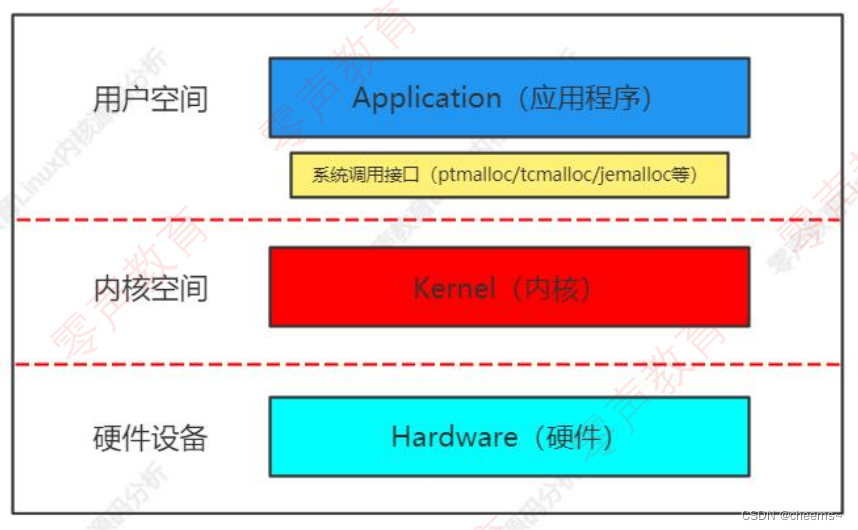
Linux内核主要有五大核心模块:进程调度、内存管理、网络协议栈、文件系统、进程间通信

下图是Linux内核源码目录组织结构

2. 进程原理分析
2.1 进程基础知识
Linux 内核把进程称为任务(task),进程的虚拟地址空间分为用户虚拟地址空间3G和内核虚拟地址空间1G。所有进程共享内核虚拟地址空间,每个进程有独立的用户空间虚拟地址空间。
所有进程有两种特殊形式:没有用户虚拟地址空间的进程称为内核线程,共享用户虚拟地址空间的进程称为用户线程。
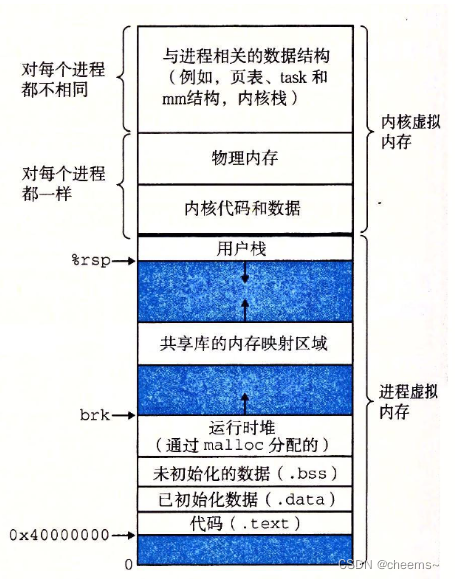
通用在不会引起混淆的情况下把用户线程简称为线程。共享同一个用户虚拟地址空间的所有用户线程组成一个线程组。
| C 标准库的进程专业术语 | Linux 内核的进程专业术语 |
|---|---|
| 包含多个线程的进程 | 线程组 |
| 只有一个线程的进程 | 进程或任务 |
| 线程 | 共享用户虚拟地址空间的进程 |
2.2 Linux进程四要素
- 有一段程序供其执行
- 有进程专用的系统堆栈空间
- 在内核有 task_struct 数据结构来描述进程
- 有独立的存储空间,拥有专有的用户空间
如果只具备前三条而缺少第四条,则称为“线程”。如果完全没有用户空间,就称为“内核线程”。而如果共享用户虚拟地址空间就称为“用户线程”。
内核为每个进程分配一个task_struct结构体,实际分配两个连续的物理页面(8192字节)。task_struct结构体的大小约占1KB左右,进程的系统空间堆栈大小约为7KB字节(不能扩展,静态确定的)
2.3 进程描述符 task_struct 数据结构主要成员内核源码分析
struct task_struct结构非常大,下面介绍比较常用的字段
struct task_struct {//进程描述符
/* -1 unrunnable, 0 runnable, >0 stopped: */
volatile long state;//表示进程的状态
void *stack;//通过该指针指向内核栈
pid_t pid;//全局的进程号
pid_t tgid;//全局的线程组标识符
struct hlist_node pid_links[PIDTYPE_MAX];//进程号,进程组标识符,会话标识符
/* Real parent process: */
struct task_struct __rcu *real_parent;//指向真实的父进程
/* Recipient of SIGCHLD, wait4() reports: */
//如果进程被另一个进程系统调用ptrace跟踪,那么parent指向跟踪进程。否则和real_parent相同
struct task_struct __rcu *parent;//指向父进程
struct task_struct *group_leader;//指向线程组的组长
//下面四个是调度策略和优先级所使用的成员
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
//对于普通的用户进程来说mm字段指向他的虚拟地址空间的用户空间部分,对于内核线程来说这部分为NULL。
struct mm_struct *mm;//指向内存描述符
//mm和active_mm都指向同一个内存描述符。
//当现在是内核线程时:active_mm从别的用户进程“借用”用户空间部分(内存描述符)-->惰性TLB
struct mm_struct *active_mm;
/* Filesystem information: */
struct fs_struct *fs;//文件系统
