🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
时间序列数据捕获(通常)定期记录的一系列数据点。一些常见的例子包括每日天气温度、股票价格和公司的销售数量。
许多经典方法(例如 ARIMA)试图以不同的成功率处理时间序列数据(并不是说它们不擅长)。在过去的几年里,长短期记忆网络 (LSTM)模型在处理这些类型的数据时已经成为一种非常有用的方法。
循环神经网络(LSTM 是其中的一种)非常擅长处理数据序列。他们可以“回忆”过去(或未来)很远的数据中的模式。在本教程中,您将学习如何使用 LSTM 根据真实数据预测未来的冠状病毒病例。
新型冠状病毒 (COVID-19)
新型冠状病毒 (Covid-19) 已迅速在世界范围内传播。在撰写本文时,Worldometers.info表明有超过95,488超过84个国家的确诊病例。
受影响最严重的前 4 个(到目前为止)是中国(病毒的来源)、韩国、意大利和伊朗。不幸的是,由于以下原因,目前没有报告许多病例:
- 一个人甚至可以在不知不觉中被感染(无症状)
- 错误的数据报告
- 试剂盒不够
- 症状看起来很像普通流感
这种病毒有多危险?
除了您可能会在新闻中看到的常见统计数据外,还有一些好消息和一些坏消息:
- 80%以上确诊病例无需就医即可康复
- 截至 3 月 3 日,世界卫生组织 (WHO) 估计的死亡率为 3.4%
- 代表单个感染者将病毒传播给的平均人数的繁殖数在 1.4 到 2.5 之间(世卫组织在 1 月 23 日估计)
最后一个真的很吓人。如果没有采取适当的措施,听起来我们可以看到一些疯狂的指数增长。
# BASH
%reload_ext watermark
%watermark -v -p numpy,pandas,torch
CPython 3.6.9
IPython 5.5.0
numpy 1.17.5
pandas 0.25.3
torch 1.4.0让我们开始吧!
import torch
import os
import numpy as np
import pandas as pd
from tqdm import tqdm
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
from matplotlib import rc
from sklearn.preprocessing import MinMaxScaler
from pandas.plotting import register_matplotlib_converters
from torch import nn, optim
%matplotlib inline
%config InlineBackend.figure_format='retina'
sns.set(style='whitegrid', palette='muted', font_scale=1.2)
HAPPY_COLORS_PALETTE = ["#01BEFE", "#FFDD00", "#FF7D00", "#FF006D", "#93D30C", "#8F00FF"]
sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))
rcParams['figure.figsize'] = 14, 10
register_matplotlib_converters()
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
每日病例数据集
该数据由约翰霍普金斯大学系统科学与工程中心 (JHU CSSE) 提供,包含按国家/地区分列的每日报告病例数。该数据集在 GitHub 上可用,并定期更新。
我们将仅获取确诊病例的时间序列数据(也提供死亡人数和康复病例数):
# BASH
# !wget https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv或者您可以使用我在本教程中使用的相同数据集(数据快照来自 2020 年 3 月 3 日):
# BASh
!gdown --id 1AsfdLrGESCQnRW5rbMz56A1KBc3Fe5aV数据探索
让我们加载数据并看看:
df=PD.read_csv('time_series_19-covid-Confirmed.csv')这里需要注意两点:
- 数据包含省、国家、纬度和经度。我们不需要这些。
- 病例数是累积的。我们将撤消积累。
让我们从摆脱前四列开始:
df = df.iloc[:, 4:]让我们检查缺失值:
df.isnull().sum().sum()0
一切似乎都已到位。让我们对所有行求和,这样我们就得到了累积的每日病例:
daily_cases = df.sum(axis=0)
daily_cases.index = pd.to_datetime(daily_cases.index)
daily_cases.head()Output:
2020-01-22 555
2020-01-23 653
2020-01-24 941
2020-01-25 1434
2020-01-26 2118
dtype: int64plt.plot(daily_cases)
plt.title("Cumulative daily cases"); 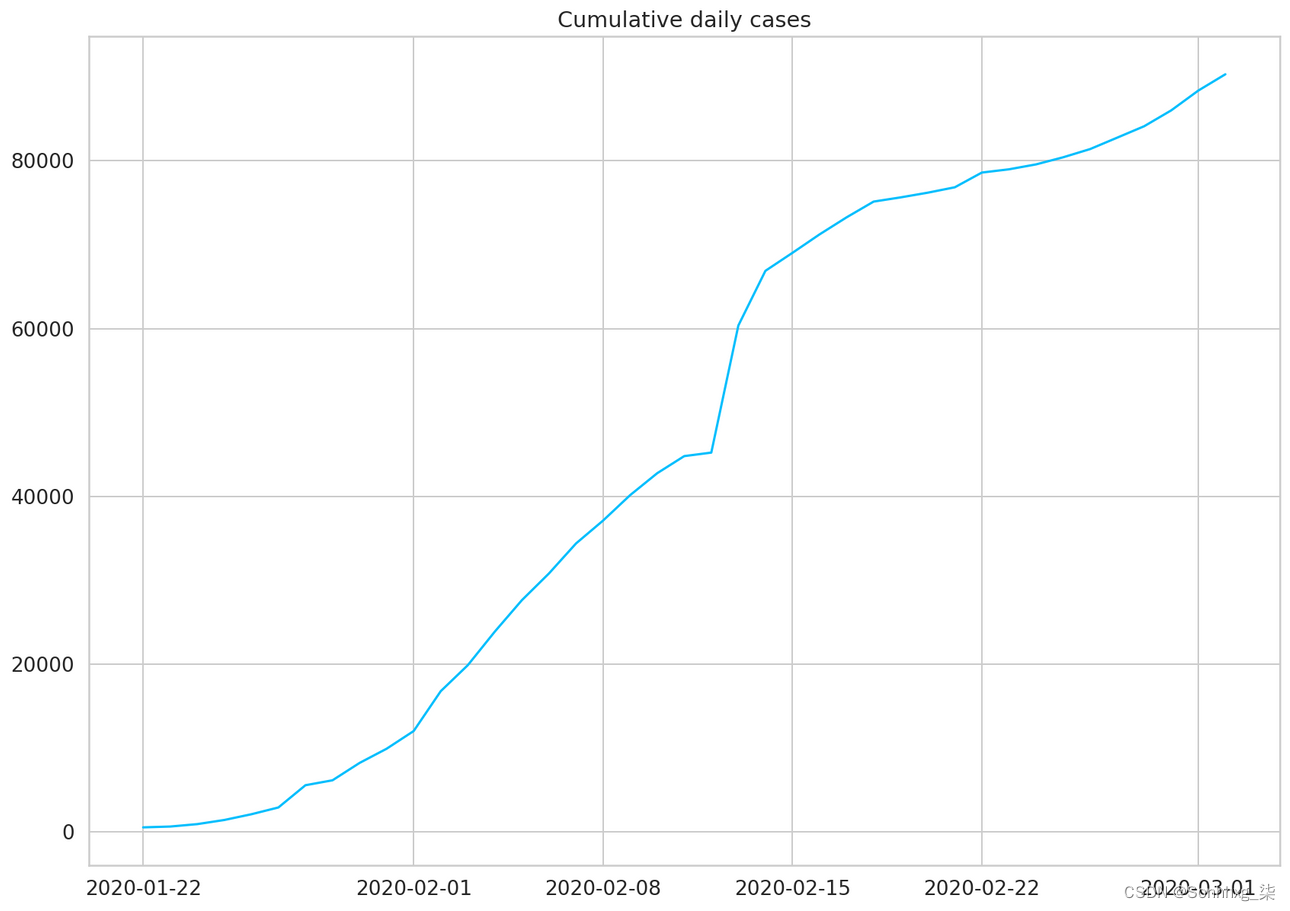
我们将通过从前一个值中减去当前值来撤消累积。我们将保留序列的第一个值:
daily_cases = daily_cases.diff().fillna(daily_cases[0]).astype(np.int64)
daily_cases.head()Output:
2020-01-22 555
2020-01-23 98
2020-01-24 288
2020-01-25 493
2020-01-26 684
dtype: int64plt.plot(daily_cases)
plt.title("Daily cases"); 
巨大的峰值(中间)主要是由于中国检测患者的标准发生了变化。这对我们的模型肯定是一个挑战。
巨大的峰值(中间)主要是由于中国检测患者的标准发生了变化。这对我们的模型肯定是一个挑战。
daily_cases.shape(41,)
不幸的是,我们只有 41 天的数据。让我们看看我们能用它做什么!
