文章目录
一、资源推荐
(1)牛逼的huggingface:https://huggingface.co/transformers/preprocessing.html
后期学的几个transformer应用的具体栗子:
https://github.com/huggingface/transformers/tree/master/examples/pytorch
(2)读论文,如ACL会议论文:https://aclanthology.org/
(3)进击的BERT:https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html
(4)学习基础后,应该上手项目练习:常见26种NLP任务的练手项目
(5)datawhale的NLP开源项目:https://datawhalechina.github.io/learn-nlp-with-transformers
(6)NLP入门新手的项目nlp-tutorial,包括9400star:https://github.com/graykode/nlp-tutorial
大佬的笔记:
(1)很多NLP比赛的总结:https://github.com/km1994/nlp_paper_study
(2)知乎蝈蝈的NLP专栏:https://www.zhihu.com/column/pythontricks
(3)注意力机制总结
二、菜鸡笔记
【NLP】(task1)Transformers在NLP中的兴起 + 环境配置
- NLP任务主要划分为4个大类:文本分类;序列标注;问答任务——抽取式问答和多选问答;生成任务——语言模型、机器翻译和摘要生成
- 先根据paper《Attention Is All You Need》中的图对transformer有大概了解,其中MHA子网络就是之前在李宏毅深度学习课程中的多头注意力(【李宏毅深度学习CP10】Self-attention(part2):https://andyguo.blog.csdn.net/article/details/119577093),另外可以复习李宏毅老师讲的transformer
- transformer的编码器和解码器是基于自注意力的模块叠加而成的,源(输入)序列和目标(输出)序列的嵌入(embedding)表示将加上位置编码(positional encoding),再分别输入到编码器和解码器中
- 课程推荐:CS224n: Natural Language Processing with Deep Learning
书籍推荐:Speech and Language Processing
另外还有2文要补看:
NLP中的预训练+微调的训练方式推荐阅读:
2021年如何科学的“微调”预训练模型?
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
【NLP】(task2)图解attention+transformer(代码讲解)
- 本次学习先根据seq2seq任务特点,初始用的RNN,但为了解决RNN在两个相关性较大的时刻距离较远时,会产生较大的信息损失问题,即使引入LSTM能部分解决这种长距离依赖问题(治标不治本),所以提出transformer,补阅读Transformer 详解。
- 台大佬说的:看代码要分清自己的需求,这个代码是不用全部背诵或者默出来。你只需要看到transformer内部的各种变化,有印象就可了。实际用的时候不需要的,除非你需要改核心结构。搞清楚输入和输出以及核心部件的构造(这部分最好能默出来)。第三部分的将PyTorch实现Transformer库,相比于官方的版本,手写的这个少了较多的判定语句。
self-attention 的本质就是从一个矩阵生成三个新的矩阵,这三个矩阵分别记作 qkv,然后将 q 乘以 k 的转置,得到的结果再与 v 相乘,再将最后得到的结果送入下游任务。因此实际上任何网络都可以融入 self-attention,生成三个新矩阵的方式也很简单,只需要调用三次 nn.Linear ()。用什么矩阵来生成三个矩阵?随意,比方说 nlp 中可以用 word2vec 的输出来作为 “母矩阵”,通过三次 nn.linear () 将 “母矩阵” 生成三个 “子矩阵”。
- 回顾【李宏毅深度学习CP18-19】自监督学习之BERT和【李宏毅深度学习CP20】GPT3模型,后者GPT-3讲的比较少内容,而这次task3学习的主要是BERT和GPT-2,GPT2的链接:【NLP】(task3下)预训练语言模型——GPT-2。
- 三类NLP任务:语言模型、基础任务、应用任务:
- 基础任务:中文分词、词性标注、句法分析、语义分析等
- 应用任务:信息抽取、情感分析、问答系统、机器翻译、对话系统等
- 学习了GPT-2以及对其父模型(只有 Decoder 的 Transformer)和带mask的Self Attention。注意GPT的Predict Next Token的过程:GPT拿到一笔训练资料的时候,先给它BOS这个token,然后GPT output一个embedding,然后接下来,你用这个embedding去预测下一个应该出现的token是什么。
- 一般Few Shot的意思是说,确实只给了它一点例子。但是GPT里的不是一般的learning,这里面完全没有gradient descent;完全没有要去调GPT那个模型参数的意思,所以在GPT的文献里面,把这种训练给了一个特殊的名字——In-context Learning(代表说它不是一般的learning,它连gradient descent都没有做)
- GPT如何进行tokenize操作?和BERT的区别是什么?