/* Open file information: */
struct files_struct *files;//打开文件列表
/* Namespaces: */
struct nsproxy *nsproxy;//命名空间
2.4 创建新进程分析
在 Linux 内核中,新进程是从一个已经存在的进程复制出来的,内核使用静态数据结构造出 0 号内核线程,0 号内核线程分叉生成 1 号内核线程和 2 号内核线程(kthreadd 线程)。1 号内核线程完成初始化以后装载用户程序,变成1 号进程,其他进程都是1号进程或者它的子孙进程分叉生成的;其他内核线程是kthreadd线程分叉生成的。
Linux 3 个系统调用创建新的进程:
- fork(分叉):子进程是父进程的一个副本,采用写时复制技术
vfork:用于创建子进程,之后子进程立即调用execve以装载新程序的情况,为了避免复制物理页,父进程会睡眠等待子进程装载新程序。现在 fork 采用了写时复制技术,vfork 失去了速度优势,已经被废弃。- clone(克隆):
可以精确地控制子进程和父进程共享哪些资源。这个系统调用的主要用处是可供pthread 库用来创建线程。clone 是功能最齐全的函数,参数多使用复杂,fork 是clone的简化函数。
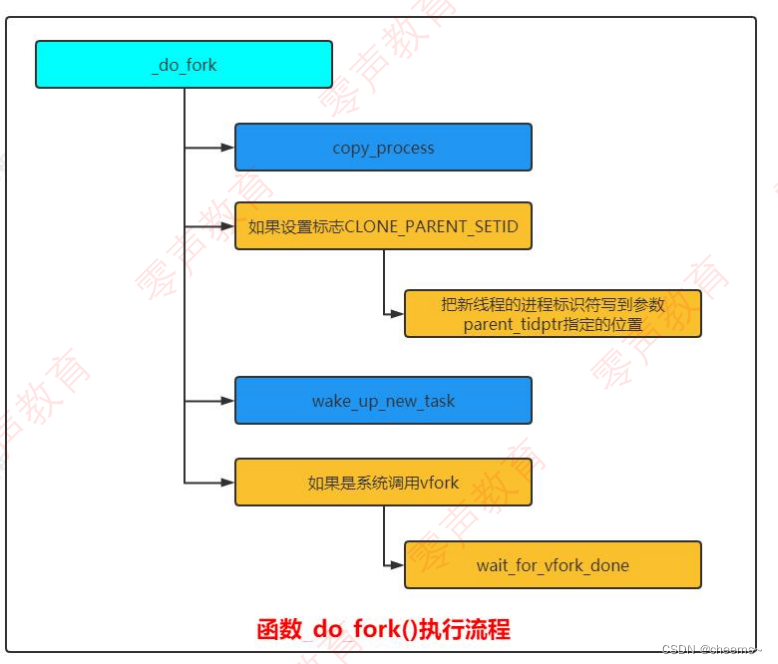
可以看到fork和clone最终调用的都是_do_fork,所以说fork 是clone的简化版
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU//内存管理单元
return _do_fork(SIGCHLD, 0, 0, NULL, NULL, 0);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}
#ifdef __ARCH_WANT_SYS_CLONE
#ifdef CONFIG_CLONE_BACKWARDS
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
unsigned long, tls,
int __user *, child_tidptr)
#elif defined(CONFIG_CLONE_BACKWARDS2)
SYSCALL_DEFINE5(clone, unsigned long, newsp, unsigned long, clone_flags,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
#elif defined(CONFIG_CLONE_BACKWARDS3)
SYSCALL_DEFINE6(clone, unsigned long, clone_flags, unsigned long, newsp,
int, stack_size,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
#else
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
#endif
{
return _do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr, tls);
}
#endif
Linux 内核定义系统调用的独特方式,目前以系统调用fork 为例:创建新进程的 3 个系统调用在文件"kernel/fork.c"中,它们把工作委托给函数_do_fork。具体源码分析如下:
/*
* Ok, this is the main fork-routine.