预处理
我们将保留前 27 天用于培训,其余用于测试:
test_data_size = 14
train_data = daily_cases[:-test_data_size]
test_data = daily_cases[-test_data_size:]
train_data.shape(27,)
如果我们想提高模型的训练速度和性能,我们必须缩放数据(值将在 0 和 1 之间)。我们将使用MinMaxScaler来自 scikit-learn 的:
scaler = MinMaxScaler()
scaler = scaler.fit(np.expand_dims(train_data, axis=1))
train_data = scaler.transform(np.expand_dims(train_data, axis=1))
test_data = scaler.transform(np.expand_dims(test_data, axis=1))目前,我们有大量的日常病例。我们将其转换为较小的:
def create_sequences(data, seq_length):
xs = []
ys = []
for i in range(len(data)-seq_length-1):
x = data[i:(i+seq_length)]
y = data[i+seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
seq_length = 5
X_train, y_train = create_sequences(train_data, seq_length)
X_test, y_test = create_sequences(test_data, seq_length)
X_train = torch.from_numpy(X_train).float()
y_train = torch.from_numpy(y_train).float()
X_test = torch.from_numpy(X_test).float()
y_test = torch.from_numpy(y_test).float()每个训练示例都包含一系列 5 个历史数据点和一个我们模型需要预测的真实值的标签。让我们深入了解:
X_train.shapetorch.Size([21, 5, 1])
X_train[:2]Outpur:
tensor([[[0.0304],
[0.0000],
[0.0126],
[0.0262],
[0.0389]],
[[0.0000],
[0.0126],
[0.0262],
[0.0389],
[0.0472]]])y_train.shapetorch.Size([21, 1])
y_train[:2]Output:
tensor([[0.0472],
[0.1696]])train_data[:10]Output:
array([[0.03036545],
[0. ],
[0.01262458],
[0.02624585],
[0.03893688],
[0.04724252],
[0.16963455],
[0.03255814],
[0.13089701],
[0.10598007]])建立模型
我们将把模型的复杂性封装到一个扩展自以下的类中torch.nn.Module:
class CoronaVirusPredictor(nn.Module):
def __init__(self, n_features, n_hidden, seq_len, n_layers=2):
super(CoronaVirusPredictor, self).__init__()
self.n_hidden = n_hidden
self.seq_len = seq_len
self.n_layers = n_layers
self.lstm = nn.LSTM(
input_size=n_features,
hidden_size=n_hidden,
num_layers=n_layers,
dropout=0.5
)
