(关键词:手把手教程、反爬、数据库、python爬虫、微博爬虫、较大数据量、数据简单过滤、ip代理池)
本教程适合有实际应用需求的python爬虫入门者阅读,该实例针对目标网站微博在requests库爬虫的基础上做了一些问题的优化,最终实例可用满足于较大数据量的数据爬取需求。作者更希望从较入门内容出发制作教程,您可以对本文内容稍作省略。
完整实例源码将放置在文末github链接中。
项目准备
Python & Pycharm
主要使用到的库有:
requests:requests库是Python中用来模拟浏览器发送网络请求与得到响应数据包的库
json:用于解析(如格式化为方便python处理的字典格式)得到的响应数据包,以便于后续对得到的数据进行操作处理
pymysql:是python下用于对mysql数据库进行相关操作的一个库,本项目中用于将爬取数据加入到本地构建好的数据库中,以及其他的相关操作(增删改查)
Mysql数据库 & Datagrip
为了适用本项目较大规模数据的存放处理以及后续的使用,因此使用了数据库。
如果数据量不大或者没有较高的数据分析需要,你也可以考虑将数据以.csv或.xlsx的格式直接保存生成(该方式直接在python源码中即可完成,可以去看一看其他教程)
本项目使用本地sql数据库存放爬取数据,为方便数据库的相关使用,选用Datagrip作为IDE对数据库进行一些操作。Datagrip界面如下:
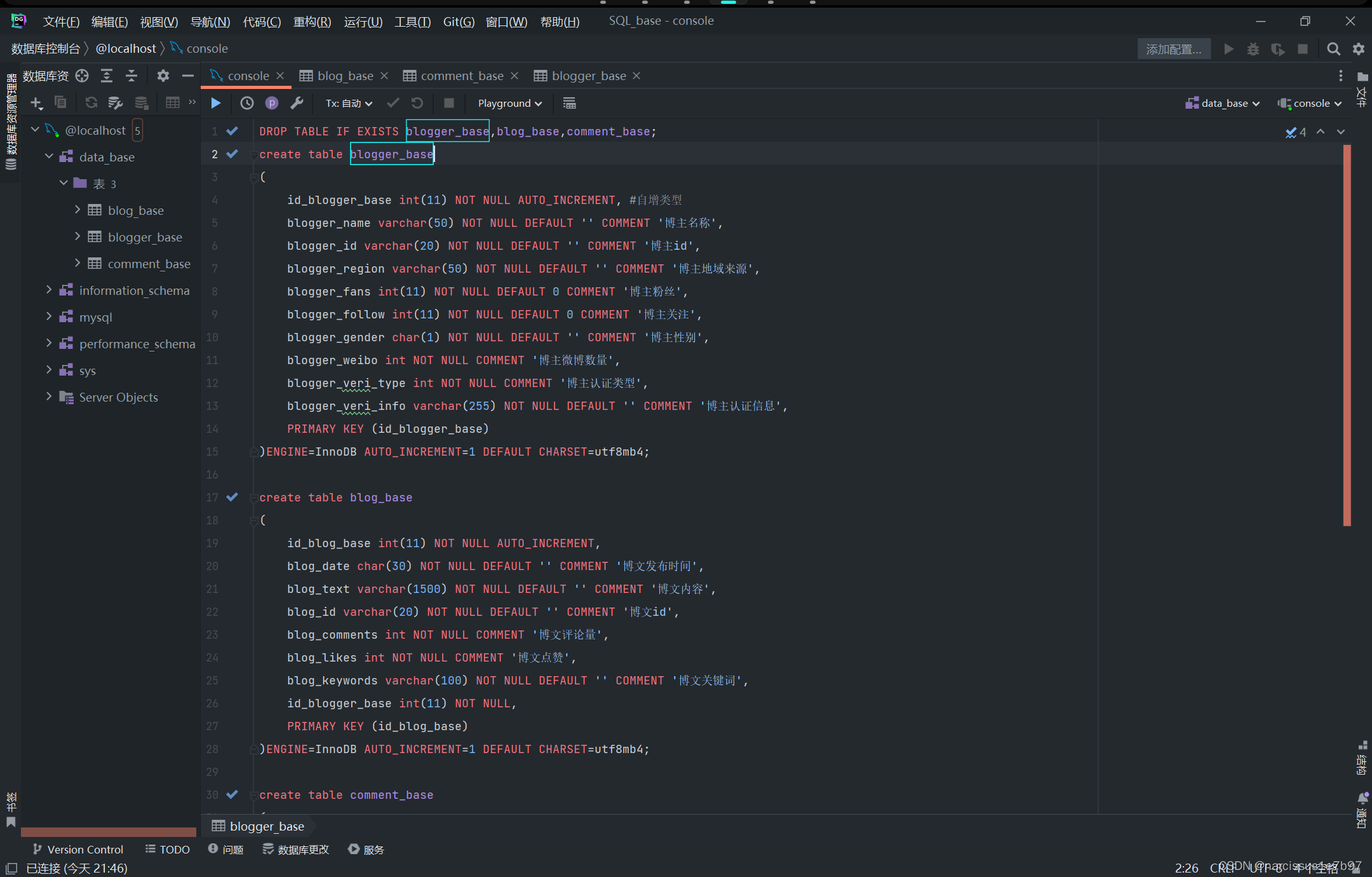
Docker
项目需要使用自建ip代理池应对微博反爬问题,该ip池的安装与使用请查看该教程:
构建一个属于自己的爬虫 ip 池 | 自用 | 免费 | 2021年10月 | windows
需求分析
1、本项目希望实现对一些账号进行特定时间段内所有博文的爬取(或依照关键字进行筛选)并获得博文下的评论与评论者的个人信息。
2、爬取的数据在数据库中分为blogger_table、blog_table、comment_table分别存储博主数据、博文数据、博文评论数据(包含评论者的信息)。各数据表间通过索引相关联(如comment_table中一条评论数据可由索引对应到blog_table中其所属的博文数据行),以此实现数据间的关联。
列举部分目标数据项如下:
blogger_name 博主名称blogger_region 博主地域来源blogger_fans 博主粉丝blogger_follow 博主关注blogger_veri_info 博主认证信息blog_date 博文发布时间blog_text 博文内容comment_text 评论内容commenter_name 评论者名称commenter_region 评论地域来源