*
* It copies the process, and if successful kick-starts
* it and waits for it to finish using the VM if required.
*/
long _do_fork(unsigned long clone_flags,//克隆标志 最低字节表示退出时是否向父进程发送信号
unsigned long stack_start,//只有创建线程的时候才有意义,指定新线程用户栈的新地址起始位置
unsigned long stack_size,//只有创建线程的时候才有意义,指定新线程用户栈的大小
int __user *parent_tidptr,//只有创建线程才有意义,新线程保存自己进程标识符的位置
int __user *child_tidptr,
unsigned long tls)
{
struct completion vfork;
struct pid *pid;
struct task_struct *p;
int trace = 0;
long nr;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls, NUMA_NO_NODE);
add_latent_entropy();
if (IS_ERR(p))
return PTR_ERR(p);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
return nr;
}
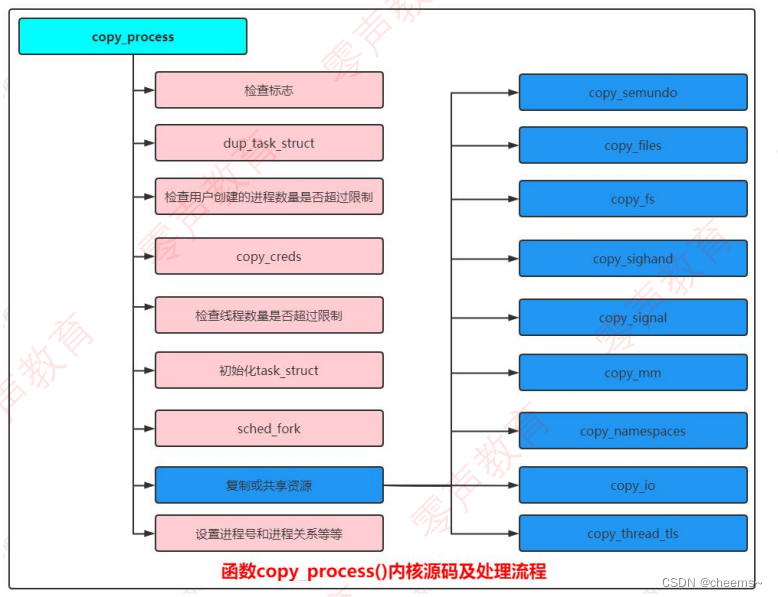
具体核心处理函数为 copy_process,创建新进程的主要工作由此函数完成,具体处理流程如下图所示:
同一个线程组的所有线程必须属于相同的用户命名空间和进程号命名空间。(ps这里想到了之前写的docker核心技术之一,namespace)
3. 剖析进程状态迁移
进程主要有 7 种状态:就绪状态、运行状态、轻度睡眠、中度睡眠、深度睡眠、僵尸状态、死亡状态,它们之间状态变迁如下:

这里的状态就对应着task_struct->state字段
- 就绪状态:TASK_RUNNING,等待调度器调度进程进行运行,这也反应了linux内核并没有严格区分就绪和运行状态。