self.linear = nn.Linear(in_features=n_hidden, out_features=1)
def reset_hidden_state(self):
self.hidden = (
torch.zeros(self.n_layers, self.seq_len, self.n_hidden),
torch.zeros(self.n_layers, self.seq_len, self.n_hidden)
)
def forward(self, sequences):
lstm_out, self.hidden = self.lstm(
sequences.view(len(sequences), self.seq_len, -1),
self.hidden
)
last_time_step = \
lstm_out.view(self.seq_len, len(sequences), self.n_hidden)[-1]
y_pred = self.linear(last_time_step)
return y_pred我们CoronaVirusPredictor包含 3 种方法:
- 构造函数 - 初始化所有辅助数据并创建图层
reset_hidden_state- 我们将使用无状态 LSTM,因此我们需要在每个示例之后重置状态forward- 获取序列,一次将它们全部通过 LSTM 层。我们获取最后一个时间步的输出并将其传递给我们的线性层以获得预测。
训练
让我们构建一个辅助函数来训练我们的模型(稍后我们将重用它):
def train_model(model,train_data,train_labels,test_data=None,test_labels=None):
loss_fn = torch.nn.MSELoss(reduction='sum')
optimiser = torch.optim.Adam(model.parameters(), lr=1e-3)
num_epochs = 60
train_hist = np.zeros(num_epochs)
test_hist = np.zeros(num_epochs)
for t in range(num_epochs):
model.reset_hidden_state()
y_pred = model(X_train)
loss = loss_fn(y_pred.float(), y_train)
if test_data is not None:
with torch.no_grad():
y_test_pred = model(X_test)
test_loss = loss_fn(y_test_pred.float(), y_test)
test_hist[t] = test_loss.item()
if t % 10 == 0:
print(f'Epoch {t} train loss: {loss.item()} test loss: {test_loss.item()}')
elif t % 10 == 0:
print(f'Epoch {t} train loss: {loss.item()}')
train_hist[t] = loss.item()
optimiser.zero_grad()
loss.backward()
optimiser.step()
return model.eval(), train_hist, test_hist请注意,隐藏状态在每个 epoch 开始时重置。我们不使用我们的模型一次看到每个示例的批量数据。我们将使用均方误差来衡量我们的训练和测试误差。我们将两者都记录下来。
让我们创建一个模型实例并对其进行训练:
model = CoronaVirusPredictor(
n_features=1,
n_hidden=512,
seq_len=seq_length,
n_layers=2
)
model, train_hist, test_hist = train_model(
model,
X_train,
y_train,
X_test,
y_test
)Output:
Epoch 0 train loss: 1.6297188997268677 test loss: 0.041186608374118805