数据定位
阅读本内容请先搜索requests库的基本使用,了解get请求与响应的基本概念!
定位博主个人信息
1、浏览器打开微博网站(pc版,请务必登录),点开任一博主的个人界面,f12打开开发者工具。
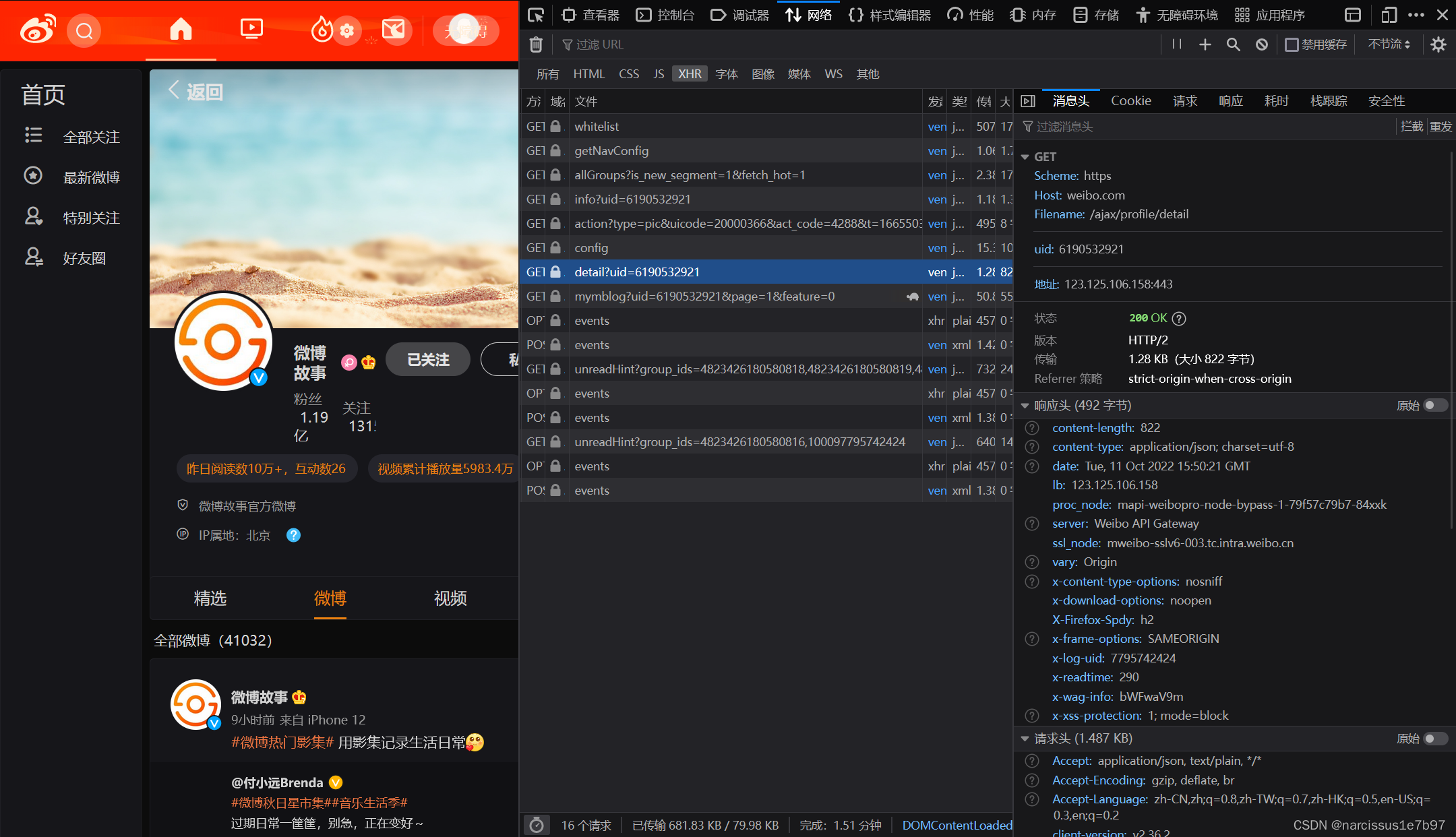
2、选中XHR
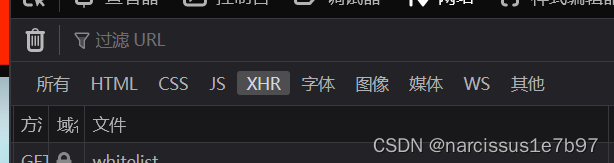
3、选中该文件

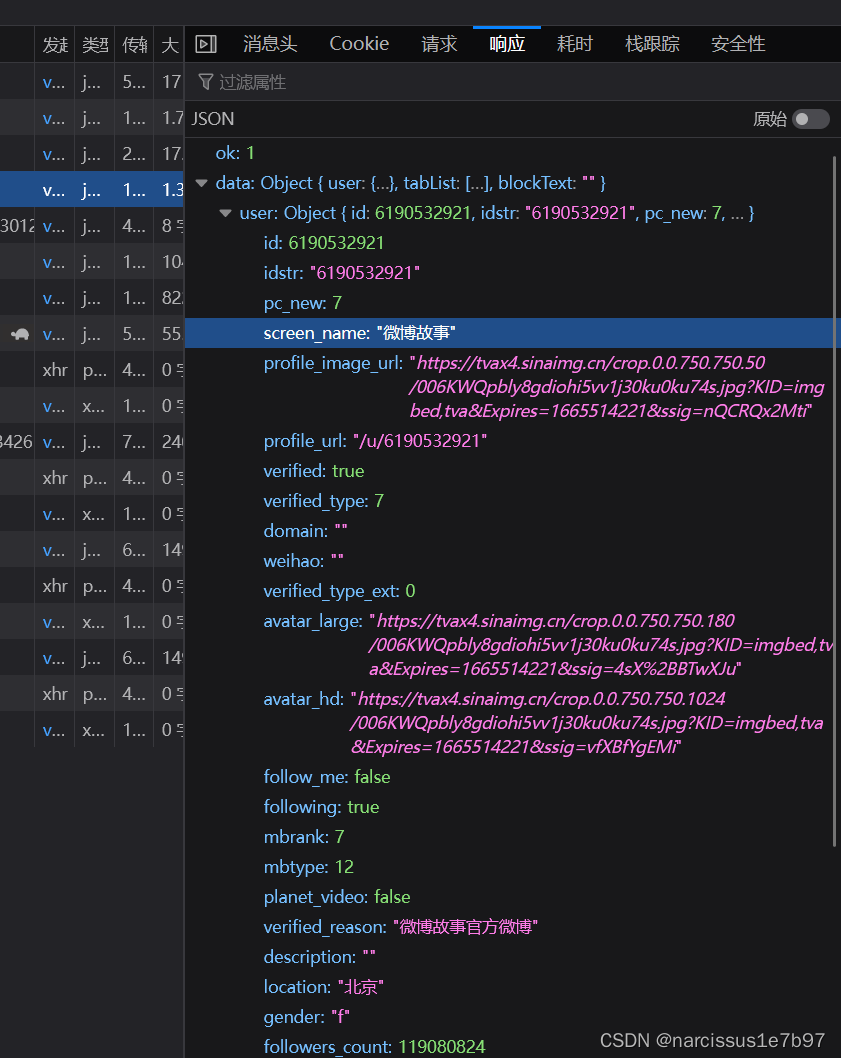
在右侧栏中找到响应,就可以得到博主的个人信息了(如screen_name、location、gender)。
稍后我们在编写过程中使用requests包模拟浏览器得到该JSON响应文件的过程,然后获得如下图所示的JSON数据,再使用json包将该数据格式化为字典,方便获得想要的数据项。
定位博主的博文位置
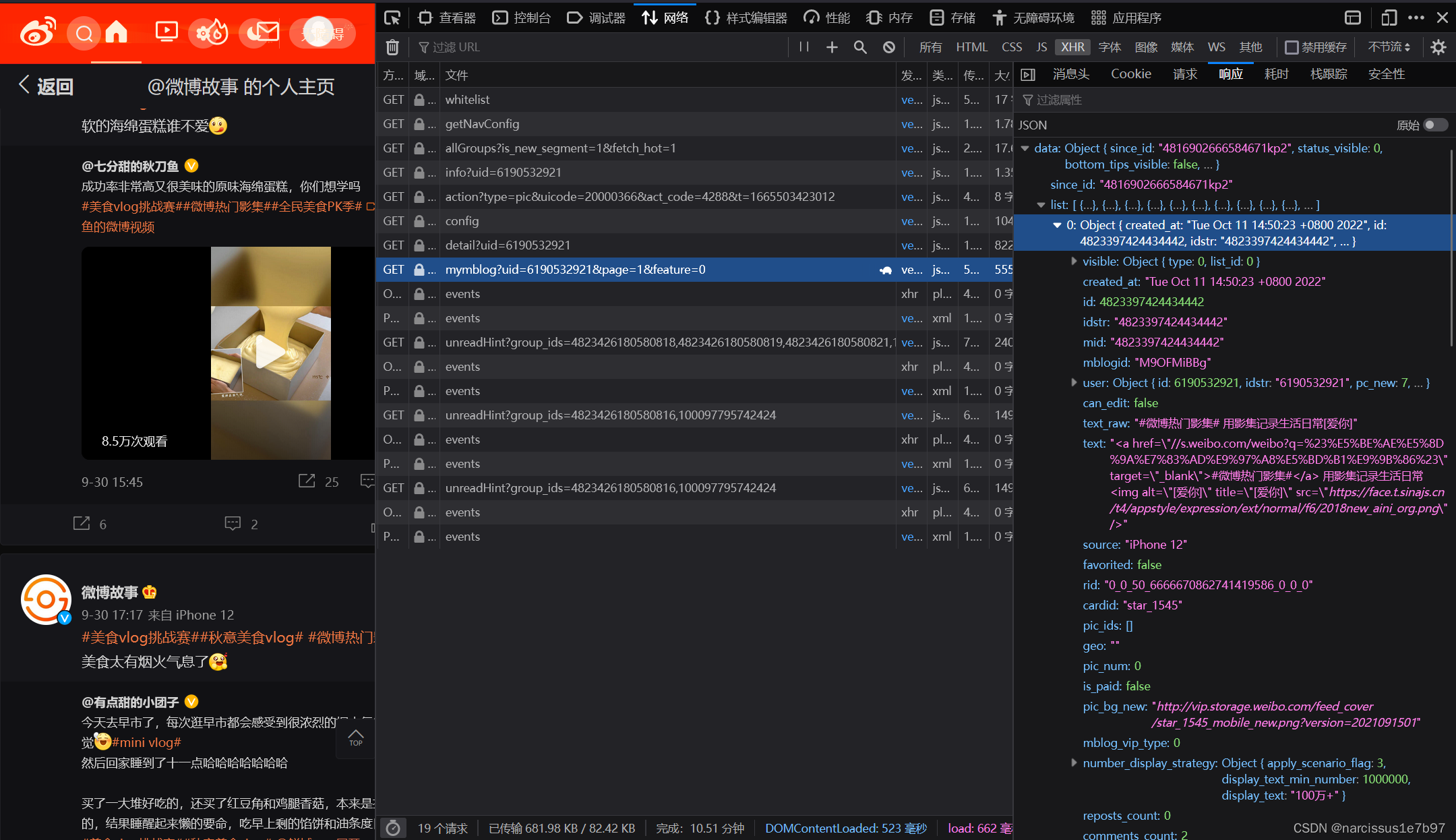
微博博文的响应数据包是按照一页多条blog来发送的,该响应数据包对应的文件名为:

uid这里指博主的用户id,page取不同数是不同的博文数据包。