- 运行状态:TASK_RUNNING,一旦被调度了,说明该进程现在就在CPU上面运行了。
- 轻度睡眠状态:TASK_INTERRUPTIBLE,轻度睡眠进程可以被信号打断
- 中度睡眠状态:TASK_KILLABLE,中度睡眠进程只能被致命的信号打断
- 深度睡眠状态:TASK_UNINTERRUPTIBLE,深度睡眠进程不可被打断
- 僵尸状态:TASK_DEAD,就是死状态,如果父进程关注子进程退出事件,那么子进程退出时会发SIGCHLD信号通知父进程。如果父进程不关注,则会进入EXIT_ZOMBIE
- 死亡状态:TASK_DEAD,父进程回收了子进程之后,会进入EXIT_DEAD状态
4. 内核调度策略优先级
4.1 Linux 内核支持调度策略
限期进程:限期调度策略(SCHED_DEADLINE)
实时进程支持三种调度策略:先进先出调度(SCHED_FIFO)、轮流调度(SCHED_RR)
普通进程支持两种调度策略:标准轮流分时(SCHED_NORMAL,使用cfs算法)和
批量调度策略( SCHED_BATCH)调度普通的非实时进程。空闲(SCHED_IDLE)则在系统空闲时调用idle 进程。一般是优先级比较低的后台作业
在Linux内核里面引入完全公平调度算法CFS之后,批量调度策略基本上就被废除了。
限期调度策略必须有 3 个参数:运行时间runtime、截止期限deadline、周期 period。每一个周期运行一次,在截止期限之前执行完,一次运行的时间长度是 runtime。
标准轮流分时策略使用完全公平调度算法CFS(把处理器时间公平地分配给每个进程)。
4.2 进程优先级
- 限期进程的优先级比实时进程高,实时进程的优先级比普通进程高
- 限制进程的优先级是-1
- 实时进程的实时优先级是 1-99,优先级数值越大,表示优先级越高
- 普通进程的静态优先级是 100-139,优先级数值越小,表示优先级越高,可通过修改 nice 值改变普通进程的优先级,优先级等于120 加上 nice 值
在 task_struct 结构体中,4 个和优先级有关的成员如下:
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
//此处省略创建内核线程打印nice和优先级的代码演示
5. 写时复制技术