Epoch 10 train loss: 0.8466923832893372 test loss: 0.12416432797908783
Epoch 20 train loss: 0.8219934105873108 test loss: 0.1438201516866684
Epoch 30 train loss: 0.8200693726539612 test loss: 0.2190694659948349
Epoch 40 train loss: 0.810839056968689 test loss: 0.1797715127468109
Epoch 50 train loss: 0.795730471611023 test loss: 0.19855864346027374让我们看一下训练和测试损失:
plt.plot(train_hist, label="Training loss")
plt.plot(test_hist, label="Test loss")
plt.ylim((0, 5))
plt.legend();
我们模型的性能在 15 个 epoch 左右后没有提高。回想一下,我们的数据很少。也许我们不应该那么信任我们的模型?
预测每日病例
我们的模型(由于我们训练它的方式)只能预测未来的一天。我们将采用一个简单的策略来克服这个限制。使用预测值作为预测未来几天的输入:
with torch.no_grad():
test_seq = X_test[:1]
preds = []
for _ in range(len(X_test)):
y_test_pred = model(test_seq)
pred = torch.flatten(y_test_pred).item()
preds.append(pred)
new_seq = test_seq.numpy().flatten()
new_seq = np.append(new_seq, [pred])
new_seq = new_seq[1:]
test_seq = torch.as_tensor(new_seq).view(1, seq_length, 1).float()我们必须反转测试数据和模型预测的缩放比例:
true_cases = scaler.inverse_transform(
np.expand_dims(y_test.flatten().numpy(), axis=0)
).flatten()
predicted_cases = scaler.inverse_transform(
np.expand_dims(preds, axis=0)
).flatten()让我们看看结果:
plt.plot(
daily_cases.index[:len(train_data)],
scaler.inverse_transform(train_data).flatten(),
label='Historical Daily Cases'
)
plt.plot(
daily_cases.index[len(train_data):len(train_data) + len(true_cases)],
true_cases,
label='Real Daily Cases'
)
plt.plot(
daily_cases.index[len(train_data):len(train_data) + len(true_cases)],
predicted_cases,
label='Predicted Daily Cases'
)
plt.legend();
正如预期的那样,我们的模型表现不佳。也就是说,预测似乎在正确的范围内(可能是由于使用最后一个数据点作为下一个数据点的强预测因子)。
使用所有数据进行训练
现在,我们将使用所有可用数据来训练相同的模型:
scaler = MinMaxScaler()
scaler = scaler.fit(np.expand_dims(daily_cases, axis=1))
all_data = scaler.transform(np.expand_dims(daily_cases, axis=1))