下方的若干Object 每一项均为一条博文
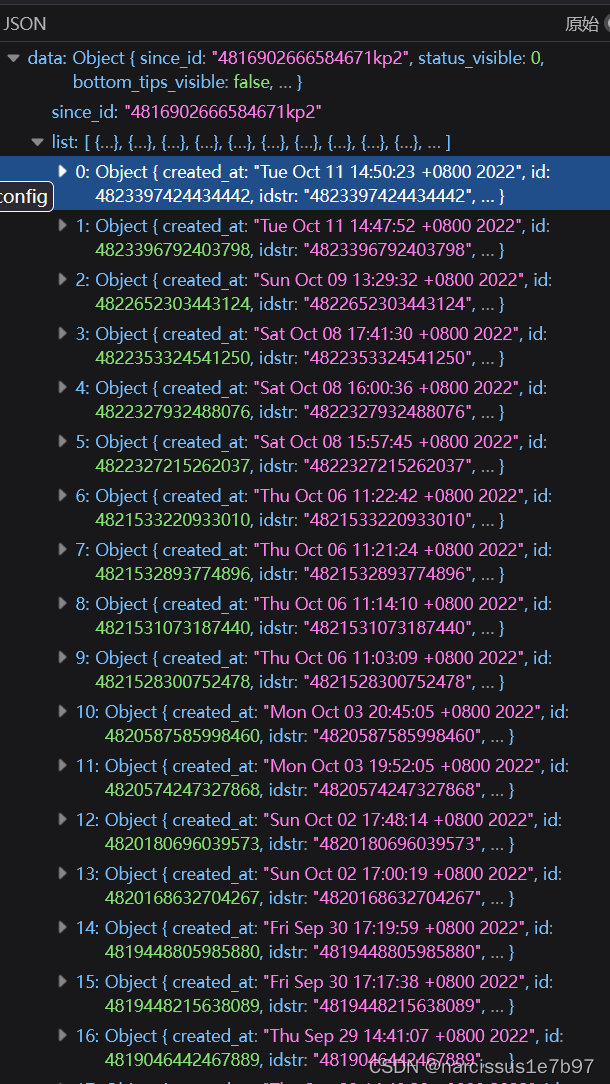
定位评论位置
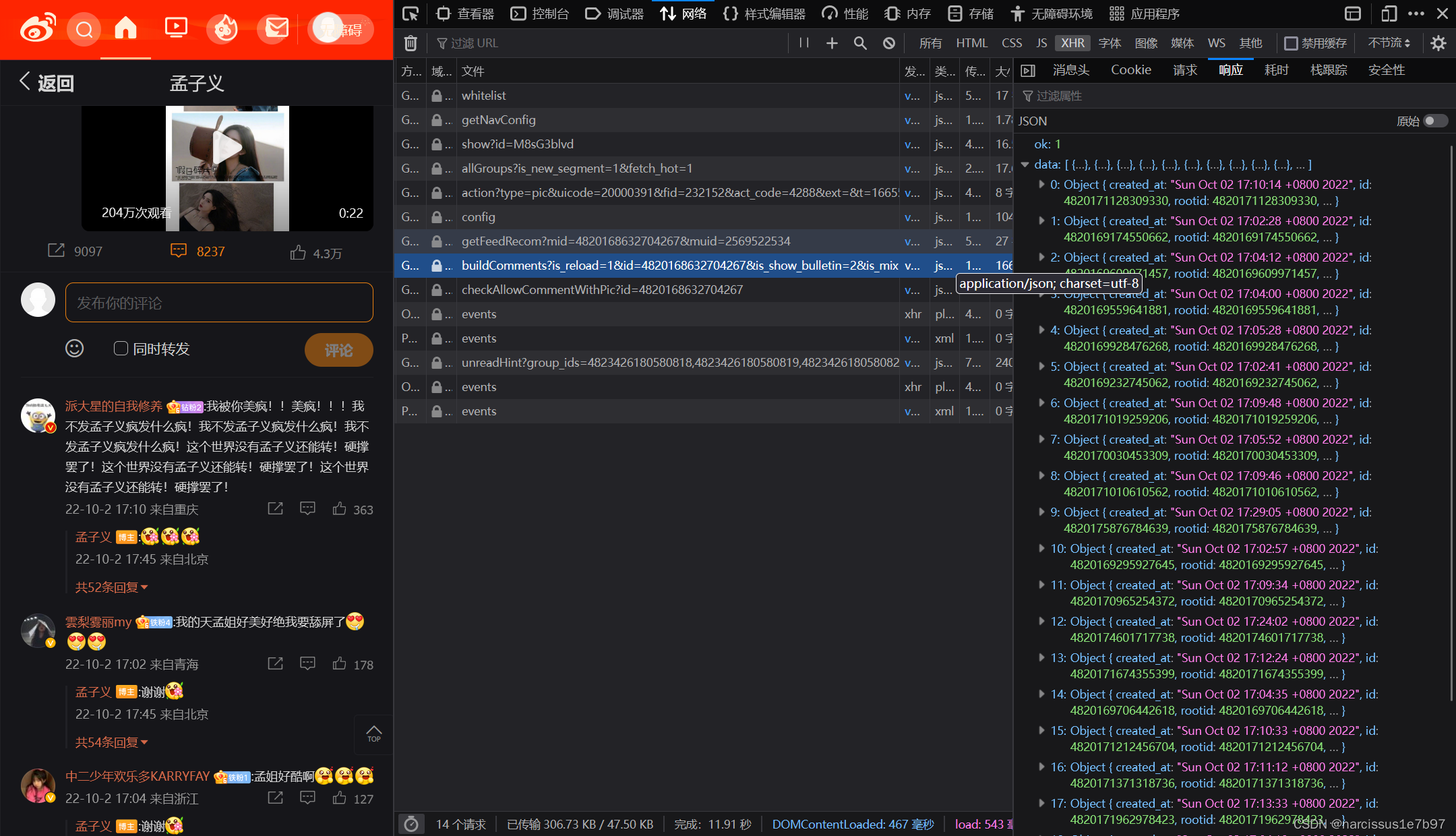
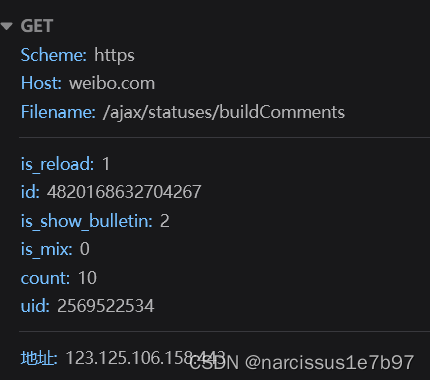
点开一条博文的评论然后进入该博文的详情页,可以得到文件名为:

鼠标滚轮往下翻评论的过程中会刷新出现若干新评论的响应数据包。但值得注意的是,与上一个博文定位不同,此时各数据包的区分并不是用page的增加来实现的

该博文的评论区,除了最前面的若干评论(对应文件列表里未刷新时的唯一一个评论数据包)以外,其余评论数据包的GET请求参数都多了一项内容max_id (注意下列两项的GET参数区分)。
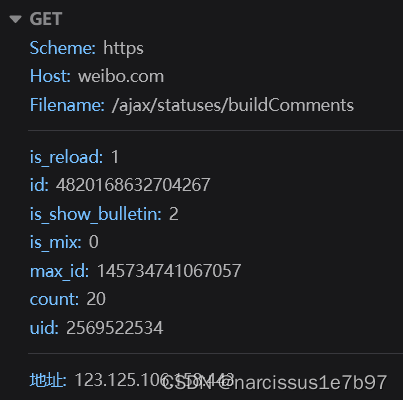
博文的定位中我们修改page的值然后模拟发送即可获得所有的博文内容,而此处我们无法采用同样的操作——很显然,max_id不是按照page那样自增的规律。
该如何获得该博文的所有的评论呢?还是需要使用max_id,其实是这样:
1、你会发现前一个评论数据包的响应JSON包含了一个max_id(如图),这个max_id其实是下一个评论数据包GET请求中所需的max_id值