写时复制核心思想:只有在不得不复制数据内容时才去复制数据内容。
申请新进程时:
- 申请一个pcb进程控制块
- 为新进程分配系统资源
- 子进程复制父进程的堆段等用户空间的所有信息
- 初始化pcb,使用父进程的pcb来初始化,除了一些特殊信息,其他几乎都是一样的
- 将新进程插入就绪队列
- 等待调度器调度
内核为新生成的子进程创建虚拟空间,但这只是复制父进程虚拟空间的结构,不为其分配真正的物理内存。它共享父进程的物理空间,当父进程有更改相应数据时,再为子进程分配其物理空间。所以说写时复制技术降低了进程对资源的浪费问题。
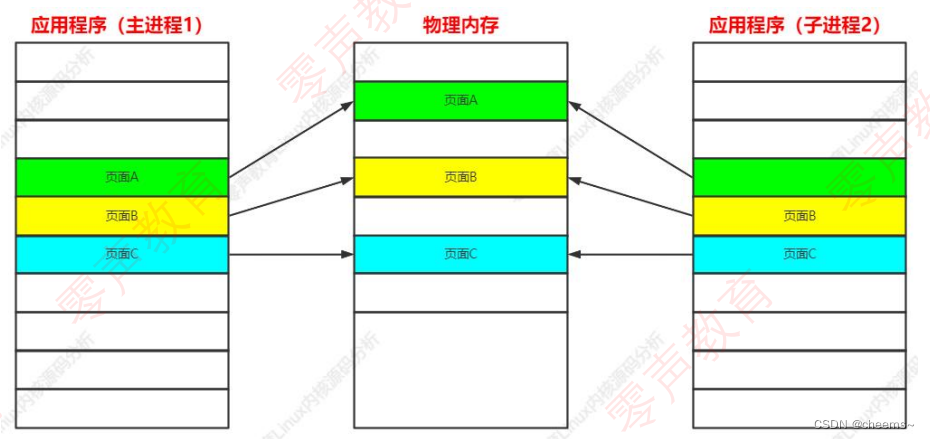
父子进程的用户虚拟空间对应的物理内存只有一份,属于共享,但是如果父子进程中的任何一个进程做了修改,那么就会在内存中拷贝一个副本,如何在这个副本上进行修改,修改完以合映射会进行修改的那个进程。
应用程序(进程 1)修改页面 C 之前:
应用程序(进程 1)修改页面 C 之后:
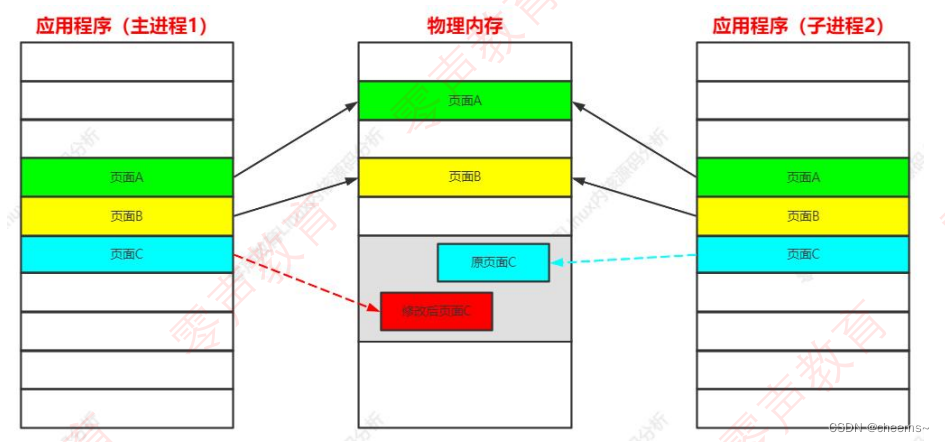
只有可修改的页面才需要标记为写时复制,不能修改的页面比如执行代码,可以由父进程和子进程共享。-------写时复制,读时共享
6. 调度器分析及系统调用实现
6.1 核心调度器
调度器的实现基于两个函数:周期性调度器函数和主调度器函数。这些函数根据现有进程的优先级分配CPU 时间。这也是为什么整个方法称之为优先调度的原因。
主调度器负责将 CPU 的使用权从一个进程切换到另一个进程。周期性调度器只是定时更新调度相关的统计信息。cfs 队列实际上是用红黑树组织的,rt 队列是用链表组织的。
6.1.1 周期性调度器函数
周期性调度器在 scheduler_tick 中实现,如果系统正在活动中,内核会按照频率 HZ 自动调用该函数。该函数主要有两个任务如下:
- 更新相关统计量:管理内核中与整个系统和各个进程的调度相关的统计量。期间执行的主要操作是对各种计数器加1。
- 激活负责当前进程的调度类的周期性调度方法。
/*
* This function gets called by the timer code, with HZ frequency.
* We call it with interrupts disabled.