all_data.shape(41, 1)
预处理和训练步骤相同:
X_all, y_all = create_sequences(all_data, seq_length)
X_all = torch.from_numpy(X_all).float()
y_all = torch.from_numpy(y_all).float()
model = CoronaVirusPredictor(
n_features=1,
n_hidden=512,
seq_len=seq_length,
n_layers=2
)
model, train_hist, _ = train_model(model, X_all, y_all)Output:
Epoch 0 train loss: 1.9441421031951904
Epoch 10 train loss: 0.8385428786277771
Epoch 20 train loss: 0.8256545066833496
Epoch 30 train loss: 0.8023681640625
Epoch 40 train loss: 0.8125611543655396
Epoch 50 train loss: 0.8225002884864807预测未来案例
我们将使用我们的“完全训练”模型来预测未来 12 天的确诊病例:
DAYS_TO_PREDICT = 12
with torch.no_grad():
test_seq = X_all[:1]
preds = []
for _ in range(DAYS_TO_PREDICT):
y_test_pred = model(test_seq)
pred = torch.flatten(y_test_pred).item()
preds.append(pred)
new_seq = test_seq.numpy().flatten()
new_seq = np.append(new_seq, [pred])
new_seq = new_seq[1:]
test_seq = torch.as_tensor(new_seq).view(1, seq_length, 1).float()和以前一样,我们将逆缩放器变换:
predicted_cases = scaler.inverse_transform(
np.expand_dims(preds, axis=0)
).flatten()要创建包含历史和预测案例的酷图表,我们需要扩展数据框的日期索引:
daily_cases.index[-1]Timestamp('2020-03-02 00:00:00')
predicted_index = pd.date_range(
start=daily_cases.index[-1],
periods=DAYS_TO_PREDICT + 1,
closed='right'
)
predicted_cases = pd.Series(
data=predicted_cases,
index=predicted_index
)
plt.plot(predicted_cases, label='Predicted Daily Cases')
plt.legend();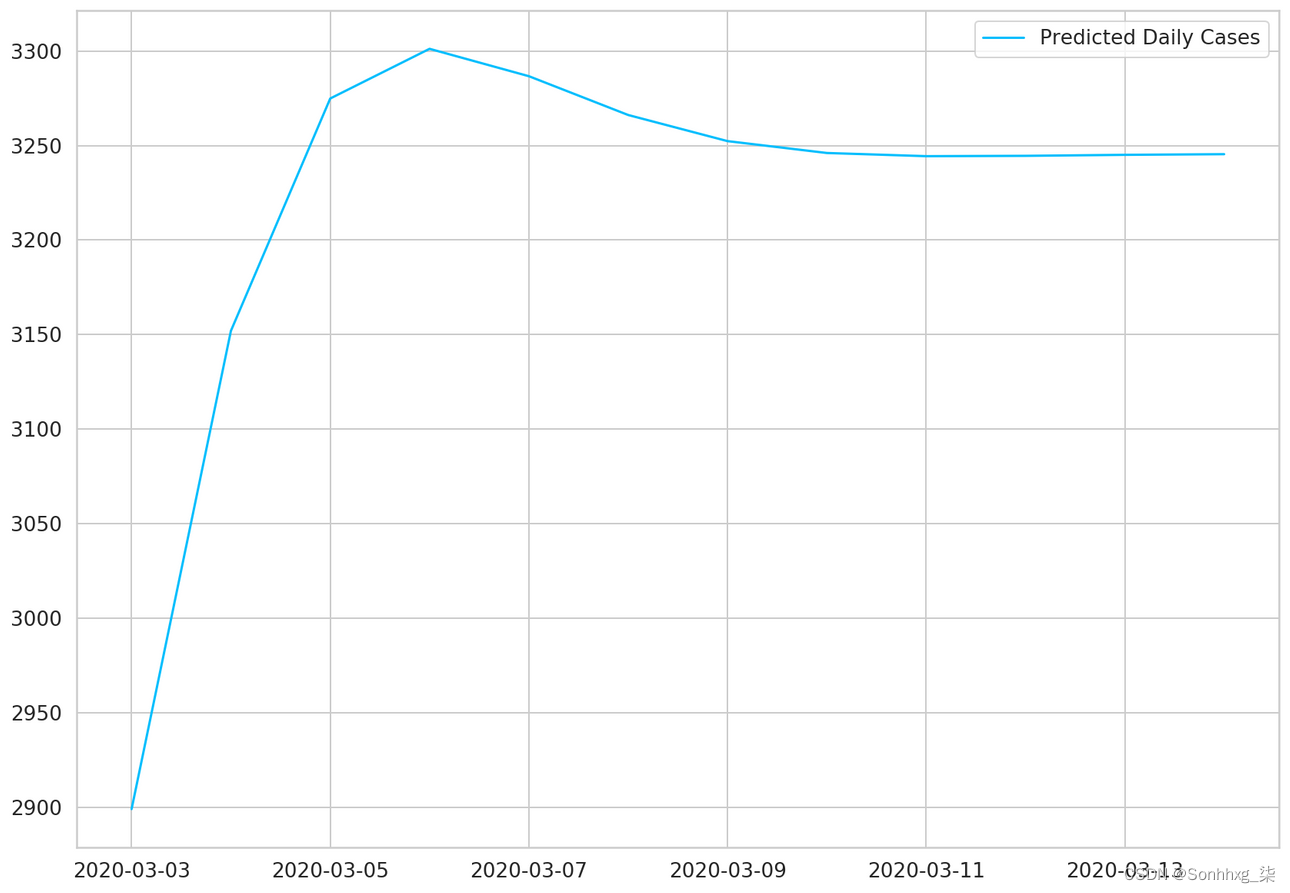
现在我们可以使用所有数据来绘制结果:
plt.plot(daily_cases, label='Historical Daily Cases')
plt.plot(predicted_cases, label='Predicted Daily Cases')
plt.legend();
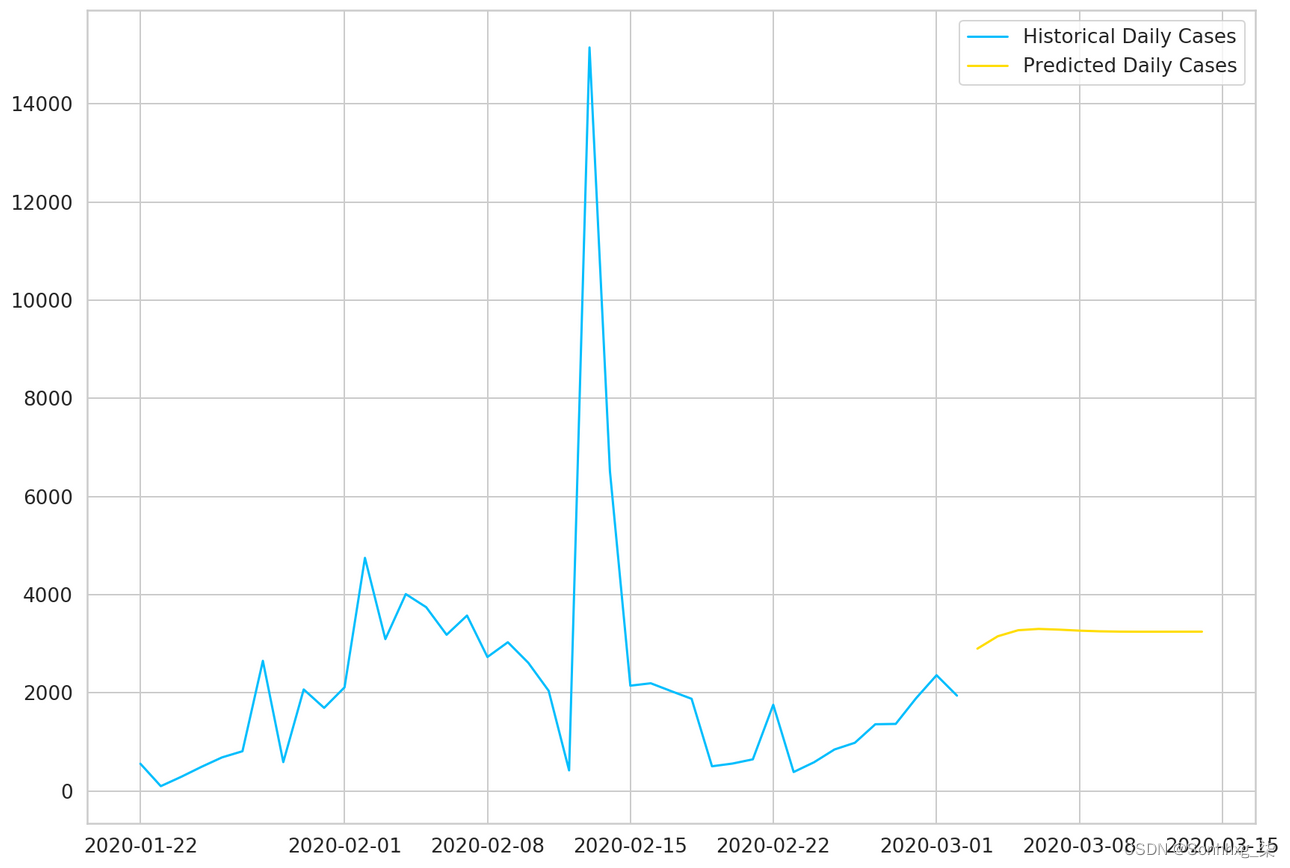
我们的模型认为事情会趋于平稳。请注意,您对未来的了解越多,您就越不应该相信您的模型预测。
结论
做得好!您学习了如何使用 PyTorch 创建一个处理时间序列数据的循环神经网络。模型性能不是很好,但这是意料之中的,因为数据量很少。
预测每日 Covid-19 病例是一个难题。我们正处于疫情爆发之中,还有更多工作要做。希望一段时间后一切都会恢复正常。