2、因此,只需要获取首个评论数据包的响应JSON中的max_id值,我们就可以获得第二个评论数据包,第二个评论数据包的响应JSON中又包含了一个max_id值,对应下一个评论数据包的GET请求参数,以此类推首尾相连。最后一个评论数据包的响应JSON不含max_id,可以作为过程结束的条件。
3、这样我们就可以获得全部的评论信息了

基本框架
以下是基本功能的实现过程,下一步会对各函数进行修改以完善。
先来爬爬用户信息叭
关于requests库的基本使用在此不做叙述,请查阅其他文章。
1、需要传入的headers项中,我设置了如下四项以保证获得响应JSON。
项目中的cookie我定义为了全局变量,以方便cookie的替换,Connection项设置为close避免过多请求带来的可能异常(或许这一项并不需要?)
2、requests.get()后记得进行utf8编码
3、用json.loads()解析res,得到字典格式的json_data
4、参照之前开发者工具中显示的层级关系,在json_data中获得需要的数据
5、认证信息存在为空但用户时认证用户的情况需要特判(verified_type是200、220这些)
import requests, json
def user_info(user_id):
params = {
'custom': user_id,
}
headers = {
'Referer': 'https://weibo.com/' + str(user_id),
'Host': 'weibo.com',
'Cookie': cookie,
'Connection': 'close'
}
res = requests.get('https://weibo.com/ajax/profile/info', headers=headers, params=params).content.decode("utf-8")
json_data = json.loads(res)
print('博主id:', json_data['data']['user']['id']) # 博主id
print('ip归属地:', json_data['data']['user']['location']) # ip归属地
print('博主名:', json_data['data']['user']['screen_name']) # 博主名
print('粉丝数:', json_data['data']['user']['followers_count']) # 粉丝数
print('关注数:', json_data['data']['user']['friends_count']) # 关注数
print('性别:', json_data['data']['user']['gender']) # 性别(f & m)
print('总微博数量:', json_data['data']['user']['statuses_count']) # 总微博数量
print('认证类型:', json_data['data']['user']['verified_type']) # 认证类型
if json_data['data']['user']['verified_type'] != -1:
print('认证信息:', json_data['data']['user']['verified_reason']) # 认证信息(注意缺省)
else:
print("Not verified")verified_type的字段:
-1普通用户;
0名人,
1政府,
2企业,
3媒体,
4校园,
5网站,
6应用,
7团体(机构),
8待审企业,
200初级达人,
220中高级达人,
400已故V用户。
-1为普通用户,200和220为达人用户,0为黄V用户,其它即为蓝V用户