*/
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
struct rq_flags rf;
sched_clock_tick();
rq_lock(rq, &rf);
update_rq_clock(rq);
curr->sched_class->task_tick(rq, curr, 0);
cpu_load_update_active(rq);
calc_global_load_tick(rq);
psi_task_tick(rq);
rq_unlock(rq, &rf);
perf_event_task_tick();
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq);
#endif
}
6.1.2 主调度器函数
在内核中的许多地方,如果要将 CPU 分配给与当前活动进程不同的另一个进程,这个时候都会直接调用主调度器函数(schedule)。
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
preempt_disable();
__schedule(false);
sched_preempt_enable_no_resched();
} while (need_resched());
}
EXPORT_SYMBOL(schedule);
6.2 调度类及运行队列
6.2.1 调度类
为 方 便 添 加 新 的 调 度 策 略 , Linux 内核抽象一个调度类sched_class,目前为止实现 5 种调度类:
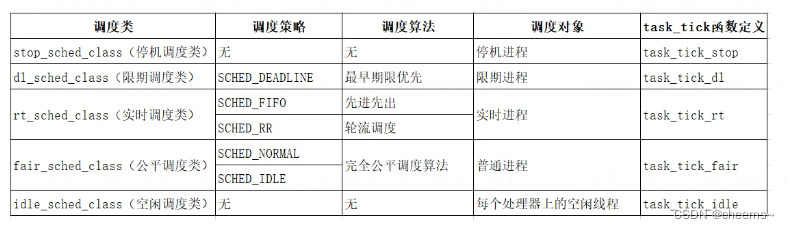
调度类优先级从高到低排序:停机调度类->限期调度类->实时调度类->公平调度类和空闲调度类。
公开调度类使用完全公平调度算法(引入虚拟运行时间这个东西)
虚拟运行时间=实际运行时间*nice0 对应的权重/进程的权重。
进程的时间片=(调度周期*进程的权重/运行队列中所有进程的权重之和)
CFS不详细解释了,执行百度
6.2.2 运行队列
每个处理器有一个运行队列,结构体是rq,定义的全局变量如下:

rq 是描述就绪队列,其设计是为每一个CPU都有一个就绪队列,本地进程在本地队列上排序。
6.2.3 调度进程
主动调度进程的函数是 schedule,它会把主要工作委托给__schedule()去处理
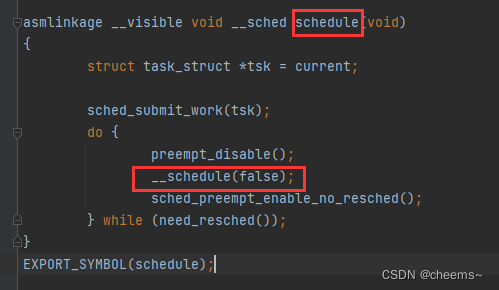
函数__shcedule 的主要处理过程如下:
- 调用
pick_next_task()以选择下一个进程 - 调用
context_switch()以切换进程
函数context_switch中:
- 切 换 用 户 虚 拟 地 址 空 间 , ARM64 架构使用默认的
switch_mm_irqs_off - 切 换 寄 存 器 , 宏 switch_to 把这项工作委托给函数
__switch_to
6.2.4 调度时机
调度进程的时机如下:
- 进程主动调用 schedule()函数。
- 周期性地调度,抢占当前进程,强迫当前进程让出处理器。
- 唤醒进程的时候,被唤醒的进程可能抢占当前进程。
- 创建新进程的时候,新进程可能抢占当前进程。
需要在编译内核时开启开启对内核抢占的支持
主动调度:
- 进程在用户模式下运行的时候,无法直接调用schedule()函数,只能通过系统调用进入内核模式,如果系统调用需要等待某个资源,如互斥锁或信号量,就会把进程的状态设置为睡眠状态,然后调用 schedule()函数来调度进程。
- 进程也可以通过系统调用 shced_yield()让出处理器,这种情况下进程不会睡眠。
- 在内核中有 3 种主动调度方式:直接调用 schedule()函数来调用进程;调用有条件重调度函数 cond_resched();如果需要等待某个资源。
//TODO 以下皆听不懂了
周期调度
- 有些“地痞流氓”进程不主动让出处理器,内核只能依靠周期性的时钟中断夺回处理器的控制权,时钟中断是调度器的脉博。时钟中断处理程序检查当前进程的执行时间有没有超过限额,如果超过限额,设置需要重新调度的标志。当时钟中断处理程序准备返点处理器还给被打断的进程时,如果被打断的进程在用户模式下运行,就检查有没有设置需要重新调度的标志,如果设置了,调用schedule 函数以调度进程。如果需要重新调度,就为当前进程的thread_info 结构体的成员 flags 设置需要重新调度的标志。
6.2.5 SMP 调度
//TODO 什么是SMP我都不知道,tmd,留着十年之后有机会再补吧