GPT2使用Transformer的Decoder模块构建
工作方式(自回归):产生每个token;将token添加到输入的序列中,形成一个新序列;将上述新序列作为模型下一个时间步的输入。
【NLP】(task4)编写BERT模型
(1)回顾上次所学,GPT是采用传统的基于自回归的语言建模方法,而BERT是用了基于自编码(Auto-Encoding)的预训练任务进行训练。有些问题如transformer 为什么使用 layer normalization,而不是其他的归一化方法?、为什么 Transformer 需要进行 Multi-head Attention?等“相对开放”的问题需要进一步探究。
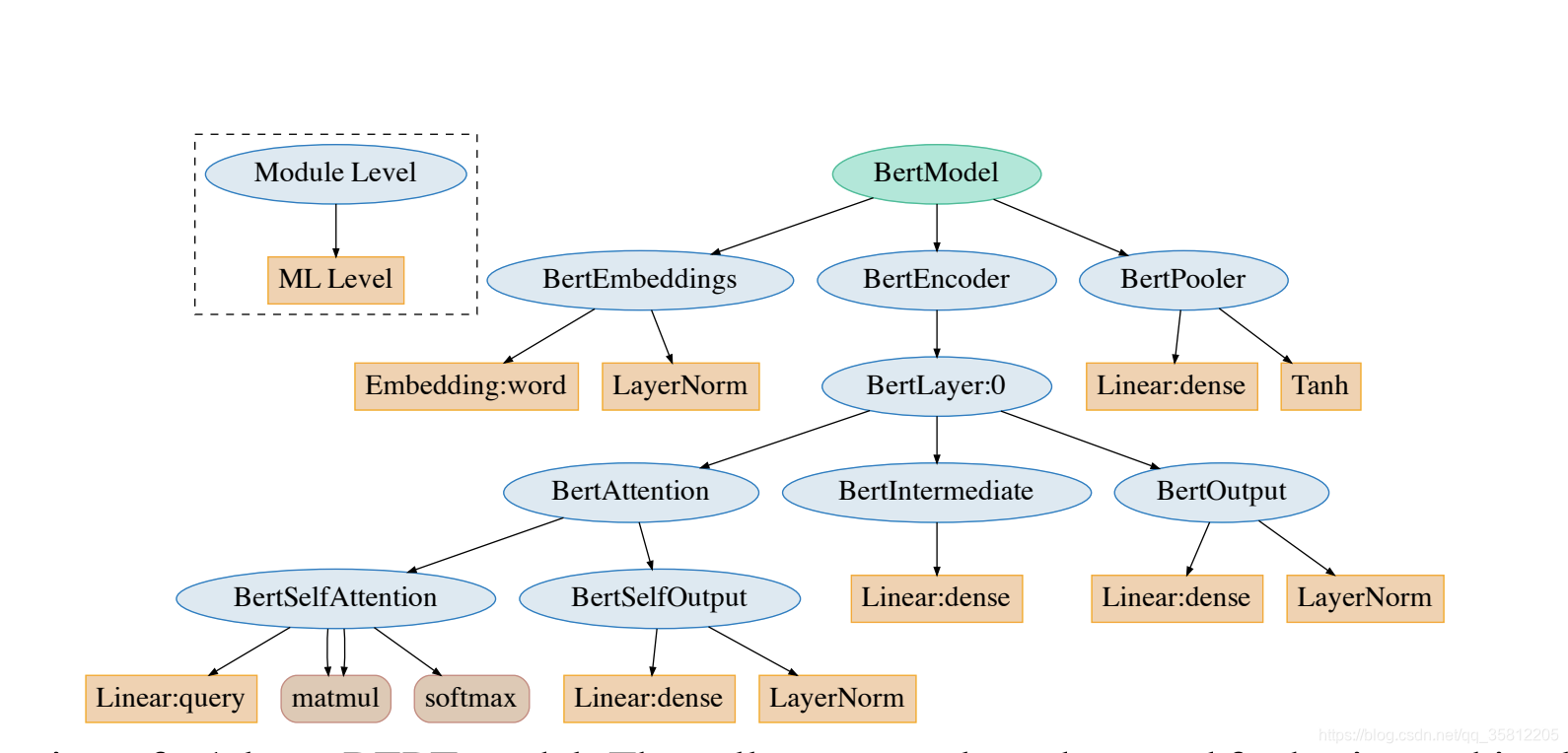
图:BERT结构,来源IrEne: Interpretable Energy Prediction for Transformers
(2)本次任务,主要讲解了BERT的源码(如上图结构),包括BertTokenizer、BertModel,其中:
BertTokenizer主要用于分割句子,并分解成subword;BertModel是BERT的本体模型类,主要包括BertEmbeddings、BertEncoder和BertPooler三部分:BertEmbeddings用于构造word、position和token_type embedings的Embeddings,BertEncoder由BertAttention、BertIntermediate和BertOutput三个部分组成,BertPooler用于取出句子的第一个token。
(3)子词切分:将一个单词切分为若干连续的片段,各种算法的基本原理都是使用尽量长且频次高的子词对单词进行切分。如在本次代码中的WordPieceTokenizer在词的基础上,进一步将词分解为子词(subword)。例如,tokenizer 这个词就可以拆解为“token”和“##izer”两部分,注意后面一个词的“##”表示接在前一个词后面。
BPE和WordPiece区别:两者在选择两个子词进行合并的策略不同——BPE选择频次最高的相邻子词进行合并,WordPiece选择能够提升语言模型概率最大的相邻子词进行合并。
【NLP】(task5)BERT应用到下游任务、训练和优化
先通过一表将BERT模型与其它文本表示方法进行对比:
| 对比项目 | BERT | GPT | ELMo | Word2vec |
|---|---|---|---|---|
| 基本结构 | Transformer | Transformer | Bi-LSTM | MLP |
| 训练任务 | MLM / NSP | LM | BiLM | Skip-gram或 CBOW |
| 建模方向 | 双向 | 单向 | 双向 | 双向 |
| 静态or动态 | 动态 | 动态 | 动态 | 静态 |
| 参数量 | 大 | 大 | 中 | 小 |
| 解码速度 | 慢 | 慢 | 中 | 快 |
| 常规应用模式 | 预训练+精调 | 预训练+精调 | 词特征提取 | 词向量 |
(1)基于上次的 B E R T BERT BERT 模型预训练,结合task5和task4。第三模块涉及几个 F i n e − t u n i n g Fine-tuning Fine−tuning任务:单句文本分类、多项选择、序列标注(词分类)和问答任务。分别从输入输出、模型结构等分析;
(2)第四模块是 B E R T BERT BERT 训练和优化部分: P r e − T r a i n i n g Pre-Training Pre−Training的参数共享, B E R T BERT BERT 的优化器: A d a m W AdamW AdamW( A d a m W e i g h t D e c a y O p t i m i z e r AdamWeightDecayOptimizer AdamWeightDecayOptimizer)和 B E R T BERT BERT的训练策略 W a r m u p Warmup Warmup。
(3)以下为关于 transformers 库(4.4.2 版本)中 BERT 应用的相关代码的具体实现分析。
【NLP】(task6)Transformers解决文本分类任务 + 超参搜索
(1)学习用BERT模型解决文本分类任务的方法及步骤,步骤主要分为加载数据、数据预处理、微调预训练模型和超参数搜索。
- 在加载数据阶段中,GLUE榜单包含了9个句子级别的分类任务,要使用与分类任务相应的
metric; - 在数据预处理阶段中,对
tokenizer分词器的建模,并完成数据集中所有样本的预处理; - 在微调预训练模型阶段,通过对模型参数进行设置,并构建
Trainner训练器,进行模型训练和评估; - 最后在超参数搜索阶段,使用
hyperparameter_search方法,搜索效果最好的超参数,并进行模型训练和评估。
(2)天国大佬的tips:其中在数据集下载时,如果没有fanqiang的话需要使用外网方式建立代理(见第五部分)。如果使用conda安装ray[tune]包时,请下载对应ray-tune依赖包。
【NLP】(task7)Transformers完成序列标注任务
(1)回顾 fine tune BERT 解决新的下游任务的5个步骤:
1)准备原始文本数据
2)将原始文本转换成BERT相容的输入格式(重点,如下图所示)
3)在BERT之上加入新layer成下游任务模型(重点)
4)训练该下游任务模型
5)对新样本做推论
而利用HuggingFace后,我们是在BERT上加入dropout和linear classsifier,最后输出用来预测类别的logits(即用了迁移学习的思想)。

(2)本次学习围绕序列标注(有NER、POS、Chunk等具体任务)中命名实体识别(Name Entity Recognition,NER):传统神经网络模型的命名实体识别方法是以词为粒度建模的;而在本次的BERT预训练语言模型用作序列标注时,通常使用切分粒度更小的分词器(如WordPiece)处理输入文本——破坏词与序列标签的一一对应关系。
(3)用BERT模型解决序列标注任务(即为文本的每个token预测一个标签):
- 在加载数据阶段中,使用
CONLL 2003 dataset数据集,并观察实体类别及表示形式; - 在数据预处理阶段中,对
tokenizer分词器的建模,将subtokens、words和标注的labels对齐,并完成数据集中所有样本的预处理; - 在微调预训练模型阶段,通过对模型参数进行设置,设置
seqeval评估方法(计算命名实体识别的相关指标),并构建Trainner训练器,进行模型训练,对precision(精确率)、recall(召回率)和f1值进行评估比较。
三、小结
四、下一阶段
把推荐的课程和书看了并做笔记+自己理解&总结:
Stanford的CS224课程:CS224n: Natural Language Processing with Deep Learning
Stanford的NLP讲义:Speech and Language Processing
今年2021年7月又出了新的预训练模型prompt,http://pretrain.nlpedia.ai/这个网站很多资源。
五、Reference
(1)Xiao Tong and datawhale course’s help(such as duoduo and so on)
(2)https://wmathor.com/index.php/archives/1534/